









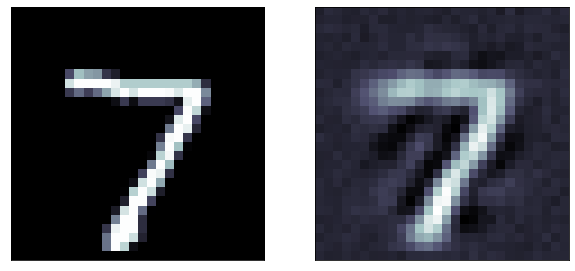
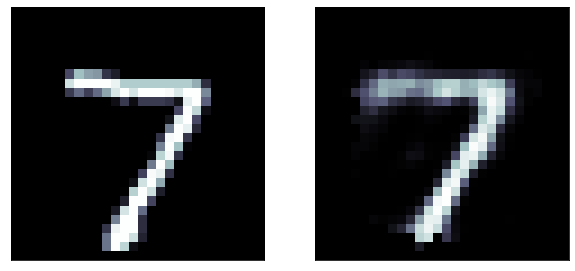
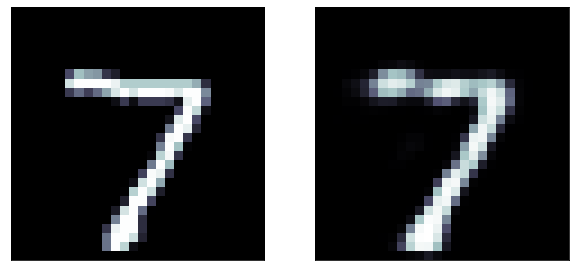
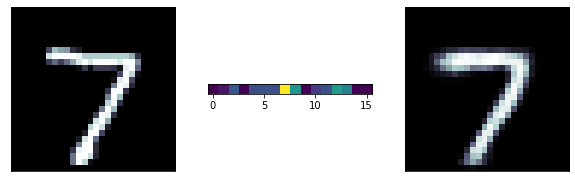
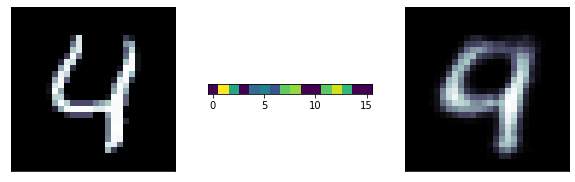
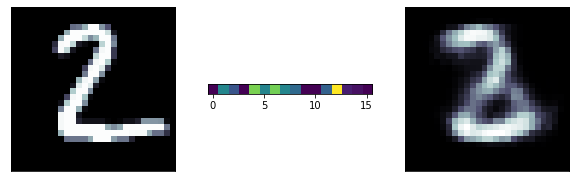




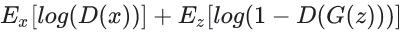
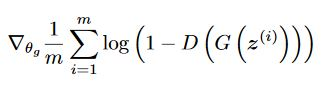
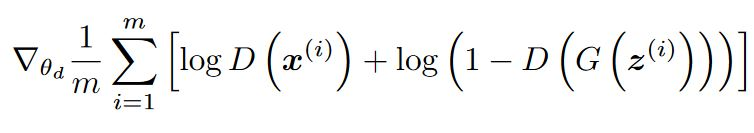


federica bianco PRO
astro | data science | data for good
dr.federica bianco | fbb.space | fedhere | fedhere
Generative AI: autoencoders
this slide deck:
0
x1
x2
b1
b2
b3
b
w11
w12
w13
w21
w22
w23
w: weight
sets the sensitivity of a neuron
b: bias:
up-down weights a neuron
output
layer of perceptrons
w: weight
sets the sensitivity of a neuron
b: bias:
up-down weights a neuron
f: activation function:
turns neurons on-off
w: weight
sets the sensitivity of a neuron
b: bias:
up-down weights a neuron
f: activation function:
turns neurons on-off
output
input layer
hidden layer
output layer
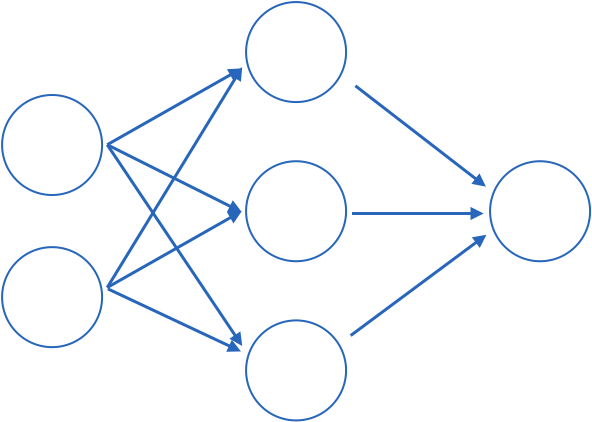
Fully connected: all nodes go to all nodes of the next layer.
output
input layer
hidden layer
output layer
Sparcely connected: all nodes go to all nodes of the next layer.
output
input layer
hidden layer
output layer
Sparcely connected: all nodes go to all nodes of the next layer.
The last layer is always connected
Except this is a very misleading representation
there are no biases or activation functions
each layer should be a different shape
1x3
3x5
5x2
=
2x1
what we are doing is just a series of matrix multiplictions.
what we are doing is exactly a series of matrix multiplictions.
3x5
5x2
2x1
=
what we are doing is exactly a series of matrix multiplictions.
3x5
5x2
2x1
=
what we are doing is exactly a series of matrix multiplictions.
3x5
5x2
2x1
=
what we are doing is exactly a series of matrix multiplictions.
The purpose is to approximate a function φ
y = φ(x)
which (in general) is not linear with linear operations
The purpose is to approximate a function φ
y = φ(x)
which (in general) is not linear with linear operations
output
input layer
hidden layer
output layer
hidden layer
32 parameters and
?? hyperparameters
activation functions -
loss function - 1
optimization method - 1
architecture - M
how many hyperparameters?
Training models with this many parameters requires a lot of care:
. defining the metric
. optimization schemes
. training/validation/testing sets
But just like our simple linear regression case, the fact that small changes in the parameters leads to small changes in the output for the right activation functions.
define a cost function, e.g.
x1
x2
b1
b2
b3
b
w11
w12
w13
w21
w22
w23
0
NN are a vast topics and we only have 2 weeks!
Some FREE references!
michael nielsen
better pedagogical approach, more basic, more clear
ian goodfellow
mathematical approach, more advanced, unfinished
michael nielsen
better pedagogical approach, more basic, more clear
Lots of parameters and lots of hyperparameters! What to choose?
cheatsheet
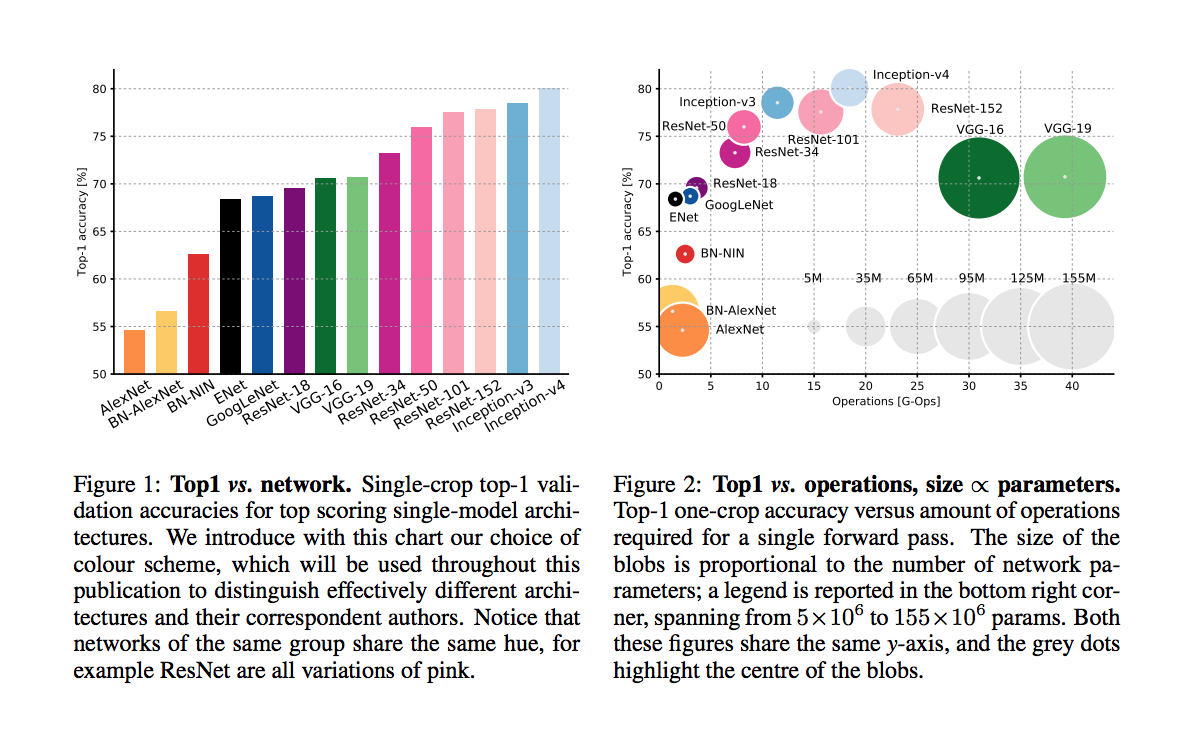
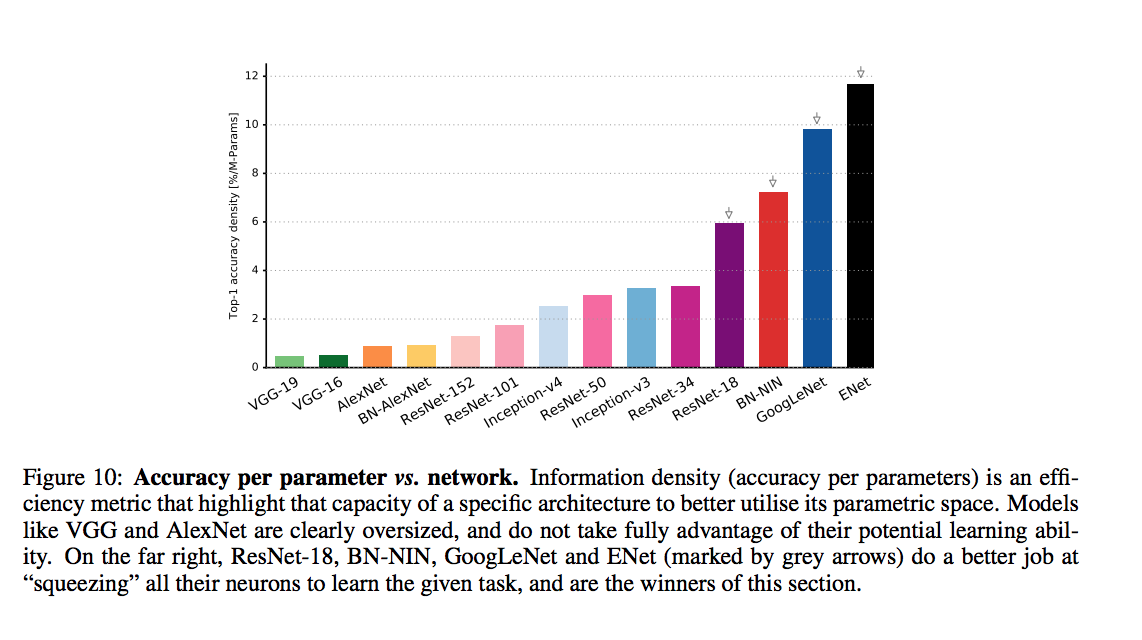
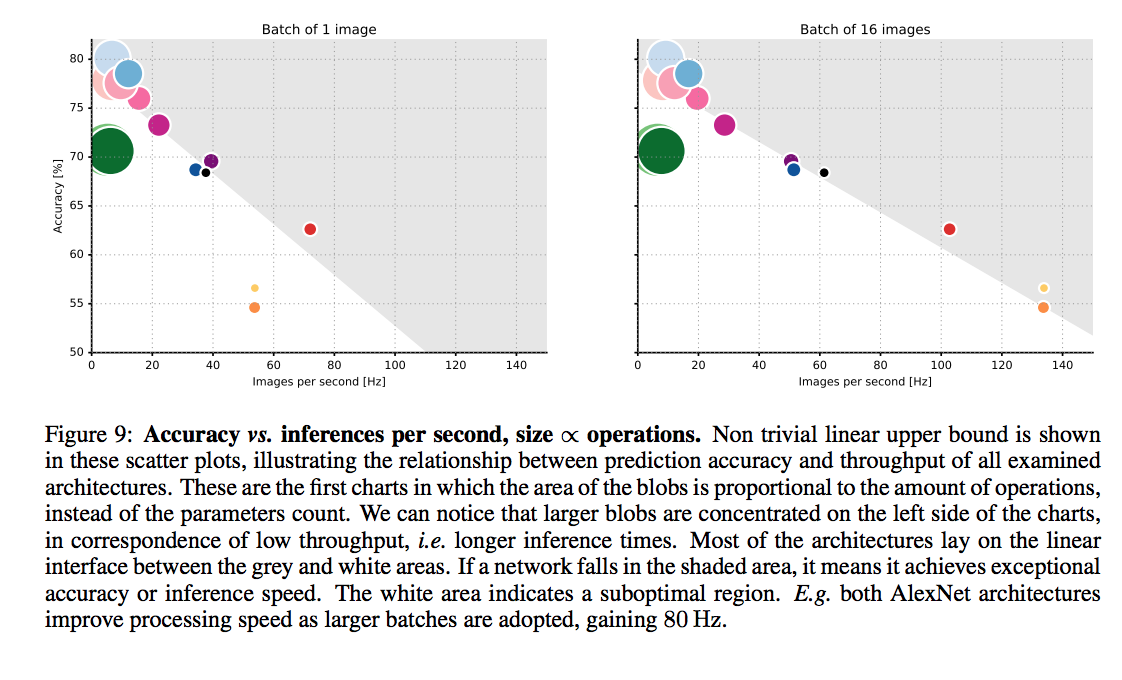
An article that compars various DNNs
An article that compars various DNNs
accuracy comparison
An article that compars various DNNs
accuracy comparison
An article that compars various DNNs
batch size
Lots of parameters and lots of hyperparameters! What to choose?
cheatsheet
What should I choose for the loss function and how does that relate to the activation functiom and optimization?
Lots of parameters and lots of hyperparameters! What to choose?
Lots of parameters and lots of hyperparameters! What to choose?
cheatsheet
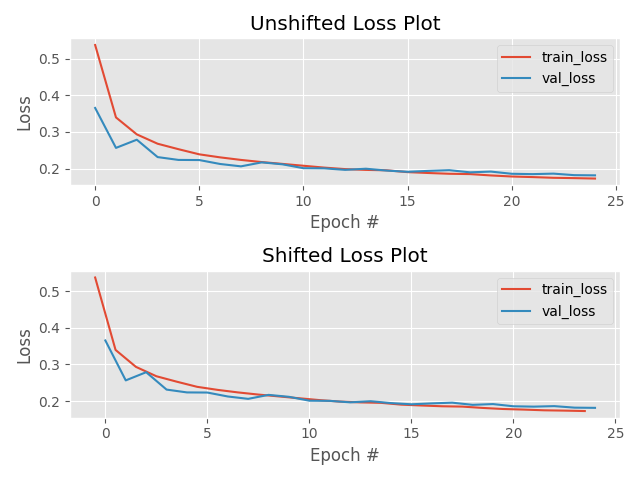
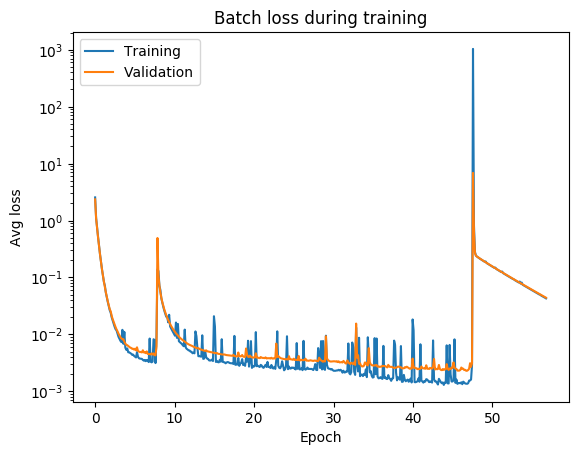
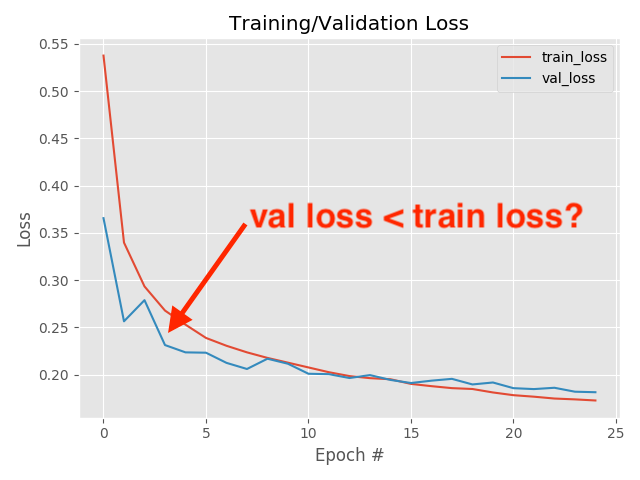
always check your loss function! it should go down smoothly and flatten out at the end of the training.
not flat? you are still learning!
too flat? you are overfitting...
loss (gallery of horrors)
jumps are not unlikely (and not necessarily a problem) if your activations are discontinuous (e.g. relu)
when you use validation you are introducing regularizations (e.g. dropout) so the loss can be smaller than for the training set
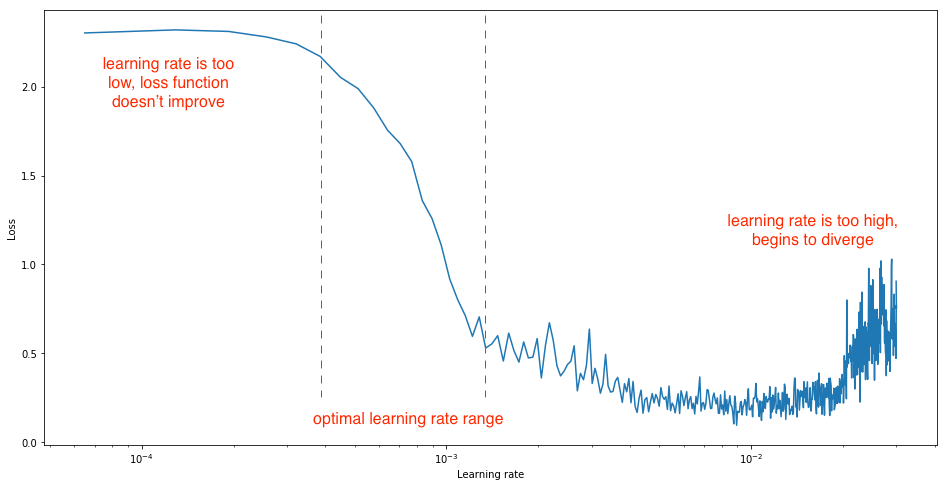
loss and learning rate (not that the appropriate learning rate depends on the chosen optimization scheme!)
Building a DNN
with keras and tensorflow
autoencoder for image recontstruction
What should I choose for the loss function and how does that relate to the activation functiom and optimization?
| loss | good for | activation last layer | size last layer |
|---|---|---|---|
| mean_squared_error | regression | linear | one node |
| mean_absolute_error | regression | linear | one node |
| mean_squared_logarithmit_error | regression | linear | one node |
| binary_crossentropy | binary classification | sigmoid | one node |
| categorical_crossentropy | multiclass classification | sigmoid | N nodes |
| Kullback_Divergence | multiclass classification, probabilistic inerpretation | sigmoid | N nodes |
On the interpretability of DNNs
1
Applications
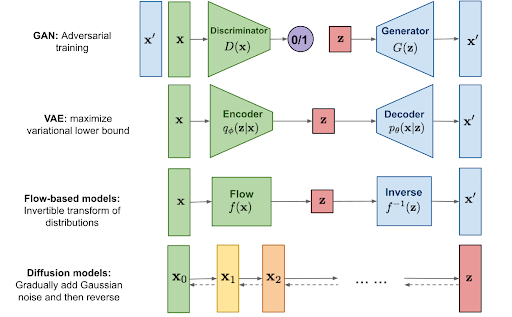
GANs
GANs
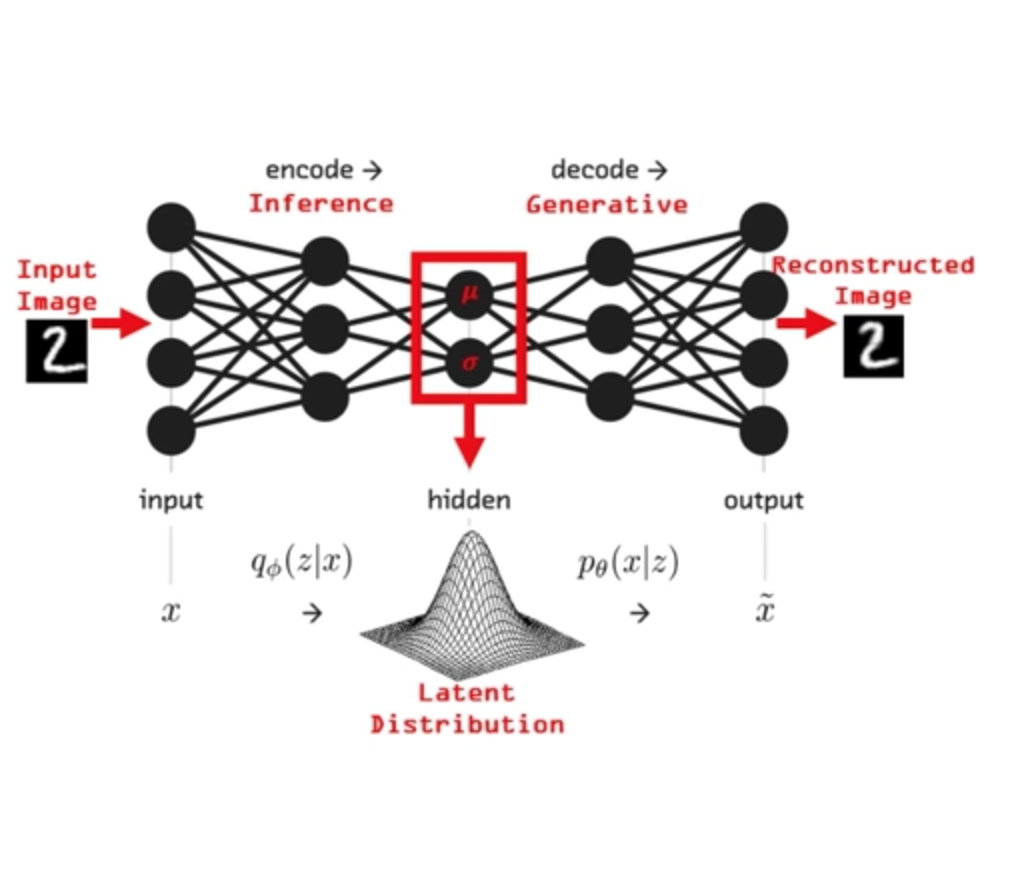
VAE
Diffusion models
VAE
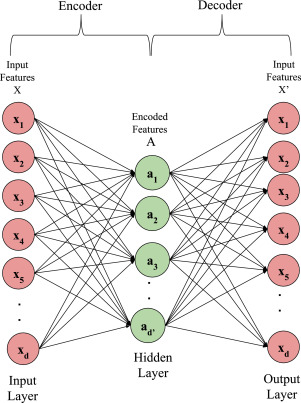
Autoencoders
2
Unsupervised learning with
Neural Networks
What do NN do? approximate complex functions with series of linear functions
.... so if my layers are smaller what I have is a compact representation of the data
Unsupervised learning with
Neural Networks
What do NN do? approximate complex functions with series of linear functions
To do that they extract information from the data
Each layer of the DNN produces a representation of the data a "latent representation" .
The dimensionality of that latent representation is determined by the size of the layer (and its connectivity, but we will ignore this bit for now)
.... so if my layers are smaller what I have is a compact representation of the data
Autoencoder Architecture
Feed Forward DNN:
the size of the input is 5,
the size of the last layer is 2
Autoencoder Architecture
Autoencoder Architecture
Building a DNN
with keras and tensorflow
Trivial to build, but the devil is in the details!
Building a DNN
with keras and tensorflow
Trivial to build, but the devil is in the details!
from keras.models import Sequential
#can upload pretrained models from keras.models
from keras.layers import Dense, Conv2D, MaxPooling2D
#create model
model = Sequential()
#create the model architecture by adding model layers
model.add(Dense(10, activation='relu', input_shape=(n_cols,)))
model.add(Dense(10, activation='relu'))
model.add(Dense(1))
#need to choose the loss function, metric, optimization scheme
model.compile(optimizer='adam', loss='mean_squared_error')
#need to learn what to look for - always plot the loss function!
model.fit(x_train, y_train, validation_data=(x_test, y_test),
epochs=20, batch_size=100, verbose=1)
#note that the model allows to give a validation test,
#this is for a 3fold cross valiation: train-validate-test
#predict
test_y_predictions = model.predict(validate_X)Building a DNN
with keras and tensorflow
autoencoder for image recontstruction
encoder
This autoencoder model has a 64-neuron bottle neck. This means it will generate a compressed representation of the data out of that layer which is 16-dimensional (the original size is 784 pixels)
Building a DNN
with keras and tensorflow
autoencoder for image recontstruction
This autoencoder model has a 64-neuron bottle neck. This means it will generate a compressed representation of the data out of that layer which is 16-dimensional (the original size is 784 pixels)
Building a DNN
with keras and tensorflow
autoencoder for image recontstruction
decoder
This autoencoder model has a 64-neuron bottle neck. This means it will generate a compressed representation of the data out of that layer which is 16-dimensional (the original size is 784 pixels)
Building a DNN
with keras and tensorflow
autoencoder for image recontstruction
This autoencoder model has a 64-neuron bottle neck. This means it will generate a compressed representation of the data out of that layer which is 16-dimensional (the original size is 784 pixels)
bottle neck
Building a DNN
with keras and tensorflow
autoencoder for image recontstruction
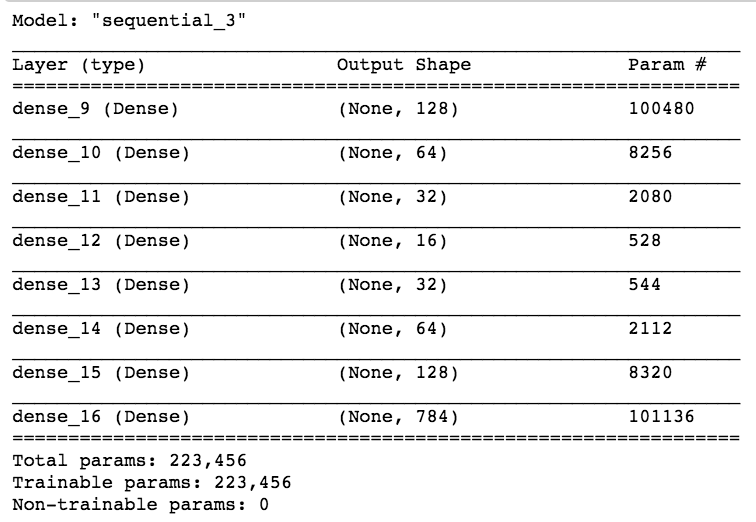
This simple model has 200K parameters!
My original choice is to train it with "adadelta" with a mean squared loss function, all activation functions are relu, appropriate for a linear regression
Building a DNN
with keras and tensorflow
autoencoder for image recontstruction
What should I choose for the loss function and how does that relate to the activation functiom and optimization?
Building a DNN
with keras and tensorflow
autoencoder for image recontstruction
What should I choose for the loss function and how does that relate to the activation functiom and optimization?
| loss | good for | activation last layer | size last layer |
|---|---|---|---|
| mean_squared_error | regression | linear | one node |
| mean_absolute_error | regression | linear | one node |
| mean_squared_logarithmit_error | regression | linear | one node |
| binary_crossentropy | binary classification | sigmoid | one node |
| categorical_crossentropy | multiclass classification | sigmoid | N nodes |
| Kullback_Divergence | multiclass classification, probabilistic inerpretation | sigmoid | N nodes |
autoencoder for image recontstruction
model_digits64.add(Dense(ndim,
activation='linear'))
model_digits64_sig.compile(optimizer="adadelta",
loss="mean_squared_error") model_digits64_sig.add(Dense(ndim,
activation='sigmoid'))
model_digits64_sig.compile(optimizer="adadelta",
loss="mean_squared_error")
model_digits64_sig.add(Dense(ndim,
activation='sigmoid'))
model_digits64_bce.compile(optimizer="adadelta",
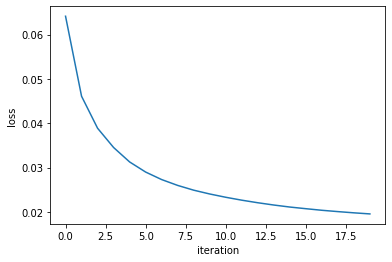
loss="binary_crossentropy")loss function: did not finish learning, it is still decreasing rapidly
The predictions are far too detailed. While the input is not binary, it does not have a lot of details. Maybe approaching it as a binary problem (with a sigmoid and a binary cross entropy loss) will give better results
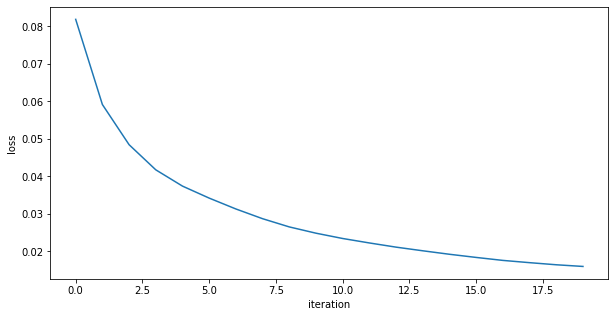
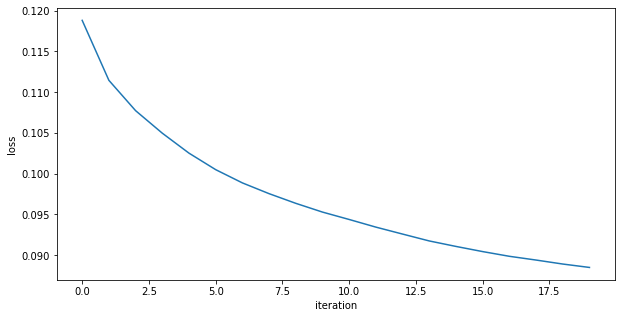
loss function: also did not finish learning, it is still decreasing rapidly
A sigmoid gives activation gives a much better result!
Binary cross entropy loss function: It is more appriopriate when the output layer is sigmoid
Even better results!
original
predicted
predicted
original
predicted
original
predicted
autoencoder for image recontstruction
A more ambitious model has a 16 neurons bottle neck: we are trying to extract 16 numbers to reconstruct the entire image! its pretty remarcable! those 16 number are extracted features from the data
predicted
original
latent
representation
Why does this AI model whitens Obama face?
Simple answer: the data is biased. The algorithm is fed more images of white people
Why does this AI model whitens Obama face?
Simple answer: the data is biased. The algorithm is fed more images of white people
But really, would the opposite have been acceptable? The bias is in society
Joy Boulamwini
3
see also https://arxiv.org/pdf/2103.04922.pdf
The latent space is assumed to be Gaussian distributed - this causes inaccuracy (blurry) generation
similar to a VAE but with a NN in the middle that approximates the true distribution of the latent space
The latent space is assumed to be Gaussian distributed - this causes inaccuracy (blurry) generation
Normalizing Flows
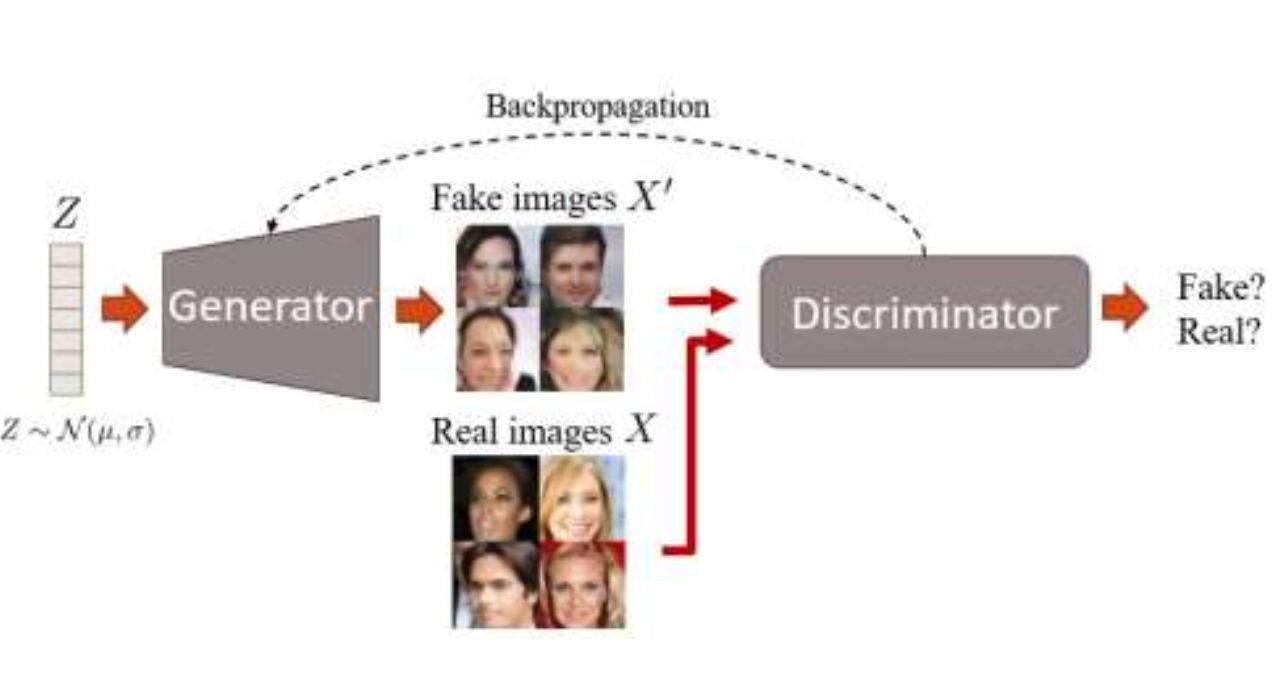
have two networks trained at the same time that compete again each other in a minimax game.
The generator generates images, starting with pure noise.
The discriminator classifies the image from the generator as Real/Fake
trained not to be fooled by the generator.
generator is trained to make better images
Ian Goodfellow et al., 2014 Generative Adversarial Networks
GANs: Generative Adversarial NN
trained not to be fooled by the generator.
generator is trained to make better images
Minmax Loss Function:
minimize
maximize
GANs: Generative Adversarial NN
trained not to be fooled by the generator.
generator is trained to make better images
Minmax Loss Function:
minimize
maximize
log(D(G(z)))
change introduced to minimize geneerator saturation
GANs: Generative Adversarial NN
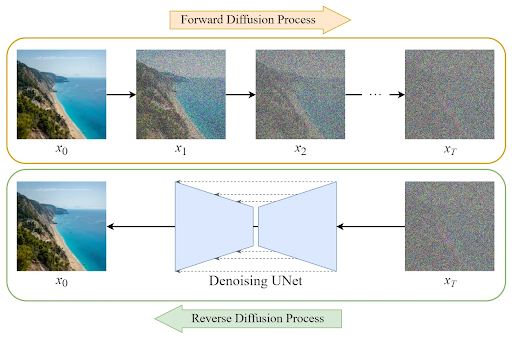
DDPM:Denoising Diffusion Probabilistic Model
Ho Jain Abbel 2006
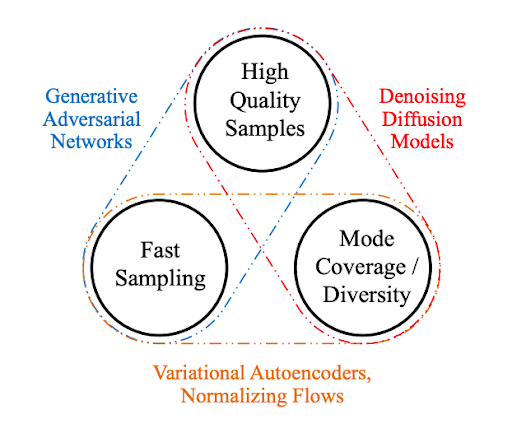
Which generative AI is right for you??
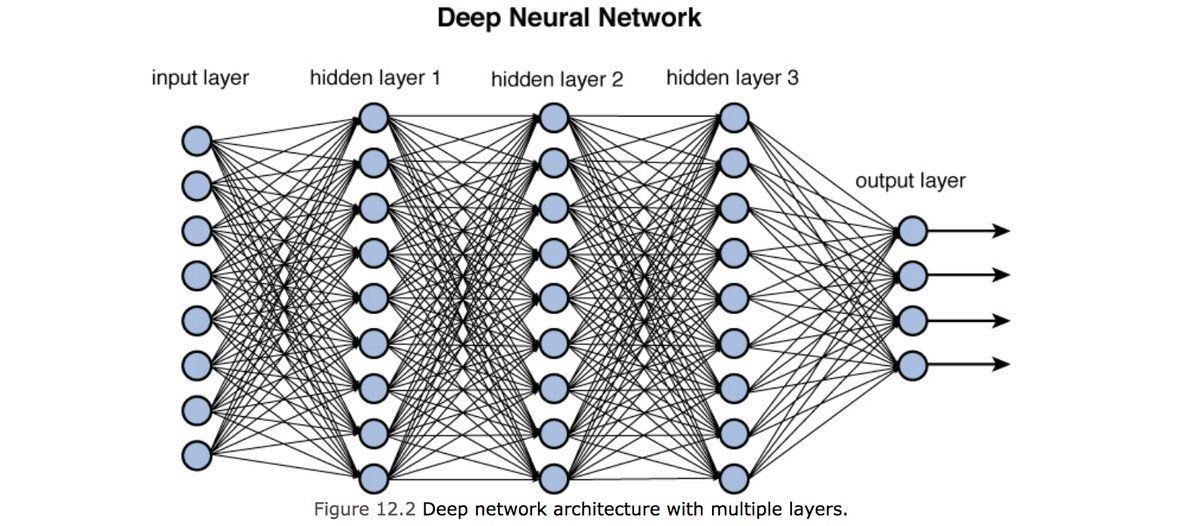
Neural Network and Deep Learning
an excellent and free book on NN and DL
http://neuralnetworksanddeeplearning.com/index.html
Deep Learning An MIT Press book in preparation
Ian Goodfellow, Yoshua Bengio and Aaron Courville
https://www.deeplearningbook.org/lecture_slides.html
History of NN
https://cs.stanford.edu/people/eroberts/courses/soco/projects/neural-networks/History/history2.html
RNN
RNN architecture
input layer
output layer
hidden layers
Feed-forward architecture
RNN architecture
output layer
hidden layers
Feed-forward NN architecture
Recurrent NN architecture
input layer
output layer
RNN hidden layers
output layer
hidden layers
input layer
RNN architecture
input layer
output layer
RNN hidden layers
current state
previous state
Remember the state-space problem!
we want process a sequence of vectors x applying a recurrence formula at every time step:
RNN architecture
input layer
output layer
RNN hidden layers
Remember the state-space problem!
we want process a sequence of vectors x applying a recurrence formula at every time step:
current state
previous state
features
(can be time dependent)
function with parameters q
A State-space model is a model to derive the value of a time-dependent variable x(t), the state, generated by a noisy Markovian process, from observations of a variable y(t), also subject to noise, linearly related to the target variable
Definition
RNN architecture
input layer
output layer
RNN hidden layers
Simplest possible RNN
Whh
Wxh
Why
RNN architecture
input layer
Alternative graphical representation of RNN
Whh
h(t-1)
h(t)
h(t+1)
h(t+2)
h(t+3)
h(t+4)
y(t)
y(t+1)
y(t+2)
y(t+4)
y(t+3)
y(t+5)
Why
Why
Why
Why
Why
Whh
Whh
Whh
Whh
Whh
Wxh
the weights are the same! always the same Whh and Why
RNN architecture
appllications
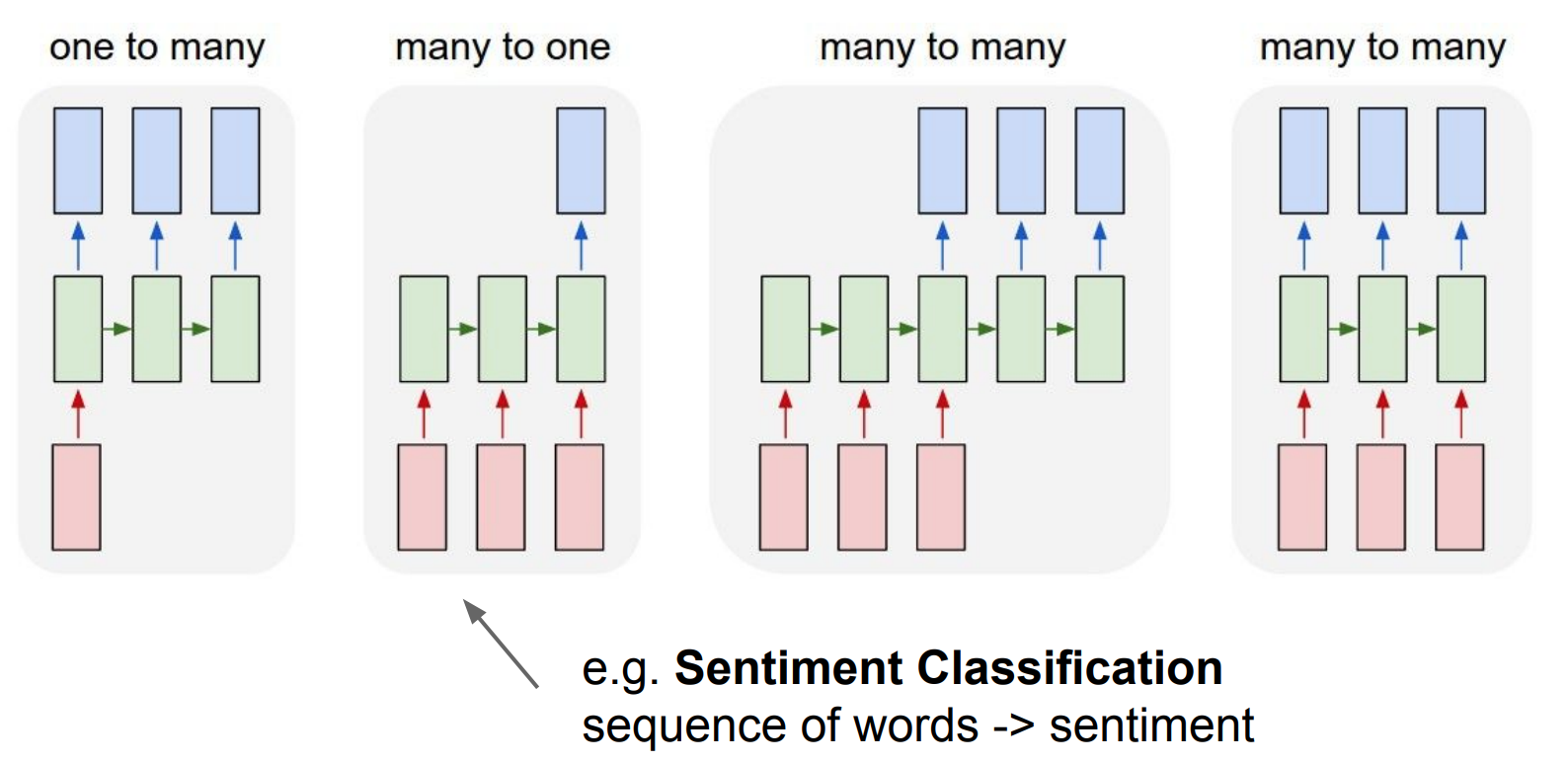
image captioning:
one image to a
sequence of worods
sentiment analysis
sequence of words to one sentiment
language translator
sequence of words to sequence of words
online: video classification frame by frame
RNN architecture
more complicated RNNs
Some layers will be recurrent, others will not. Does not need to be fully connected
RNN architecture
input layer
e(t)
h(t-1)
h(t)
h(t+1)
h(t+2)
h(t+3)
h(t+4)
y(t)
y(t+1)
y(t+2)
y(t+4)
y(t+3)
y(t+5)
Why
Why
Why
Why
Why
Whh
Whh
Whh
Whh
Whh
Wxh
each output has its own loss
Why
e(t+1)
e(t+2)
e(t+3)
e(t+4)
e(t+5)
vanishing gradient problem!
input layer
h(t-1)
h(t)
h(t+1)
h(t+2)
h(t+3)
h(t+4)
y(t)
y(t+1)
y(t+2)
y(t+4)
y(t+3)
y(t+5)
Why
Why
Why
Why
Why
Whh
Whh
Whh
Whh
Whh
Wxh
Why
Learns Fast!
Learns slow!
RNN
obsesses
over
recent
past
forgets
remote
past
vanishing gradient problem!
input layer
e(t)
h(t-1)
h(t)
h(t+1)
h(t+2)
h(t+3)
h(t+4)
y(t)
y(t+1)
y(t+2)
y(t+4)
y(t+3)
y(t+5)
Why
Why
Why
Why
Why
Whh
Whh
Whh
Whh
Whh
Wxh
Why
e(t+1)
e(t+2)
e(t+3)
e(t+4)
e(t+5)
vanishing gradient problem is exacerbated by having the same set of weights.
The vanishing gradient problem causes early layer to not to learn as effectively
The earlier layers learn from the remote past
As a result: vanilla RNN would only have short term memory (only learn from recent states)
Whh
Whh
Whh
Whh
Whh
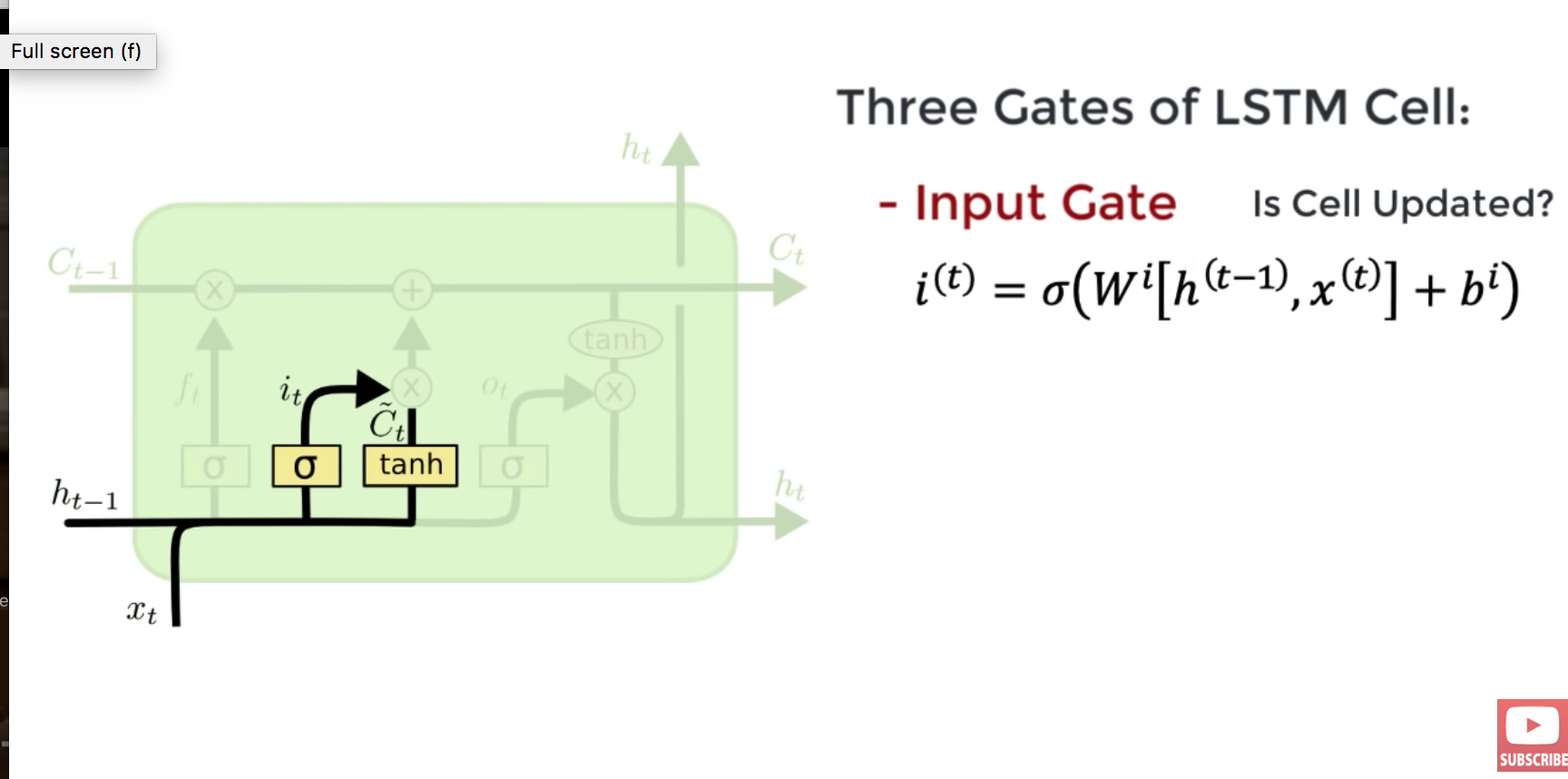
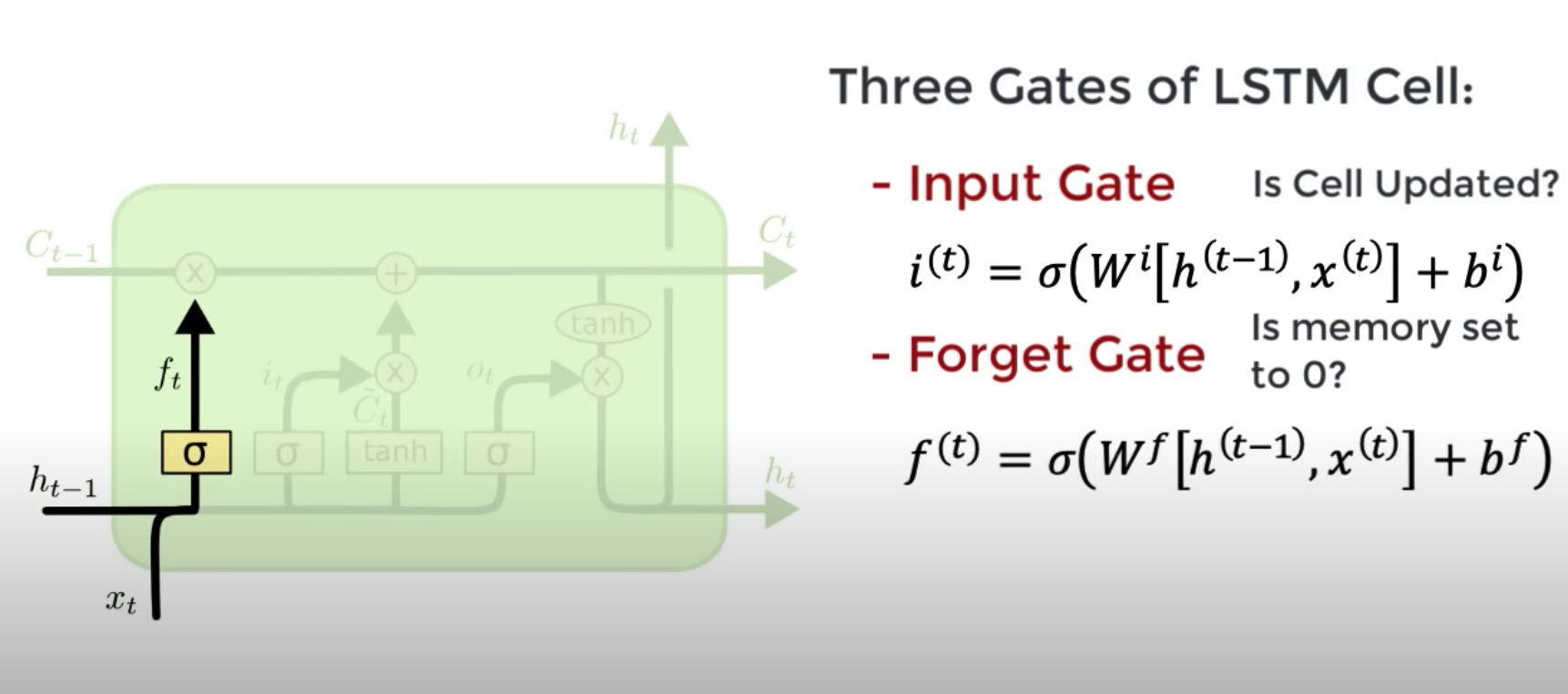
LSTM
LSTM: long short term memory
solution to the vanishing gradient problem
in one (or 4) slide(s)
input gate:
do I update the current cell?
forget gate:
do i keep memory of this past step
LSTM: long short term memory
solution to the vanishing gradient problem
in one (or 4) slide(s)
By federica bianco
autoencoders



