





























Daniel Himmelstein
Head of Data Integration at Related Sciences. Digital craftsman of the biodata revolution.
Epistasis Discovery in Genetics and Epidemiology (EDGE)
Marriott Key West Beachside Hotel
Salon C · 1:00 PM
February 8, 2018
Slides at slides.com/dhimmel/edge
Moore Lab Lunch
Jesse's Tavern
August, 2007
http://www.greenelab.com/
Approaches in network medicine have traditionally focused on generating insights from graphs with a single type of node and relationship. However, biology's complexity demands a richer network structure capable of integrating diverse, multi-scale information. Towards this end, we develop hetnets — networks with multiple types of nodes and relationships.
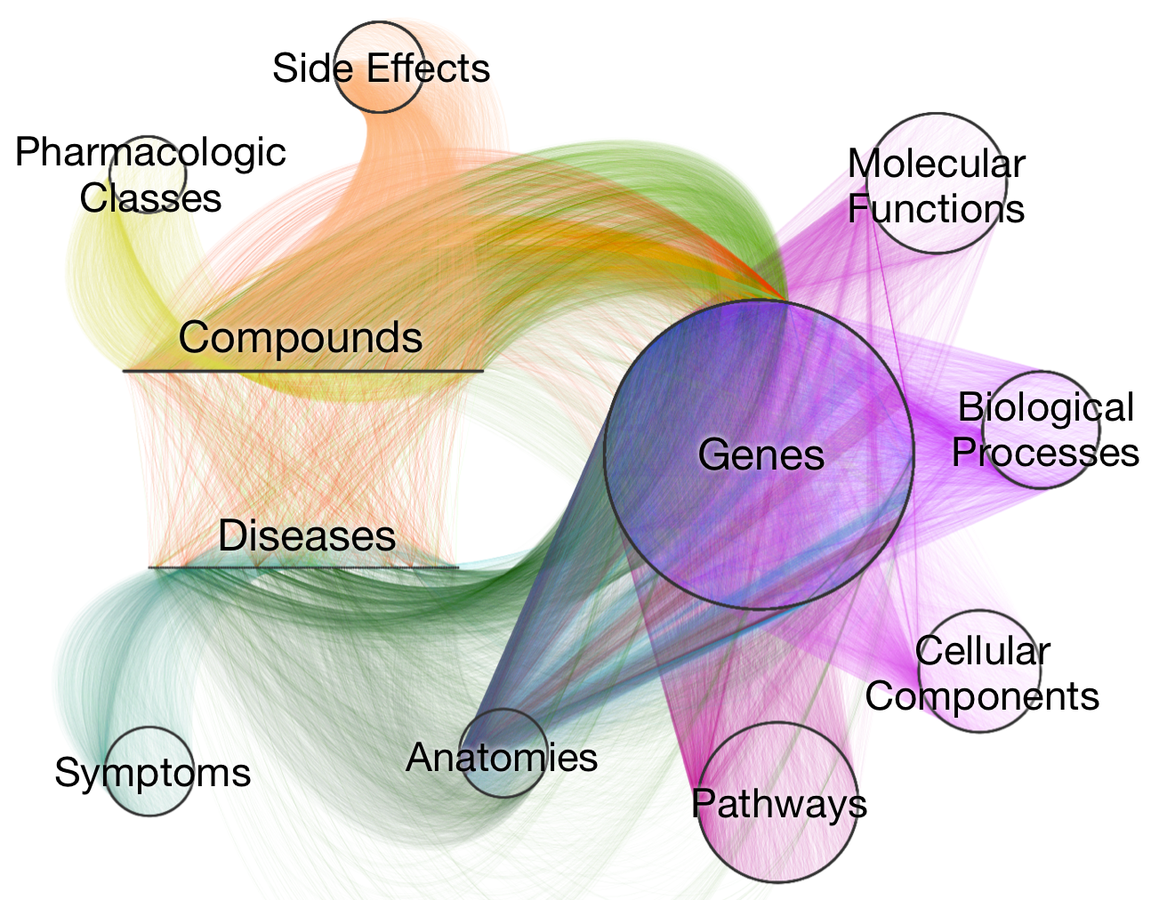
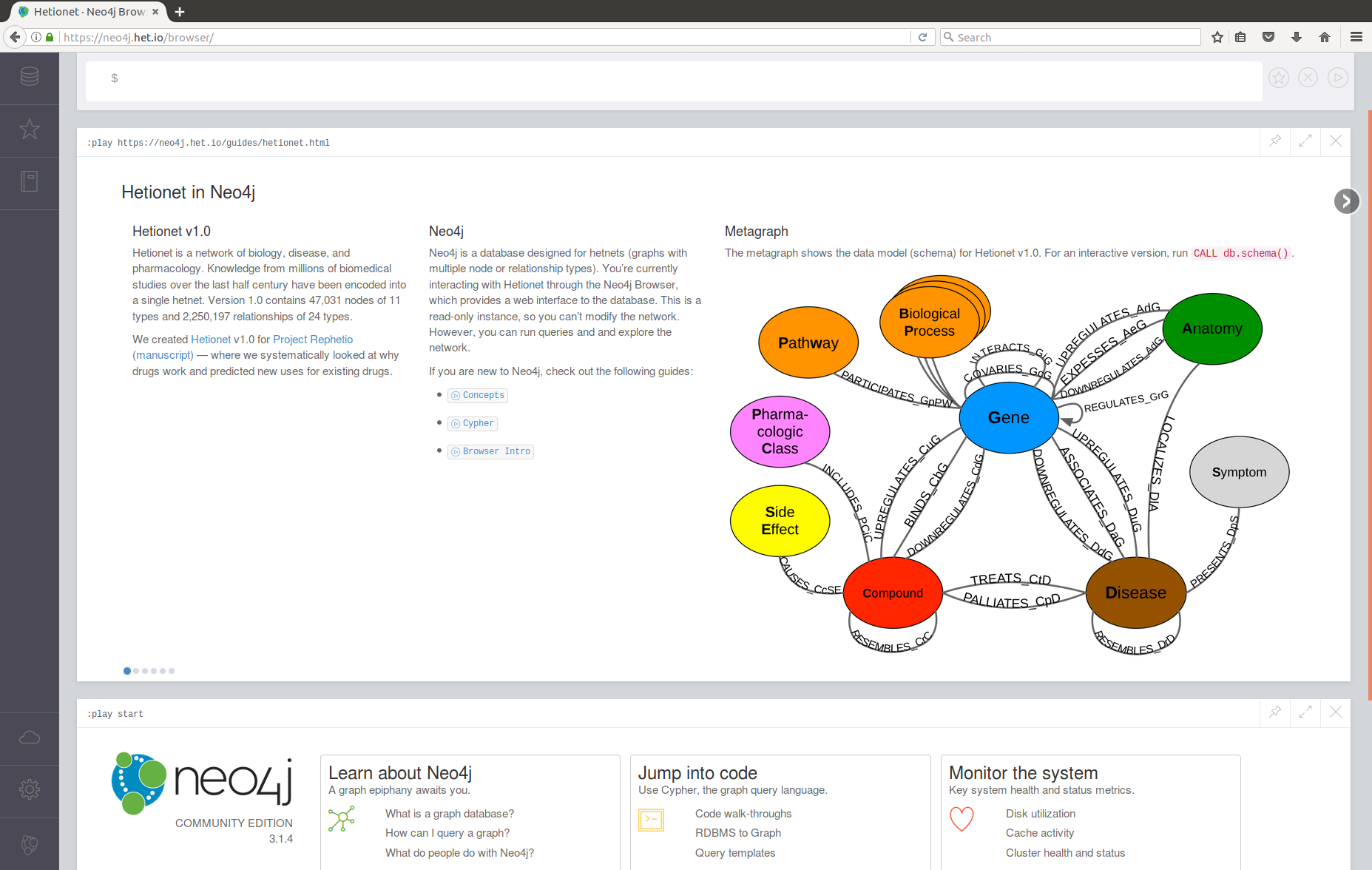
Specifically we created Hetionet — a network of biology, disease, and pharmacology. This resource encodes knowledge from millions of biomedical studies over the last half century. Version 1.0 contains 47,031 nodes of 11 types and 2,250,197 relationships of 24 types. We host a public Neo4j database instance at https://neo4j.het.io allowing users to interact with Hetionet.
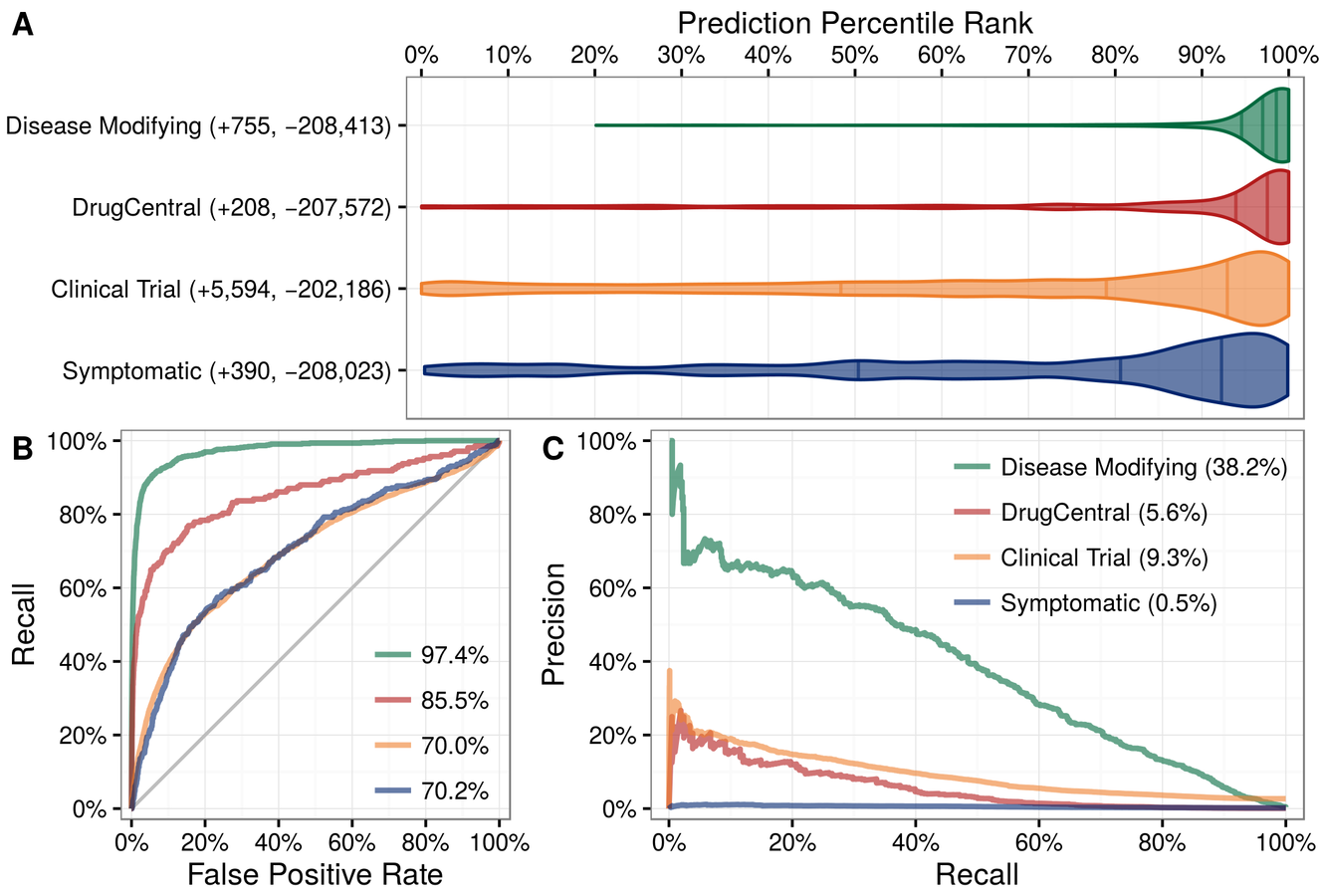
In Project Rephetio, we applied Hetionet to predict new uses for existing drugs. Our approach learned the network patterns of connectivity that differentiate treatments from non-treatments, enabling us to predict the probability of treatment for 209,168 compound–disease pairs. These predictions prioritize treatments under investigation by clinical trial.
Going forward, we're investigating more efficient algorithms for feature extraction on hetnets. In addition, we're looking to automate hetnet construction by text mining the literature. The success of hetnets will depend on the availability of openly licensed inputs. As such, I'll briefly discuss data analyses I've performed in hopes of making science more open.
Graphs are composed of:
Nodes / relationships have type:
networks with multiple node or relationship types
multilayer network, multiplex network, multivariate network, multinetwork, multirelational network, multirelational data, multilayered network, multidimensional network, multislice network, multiplex of interdependent networks, hypernetwork, overlay network, composite network, multilevel network, multiweighted graph, heterogeneous network, multitype network, interconnected networks, interdependent networks, partially interdependent networks, network of networks, coupled networks, interconnecting networks, interacting networks, heterogenous information network
A 2012 Study identified 26 different names for this type of network:
hetnet
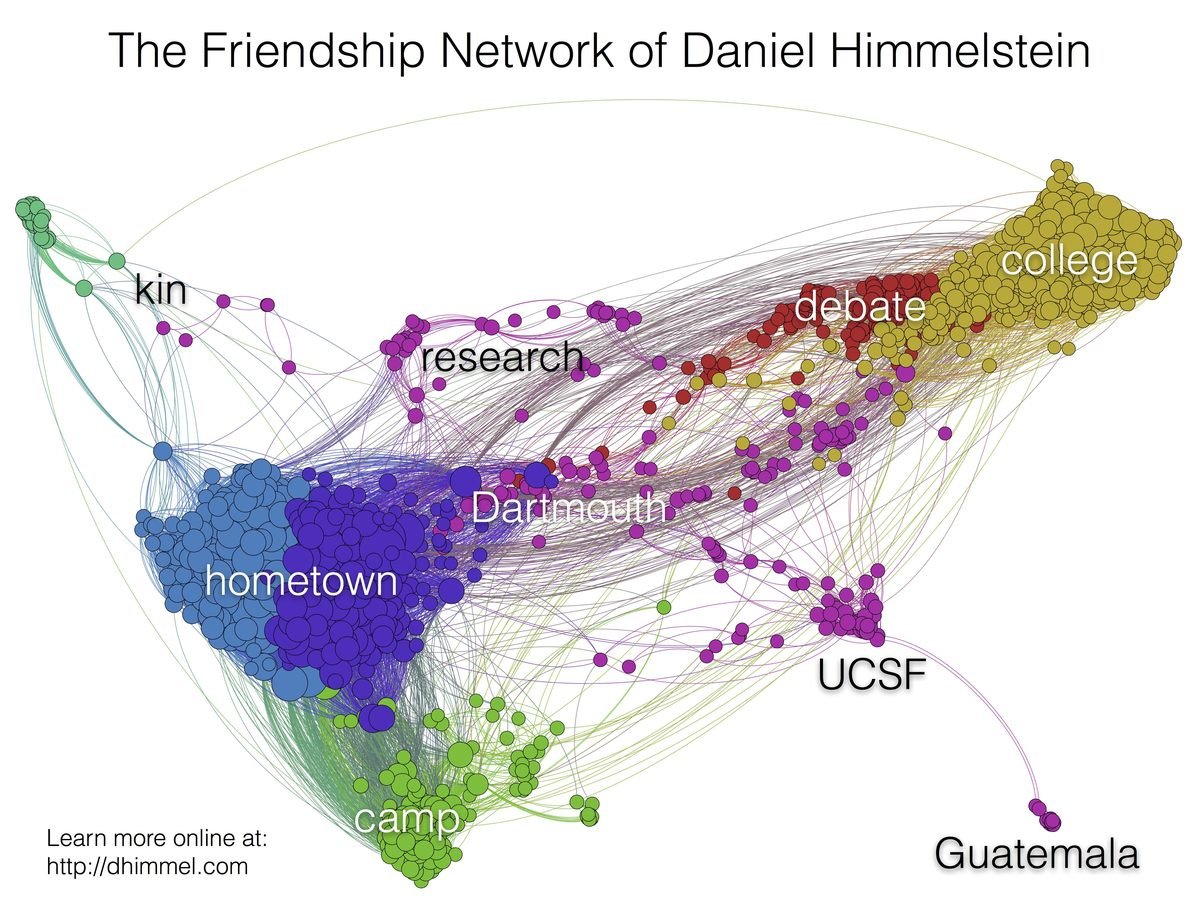
Visualizing Hetionet v1.0
>>> import phd
What's the best software for storing and querying hetnets?
| dhimmel/hetio | |
|---|---|
| 86 | |
| 5 | |
| 2 |
| neo4j/neo4j |
|---|
| 42,498 |
| 3,071 |
| 1,007 |
GitHub stats from 2016-10-09
Details at doi.org/brsc
MATCH path =
// Specify the type of path to match
(n0:Disease)-[e1:ASSOCIATES_DaG]-(n1:Gene)-[:INTERACTS_GiG]-
(n2:Gene)-[:PARTICIPATES_GpBP]-(n3:BiologicalProcess)
WHERE
// Specify the source and target nodes
n0.name = 'multiple sclerosis' AND
n3.name = 'retina layer formation'
// Require GWAS support for the
// Disease-associates-Gene relationship
AND 'GWAS Catalog' in e1.sources
// Require the interacting gene to be
// upregulated in a relevant tissue
AND exists(
(n0)-[:LOCALIZES_DlA]-(:Anatomy)-[:UPREGULATES_AuG]-(n2))
RETURN pathMore queries at thinklab.com/d/220
Systematic integration of biomedical knowledge prioritizes drugs for repurposing
Daniel S Himmelstein, Antoine Lizee, Christine Hessler, Leo Brueggeman, Sabrina L Chen, Dexter Hadley, Ari Green, Pouya Khankhanian, Sergio E Baranzini
In pres at eLife. https://doi.org/10.1101/087619
features = metapaths
observations =
compound–disease pairs
positives = treatments
negatives =
non-treatments
Browse at het.io/repurpose/metapaths.html
Compound–causes–SideEffect–causes–Compound–treats–Disease
Compound–binds–Gene–binds–Compound–treats–Disease
Compound–binds–Gene–associates–Disease
Compound–binds–Gene–participates–Pathway–participates–Disease
MATCH path = (n0:Compound)-[:BINDS_CbG]-(n1)-[:PARTICIPATES_GpPW]-
(n2)-[:PARTICIPATES_GpPW]-(n3)-[:ASSOCIATES_DaG]-(n4:Disease)
USING JOIN ON n2
WHERE n0.name = 'Bupropion'
AND n4.name = 'nicotine dependence'
AND n1 <> n3
WITH
[
size((n0)-[:BINDS_CbG]-()),
size(()-[:BINDS_CbG]-(n1)),
size((n1)-[:PARTICIPATES_GpPW]-()),
size(()-[:PARTICIPATES_GpPW]-(n2)),
size((n2)-[:PARTICIPATES_GpPW]-()),
size(()-[:PARTICIPATES_GpPW]-(n3)),
size((n3)-[:ASSOCIATES_DaG]-()),
size(()-[:ASSOCIATES_DaG]-(n4))
] AS degrees, path
RETURN
path,
reduce(pdp = 1.0, d in degrees| pdp * d ^ -0.4) AS path_weight
ORDER BY path_weight DESC
LIMIT 10Cypher query to find the top CbGbPWaD paths
Try at https://neo4j.het.io
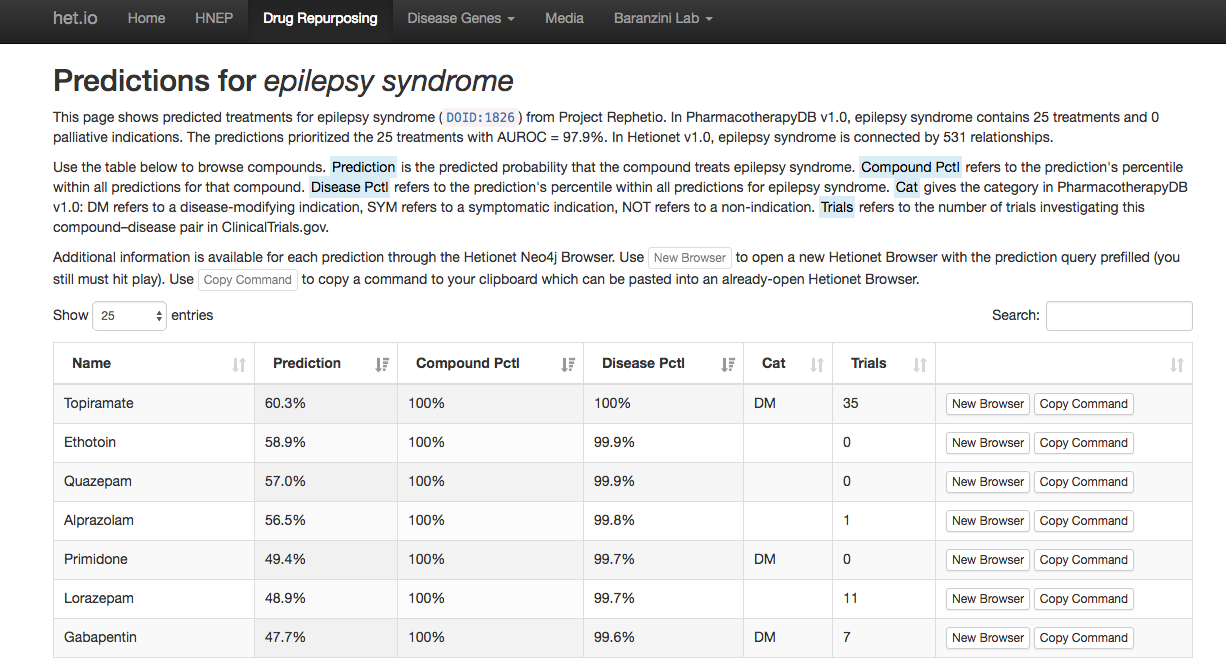
Browse all predictions at het.io/repurpose. Discuss at thinklab.com/d/224
Discuss at thinklab.com/d/224#5
Discuss at thinklab.com/d/230#14
Nice of you to share this big network with everyone; however, I think you need to take care not to get yourself into legal trouble here. …
I am not trying to cause trouble here — just the contrary. When making a meta-resource, licenses and copyright law are not something you can afford to ignore. I regularly leave out certain data sources from my resources for legal reasons.
One network to rule them all
We have completed an initial version of our network. …
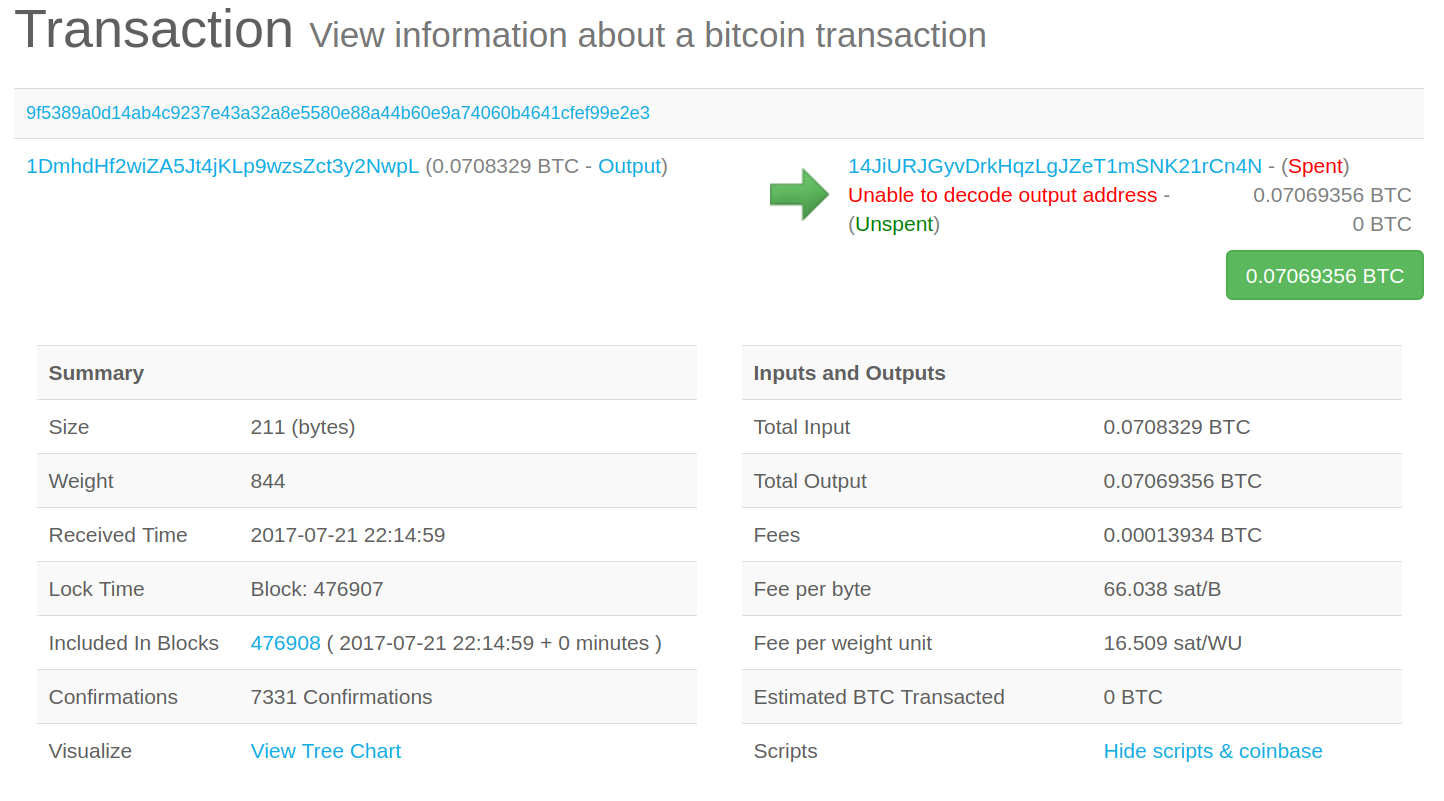
Network existence (SHA256 checksum for graph.json.gz) is proven in Bitcoin block 369,898.
Recommendations:
Kyle Kloster
@kkloste
Michael Zietz
@zietzm
https://github.com/greenelab/hetmech
the hetnet search engine
https://zietzm.github.io/Vagelos2017/
days to seconds
https://github.com/greenelab/snorkeling
David Robinson
@danich1
powering the next generation of scholarly manuscript
The Manubot project began with the [Deep Review](https://github.com/greenelab/deep-review),
where it was used to compose a highly-collaborative review article [@doi:10.1101/142760].
Other manuscripts that were created with Manubot include:
+ The Sci-Hub Coverage Study
([GitHub](https://github.com/greenelab/scihub-manuscript), [HTML manuscript](https://greenelab.github.io/scihub-manuscript/))
[@doi:10.7287/peerj.preprints.3100]
+ Michael Zietz's Report for the Vagelos Scholars Program
([GitHub](https://github.com/zietzm/Vagelos2017), [HTML manuscript](https://zietzm.github.io/Vagelos2017/))
[@doi:10.6084/m9.figshare.5346577]
The Manubot project began with the Deep Review, where it was used to compose a highly-collaborative review article [1]. Other manuscripts that were created with Manubot include:
1. Opportunities And Obstacles For Deep Learning In Biology And Medicine
Travers Ching, Daniel S. Himmelstein, Brett K. Beaulieu-Jones, Alexandr A. Kalinin, Brian T. Do, Gregory P. Way, Enrico Ferrero, Paul-Michael Agapow, Wei Xie, Gail L. Rosen, … Casey S. Greene
Cold Spring Harbor Laboratory (2017-05-28) https://doi.org/10.1101/142760
2. Sci-Hub provides access to nearly all scholarly literature
Daniel S Himmelstein, Ariel R Romero, Stephen R McLaughlin, Bastian Greshake Tzovaras, Casey S Greene
PeerJ Preprints (2017-07-20) https://doi.org/10.7287/peerj.preprints.3100
3. Vagelos Report Summer 2017
Michael Zietz
Figshare (2017) https://doi.org/10.6084/m9.figshare.5346577
Write markdown
Automatically converted to rich text
Automatic bibliographic metadata
[@doi:10.7287/peerj.preprints.3100][@arxiv:1407.3561v1]
[@pmid:24159271]
[@url:http://blog.dhimmel.com/biorxiv-licenses/]1. Modify the manuscript source
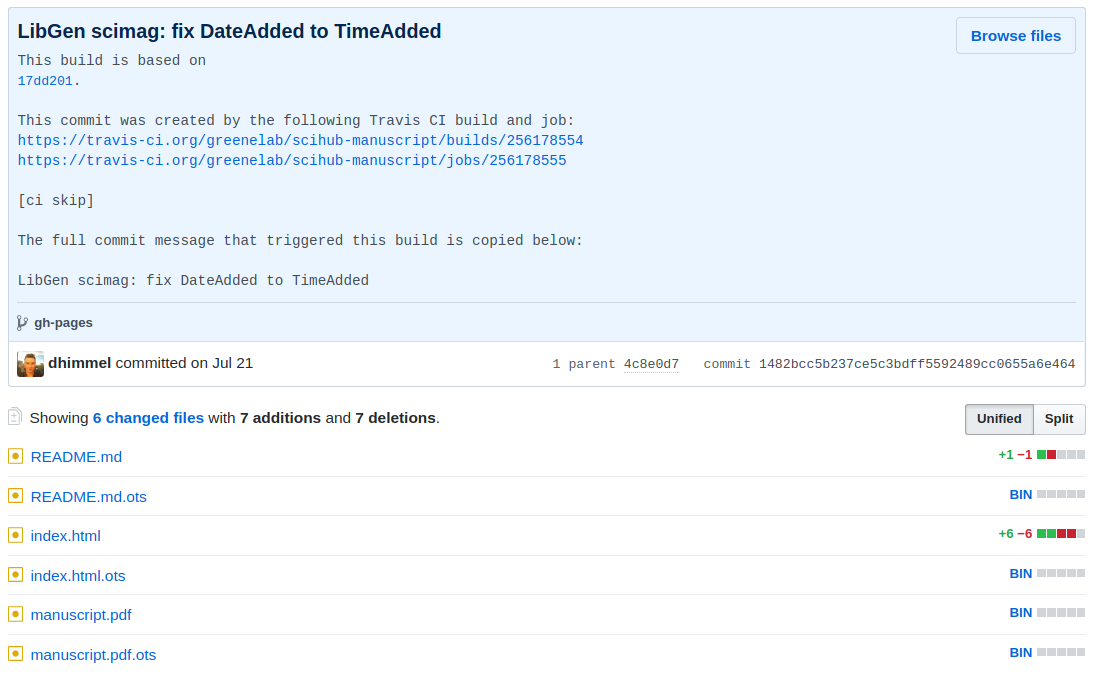
2. Continuous integration rebuilds the manuscript
Timestamped on the Bitcoin blockchain via OpenTimestamps
3. Continuous deployment back to GitHub
https://greenelab.github.io/deep-review/
Pull requests for manuscript collaboration
Get started at tiny.cc/manubot
https://github.com/greenelab/manubot-rootstock
@dhimmel
0000-0002-3012-7446
#EDGE18
https://slides.com/dhimmel/edge
https://lighterpack.com/r/e6zymv
By Daniel Himmelstein
Presentation on 2018-02-08 at EDGE 2018 (http://edge2018.cloudaccess.hosthttp://edge2018.cloudaccess.hosthttp://edge2018.cloudaccess.host This presentation is released under a CC BY 4.0 License.



