Deep Code Search
By Xiaodong Gu, et al.
Presented by David A.N
Code Search
and the Reusability
Developers usually search and reuse previously written code by performing free-text queries...
Code Search Approaches
| Approach | Technique | Novelty |
|---|---|---|
| Sourcerer (Linstead et al., 2009) | IR | Combines the textual content of a program with structural information. |
| Portfolio (McMillan et al., 2011) | PageRank | Returns chain of functions through keyword matching. |
| CodeHow (Lv et al., 2015) | IR | Combines text similarity matching and API matching. |
Code Search Approaches
| Approach | Technique | Novelty |
|---|---|---|
| Sourcerer (Linstead et al., 2009) | IR | Combines the textual content of a program with structural information. |
| Portfolio (McMillan et al., 2011) | PageRank | Returns chain of functions through keyword matching. |
| CodeHow (Lv et al., 2015) | IR | Combines text similarity matching and API matching. |
Not Machine Learning
Deep Learning for Source Code
| Approach | Novelty |
|---|---|
| White et al., 2016 | Predicting software tokens by using RNN language model. |
| DEEPAPI (Gu, et al., 2016) | Deep learning method that learns the semantic of queries and the corresponding API sequences. |
The gap
and the dilemma of matching meaning from Source Code and Natural Language
IR-Based Code Search Fundamental Problem
-
Source code and Natural Language queries are heterogeneous
-
They may not share common lexical tokens, synonyms, or language structure
-
They can be only semantically related
Semantic Mapping
Query: "read an object from an XML"
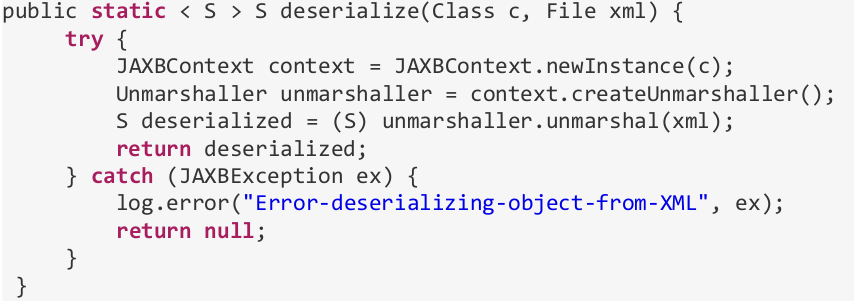
Can anybody see the problem?
Intuition
- Embeddings techniques
- RNN for sequence embeddings
- Joint Embedding of Heterogeneous Data
Embedding Techniques
- CBOW
- Skip-Gram
A sentence can also be embedded as a vector.
execute = [0.12, -0.32]
run = [0.42, -0.52]
RNN for Sequence Embeddings
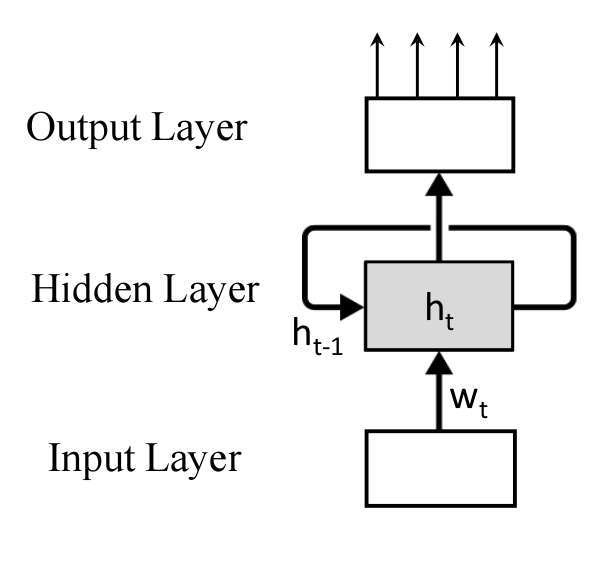
s=w_1,...,w_T
w_t=V(w_t)
V(w_t) \in \mathbb{R}^d
RNN for Sequence Embeddings
s=w_1,...,w_T
w_t=V(w_t)
V(w_t) \in \mathbb{R}^d
RNN for Sequence Embeddings
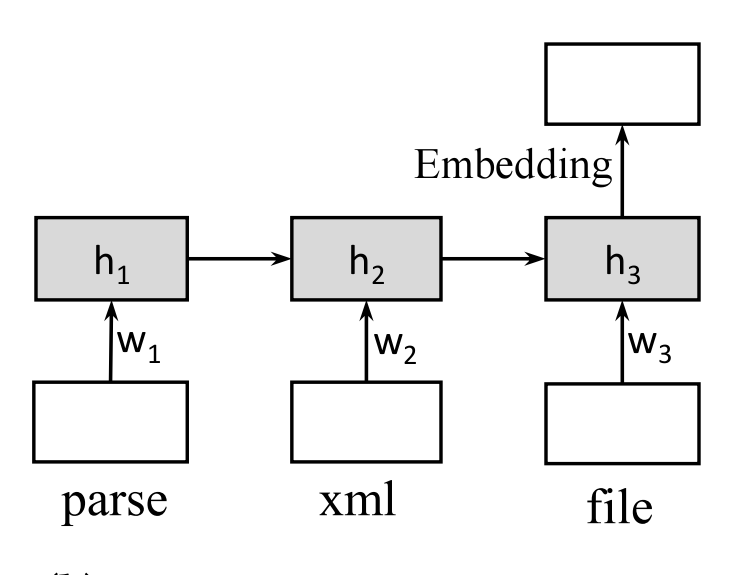
h_t = tanh(W[h_{t-1};w_t]), \forall_t = 1,2,...,T
RNN for Sequence Embeddings
h_t = tanh(W[h_{t-1};w_t]), \forall_t = 1,2,...,T
RNN for Sequence Embeddings
h_t = tanh(W[h_{t-1};w_t]), \forall_t = 1,2,...,T
2 ways for embedding:
- using last NN
- using maxpooling
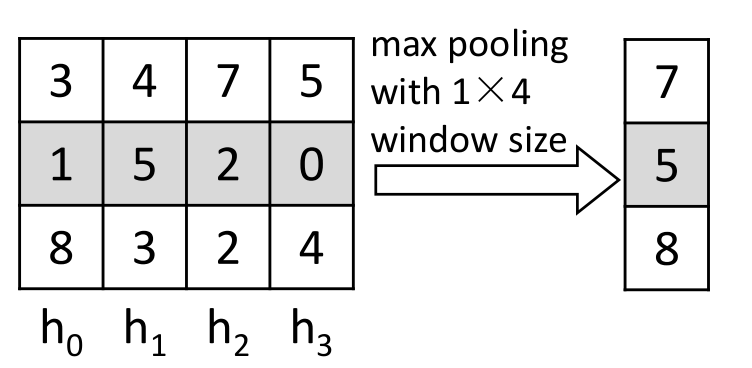
s=maxpooling([h_1,...,h_T])
RNN for Sequence Embeddings
Joint Embeddings
f:x \to y
x \rightarrow^\phi V_x \rightarrow J(V_x,Vy) \leftarrow V_y \leftarrow^\psi y
Joint Embeddings
f:x \to y
x \rightarrow^\phi V_x \rightarrow J(V_x,Vy) \leftarrow V_y \leftarrow^\psi y
Joint Embeddings
f:x \to y
x \rightarrow^\phi V_x \rightarrow J(V_x,Vy) \leftarrow V_y \leftarrow^\psi y
Joint Embeddings
f:x \to y
x \rightarrow^\phi V_x \rightarrow J(V_x,Vy) \leftarrow V_y \leftarrow^\psi y
Solution/Approach
COde Description Embedding Neural Network (CODEnn)
Code and Queries in the same space
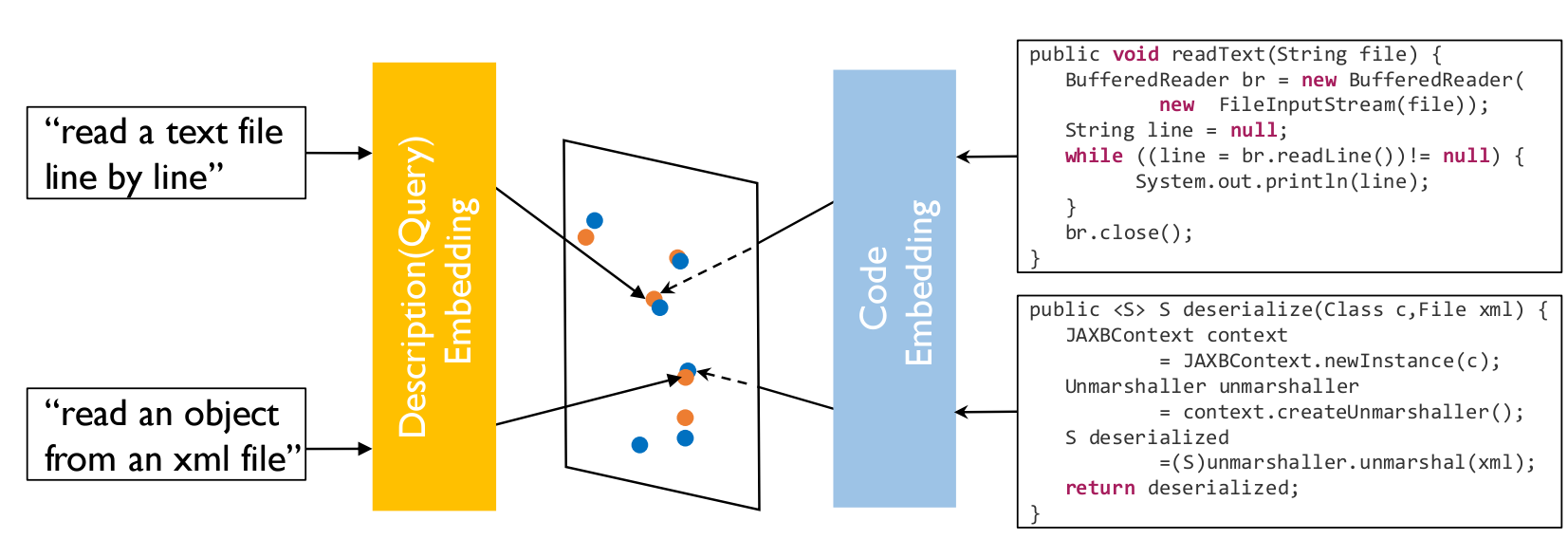
Code and Queries in the same space
CoNN
Code and Queries in the same space
CoNN
DeNN
Huge Multi-Layer Perceptron
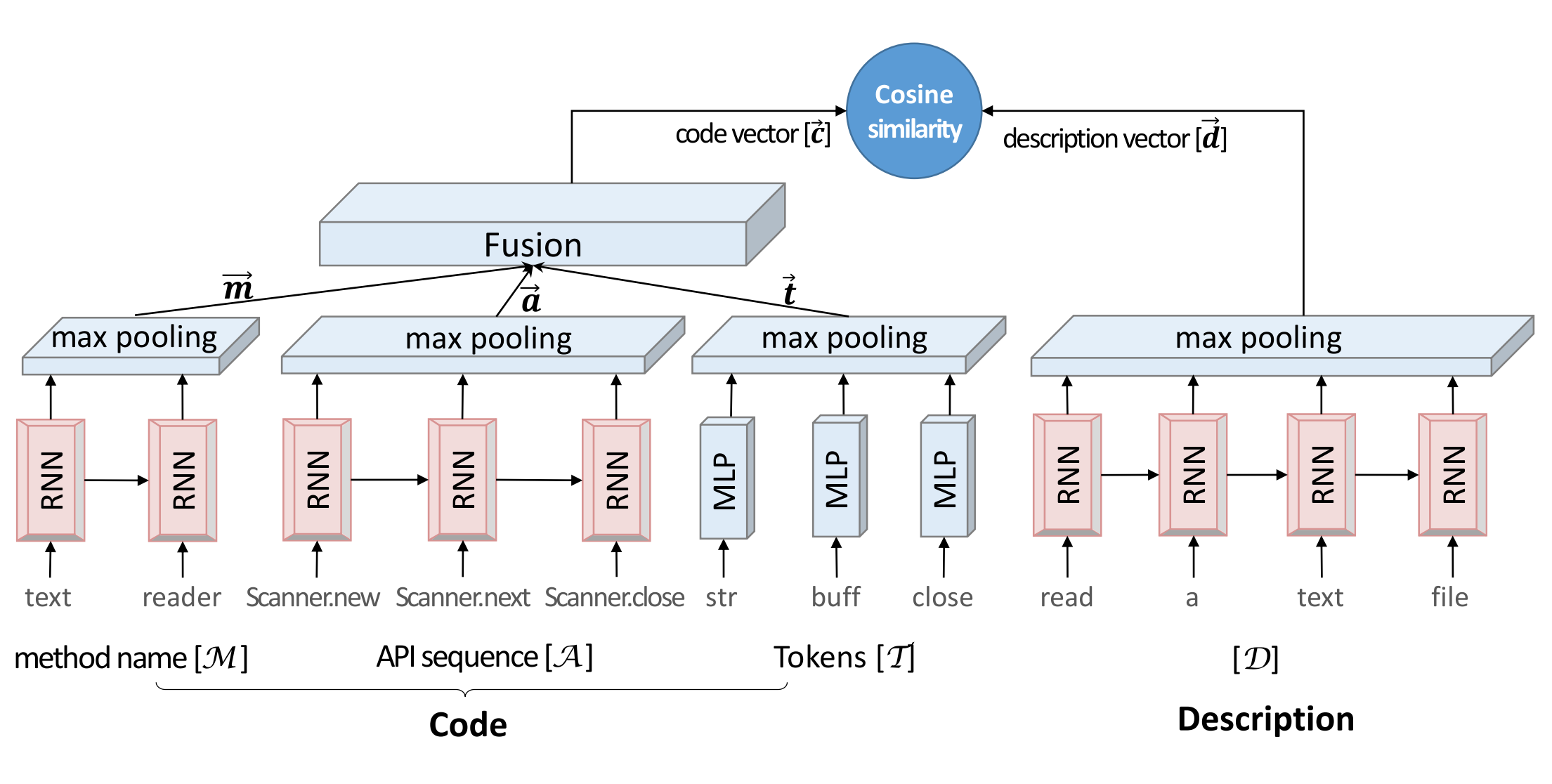
Huge Multi-Layer Perceptron
Huge Multi-Layer Perceptron
Huge Multi-Layer Perceptron
Huge Multi-Layer Perceptron
Huge Multi-Layer Perceptron
Huge Multi-Layer Perceptron
Model Training
The hinge loss
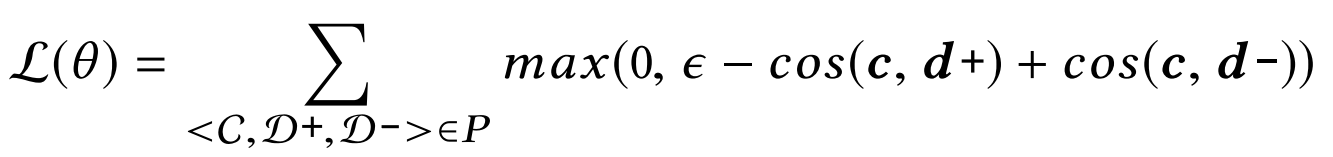
Model Training
Parameters of NN
Model Training
Training Tuple
Model Training
Constant Margin
Model Training
Embedded Vectors
DEEPCS
as a code search tool
Workflow
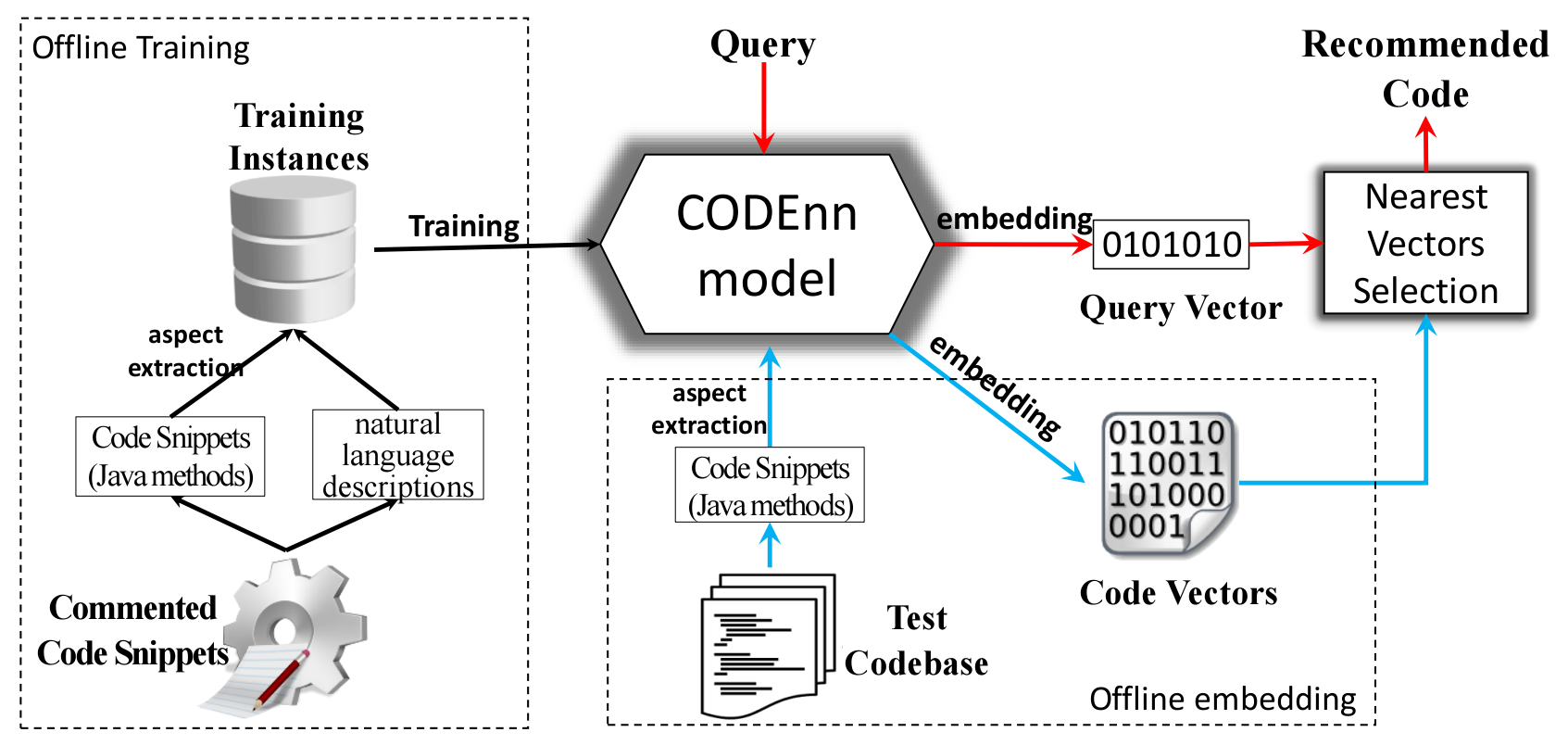
Workflow
Workflow
Workflow
The magic extraction
Preprocessing as camel-case and AST parsing.
Source: GitHub and JavaDoc

The magic extraction
Preprocessing as camel-case and AST parsing.
Source: GitHub and JavaDoc
Evaluation
- 18,233,872 commented Java Methods
- Bi-directional LSTM
- d = 100
- Batch = 128
- Keras & Theano
Performance Measures
- SuccessRate@K: measures the percentage of queries for which more than one correct result could exist in the top k ranked results.
- FRank: is the rank of the first hit result in the result list; the smaller, the lowest inspection effort.
- Precision@K: measures the percentage of a relevant result in the returned top k.
- MRR: is the average of the reciprocal ranks of the results of a set of queries.
Baseline vs DeepCS in terms of accuracy
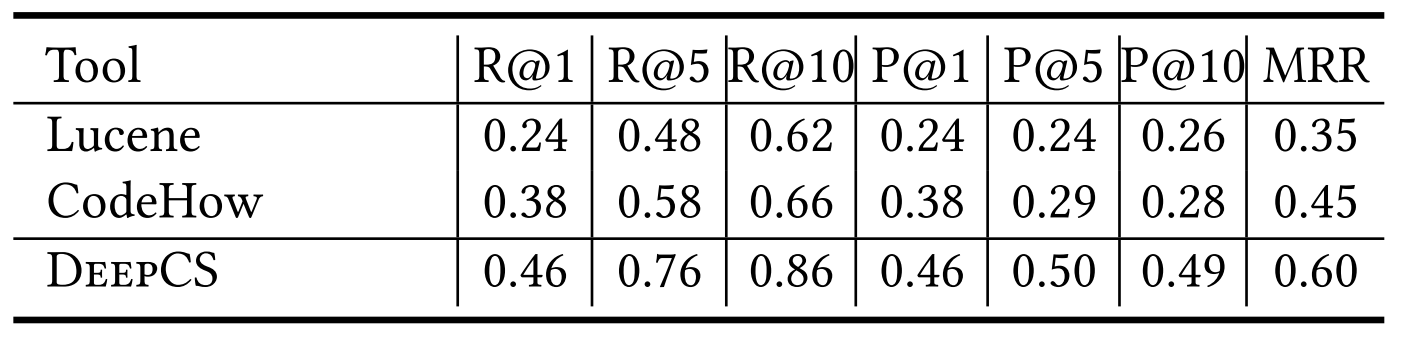
Baseline vs DeepCS in terms of accuracy
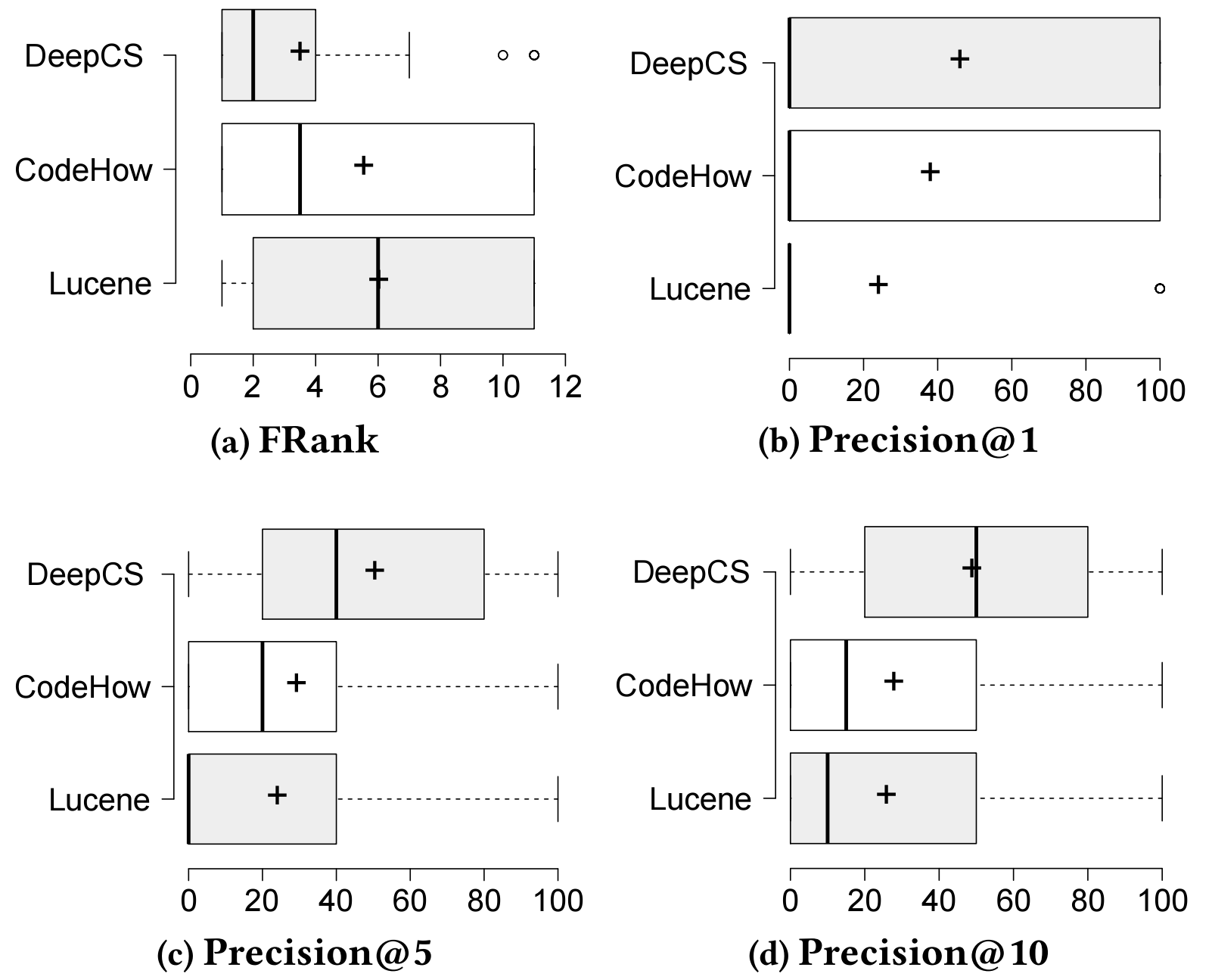
Discussion
Why does DeepCS work?
Does DeepCS work?
:|
Discussion
- What are the advantages of using a Recurrent Neural Network instead of a typical multilayer perceptron?
- How can the Joint Embedding be improved?
- Are there any ways of transferring information among datasets different from common error training?
Deep Code Search
By David Nader Palacio



