Introducción al Data Science y Big Data con Apache Spark

Favio Vázquez
Cosmólogo y Data Scientist


@faviovaz





19 de mayo de 2017

Seguir presentación en vivo

Repositorio de la charla
¿Quién soy?
- Venezolano
- Licenciado en Física e Ingeniero en Computación
- Estudiante de Maestría en el PCF-UNAM
- Data Scientist
- Colaborador del Proyecto de Apache Spark en GitHub



Releases 1.3.0, 1.4.0, 1.4.1 y 1.5.0


Resumen

¿Qué es el Big Data?
Actual paradigma en Big Data
¿Quién es un Data Scientist?
Apache Spark
Databricks
Demo (Spark + Databricks)
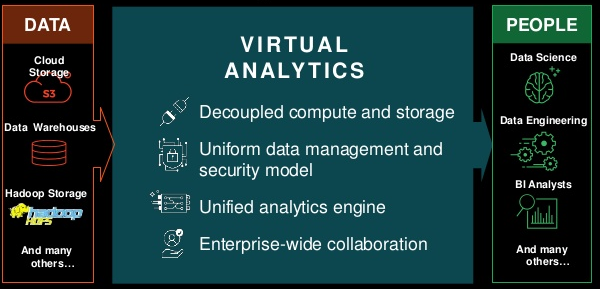
Big Data

¿Qué es?
Son los diversos tipos de procesos y estrategias de recolección, guardado y análisis que incluyen e integran distintos tipos de datos que no podrían ser estudiados con técnicas tradicionales de minería de datos.

Big Data
Nuevo Paradigma
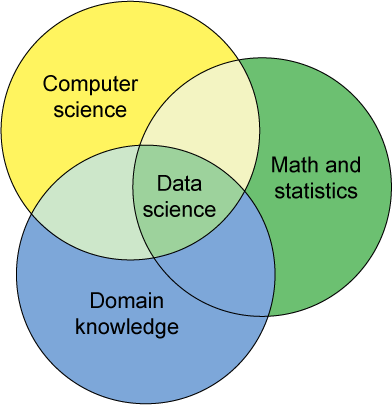
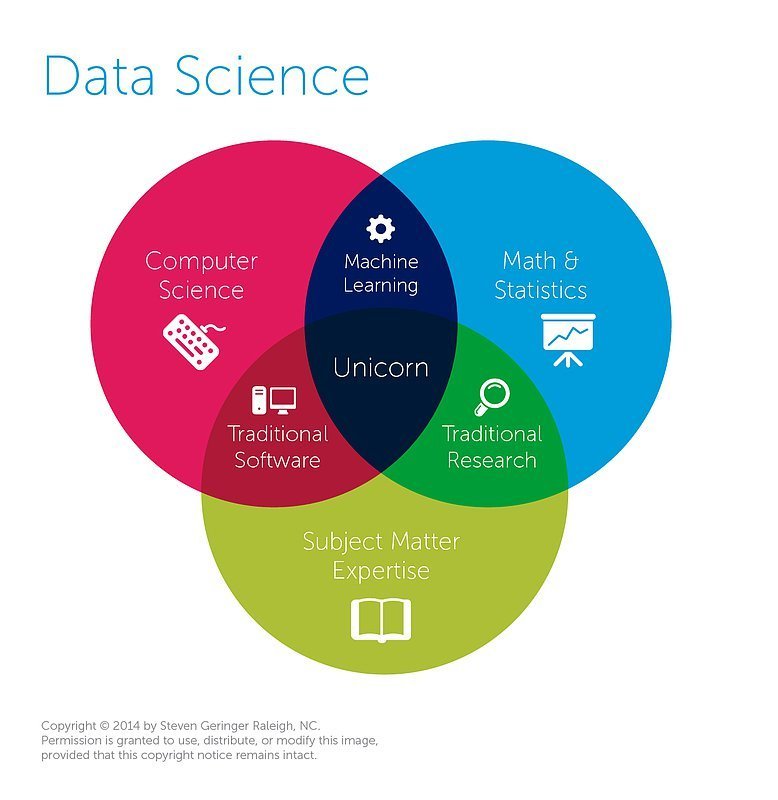
Data Scientist
¿Quién es?

El encargado de saber todo lo necesario para poder utilizar las herramientas, lenguajes, plataformas y sistemas usados para analizar datos (tanto a pequeña como a gran escala)

Data Scientist
¿Qué debe saber?



¿Qué es complicado en Big Data?
La combinación compleja de hilos de ejecución, sistemas de almacenamiento y modos de trabajo.
- ETL, agregaciones, machine learning, streaming, etc.
Muy complicado obtener productividad y performance
¿Qué es?
Es un motor general y muy rápido para el procesamiento en paralelo de datos en gran escala.




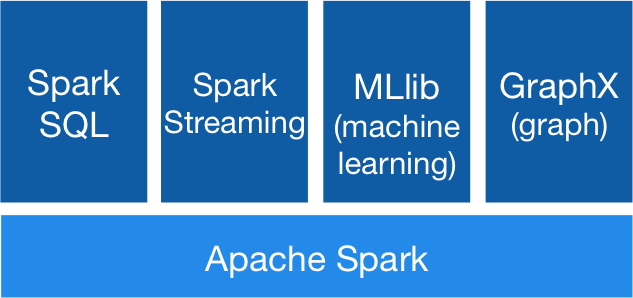

Motor Unificado
APIs de alto nivel con espacio para optimizar
- Expresa todo el workflow con una API
- Conecta librerías existentes y sistemas de almacenamiento
RDD
Transformaciones
Acciones
Caché
Dataset
Tipado
Scala y Java
Beneficios de RDD
Dataframe
Dataset[Row]
Optimizado
Versátil
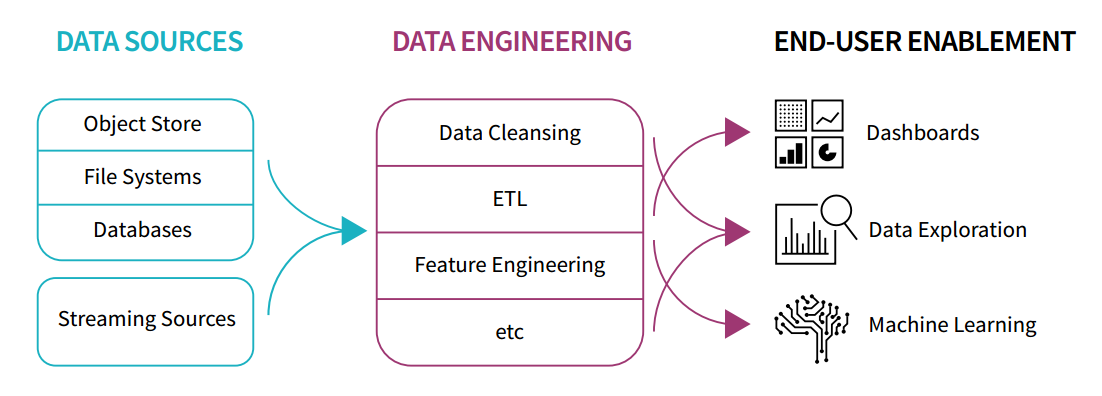



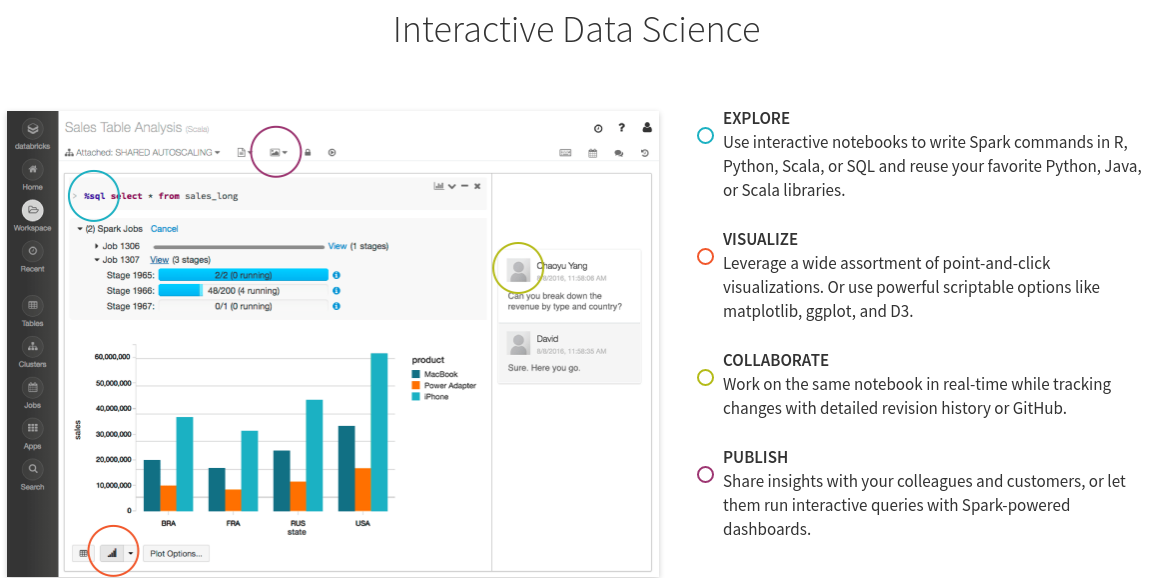
DEMO

DEMO


DEMO


¿Preguntas? ¿Dudas?
Favio Vázquez
Cosmólogo y Data Scientist
@faviovaz

Apache Spark
Introducción al Data Science y Big Data con Apache Spark
By Favio Vazquez
Introducción al Data Science y Big Data con Apache Spark
Charla a dar el 19 de mayo en el IA de la UNAM




