


Davide Murari
A PhD student in numerical analysis at the Norwegian University of Science and Technology.
Learning Hamiltonians of constrained mechanical systems
Davide Murari
Machine Learning and Dynamical Systems
Alan Turing Institute - 05/05/2022
\(\texttt{davide.murari@ntnu.no}\)
Joint work with Elena Celledoni, Andrea Leone and Brynjulf Owren
Definition of the problem
GOAL : approximate the unknown \(f\) on \(\Omega\)
DATA:
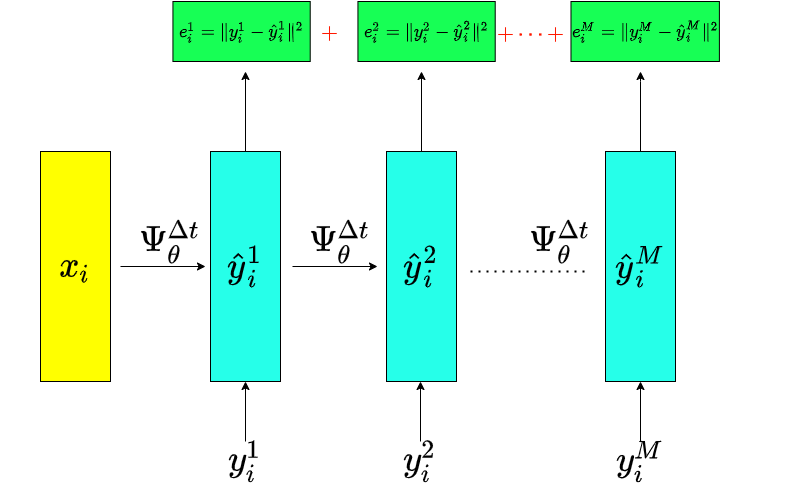
Approximation of a dynamical system
Introduce a parametric model
1️⃣
3️⃣
Choose any numerical integrator applied to \(\hat{f}_{\theta}\)
2️⃣
Unconstrained Hamiltonian systems
Choice of the model:
Measuring the approximation quality
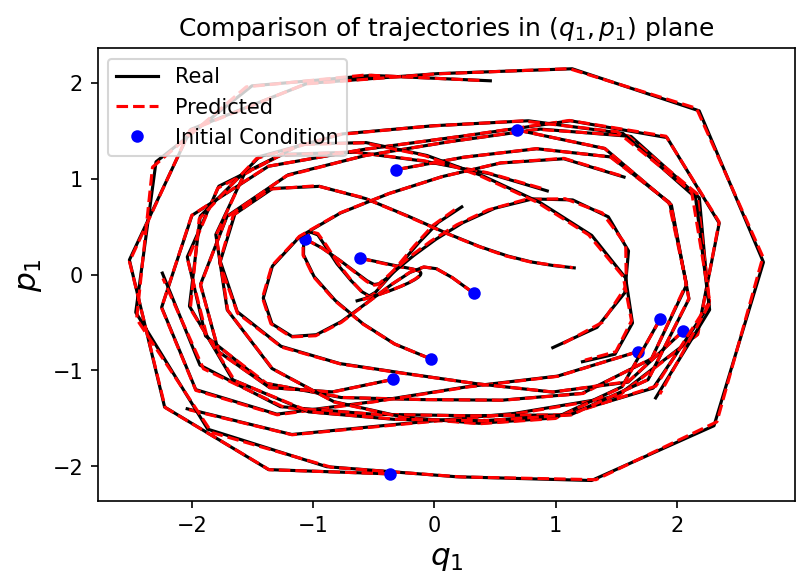
Test initial conditions
Numerical experiment
⚠️ The integrator used in the test, can be different from the training one.
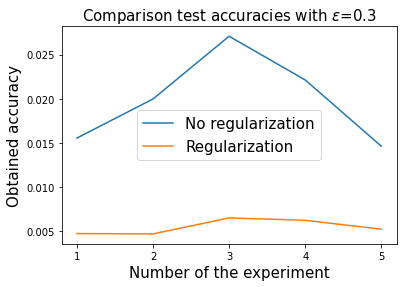
Physics informed regularization
If there is a known conserved quantity \(I(x(t))=I(x(0))\) we can add it to the loss, to get a physics informed regularization:
On clean trajectories
Constrained Hamiltonian systems
This implies that the dynamics can be defined as a vector field on
Modelling the vector field on \(\mathcal{M}\)
On \(\mathcal{M}\) the dynamics can be written as
Example with \(\mathcal{Q}=S^2\)
On \(\mathcal{M}\) the dynamics can be written as
Learning constrained Hamiltonian systems
Proceed as in the general case, but the vector field \(\tilde{f}_{\theta}\) has a particular structure, as for the unconstrained case.
⚠️ \(\hat{f}_{\theta}\) makes sense also for \((q,p)\in\mathbb{R}^{2n}\setminus \mathcal{M}\), even if no more as a vector field on \(\mathcal{M}\)
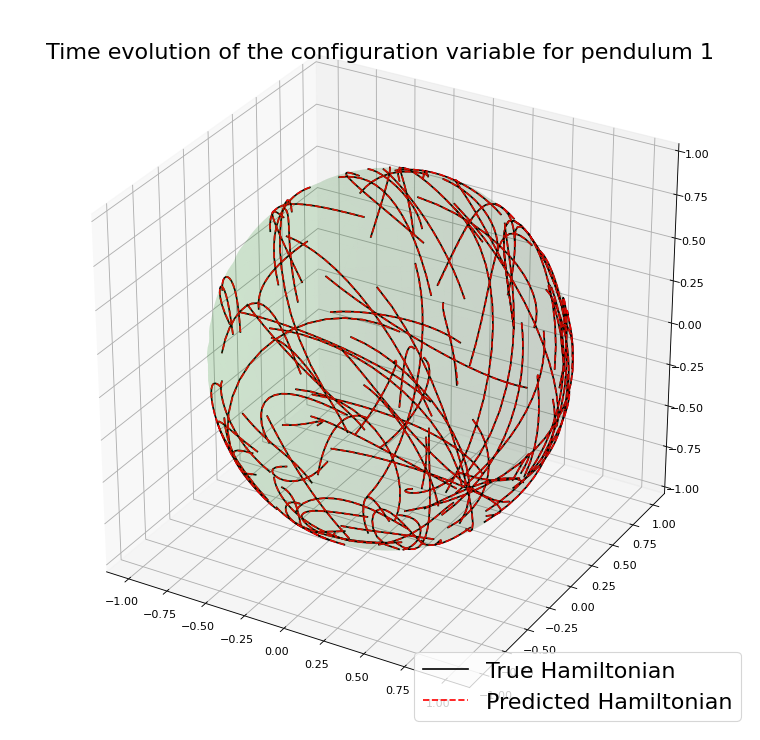
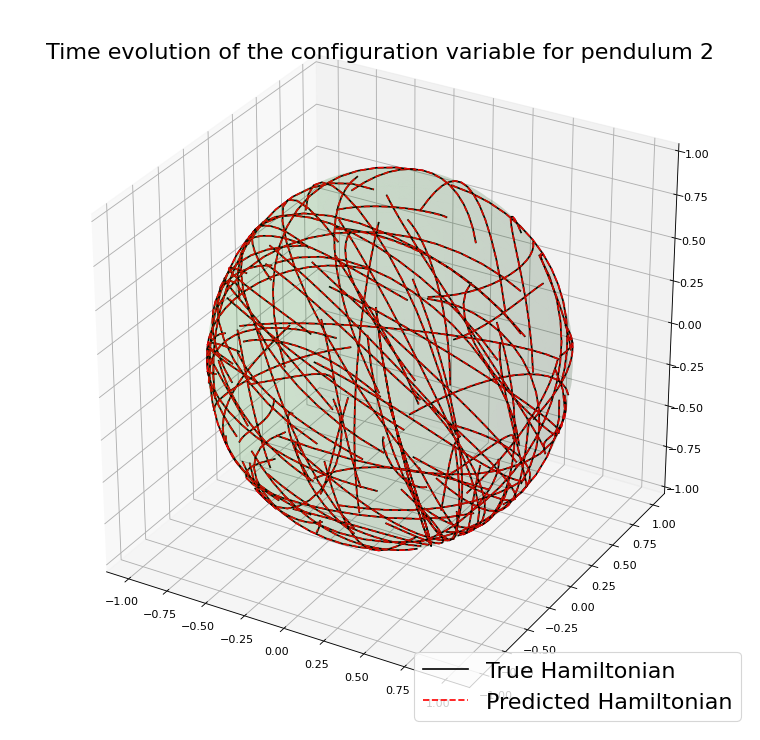
Example with the double spherical pendulum
Using an integrator \(\Psi^{\Delta t}_{\theta}\) that preserves \(\mathcal{M}\)
PROS
CONS
On \(\mathcal{M}\) the function \(H_{\theta}\) is unique
The approximation error is not influenced by the drift from the manifold.
These methods are more involved, and often implicit.
The loss function can become harder to be optimized.
The simulated trajectories in the training are physically meaningful.
Not in general clear the impact this has on the final result.
Case with \(\mathcal{M}\) homogeneous
A manifold \(\mathcal{M}\) is homogeneous if there is a Lie group \(\mathcal{G}\) that defines a transitive group action \(\varphi:\mathcal{G}\times\mathcal{M}\rightarrow\mathcal{M}\).
Case with \(\mathcal{M}\) homogeneous
A manifold \(\mathcal{M}\) is homogeneous if there is a Lie group \(\mathcal{G}\) that defines a transitive group action \(\varphi:\mathcal{G}\times\mathcal{M}\rightarrow\mathcal{M}\).
A vector field \(f\) on \(\mathcal{M}\) can be represented as \(f(x) = \varphi_*(\xi(x))(x)\), for a function
\(\xi:\mathcal{M}\rightarrow\mathfrak{g}\simeq T_e\mathcal{G}\).
Lie Group Methods are a class of methods exploiting this structure and preserving \(\mathcal{M}\). The simplest is Lie Euler:
\(y_i^{j+1} = \varphi(\exp(\Delta t \,\xi(y_i^j)),y_i^j)\)
Basic idea of a class of Lie group methods
\(\mathcal{M}\)
\(y_i^j\)
\(y_i^{j+1}=\varphi_g(y_i^j)\)
\(\mathfrak{g}\)
\(\xi\)
\(\exp\)
\(\mathcal{G}\)
\(\varphi_g\)
\(\Psi^{\Delta t}\)
\(0\)
\(\Delta t \xi(y_i^j)\)
\(g=\exp(\Delta t\,\xi(y_i^j))\)
\(f\in\mathfrak{X}(M)\)
\(f^L\in\mathfrak{X}(\mathfrak{g})\)
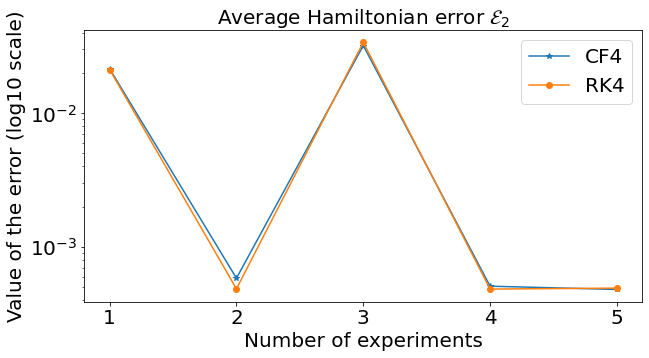
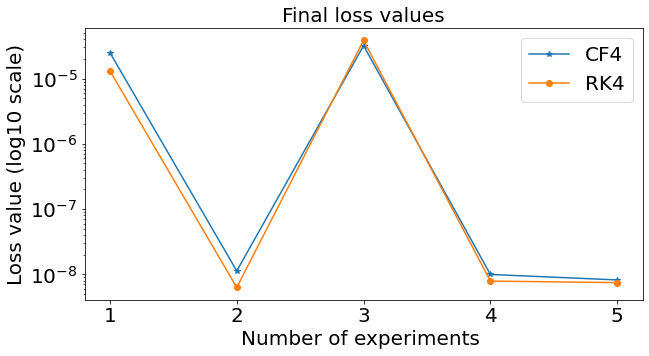
A case where preserving \(\mathcal{M}\) helps
Suppose to have just few unknown elements in the expression of the Hamiltonian
As a consequence, one expects a very accurate approximation.
Example with the spherical pendulum:
Similar results preserving \(\mathcal{M}\)
System studied: Spherical pendulum
Thank you for the attention
Slides available at
https://slides.com/davidemurari/constrained-hamiltonian
By Davide Murari
Slides talk Machine Learning and Dynamical Systems, Alan Turing Institute, 05/05/2022




