
Cosmin Cătălin Sanda
Data Scientist & Engineer
Cosmin Catalin Sanda
Data Scientist and Engineer at AudienceProject
Blogging at https://cosminsanda.com
Github at https://github.com/cosmincatalin
AudienceProject helps brands, agencies and publishers plan, optimize and validate digital campaigns and to activate our customers online audiences in order to deliver reach
in high-value segments.
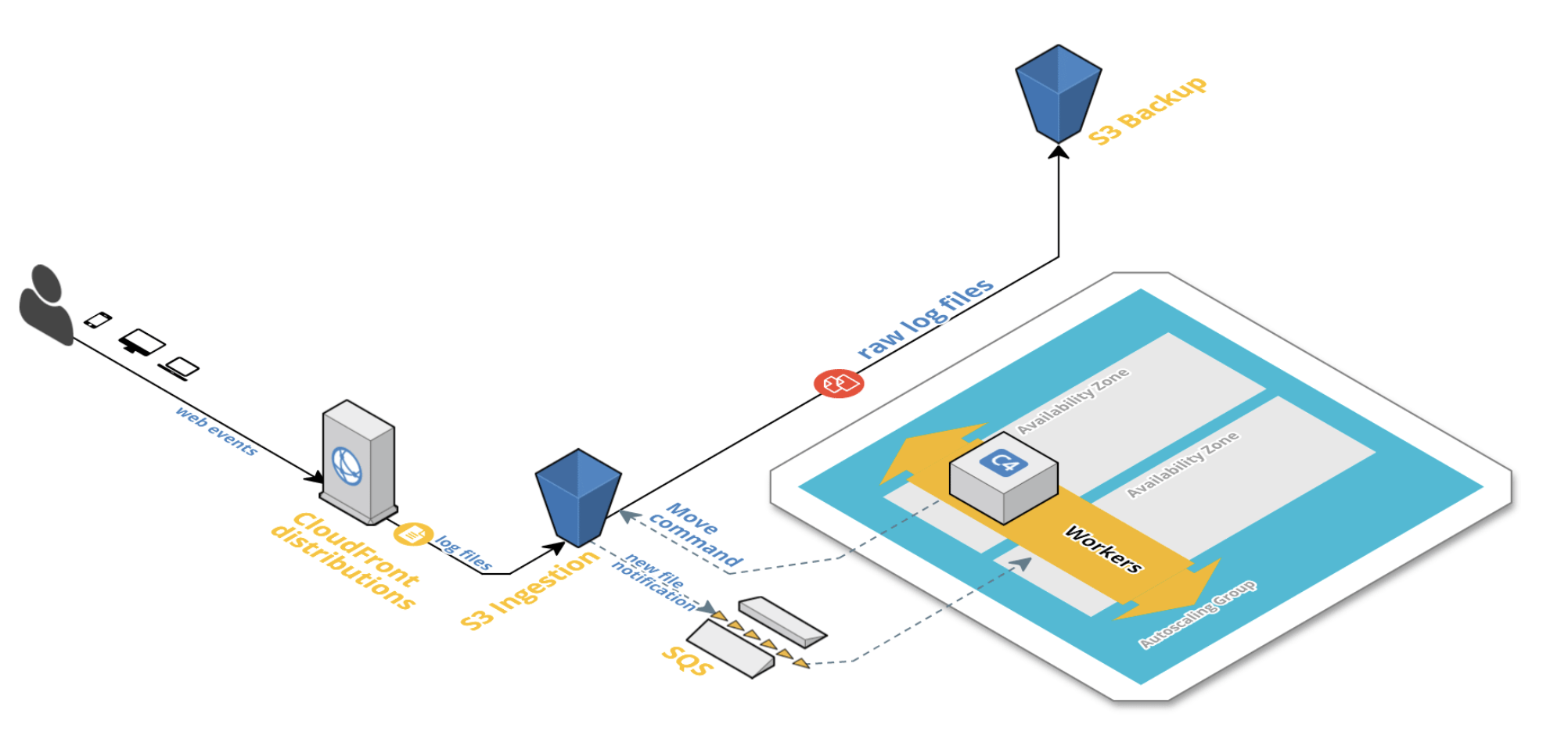
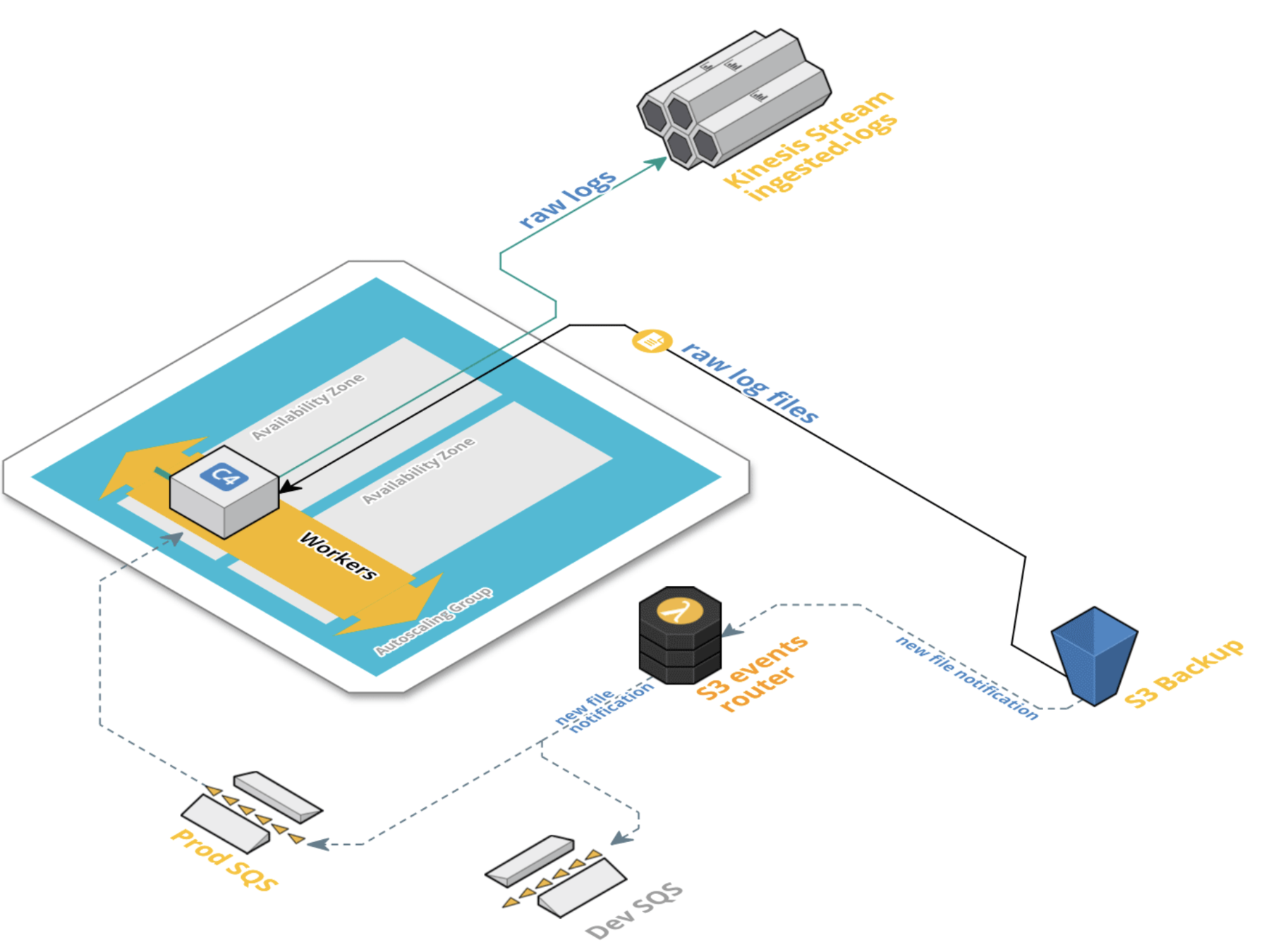
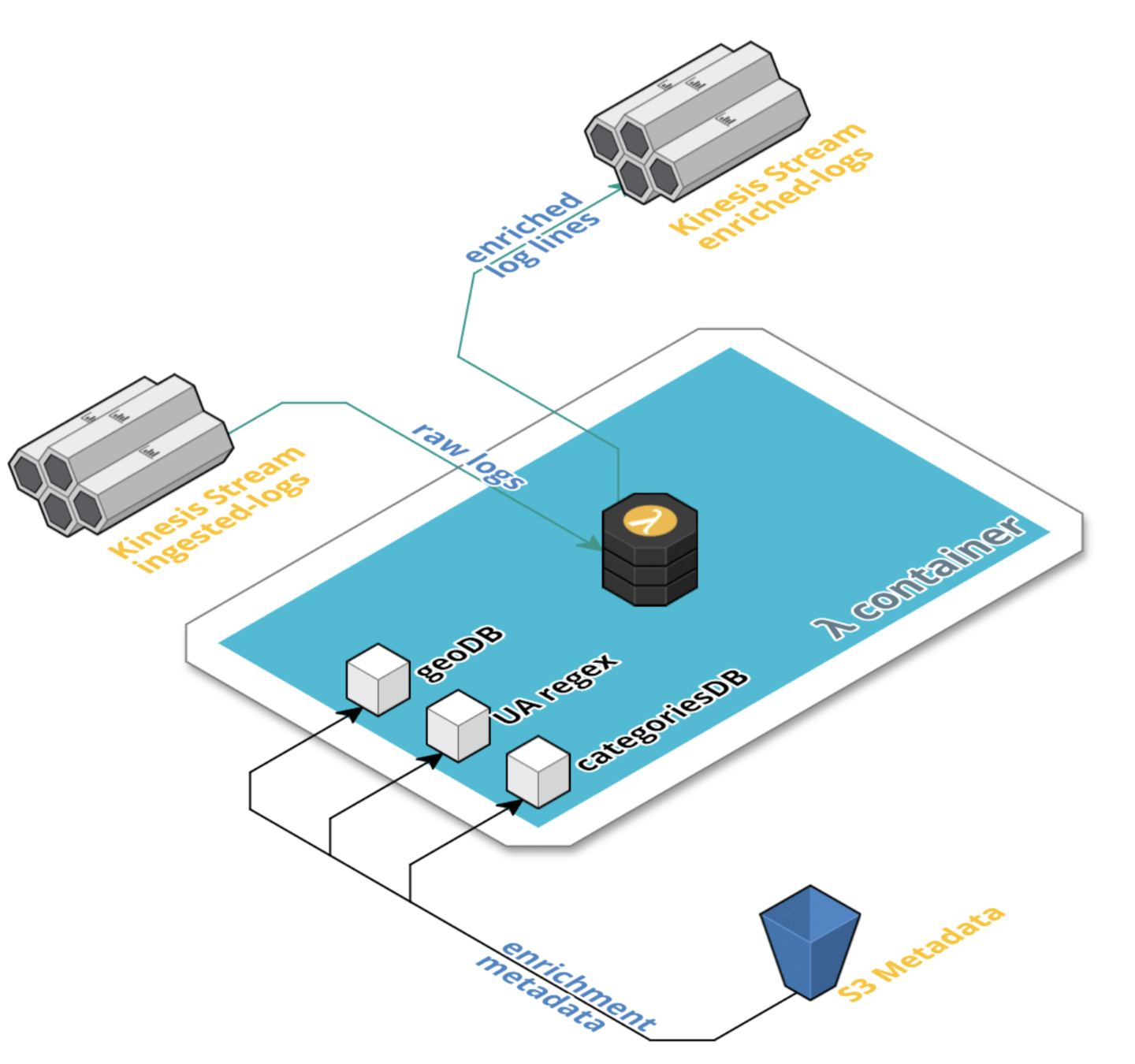
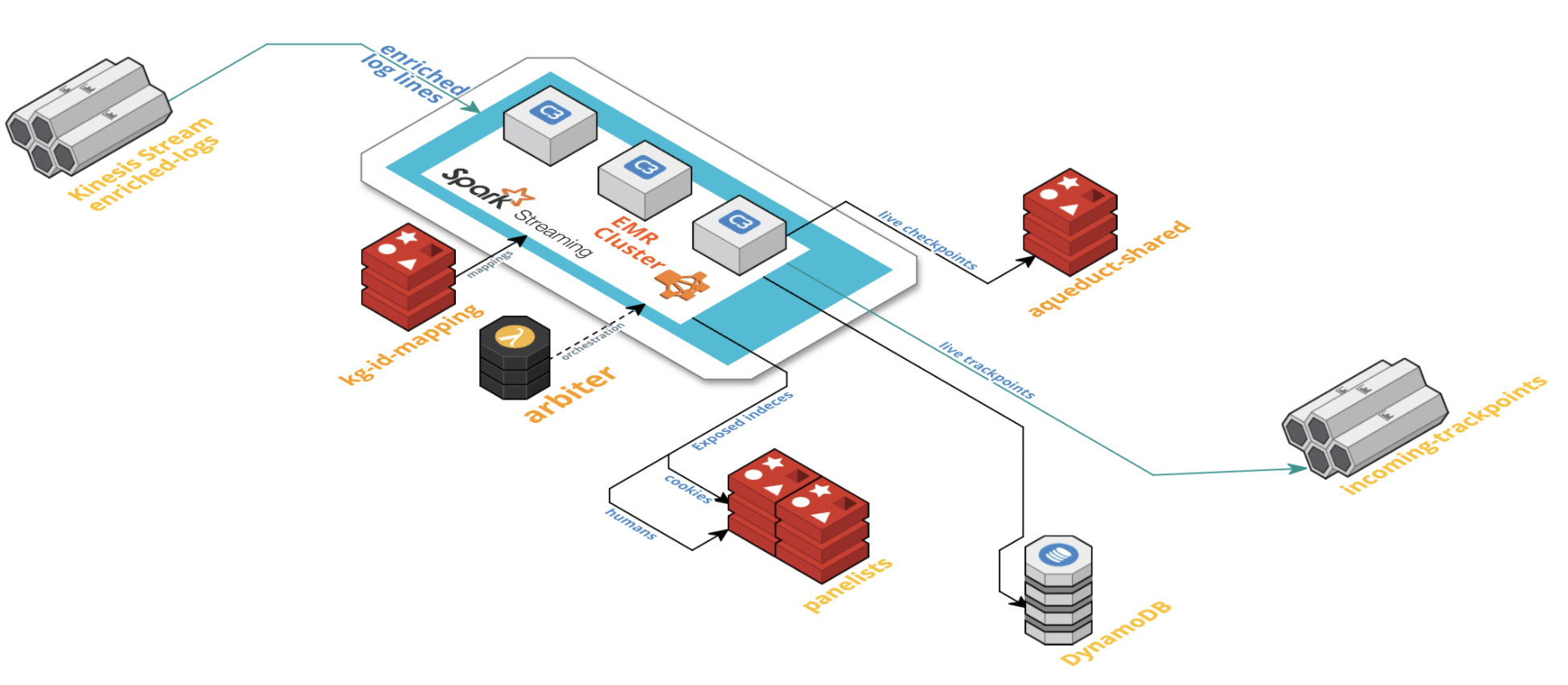
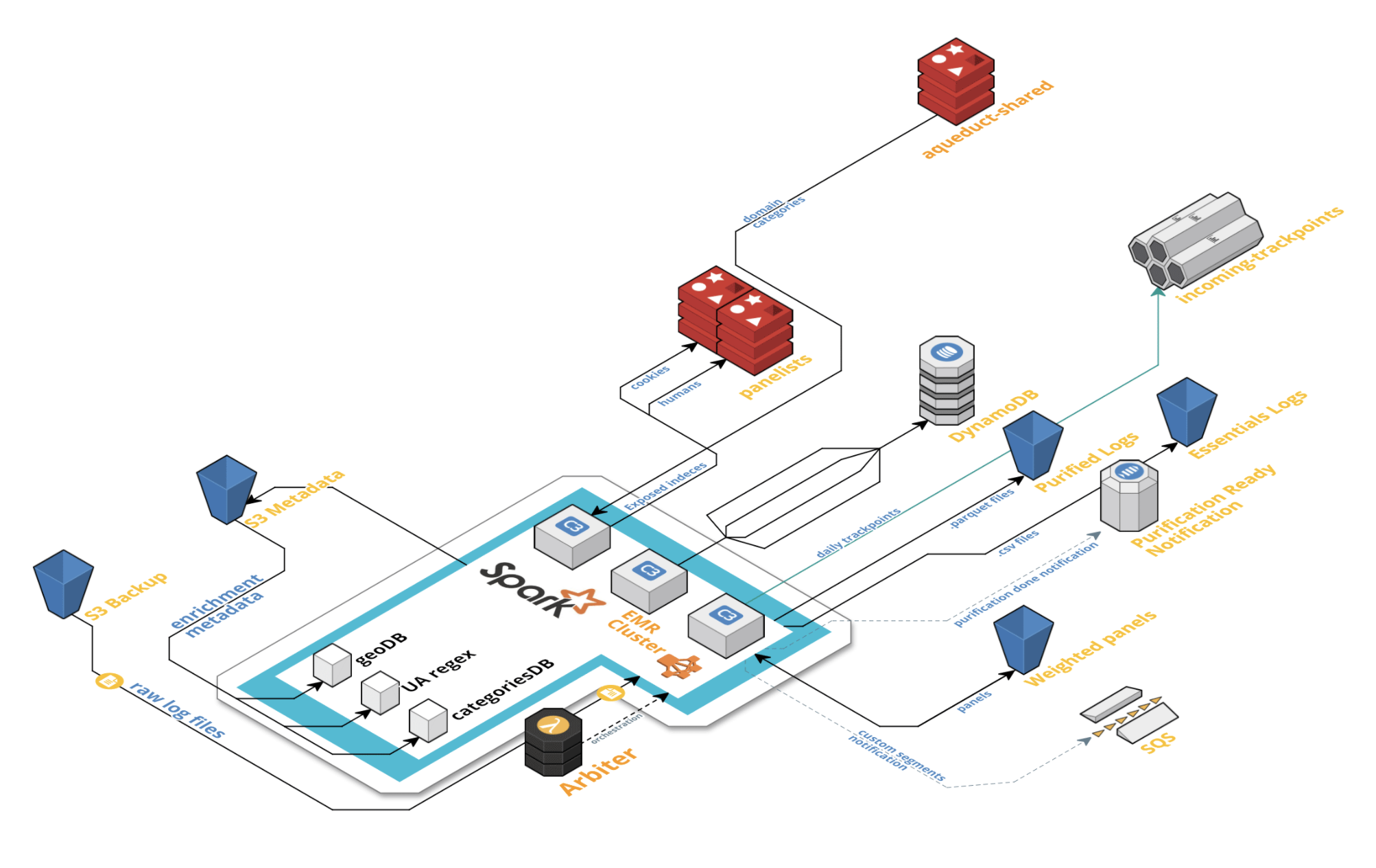
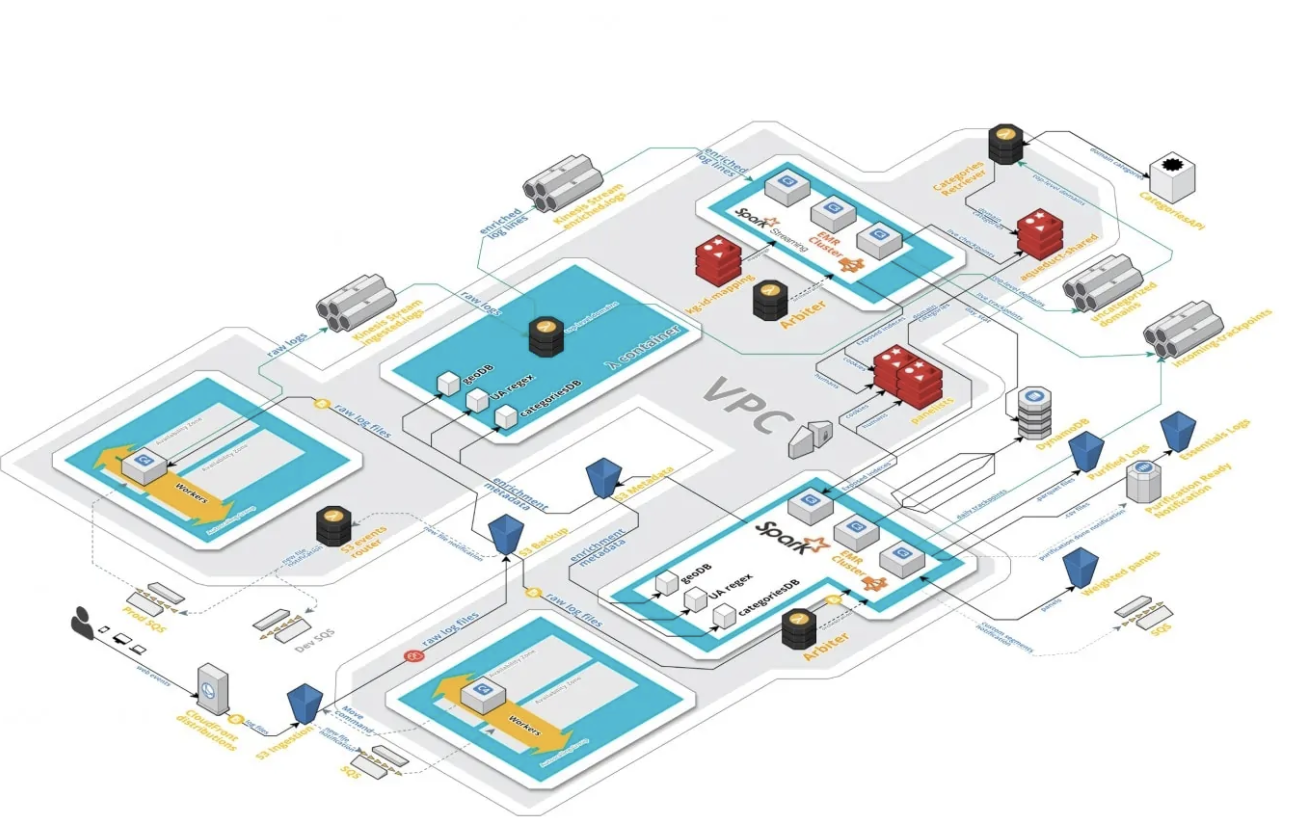
Problems with the old pipeline:
The new pipeline in turn needed to be:
Business impact
By Cosmin Cătălin Sanda


