Games AI
0: Intro
ABout & not about
ABout & not about
- Not about Neuronal Networks
- Not about Mathematics
- Reinforcement Learning
ABout & not about
- Not about Neuronal Networks
- Not about Mathematics
- Reinforcement Learning
- But were still doing it
- But were still doing it
- Were creating AI that learns a Game
- Were not creating AI to be in a Game
- Important for reasoning
- Unavoidable for certain problems
About me
About me



About me

About me
Course Overview
Chapters
Chapters
0
RL
Intro
- General Infos
- Base Principle
- Markov Decision Process
Chapters
1
Dynamic
Programming
0
RL
Intro
- Markov Decision Process
- General Policy Iteration
- Asuming perfect Conditions
- Learning
- On Policy
- Model Based
Chapters
2
Monte
Carlo
1
Dynamic
Programming
0
RL
Intro
- Sampling Theory
- Monte Carlo Variants
- Learning
- Off Policy
- Model Free
Chapters
2
Monte
Carlo
1
Dynamic
Programming
3
Temporal
Difference
0
RL
Intro
- Merging Chapter 1 & 2
- SARSA / Q-Learning
- Learning
- Online
- Immediately
Chapters
2
Monte
Carlo
1
Dynamic
Programming
3
Temporal
Difference
4
Function
Approximation
0
RL
Intro
- Eliminate memory limitations
- Improve on Chapter 3
- Learn Generalisation
- Pytorch Intro
Chapters
2
Monte
Carlo
1
Dynamic
Programming
3
Temporal
Difference
4
Function
Approximation
5
Deep
QLearning
0
RL
Intro
- Neuronal Networks
- Improve RL Loop
- Improve NN Loop
Chapters
2
Monte
Carlo
1
Dynamic
Programming
3
Temporal
Difference
4
Function
Approximation
5
Deep
QLearning
0
RL
Intro
6
Policy
Gradient
Portfolio
2
Monte
Carlo
1
Dynamic
Programming
3
Temporal
Difference
4
Function
Approximation
5
Deep
QLearning
0
RL
Intro
6
Policy
Gradient
Portfolio
2
Monte
Carlo
1
Dynamic
Programming
3
Temporal
Difference
4
Function
Approximation
5
Deep
QLearning
0
RL
Intro
6
Policy
Gradient
Portfolio
2
Monte
Carlo
1
Dynamic
Programming
3
Temporal
Difference
4
Function
Approximation
5
Deep
QLearning
PORTFOLIO
2
Monte
Carlo
Blackjack
1
Dynamic
Programming
Icy Lake

3
Temporal
Difference
Taxi

4
Function
Approximation
Mountain Car
5
Deep
QLearning
Atari 2600

Rating
2
Monte
Carlo
Blackjack
1
Dynamic
Programming
Icy Lake
3
Temporal
Difference
Taxi
4
Function
Approximation
Mountain Car
5
Deep
QLearning
Atari 2600
20%
20%
20%
20%
20%
5
5
5
5
5
Rating
2
Monte
Carlo
Blackjack
1
Dynamic
Programming
Icy Lake
3
Temporal
Difference
Taxi
4
Function
Approximation
Mountain Car
5
Deep
QLearning
Atari 2600
20%
20%
20%
20%
20%
5
5
5
5
5
Note 5
Note 4
Note 3
Note 2
Note 1
Rating
2
Monte
Carlo
Blackjack
1
Dynamic
Programming
Icy Lake
3
Temporal
Difference
Taxi
4
Function
Approximation
Mountain Car
5
Deep
QLearning
Atari 2600
20%
20%
20%
20%
20%
5
5
5
5
5
Note 5
Note 4
Note 3
Note 2
Note 1
00 - 04
05 - 10
11 - 15
16 - 20
21 - 25
Literature
The Book
The Book

The Book
- "Bible" of RL
- Very detailed
- PDF is for free
A Video Playlist
A VIDEO PLAYLIST
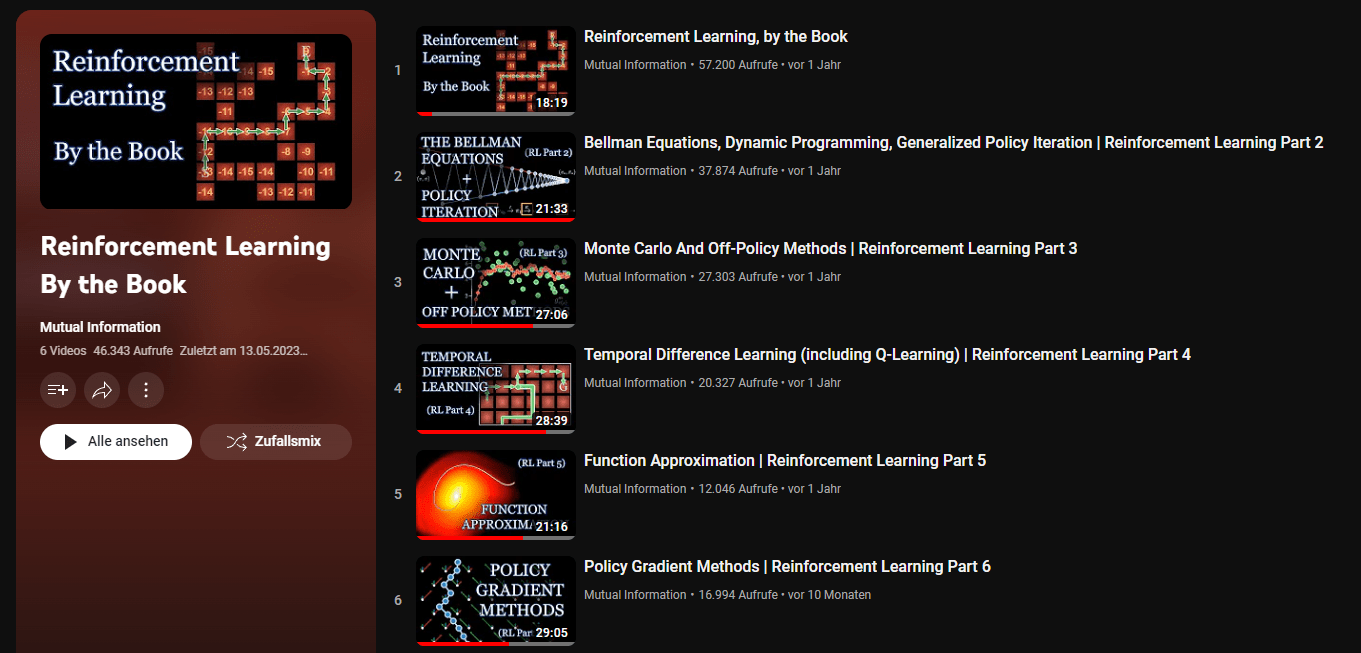
A VIDEO PLAYLIST
- Fast & compressed
- Beatiful visualisations
- Linked Github Repo
Examples

https://openai.com/research/openai-five
Dota 2
https://deepmind.google/technologies/alphago/
AlphaGo

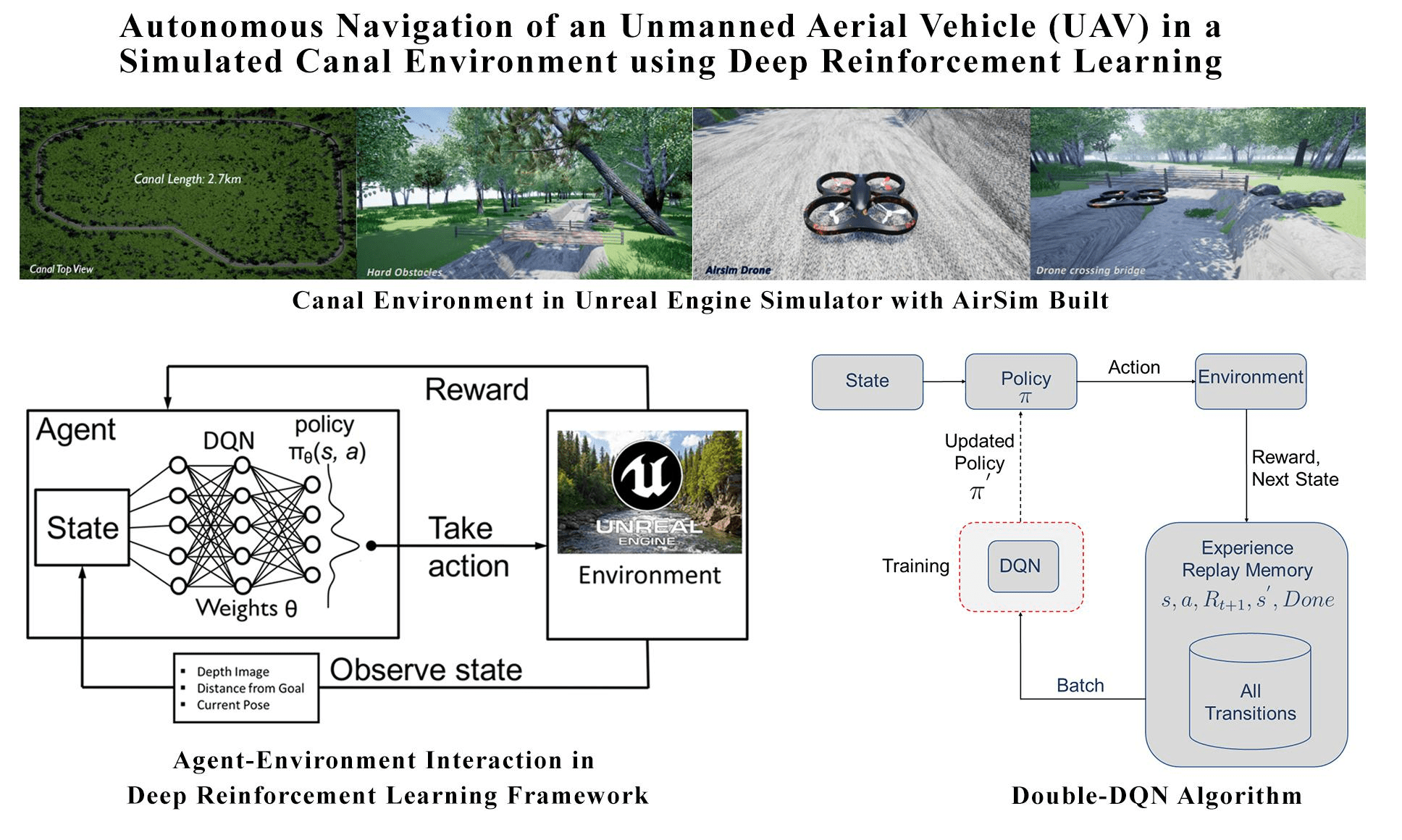
https://arxiv.org/pdf/1801.05086.pdf
Autonomous UAV Navigation
https://www.roboticsproceedings.org/rss05/p27.pdf
LITTLEDOG BOSTON DYNAMICS

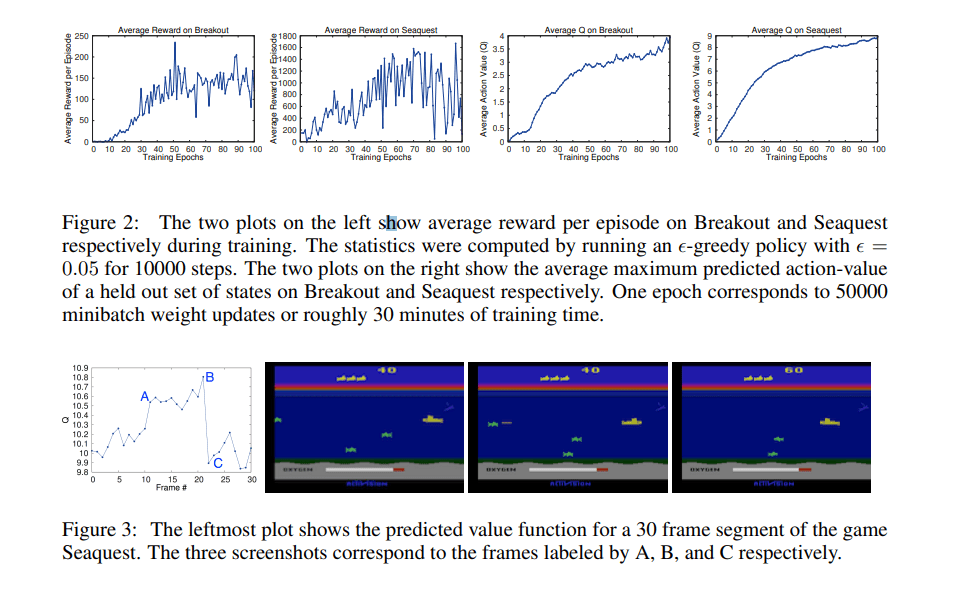
https://www.cs.toronto.edu/~vmnih/docs/dqn.pdf
PLAYING ATARI
Tools
Gymnasium
PyTorch

Python + JUPYTER
Reinforcment Learning
WHat is RL
WHat is RL
Supervised
Unsupervised
Machine Learning
Reinforcement
- Labeled Data
- Regression
- Classification
- Unlabeled Data
- Clustering
- Embedding
- Semisupervised
- Interactive
WHat is RL
Supervised
Unsupervised
Machine Learning
Reinforcement
- Labeled Data
- Regression
- Classification
- Unlabeled Data
- Clustering
- Embedding
- Semisupervised
- Interactive
WHat is RL
Supervised
Unsupervised
Machine Learning
Reinforcement
- Labeled Data
- Regression
- Classification
- Unlabeled Data
- Clustering
- Embedding
- Semisupervised
- Interactive
WHat is RL
Supervised
Unsupervised
Machine Learning
Reinforcement
- Labeled Data
- Regression
- Classification
- Unlabeled Data
- Clustering
- Embedding
- Semisupervised
- Interactive
WHat is RL
Supervised
Unsupervised
Machine Learning
Reinforcement
PRINCIPLE
PRINCIPLE
Agent
PRINCIPLE
Agent
Environment
PRINCIPLE
Agent
A_t
Environment
t \in T \{0,1,2,...\}
a \in A
Time
Action
PRINCIPLE
Agent
S_t
S_{t+1}
A_t
Environment
t \in T \{0,1,2,...\}
s \in S
a \in A
Time
State
Action
PRINCIPLE
Agent
S_t
R_t
S_{t+1}
R_{t+1}
A_t
Environment
t \in T \{0,1,2,...\}
s \in S
r \in R \in \mathbb{R}
a \in A
Time
State
Action
Reward
PRINCIPLE
Agent
S_t
R_t
S_{t+1}
R_{t+1}
A_t
Environment
t \in T \{0,1,2,...\}
s \in S
r \in R \in \mathbb{R}
a \in A
S_0, A_0, R_1, \hspace{3mm} S_1, A_1, R_2, \hspace{3mm} S_2, A_2, R_3, \hspace{3mm} \ldots
Time
State
Action
Reward
Trail:
PRINCIPLE
Agent
S_t
R_t
S_{t+1}
R_{t+1}
A_t
Environment
t \in T \{0,1,2,...\}
s \in S
r \in R \in \mathbb{R}
a \in A
S_0, A_0, R_1, \hspace{3mm} S_1, A_1, R_2, \hspace{3mm} S_2, A_2, R_3, \hspace{3mm} \ldots
G_t = R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + ... = \sum_{k=0}^T\gamma^k R_{t+k+1}
Time
State
Action
Reward
Trail:
Goal:
PRINCIPLE
Agent
S_t
R_t
S_{t+1}
R_{t+1}
A_t
Environment
t \in T \{0,1,2,...\}
s \in S
r \in R \in \mathbb{R}
a \in A
S_0, A_0, R_1, \hspace{3mm} S_1, A_1, R_2, \hspace{3mm} S_2, A_2, R_3, \hspace{3mm} \ldots
G_t = R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + ... = \sum_{k=0}^T\gamma^k R_{t+k+1}
Time
State
Action
Reward
Trail:
Goal:
PRINCIPLE
Agent
S_t
R_t
S_{t+1}
R_{t+1}
A_t
Environment
p(s', r \mid s, a)
t \in T \{0,1,2,...\}
s \in S
r \in R \in \mathbb{R}
a \in A
S_0, A_0, R_1, \hspace{3mm} S_1, A_1, R_2, \hspace{3mm} S_2, A_2, R_3, \hspace{3mm} \ldots
G_t = R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + ... = \sum_{k=0}^T\gamma^k R_{t+k+1}
Time
State
Action
Reward
Trail:
Goal:
PRINCIPLE
Agent
S_t
R_t
S_{t+1}
R_{t+1}
A_t
Environment
p(s', r \mid s, a)
\pi(a \mid s)
t \in T \{0,1,2,...\}
s \in S
r \in R \in \mathbb{R}
a \in A
S_0, A_0, R_1, \hspace{3mm} S_1, A_1, R_2, \hspace{3mm} S_2, A_2, R_3, \hspace{3mm} \ldots
G_t = R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + ... = \sum_{k=0}^T\gamma^k R_{t+k+1}
Time
State
Action
Reward
Trail:
Goal:

Finite Markov Decision process
Agent
S_t
R_t
S_{t+1}
R_{t+1}
A_t
Environment
p(s', r \mid s, a)
\pi(a \mid s)
t \in T \{0,1,2,...\}
s \in S
r \in R \in \mathbb{R}
a \in A
S_0, A_0, R_1, \hspace{3mm} S_1, A_1, R_2, \hspace{3mm} S_2, A_2, R_3, \hspace{3mm} \ldots
G_t = R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + ... = \sum_{k=0}^T\gamma^k R_{t+k+1}
Time
State
Action
Reward
Trail:
Goal:
Finite Markov Decision process
Agent
S_t
R_t
S_{t+1}
R_{t+1}
A_t
Environment
p(s', r \mid s, a)
\pi(a \mid s)

Markov What?
Markov Property
The probability of transitioning to the next state depends only on the current state, not on the sequence of events that preceded it.
MDP
Finite Markov Decision process
Agent
S_t
R_t
S_{t+1}
R_{t+1}
A_t
Environment
p(s', r \mid s, a)
\pi(a \mid s)
t \in T \{0,1,2,...\}
s \in S
r \in R \in \mathbb{R}
a \in A
S_0, A_0, R_1, \hspace{3mm} S_1, A_1, R_2, \hspace{3mm} S_2, A_2, R_3, \hspace{3mm} \ldots
G_t = R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + ... = \sum_{k=0}^T\gamma^k R_{t+k+1}
Time
State
Action
Reward
Trail:
Goal:
Finite Markov Decision process
Agent
S_t
R_t
S_{t+1}
R_{t+1}
A_t
Environment
p(s', r \mid s, a)
\pi(a \mid s)
t \in T \{0,1,2,...\}
s \in S
r \in R \in \mathbb{R}
a \in A
S_0, A_0, R_1, \hspace{3mm} S_1, A_1, R_2, \hspace{3mm} S_2, A_2, R_3, \hspace{3mm} \ldots
G_t = R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + ... = \sum_{k=0}^T\gamma^k R_{t+k+1}
Time
State
Action
Reward
Trail:
Goal:
v_\pi(s) \equiv \mathbb{E}_\pi[G_t \,|\, S_t = s] = \mathbb{E}_\pi \left[ \sum_{k=0}^\infty \gamma^k R_{t+k+1} \,|\, S_t = s \right], \text{ for all } s \in \mathcal{S}
q_\pi(s, a) \equiv \mathbb{E}_\pi[G_t \,|\, S_t = s, A_t = a] = \mathbb{E}_\pi \left[ \sum_{k=0}^\infty\gamma^k R_{t+k+1} \,|\, S_t = s, A_t = a \right]
State Value:
Action Value:
Rewards & Objective
G_t = R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + ... = \sum_{k=0}^\infty\gamma^k R_{t+k+1}
Goal:
v_\pi(s) \equiv \mathbb{E}_\pi[G_t \,|\, S_t = s] = \mathbb{E}_\pi \left[ \sum_{k=0}^\infty\gamma^k R_{t+k+1} \,|\, S_t = s \right], \text{ for all } s \in \mathcal{S}
q_\pi(s, a) \equiv \mathbb{E}_\pi[G_t \,|\, S_t = s, A_t = a] = \mathbb{E}_\pi \left[ \sum_{k=0}^\infty\gamma^k R_{t+k+1} \,|\, S_t = s, A_t = a \right]
State Value:
Action Value:
REWARDS & OBJECTIVE
G_t = R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + ... = \sum_{k=0}^\infty\gamma^k R_{t+k+1}
Goal:
v_\pi(s) \equiv \mathbb{E}_\pi[G_t \,|\, S_t = s] = \mathbb{E}_\pi \left[ \sum_{k=0}^\infty\gamma^k R_{t+k+1} \,|\, S_t = s \right], \text{ for all } s \in \mathcal{S}
q_\pi(s, a) \equiv \mathbb{E}_\pi[G_t \,|\, S_t = s, A_t = a] = \mathbb{E}_\pi \left[ \sum_{k=0}^\infty\gamma^k R_{t+k+1} \,|\, S_t = s, A_t = a \right]
State Value:
Action Value:
REWARDS & OBJECTIVE
G_t = \sum_{k=0}^\infty\gamma^k R_{t+k+1}
Goal:
v_\pi(s) \equiv \mathbb{E}_\pi[G_t \,|\, S_t = s] = \mathbb{E}_\pi \left[ \sum_{k=0}^\infty\gamma^k R_{t+k+1} \,|\, S_t = s \right], \text{ for all } s \in \mathcal{S}
q_\pi(s, a) \equiv \mathbb{E}_\pi[G_t \,|\, S_t = s, A_t = a] = \mathbb{E}_\pi \left[ \sum_{k=0}^\infty\gamma^k R_{t+k+1} \,|\, S_t = s, A_t = a \right]
State Value:
Action Value:
REWARDS & OBJECTIVE
G_t = \sum_{k=0}^\infty\gamma^k R_{t+k+1}
Goal:
v_\pi(s) \equiv \mathbb{E}_\pi[G_t \,|\, S_t = s] = \mathbb{E}_\pi \left[ \sum_{k=0}^\infty\gamma^k R_{t+k+1} \,|\, S_t = s \right], \text{ for all } s \in \mathcal{S}
q_\pi(s, a) \equiv \mathbb{E}_\pi[G_t \,|\, S_t = s, A_t = a] = \mathbb{E}_\pi \left[ \sum_{k=0}^\infty\gamma^k R_{t+k+1} \,|\, S_t = s, A_t = a \right]
State Value:
Action Value:
REWARDS & OBJECTIVE
G_t = \sum_{k=0}^\infty\gamma^k R_{t+k+1}
Goal:
v_\pi(s) \equiv \mathbb{E}_\pi[G_t \,|\, S_t = s] = \mathbb{E}_\pi \left[ \sum_{k=0}^\infty\gamma^k R_{t+k+1} \,|\, S_t = s \right], \text{ for all } s \in \mathcal{S}
q_\pi(s, a) \equiv \mathbb{E}_\pi[G_t \,|\, S_t = s, A_t = a] = \mathbb{E}_\pi \left[ \sum_{k=0}^\infty\gamma^k R_{t+k+1} \,|\, S_t = s, A_t = a \right]
State Value:
Action Value:
REWARDS & OBJECTIVE
G_t = \sum_{k=0}^\infty\gamma^k R_{t+k+1}
Goal:
v_\pi(s) \equiv \mathbb{E}_\pi[G_t \,|\, S_t = s]
q_\pi(s, a) \equiv \mathbb{E}_\pi[G_t \,|\, S_t = s, A_t = a]
State Value:
Action Value:
REWARDS & OBJECTIVE
G_t = \sum_{k=0}^\infty\gamma^k R_{t+k+1}
Goal:
v_\pi(s) \equiv \mathbb{E}_\pi[G_t \,|\, S_t = s]
q_\pi(s, a) \equiv \mathbb{E}_\pi[G_t \,|\, S_t = s, A_t = a]
State Value:
Action Value:
REWARDS & OBJECTIVE
G_t = \sum_{k=0}^\infty\gamma^k R_{t+k+1}
Goal:
v_\pi(s) \equiv \mathbb{E}_\pi[G_t \,|\, S_t = s]
q_\pi(s, a) \equiv \mathbb{E}_\pi[G_t \,|\, S_t = s, A_t = a]
State Value:
Action Value:
REWARDS & OBJECTIVE
G_t = \sum_{k=0}^\infty\gamma^k R_{t+k+1}
Goal:
v_\pi(s) \equiv \mathbb{E}_\pi[G_t \,|\, S_t = s]
q_\pi(s, a) \equiv \mathbb{E}_\pi[G_t \,|\, S_t = s, A_t = a]
State Value:
Action Value:
The actual Outcome for t
REWARDS & OBJECTIVE
G_t = \sum_{k=0}^\infty\gamma^k R_{t+k+1}
Goal:
State Value:
Action Value:
The actual Outcome for t
q_\pi(s, a) \equiv \mathbb{E}_\pi[G_t \,|\, S_t = s, A_t = a]
v_\pi(s) \equiv \mathbb{E}_\pi[G_t \,|\, S_t = s]

REWARDS & OBJECTIVE
G_t = \sum_{k=0}^\infty\gamma^k R_{t+k+1}
Goal:
v_\pi(s) \equiv \mathbb{E}_\pi\Rightarrow
State Value:
Action Value:
What is the expected Outcome at the given state
The actual Outcome for t
q_\pi(s, a) \equiv \mathbb{E}_\pi[G_t \,|\, S_t = s, A_t = a]
REWARDS & OBJECTIVE
G_t = \sum_{k=0}^\infty\gamma^k R_{t+k+1}
Goal:
v_\pi(s) \equiv \mathbb{E}_\pi\Rightarrow
q_\pi(s, a) \equiv \mathbb{E}_\pi \Rightarrow
State Value:
Action Value:
What is the expected Outcome at the given state
What is the expected Outcome at the given state taking an action
The actual Outcome for t
REWARDS & OBJECTIVE
G_t = \sum_{k=0}^\infty\gamma^k R_{t+k+1}
Goal:
v_\pi(s) \equiv \mathbb{E}_\pi[G_t \,|\, S_t = s]
q_\pi(s, a) \equiv \mathbb{E}_\pi[G_t \,|\, S_t = s, A_t = a]
State Value:
Action Value:
REWARDS & OBJECTIVE
G_t = \sum_{k=0}^\infty\gamma^k R_{t+k+1}
Goal:
v_\pi(s) \equiv \mathbb{E}_\pi[G_t \,|\, S_t = s]
q_\pi(s, a) \equiv \mathbb{E}_\pi[G_t \,|\, S_t = s, A_t = a]
State Value:
Action Value:
REWARDS & OBJECTIVE & Policies
G_t = \sum_{k=0}^\infty\gamma^k R_{t+k+1}
Goal:
v_\pi(s) \equiv \mathbb{E}_\pi[G_t \,|\, S_t = s]
q_\pi(s, a) \equiv \mathbb{E}_\pi[G_t \,|\, S_t = s, A_t = a]
State Value:
Action Value:
\pi(a | s)
Policy:
REWARDS & OBJECTIVE & POLICIES
G_t = \sum_{k=0}^\infty\gamma^k R_{t+k+1}
Goal:
v_\pi(s) \equiv \mathbb{E}_\pi[G_t \,|\, S_t = s]
q_\pi(s, a) \equiv \mathbb{E}_\pi[G_t \,|\, S_t = s, A_t = a]
State Value:
Action Value:
\pi(a | s)
Policy:
\pi_*(a | s)
optimal Policy:
REWARDS & OBJECTIVE & POLICIES
G_t = \sum_{k=0}^\infty\gamma^k R_{t+k+1}
Goal:
v_\pi(s) \equiv \mathbb{E}_\pi[G_t \,|\, S_t = s]
q_\pi(s, a) \equiv \mathbb{E}_\pi[G_t \,|\, S_t = s, A_t = a]
State Value:
Action Value:
\pi(a | s)
Policy:
\pi_*(a | s)
optimal Policy:
REWARDS & OBJECTIVE & POLICIES
G_t = \sum_{k=0}^\infty\gamma^k R_{t+k+1}
Goal:
v_\pi(s) \equiv \mathbb{E}_\pi[G_t \,|\, S_t = s]
q_\pi(s, a) \equiv \mathbb{E}_\pi[G_t \,|\, S_t = s, A_t = a]
State Value:
Action Value:
\pi(a | s)
Policy:
\pi_*(a | s)
optimal Policy:
REWARDS & OBJECTIVE & POLICIES
G_t = \sum_{k=0}^\infty\gamma^k R_{t+k+1}
Goal:
v_\pi(s) \equiv \mathbb{E}_\pi[G_t \,|\, S_t = s]
q_\pi(s, a) \equiv \mathbb{E}_\pi[G_t \,|\, S_t = s, A_t = a]
State Value:
Action Value:
\pi(a | s)
Policy:
\pi_*(a | s)
optimal Policy:
v_{\pi_*}(s) \geq v_\pi(s)
\text{for all}\ s\ \text{and any}\ \pi
REWARDS & OBJECTIVE & POLICIES
G_t = \sum_{k=0}^\infty\gamma^k R_{t+k+1}
Goal:
v_\pi(s) \equiv \mathbb{E}_\pi[G_t \,|\, S_t = s]
q_\pi(s, a) \equiv \mathbb{E}_\pi[G_t \,|\, S_t = s, A_t = a]
State Value:
Action Value:
\pi(a | s)
Policy:
\pi_*(a | s)
optimal Policy:
v_{\pi_*}(s) \geq v_\pi(s)
\text{for all}\ s\ \text{and any}\ \pi
q_{\pi_*}(s,a) \geq q_\pi(s,a)
\text{for all}\ s,a\ \text{and any}\ \pi
REWARDS & OBJECTIVE & POLICIES
G_t = \sum_{k=0}^\infty\gamma^k R_{t+k+1}
Goal:
v_\pi(s) \equiv \mathbb{E}_\pi[G_t \,|\, S_t = s]
q_\pi(s, a) \equiv \mathbb{E}_\pi[G_t \,|\, S_t = s, A_t = a]
State Value:
Action Value:
\pi(a | s)
Policy:
\pi_*(a | s)
optimal Policy:
v_{\pi_*}(s) \geq v_\pi(s)
\text{for all}\ s\ \text{and any}\ \pi
q_{\pi_*}(s,a) \geq q_\pi(s,a)
\text{for all}\ s,a\ \text{and any}\ \pi
\pi_* = \argmax_{a}\ q_*(s, a)
RL old
By Eric Dolch
