



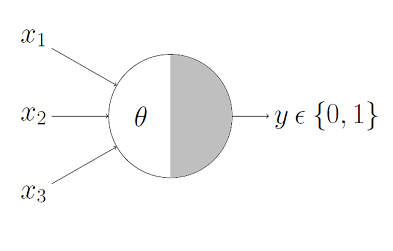






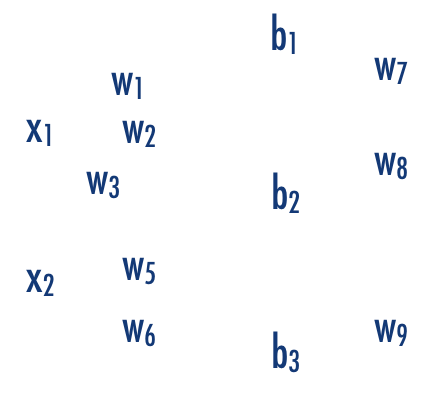


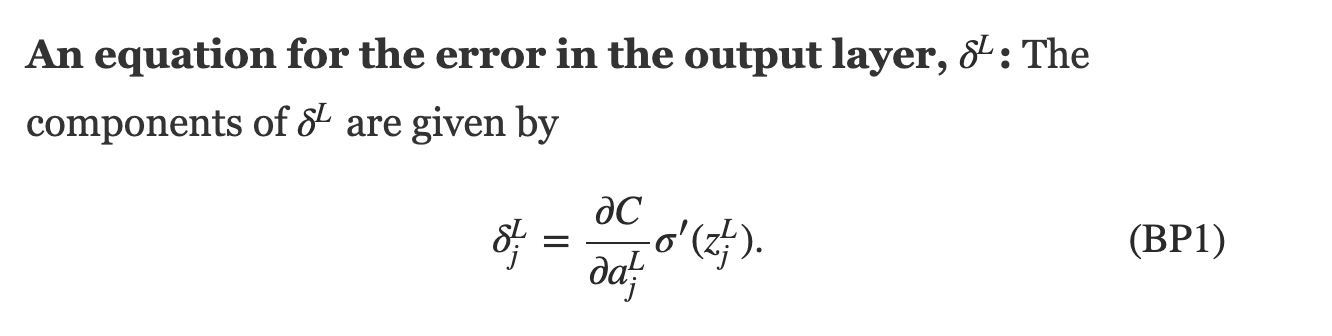

















federica bianco PRO
astro | data science | data for good
dr.federica bianco | fbb.space | fedhere | fedhere
NNs and Deep Learning
this slide deck:
0
Data driven models for exploration of structure, prediction that learn parameters from data.
Machine Learning
used to:
Data driven models for exploration of structure, prediction that learn parameters from data.
unupervised ------ supervised
set up: All features known for all observations
Goal: explore structure in the data
- data compression
- understanding structure
Algorithms: Clustering, (...)
x
y
Machine Learning
Data driven models for exploration of structure, prediction that learn parameters from data.
unupervised ------ supervised
set up: All features known for a sunbset of the data; one feature cannot be observed for the rest of the data
Goal: predicting missing feature
- classification
- regression
Algorithms: regression, SVM, tree methods, k-nearest neighbors, neural networks, (...)
x
y
Machine Learning
unupervised ------ supervised
set up: All features known for a sunbset of the data; one feature cannot be observed for the rest of the data
Goal: predicting missing feature
- classification
- regression
Algorithms: regression, SVM, tree methods, k-nearest neighbors, neural networks, (...)
unupervised ------ supervised
set up: All features known for all observations
Goal: explore structure in the data
- data compression
- understanding structure
Algorithms: k-means clustering, agglomerative clustering, density based clustering, (...)
Machine Learning
model parameters are learned by calculating a loss function for diferent parameter sets and trying to minimize loss (or a target function and trying to maximize)
e.g.
L1 = |target - prediction|
Learning relies on the definition of a loss function
Machine Learning
Learning relies on the definition of a loss function
| learning type | loss / target |
|---|---|
| unsupervised | intra-cluster variance / inter cluster distance |
| supervised | distance between prediction and truth |
Machine Learning
The definition of a loss function requires the definition of distance or similarity
Machine Learning
Minkowski distance
Jaccard similarity
Great circle distance
The definition of a loss function requires the definition of distance or similarity
Machine Learning
NN are a vast topics and we only have 2 weeks!
Some FREE references!
michael nielsen
better pedagogical approach, more basic, more clear
ian goodfellow
mathematical approach, more advanced, unfinished
michael nielsen
better pedagogical approach, more basic, more clear
Neural Networks
1
Neural Networks
1.1
origins
1943
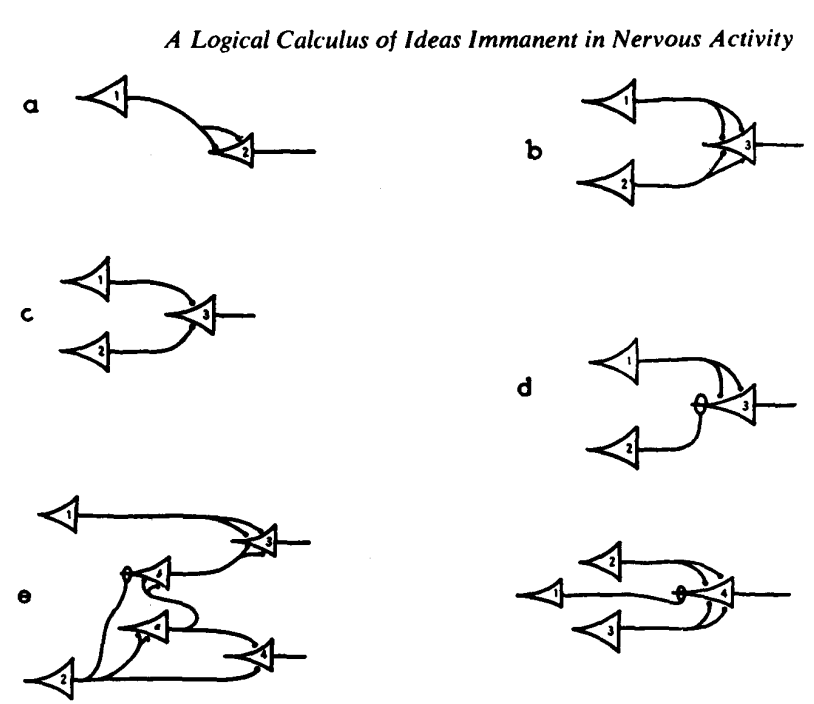
M-P Neuron McCulloch & Pitts 1943
1943
M-P Neuron McCulloch & Pitts 1943
1943
M-P Neuron McCulloch & Pitts 1943
M-P Neuron
1943
M-P Neuron
its a classifier
M-P Neuron McCulloch & Pitts 1943
M-P Neuron
1943
M-P Neuron McCulloch & Pitts 1943
M-P Neuron
1943
if is Bool (True/False)
what value of corresponds to logical AND?
M-P Neuron McCulloch & Pitts 1943
The perceptron algorithm : 1958, Frank Rosenblatt
1958
Perceptron
The perceptron algorithm : 1958, Frank Rosenblatt
.
.
.
output
weights
bias
linear regression:
1958
Perceptron
Perceptrons are linear classifiers: makes its predictions based on a linear predictor function
combining a set of weights (=parameters) with the feature vector.
The perceptron algorithm : 1958, Frank Rosenblatt
x
y
1958
Perceptrons are linear classifiers: makes its predictions based on a linear predictor function
combining a set of weights (=parameters) with the feature vector.
The perceptron algorithm : 1958, Frank Rosenblatt
x
y
1958
1
0
{
{
.
.
.
output
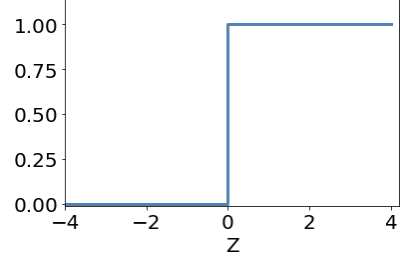
activation function
weights
bias
perceptron
The perceptron algorithm : 1958, Frank Rosenblatt
Perceptrons are linear classifiers: makes its predictions based on a linear predictor function
combining a set of weights (=parameters) with the feature vector.
The perceptron algorithm : 1958, Frank Rosenblatt
output
activation function
weights
bias
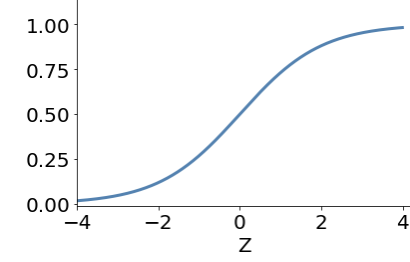
sigmoid
.
.
.
Perceptrons are linear classifiers: makes its predictions based on a linear predictor function
combining a set of weights (=parameters) with the feature vector.
The perceptron algorithm : 1958, Frank Rosenblatt
output
activation function
weights
bias
.
.
.
Perceptron
The perceptron algorithm : 1958, Frank Rosenblatt
Perceptron
The Navy revealed the embryo of an electronic computer today that it expects will be able to walk, talk, see, write, reproduce itself and be conscious of its existence.
The embryo - the Weather Buerau's $2,000,000 "704" computer - learned to differentiate between left and right after 50 attempts in the Navy demonstration
July 8, 1958
The perceptron algorithm : 1958, Frank Rosenblatt
Perceptron
The Navy revealed the embryo of an electronic computer today that it expects will be able to walk, talk, see, write, reproduce itself and be conscious of its existence.
The embryo - the Weather Buerau's $2,000,000 "704" computer - learned to differentiate between left and right after 50 attempts in the Navy demonstration
July 8, 1958
2
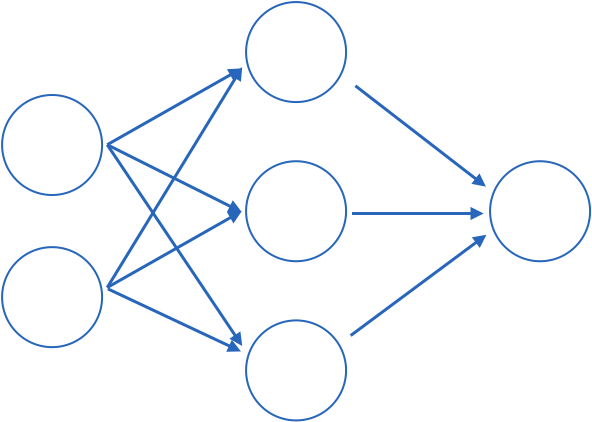
output
layer of perceptrons
output
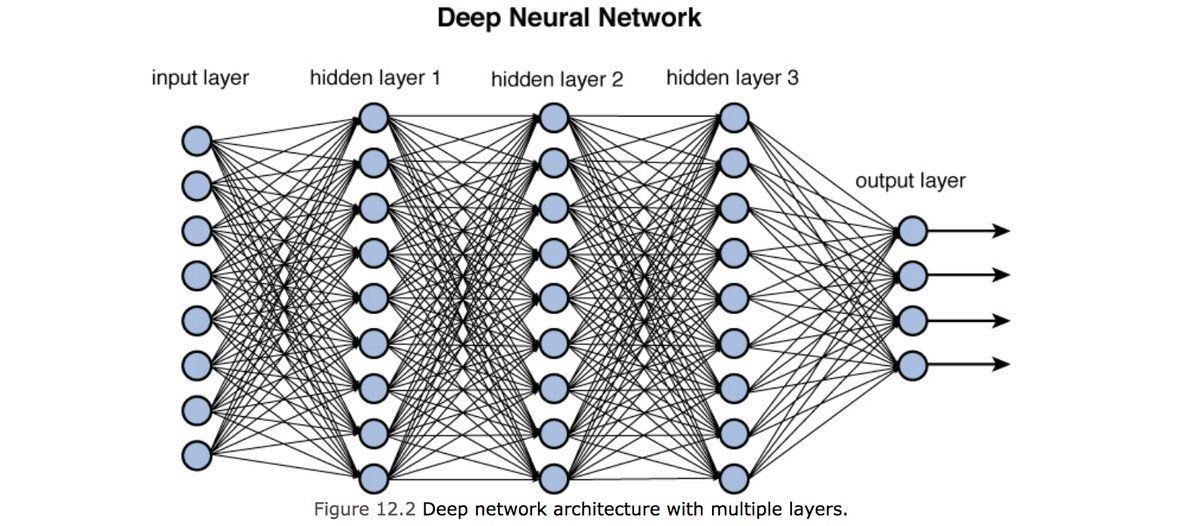
input layer
hidden layer
output layer
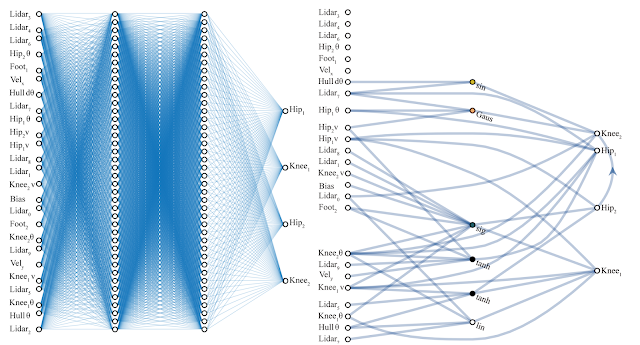
1970: multilayer perceptron architecture
Fully connected: all nodes go to all nodes of the next layer.
output
layer of perceptrons
output
layer of perceptrons
layer of perceptrons
output
layer of perceptrons
output
Fully connected: all nodes go to all nodes of the next layer.
layer of perceptrons
output
Fully connected: all nodes go to all nodes of the next layer.
layer of perceptrons
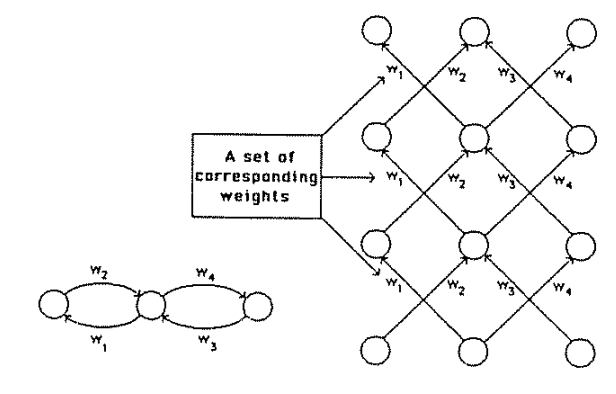
w: weight
sets the sensitivity of a neuron
b: bias:
up-down weights a neuron
learned parameters
output
Fully connected: all nodes go to all nodes of the next layer.
layer of perceptrons
w: weight
sets the sensitivity of a neuron
b: bias:
up-down weights a neuron
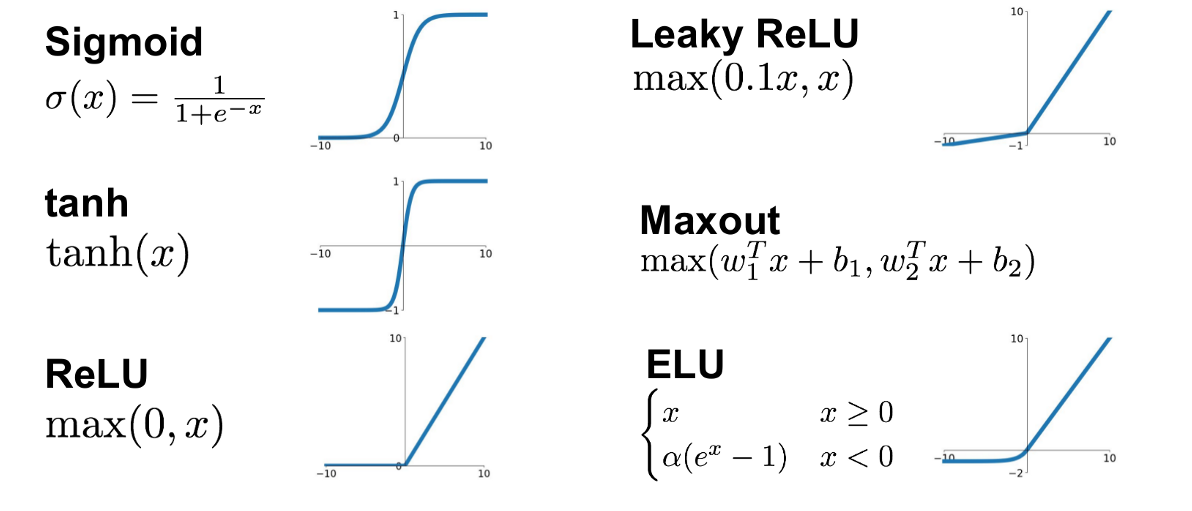
f: activation function:
turns neurons on-off
hyperparameters of DNN
3
output
how many parameters?
input layer
hidden layer
output layer
hidden layer
output
input layer
hidden layer
output layer
hidden layer
how many hyperparameters?
GREEN: architecture hyperparameters
RED: training hyperparameters
output
input layer
hidden layer
output layer
hidden layer
how many hyperparameters?
GREEN: architecture hyperparameters
RED: training hyperparameters
training DNN
4
Fully connected: all nodes go to all nodes of the next layer.
1986: Deep Neural Nets
f: activation function:
turns neurons on-off
w: weight
sets the sensitivity of a neuron
b: bias:
up-down weights a neuron
In a CNN these layers would not be fully connected except the last one
Seminal paper
Y. LeCun 1998
.
.
.
Any linear model:
y : prediction
ytrue : target
Error: e.g.
intercept
slope
L2
x
Find the best parameters by finding the minimum of the L2 hyperplane
at every step look around and choose the best direction
how does linear descent look when you have a whole network structure with hundreds of weights and biases to optimize??
.
.
.
output
Training models with this many parameters requires a lot of care:
. defining the metric
. optimization schemes
. training/validation/testing sets
But just like our simple linear regression case, the fact that small changes in the parameters leads to small changes in the output for the right activation functions.
define a cost function, e.g.
Training models with this many parameters requires a lot of care:
. defining the metric
. optimization schemes
. training/validation/testing sets
But just like our simple linear regression case, the fact that small changes in the parameters leads to small changes in the output for the right activation functions.
define a cost function, e.g.
Training a DNN
feed data forward through network and calculate cost metric
for each layer, calculate effect of small changes on next layer
how does linear descent look when you have a whole network structure with hundreds of weights and biases to optimize??
think of applying just gradient to a function of a function of a function... use:
1) partial derivatives, 2) chain rule
define a cost function, e.g.
Training a DNN
Deep Neural Net are not some fancy-pants methods, they are just linear models with a bunch of parameters
Because they have many parameters they are difficult to "interpret" (no easy feature extraction)
that may be ok because they are prediction machines
Because they have many parameters they are difficult to "interpret" (no easy feature extraction)
that may be ok because they are prediction machines
Epistemic transparency
tration by Hanne Morstad
Accountability: who is responsible if an algorithm does harm
strictly policy issues:
proprietary algorithms + audability
technical + policy issues:
data access and redress + data provenance
https://www.darpa.mil/attachments/XAIProgramUpdate.pdf
trivially intuitive
generalized additive models
decision trees
SVM
Random Forest
Deep Learning
Accuracy
univaraite
linear
regression
we're still trying to figure it out
trivially intuitive
generalized additive models
decision trees
Deep Learning
number of features that can be effectively included in the model
thousands
1
SVM
Random Forest
univaraite
linear
regression
https://www.darpa.mil/attachments/XAIProgramUpdate.pdf
Accuracy in solving complex problems
we're still trying to figure it out
trivially intuitive
univaraite
linear
regression
generalized additive models
decision trees
Deep Learning
SVM
Random Forest
https://www.darpa.mil/attachments/XAIProgramUpdate.pdf
time
Accuracy in solving complex problems
we're still trying to figure it out
1
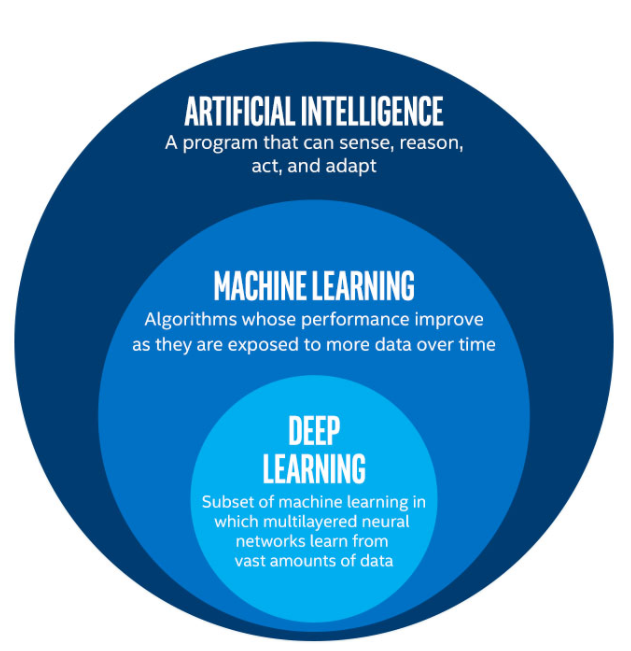
Machine learning: any method that learns parameters from the data
2
The transparency of an algorithm is proportional to its complexity and the complexity of the data space
3
The transparency of an algorithm is limited by our own ability and preparedness to interpret it
Toward Interpretable Machine Learning, Samek+2003
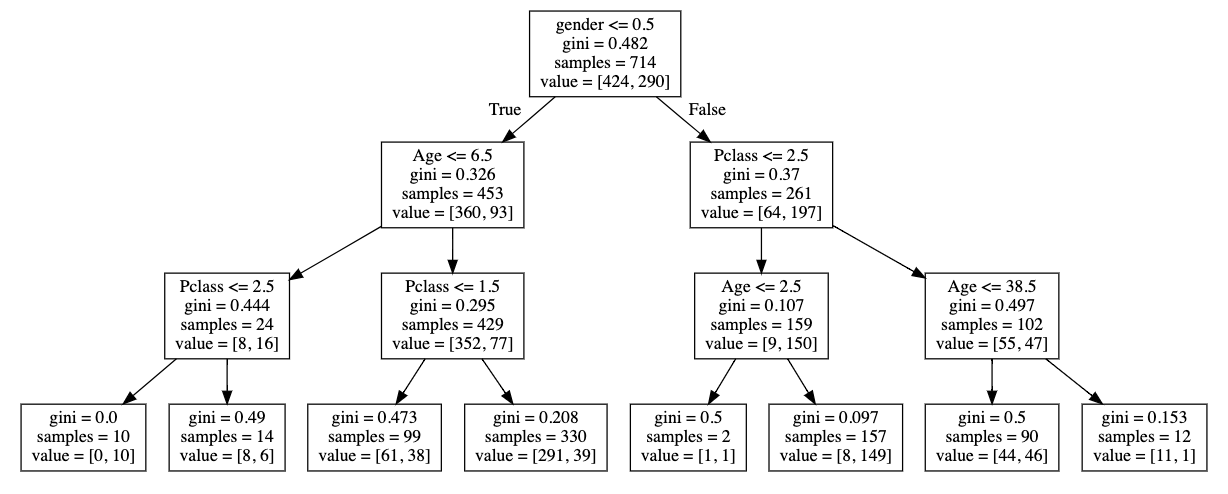
A single tree model
In a press release, the ACLU wrote, “Mr. Williams’ experience was the first case of wrongful arrest due to facial recognition technology to come to light in the United States.”
In a press release, the ACLU wrote, “Mr. Williams’ experience was the first case of wrongful arrest due to facial recognition technology to come to light in the United States.”
Who is responsible for setting the threshold?
FR returns a probabilistic result
a threshold is chosen to turn it into a T/F match for decision making
https://modelviewculture.com/pieces/the-hidden-dangers-of-ai-for-queer-and-trans-people
Text
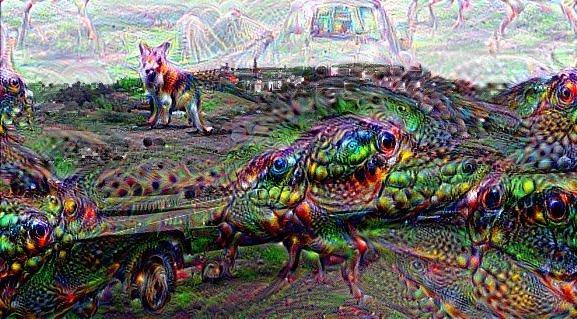
Deep Dream (DD) is a google software, a pre-trained NN (originally created on the Cafe architecture, now imported on many other platforms including tensorflow).
The high level idea relies on training a convolutional NN to recognize common objects, e.g. dogs, cats, cars, in images. As the network learns to recognize those objects is developes its layers to pick out "features" of the NN, like lines at a cetrain orientations, circles, etc.
The DD software runs this NN on an image you give it, and it loops on some layers, thus "manifesting" the things it knows how to recognize in the image.
@akumadog
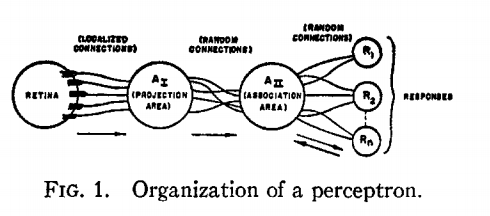
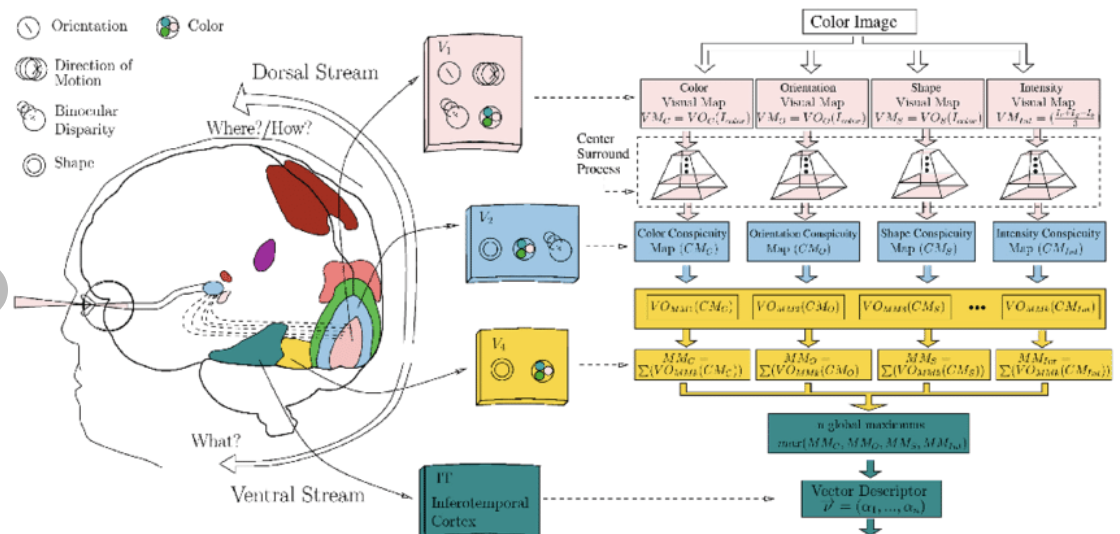
The visual cortex learns hierarchically: first detects simple features, then more complex features and ensembles of features
The visual cortex learns hierarchically: first detects simple features, then more complex features and ensembles of features
The visual cortex learns hierarchically: first detects simple features, then more complex features and ensembles of features
The visual cortex learns hierarchically: first detects simple features, then more complex features and ensembles of features
The visual cortex learns hierarchically: first detects simple features, then more complex features and ensembles of features
The visual cortex learns hierarchically: first detects simple features, then more complex features and ensembles of features
The visual cortex learns hierarchically: first detects simple features, then more complex features and ensembles of features
The visual cortex learns hierarchically: first detects simple features, then more complex features and ensembles of features
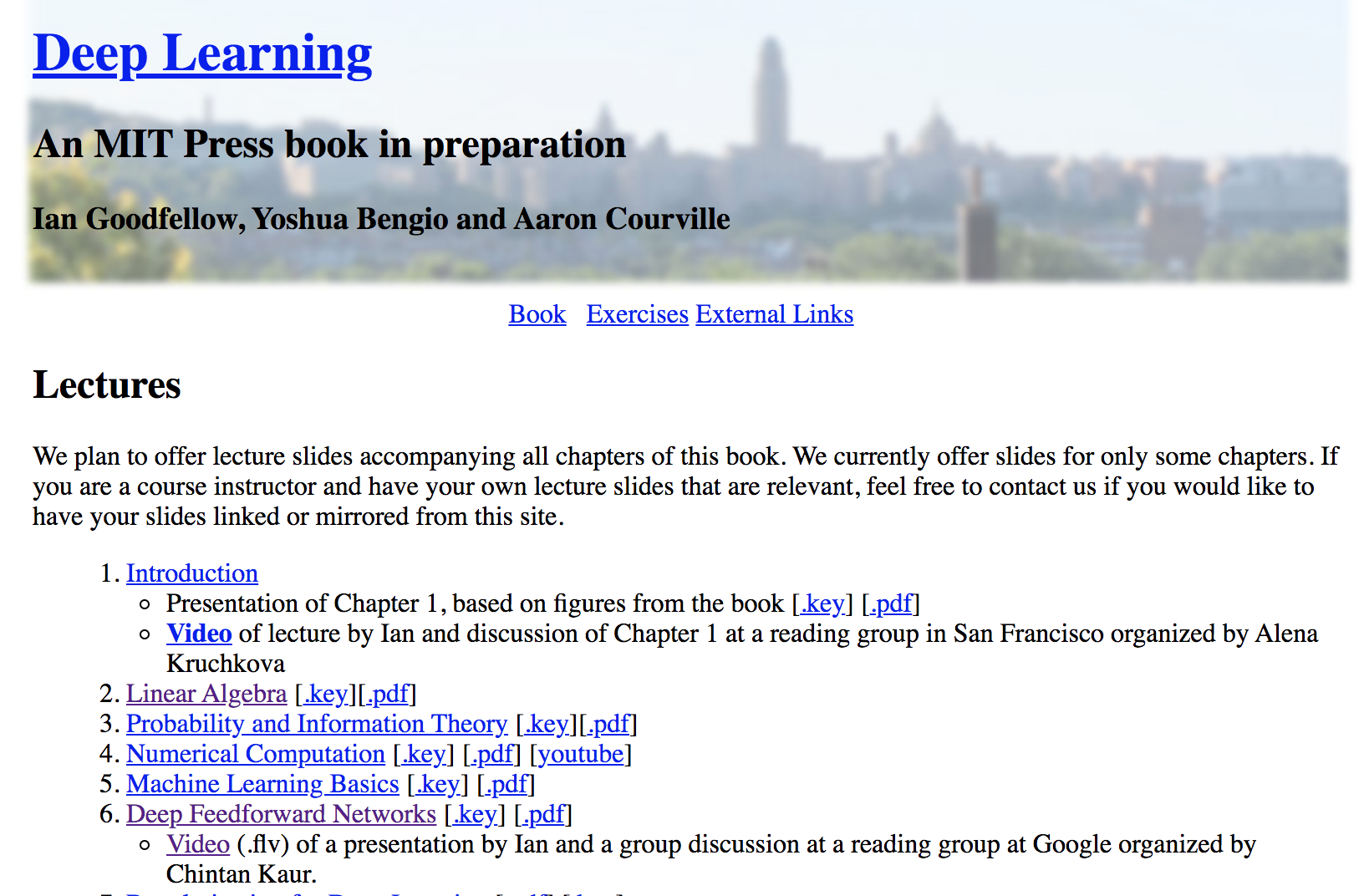
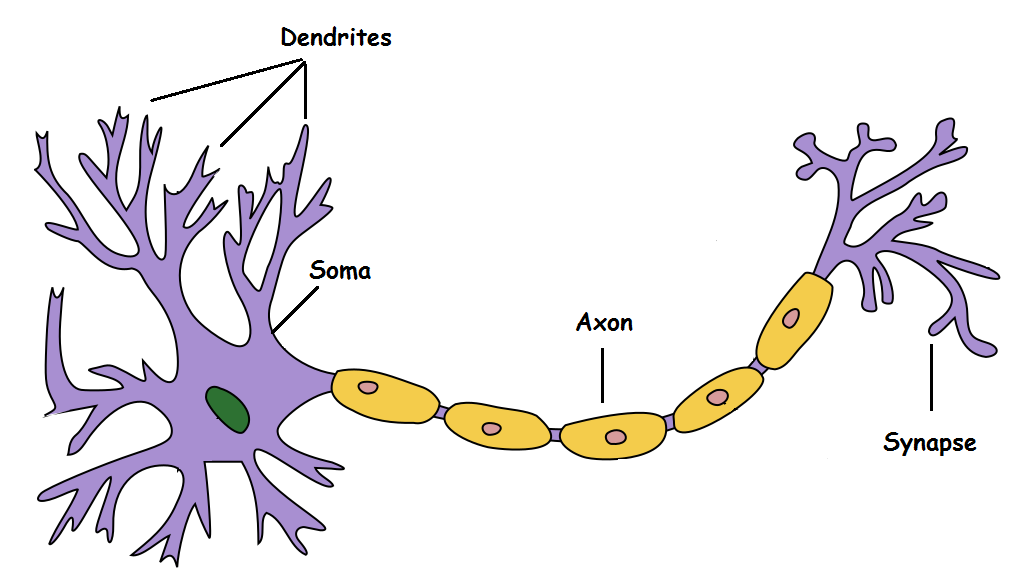
Neural Network and Deep Learning
an excellent and free book on NN and DL
http://neuralnetworksanddeeplearning.com/index.html
History of NN
https://cs.stanford.edu/people/eroberts/courses/soco/projects/neural-networks/History/history2.html
By federica bianco
DNN 101 - deepdreams



