Presented by: Elaheh Barati
elaheh@wayne.edu
Wayne State University
Multi-view CNN (MVCNN) for shape recognition
Hang Su, Subhransu, Maji Evangelos, Kalogerakis Erik, Learned-Miller
University of Massachusetts, Amherst
"Multi-view Convolutional Neural Networks for 3D shape Recognition"
"Proceedings of the IEEE international conference on computer vision pp. 945-953. 2015."
3D shapes can be represented with:
- descriptors operating on 3D formats
- view-based descriptors
3D shapes can be represented with:
- descriptors operating on 3D formats
- view-based descriptors
Recognizing 3D shapes from a collection of their rendered views on 2D images
2D representations
3D representations

3D representation:
- Contains all of the information about an object
- In order to use a voxel-based representation in a deep network, the resolution needs to be significantly reduced.
-
For example:
- 3D ShapeNets use a coarse representation of shape, a 30×30×30 grid of binary voxels.
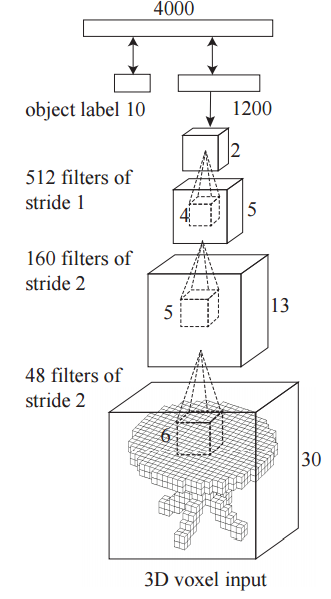
[1] Wu, Zhirong, Shuran Song, Aditya Khosla, Fisher Yu, Linguang Zhang, Xiaoou Tang, and Jianxiong Xiao. "3d shapenets: A deep representation for volumetric shapes." In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1912-1920. 2015.
[1]
2D representation:
- A single projection of the 3D model of the same input size corresponds to an image of 164×164 pixels, or slightly smaller if multiple projections are used.
- Contains all of the information about an object
- In order to use a voxel-based representation in a deep network, the resolution needs to be significantly reduced.
-
For example:
- 3D ShapeNets use a coarse representation of shape, a 30×30×30 grid of binary voxels.
Trade-off

Increasing the amount of explicit depth information (3D models)
Increasing spatial resolution
(projected 2D models)

2D 3D
using 2D representations:
- Leverage advances in image descriptors
- Use massive image databases (ImageNet) to pre-train CNN architectures
2D 3D
Learn a good deal about generic features for 2D image categorization
Fine-tune to specifics about 3D model projections
This paper presents:
- Classifying views independently
- Using existing 2D image features directly and producing a descriptor for each view
- It works remarkably well
- Generating compact object descriptors
- using multi-view CNN
Multi-view CNN
- Informative for classification and retrieval
- Facilitates efficient retrieval using either a similar 3D object or a simple hand-drawn sketch
- State-of-the-art results on:
- 3D object classification
- 3D object retrieval using 3D objects
- 3D object retrieval using sketches
- Sketch classification
View-based descriptors for 3D shapes:
- Trainable
- Produce informative representations for recognition and retrieval tasks
- Efficient to compute

Multi-view Representation
Give an Input 3D Object
Multi-view Representation
Generating multi-views of the 3D object by
rendering engine

Multi-view Representation
Generating multi-views of the 3D object by
rendering engine

Multi-view Representation
Generating multi-views of the 3D object by
rendering engine
view 1
view 2
view 3
view N
Approaches to using multiple views
Average the individual descriptors
treating all the views as equally important
Generate a 2D image descriptor per each view
Use the individual descriptors directly for recognition tasks based on some voting or alignment scheme
Concatenate the 2D descriptors of all the views.
Method 1:
Approaches to using multiple views
An aggregated representation combining features from multiple views
Method 2:
Approaches to using multiple views
Combine information from multiple views using a unified CNN architecture that includes a view-pooling layer
Method 2:
An aggregated representation combining features from multiple views
Multi-view Representation

Multi-view Representation (Input Generation)
- 3D models in online databases are stored as polygon meshes:
- collections of points connected with edges forming faces
- Generate rendered views of polygon meshes using the Phong reflection model
[1] B. T. Phong. Illumination for computer generated pictures. Commun. ACM, 18(6), 1975.
[1]
Multi-view Representation (Input Generation)
Phong reflection model
- Approximate surface color as sum of three components:
- an ideal diffuse component
- a glossy/blurred specular component
- an ambient term
- The mesh polygons are rendered under a perspective projection
- The pixel color is determined by interpolating the reflected intensity of the polygon vertices
- Shapes are uniformly scaled to fit into the viewing volume
Multi-view Representation (Input Generation)
Setup viewpoints (virtual cameras) for rendering each mesh:
1st camera setup
-
Assumption:
- The input shapes are upright oriented along a consistent axis (e.g., z-axis).
- Create 12 rendered views by placing 12 virtual cameras around the mesh every 30 degrees
- The cameras are elevated 30 degrees from the ground plane, pointing towards the centroid of the mesh
- The centroid is calculated as the weighted average of the mesh face centers, where the weights are the face areas
Multi-view Representation (Input Generation)
Setup viewpoints (virtual cameras) for rendering each mesh:
2nd camera setup
- Render from several more viewpoints
- The renderings are generated by placing 20 virtual cameras at the 20 vertices of an icosahedron enclosing the shape.
- All cameras point towards the centroid of the mesh.
- Generate 4 rendered views from each camera, using 0, 90, 180, 270 degrees rotation along the axis passing through the camera and the object centroid, yielding total 80 views.
Multi-view Representation (Recognition)
The most straightforward approach to utilizing the multi-view representation:
- Using existing 2D image features directly
- Produce a descriptor for each view
It results in multiple 2D image descriptors per 3D shape, one per view
Need to be integrated for recognition tasks
Two Types of Image Descriptors:
- image descriptor based on Fisher vectors with multiscale SIFT
- CNN activation features
Multi-view Representation (Recognition)
[1]
[2]
[1] J. Sanchez, F. Perronnin, T. Mensink, and J. Verbeek. Image classification with the Fisher vector: Theory and practice. 2013.
[2] J. Donahue, Y. Jia, O. Vinyals, J. Hoffman, N. Zhang, E. Tzeng, and T. Darrell. DeCAF: A deep convolutional activation feature for generic visual recognition. CoRR, abs/1310.1531, 2013.
The Fisher vector image descriptor:
- Implemented using VLFeat
- For each image:
- multi-scale SIFT descriptors are extracted densely.
- descriptors are projected to 80 dimensions with PCA
- Fisher vector pooling with
- a Gaussian mixture model with 64 components,
- Square-root
- ℓ2 normalization
Multi-view Representation (Recognition)
[1]
[1] A. Vedaldi and B. Fulkerson. VLFeat: An open and portable library of computer vision algorithms. http://www. vlfeat.org/, 2008.
CNN features:
- VGG-M network :
- Five convolutional layers conv1,...,5
- Three fully connected layers fc6,...,8
- a softmax classification layer
- The layer fc7 (after ReLU non-linearity, 4096-dimensional) is used as image descriptor
- The network is pre-trained on ImageNet images from 1k categories
- fine-tuned on all 2D views of the 3D shapes in training set
Multi-view Representation (Recognition)
[1]
[1] K. Chatfield, K. Simonyan, A. Vedaldi, and A. Zisserman. Return of the devil in the details: Delving deep into convolutional nets. In Proc. BMVC, 2014.
Classification
- Train one-vs-rest linear SVMs to classify shapes using their image features
- each view is treated as a separate training sample
- At test time
- Sum up the SVM decision values over all 12 views
- Return the class with the highest sum
Multi-view Representation (Recognition)
Retrieval
The distance between shape x and y is defined in:
Multi-view Representation (Recognition)
A distance or similarity measure is required for retrieval tasks
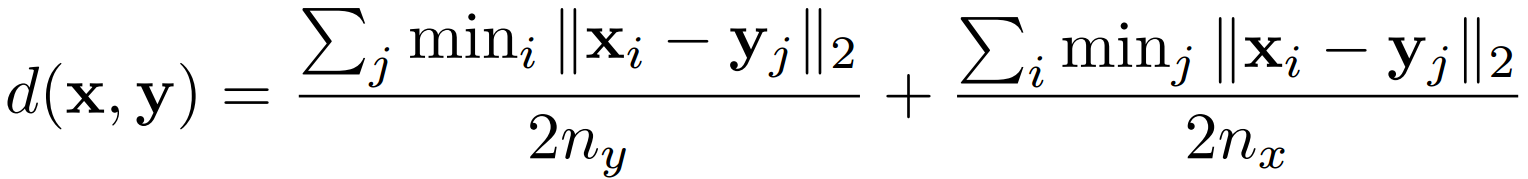
image descriptors
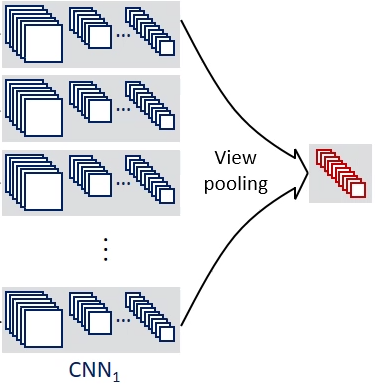
Multi-view CNN: Learning to Aggregate Views
Multi-view CNN: Learning to Aggregate Views
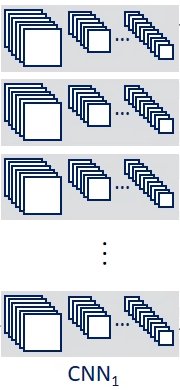
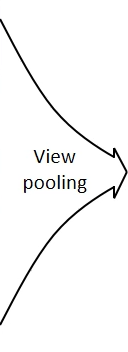
Share the same parameters
Multi-view CNN: Learning to Aggregate Views
element-wise maximum pooling across the views
Multi-view CNN: Learning to Aggregate Views
Produce shape descriptors
Multi-view CNN: Learning to Aggregate Views
Fine-tuned using Stochastic gradient descent with back-propagation
Dataset
- Evaluated on the Princeton ModelNet dataset
- ModelNet currently contains 127,915 3D CAD models from 662 categories.
- ModelNet40: a 40-class well-annotated subset containing 12,311 shapes from 40 common categories
[1] The Princeton ModelNet. http://modelnet.cs. princeton.edu/.
[1]


3D Shape Classification and Retrieval
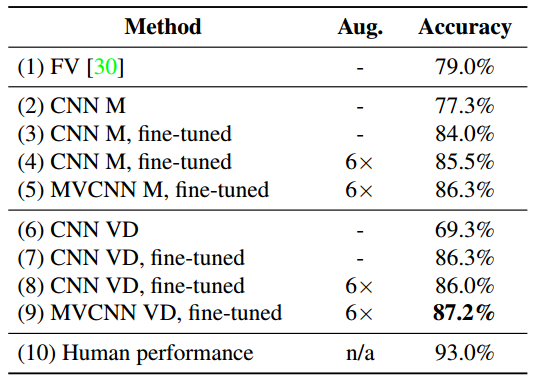
Baselines
- 3D ShapeNets
- Spherical Harmonic descriptor (SPH)
- LightField descriptor (LFD)
- Fisher vectors
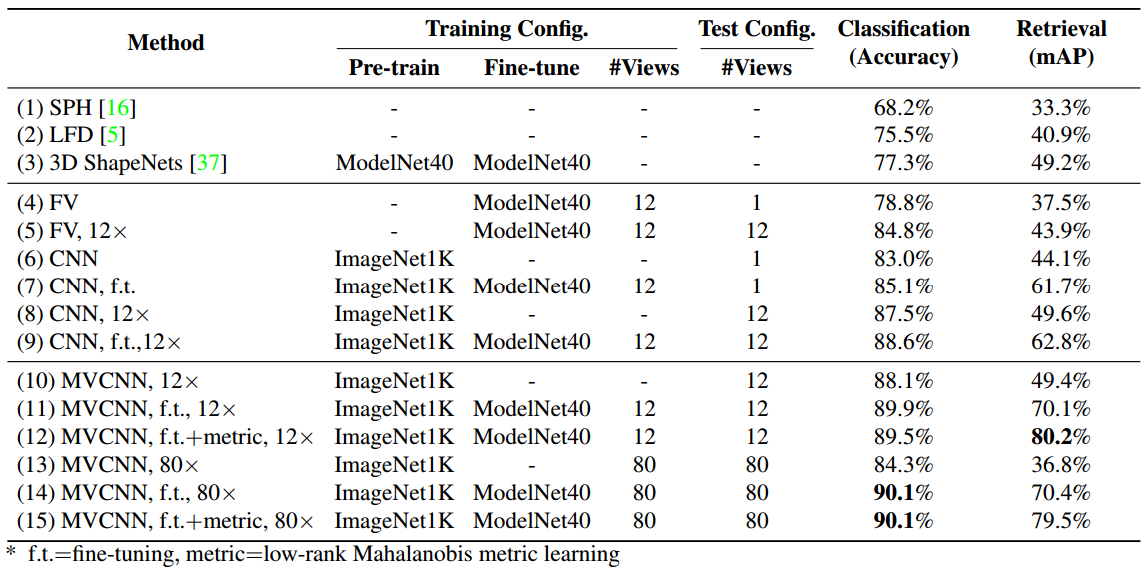
Classification and retrieval results on the ModelNet40 dataset
Classification and retrieval results on the ModelNet40 dataset
Classification and retrieval results on the ModelNet40 dataset
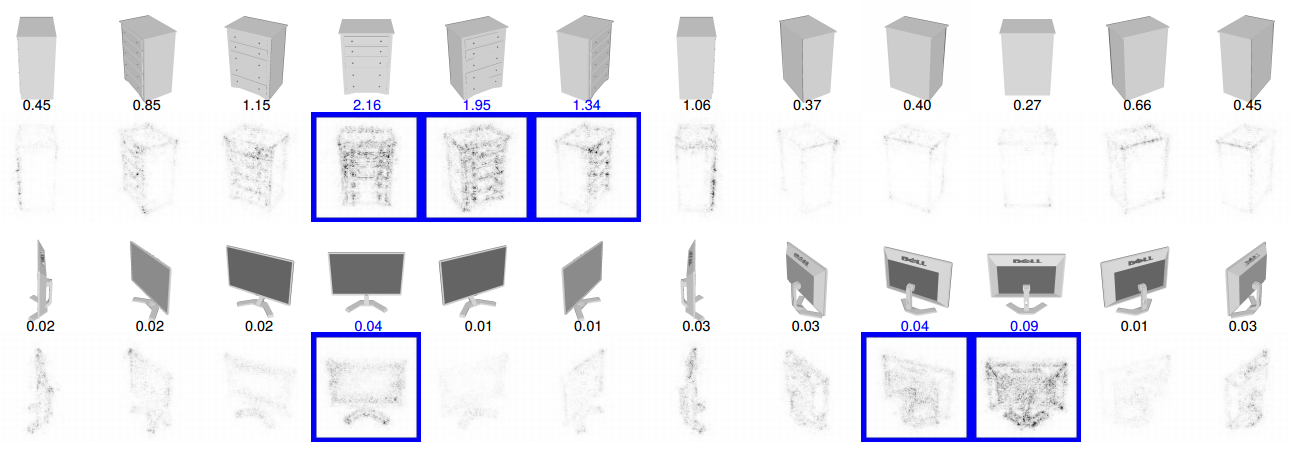
Saliency map among views
Rank pixels in the 2D views w.r.t. their influence on the output score Fc of the network for the class c
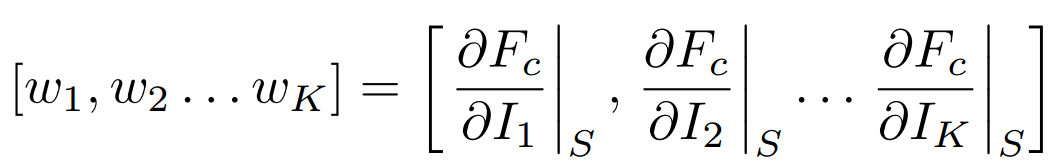
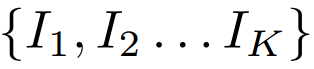
a set of K 2D views
The saliency maps are computed by back-propagating the gradients of the class score onto the image via the view-pooling layer.
Examples of saliency maps
Top three views with the highest saliency
Sketch Recognition
Whether aggregating multiple views of a 2D image also improve performance?
Sketch Recognition (Jittering revisited)
Data jittering, or data augmentation:
Generate extra samples from a given image
the process of perturbing the image by transformations that change its appearance while leaving the high-level information (class, label, attributes, etc.) intact
- Applied at training time to augment training samples and to reduce overfitting
- Applied at test time to provide more robust predictions
Sketch Recognition (Jittering revisited)
Data jittering improves the performance of deep representations on 2D image classification tasks
includes random image translations (implemented as random crops), horizontal reflections, and color perturbations
only includes a few crops (e.g., four at the corners, one at the center and their horizontal reflections)
training
test
Sketch Recognition (Jittering revisited)
20,000 hand-drawn sketches of 250 object categories such as airplanes, apples, bridges, etc
[1]
[1] M. Eitz, J. Hays, and M. Alexa. How do humans sketch objects? ACM Trans. Graph., 31(4):44:1–44:10, 2012.

human sketch dataset
The cleaned dataset (SketchClean) contains 160 categories
Sketch Recognition (Jittering revisited)
To get multiple views from 2D images, jittering is used to mimic the effect of views.
- For each hand-drawn sketch
- in-plane rotation with three angles: −45°, 0°, 45°
- horizontal reflections (hence 6 samples per image).
Sketch Recognition
Sketch-based 3D Shape Retrieval
Most online repositories provide only text-based search engines or hierarchical catalogs for 3D shape retrieval.



Sketch-based 3D Shape Retrieval
Sketchbased shape retrieval has been proposed as an alternative for users to retrieve shapes with an approximate sketch of the desired 3D shape in mind
hand-drawn sketches
sketches can be highly abstract and visually different from target 3D shapes.
Sketch-based retrieval involves two heterogeneous data domain
3D shapes
Sketch-based 3D Shape Retrieval
Dataset
193 sketches and 790 CAD models from 10 categories existing in both SketchClean and ModelNet40

Sketch-based 3D Shape Retrieval
- Detecting Canny edges on the depth buffer (also known as z-buffer) from 12 viewpoints.
- These edge maps are then passed through CNNs to obtain image descriptors.
- Descriptors are also extracted from 6 perturbed samples of each query sketch
- Rank 3D shapes w.r.t. “average minimum distance” to the sketch descriptor
Renderings of 3D shapes with a style similar to hand-drawn sketches
Sketch-based 3D Shape Retrieval
- Retrieve 3D objects from the same class with the query sketch
- Performance is 36.1% mAP on this dataset.
- Use the VGG-M network trained on ImageNet without any fine-tuning on either sketches or 3D shapes
- With a fine-tuning procedure that optimizes a distance measure between hand-drawn sketches and 3D shapes, e.g., by using a Siamese Network retrieval performance can be further improved.
Sketch-based 3D Shape Retrieval
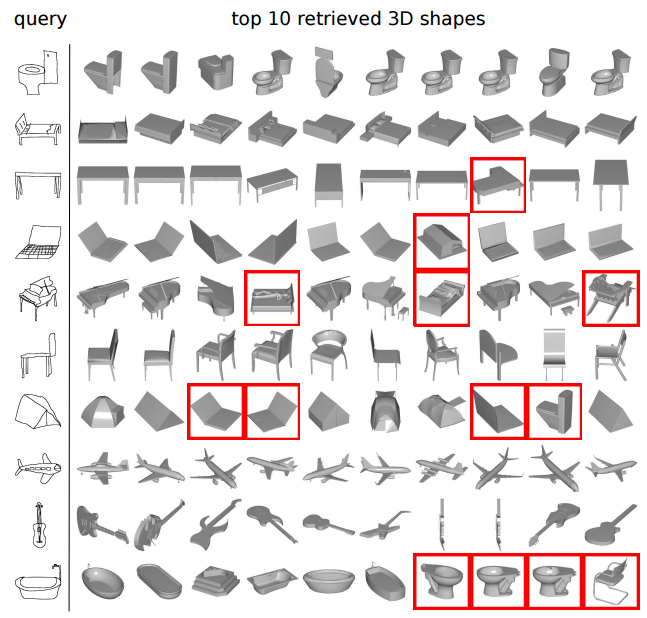
Conclusion
- By using images of shapes as inputs, we can achieve performance better than those that operate on direct 3D representations of shapes
- the naive usage of multiple 2D projections yields impressive discrimination performance
- Building descriptors that are aggregations of information from multiple views helps to achieve compactness, efficiency, and better accuracy
- By relating the content of 3D shapes to 2D representations like sketches, we can retrieve these 3D shapes at high accuracy using sketches, and leverage the implicit knowledge of 3D shapes contained in their 2D views
Future work
- Experiment with different combinations of 2D views
- Which views are most informative?
- How many views are necessary for a given level of accuracy?
- Can informative views be selected on the fly?
- Whether our view aggregating techniques can be used for building compact and discriminative descriptors for real-world 3D objects from multiple views, or automatically from video, rather than merely for 3D polygon mesh models.
- object recognition
- face recognition.

Multi-view CNNs for 3D shape recognition
By Elaheh Barati


