

















Elisa Beshero-Bondar PRO
Professor of Digital Humanities and Chair of the Digital Media, Arts, and Technology Program at Penn State Erie, The Behrend College.
Slides Link: bit.ly/collThinkSlides
Comparing different versions of a text
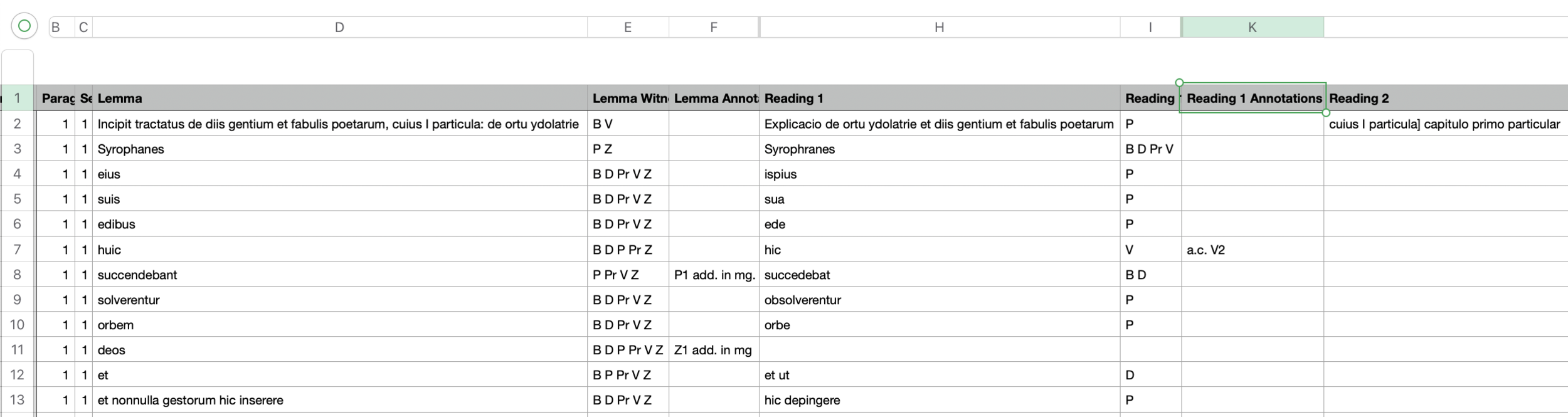
Carter "Hailey’s Comet" Portable Optical Collator.
Source: https://www.folger.edu/blogs/collation/welcome-to-the-collation/
Tracing version history of a work
What is your "theory of the text"?
How many texts are you comparing, and on what basis?
What tools can best help you with this comparison?
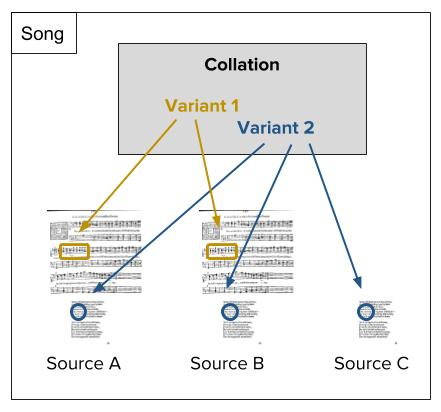
What constitutes a variant?
(and when collating music notation?)
Transpositions (on multiple levels)
*1769 in Leipzig
music literate, critic, publisher
witnessed the Battle of Leipzig
in October 1813 (Napoleon vs. most of Europe)
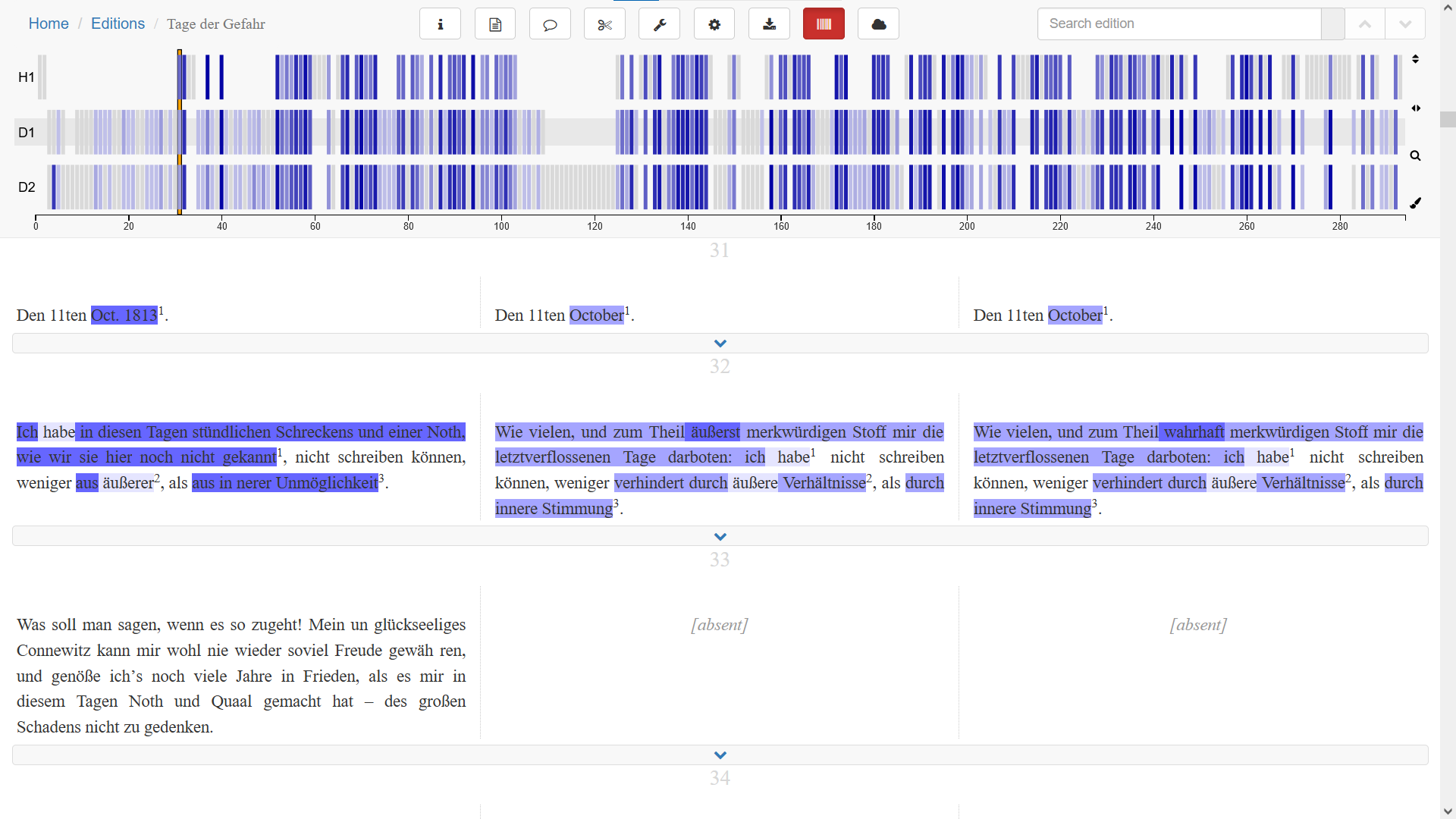
author of “Tage der Gefahr ”
(„days of peril“), 1813 – 1822
„Ich habe in diesen Tagen stündlichen Schreckens und einer Noth, wie wir sie hier noch nicht gekannt, nicht schreiben können …“
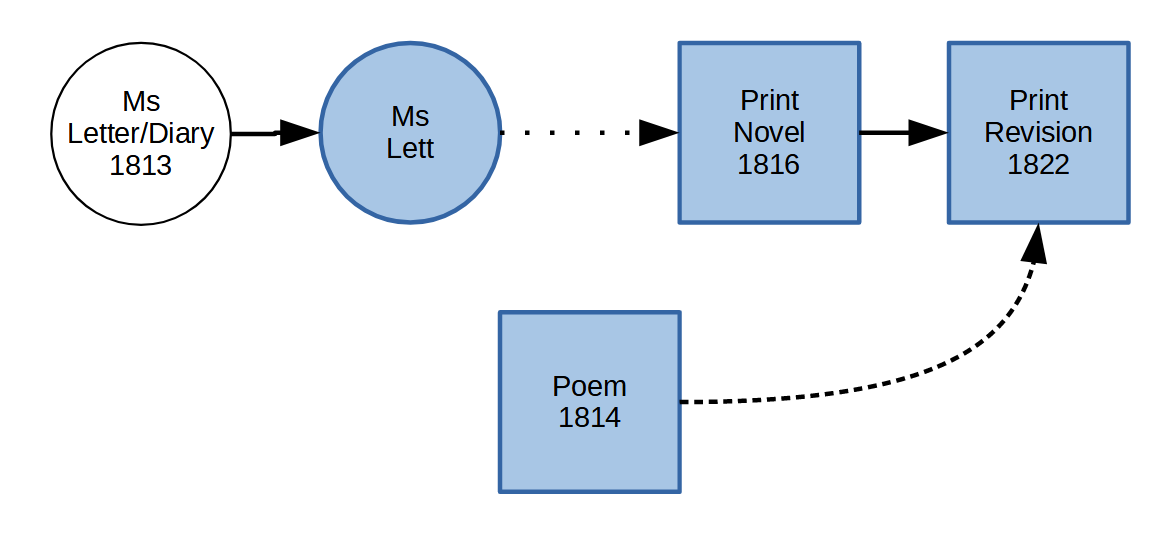
a text published in 1814 which was included in the 1822 edition
multiple changes of genre → no ideal base text
high degree of variance amongst “versions”
1816 / 1822: using apparatus seems convenient
1814 / 1816 / 1822: is an apparatus still the appropriate method?
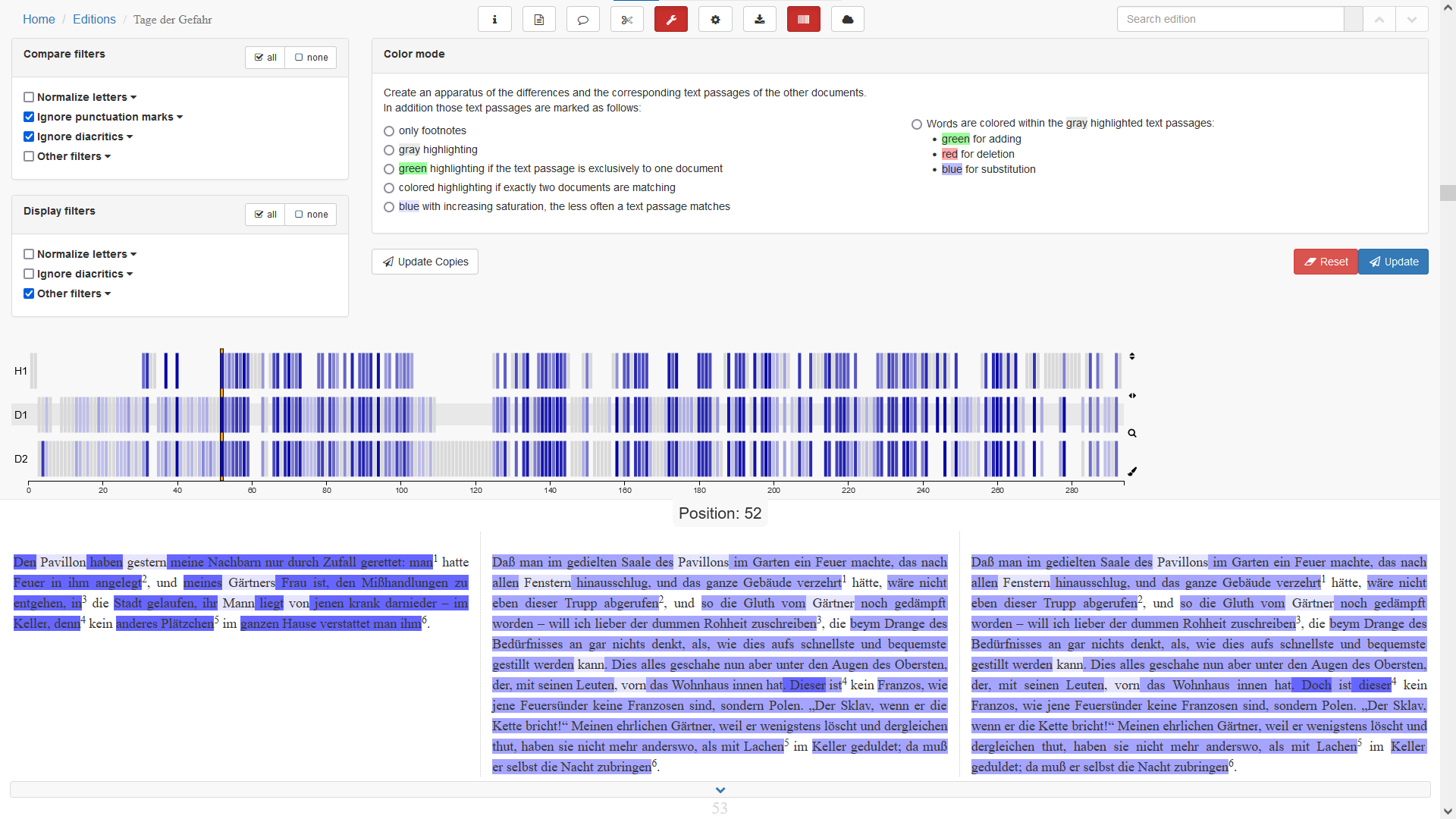
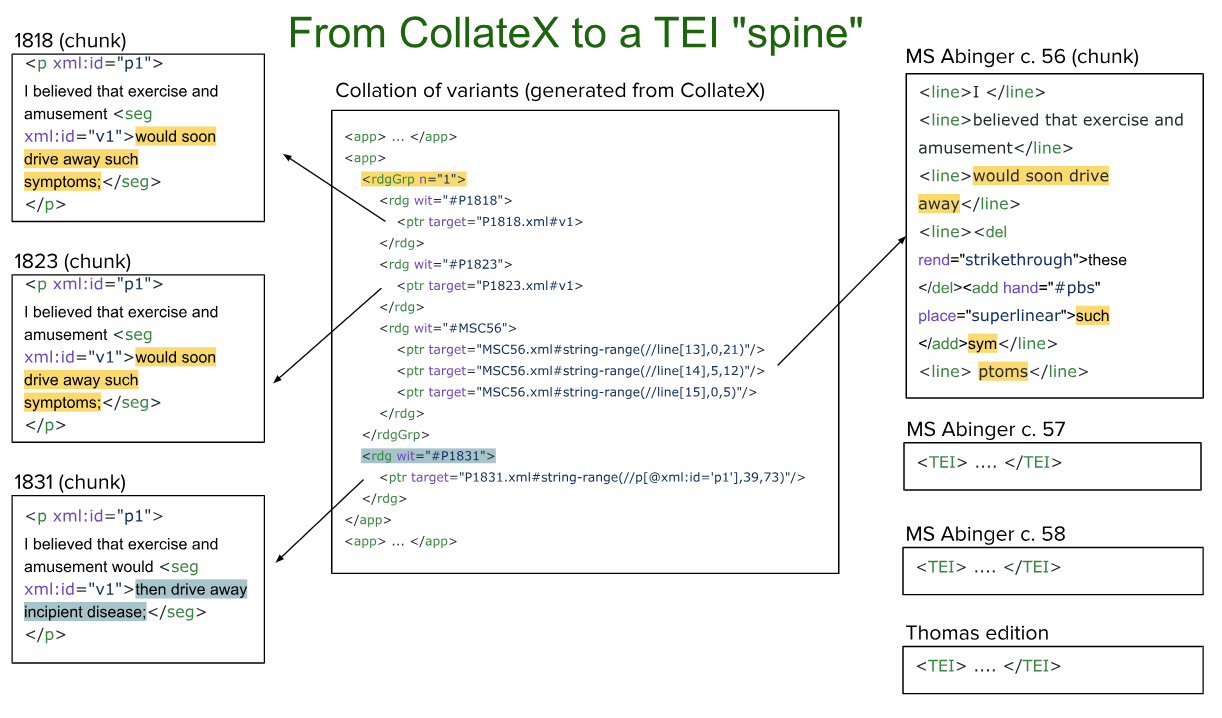
two-level apparatus
level 1: alignment of chunks → focus on similarities
level 2: collation of tokens → focus on differences
chunk level
token level
one-column presentation, marginal apparatus
→ eternal beta: http://gefahr.elitepiraten.de
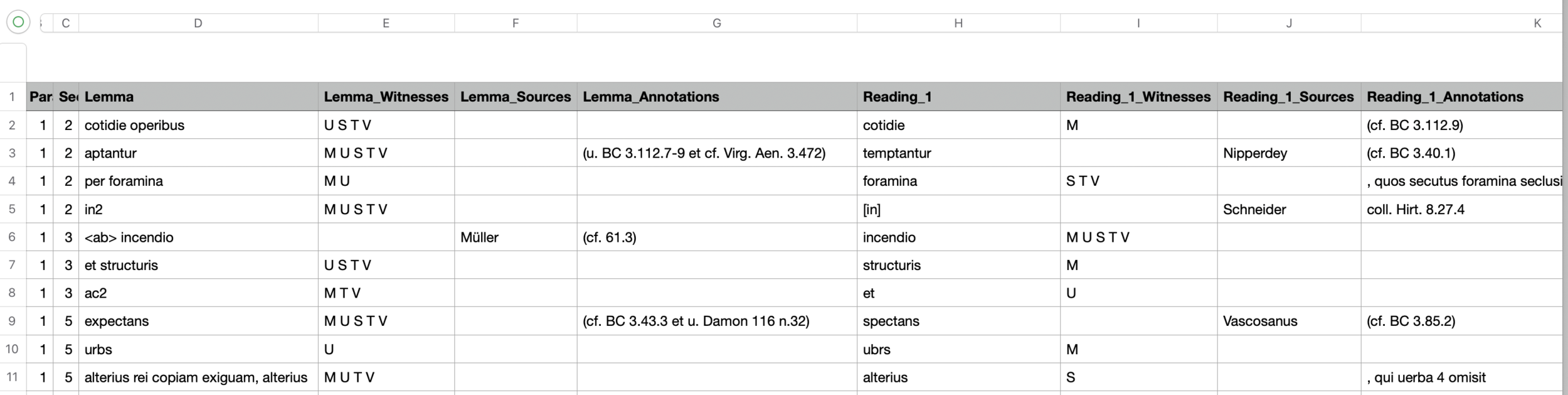
about the source documents:
(from the TEI Guidelines Ch. 12 Critical Apparatus)
about the identification of reading "witnesses"
(from the TEI Guidelines Ch. 12 Critical Apparatus)
about the handling of variation
(from the TEI Guidelines Ch. 12 Critical Apparatus)
How can the Guidelines Critical Apparatus chapter better discuss the challenges of alignment?
How is alignment related to describing variants?
Alignment: What constitutes a "same" starting point or ending point for a passage?
Do we need a theory of alignment for our texts?
"Chunking up" the texts in small passages that align via...
<app>
<rdgGrp
n="['<del>and this makes us all very wretched, as much so nearly as after the death
of your dear mother.</del>', 'and this suspicion fills us with anguish.
i perceive that your father <del>conceals</del> attempts to conceal his fears from me;
but cheerfulness has flown from our little circle, only to be restored by a certain assuranance
that there is no foundation for our anxiety. at one time']">
<rdg wit="fThomas"><del rend="strikethrough">and this makes us all very wretched,
as much so nearly as after the death of your dear mother.</del> <add
place="bottom">and this suspicion fills us with anguish. I perceive that your
father <del-INNER>conceals</del-INNER> attempts to conceal his fears
from me; but cheerfulness has flown from our little circle, only to be restored by a
certain assuranance that there is no foundation for our anxiety. At one
time</add></rdg>
</rdgGrp>
<rdgGrp n="['and', 'this', 'makes', 'us']">
<rdg wit="f1818">and this makes us</rdg>
<rdg wit="f1823">and this makes us</rdg>
<rdg wit="fMS"><mod sID="c56-0058__main__d5e11820"/><sga-add
place="superlinear" sID="c56-0058__main__d5e11822"/>and this makes us</rdg>
</rdgGrp>
</app>
<app>
<rdgGrp n="['all']">
<rdg wit="f1818">all</rdg>
<rdg wit="f1823">all</rdg>
</rdgGrp>
</app>
<app>
<rdgGrp n="['very']">
<rdg wit="f1818">very</rdg>
<rdg wit="f1823">very</rdg>
<rdg wit="fMS">very</rdg>
</rdgGrp>
</app>
<app>
<rdgGrp n="['wretched']">
<rdg wit="fMS">wretched</rdg>
</rdgGrp>
<rdgGrp n="['wretched,']">
<rdg wit="f1818">wretched,</rdg>
<rdg wit="f1823">wretched,</rdg>
</rdgGrp>
</app>...unless we
Background image created by Elisa from a picture of a machine loom on Reddit and the frontispiece illustration of Frankenstein (1831)
algorithm for computer-assisted collation, developed in 2009 workshop of collateX and Juxta developers.
Tokenization :
Break down the smallest unit of comparison: (words--with punctuation, or character-by-character):
FV tokenizes words and includes punctuation and tags:
'<del>the', 'frame', 'on', 'whic<del>', 'my', 'man', 'completeed,.'
Normalization
'&' = 'and'
<p xml:id="novel1_letter4_div4_p2"> = <p/>
Alignment
Identify comparable divergence: what makes text sequences comparable units?
“Chunking” text into comparable passages (chapters/paragraphs that line up with identifiable start and end points). Collation proceeds chunk by chunk.
Analysis
Study output, correct, and re-align after machine process, AND refine automated processing
Visualization:
Critical edition interface, graph displays
collateX
Lera
Juxta (no longer a web service)
automatic alignment by segments + collation within segments
“Locate, Explore, Retrace and Apprehend complex text variants”
step 1: upload documents
feature: segmentation e.g. by TEI elements or line breaks
step 2: choose documents for alignment/collation (“edition”)
feature: automatic alignment of unaligned segments
step 3: alignment revision and collation configuration
feature: dynamically updated visualizations
step 4: TEI export
Discuss: Troubles with Gothenburg...
<app xml:id="C11_app11" n="20">
<rdgGrp xml:id="C11_app11_rg_empty">
<rdg wit="#f1831"/>
</rdgGrp>
<rdgGrp n="['henry', '–', 'surely', 'victor']" xml:id="C11_app11_rg1">
<rdg wit="#fMS">
<ptr target="https://raw.githubusercontent.com/FrankensteinVariorum/fv-data/master/2023-variorum-chapters/fMS_box_c56_ch_v_113.xml#C11_app11-fMS"/>
<witDetail wit="#fMS" target="sga:c56/#/p58">
<ref type="page"
target="https://raw.githubusercontent.com/umd-mith/sga/6b935237972957b28b843f8d6d9f939b9a95dcb5/data/tei/ox/ox-ms_abinger_c56/ox-ms_abinger_c56-0058.xml">
<ptr target="https://raw.githubusercontent.com/umd-mith/sga/6b935237972957b28b843f8d6d9f939b9a95dcb5/data/tei/ox/ox-ms_abinger_c56/ox-ms_abinger_c56-0058.xml#string-range(//tei:surface[@xml:id='ox-ms_abinger_c56-0058']/tei:zone[@type='main']//tei:line[8],0,22)"/>
<fv:line_text>Henry – Surely Victor</fv:line_text>
<fv:resolved_text>Henry – Surely Victor</fv:resolved_text>
</ref>
</witDetail>
</rdg>
</rdgGrp>
<rdgGrp n="['henry.', 'surely,', 'victor,']" xml:id="C11_app11_rg2">
<rdg wit="#f1818">
<ptr target="https://raw.githubusercontent.com/FrankensteinVariorum/fv-data/master/2023-variorum-chapters/f1818_vol_1_chapter_v.xml#C11_app11-f1818"/>
</rdg>
<rdg wit="#f1823">
<ptr target="https://raw.githubusercontent.com/FrankensteinVariorum/fv-data/master/2023-variorum-chapters/f1823_vol_1_chapter_v.xml#C11_app11-f1823"/>
</rdg>
<rdg wit="#fThomas">
<ptr target="https://raw.githubusercontent.com/FrankensteinVariorum/fv-data/master/2023-variorum-chapters/fThomas_vol_1_chapter_v.xml#C11_app11-fThomas"/>
</rdg>
</rdgGrp>
</app>1. What special challenges do we encounter in the collation of music—in identification of meaningful variation, determining alignment, etc?
2. When would you want to collate markup or "pseudomarkup" in your projects? Or what kinds of projects might benefit from this?
3. Try out the Jupyter notebook linked in these slides. Where might "machine-assisted collation" be beneficial? Where might it cause problems?
4. What's wrong with machine-assisted collation now? How should it be better? What would it need to do to better work with humanities text / music collation challenges?
<app>, <lem>, <rdg>, <rdgGrp>, <wit>, <witDetail>, @wit
<app> started out as phrase level, but can contain structures (as of v. 2.9.1, fall 2015)
<app> can nest, so multi-level variation can be handled, but is that enough?
<tei:app>
<tei:rdg wit="#El">Experience though noon Auctoritee</rdg>
<tei:rdg wit="#La">Experiment thouh noon Auctoritee</rdg>
<tei:rdg wit="#Ra2">Eryment though none auctorite</rdg>
</tei:app><!-- In the document content: -->
<mei:app>
<mei:rdg source="#critApp.source1">
<!-- reading of source 1 -->
</mei:rdg>
<mei:rdg source="#critApp.source2 #critApp.source3">
<!-- reading of sources 2 *and* 3 -->
</mei:rdg>
</mei:app>TEI Guidelines Chapter 12
MEI Guidelines Chapter 11
multiple witnesses to largely the same text
multiple versions
(new editions, reworked material)
text re-use
From Early Modern Songscapes: https://ems.digital.utsc.utoronto.ca/
Considerations:
too many witnesses...
working with data from the critical apparatus...mapping it back to the editions
Choose a topic to discuss in small groups for ~30 minutes.
By Elisa Beshero-Bondar
Slides to accompany a workshop at TEI - MEC 2023 Paderborn


