Secure your AI models against adversarial threats - Python libraries Cleverhans and Foolbox
By
Deya Chatterjee
“If you know the enemy and know yourself, you need not fear the result of a hundred battles.”
-- Sun Tzu, 500 BC
Subtitle
(Thanks, Dr Lowd.)
Why do we need to protect our AI models?
- Data is out there publicly, hence vulnerable.
- Protect our models to protect our data also (confidential data like medical records, esp.)
- Re-identification, de-identification, anonymization and linkage attacks
- Data frauds have always been there, but stronger now
- Adversarial attacks
- Dangers to users of specific use cases (even fatalities. e.g., in autonomous driving and healthcare)
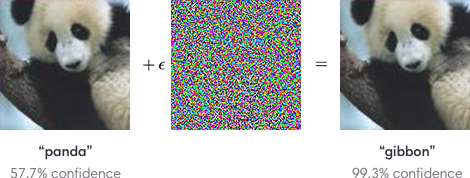
Note that the confidence for the panda label is way lower than the confidence for the gibbon level even!

Image credits: Adversarial examples for AlexNet by Szegedy et. al (2013) and this amazing book.
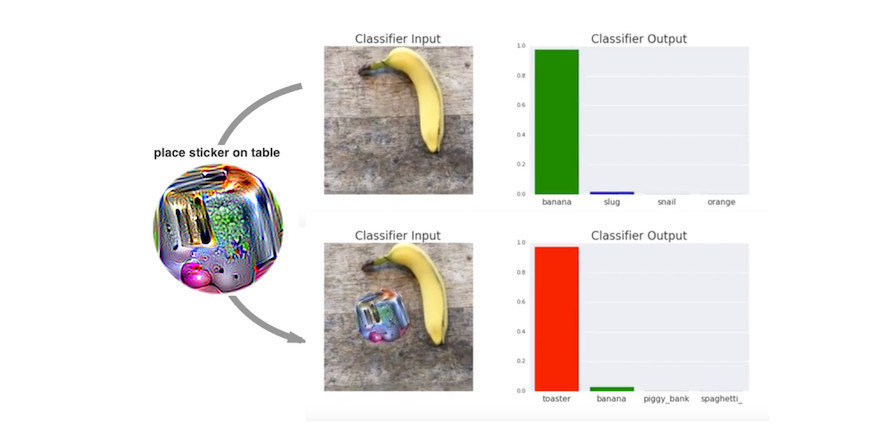
Image credits: Brown et. al (2017) and this amazing book.
Banana or toaster?
Image credits: Su et. al (2019) and this amazing book
Jellyfish or bathing tub??
What is the main goal, u say?
Optimize the noise to maximize the error.
Now, what is the goal of our talk?
- Understand adversarial examples and attacks
- Understand the dangers and why defenses are needed
- How different Python libraries can be used to craft attacks, defenses, and check for robustness
- Give an idea about trends in the field
- Walk through code, demo and snippets
- Take away (hopefully) an interest in this field and probably more contributors!
What is Cleverhans?
Python library to test ML systems' vulnerability to adversarial examples
Or, to install latest version as it is on Github:
pip install cleverhanspip install git+https://github.com/tensorflow/cleverhans.git#egg=cleverhans
Non-targeted
- Generalized type
- Make classifier give incorrect prediction, whatever the prediction may be
Targeted
- Specialized type
- Target class: make classifier predict target class
- more difficult
- more dangerous (for fraud, etc.)
Based on targets, there are two:
Whitebox
- Complete access to model
- Model arch, params
- Hence, easier to attack
Blackbox
- Attacker knows only model o/p
- Target class: make classifier predict target class
- more difficult
- more dangerous (for fraud, etc.)
FGSM
Fast Gradient Sign Method
from cleverhans.attacks import FastGradientMethodQuite a basic method. Foundation for advanced attacks.
Iterative FGSM
Iterative Fast Gradient Sign Method, duh!
Advancement upon the previous.
L-BFGS
The Limited-memory Broyden-Fletcher-Goldfarb-Shanno (wow!)
- Slow, but high accuracy.
- For convolutional neural networks.
- Whitebox attack.
Code Snippets
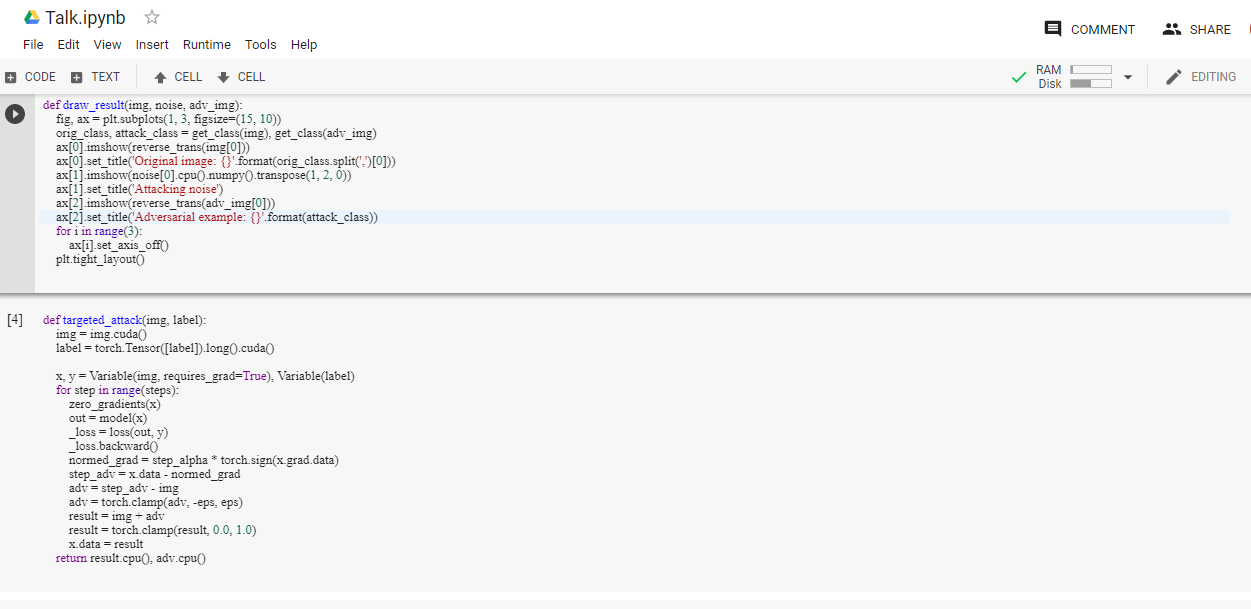
Code Snippets
Enough about attacks!
What about defenses?
Defensive distillation
However, it can be defeated :(
Adversarial training
In other news.. (cleverhans on twitter)
Like, what about other libs in Python..?
- advertorch (Pytorch)
- baidu/AdvBox
- bethgelab/foolbox
- IBM/adversarial-examples-toolbox
- BorealisAI (Pytorch)
What other than Cleverhans?
This week in using Python to combat adversarial examples
This week in using Python to combat adversarial examples (contd.)
This week in using Python to combat adversarial examples (contd.)
To know how noise works, types of noise and models' sensitivity to noise, check out these notebooks!
Subtitle
Interesting references - Part 1
Possible explanation for why NNs are susceptible to adversarial attacks in the first place
Subtitle
Interesting references - Part 2
Contribute!
-
To my project: ping me on Github/ LinkedIn
-
To Cleverhans ! Check out the issues.
-
Read the contributing guidelines.
-
Follow same method for other libs
-
Find one that matches with your favorite DL framework!
Thank you!
Adversarial examples and Cleverhans
By deya_not_diya


