Need for speed
Because robots need performant software

About me (Davide Faconti)
Software domains:
- Real time control
- Low-level interfaces
- Manipulation
- Biped Locomotion
- Navigation
- Perception
- High-level planning
Robots I worked with:
- Humanoid
- Mobile robots (indoor and outdoor)
- Industrial AGV

Why speed is important
-
Throughput: can you process your sensor data in real time?
-
Latency: how long does it take to react?
-
Closed-loop control: how fast is your loop?
-
Bill of Material: how powerful does your hardware need to be?
"Can I run my algorithm on a GPU?"

CPP Optimizations Diary
- Simple and actionable rules to find bottlenecks in your code.
- Best practices to avoid "death by 1000 paper cuts".
- Practical examples from my Open Source contributions.

"That feeling when your software runs 2x faster"
Don't make assumptions, measure first.

Learn performance-related design patterns.
Don't sacrifice code quality and readability
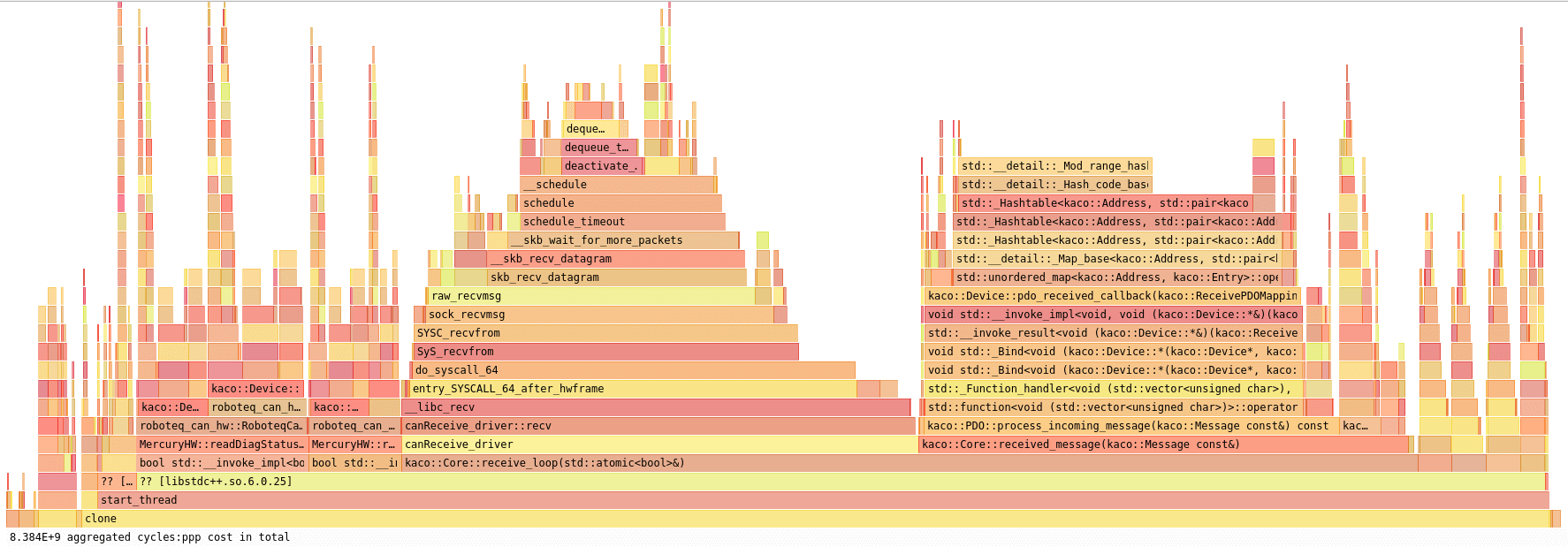
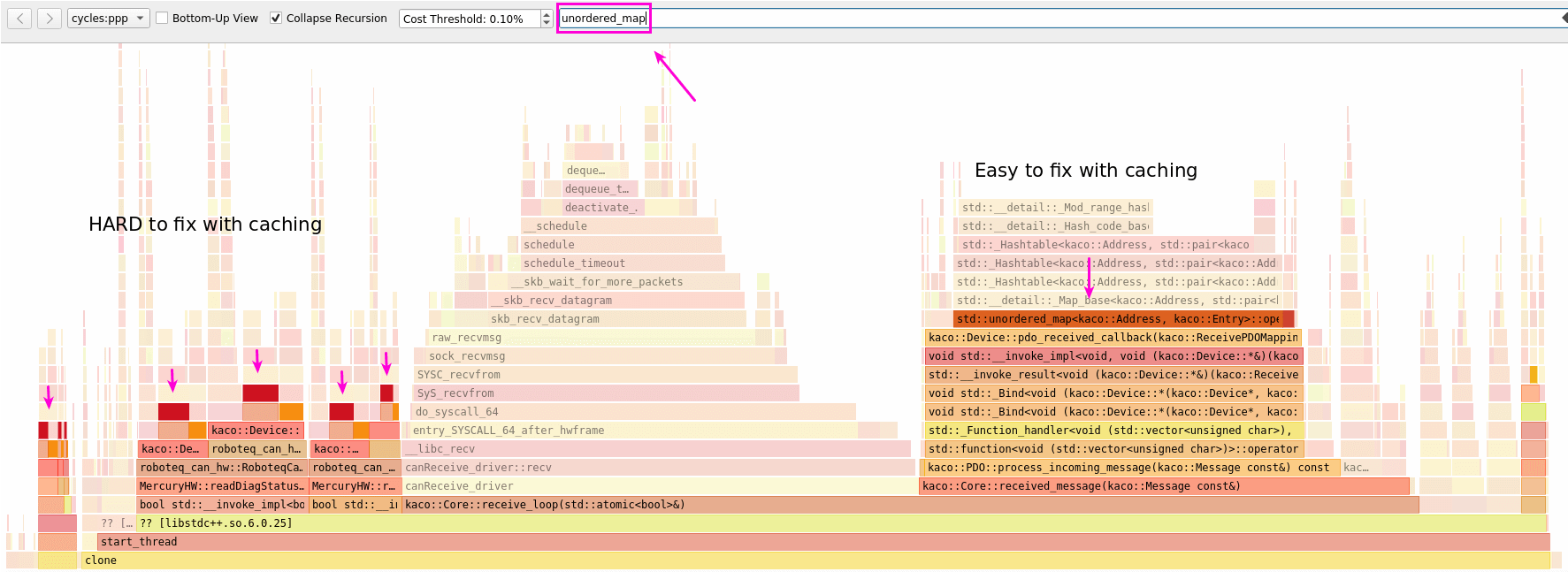
Tools: Perf and Hotspot
- Whole-application benchmarking? Hard to find the "smoking gun".
- Intrusive profiling like easy_profiler? So 2000s !
- Embrace Linux Perf and Hotspot !
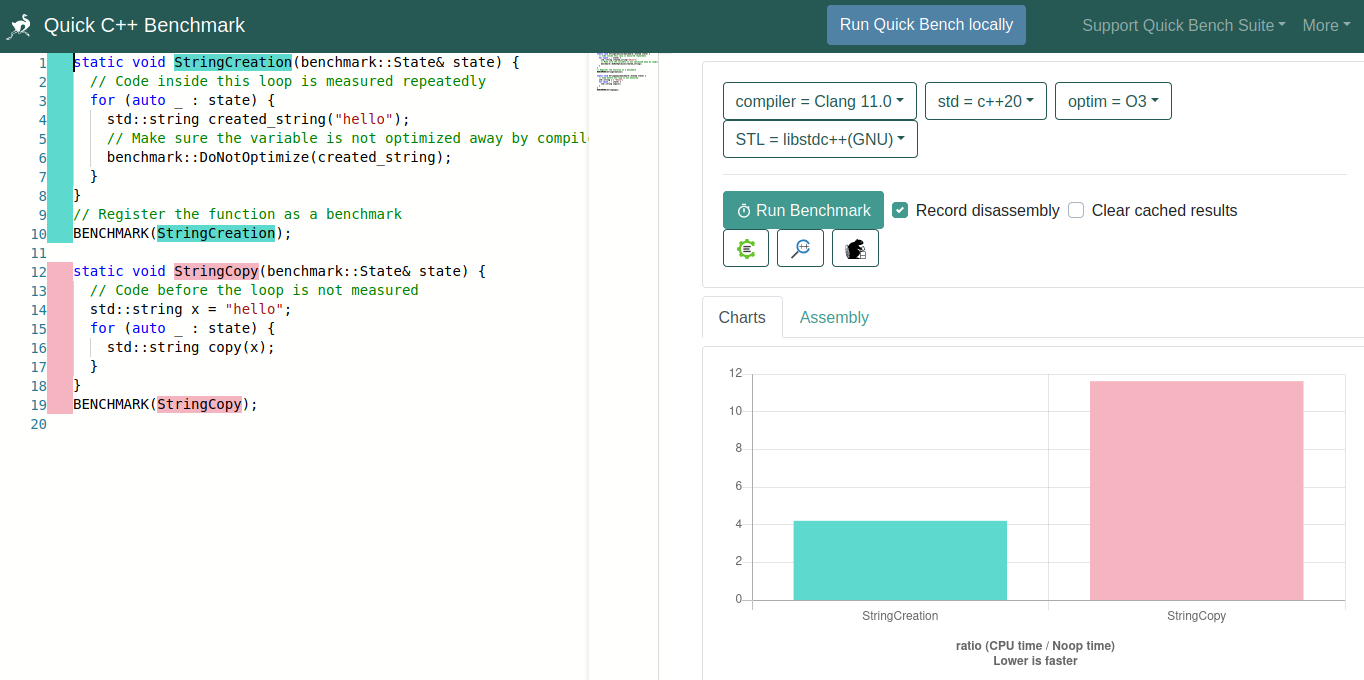
Tools: Google Benchmark
- Library can be found here: https://github.com/google/benchmark
- Ideal for micro-benchmarking of specific functions / algorithms.
- You can run it online: https://quick-bench.com
Tools: Heaptrack
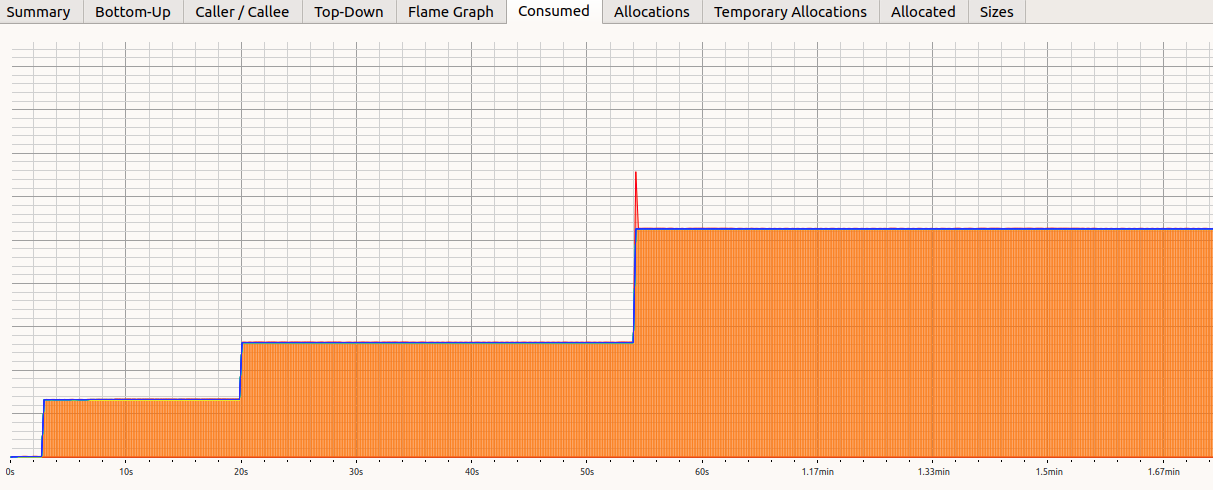
Tip #1: avoid memory allocations
- Memory allocation can be expensive.
- Perf can tell you how much CPU is wasted doing new and delete
- Beware data structure that will create objects in the heap (std::list and std::map, during insertion).
- Allocating "big" objects might be slow (PointClouds, Images, etc.). Consider "recycling" objects or use a memory pool.
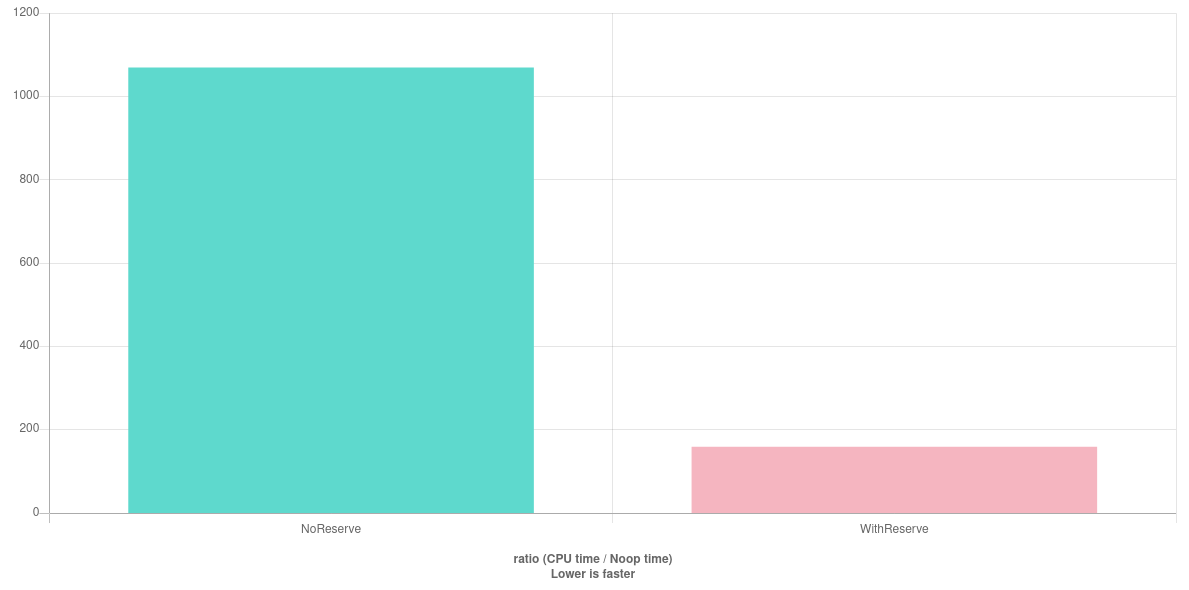
Tip #2: use std::vector and SmallVector
Use std::vector<>::reserve()
std::vector<size_t> v;
v.reserve(100);
for(size_t i=0; i<100; i++)
{
v.push_back(i);
}
Tip #2: use std::vector and SmallVector
Example: improving The RealSense ROS driver
// BEFORE: this list was created and populated at each frame
std::list<unsigned> valid_indices;
// AFTER: create this vector only once and re-use it (after clean)
// The memory is allocate only once and iteration is faster
std::vector<unsigned> valid_indices;
Tip #2: use std::vector and SmallVector
SmallVector: a data structure that pre-allocates a certain number of elements in the stack (not the heap).
Implementations:
Avoid std::list, prefer std::deque or boost::circular_buffer
Tip #3: test multiple associative containers
- std::map is usually bad
- std::unordered_map is a good default.
- Sometimes, an ordered std::vector<std::pair<Key,Value>> is an option.
- Consider boost::container_flat_map.
- There are many alternatives to unordered_map which claim to be faster.
Tip #3: test multiple associative containers


Change: remove std::map and use std::vector instead
Tip #4: don't compute twice
std::vector<double> LUT_cos;
std::vector<double> LUT_sin;
double angle = angle_minimum;
for(int i=0; i<scan_distance.size(); i++)
{
LUT_cos.push_back( cos(angle) );
LUT_sin.push_back( sin(angle) );
angle += angle_increment;
}
// ----- The efficient scan conversion ------
std::vector<double> scan_distance;
std::vector<Pos2D> cartesian_points;
cartesian_points.reserve( scan_distance.size() );
for(int i=0; i<scan_distance.size(); i++)
{
const double dist = scan_distance[i];
double x = dist*LUT_cos[i];
double y = dist*LUT_sin[i];
cartesian_points.push_back( Pos2D(x,y) );
}
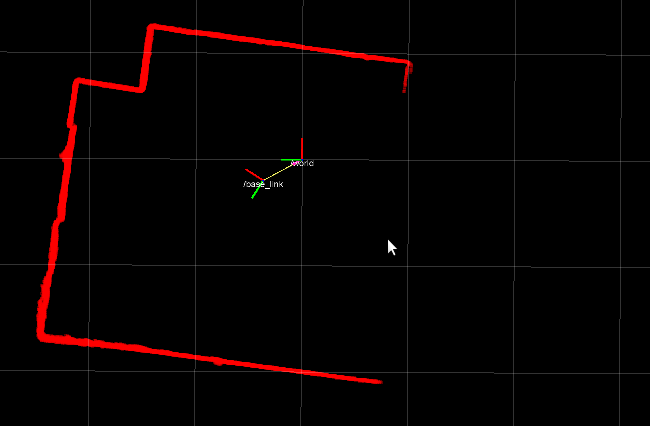
Example: polar to cartesian transform in LaserScan
Tip #4: don't compute twice
Tip #4: don't compute twice
// index in a matrix is usally calculated as:
index = column * num_rows + row;
// Nice and readable...
for( size_t y = y_min; y < y_max; y++ )
{
for( size_t x = x_min; x < x_max; x++ )
{
matrix_out( x,y ) = std::max( mat_a( x,y ), mat_b( x,y ) );
}
}
// ...But considerably faster
for(size_t y = y_min; y < y_max; y++)
{
size_t offset_out = y * matrix_out.rows();
size_t offset_a = y * mat_a.rows();
size_t offset_b = y * mat_b.rows();
for(size_t x = x_min; x < x_max; x++)
{
size_t index_out = offset_out + x;
size_t index_a = offset_a + x;
size_t index_b = offset_b + x;
matrix_out( index_out ) = std::max( mat_a( index_a ), mat_b( index_b ) );
}
}Optimization opportunity iterating over a large 2D matrix.
Tip #5: try changing algorithm
- Big O() complexity is still the most important factor
- Explore alternative implementations of the same algorithm
Simply used
boost::sort::spreadsort::integer_sort
instead of
std::sort
Summary
- No rocket science. Optimizations opportunities are banally simple sometimes.
- It is all using good tools agressively.
Advanced topics for curious minds
- Cache friendly and data-driven development
- SIMD operations
- And of course... GPU!
Need for speed
By Davide Faconti




