



Davide Murari
A PhD student in numerical analysis at the Norwegian University of Science and Technology.
Davide Murari
davide.murari@ntnu.no
Theoretical and computational aspects of dynamical systems
HB60
What are neural networks
They are compositions of parametric functions
\( \mathcal{N}(x) = f_{\theta_k}\circ ... \circ f_{\theta_1}(x)\)
ResNets
\(\Sigma(z) = [\sigma(z_1),...,\sigma(z_n)],\)
\( \sigma:\mathbb{R}\rightarrow\mathbb{R}\)
Neural networks motivated by dynamical systems
\( \dot{x}(t) = h(x(t),\theta(t))=:h_{s(t)}(x(t)) \)
Where \(f_i(x) = f(x,\theta_i)\)
{
Neural networks motivated by dynamical systems
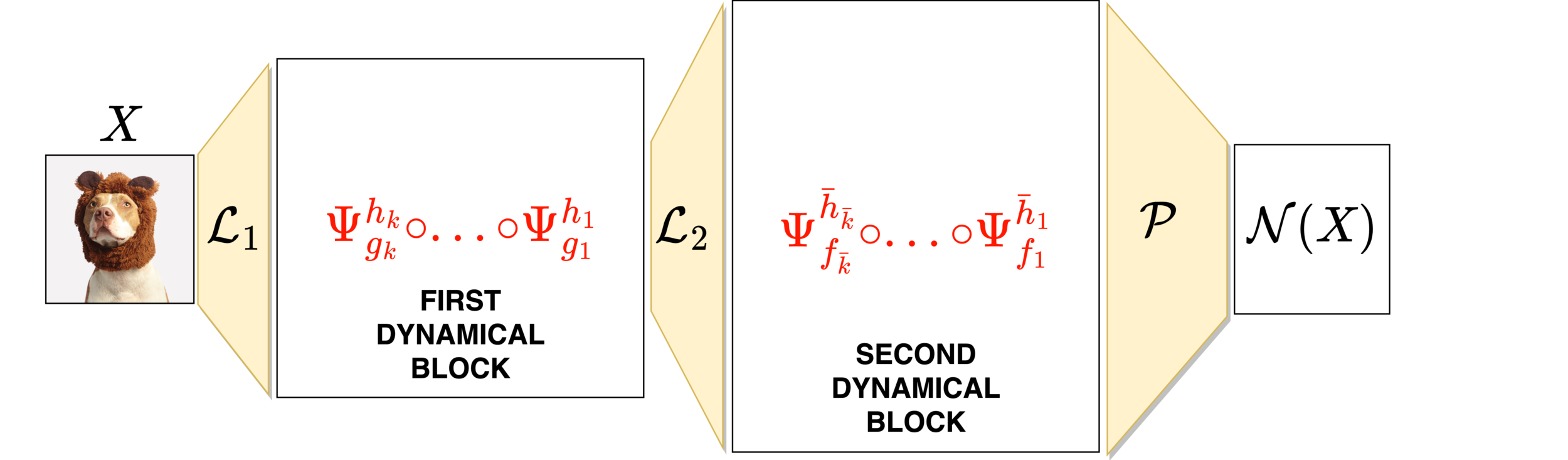
What if I want a network with a certain property?
GENERAL IDEA
EXAMPLE
Property \(\mathcal{P}\)
\(\mathcal{P}=\)Volume preservation
Family \(\mathcal{F}\) of vector fields that satisfy \(\mathcal{P}\)
\(X_{\theta}(x,v) = \begin{bmatrix} \Sigma(Av+a) \\ \Sigma(Bx+b) \end{bmatrix} \)
\(\mathcal{F}=\{X_{\theta}:\,\,\theta\in\mathcal{A}\}\)
Integrator \(\Psi^h\) that preserves \(\mathcal{P}\)
1.
2.
3.
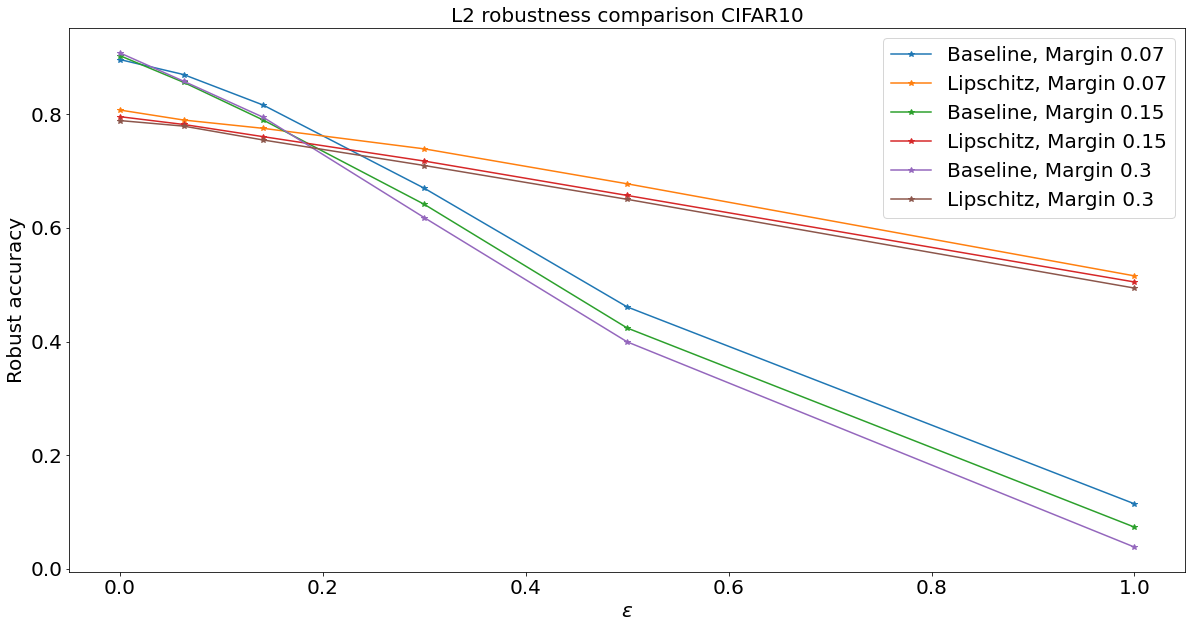
Lipschitz-constrained networks
\(m=1\)
\(m=\frac{1}{2}\)
\(\Sigma(x) = \max\left\{x,\frac{x}{2}\right\}\)
We consider orthogonal weight matrices
Lipschitz-constrained networks
Lipschitz-constrained networks
We impose :
Adversarial examples
\(X\) ,
Label : Plane
\(X+\delta\),
\(\|\delta\|_2=0.3\) ,
Label : Cat
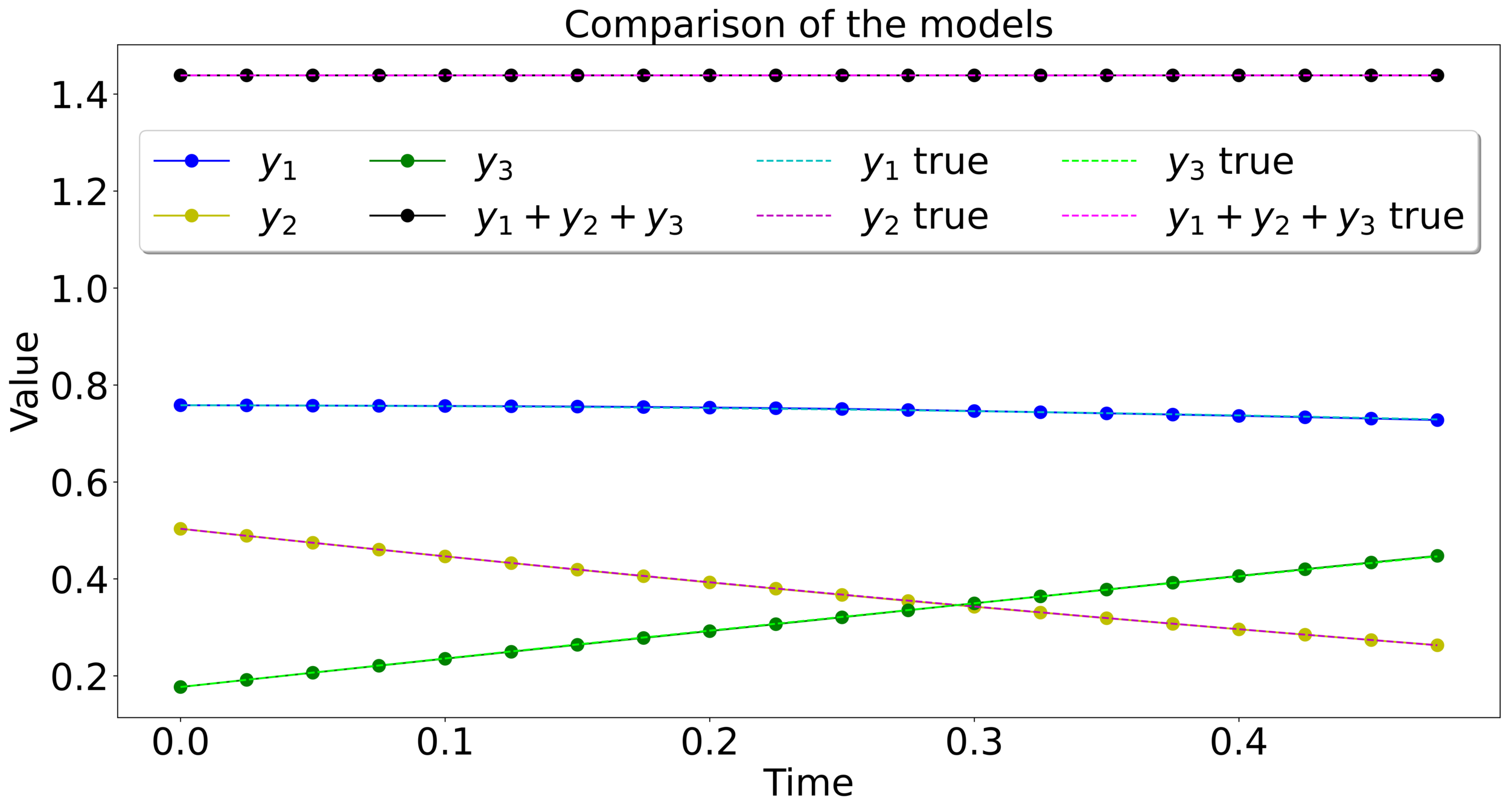
Then \(F\) can be approximated with flow maps of gradient and sphere preserving vector fields.
Can we still accurately approximate functions?
Can we still accurately approximate functions?
By Davide Murari
Slides HB60




