



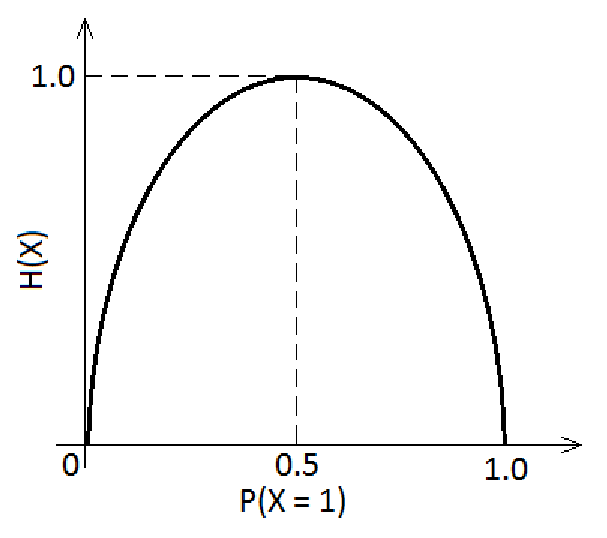



cvanelteren
Computational scientist
Casper van Elteren
Dynamic importance of nodes is poorly predicted by static topological features
Complex systems are ubiquitous
Most approaches are not applicable to complex systems:
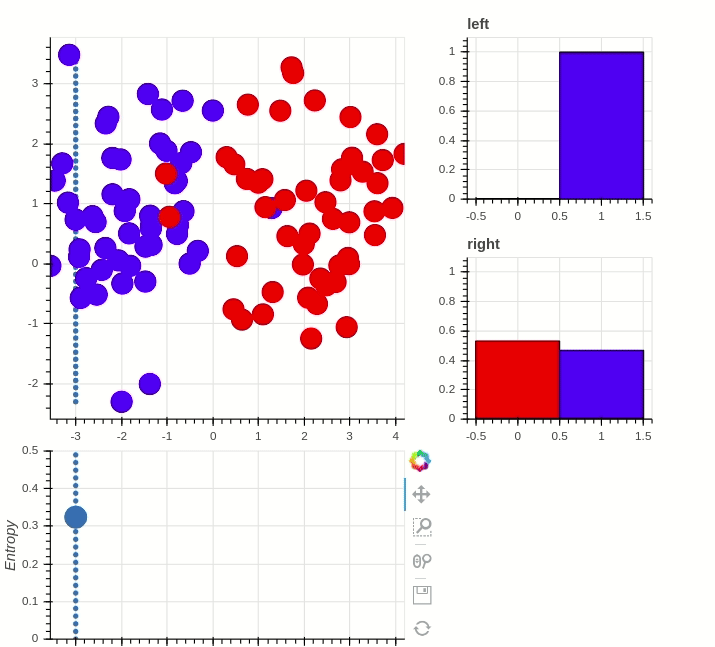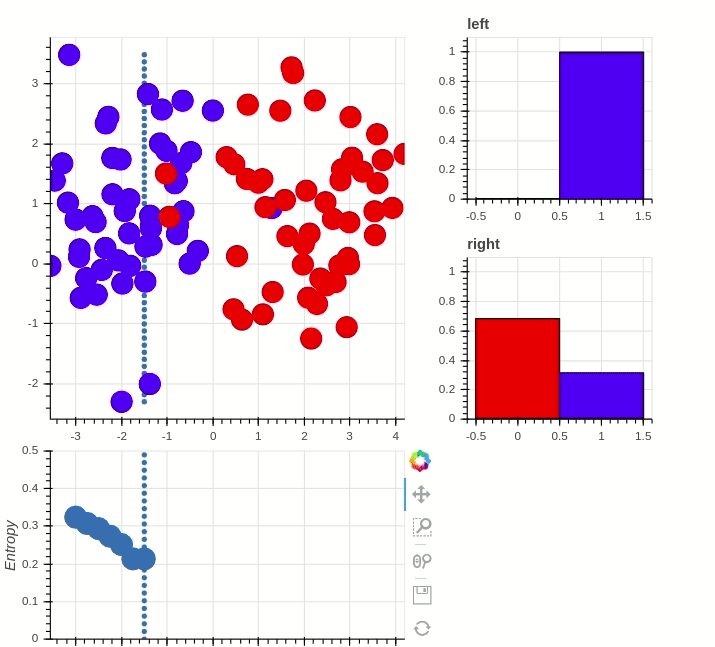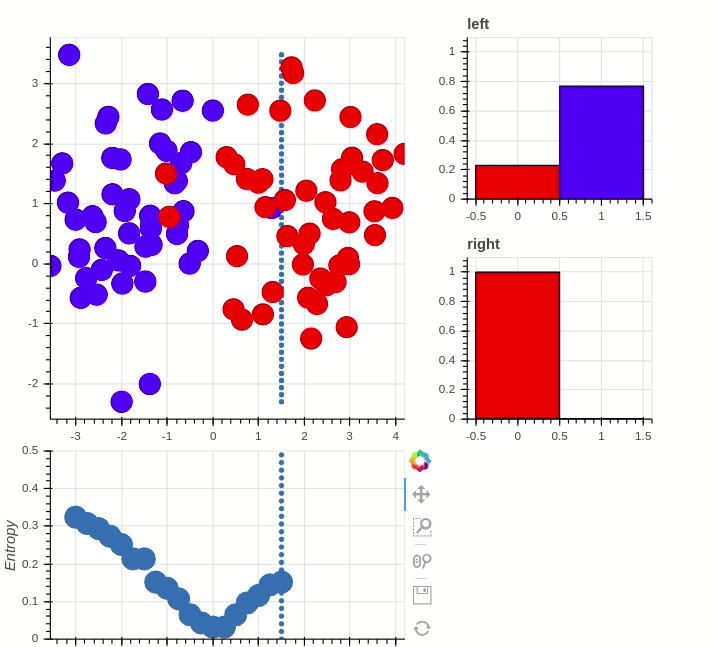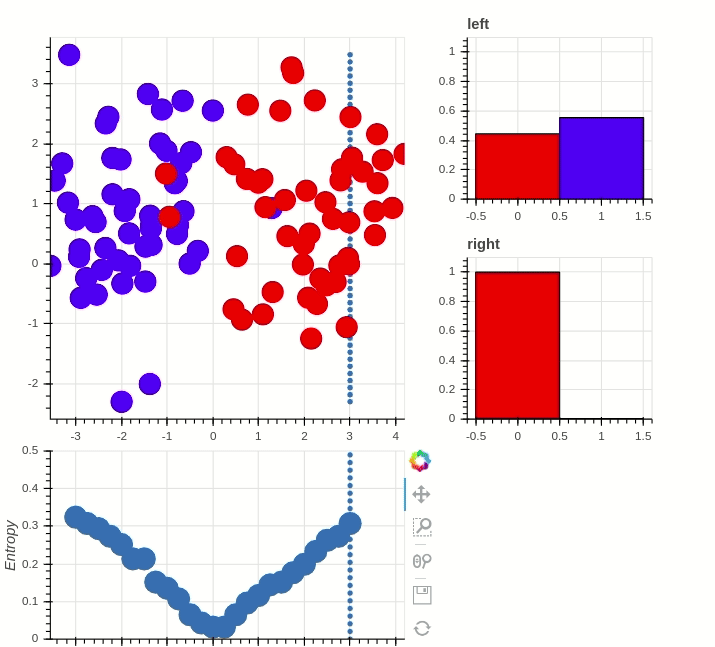
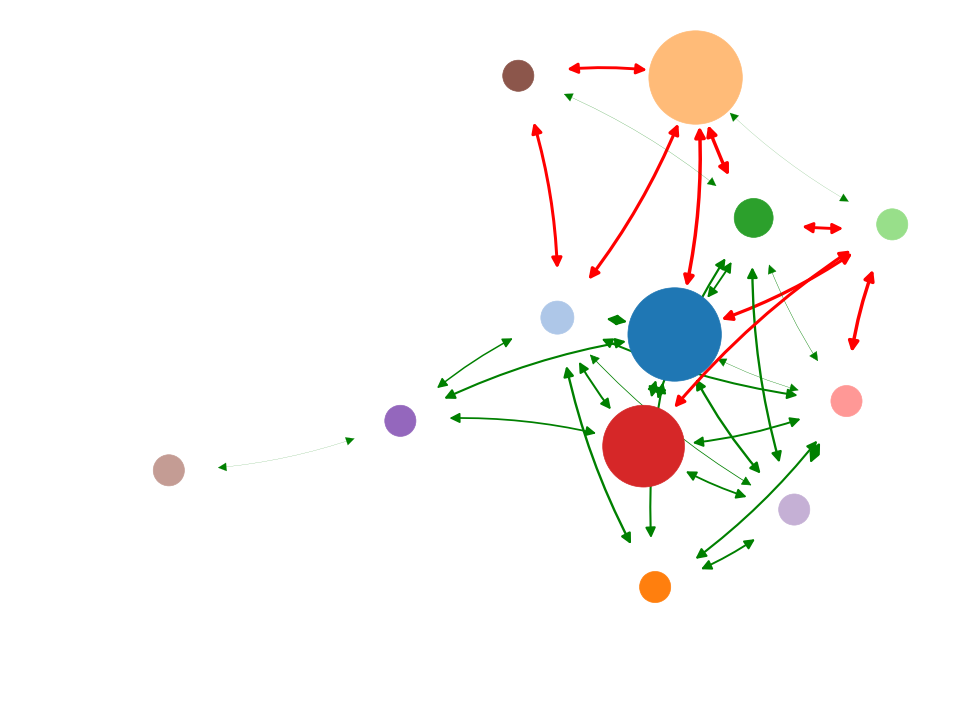
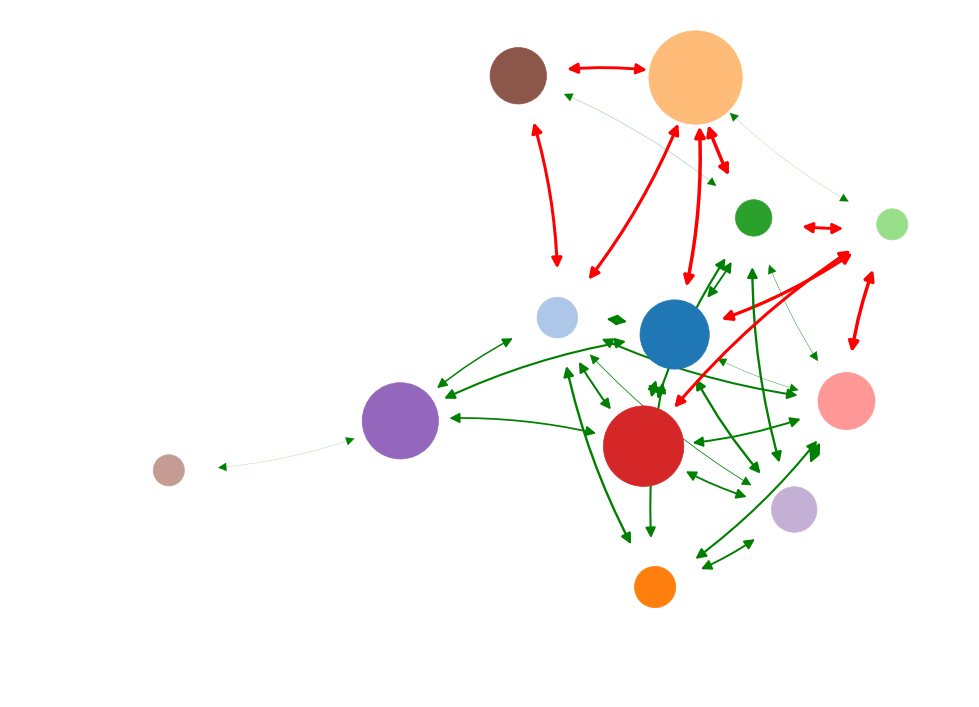
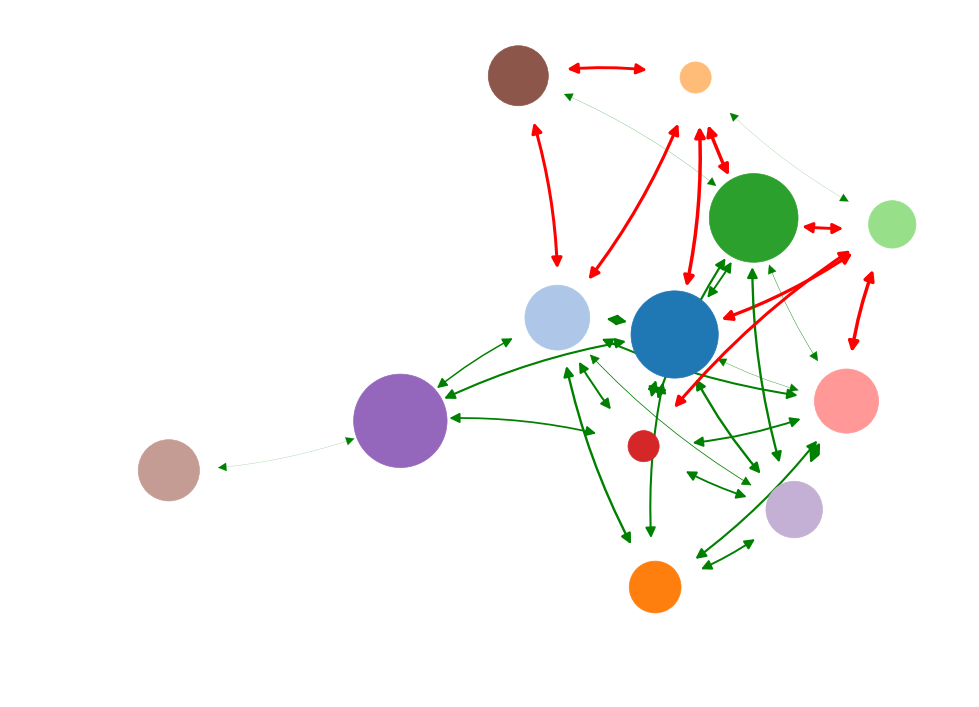
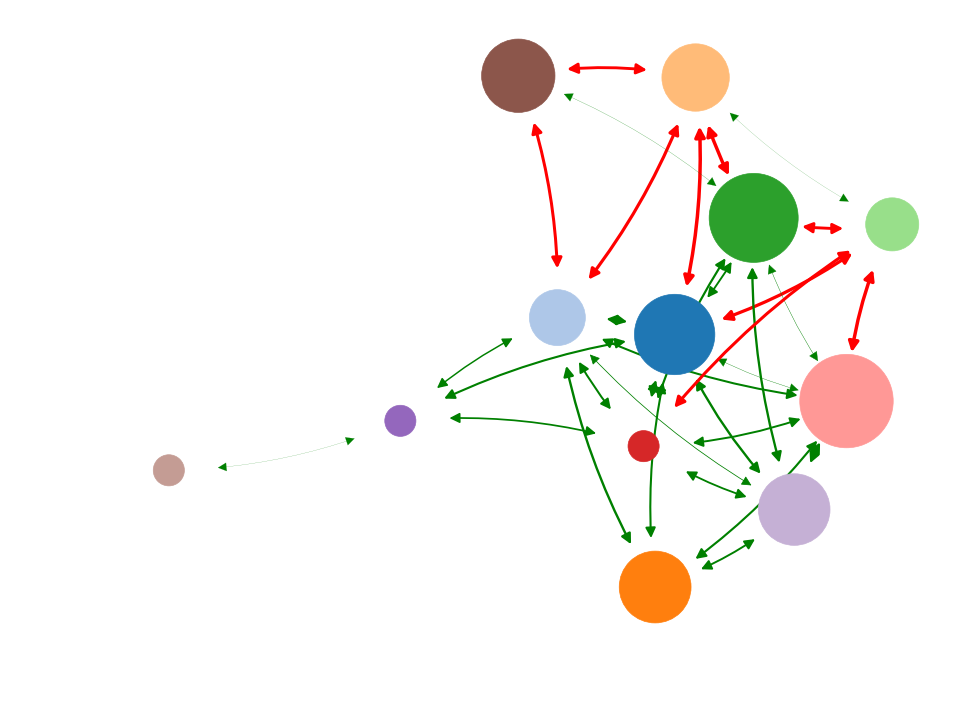
What is the most important node?
> What node drives the system?
Wang et al. (2016)
However we have a many-to-one mapping
1. Simplified dynamics
"Well-connected nodes are dynamically important"
2. Which feature to select?
N.B. implicit dynamics assumption!
Harush et al. (2017)
2. Dynamic importance interacts with structure
Genetic
Epidemic
Biochemical
Ecological
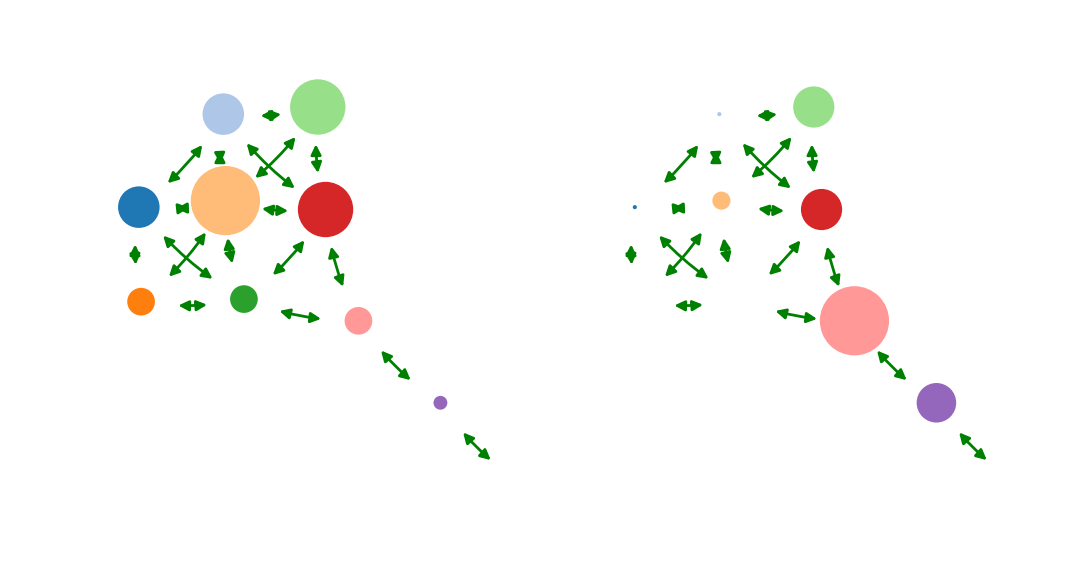
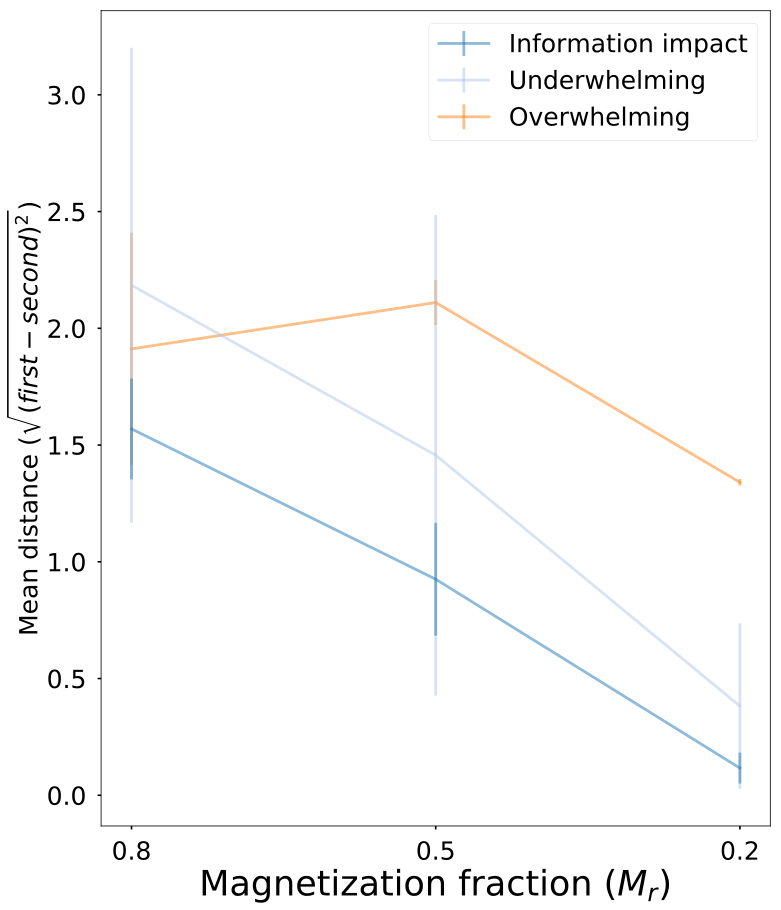
3. The size of intervention matters
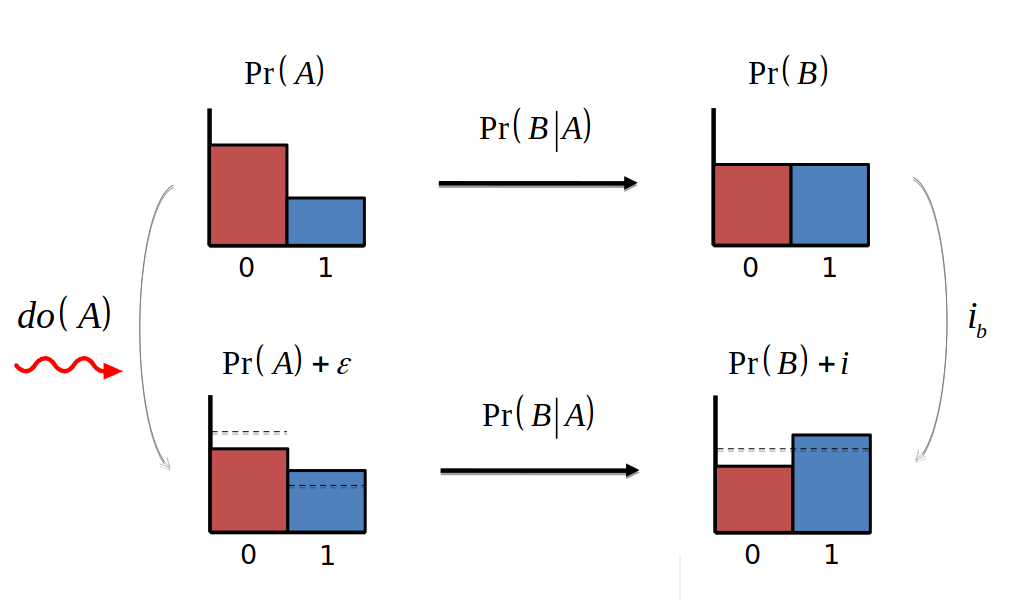
Pearl (2000)
Mechanism driving behavior are different under overwhelming interventions!
We have seen:
Possible solution: information theory
Information theory and complex systems
Traditional approaches are domain specific but all ask similar questions, e.g.:
Quax et al. (2016)
How to achieve universal approach to study various complex behavior?
There is a need for a universal language that decouples syntax from semantics
Quax et al. (2016)
Domain specific
+
Quantify in terms of "information"
Traditional approach
Information viewpoint
Up
Down
...
P(System)
Up
Down
...
P(Bird)
Shannon (1948)
Information Entropy: "Amount of uncertainty"
Mutual information: "Shared information"
N.B. No assumption on what generates P
Information in complex systems
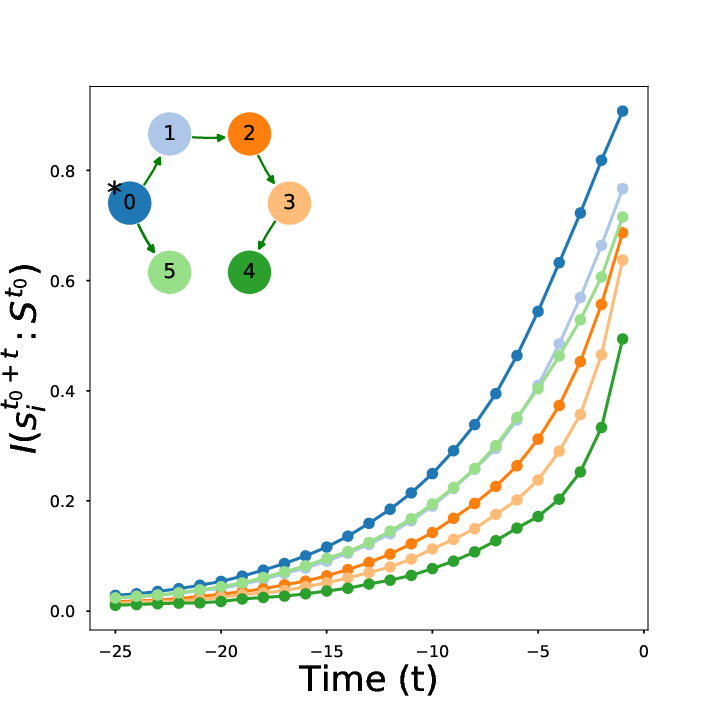
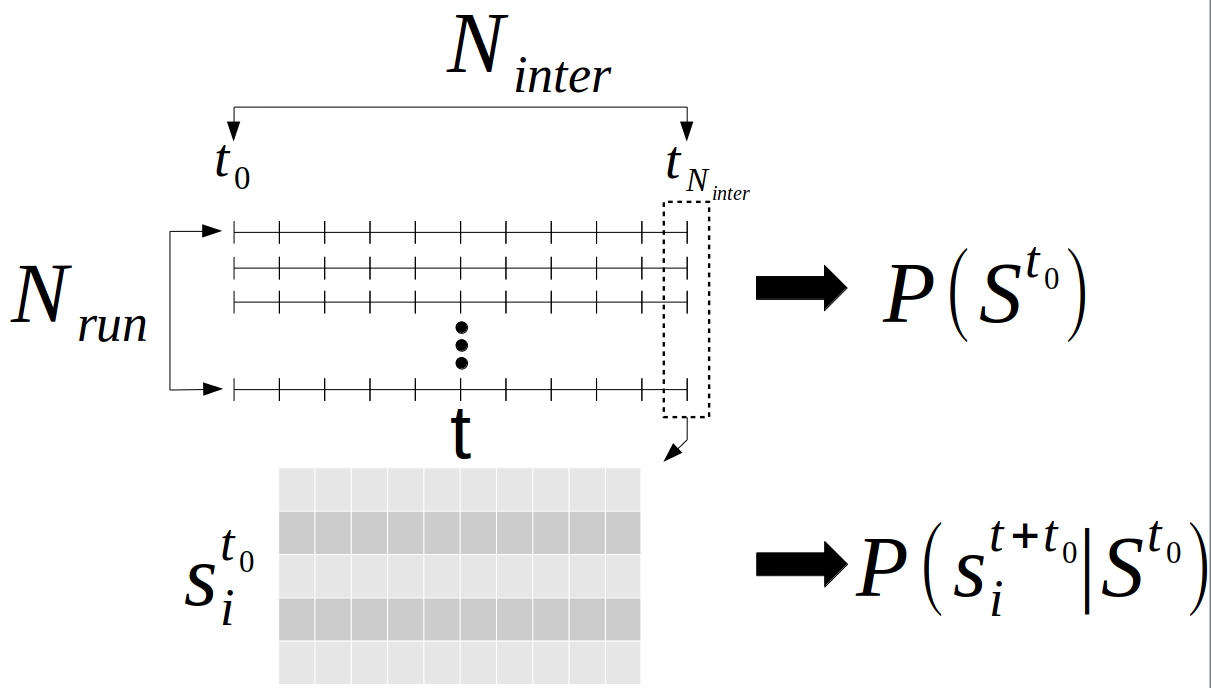
Given ergodic system S
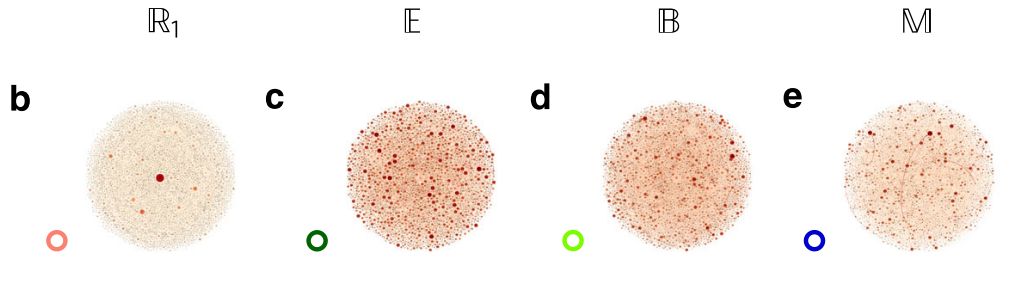
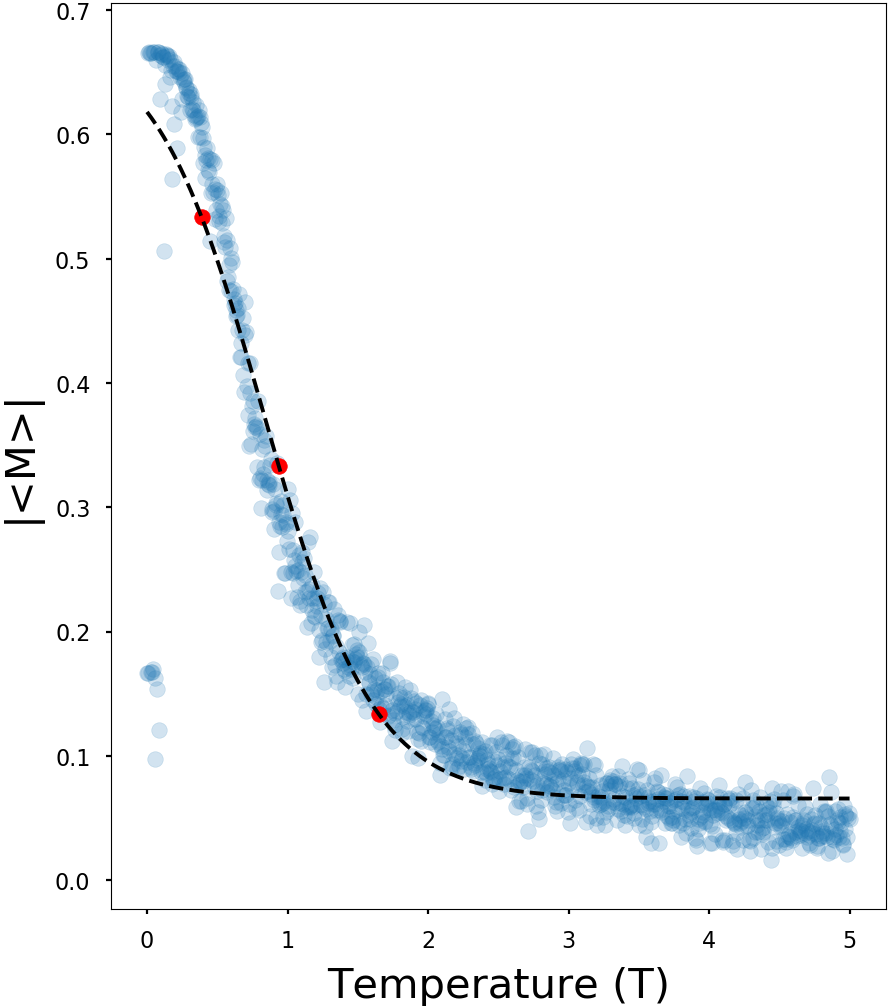
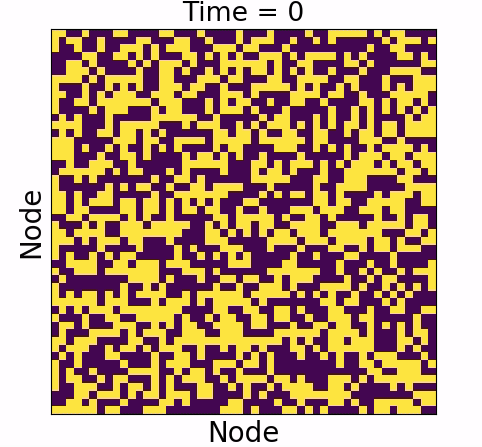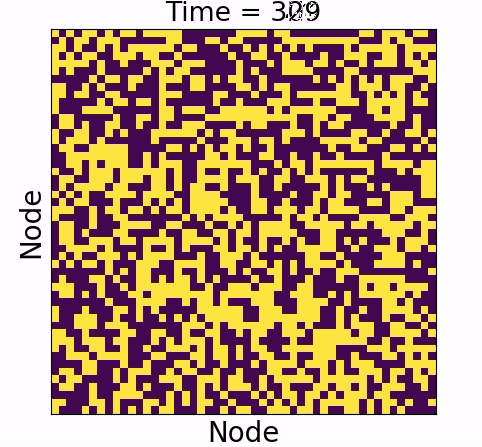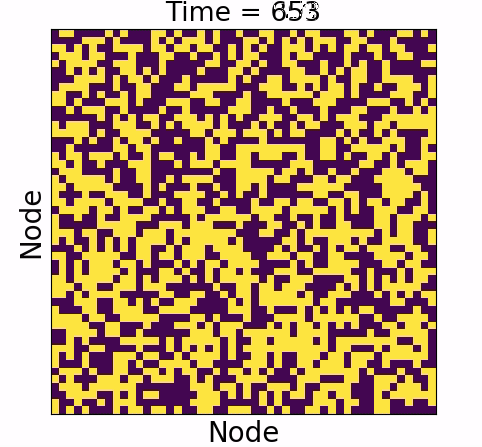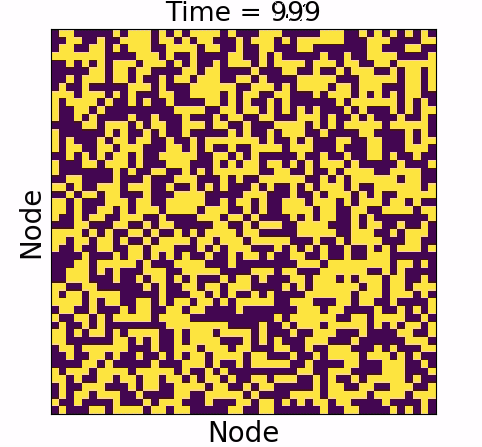
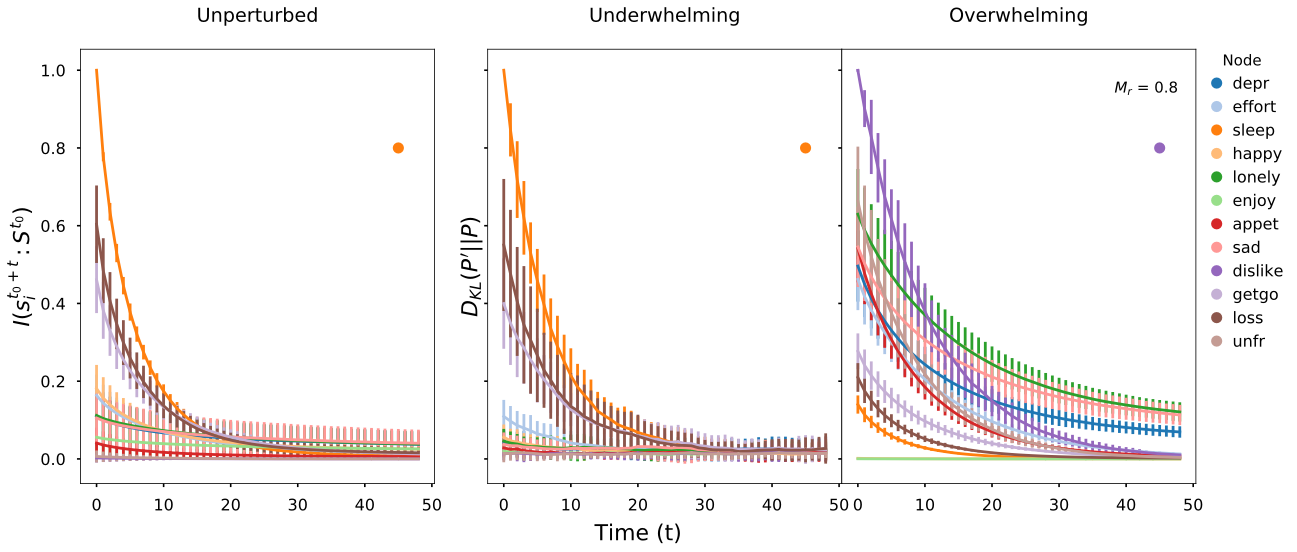
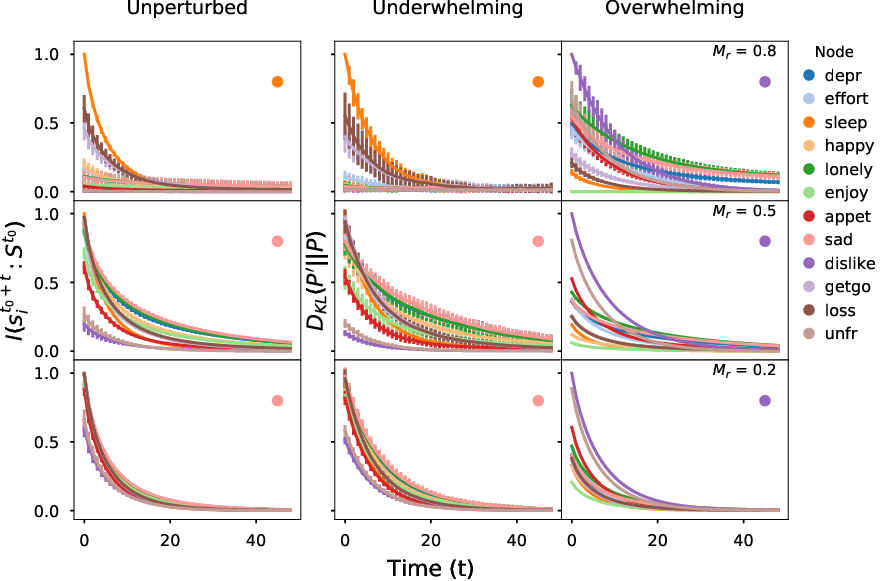
Information will always decrease as function of time
Driver-node will share the most information with the system over time
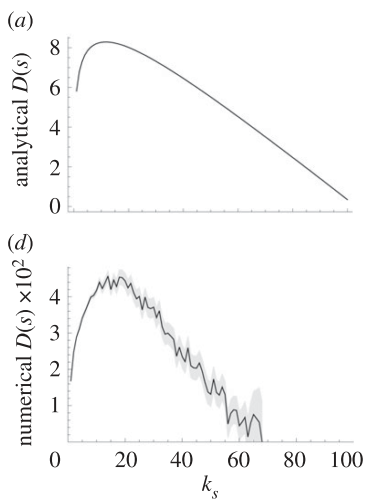
Diminishing role of hubs
Quax & Sloot (2013)
Degree
Numerical
Analytical
Answer:
Prior results:
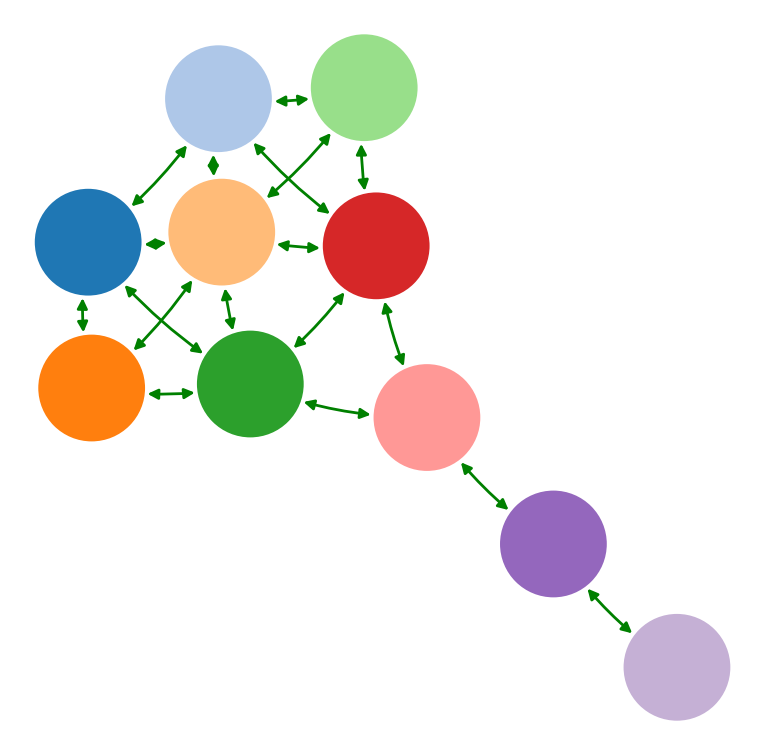
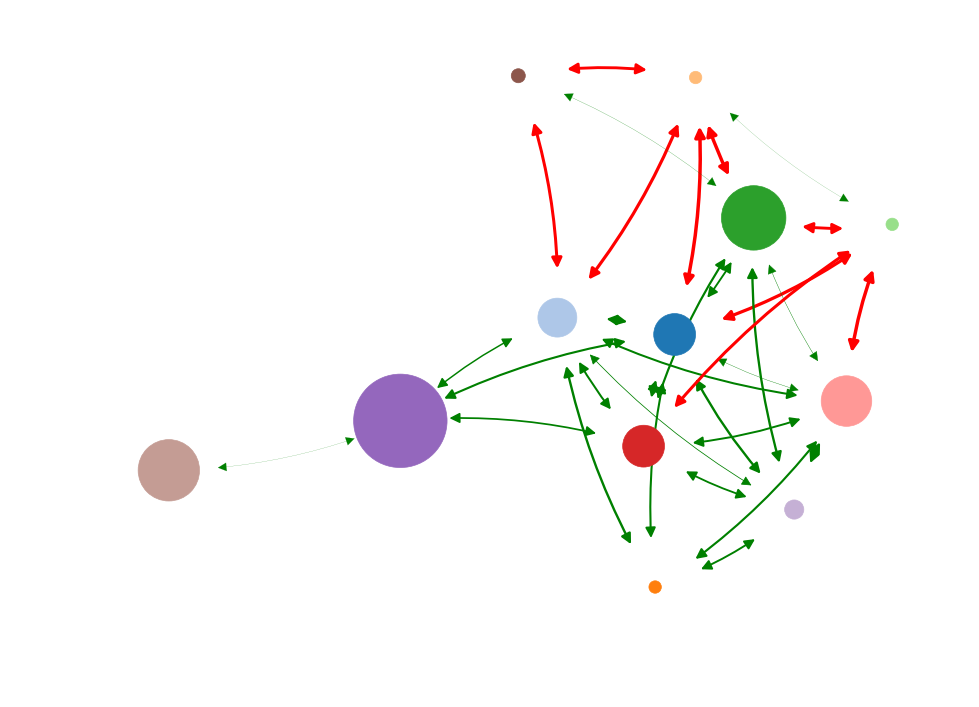
Goal: identify driver-node in real-world systems
Fried et al. (2015)
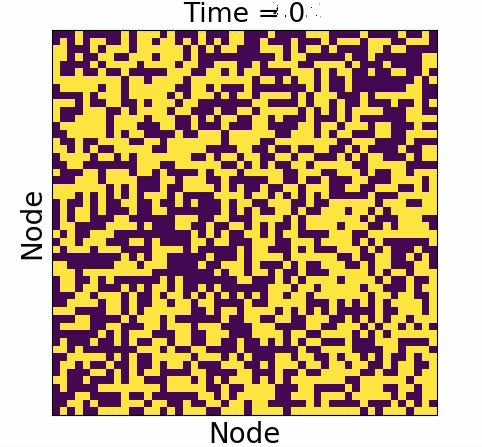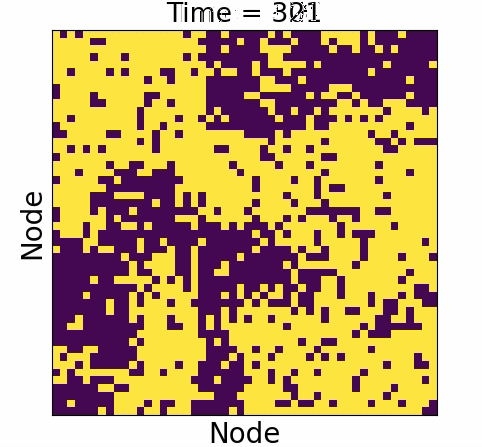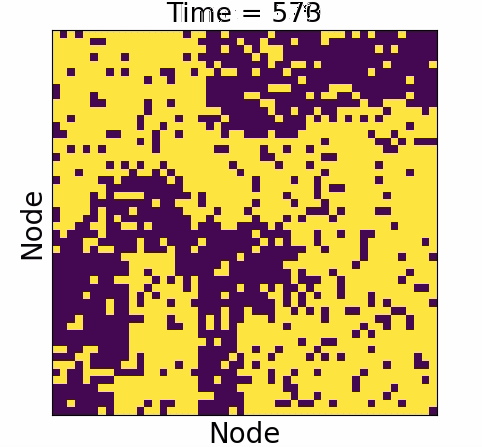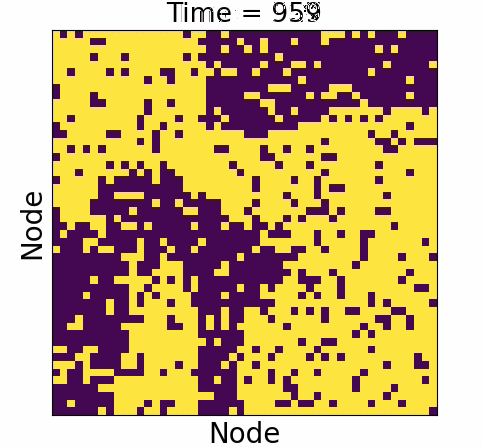
Node dynamics
Ising spin dynamics
Glauber (1963)
Used to model variety of behavior
Causal influence forms the ground truth
Advantages of KullBack-Leibler divergence:
| Name | What does it measure? |
|---|---|
| Betweenness | Shortest path |
| Degree | Local influence |
| Current flow | Least resistance |
| Eigenvector | Infinite walks |
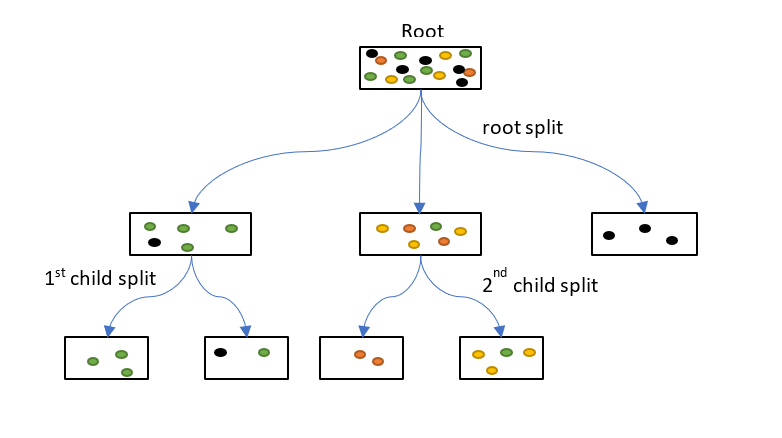
Statistical procedure
| Ind. var max(x) | Dep. var |
|---|---|
| - Degree centrality - Betweenness centrality - Current flow centrality - Eigenvector centrality - Information impact |
Causal impact - Underwhelming - Overwhelming |
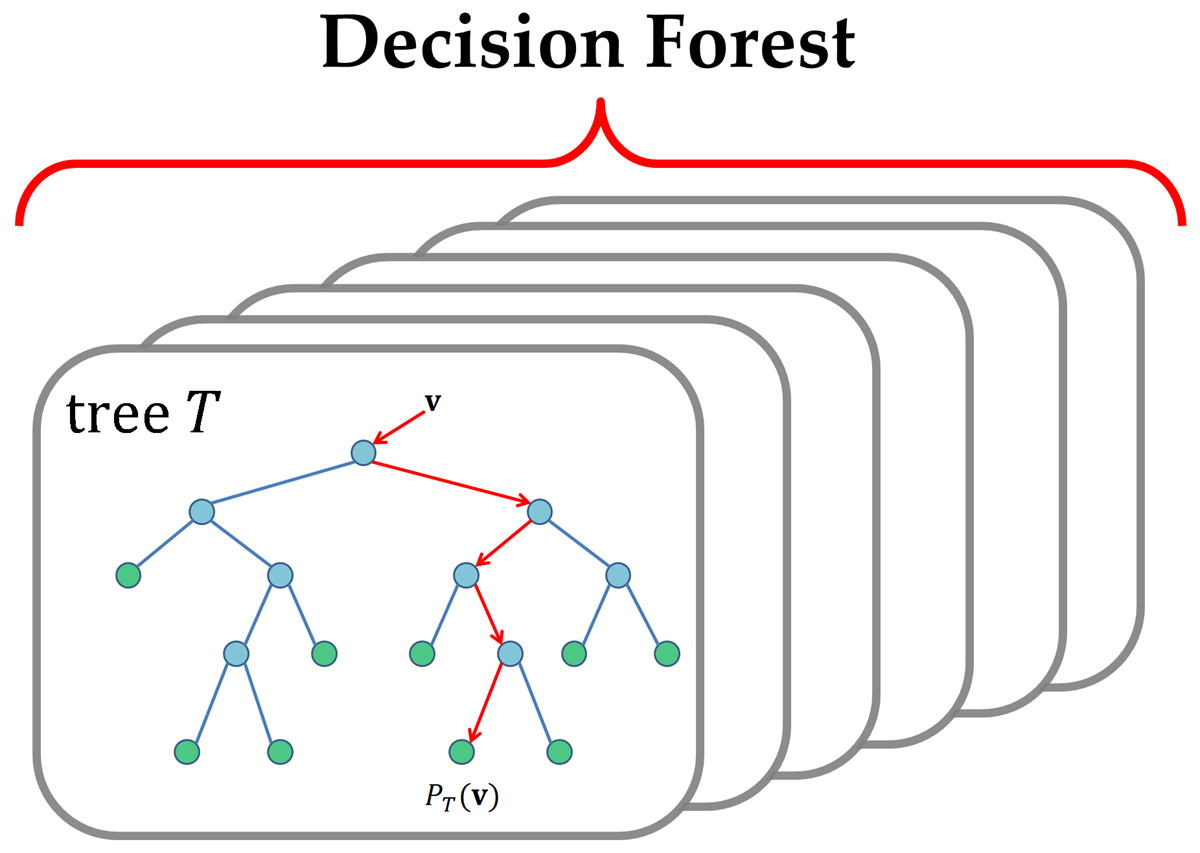
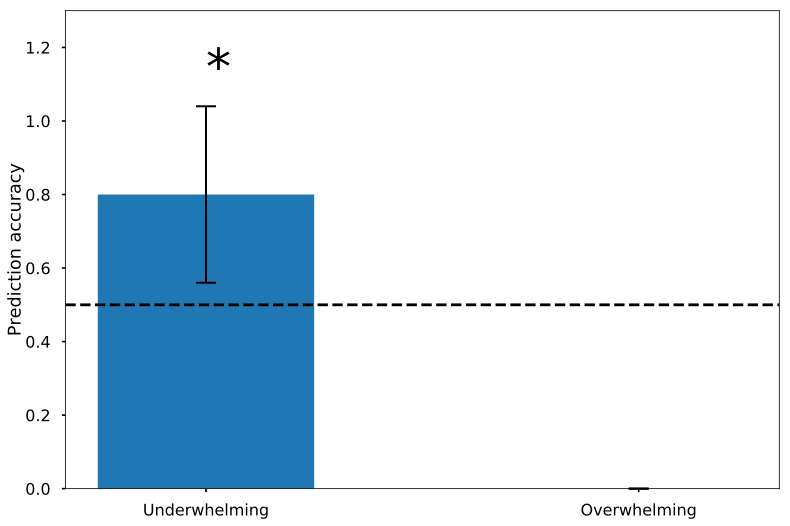
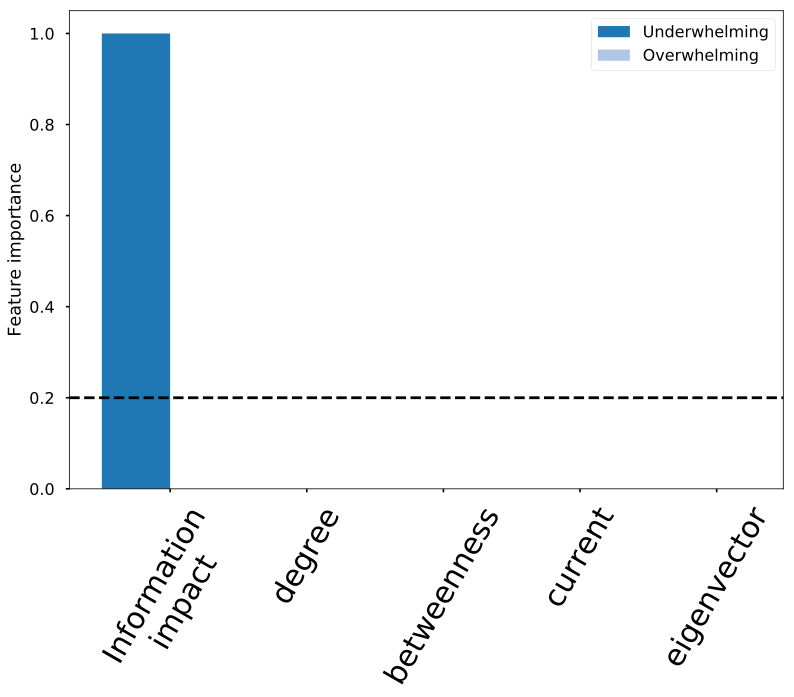
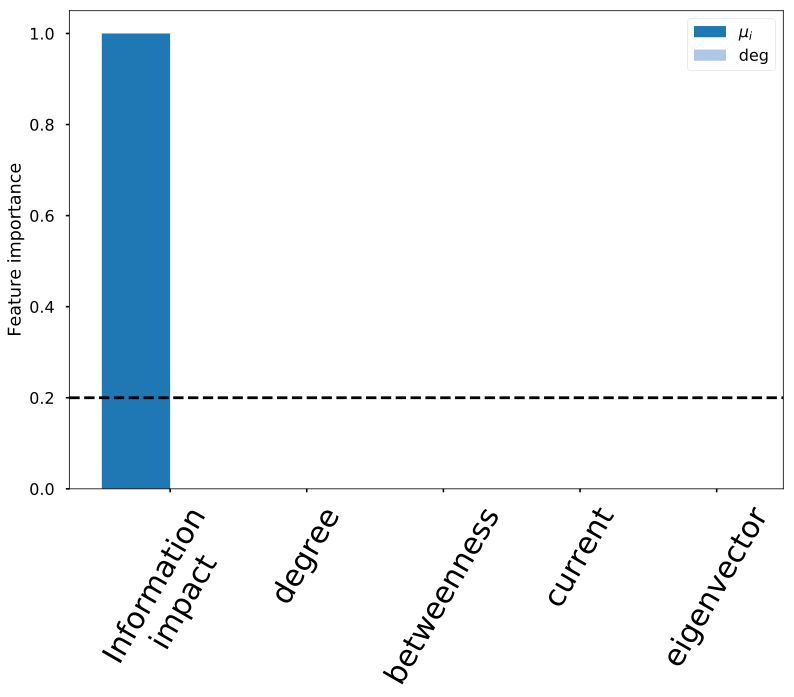
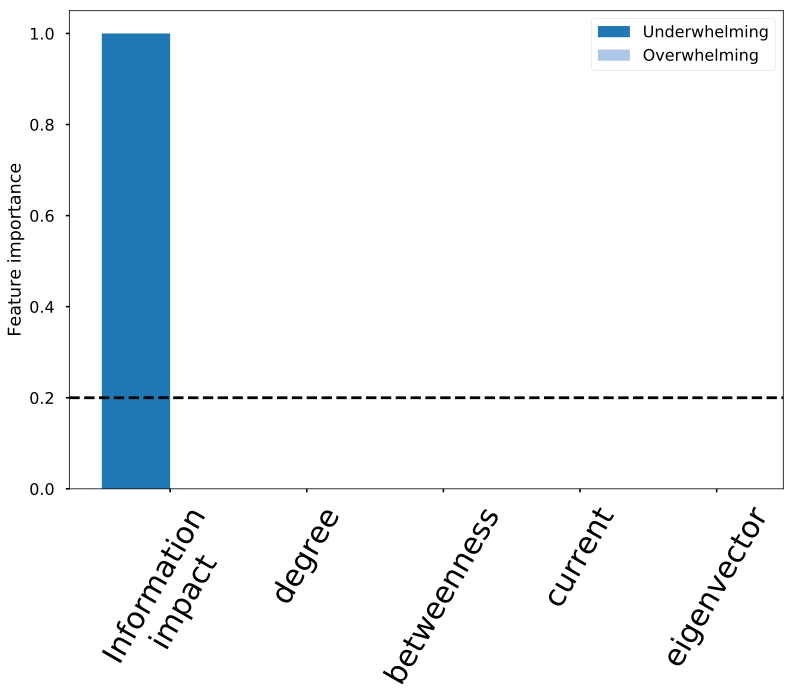
Classification with random forest:
RNF classifier with high prediction accuracy
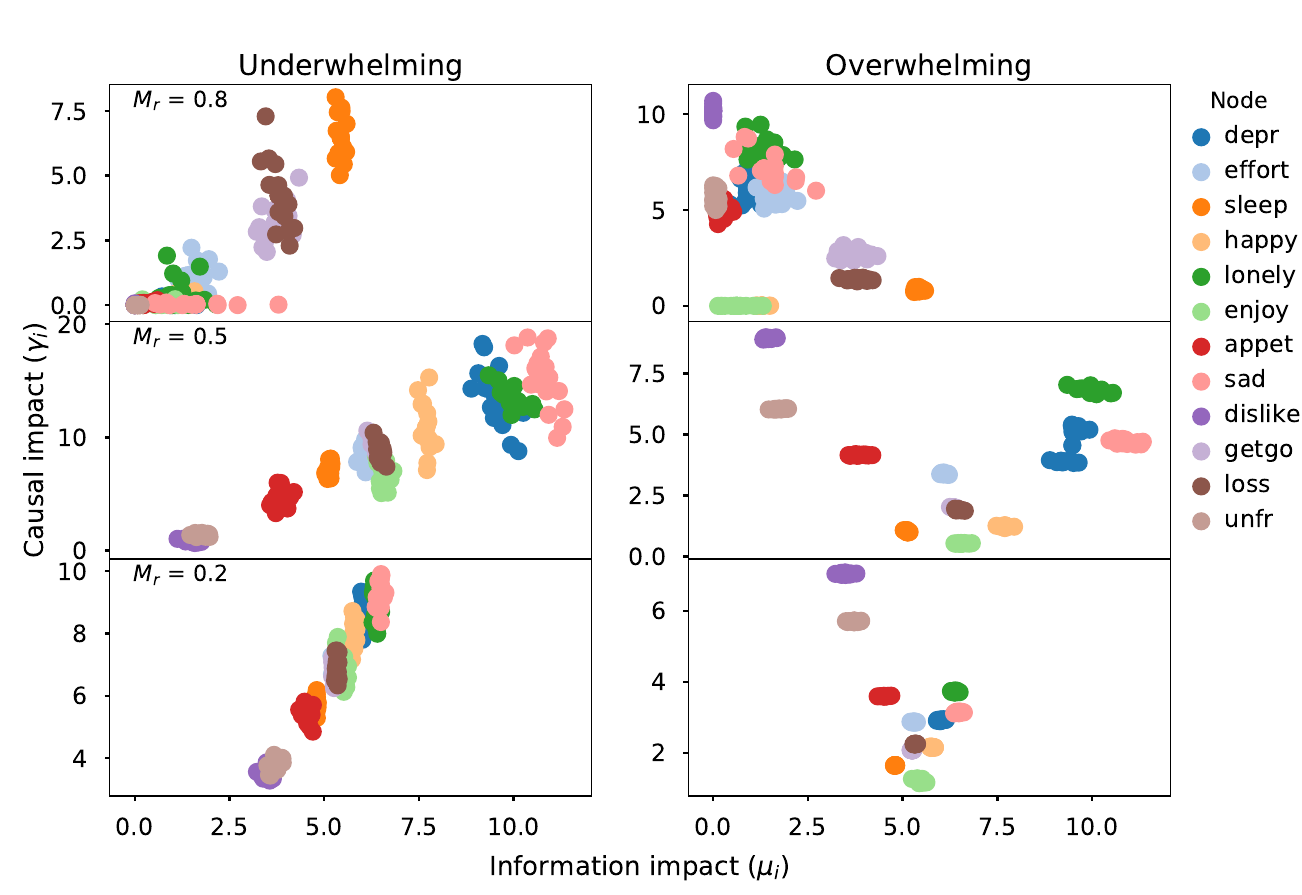
Information impact captures driver-node change
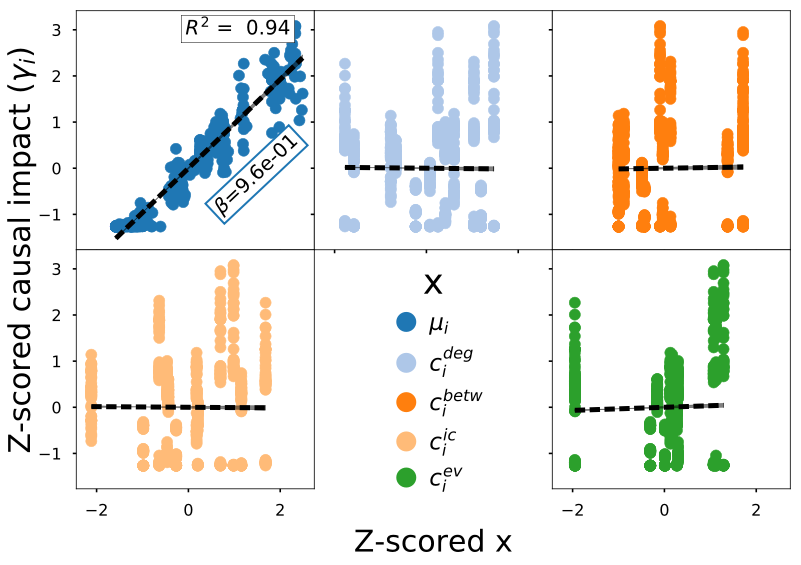
Information impact varies linearly with low causal impact
Summary
Take-home message:
Structural connectedness != dynamic importance
Future direction
Acknowledgement
Models
Information
toolbox
Plotting toolbox
IO toolbox
- Fast
- Extendable
- User-friendly
Information toolbox
Reference
Information impact
Betweenness
Degree
Current flow
Eigenvector
Low causal impact
High causal impact
Shannon (1948)
A
B
P(A)
0
1
P(B | A = a)
0
1
Entropy
Mutual information
Statistical procedure
m = amount of regressors
N = number of samples
By cvanelteren
My talk at the TU delft and IAS. Preprint can be found at https://arxiv.org/abs/1904.06654
