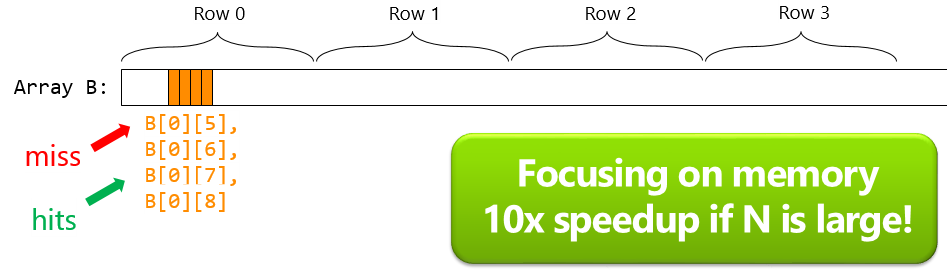
Cache friendly programming in C++
Can you make your code 10x faster?
Is this good?
int array[COLS][ROWS];
long sum = 0;
// initialize array.
for (int r=0; r<ROWS; ++r)
for (int c=0; c<COLS; ++c)
sum += array[c][r];

Much better!
int array[COLS][ROWS];
long sum = 0;
// initialize array.
for (int c=0; c<COLS; ++c)
for (int r=0; r<ROWS; ++r)
sum += array[c][r];
Same amount of instructions,
same amount of computation,
but
DIFFERENT SPEEDS!!!

You forgot about the magician inside the machine

Modern software gave you valuable abstractions, but you might have forgotten that you are talking with a machine.
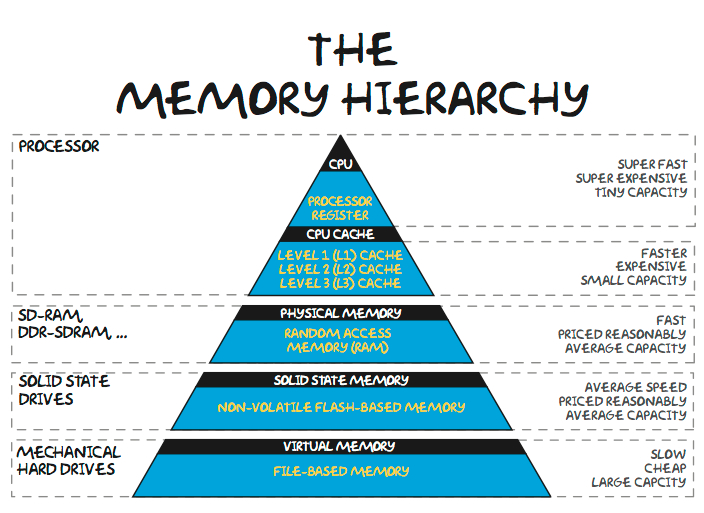
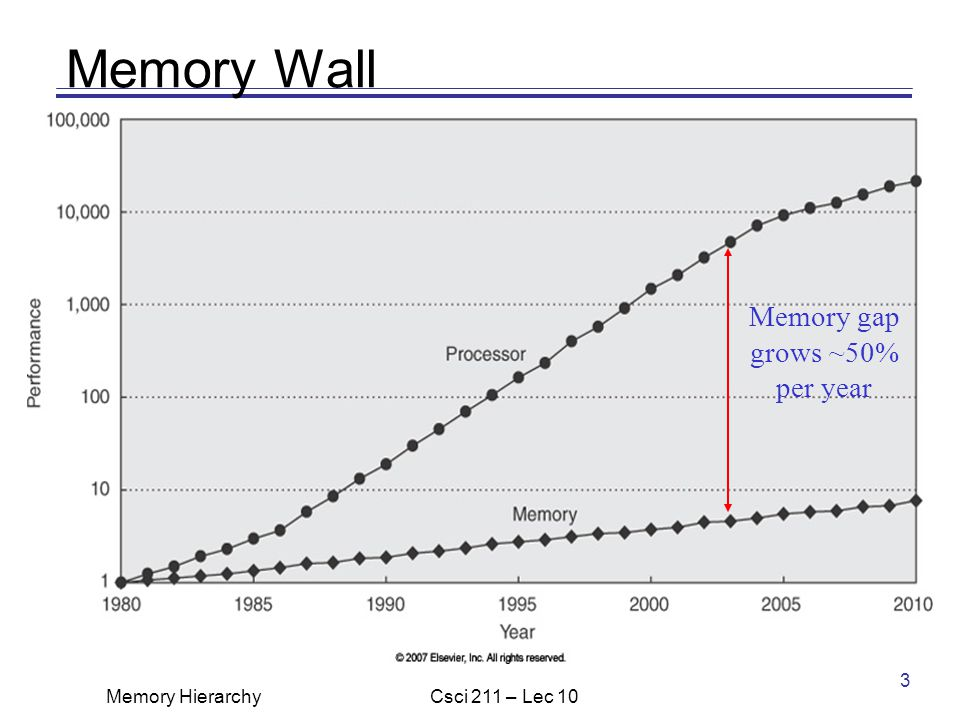
It is getting worse and worse!!
Core
L1 cache
L2 cache
L3 cache
...
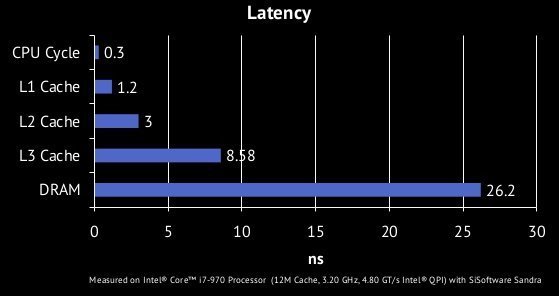
- L1 cache: 32 KB, 4 cycles
- L2 cache: 256 kB, 10 cycles
- L3 cache: 8MB, ~30 cycles
- DRAM: X GB, ~90 cycles
Core
L1 cache
L2 cache
Core
L1 cache
L2 cache
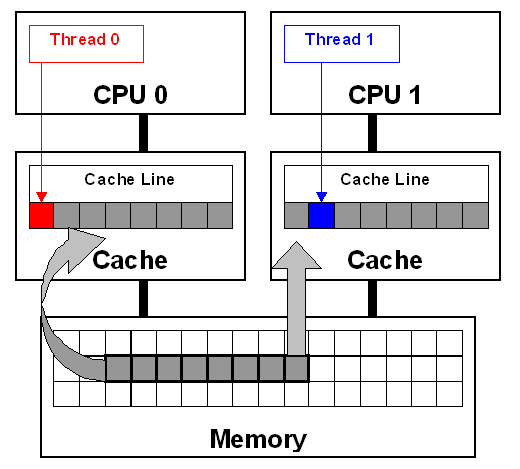
Cache is copied using contiguous segments
- Typically 64 bytes...
- The same cache line is copied on multiple CPUs.
- If any CPU modifies it, the entire line is marked "dirty".
int doWork(const vector<int>& data)
{
unsigned long sum = 0;
for (int d : data)
sum += d * d;
return (int)(sum / data.size());
}
Case A: iterate through a vector
auto data = vector<int>(SIZE);
initData( data );
doWork( data ); //benchmark this
int doWork(const vector<int*>& data)
{
unsigned long sum = 0;
for (int* d : data)
sum += (*d) * (*d);
return (int)(sum / data.size());
}
Case B: simple indirection
auto data = vector<int>(SIZE);
auto pointers = vector<int*>(data.size());
for (size_t i = 0; i < data.size(); ++i)
pointers[i] = &data[i]; // pointing to contiguous memory
}
initData( data );
doWork( pointers );int doWork(const vector<int*>& data)
{
unsigned long sum = 0;
for (int* d : data)
sum += (*d) * (*d);
return (int)(sum / data.size());
}
Case C: shuffled memory
auto pointers = vector<int*>( dataSize );
for (size_t i = 0; i < dataSize; ++i)
pointers[i] = new int; // pointing to "sparse memory"
}
initData( pointers );
doWork( pointers );
Example of antipattern
struct Object{
bool toBeUpdated;
// ...
//stuff
//....
};
std::vector< Object > objectList;
//main loop
for(int i=0; i objectList.size(); i++){
if( objectList[i].toBeUpdated )
updateObject( objectList[i] );
}Top get the value of the field "toBeUpdated", you are obliged to read a chunk of the Object
Fix
std::vector< bool > toBeUpdated;
std::vector< Object > objectList;
//main loop
for(int i=0; i objectList.size(); i++){
if( toBeUpdated[i] )
updateObject( objectList[i] );
}You don't need to read the Object from memory unless "toBeUpdated[i]" is true

OOP...
You have been fooled to think that "objects are cool".
Sometimes the truth is that they can impact your cache locality
There is more...
false sharing!
int odds = 0;
for( int i = 0; i < DIM; ++i )
for( int j = 0; j < DIM; ++j )
if( matrix[i*DIM + j] % 2 != 0 )
++odds;
Example: count odds in a matrix
void computeOdds(int *matrix_chunk, int chunk_size, int &partial_count)
{
for( int i = 0; i < chunk_size; ++i )
if( matrix_chunk[i] %2 == 0 )
partial_count++;
}
int computeOddsInParallel( int *matrix, int DIM )
{
int result[POOL_SIZE];
// Each of P parallel workers processes 1/P-th of the data
// let's suppose for the sake of simplicity that DIM is a multiple of POOL_SIZE...
int chunkSize = DIM/POOL_SIZE;
for( int p = 0; p < POOL_SIZE; ++p )
{
// push partial work inside a worker
pool.run( std::bind(computeOdds, &matrix[ p*chunkSize ], chunkSize, result[p] ));
}
// Wait for the parallel work to complete…
pool.join();
// Finally, do the sequential "reduction" step to combine the results
int odds = 0;
for( int p = 0; p < POOL_SIZE; ++p )
odds += result[p];
return odds;
}Making it parallel (some pseudo code used)
void computeOdds(int *matrix_chunk,
int chunk_size,
int &partial_count)
{
int count = 0;
for( int i = 0; i < chunk_size; ++i )
if( matrix_chunk[i] %2 == 0 )
count++;
partial_count = count;
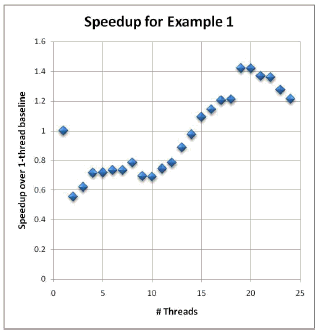
}What the f**k?
void computeOdds(int *matrix_chunk,
int chunk_size,
int &partial_count)
{
for( int i = 0; i < chunk_size; ++i )
if( matrix_chunk[i] %2 == 0 )
partial_count ++;
}
int result[POOLS_SIZE] was on a single cache line.
Unfortunately it was continuously invalidated!!!
Resources
-
http://www.drdobbs.com/parallel/eliminate-false-sharing/217500206 -
http://gameprogrammingpatterns.com/data-locality.html -
http://bitbashing.io/memory-performance.html -
https://www.youtube.com/watch?v=WDIkqP4JbkE&index=31&list=PLXIxC-YkNzOKdmwQvTJvfZa-E69AXNY70 - https://www.youtube.com/watch?v=rX0ItVEVjHc
- https://www.youtube.com/watch?v=KN8MFFvRl50
Cache friendly programming in C++
By Davide Faconti



