

























































Danielle Navarro
I am a computational cognitive scientist at the University of New South Wales. My research focuses on human concept learning, reasoning and decision making.
13 July 2018, useR! conference, Brisbane
slides.com/djnavarro/user2018
(Part 1)
(Part 2)
(Part 3)
compcogscisydney.org/learning-statistics-with-r/
Frequentist statistics
Bayesian statistics
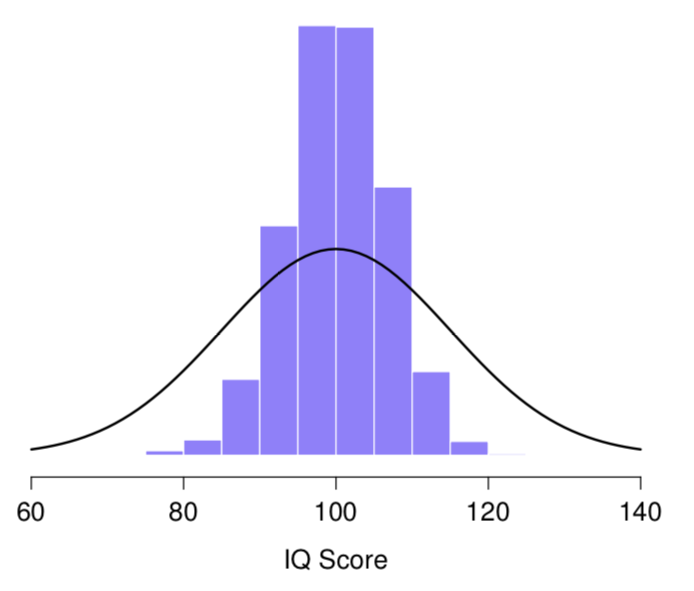
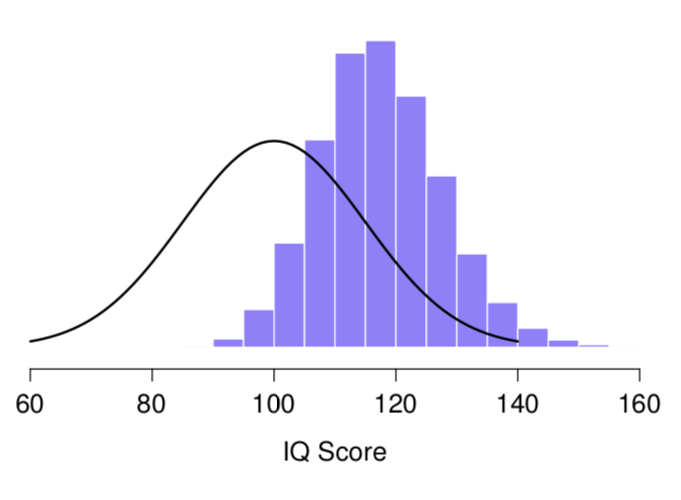
We teach the sampling distribution of the mean
...but we don't talk about sampling distributions in any other context
Sampling distribution for the maximum of 5 measurements?
Easy to simulate, if you have the tools!
* I wasn't at UNSW at the time, but I've heard these sentiments from all over
it's 2010?
A lot of my students are priced out
my_data <- attach(iris)
I attached the data, and it doesn't work...
... ah, right. I can't reasonably expect to take a text written for a different audience and think it will work in my class.
http://compcogscisydney.org/
learning-statistics-with-r/
I tried to address student fears
I aimed for a relaxed style
I covered the usual topics for psych methods
Extended to cover Bayesian and orthodox
I tried to show complexity where I could
I discussed some of R's quirks
I covered basic data visualisation
I covered basic programming
I even touched on regular expressions for some reason
... I may have gone a little overboard
Well, it certainly helped me
The students?
The book has limitations
Also this...
"An introductory textbook, well-written though it is, does not constitute a scholarly work"
http://compcogscisydney.org/
learning-statistics-with-r/
compcogscisydney.org/projects/
Photo by Tachina Lee on Unsplash
Sharks have plaxium blood
Seagulls do not
Training set:
Test set:
Rather a lot of methodological details here
Sharks have plaxium blood
Seagulls do not
Training set:
model {
# mean and covariance matrix defining the Gaussian process
for(i in 1:ncat) {
mean_gp[i] <- m
cov_gp[i,i] <- (sigma^2) + (tau^2)
for(j in (i+1):ncat) {
cov_gp[i,j] <- (tau^2) * exp(-rho * (test[i] - test[j])^2)
cov_gp[j,i] <- cov_gp[i,j]
}
}
# sample a function from the Gaussian process
cov_gp_inv <- inverse(cov_gp)
f ~ dmnorm(mean_gp, cov_gp_inv)
# pass f through logit function to get a function on [0,1]
for(i in 1:ncat) {
phi[i] <- 1/(1+exp(-f[i]))
}
#
# [SNIP]
#
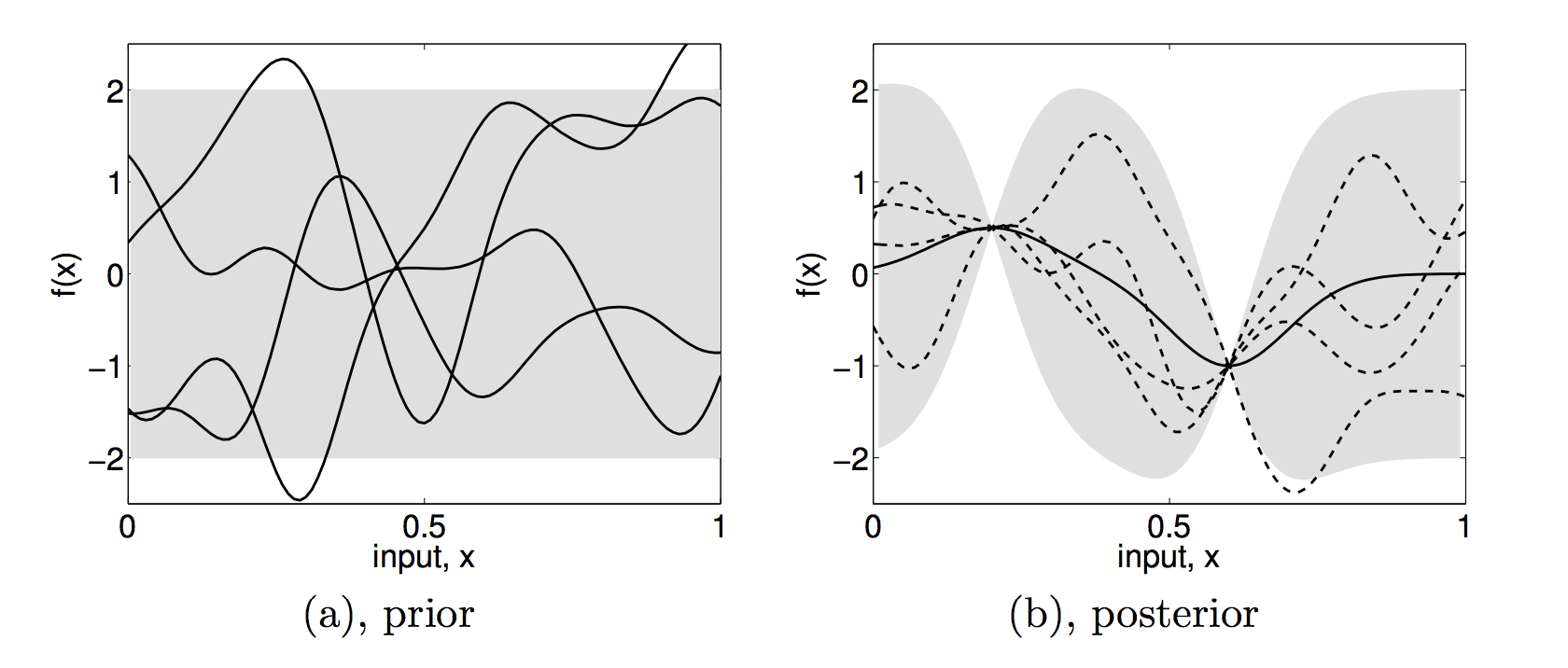
}Gaussian process prior
Classification function
Data
Gaussian process prior
Classification function
Data
Learning and classification and are viewed as an inverse probability problem ... i.e. Bayesian reasoning
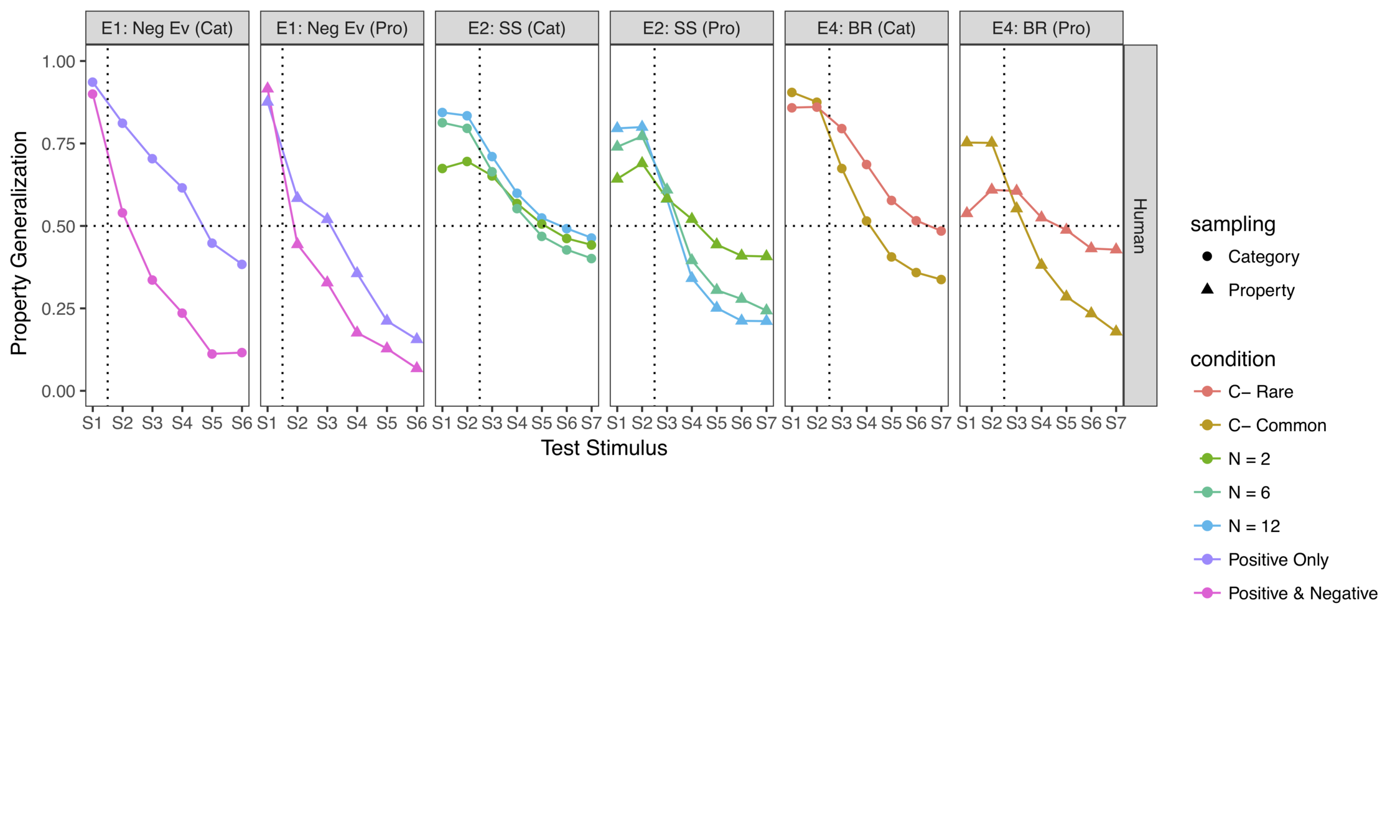
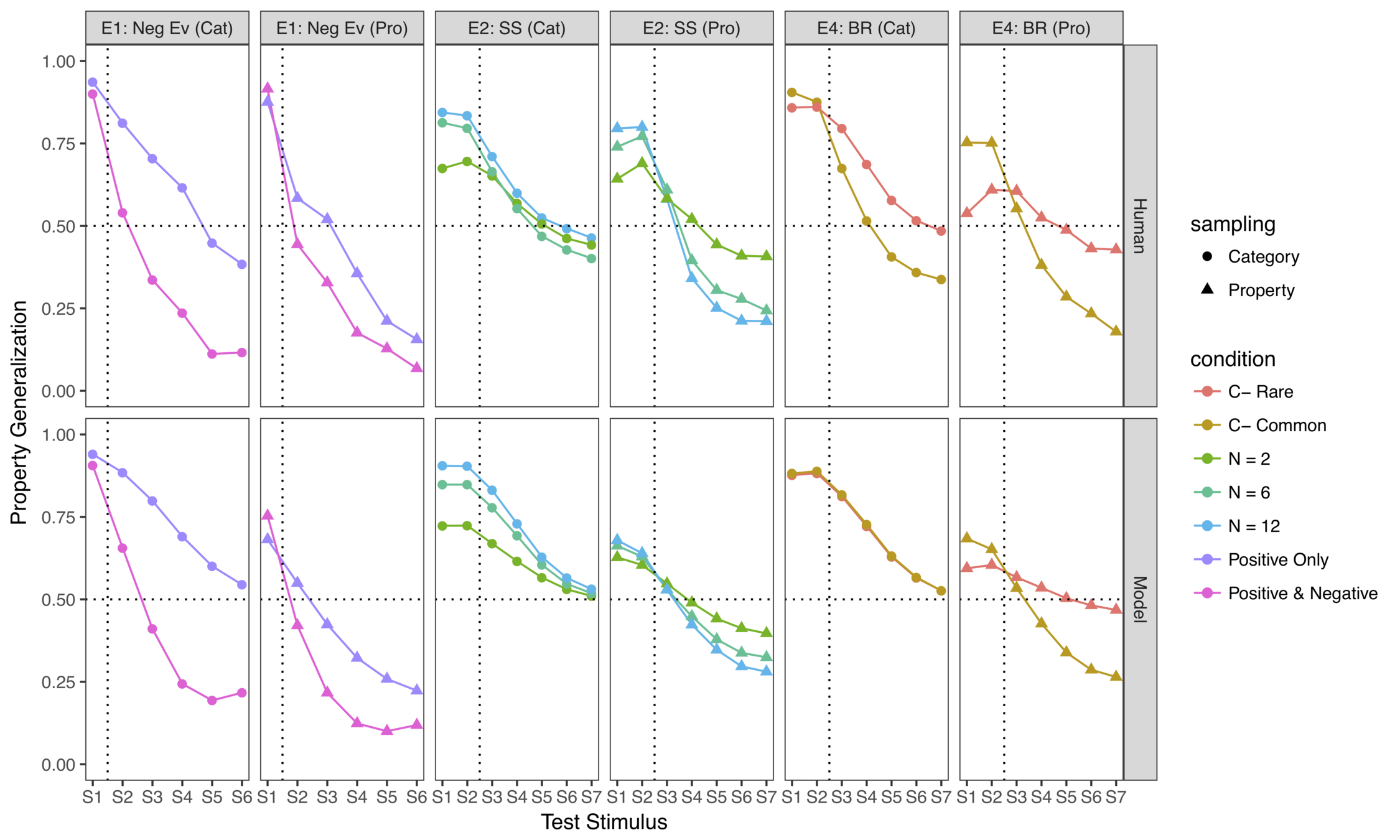
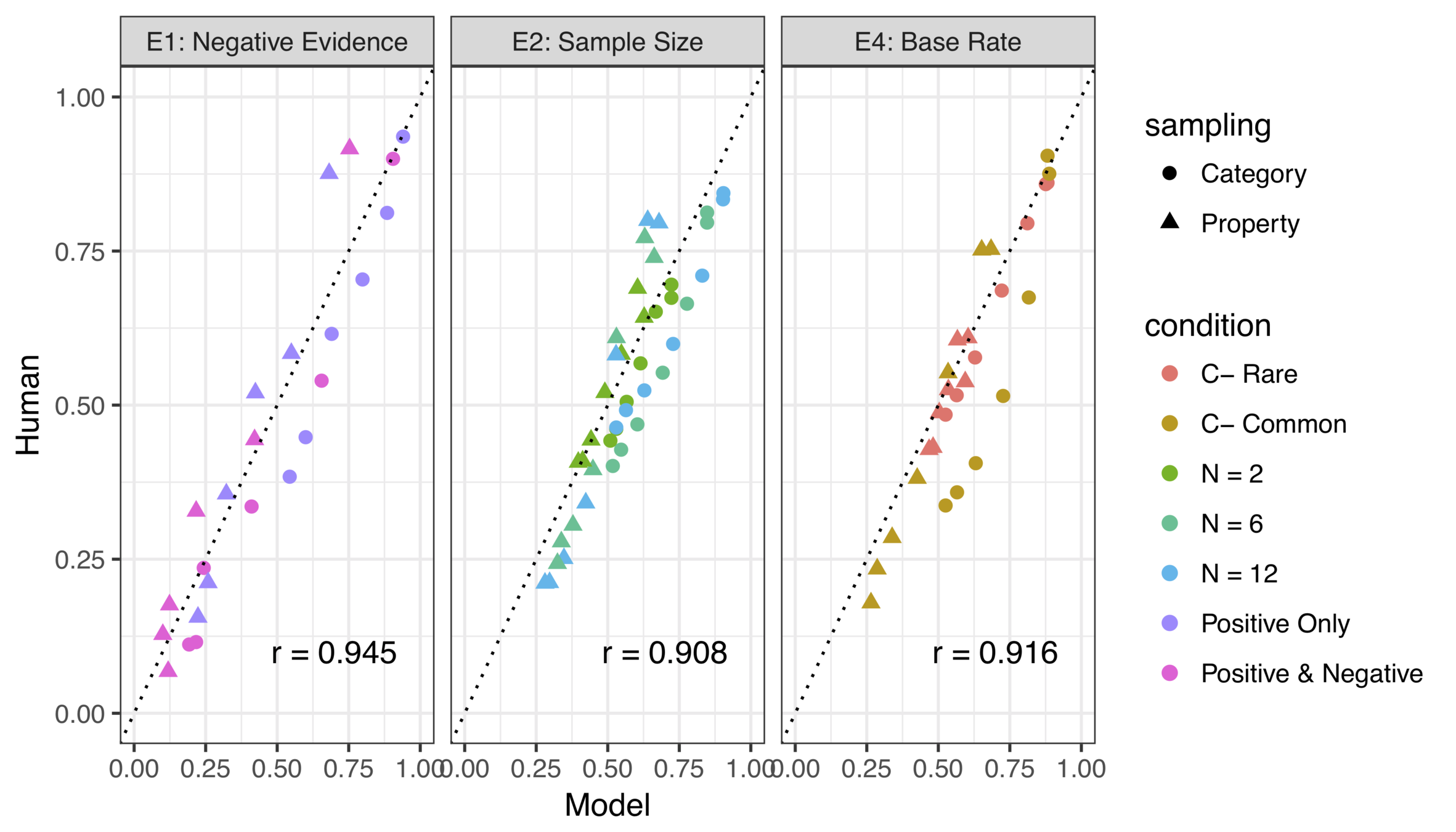
Some experiments...
... and some model fits
(there's a modest amount of parameter tuning required to get quantitative fits but the ordinal effects are invariant)
It works surprisingly well
The usual things...
The less usual...
image source: flaticon
M1
M2
M3
M4
lose $5
win $2
lose $1
lose $1
win $2
lose $3
I've not used these machines recently, and someone else has taken them
I've concentrated recent bets on these machines
win $2
lose $5
1
2
3
4
5
6
7
8
chosen
viable option not chosen
someone takes the machine
someone takes the machine
Expected reward for option \(j\) on this trial
Uncertainty about reward for option \(j\) on this trial
Expected reward for option \(j\) on last trial
Uncertainty about reward for option \(j\) on last trial
Uncertainty drives Kalman gain
Kalman gain influences beliefs about expected reward and uncertainty
# Update the expected utility of the arm by applying a Kalman
# filtering update rule. The model here does not learn any underlying
# trend for the arm, nor does it learn the volatility of the environment
mod$utilityUpdate <- function(current, chosen, gain, outcome) {
current + chosen * gain * (outcome - current)
}
# Compute the Kalman gain
mod$kalmanGain <- function(uncertainty, mod) {
(uncertainty + mod$param["sigma_xi"]^2) /
(uncertainty + mod$param["sigma_xi"]^2 + mod$param["sigma_eps"]^2)
}
# Update the posterior uncertainty associated with the arm, again
# using the Kalman rule
mod$uncertaintyUpdate <- function(current, chosen, gain, mod) {
(1 - chosen * gain) * (current + mod$param["sigma_xi"]^2)
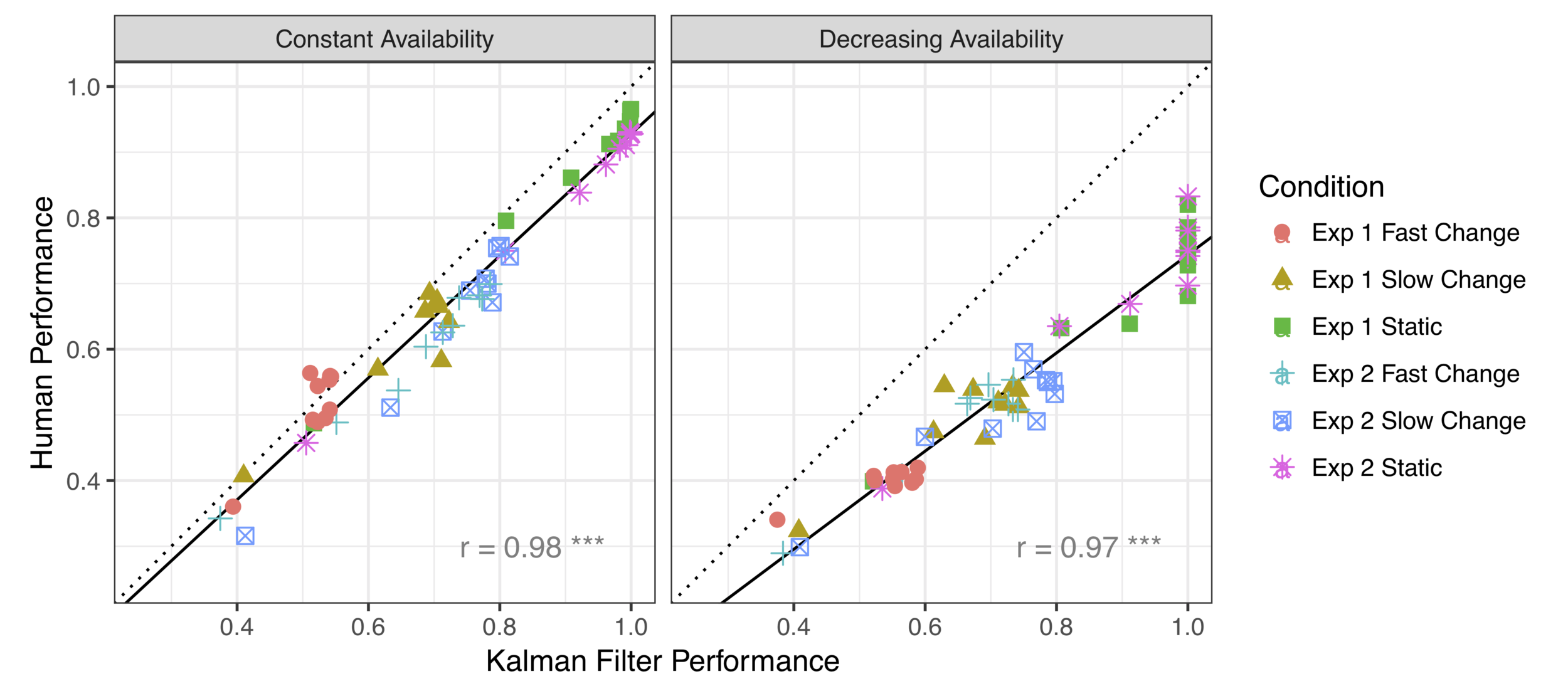
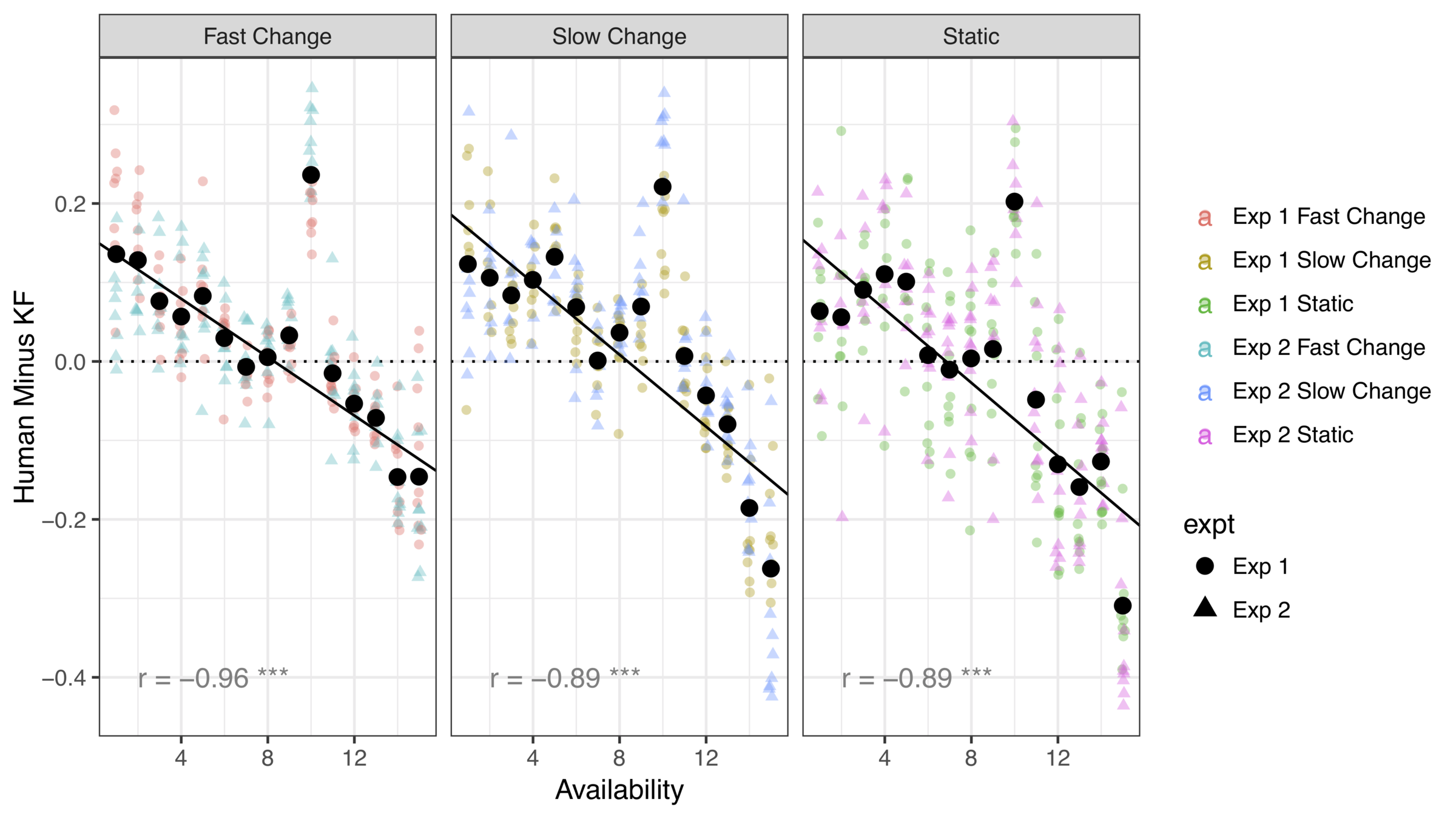
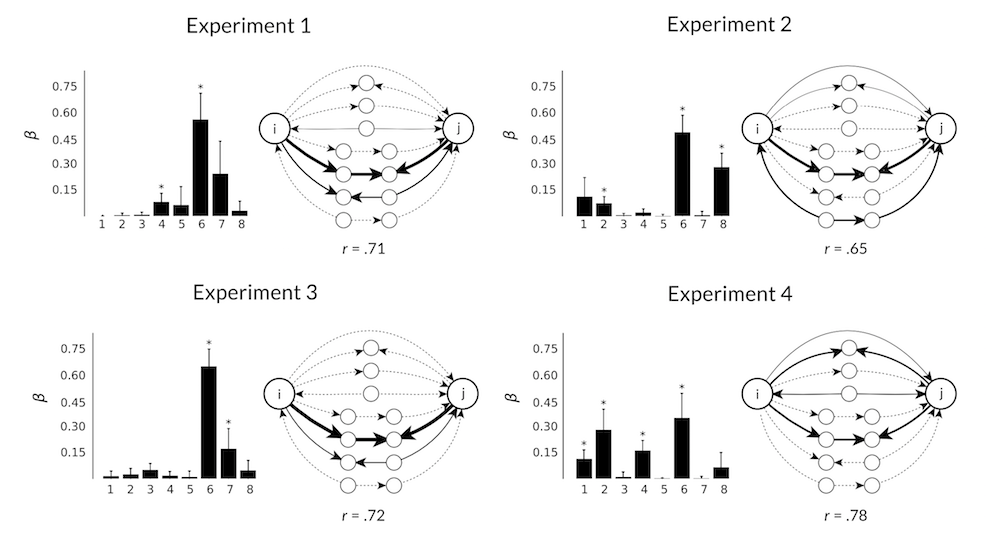
}In the standard reinforcement learning task, human behaviour is closely approximated by the Kalman filter model
When the threat of option loss is added, systematic differences appear
(* Yes, there's a data point missing. I'm hiding something)
The usual...
The others...
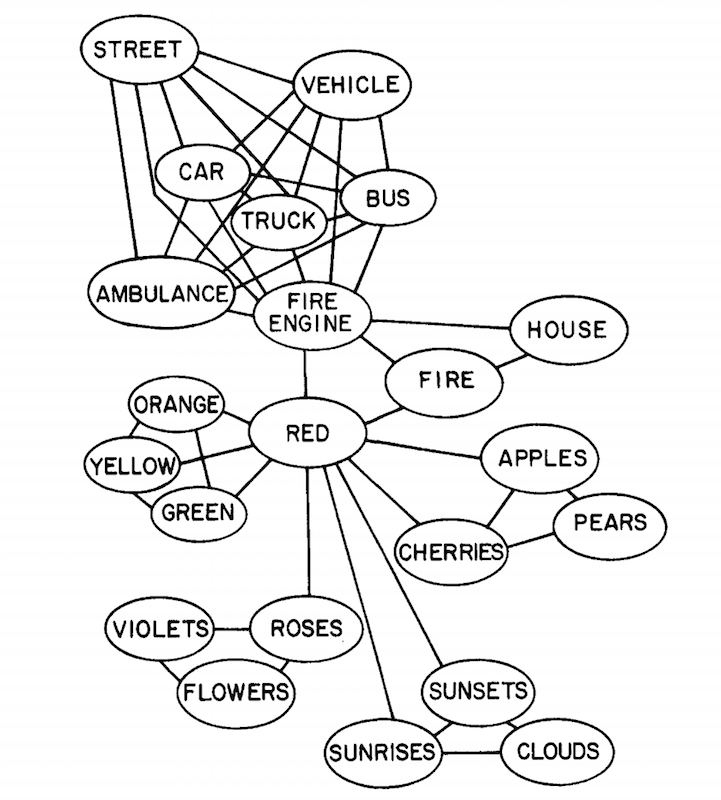
smallworldofwords.org
(cue)
(response)
https://smallworldofwords.org/en/project/visualize
(Collins & Loftus 1975)
similarity(rose, car)
similarity(cloud, house)
>
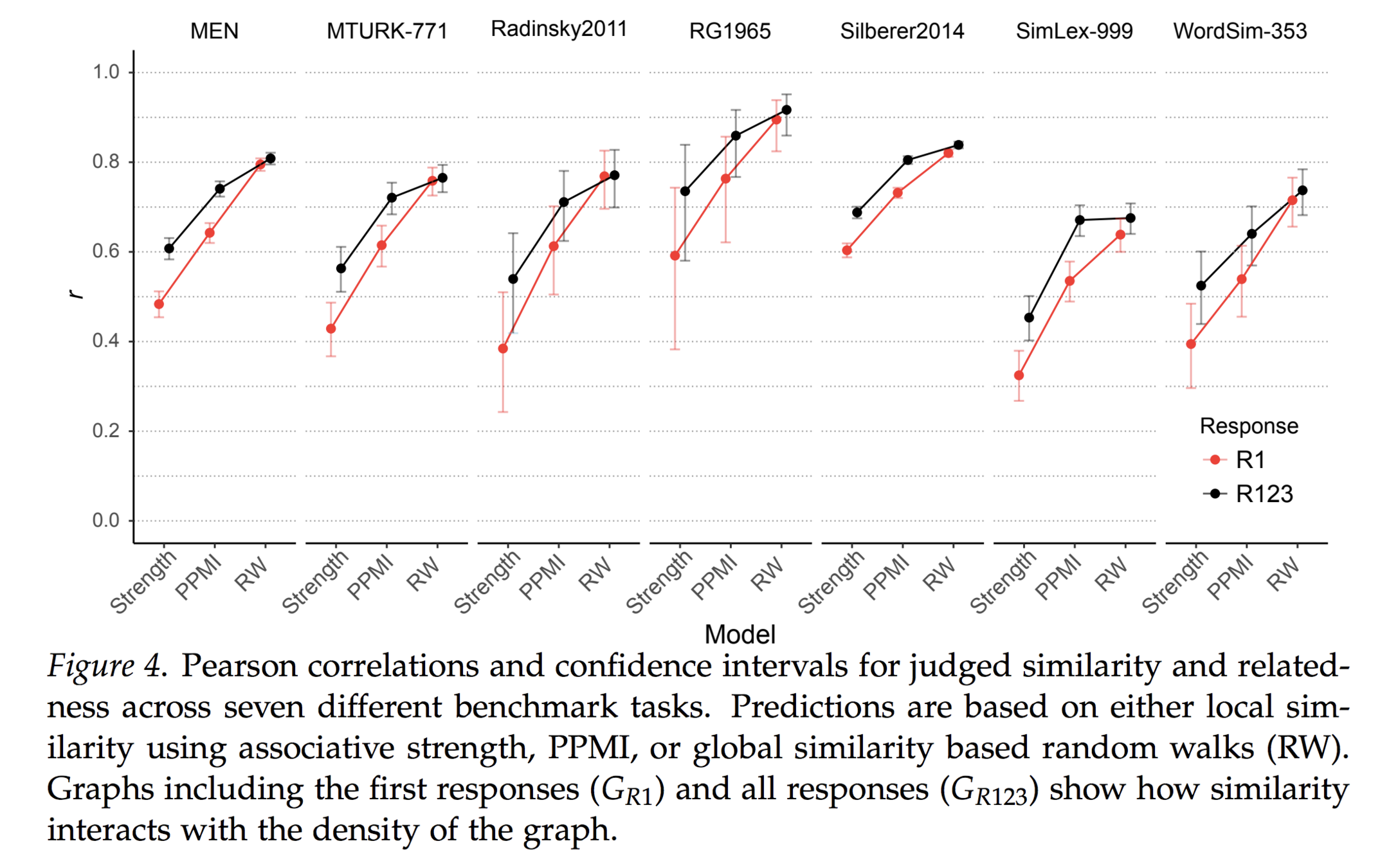
Useful at the margins
My skill limitations?
A cognitive psychologist with some experience with R
A grumpy psychometrician with a limited time budget
A social psychologist who wants to believe
Hello? Was it something I said?
Photo by Sven Scheuermeier on Unsplash
Act I
Act II
Hey, how would you feel about posting research code to the web?
Oh hell no. People would call me stupid
What? You literally wrote a textbook on latent variable modelling and your Ph.D. research won a best paper award at Multivariate Behavior Research. You are not stupid
Yeah but my code has to be written in 20 minute consults and it's ugly. People are unkind about code
https://quoteinvestigator.com/2010/06/29/be-kind/
base R
tidyverse
jsPsych
Matlab
JASP
BayesFactor
.Rmd
SQL
lme
JAGS
Stan
base R
tidyverse
jsPsych
Matlab
JASP
BayesFactor
.Rmd
SQL
lme
JAGS
Stan
Even after 2.5 years at UNSW, integration of tools across different contexts is modest
Model selection via MDL principle, imposing a complexity penalty similar to a Bayesian approach with Jeffreys priors
You should use AIC
Hypothesis testing used a priori mapping of theoretically meaningful patterns onto order constrained inference problems
You need to run an ANOVA to test for interactions
We used package A
Everybody knows that package B is better
(seriously, you are terrible at sales)
tidyverse
lme
git
BayesFactor
lavaan
car
Shiny
R markdown
knowing all the R
It can be hard to find a team within a single applied field...
#rstats
But there are people who will support you
Yay!
By Danielle Navarro
Traditionally, R has been viewed as a language for data science and statistics. In the social sciences it has been extremely popular with researchers at the more quantitative end of the spectrum - but uptake has been less widespread outside of the more statistically inclined. I don't think the R language needs to be limited in this way. Since 2011 I've been teaching introductory research methods classes for undergraduates using R, running programming classes for R with postgraduate students, doing my own data analysis with R, implementing cognitive models with R and occasionally even running behavioural experiments in R. In this talk I reflect on some of these experiences - the good, the bad and the ugly - and discuss prospects and challenges for wider adoption R as a tool within the psychological sciences.




