



Daniel Himmelstein
Head of Data Integration at Related Sciences. Digital craftsman of the biodata revolution.
slides released under CC BY 4.0
slides.com/dhimmel/efo-disease-precision
Prepared at nxontology-ml/issues/13
NetworkX-based Python library for representing ontologies. Uses fastobo, pronto, pygraphviz.
Posted to the obo-community slack by Philip Strömert generated with Midjourney prompt:
We cannot interpret our research data anymore because we did not annotate it with ontologies
Really easy access to popular biomedical ontologies based on JSON files that can be read into Python's networkx.
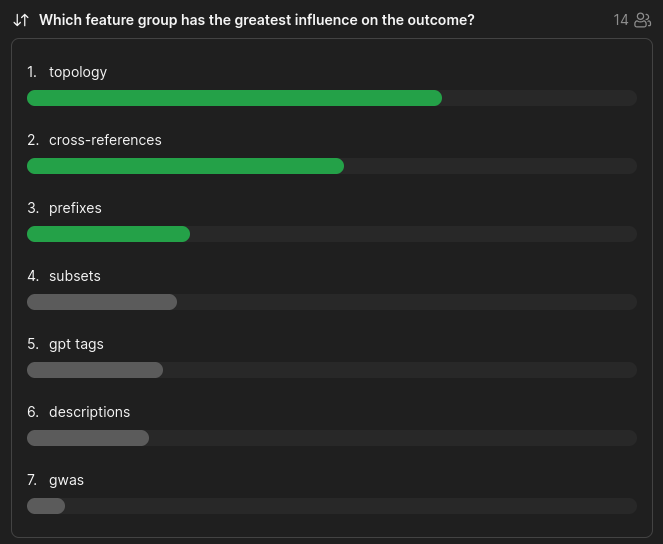
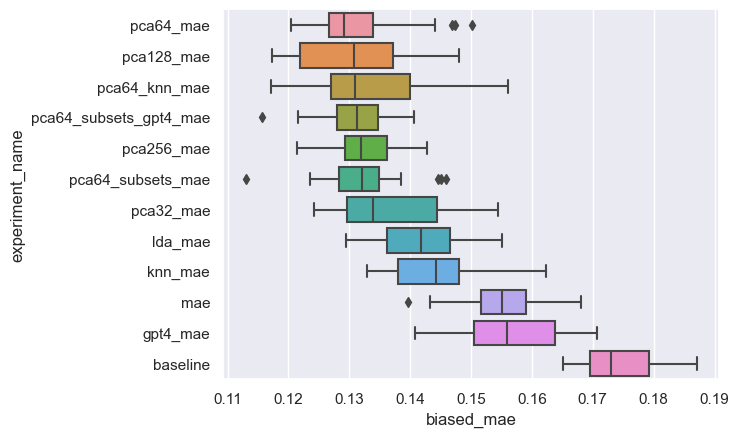
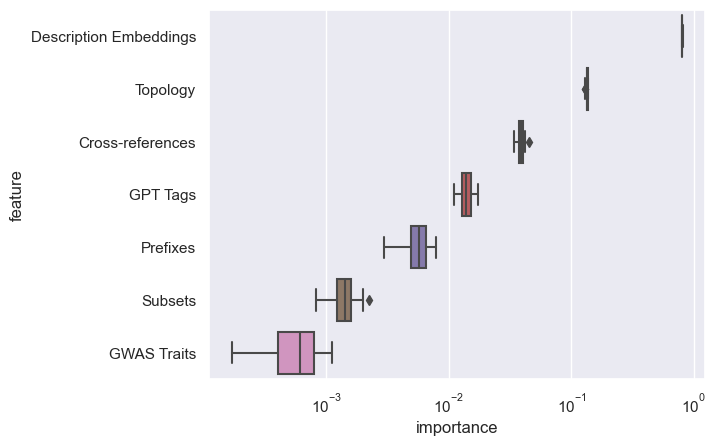
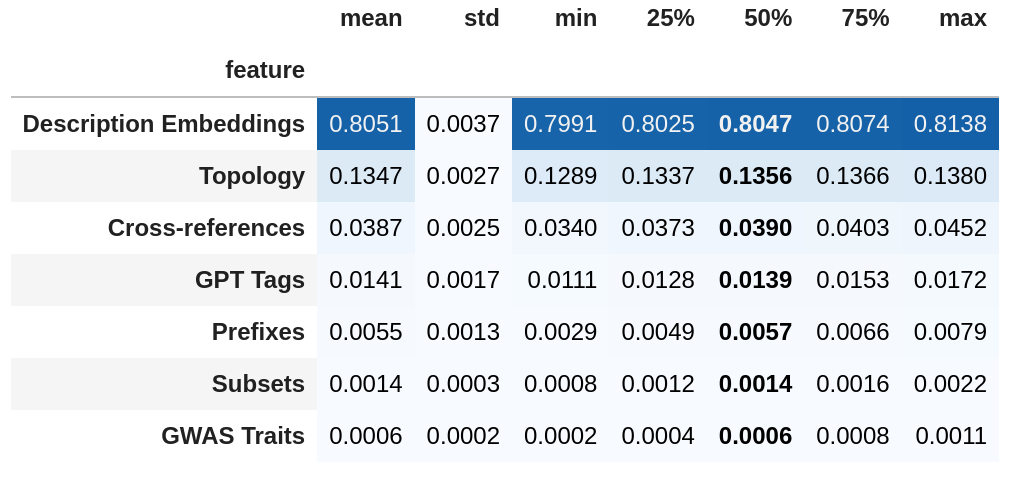
feature groups:
derived solely from the topology of the directed acyclic graph
cross-references (xref) counts by external database.
nxontology-data performs bioregistry normalization of xref prefixes
EFO includes terms imported from other ontologies.
Counts from EFO Otar Slim v3.57.0
from collections import Counter
from nxontology import NXOntology
url = "https://github.com/related-sciences/nxontology-data/raw/2ce01d8495024d46cbc54fb0c26a92500ad717e0/efo_otar_slim.json"
nxo = NXOntology.read_node_link_json(url)
prefix_counts = Counter()
for node in nxo.graph.nodes:
prefix, _ = node.split(":")
prefix_counts[prefix] += 1
for prefix, count in prefix_counts.most_common():
print(f"{prefix}: {count:,}")
EFO includes subsets, many imported from MONDO. We're not actually sure how to find documentation for these subsets, but they sound relevant.
EFO notes whether a term is a GWAS trait.
Large "Embedding" Vector (768 demensions)
EFO Node description (term name & definition)
Compressed "Embedding" Vector (64 dimensions)
Transformer Model ("BioLinkBERT")
Dimensionality reduction (e.g. PCA, LDA)
MONDO:0005301 🡒 multiple sclerosis: A progressive autoimmune disorder affecting the central nervous system resulting in demyelination. Patients develop physical and cognitive impairments that correspond with the affected nerve fibers. [ NCIT : P378 ]
A list of records will be provided from an ontology of disease terms. Each record will contain information describing a single term.
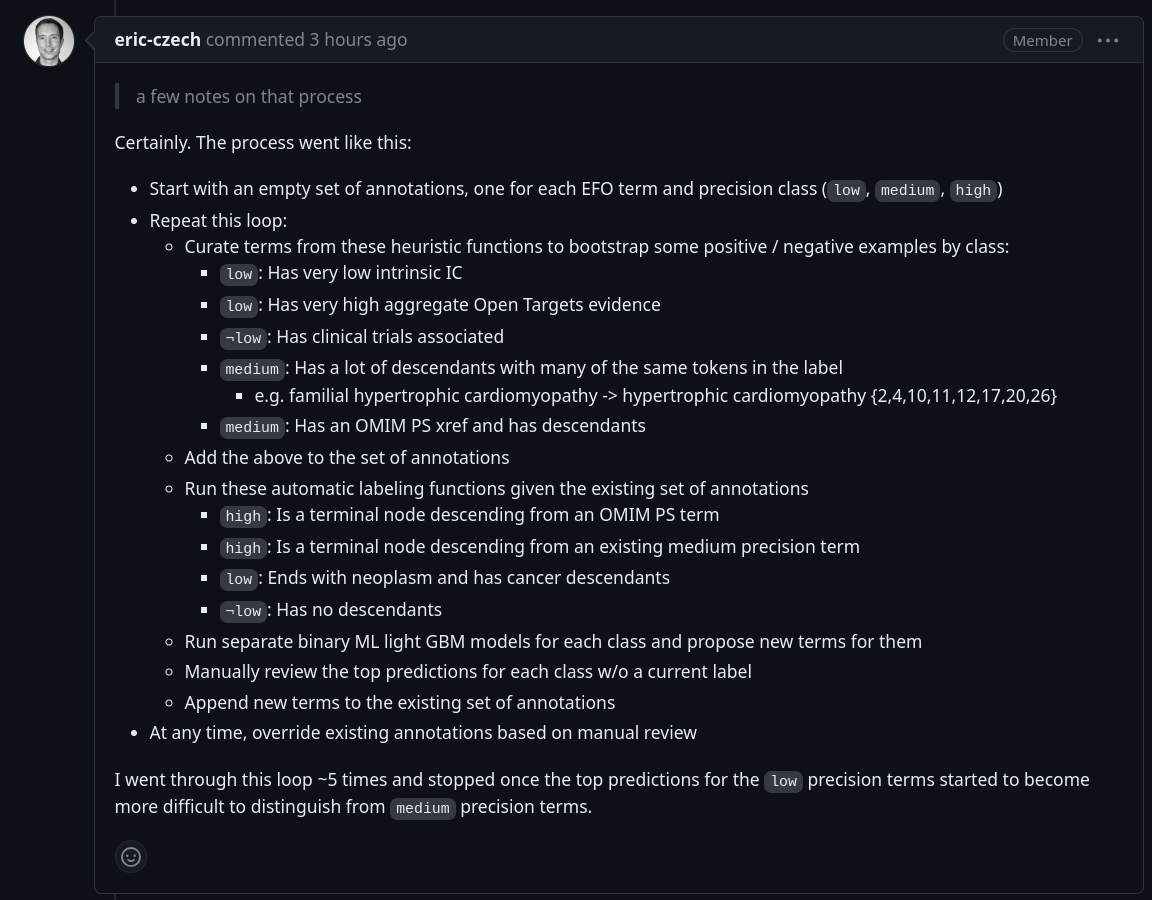
Assign a `precision` label to each of these terms that captures the extent to which they correspond to patient populations with distinguishing clinical, demographic, physiological or molecular characteristics. Use exactly one of the following values for this label:
- `high`: High precision terms have the greatest ontological specificity, sometimes (but not necessarily) correspond to small groups of relatively homogeneous patients, often have greater diagnostic certainty and typically represent the forefront of clinical practice.
- `medium`: Medium precision terms are the ontological ancestors of `high` precision terms (if any are known), often include indications in later stage clinical trials and generally reflect groups of patients assumed to be suffering from a condition with a shared, or at least similar, physiological or environmental origin.
- `low`: Low precision terms are the ontological ancestors of both `medium` and `high` precision terms, group collections of diseases with *some* shared characteristics and typically connote a relatively heterogenous patient population. They are often terms used within the ontology for organizational purposes.
The records provided will already have the following fields:
- `id`: A string identifier for the term
- `label`: A descriptive name for the term
- `description`: A longer, possibly truncated description of what the term is; may be NA (i.e. absent)
Here is a list of such records (in YAML format) where the `precision` label is already assigned for 3 examples at each level of precision:
Examples:
Which feature group has the greatest influence on the outcome?
Slido: 1342 945
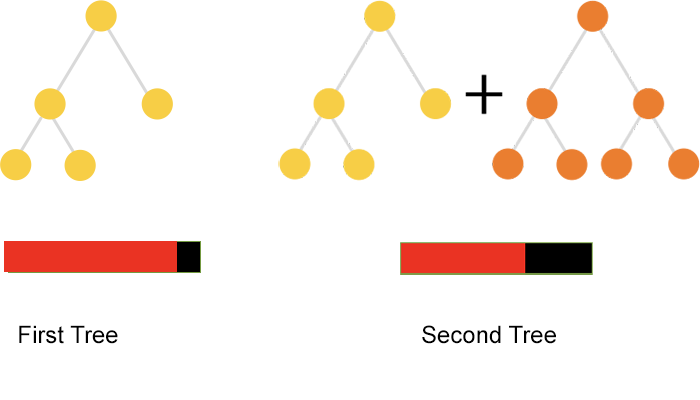
Source: https://catboost.ai/news/catboost-enables-fast-gradient-boosting-on-decision-trees-using-gpus
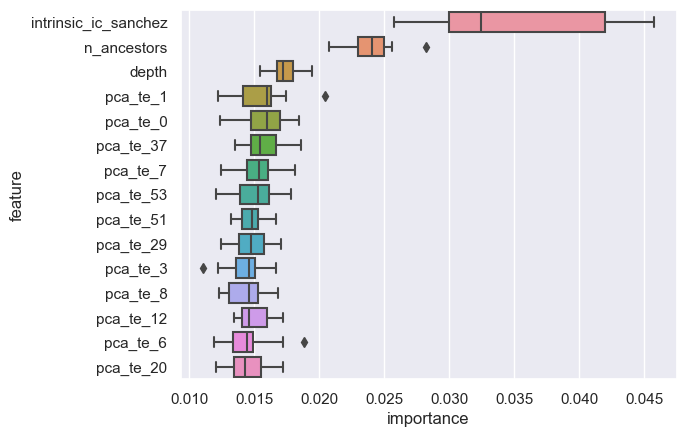
intrinsic_ic_sanchez source
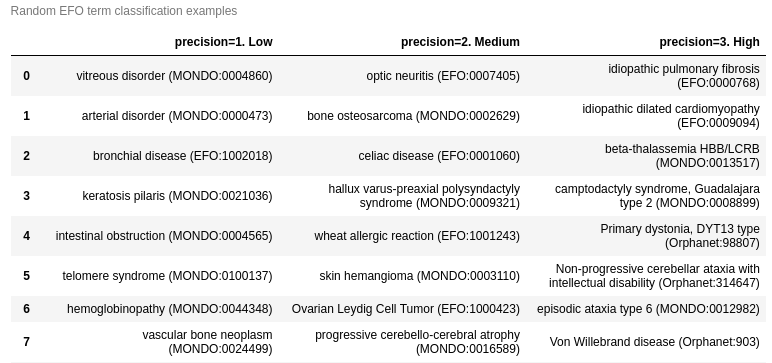
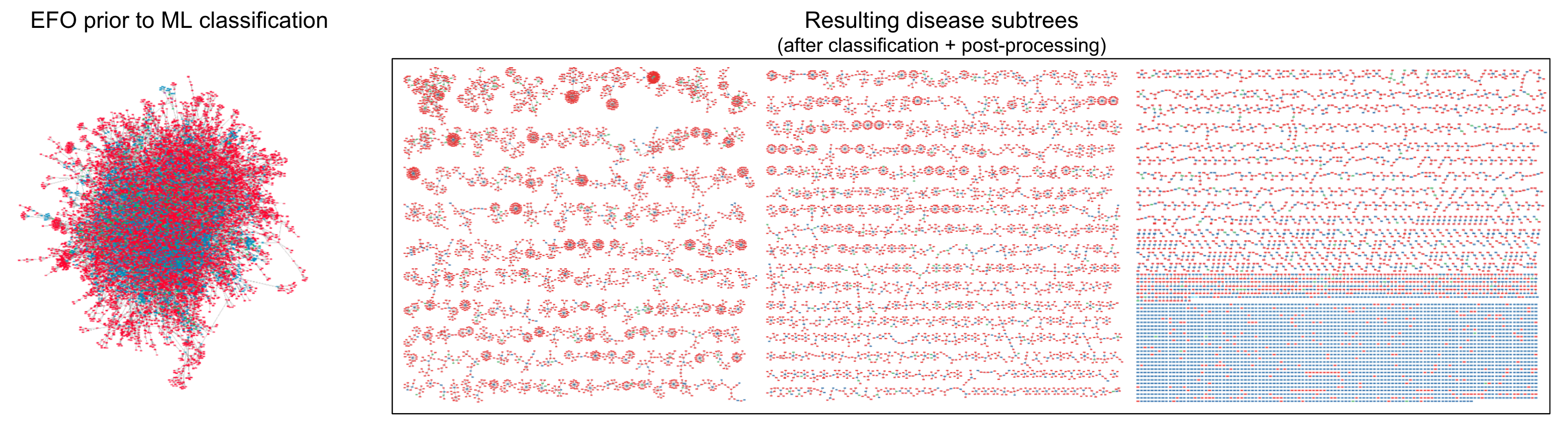
Visualization: precision by border
By Daniel Himmelstein




