Secure your AI models against adversarial threats - Python libraries Cleverhans and Foolbox
By
Deya Chatterjee
https://deyachatterjee.github.io
Why do we need to protect our AI models?
- Data is out there publicly, hence vulnerable.
- Protect our models to protect our data also (confidential data like medical records, esp.)
- Re-identification, de-identification, anonymization and linkage attacks
- Data frauds have always been there, but stronger now
- Adversarial attacks
- Dangers to users of specific use cases (even fatalities. e.g., in autonomous driving and healthcare)
Now, what is the goal of our talk?
- Understand adversarial examples and attacks
- Understand the dangers and why defenses are needed
- How different Python libraries can be used to craft attacks, defenses, and check for robustness
- Give an idea about trends in the field
- Walk through code, demo and snippets
- Take away (hopefully) an interest in this field and probably more contributors!
Adversarial examples
1. First, see some examples to gain intuition.
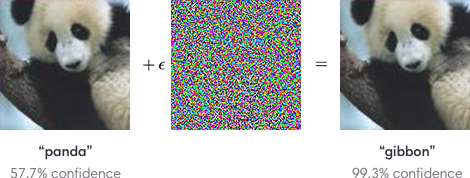
Note that the confidence for the panda label is way lower than the confidence for the gibbon level even!

All three on the right have been classified as ostriches!
Image credits: Adversarial examples for AlexNet by Szegedy et. al (2013) and this amazing book.
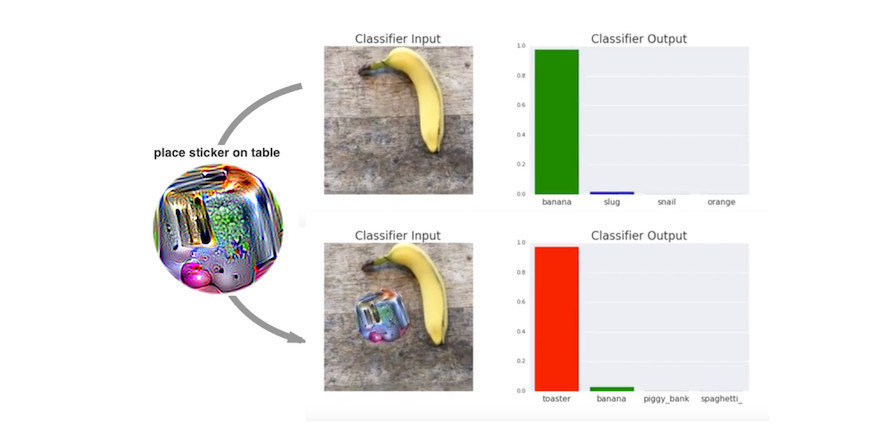
Image credits: Brown et. al (2017) and this amazing book.
Banana or toaster? Notice the class labels in the right graph. This is also how physical adversarial attacks are done on SDCs.
Adversarial examples
2. Basic concepts: why it works?
What is the main goal, u say?
Optimize the noise to maximize the error.
Basic technicality for generating adversarial examples
- Think about gradient descent, i.e., how we normally train our NNs (take baby steps in direction of gradient to finally converge to local minima)
- Now think about loss function: see below
- Finally, turn the entire thing upside down! (can be said as 'gradient ascent')
//gradient descent
theta' = theta - alpha. d(loss) //where loss is L(X,y,theta)
x'=x+alpha.d(loss) //generate adversarial examples
To digress a little, let's talk about GANs
- Generator G + Discriminator D playing off each other
- the 'adversarial' concept arises from here
- Inspiration: game theory
- open problem: relate GANs with adversarial examples (e.g., what if I adversarial attack a GAN model? The 'D' is built as adversarially robust in that scenario, so would it be affected ?)
- 2 architectures I would specifically talk about: AT-GAN and Cycle-GAN

Source: AT-GAN paper by Wang et al. (Paper link)

Source: AT-GAN paper by Wang et al. (Paper link)
Adversarial attacks
1. Cleverhans
2. Types of attacks
What is Cleverhans?
Python (Tensorflow) library to test ML systems' vulnerability to adversarial examples


Or, to install latest version as it is on Github:
pip install cleverhanspip install git+https://github.com/tensorflow/cleverhans.git#egg=cleverhans
Non-targeted attacks
- Generalized type
- Make classifier give incorrect prediction, whatever the prediction may be
- Just make sure that the actual label is not outputted
Targeted attacks
- Specialized type
- Target class: make classifier predict target class
- more difficult
- more dangerous (for fraud, etc.)
Based on targets, there are two types of attacks:
Whitebox attacks
- Complete access to model
- Model arch, params, gradients
- Hence, easier to attack
- More dangerous ; attacker has more power
Blackbox attacks
- Attacker knows only model o/p or maybe probability/accuracy for a particular task
- No knowledge about model gradients to tweak it
- However, they can be AS EFFECTIVE
Based on access to model internalities, there are again two types of attacks:
FGSM
Fast Gradient Sign Method
from cleverhans.attacks import FastGradientMethod- The most basic method. Foundation for advanced attacks.
- Remember the panda->gibbon example? FGSM did that
- Whitebox attack
//gradient descent
theta' = theta - alpha. d(loss) // where loss is L(X,y,theta)
x'=x+alpha.d(loss) // generate adversarial examples
//for FGSM replace alpha by epsilon, which is fixed perturbation per pixel
x'=x+epsilon.d(loss)
L-BFGS
The Limited-memory Broyden-Fletcher-Goldfarb-Shanno attack
- Slow, but high accuracy.
- For convolutional neural networks.
- Whitebox attack.
- Extension of L-BFGS: Carlini Wagner attack
PGD attack
Projected stochastic gradient descent attack
- Said to be 'the most complete whitebox adversary': gives attacker unrestrained freedom to launch attack
- Whitebox attack.
- BIM (Basic Iterative Method) attack is very important.
- Commonly used.
Consequences
Are our systems at stake?
There are contrasting views to this.


Consequences (contd.)
Are our systems at stake?
- self-driving cars
- medical deep learning systems
- malware classification in file systems
- basically, should we trust automated decision tools?
- adversarial audio: security of automated assistants (e.g., Siri)
- any deployed ML system is at stake.
Yes, they are.
Code demo
Adversarial examples against medical systems
Part 1: visual demo
Image credits for following 2 slides: Finlayson et al. and Ma et al. (ArXiv), MIT Media Lab and cyber.harvard.edu
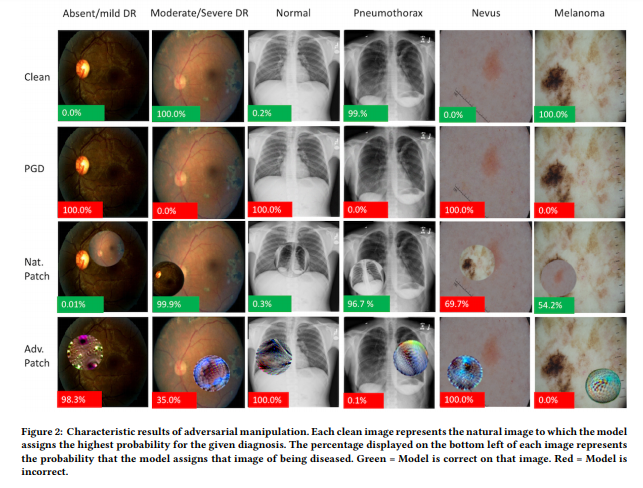
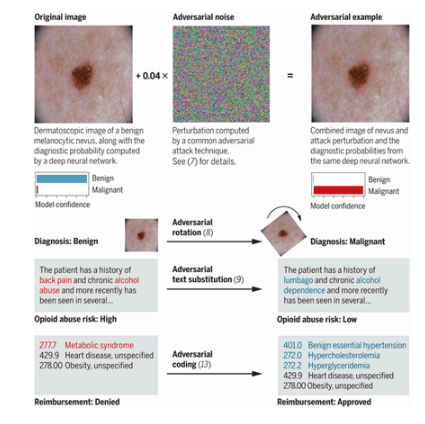
Code demo
Adversarial examples against medical systems
Part 2: code snippets
Second code created as a wrapper over https://github.com/sgfin/adversarial-medicine
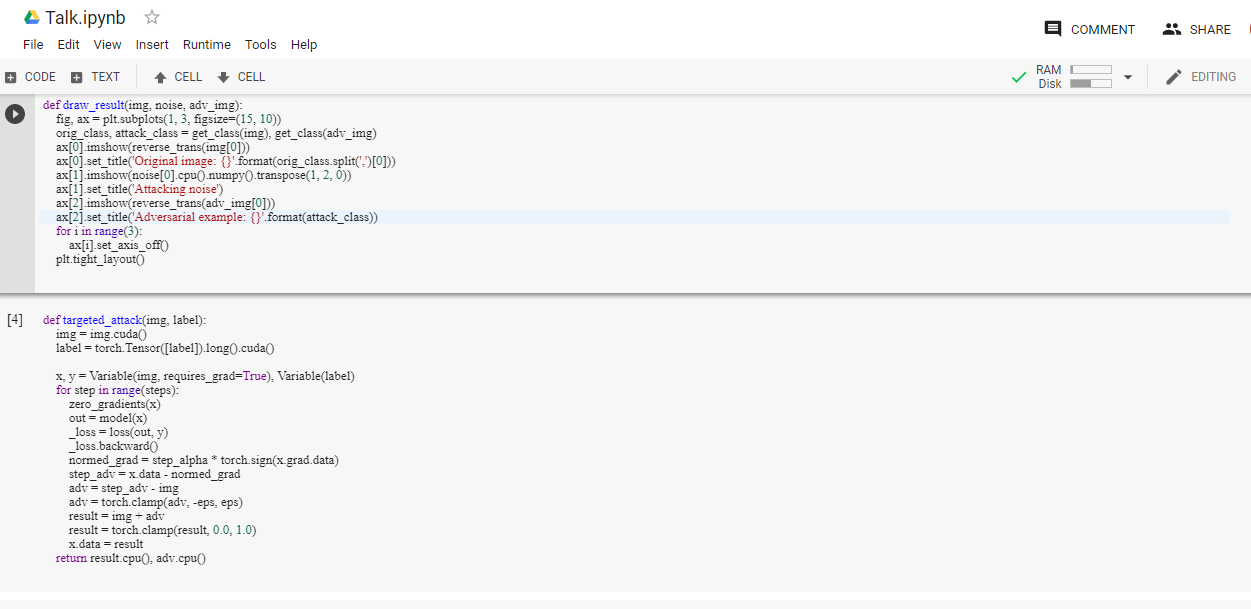
Code Snippets
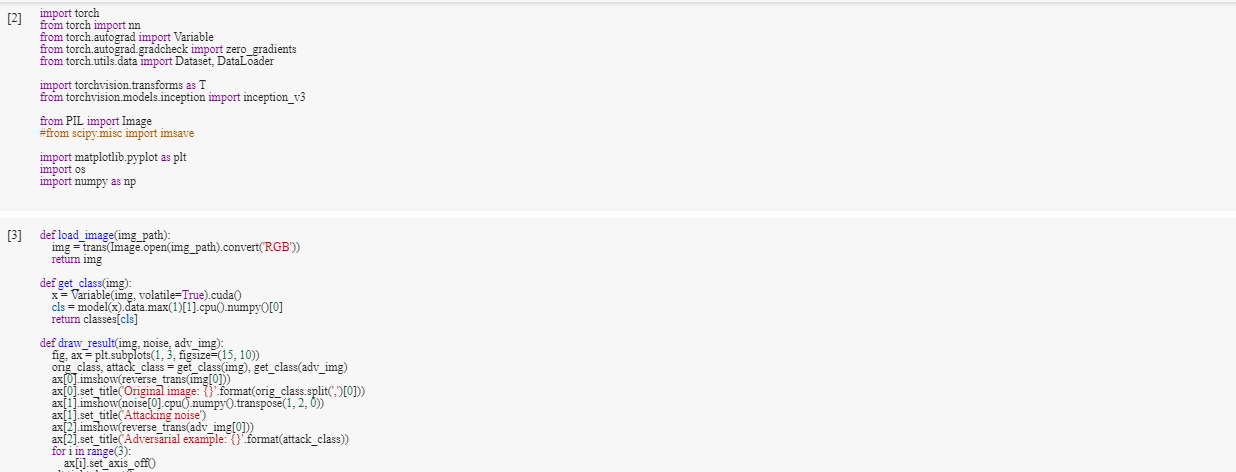
Code Snippets
Enough about attacks!
What about defenses?
- But some studies say that maybe attacking ML models is easier than defending them
- True, not much research has been done with defenses as they have been with attacks, but we can hope.
- Some techniques: Defense-GAN, distillation, input transformations and adversarial training.
Defensive distillation
However, it can be defeated :(
-
adds flexibility to an algorithm’s classification process so the model is less susceptible to exploitation
-
one model is trained to predict the output probs of another model that was trained on an earlier, baseline standard
Adversarial training
Main takeaway: augment dataset with adversarial examples to make it more adversarially robust. But it doesn't perform well when attacker takes a different strategy.
In other news.. (cleverhans on twitter)
Like, what about other libs in Python..?
- advertorch (Pytorch)
- baidu/AdvBox
- bethgelab/foolbox
- IBM/adversarial-examples-toolbox
- BorealisAI (Pytorch)
What other than Cleverhans?
This week in using Python to combat adversarial examples
This week in using Python to combat adversarial examples (contd.)
This week in using Python to combat adversarial examples (contd.)
To know how noise works, types of noise and models' sensitivity to noise, check out these notebooks!
Interesting references - Part 1
Possible explanation for why NNs are susceptible to adversarial attacks in the first place
Interesting references - Part 2
Contribute!
-
To our project: ping me on Github/ LinkedIn
-
To Cleverhans ! Check out the issues.
-
Read the contributing guidelines.
-
Follow same method for other libs
-
Find one that matches with your favorite DL framework!
Thank you!
On adversarial examples and Cleverhans
By deya_not_diya


