




Davide Murari
A PhD student in numerical analysis at the Norwegian University of Science and Technology.
Davide Murari
ICIAM - 22/08/2023
\(\texttt{davide.murari@ntnu.no}\)
In collaboration with : Elena Celledoni, Brynjulf Owren, Carola-Bibiane Schönlieb and Ferdia Sherry
Structured neural networks and some applications
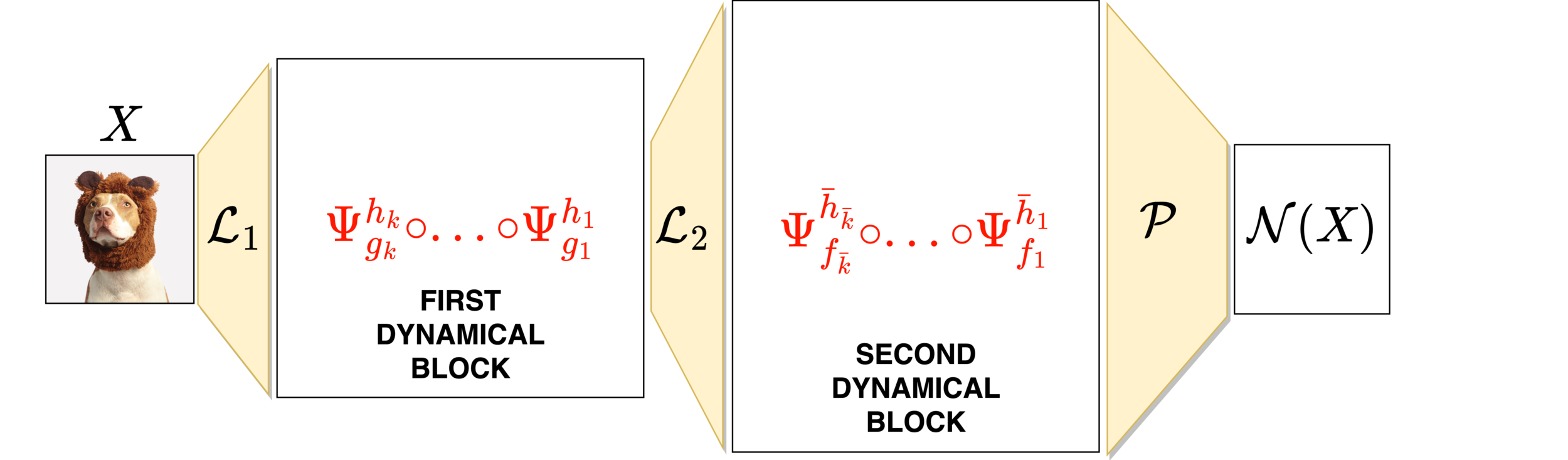
Neural networks motivated by dynamical systems
\( \mathcal{N}(x) = f_{\theta_L}\circ ... \circ f_{\theta_1}(x)\)
Neural networks motivated by dynamical systems
\( \mathcal{N}(x) = f_{\theta_L}\circ ... \circ f_{\theta_1}(x)\)
\( \dot{x}(t) = F(x(t),\theta(t))=:F_{s(t)}(x(t)) \)
Where \(F_i(x) = F(x,\theta_i)\)
\( \theta(t)\equiv \theta_i,\,\,t\in [t_i,t_{i+1}),\,\, h_i = t_{i}-t_{i-1}\)
Neural networks motivated by dynamical systems
Neural networks motivated by dynamical systems
Accuracy is not all you need
\(X\) , Label : Plane
\(X+\delta\), \(\|\delta\|_2=0.3\) , Label : Cat
GENERAL IDEA
EXAMPLE
Property \(\mathcal{P}\)
\(\mathcal{P}=\) Volume preservation
Imposing some structure
GENERAL IDEA
EXAMPLE
Property \(\mathcal{P}\)
\(\mathcal{P}=\) Volume preservation
Family \(\mathcal{F}\) of vector fields that satisfy \(\mathcal{P}\)
\(F_{\theta}(x,v) = \begin{bmatrix} \Sigma(Av+a) \\ \Sigma(Bx+b) \end{bmatrix} \)
\(\mathcal{F}=\{F_{\theta}:\,\,\theta\in\mathcal{P}\}\)
Imposing some structure
GENERAL IDEA
EXAMPLE
Property \(\mathcal{P}\)
\(\mathcal{P}=\) Volume preservation
Family \(\mathcal{F}\) of vector fields that satisfy \(\mathcal{P}\)
\(F_{\theta}(x,v) = \begin{bmatrix} \Sigma(Av+a) \\ \Sigma(Bx+b) \end{bmatrix} \)
\(\mathcal{F}=\{F_{\theta}:\,\,\theta\in\mathcal{P}\}\)
Integrator \(\Psi^h\) that preserves \(\mathcal{P}\)
Imposing some structure
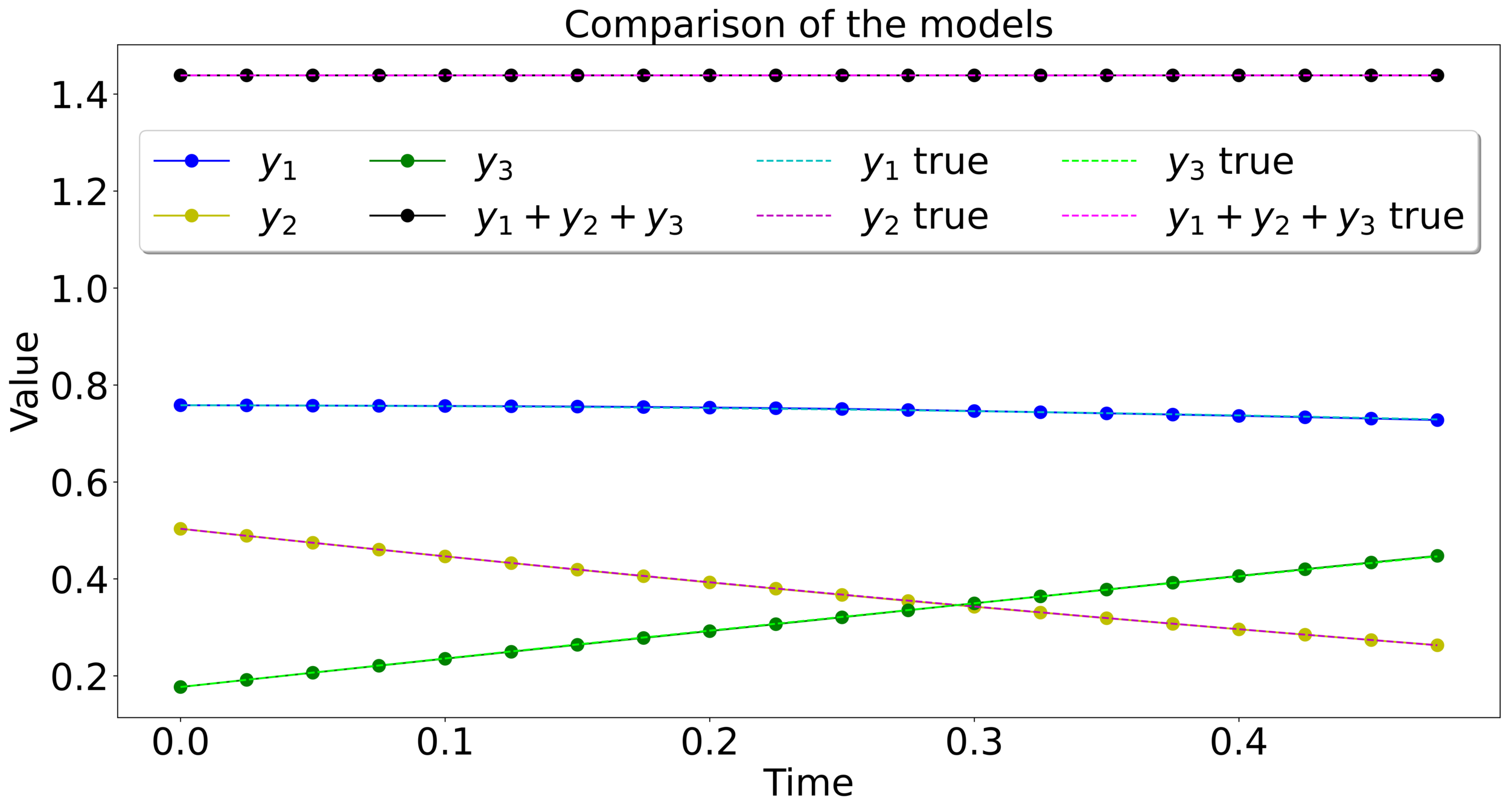
Mass-preserving networks
Lipschitz-constrained networks
\(m=1\)
\(m=\frac{1}{2}\)
\(\Sigma(x) = \max\left\{x,\frac{x}{2}\right\}\)
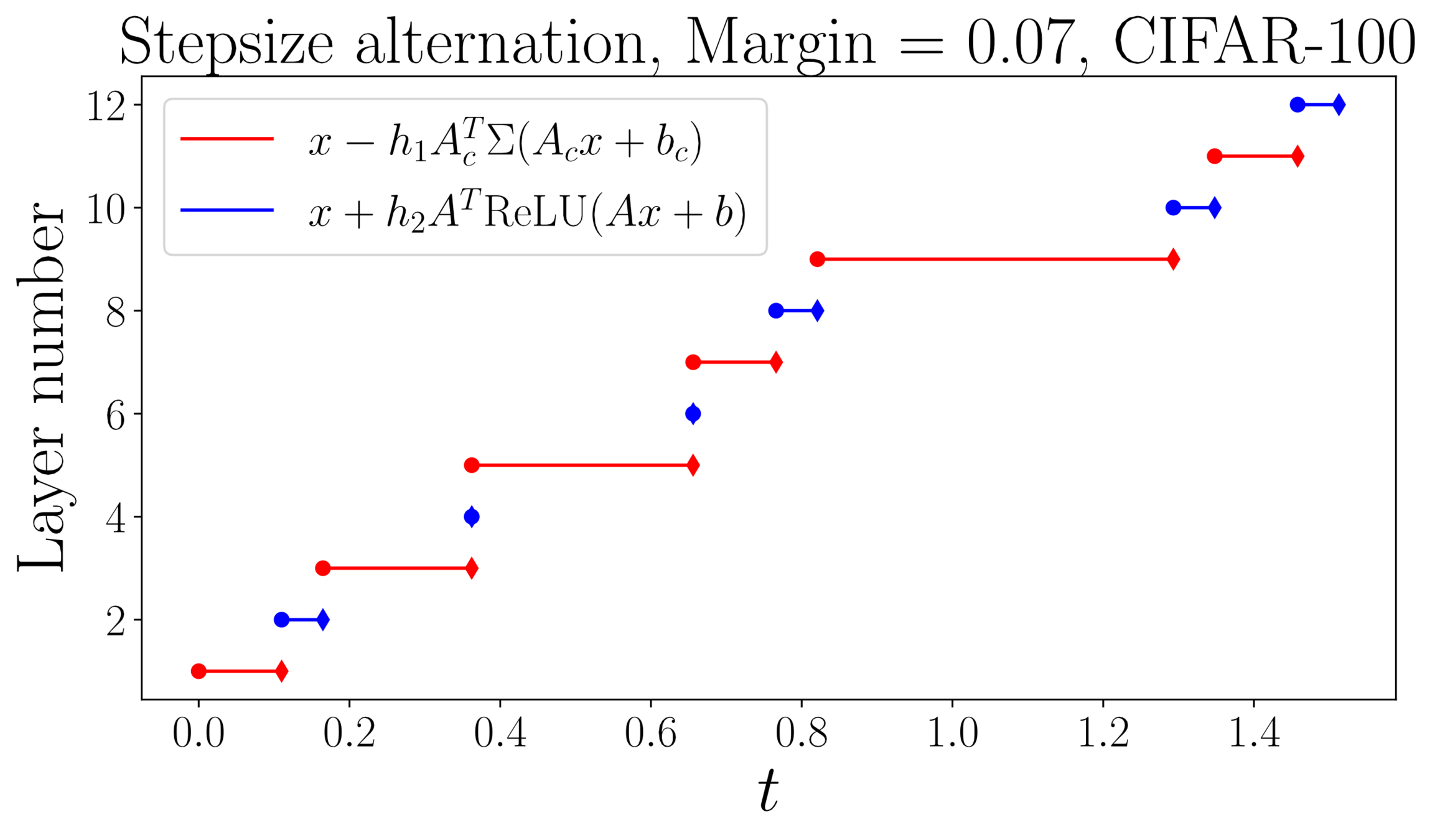
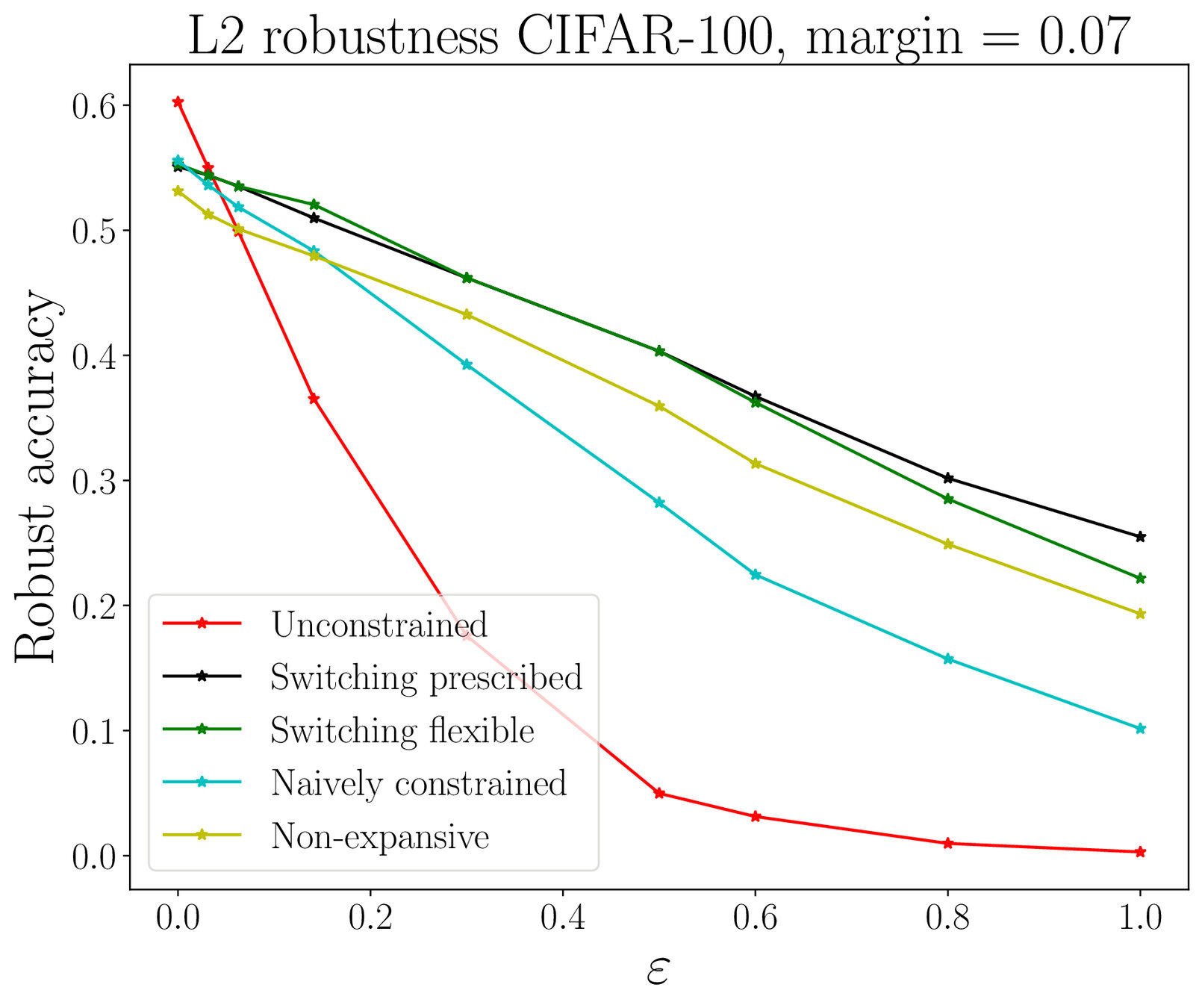
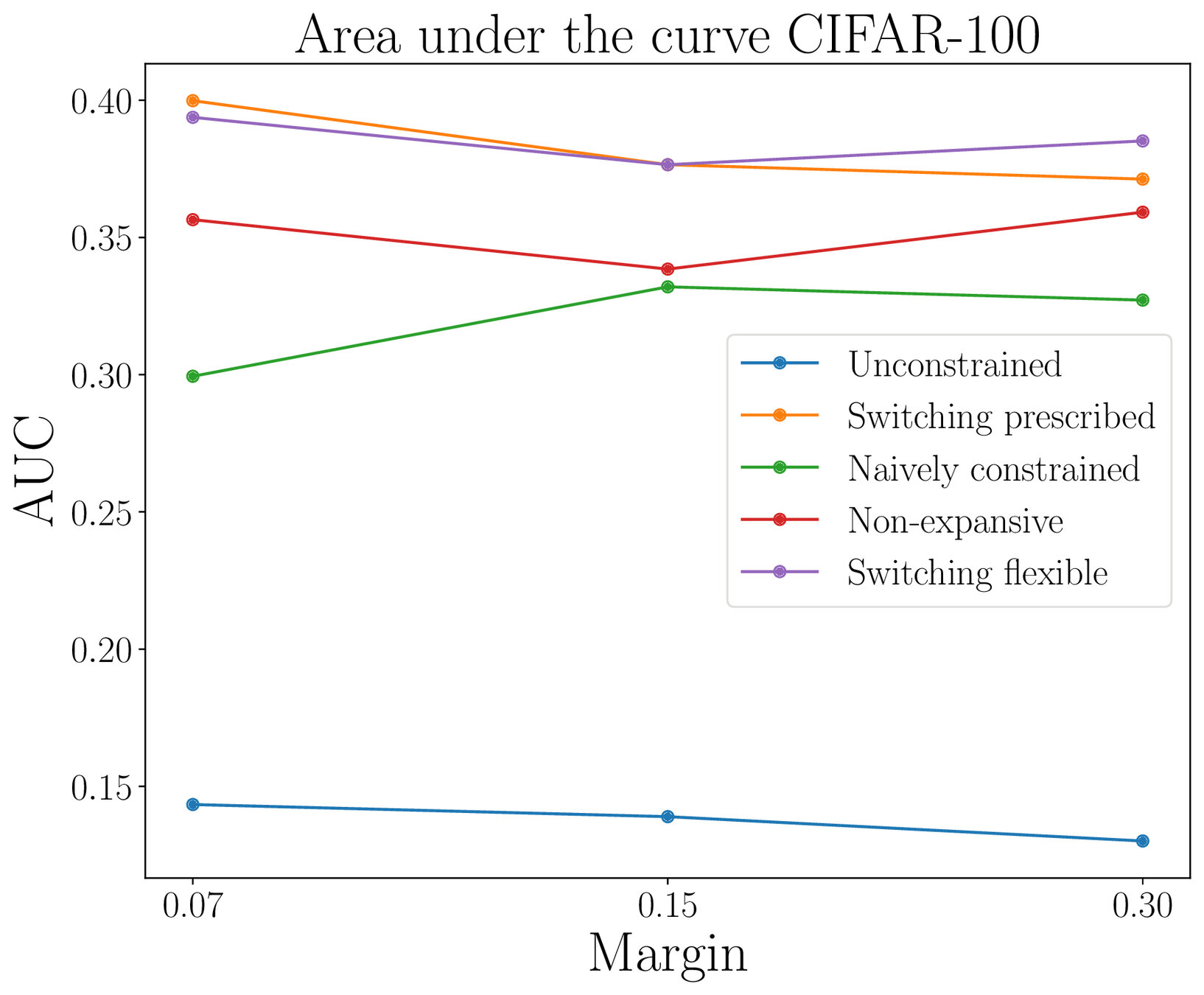
Lipschitz-constrained networks
Lipschitz-constrained networks
Adversarial robustness
Thank you for the attention
\(\texttt{davide.murari@ntnu.no}\)
Examples
1-LIPSCHITZ NETWORKS
HAMILTONIAN NETWORKS
VOLUME PRESERVING, INVERTIBLE
Naively constrained networks
By Davide Murari
Slides ICIAM




