












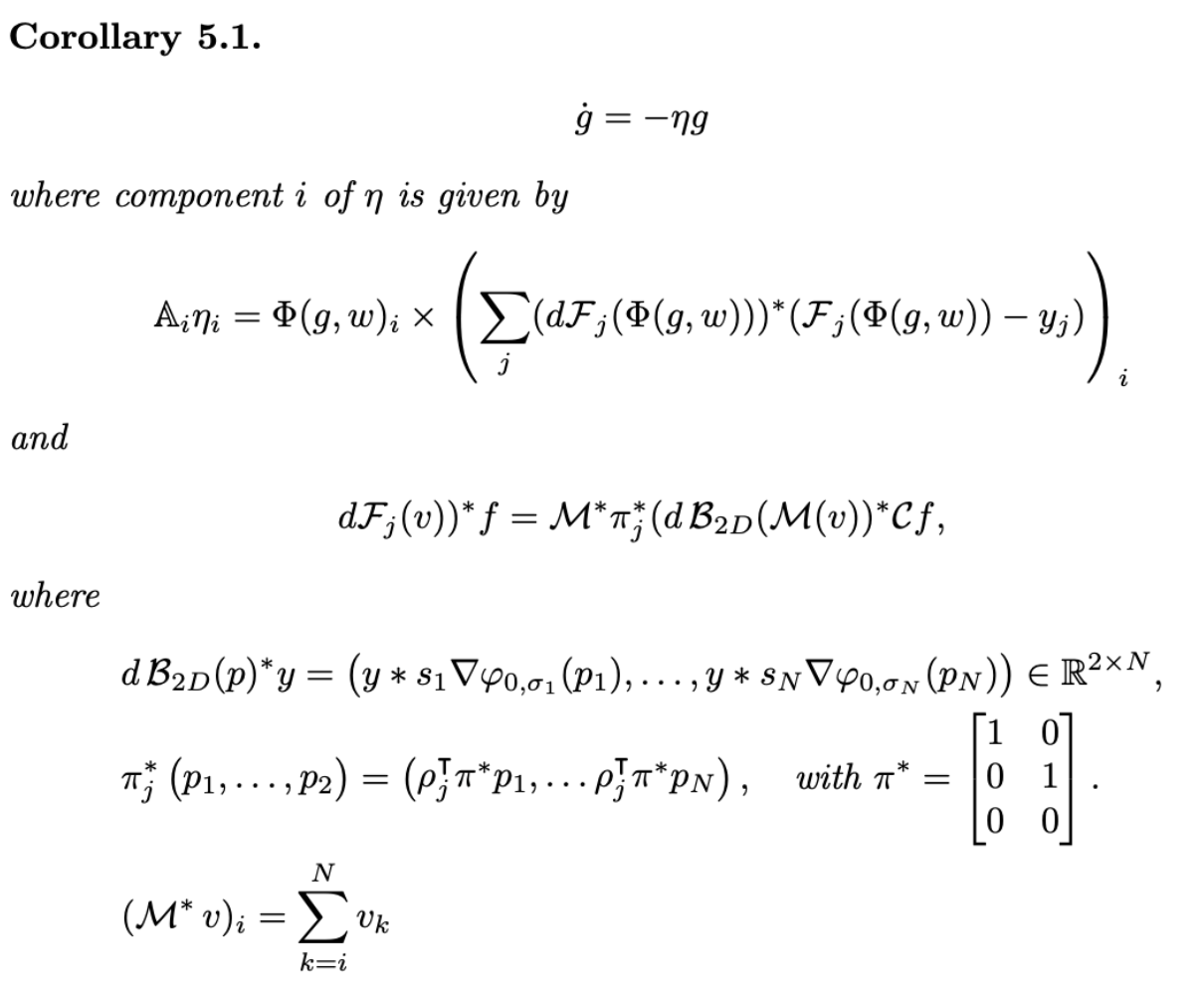

Erik Jansson
WASP and KAW postdoctoral fellow in the Cambridge Image Analysis Group and CRA at Wolfson College.
Klas Modin (Chalmers Uni)
Carola-Bibiane Schönlieb
(Cambridge)
Ozan Öktem (KTH)
Jonathan Krook (KTH)
in 30 seconds (by a maths person)
Electron
microscope
Low dose: low SNR
Many images
Many copies of the same protein but at different orientations and conformations
Particle picking
Issue: SNR is around 0.01-0.001, so almost no information
Could the problem be made easier if we knew which protein
was imaged and that we are observing a deformation of a representative conformation?
Hint: Yes, this incorporates an
"anatomical prior"
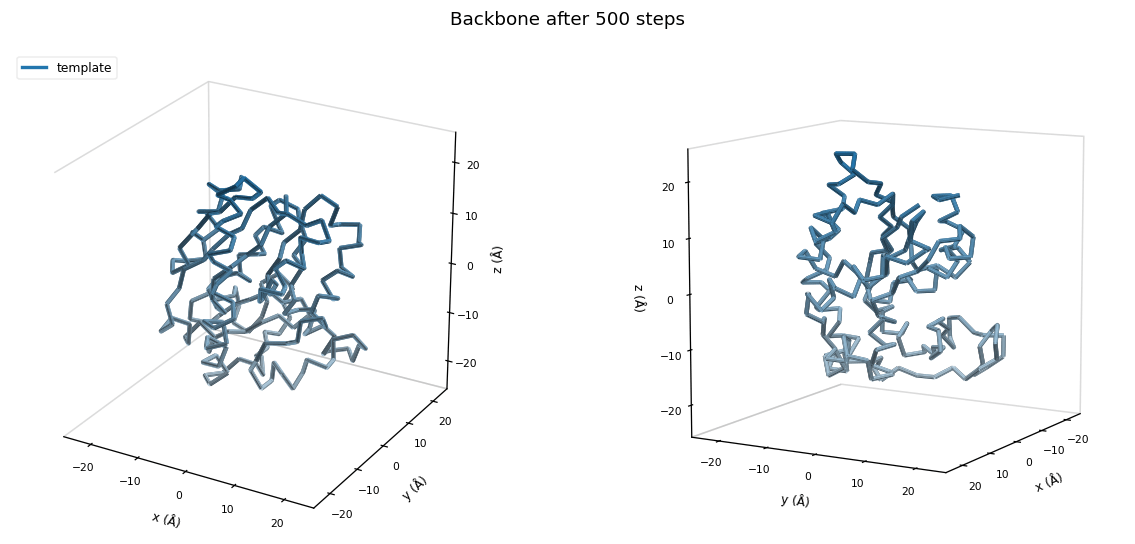
Goal to reconstruct
Template
in 30 seconds (by a maths person)
X-ray tube
Test object
Detector
Rotation
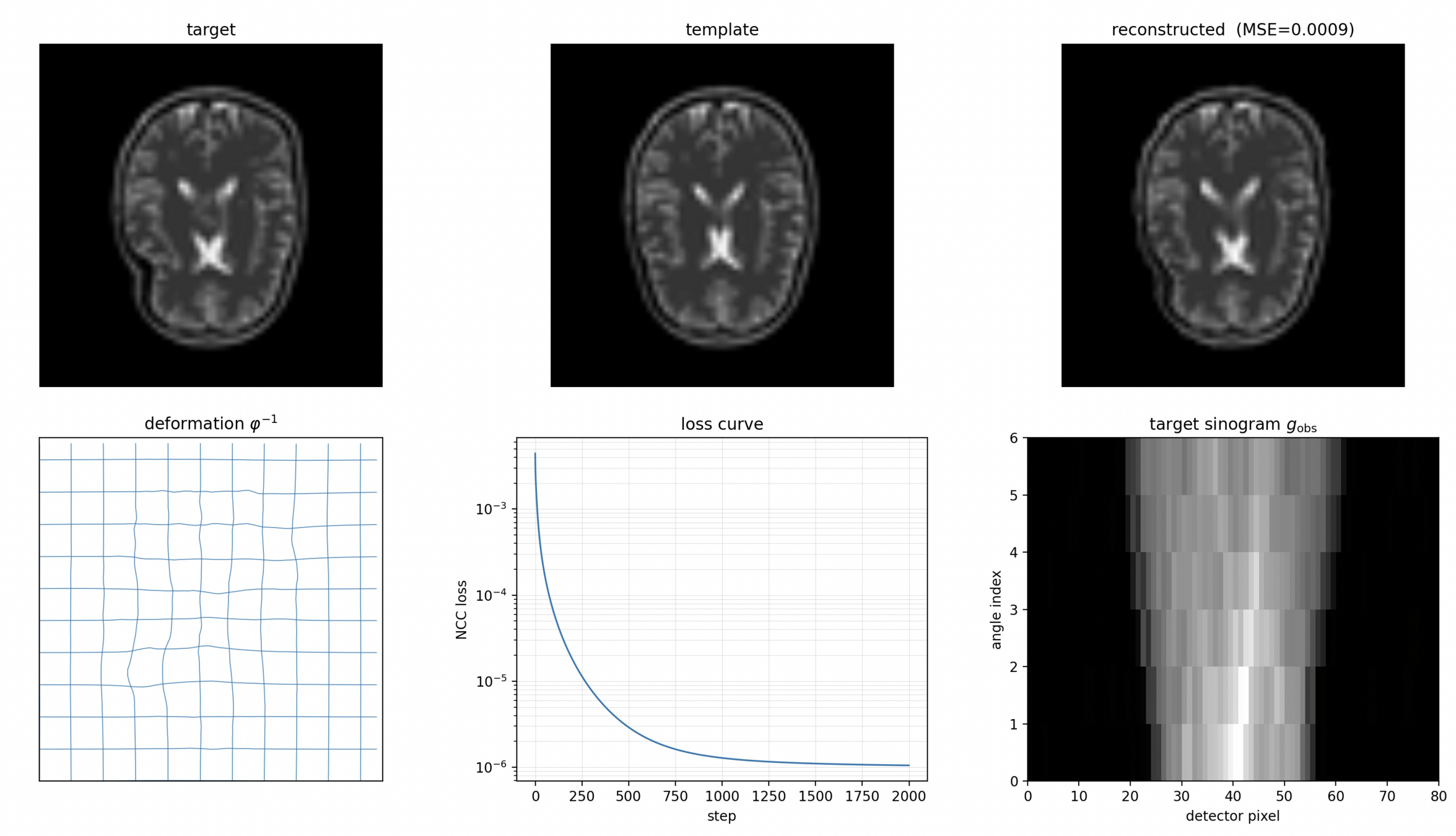
We consider the limited angle (angle X-ray tube can slide to most 60 degrees)
sparse (only six angles) tomography.
Data
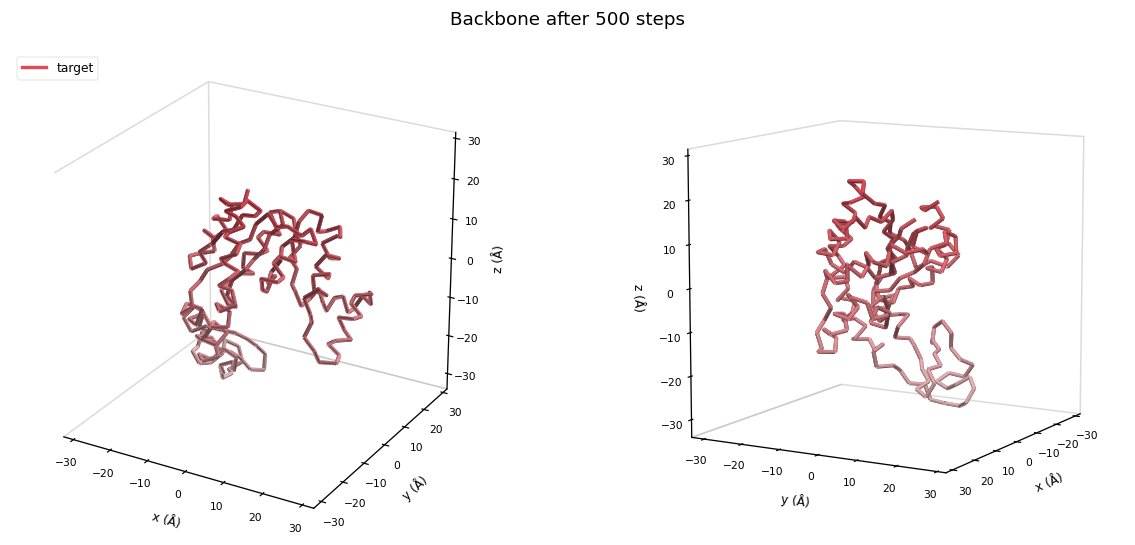
Target
Two classic reconstructions
"Our" reconstruction
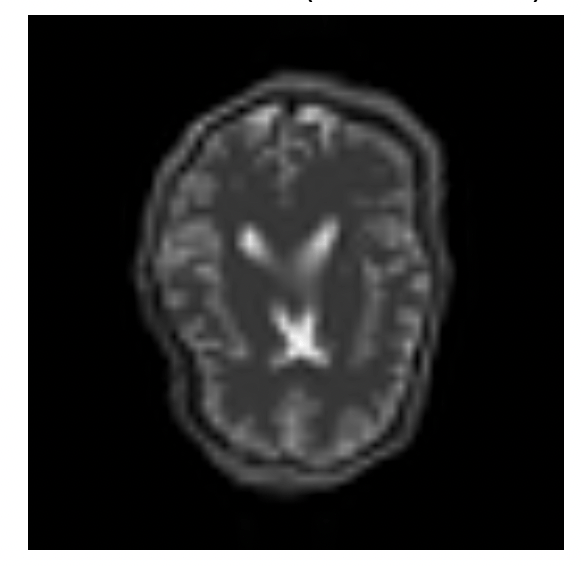
We are imaging a brain: anatomical prior
Data
Target
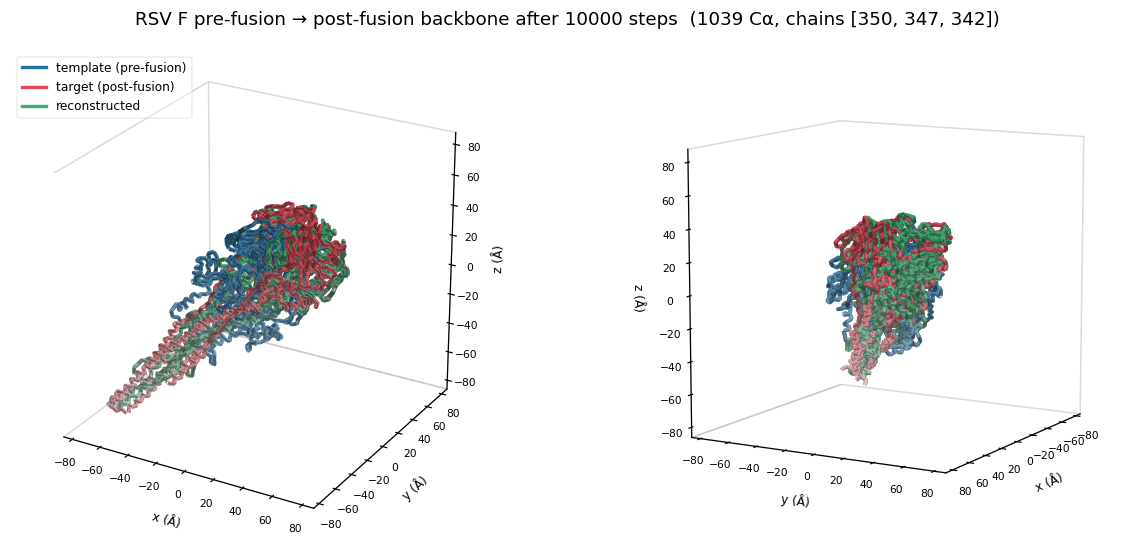
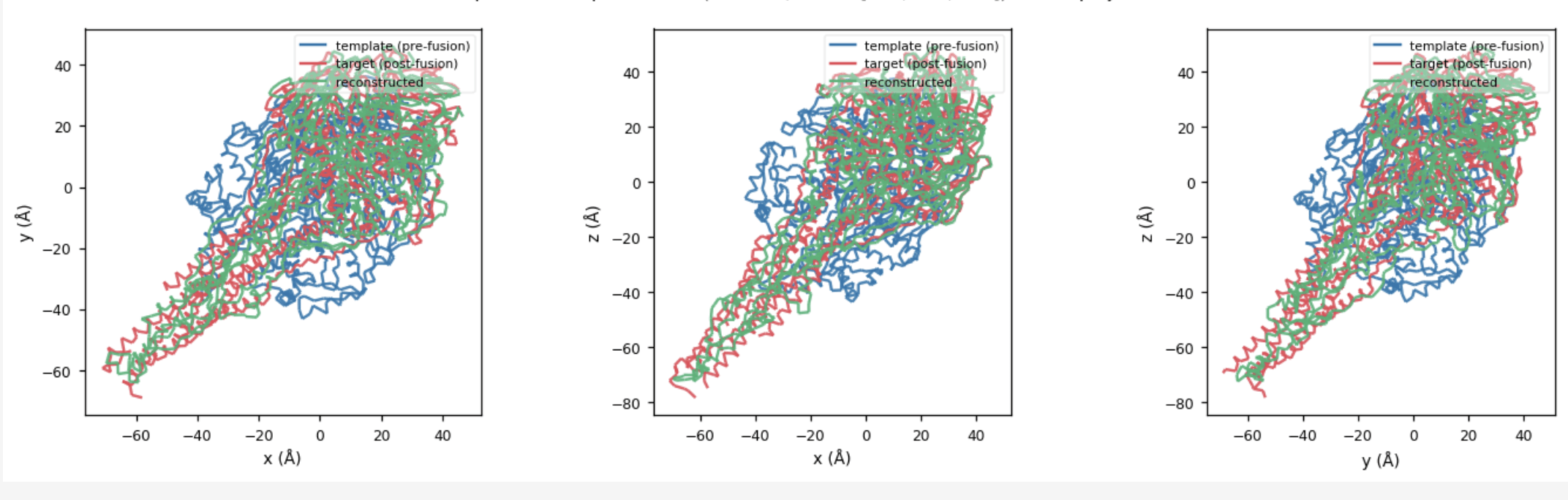
Template
Deform a template to match an indirectly observed target
Stage is set for some shape matching!
Shapes are in a (metric) space \(V\) acted upon by a Lie group of deformations \(G\).
Deformations \(\gamma\) is endpoint of curve \(\gamma \colon [0,1] \to G \)
Right-invariance of metric
Geometric framework remains the same.
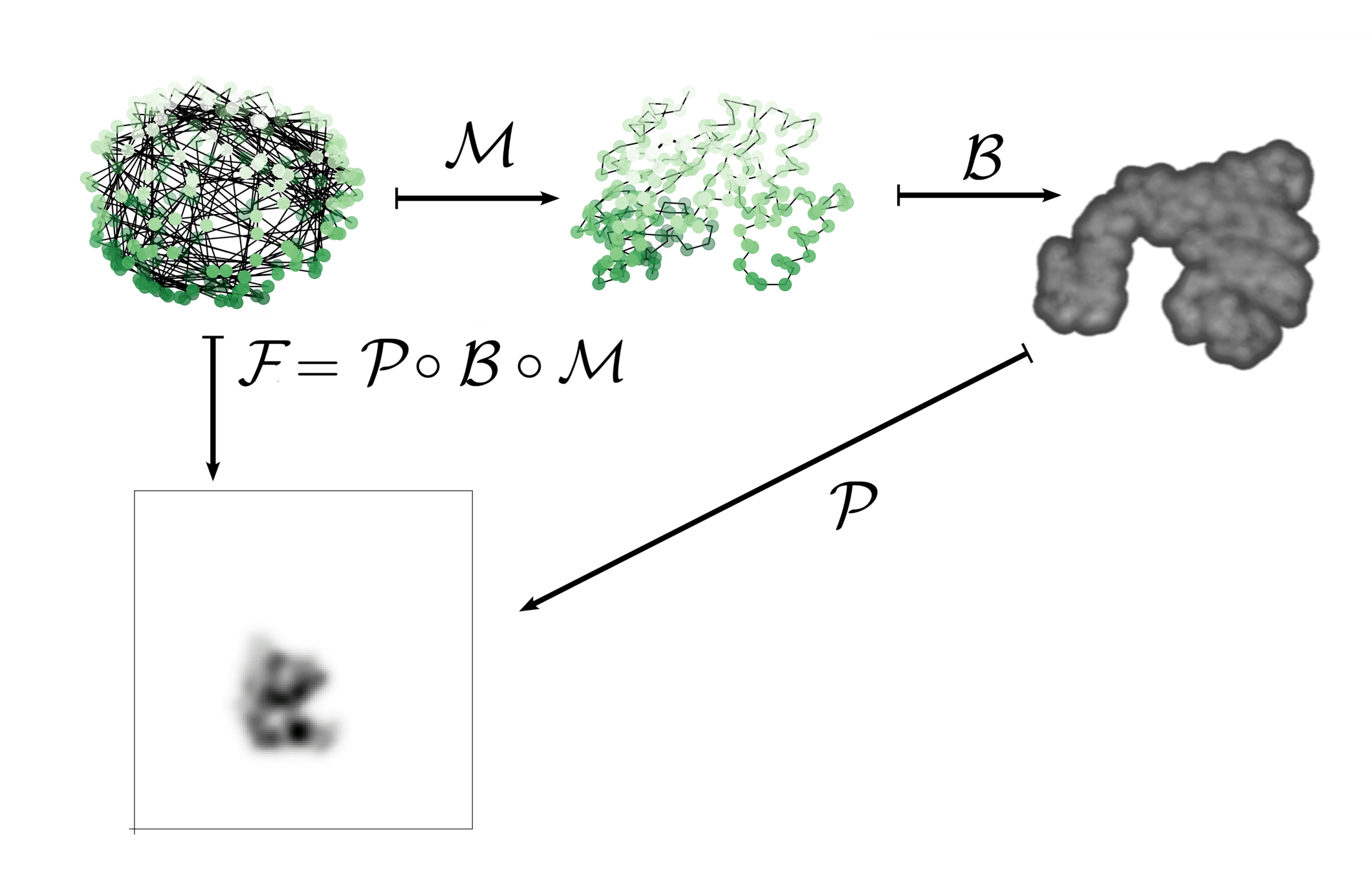
Include a forward operator \(\mathcal{F}\colon V \to Y\)
Reconstructs the \(\gamma(1).A\) that best would map to \(B\)
Following Balehoskwy, Karlsson and Modin, there might be a faster way
Gradients are Riemannian object, so equip \(G\) with a right-invariant metric.
Translate vectors back to algebra, map one to dual with inertia operator, take duality pairing
The Lie group action on the shape space induces a momentum map
Let \(f\colon V \to \R\) and take \(E(g) = f(\Phi(g,w))\)
\(\Phi\colon G \times V \to V\) is the group action
Let \(y \in Y\) be observed data
Set \(f = \mathcal{L}_y \circ \mathcal{F} \) for data loss function \(\mathcal{L}_y \colon Y \to \mathbb{R} \) and forward model \(\mathcal{F}\colon V \to Y\)
Then \(E(g) = \mathcal{L} \circ \mathcal{F} \circ \Phi(g,w)\) is a indirect matching loss!
We would like to minimize:
So we run:
A question: isn't this just greedy matching?
No, because we can easily regularize: Extend shape space \(V' = V \times V_R\), where the action of \(G\) on \(V_R\) is something that we should keep small (i.e., metric, background density, etc. Depends on group and problem)
Goal to reconstruct
Template
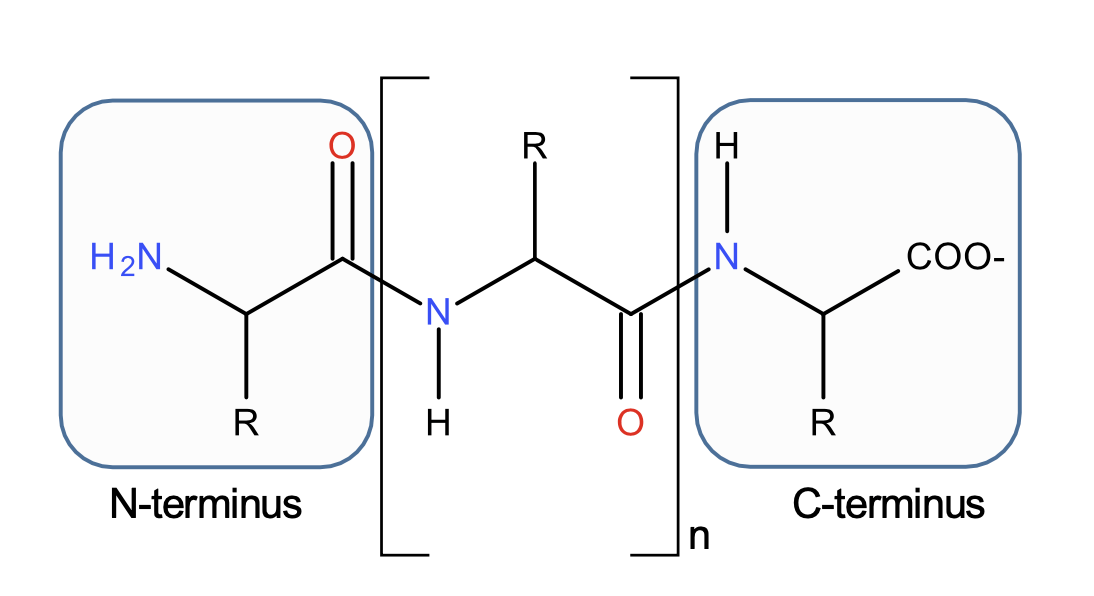
Proteins in 30 seconds (by a mathematician)
In this work: forget about everything but the \(C_\alpha\)s
Relative positions
\((\mathbb R^3)^N\)
Mathematical model for proteins
Shape space: space of relative positions \(V = \mathbb{R}^{3N}\)
Data space - M 2D images, \(L^2(\mathbb{R}^2)^M\)
We want rigid deformations, so \(G = \operatorname{SO}(3)^N\)
Action of rotations on relative positions ensures that a deformed protein backbone looks like a protein backbone
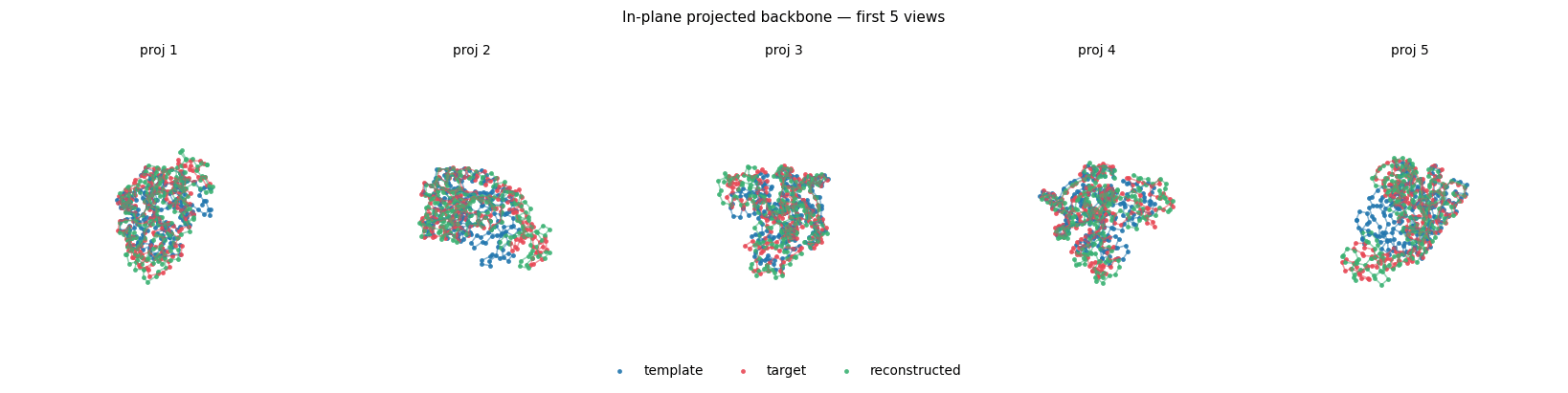
In the end: Each image with one projection and forward model \(\mathcal{F}_j, j = 1,\ldots, M\)
We use NCC as a similarity measure, i.e., \(\mathcal{L}_y(y') = \sum_i \alpha_i(1-\frac{\langle y_i,y_i'\rangle}{\|y_i\|\|y_i'\|})\)
Group action \(\Phi\) by element-wise multiplication,
momentum map is angular momentum in each component
\(y_1, \ldots y_M\) are micrographs,
The adjoint is easy to derive but results in rather unaesthetic expression
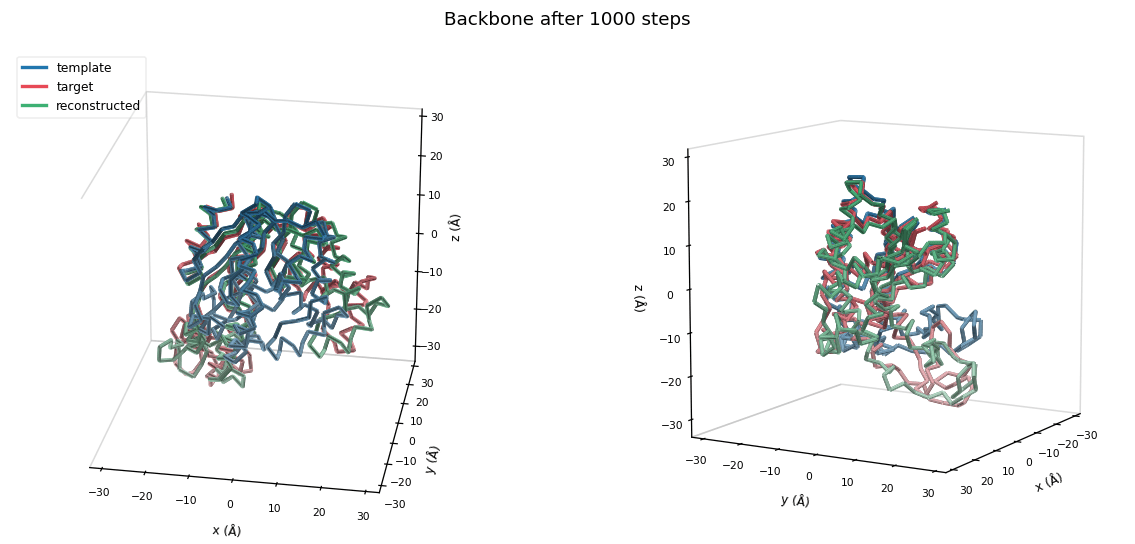
210 residues, ADK, one chain (monomer)
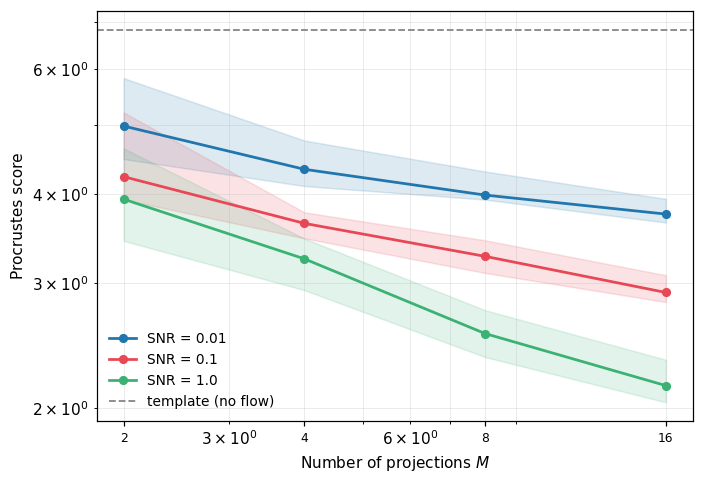
More projections = Good
Less noise = good
Reconstruction to multimer proteins is straightforward.
Here: 3 Chains, each of ~340 residues, in total 1039 residues
In finite dimensions
(on a compact group)....
Global well-posedness is easy to prove!
As are the properties of the IP
Momentum map of action \(\Phi(g,w) = w\circ g^{-1}\)
The unregularized gradient flow is given by:
How and why to regularize?
Observations
Reconstruction
Target
Runs in a few seconds (but quite small images)
But now turn up the noise... (a factor 100, so not super realistic)
Reconstruction quality starts to deterioriate!
Recovers regularization part of a gradient flow from Bauer et al.
Recovers regularization part of a gradient flow from Balehowsky et al.
Extend shape space and re-apply momentum map (which now is a sum)
Big question for me: Well-posedness.
For example, in tomography, pseudodifferential operators inside the GF appears.
Bit messy, but maybe Ebin–Marsden saves the day?
Fast and easy to converge
Comparable reconstructions to LDDMM
Easy to regularize
(but this is a story for another time)
By Erik Jansson




