Fusing representations for code-mixed low resource language processing
Problem?
- Low resource language data being generated at a large scale now.
- Major work has been done only for English-x language code-mixed language models.
- Untapped potential of low resource to low resource code-mixed language data.

Notable Work
Proposed Solution
Generate data using GCM
GANFusion to fuse representations
Extract representations and use for a demo task
Repeat for multiple language combinations
What is GANFusion?
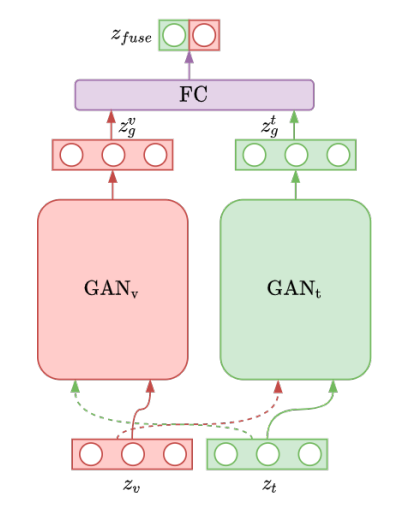
Pre-processing for the z-vector
- Text cleaning using Ekphrasis
- POS tagging to create a "(subject, object, verb, modifier)" pointer
- pt is passed through a LSTM+Word Attention model to create the input to GAN:
p_t
z_t
Impact?
- Low resource code-mixed language processing
- Transfer Learning to English-x code-mixed tasks
- Social computing based Computational Social Science Tasks
Thank you!
Copy of unicode-research-presentation
By deep1401
Copy of unicode-research-presentation
Presentation for Unicode Research project

