




































federica bianco PRO
astro | data science | data for good
Federica Bianco
University of Delaware
Rubin Observatory
Special thanks to A. Bayo
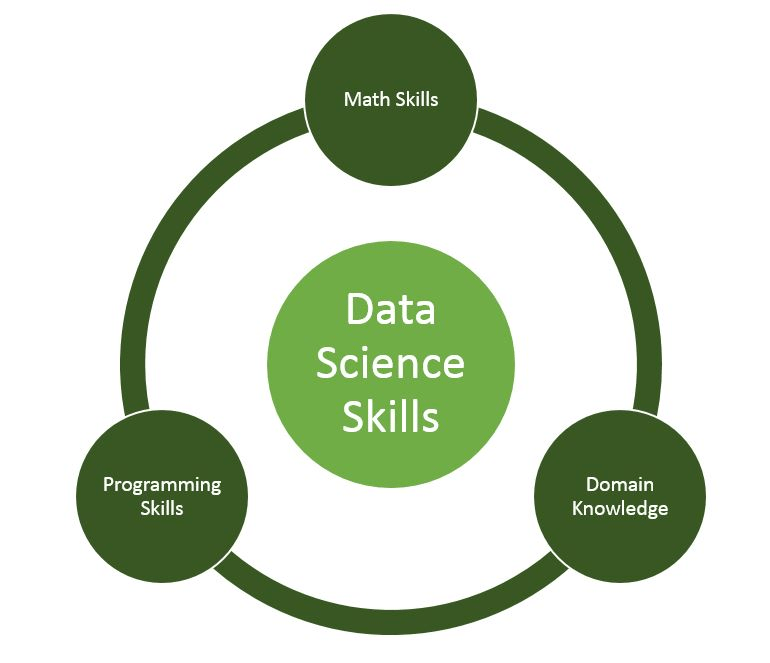
what data science is (not)
1/5
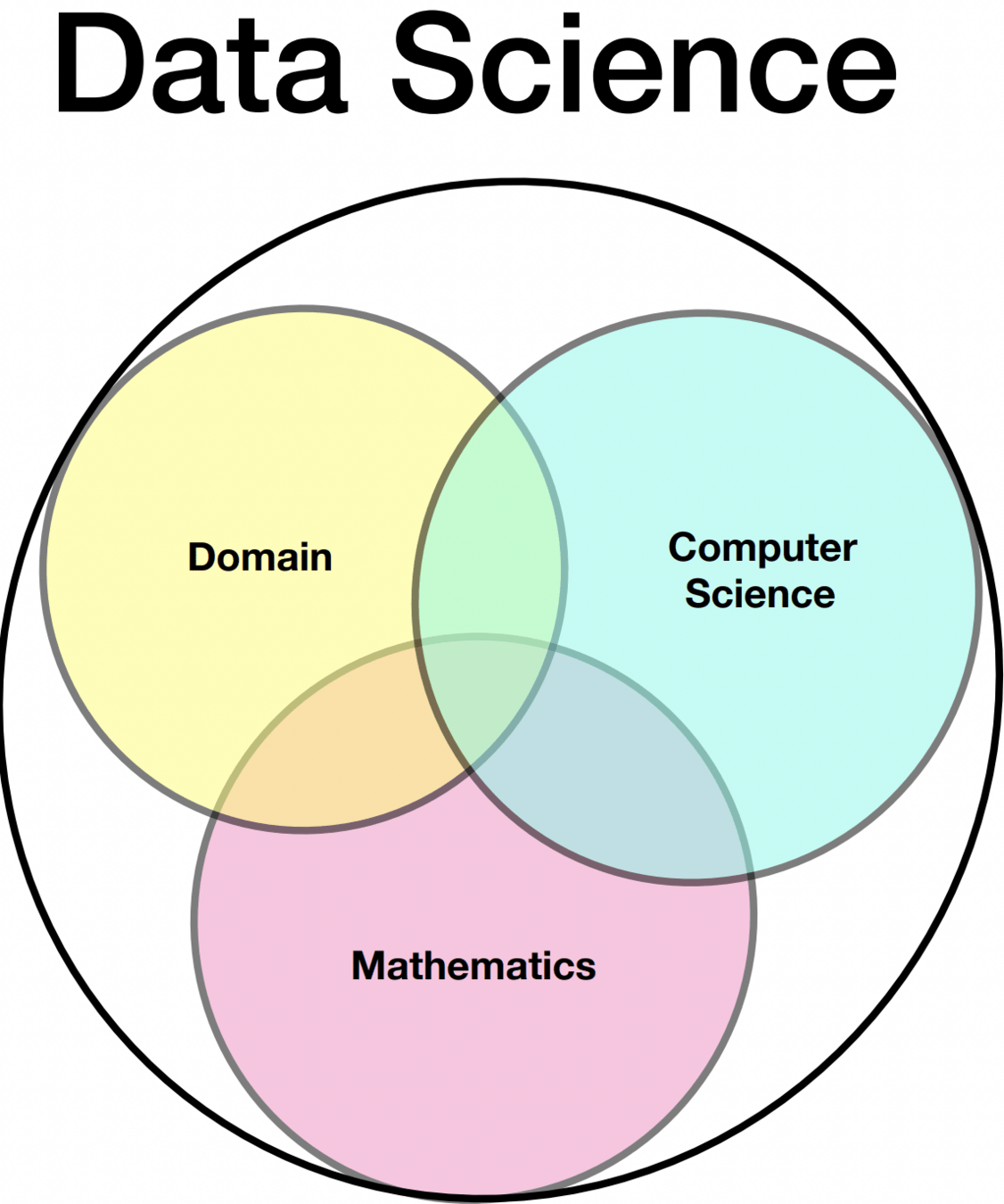
DS = ML
ML:
Machine Learning is the domain that develops, interprets, and applies mathematical model with parameters that are learned from data.
DS:
The discipline that deals with extraction of information from data
DS = ML
ML:
Machine Learning is the domain that develops, interprets, and applies mathematical model with parameters that are learned from data.
DS:
The discipline that deals with extraction of information from data
What is missing??
Life Cycle of a DS project
scientific question
Life Cycle of a DS project
scientific question
Data
collection
Proposal writing
Instrument Building
Calibration
Deployment
Collection
scientific question
Life Cycle of a DS project
scientific question
Data
collection
Proposal writing
Instrument Building
Calibration
Deployment
Collection
scientific question
...Search web for data...
Life Cycle of a DS project
scientific question
Data
collection
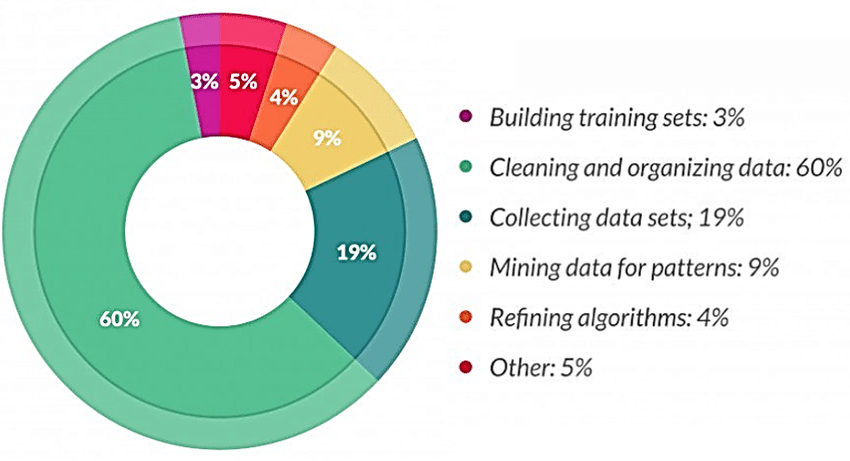
Data preparation and preprocessing for broadcast systems monitoring in PHM framework
Data
Engineering
Data Wrangling
Data cleaning
Feature extraction
Feature engineering
Data
exploration
statistical analysis and extraction of statistical properties
DS = ML
ML:
Machine Learning is the domain that develops, interprets, and applies mathematical model with parameters that are learned from data.
DS:
The discipline that deals with extraction of information from data, including all phases of data driven inference from data collection through modeling and communication, and its interpretation in a domain context
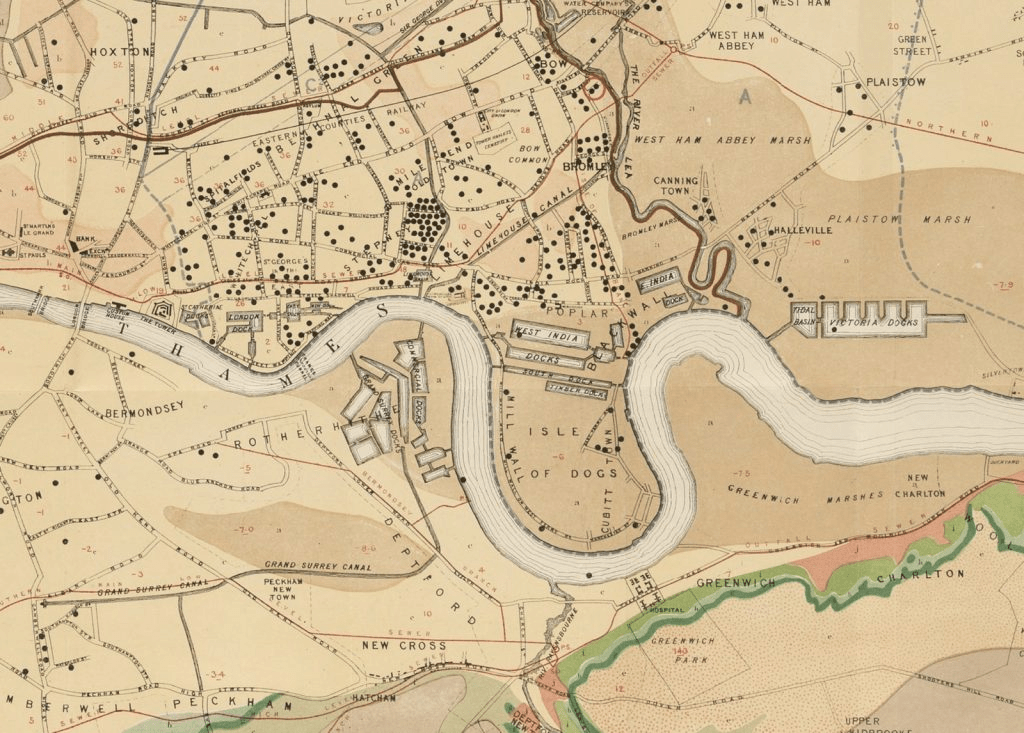
The fist data science project:
John Show map of cholera
Idea driven by domain knowledge (he was a doctor)
Data collection
Data exploration
The fist data science project:
John Show map of cholera
Idea driven by domain knowledge (he was a doctor)
Data collection
Data exploration
digitized data accessibel here https://blog.rtwilson.com/john-snows-cholera-data-in-more-formats/
Life Cycle of a DS project
scientific question
Data
collection
Data
Engineering
Data
exploration
Modeling
Apply ML models
Adapt ML model
Create ML model
Modeling
Apply ML models
Adapt ML model
Create ML model
Life Cycle of a DS project
scientific question
Data
collection
Data
Engineering
Data
exploration
Modeling
Modeling
Communication
of results
Visualize data
Visualize results
Tell the story
Paper
Report
Presentation
Blog post...
The fist data science project:
John Show map of cholera
Idea driven by domain knowledge (he was a doctor)
Data collection
Data exploration
Communication
what's astronomy got to do with it
2/5
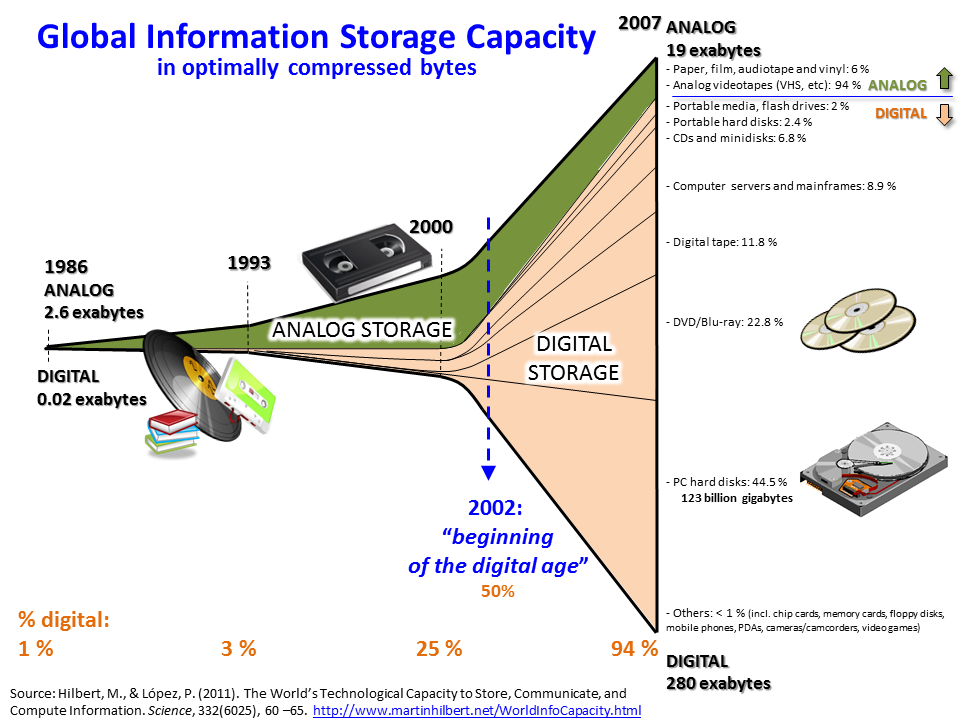
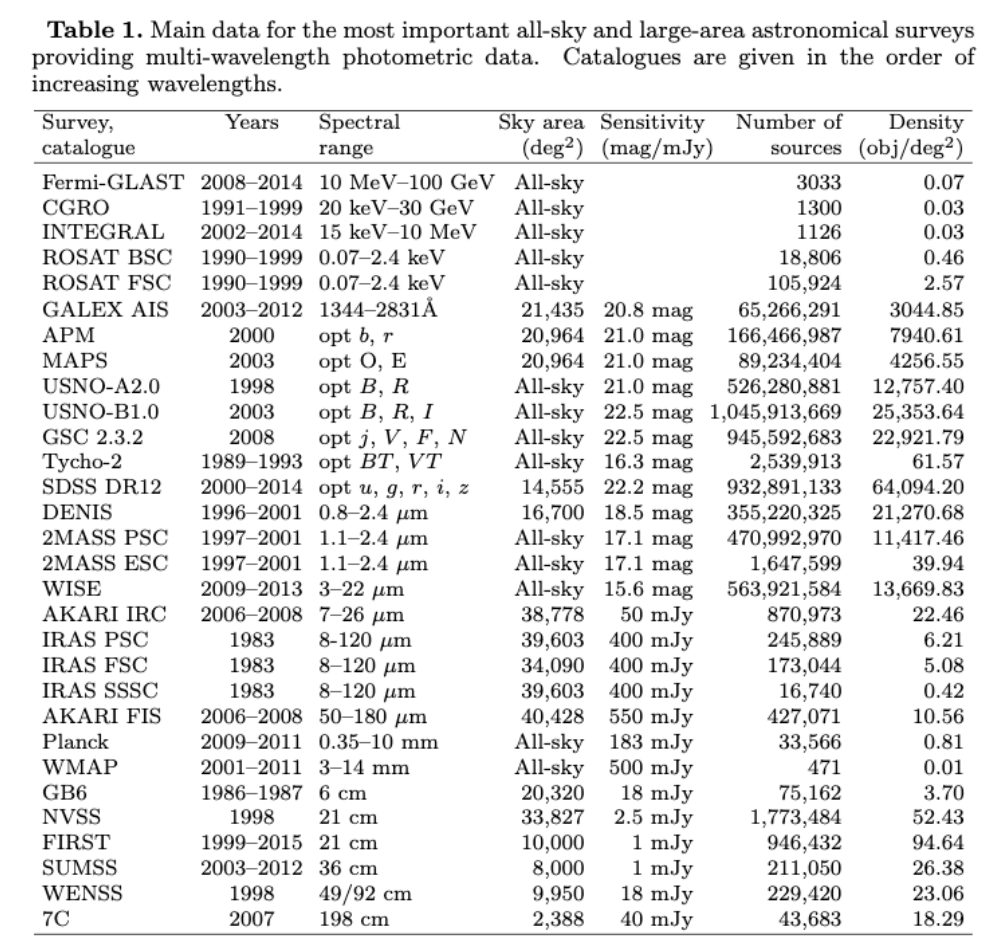
"Data that does not fit in memory"
Both data volumes and data rates grow exponentially, with a doubling time ~ 1.5 years
It is also estimated that everyone has access to 50% of the existing data!
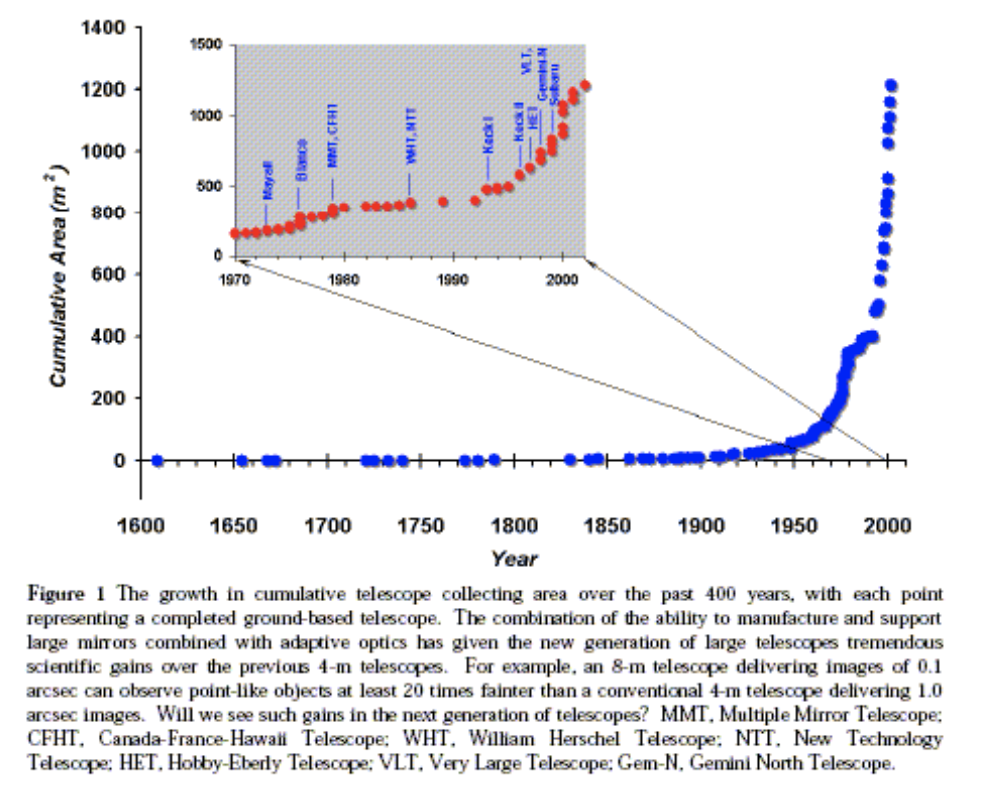
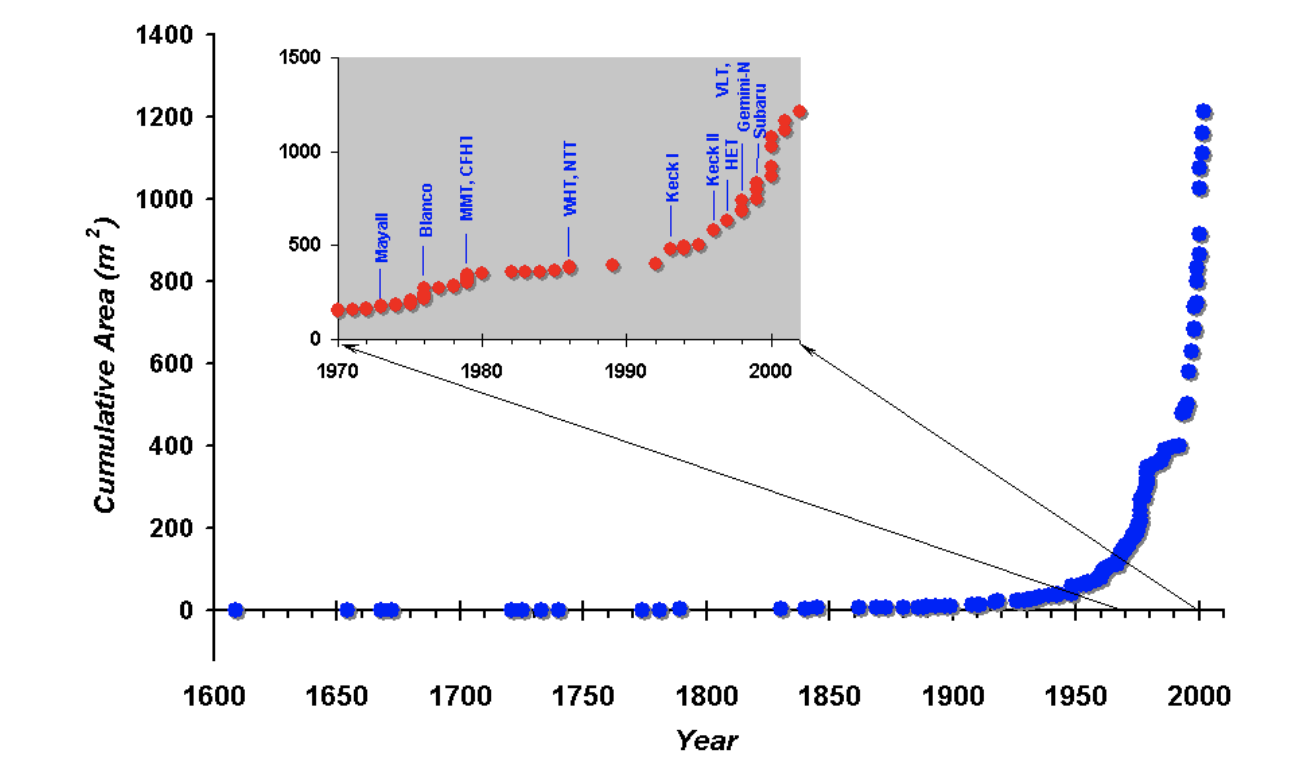
Area vs Volume
number of sources
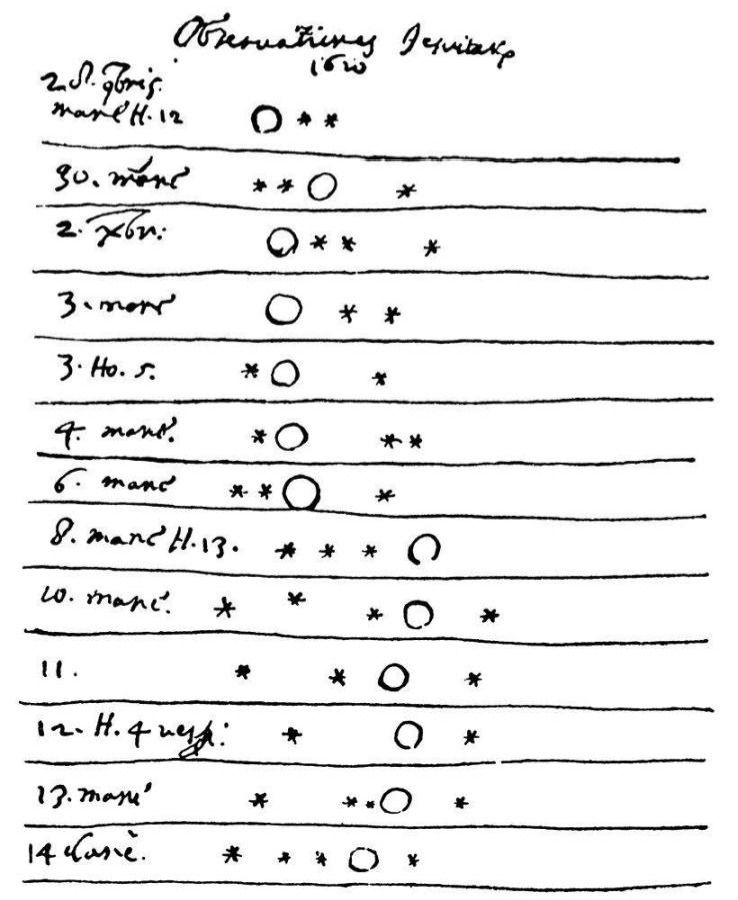
Galileo Galilei 1610
Following: Djorgovski
https://events.asiaa.sinica.edu.tw/school/20170904/talk/djorgovski1.pdf
Experiment driven
Enistein 1916
Theory driven | Falsifiability
Experiment driven
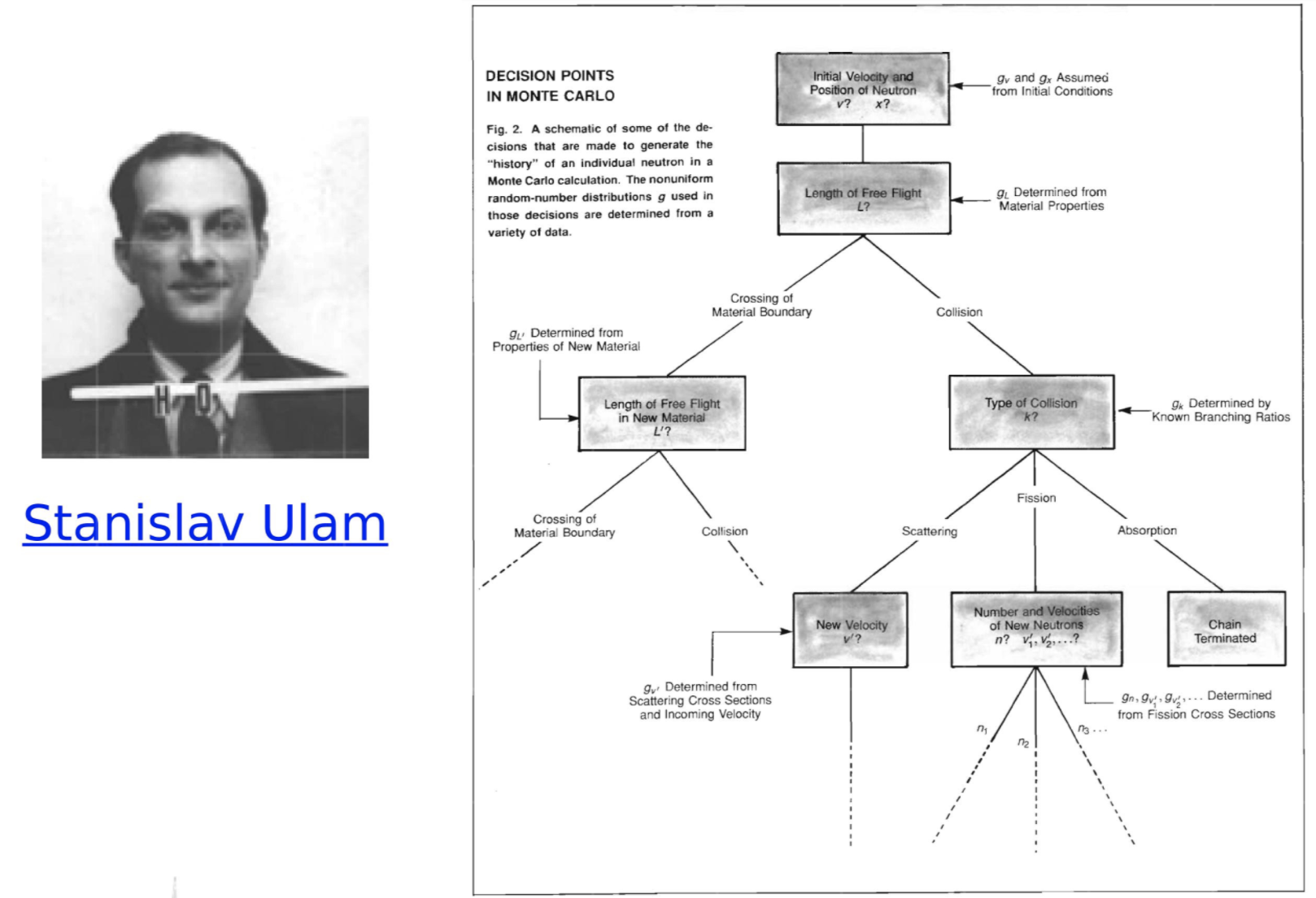
Ulam 1947
Theory driven | Falsifiability
Experiment driven
Simulations | Probabilistic inference | Computation
http://www-star.st-and.ac.uk/~kw25/teaching/mcrt/MC_history_3.pdf
Theory driven | Falsifiability
Experiment driven
Simulations | Probabilistic inference | Computation
Ulam 1947
the 2000s
Theory driven | Falsifiability
Experiment driven
Simulations | Probabilistic inference | Computation
Data | Survey astronomy | Computation | pattern discovery
Theory driven | Falsifiability
Experiment driven
Simulations | Probabilistic inference | Computation
Data | Survey astronomy | Computation | pattern discovery
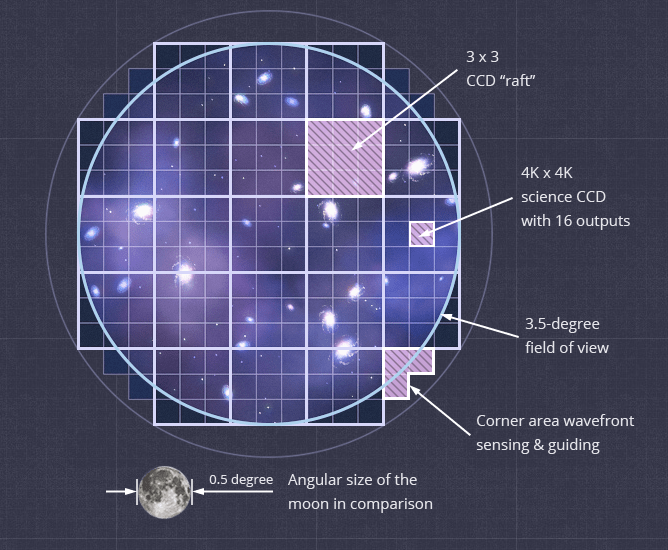
3.2 Gpix Rubin camera
the 2000s
Theory driven | Falsifiability
Experiment driven
Simulations | Probabilistic inference | Computation
Data | Survey astronomy | Computation | pattern discovery
3.2 Gpix Rubin camera
lazy learning
learning by example
(supervised learning)
pattern discovery
(unsupervised learning)
telescope size
FoV
camera size
resolution
fainter, more distant
more sky area at once
more data units
more objects/details
filters
variety (complexity)
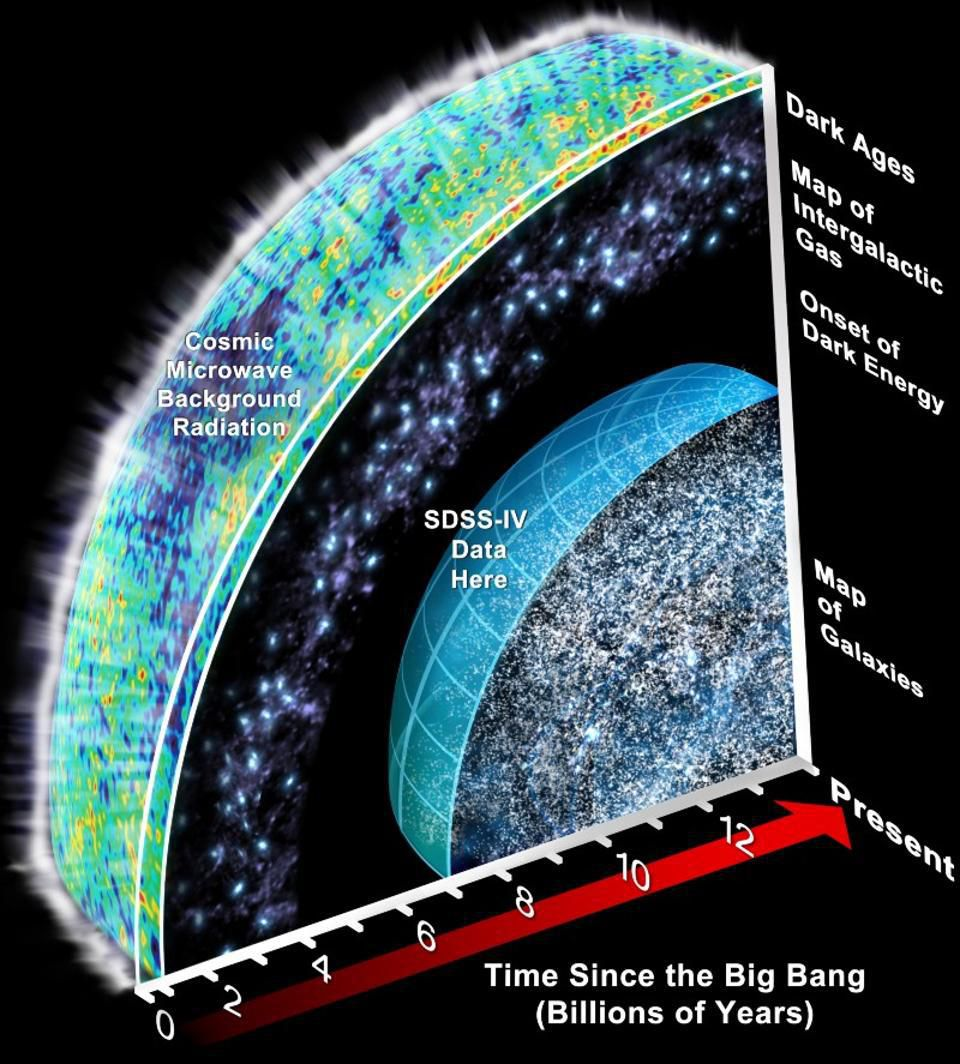
"The Sloan Digital Sky Survey has created the most detailed three-dimensional maps of the Universe ever made, with deep multi-color images of one third of the sky, and spectra for more than three million astronomical objects. Learn and explore all phases and surveys—past, present, and future—of the SDSS."
2.5m
6 sq degree
4Mpix
1''/pix
5 bands
| SDSS DR | images | catalog | 1D+2D spectra |
|---|---|---|---|
| 2003 DR1 | 2.3Tb | 0.5Tb | |
| 2003 DR2 | 5Tb | 0.7Tb | |
| 2004 DR3 | 6Tb | 1.2Tb | |
| ... | |||
| 2009 DR7 | 15.7Tb | 18Tb | 3.5 TB |
| ... | |||
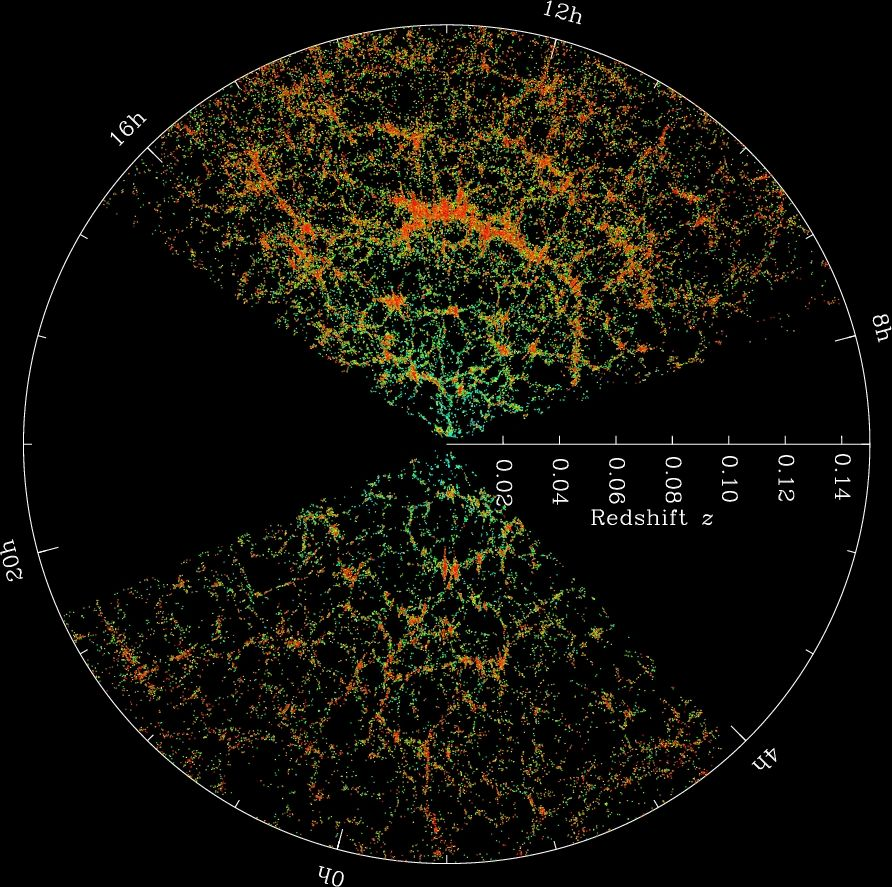
The SDSS map of the Universe. Each dot is a galaxy; the color bar shows the local density.
2019 DR16
273 TB
photometric parameters for 53 million unique objects.
2019 DR2 PanSTARRS
1.6 Pb
The amount of imaging data is equivalent to two billion selfies, or 30,000 times the total text content of Wikipedia. The catalog data is 15 times the volume of the Library of Congress.
1.8m
7 sq degree
1.4Gpix
0.26''/pix
6 bands
| Number of raw on-sky camera exposures ingested: | 40,000 | 23 TB |
|---|---|---|
| Volume (with ancillary files): | 195 TB | |
| Number of lightcurves | 319 | 110 GB |
4m
3 sq degree
96 Mpix
0.2''/pix
570 MP camera with a 3 deg2 field of view installed at the prime focus of the Blanco 4 m
0.5Gpix
0.2''/pix
5 bands
1.2m
0.5Gpix
1.2m
47 sq degree
1''/pix
2
band
1.2m
3.2Gpix
8m (6.5 effective)
9 sq degree
0.2''/pix
6 bands
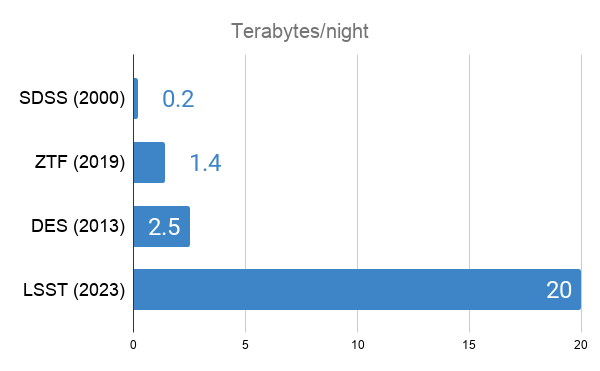
Nightly data rates
FITS files: universal data storage
Strong pressure on making data public
Strong tradition of collaboration
Still lack of trust in cloud services
sparse collaboration between institutes generating solutions, a ton of platforms that work differently
slow integration of methods
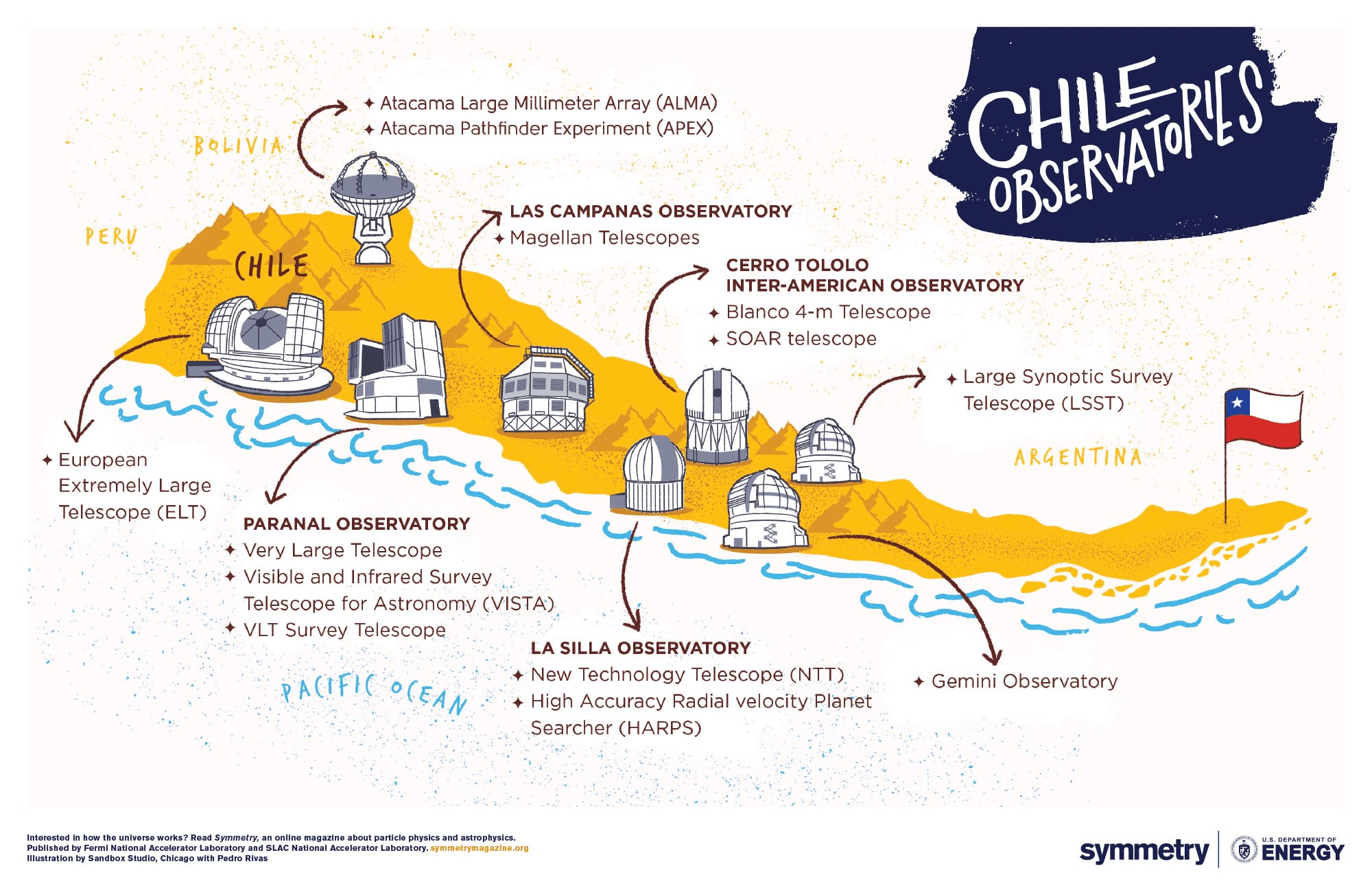
La Serena School for Data Science
3/5
What does astronomy have to do with it??
slide credit: A. Bayo
We propose to meet the need for scientists with experience in using these tools and techniques by beginning to train advanced undergraduates and beginning graduate students today.
You!
4/5
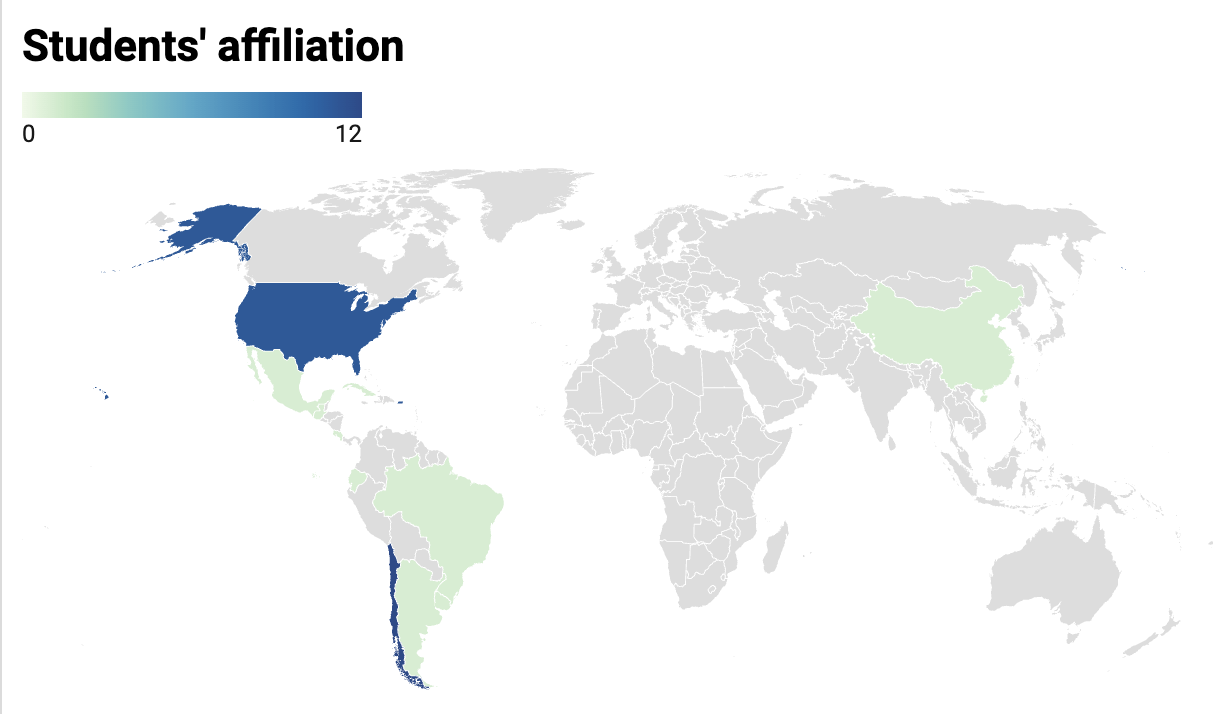
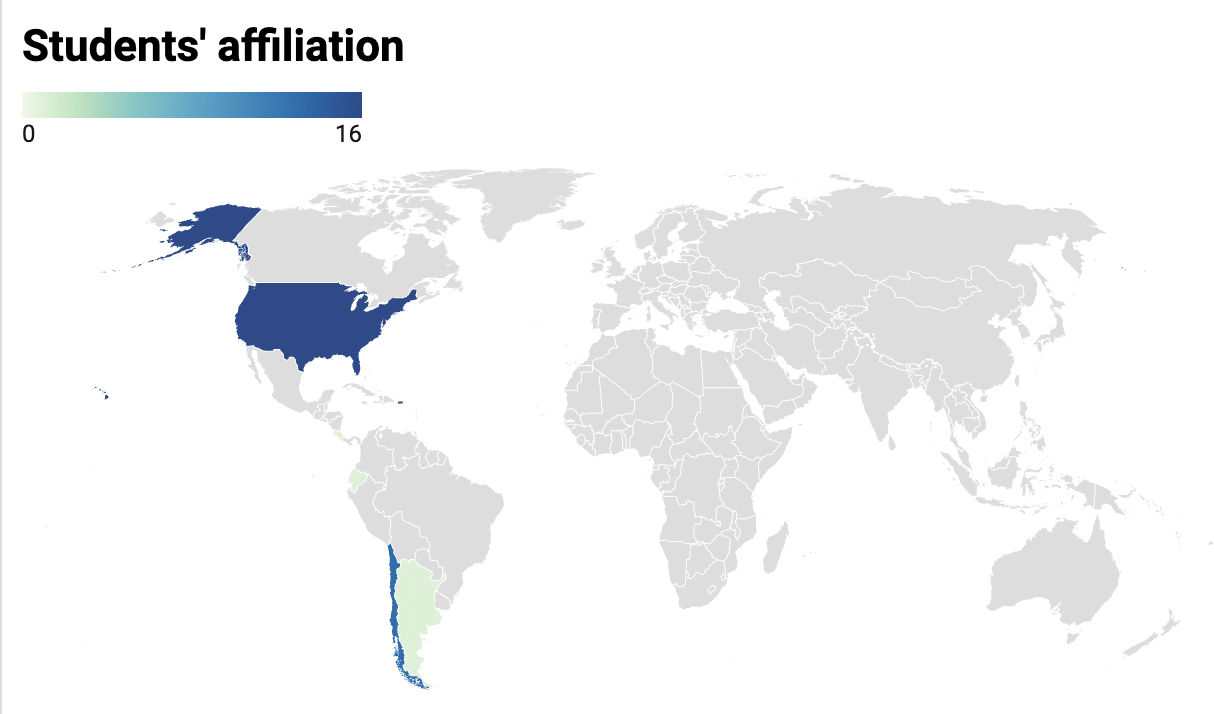
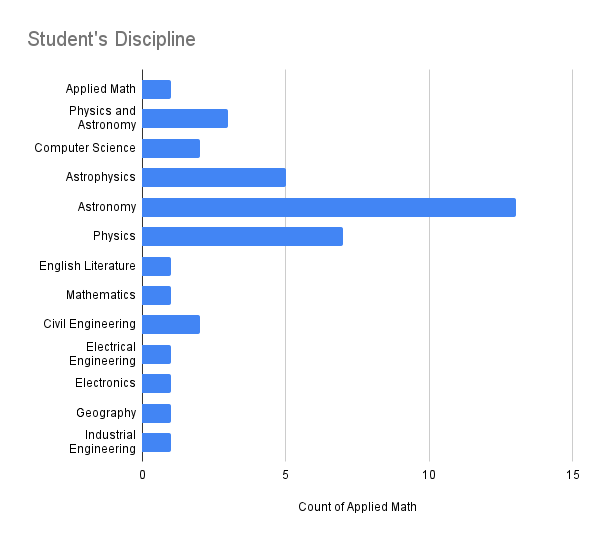
Country of Affiliation
| United States |
| Costa Rica |
| Ecuador |
| Argentina |
| Chile |
| Cuba |
| Brazil |
| Mexico |
| China |
| Guatemala |
| Uruguay |
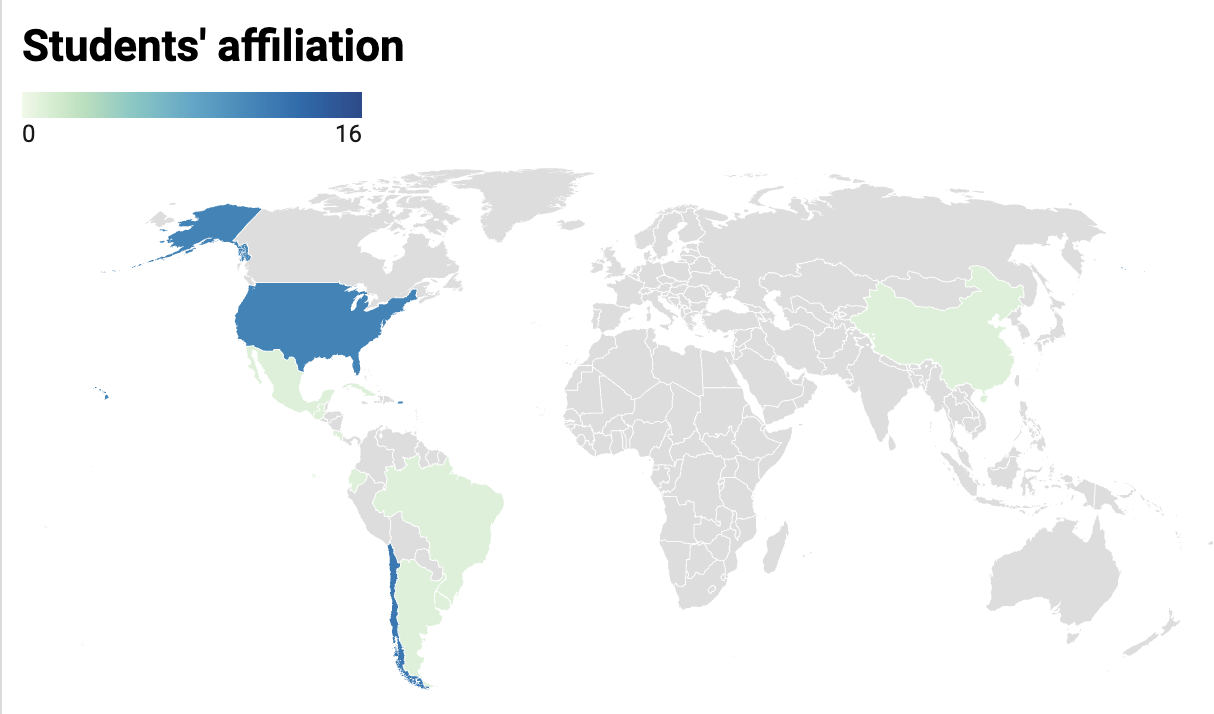
Country of Nationality
| United States |
| Costa Rica |
| Ecuador |
| Argentina |
| Chile |
Astronomical Data Acquisition,
Introductory Probability and Statistics,
Data Processing Pipelines and their output,
Astronomical Databases,
Tools of the Virtual Observatory,
Tools of High Performance Computing,
Advanced Statistical tools applied to Astronomy.
The Ethics of DS and AI
5/5
What is missing??
The main skill that is missing in the portfolio of our new hires is data ethics
the butterfly effect
NGC 4565 is an edge-on spiral galaxy about 30 to 50 million light-years away. The faculty at the LSSDS used a AI model (emulator) to predict the hidden physical parameters of the Galaxy wrongfully estimating the DM content of NCG 4565.
the butterfly effect
NGC 4565 is an edge-on spiral galaxy about 30 to 50 million light-years away. The faculty at the LSSDS used a AI model (emulator) to predict the hidden physical parameters of the Galaxy wrongfully estimating the DM content of NCG 4565.
The galaxy had been banned from all astrophysics media appearances. The galaxy claims emotional damage and loss of revenue
the butterfly effect
the butterfly effect
We use astrophyiscs as a neutral and safe sandbox to learn how to develop and apply powerful tool.
Deploying these tools in the real worlds can do harm.
Ethics of AI is essential training that all data scientists shoudl receive.
November 30, 2022
will be made available to developers through Google Cloud’s API from December 13, 2023
Vinay Prabhu exposes racist bias in GPT-3
Timnit Gebru,
We have identified a wide variety of costs and risks associated with the rush for ever larger LMs, including:
environmental costs (borne typically by those not benefiting from the resulting technology);
financial costs, which in turn erect barriers to entry, limiting who can contribute to this research area and which languages can benefit from the most advanced techniques;
opportunity cost, as researchers pour effort away from directions requiring less resources; and the
risk of substantial harms, including stereotyping, denigration, increases in extremist ideology, and wrongful arrest, should humans encounter seemingly coherent LM output and take it for the words of some person or organization who has accountability for what is said.
Timnit Gebru,
When we perform risk/benefit analyses of language technology, we must keep in mind how the risks and benefits are distributed, because they do not accrue to the same people. On the one hand, it is well documented in the literature on environmental racism that the negative effects of climate change are reaching and impacting the world’s most marginalized communities first [1, 27].
Is it fair or just to ask, for example, that the residents of the Maldives (likely to be underwater by 2100 [6]) or the 800,000 people in Sudan affected by drastic floods pay the environmental price of training and deploying ever larger English LMs, when similar large-scale models aren’t being produced for Dhivehi or Sudanese Arabic?
While the average human is responsible for an estimated 5t CO2 per year, the authors trained a Transformer (big) model [136] with neural architecture search and estimated that the training procedure emitted 284t of CO2. [...]
Timnit Gebru,
4.1 Size Doesn’t Guarantee Diversity The Internet is a large and diverse virtual space, and accordingly, it is easy to imagine that very large datasets, such as Common Crawl (“petabytes of data collected over 8 years of web crawling”, a filtered version of which is included in the GPT-3 training data) must therefore be broadly representative of the ways in which different people view the world. However, on closer examination, we find that there are several factors which narrow Internet participation [...]
Starting with who is contributing to these Internet text collections, we see that Internet access itself is not evenly distributed, resulting in Internet data overrepresenting younger users and those from developed countries [100, 143]. However, it’s not just the Internet as a whole that is in question, but rather specific subsamples of it. For instance, GPT-2’s training data is sourced by scraping outbound links from Reddit, and Pew Internet Research’s 2016 survey reveals 67% of Reddit users in the United States are men, and 64% between ages 18 and 29. Similarly, recent surveys of Wikipedians find that only 8.8–15% are women or girls [9].
Timnit Gebru,
4.3 Encoding Bias It is well established by now that large LMs exhibit various kinds of bias, including stereotypical associations [11, 12, 69, 119, 156, 157], or negative sentiment towards specific groups [61]. Furthermore, we see the effects of intersectionality [34], where BERT, ELMo, GPT and GPT-2 encode more bias against identities marginalized along more than one dimension than would be expected based on just the combination of the bias along each of the axes [54, 132].
Timnit Gebru,
The ersatz fluency and coherence of LMs raises several risks, precisely because humans are prepared to interpret strings belonging to languages they speak as meaningful and corresponding to the communicative intent of some individual or group of individuals who have accountability for what is said.
RAISE ALL VOICES
RAISE ALL VOICES
Federica B. Bianco
University of Delaware
Physics and Astronomy
Biden School of Public Policy and Administration
Data Science Institute
Rubin Observatory Construction
Deputy Project Scientist
Rubin Observatory Operations
Interim Head of Science
fbianco@udel.edu
thank you!
University of Delaware
Department of Physics and Astronomy
Biden School of Public Policy and Administration
Data Science Institute
federica bianco
fbianco@udel.edu
By federica bianco




