Python & Nibabel
(3D Convolutional networks & MRIs)
Content
- Context
- Tools
- Data exploration
- Preprocessing Input
- Model
- Training
- Results
- Q&A
Context
Problem
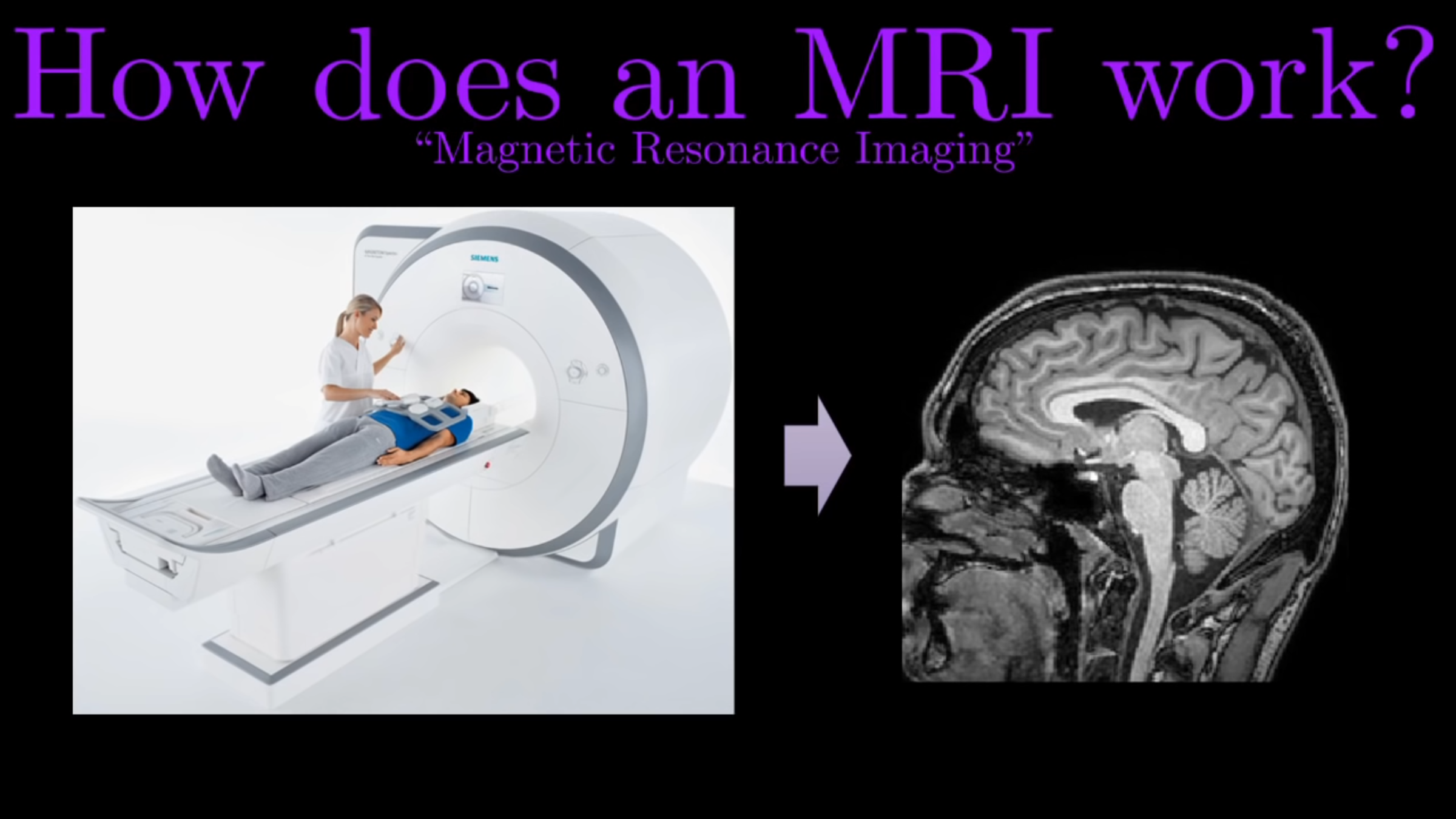
Automatic MRI classification
?

Strong
Weak

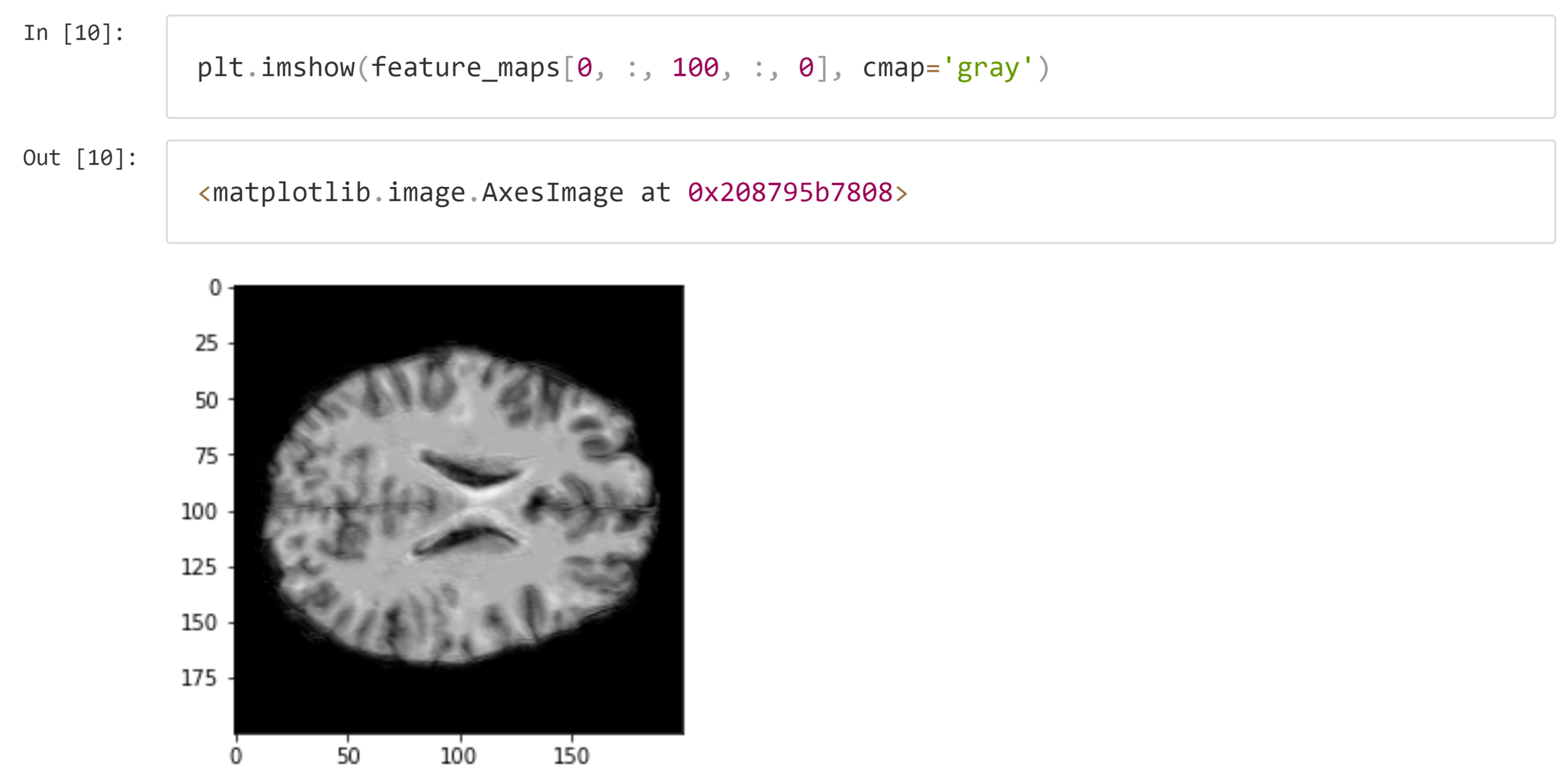
ctscan???


NMR


Signals
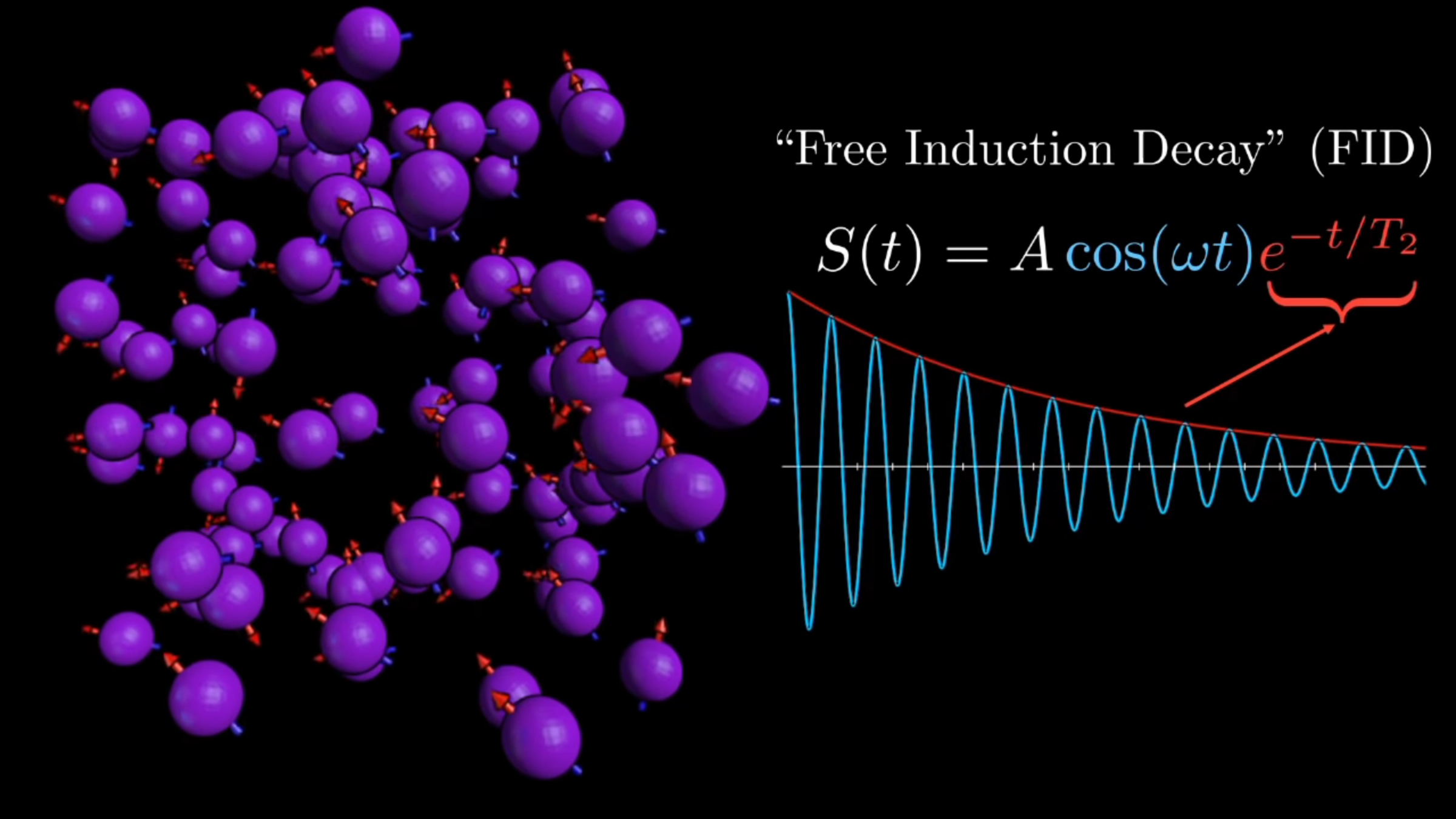
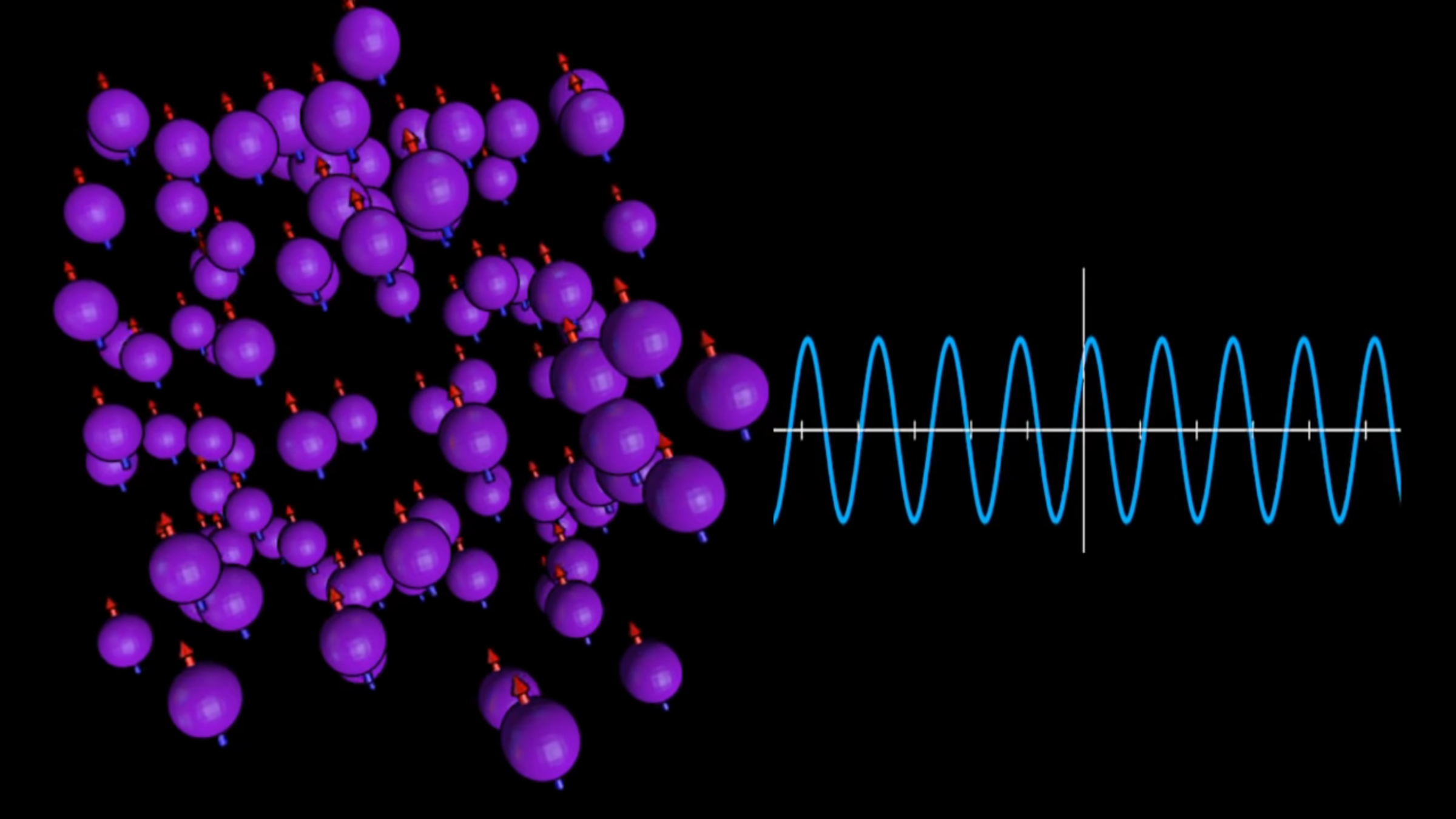
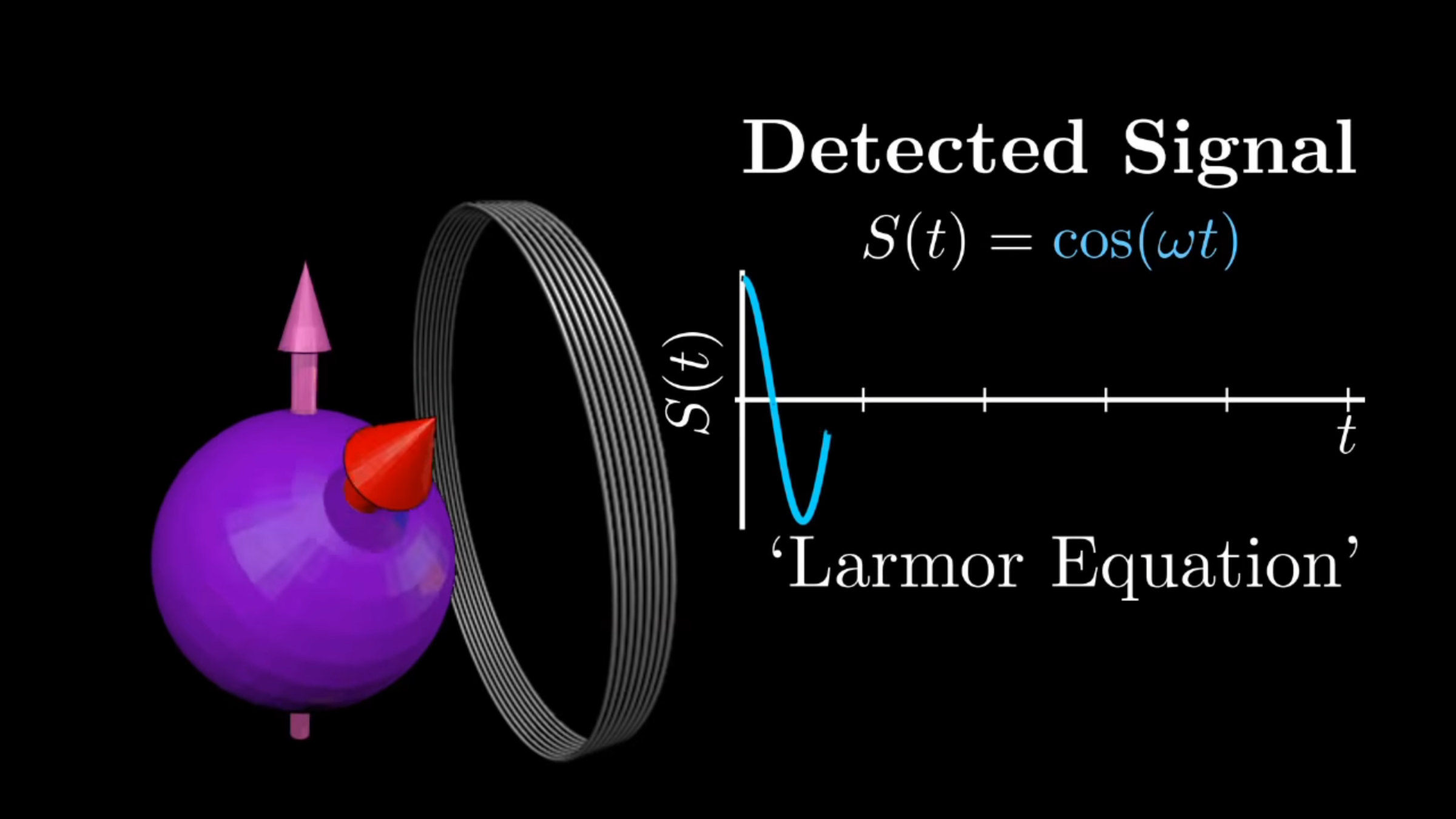
T2 tissue contrasting
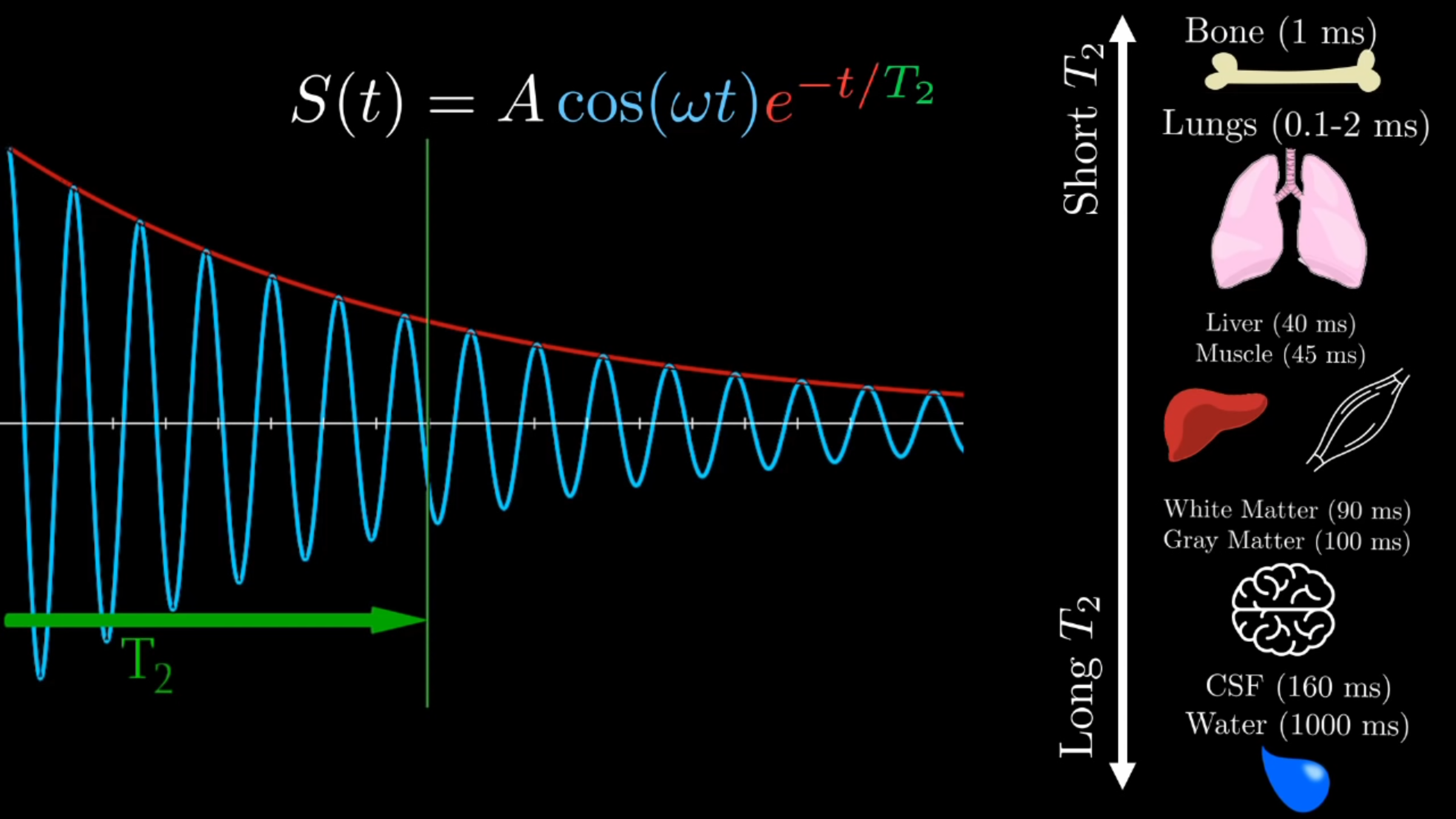
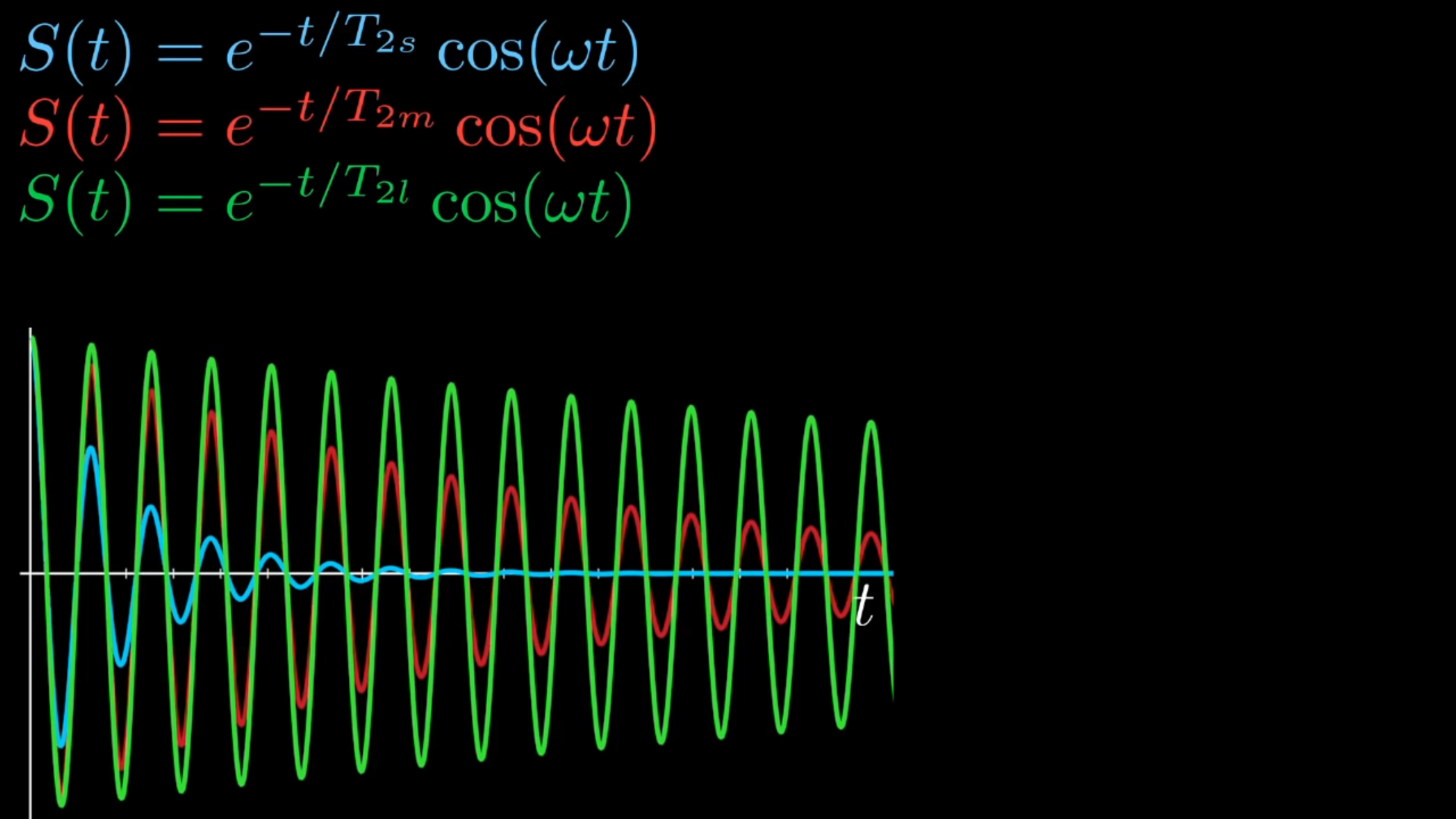
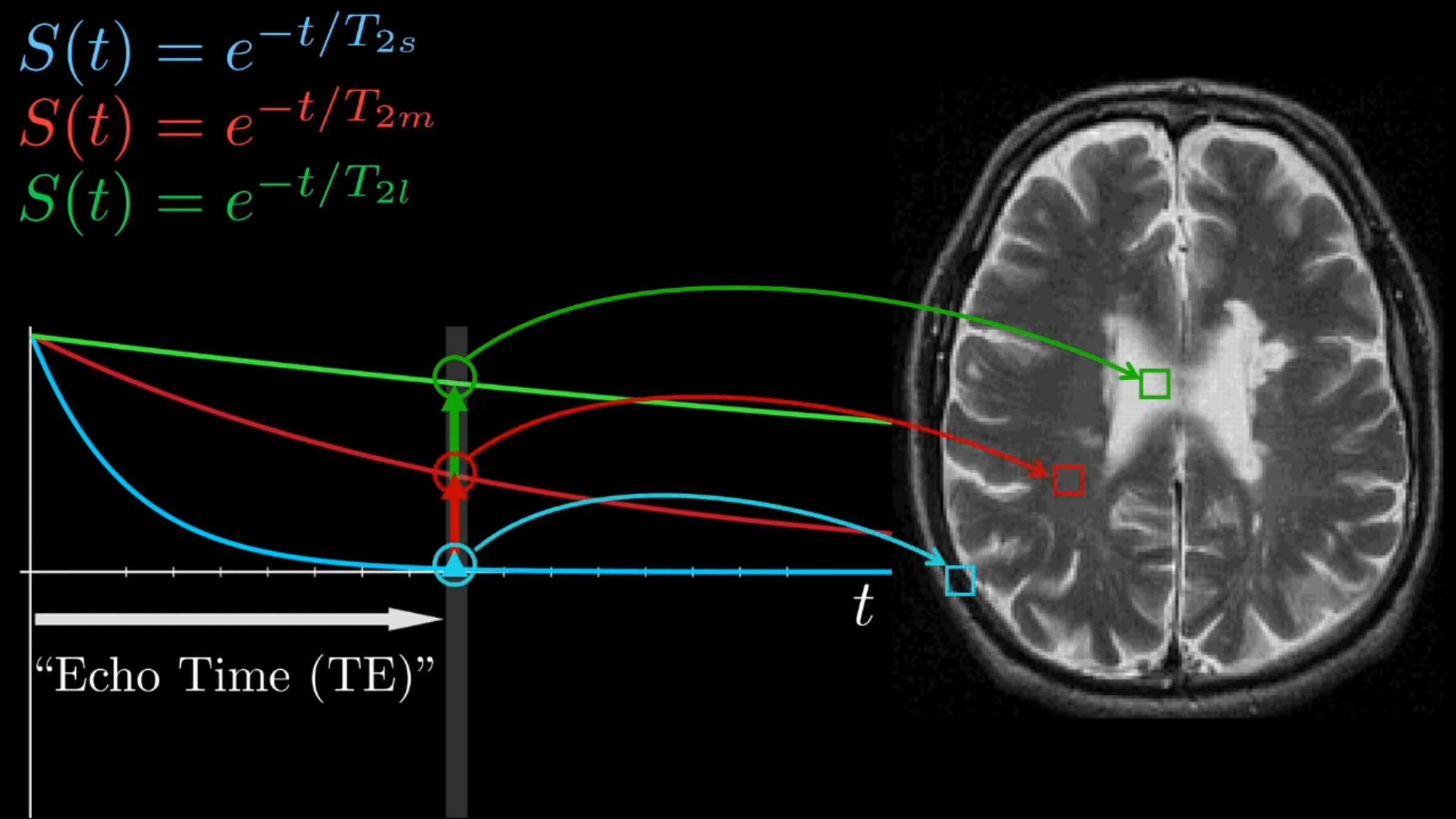

T1 tissue contrasting
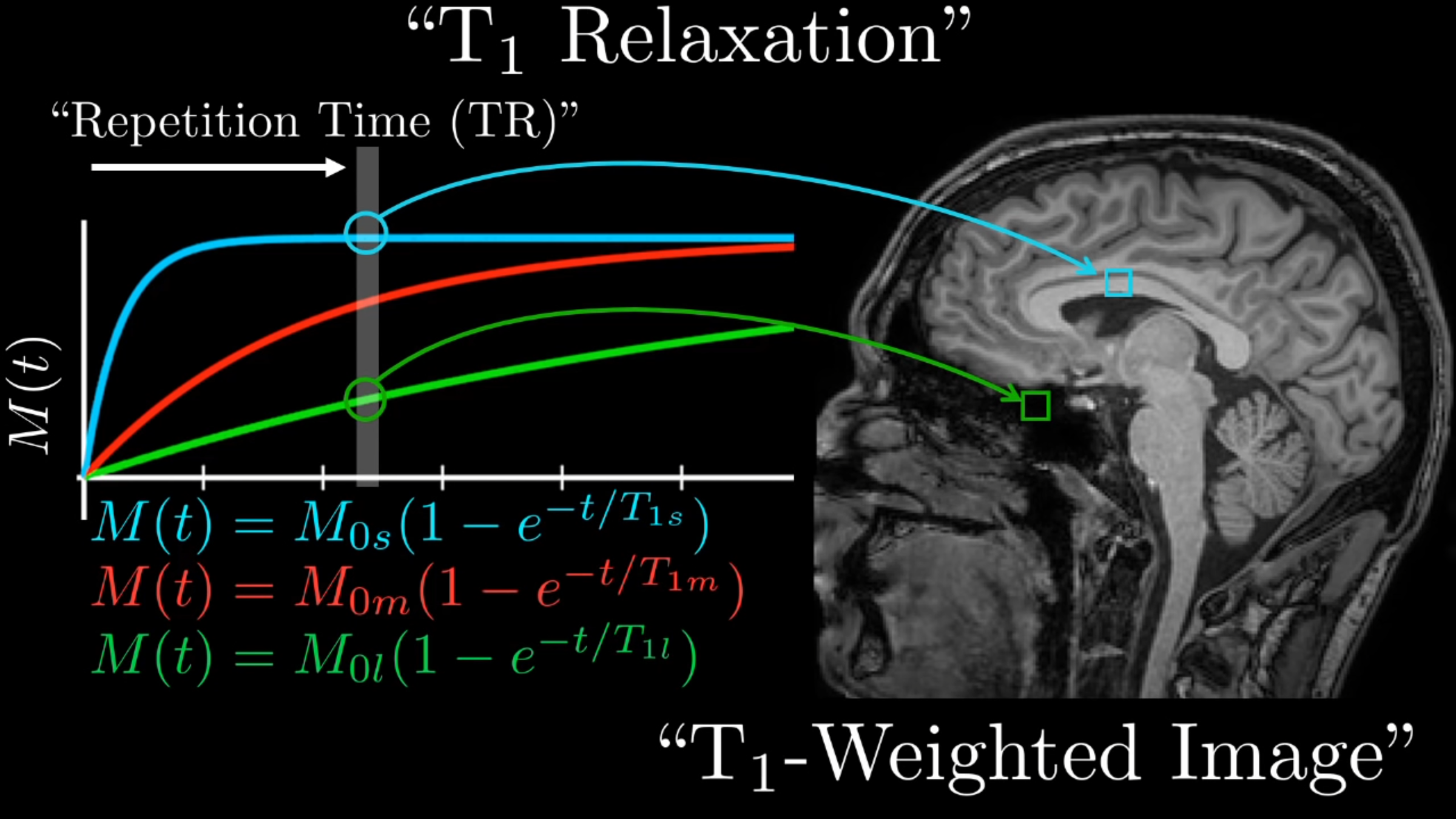

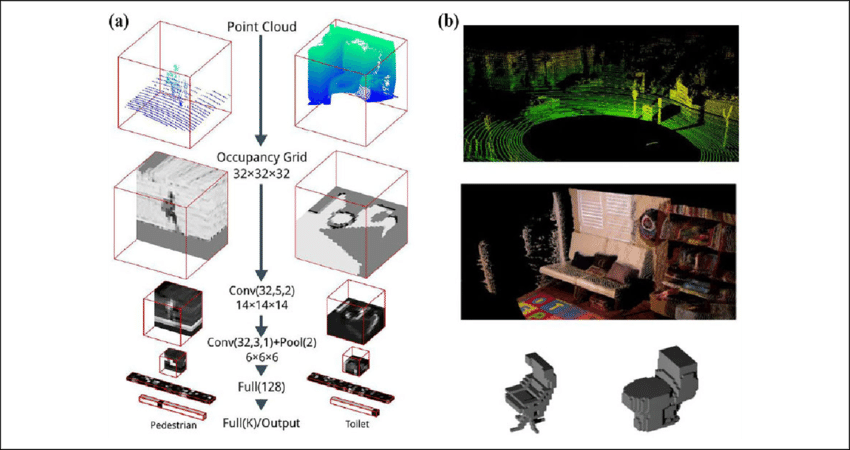
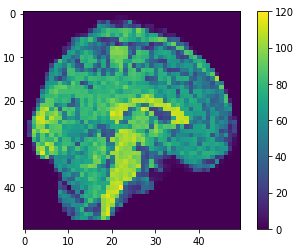
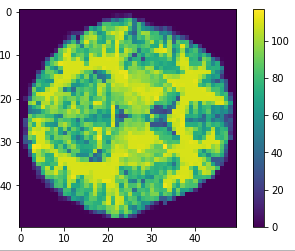
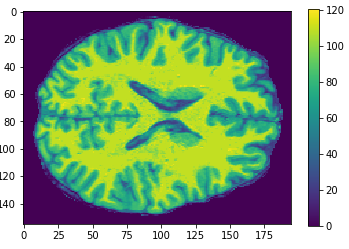
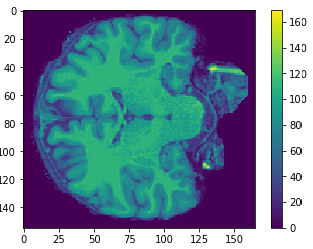
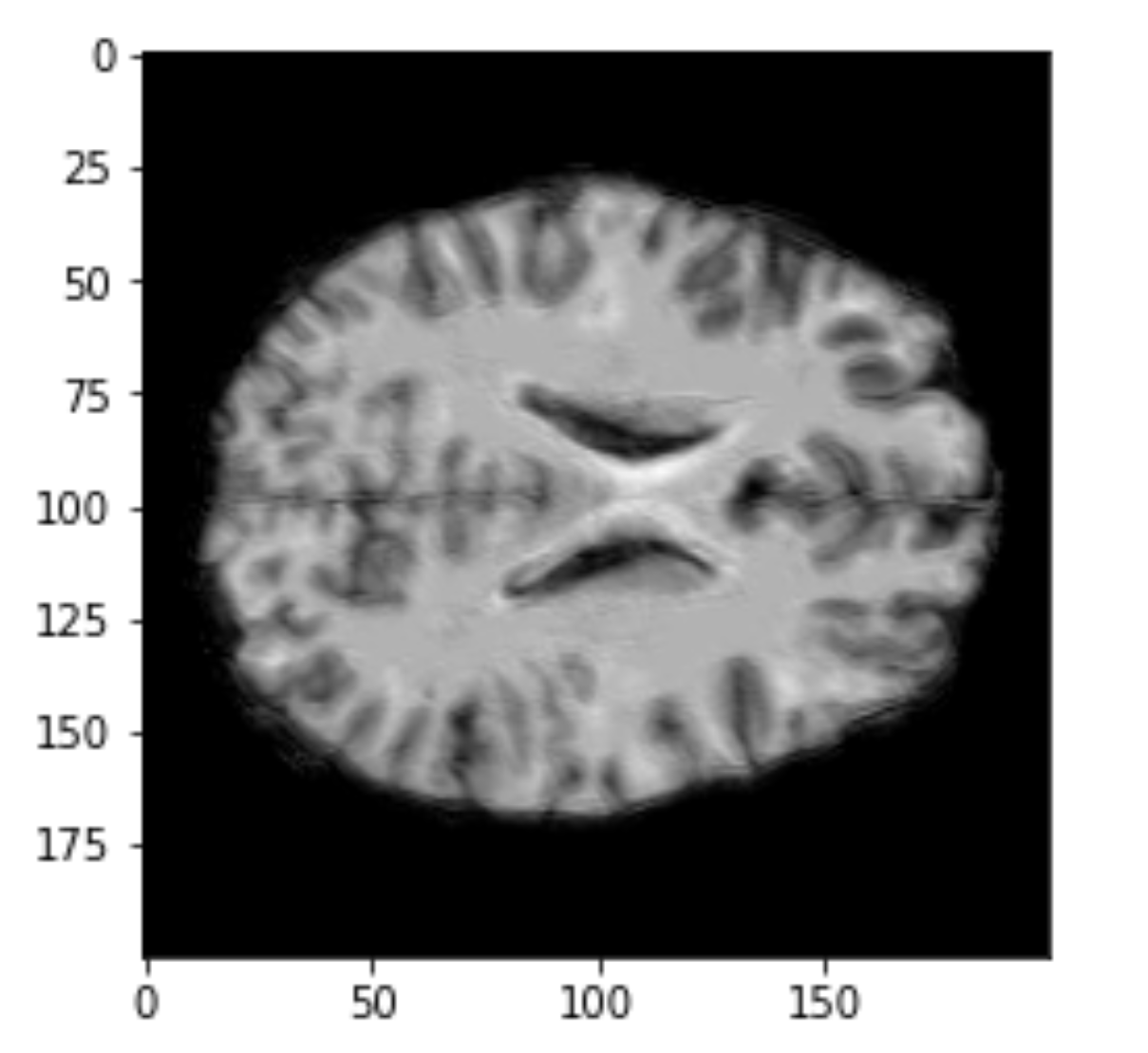
Obtaining an image.
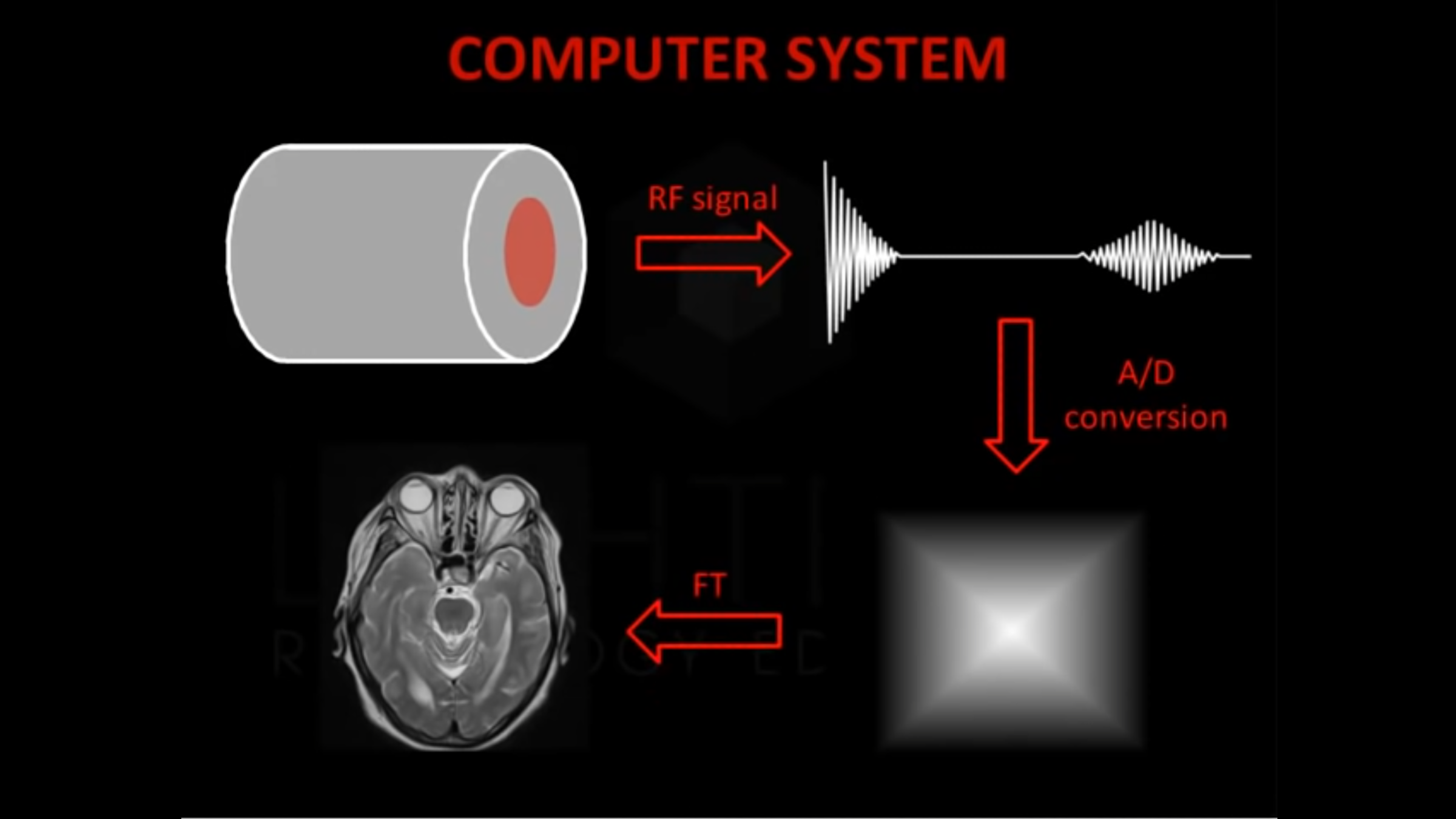
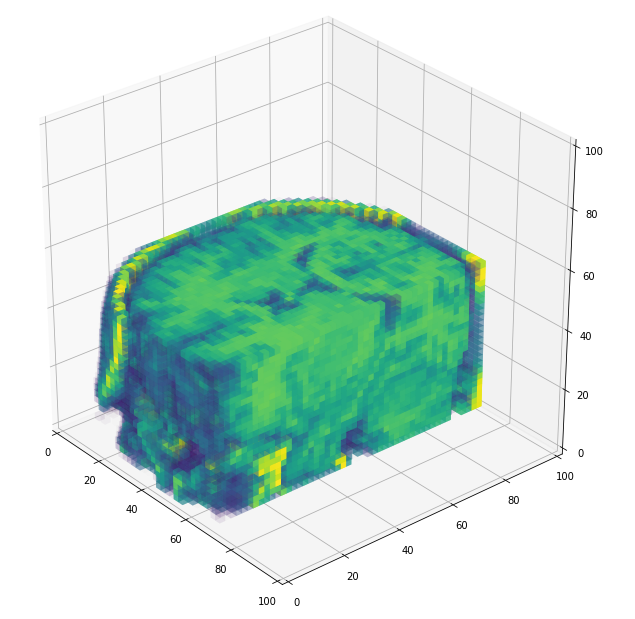
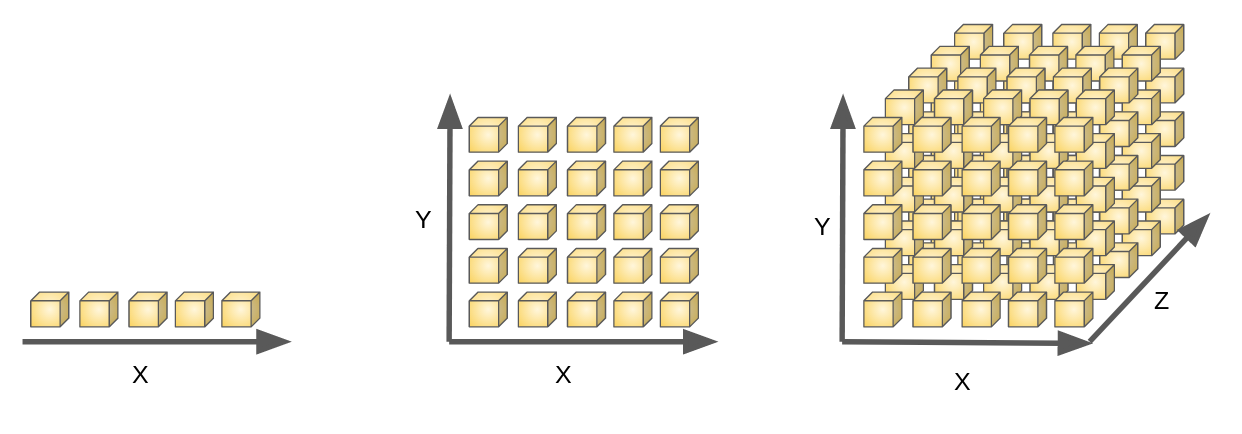
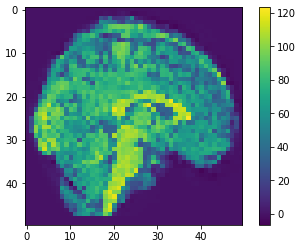
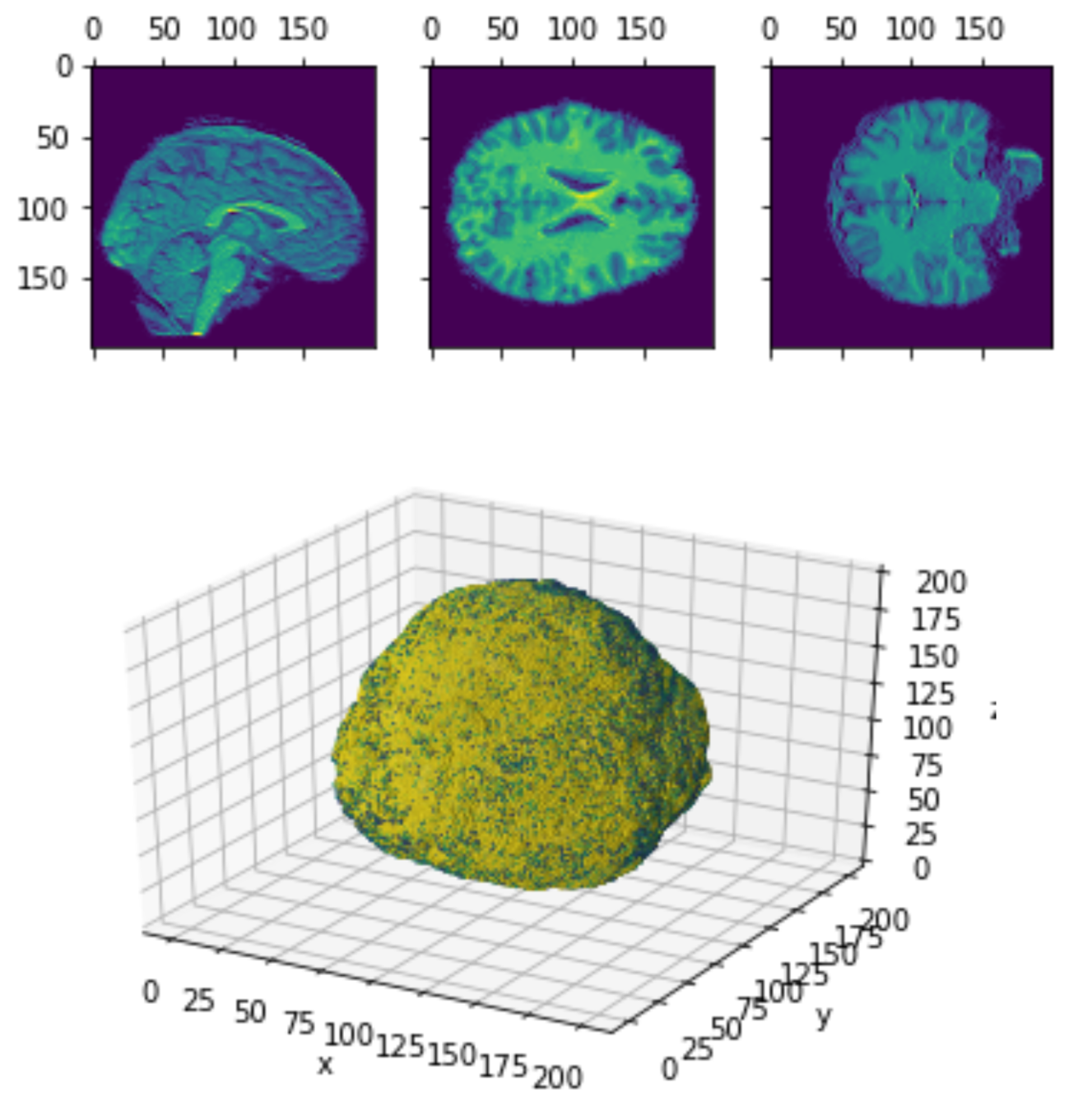
Volumetric representation
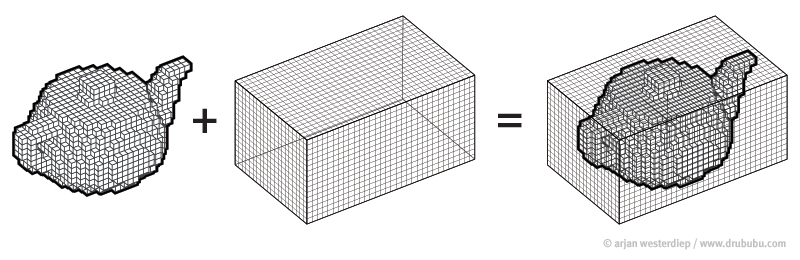
Voxelzed object
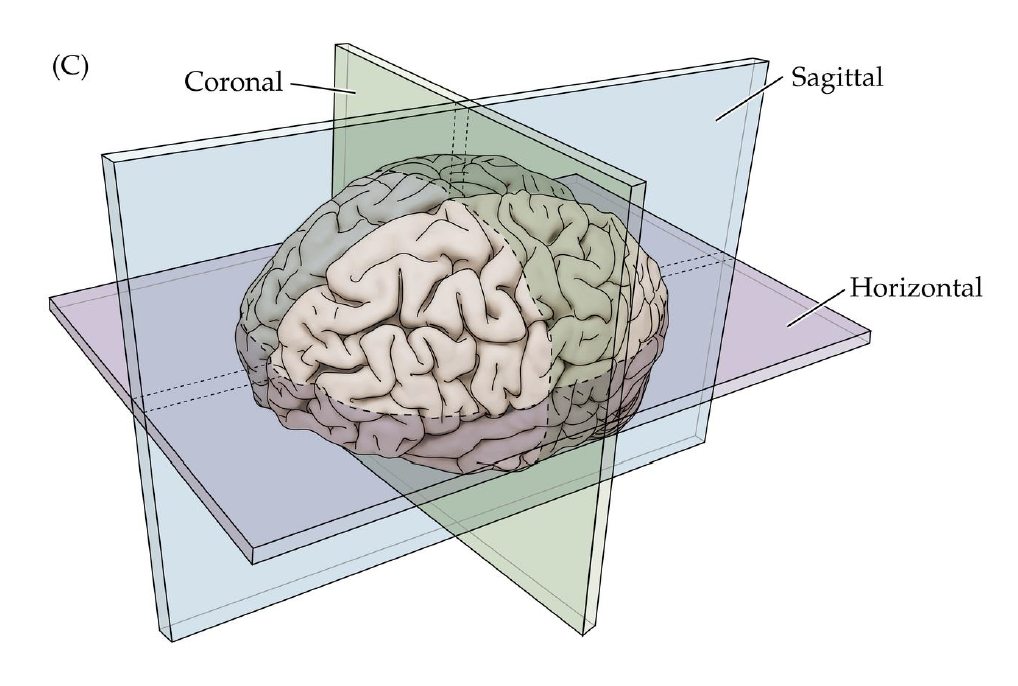
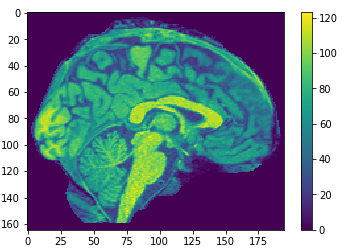
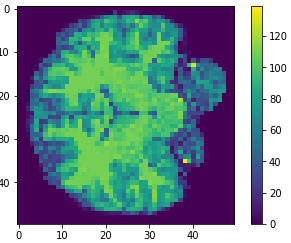
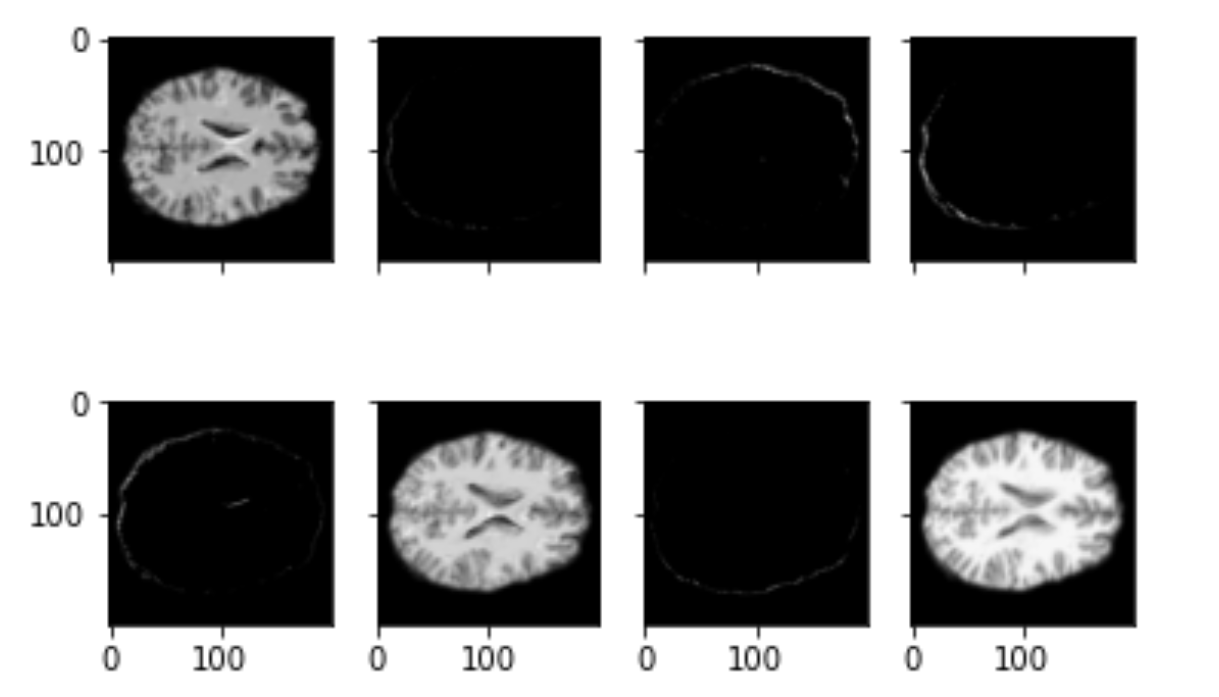
Brain slices
Tools
Python & Jupyter Notebooks
Open-source web application used for data science and scientific computing across all programming languages.

NiBabel

Matplolib
For plotting with python.
- Good documentation.
- Easy to use.
- Nice Visualizations.

Scikit-learn,
Tensorflow & Keras
Polular machine learning frameworks.
- Good documentation.
- Easy to use.
- Premade models and layers.


Data exploration
What is Dimensionality Reduction?
- Too many features while the availability of training examples is not infinite
E.g. 3D Image processing 256*256*256 = 16777216 features
- As the number of feature or dimensions grows, the amount of data we need to generalise accurately grows exponentially.
- Sometimes, most of these features are correlated and hence redundant
- Feature selection & Feature extraction
Avoid curse of dimensionality:
- Reduce computational time and space required
- Ease of fitting models with high accuracy (bye to over-fitting)
- Possibility to visualize the data when reduced to 2D or 3D
Why dimensionality reduction...
Data & Data Structure
- MRI brain images (volumetric representation)
- NIfTI (.nii) files
- Size: 17.3 GB
- 1113 samples (brains)
- Preprocessed version of data
- Skull stripping.
- Normalized.
The human connectome project, 1113 subjects’ brain T1w structural images. These 3D MPRAGE (this sounds nice) images obtained from Siemens 3T platforms using a 32-channel head coil.
Data exploration
Cropping
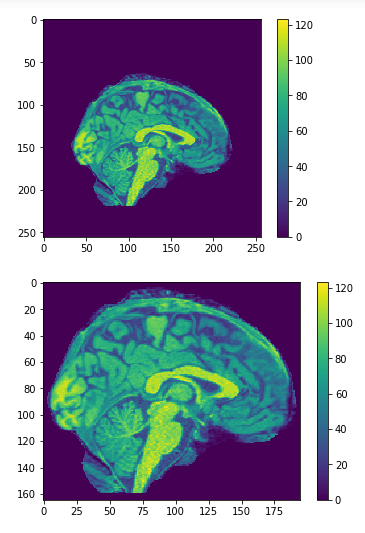
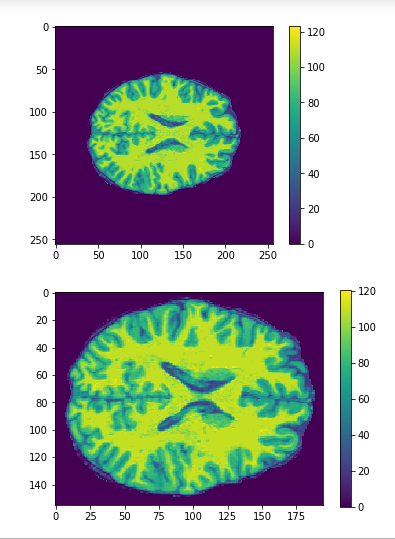
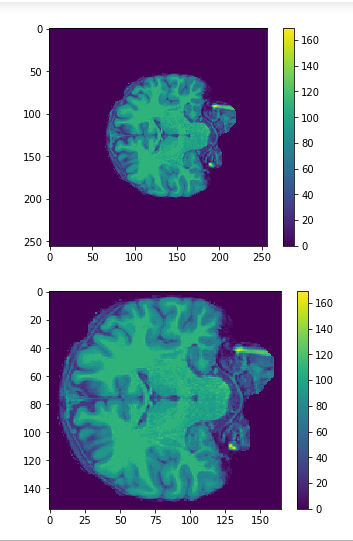
cropped = data[50:205,60:225,30:225] #155x165x195
data = img.get_data() #256x256x256
Resize
(155, 165, 195) array #4987125 voxels (50, 50, 50) array #125000 voxels
resampled = zoom(cropped, (50/cropped.shape[0], 50/cropped.shape[1] , 50/cropped.shape[2])
Flatten
(50, 50, 50) array #125000 voxels
vector = array.flatten()
(125000)array #125000 voxels
256x256x256
155x165x195
50x50x50
Original
Cropped
Resized
Input sizes
50x50x50
1113x125000
ML methods
1113
1
Flatten
SVM
KNN
PCA
SVM
SVM
Feasibility check
Data pre-processing
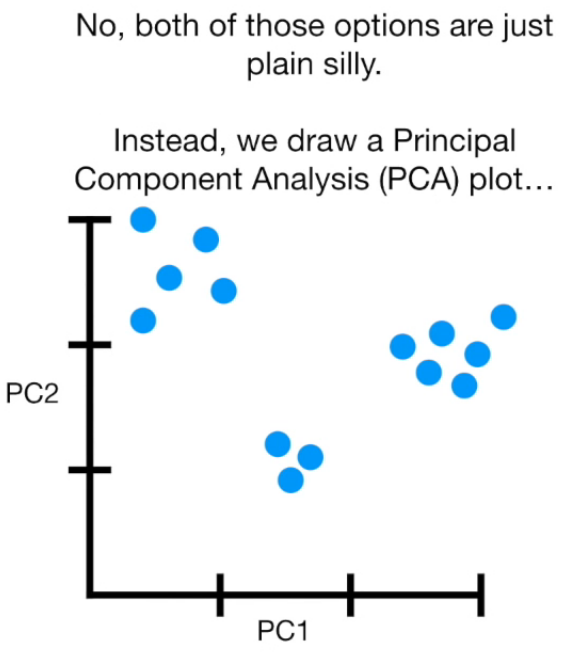
Principal Component Analysis
(PCA)
What is PCA
- Finding correlation between variables.
- Separating samples on a dataset.
- Eigenvalues and eigenvectors (axes of subspace)
Principal Component Analysis (PCA) is a dimension-reduction tool that can be used to reduce a large set of variables to a small set that still contains most of the information in the large set.
Visually

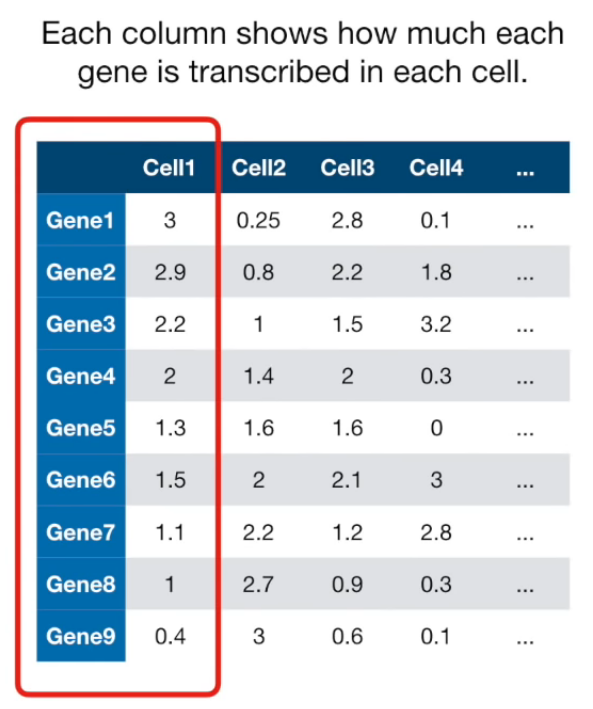
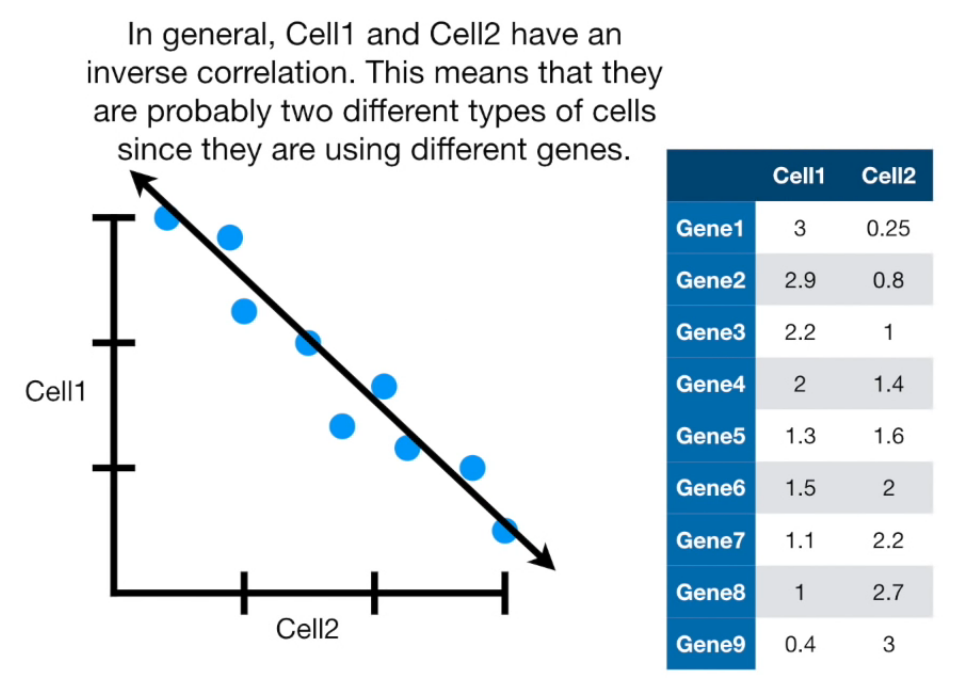
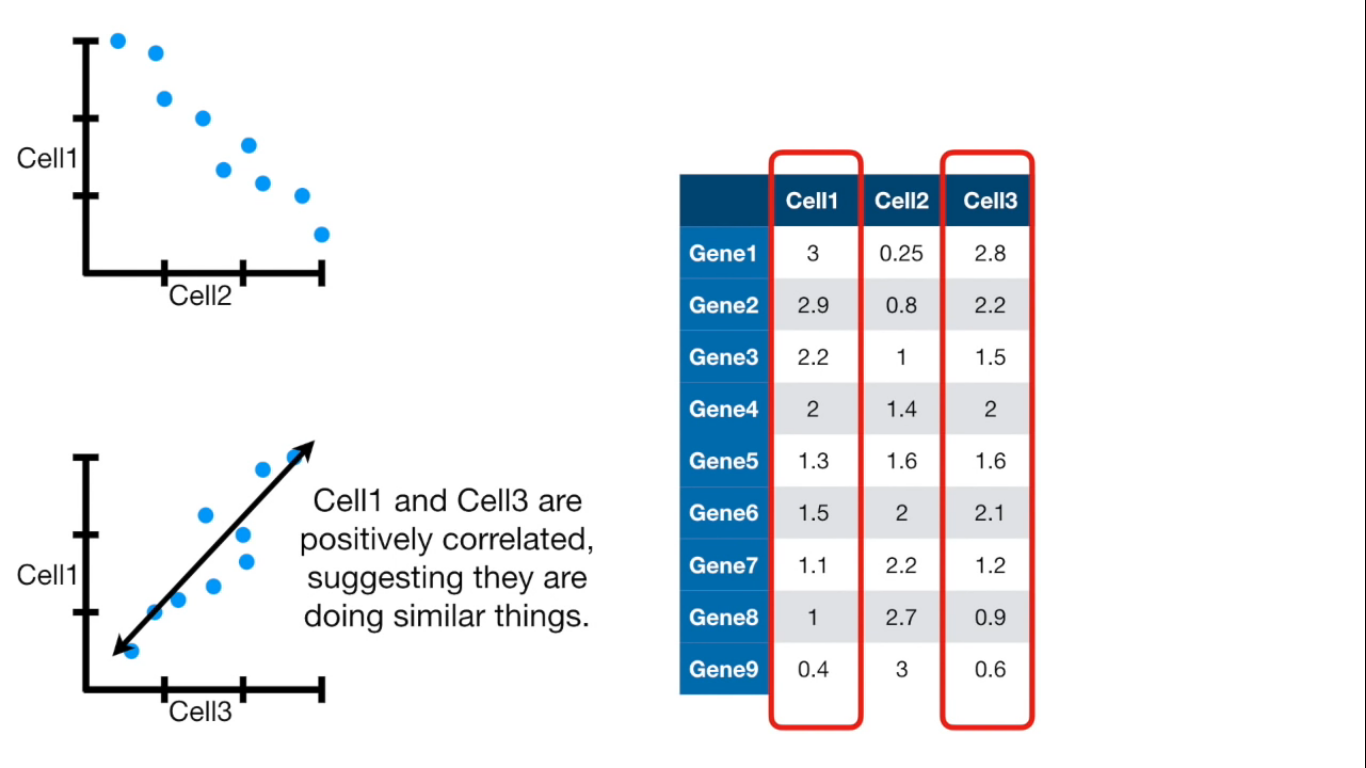
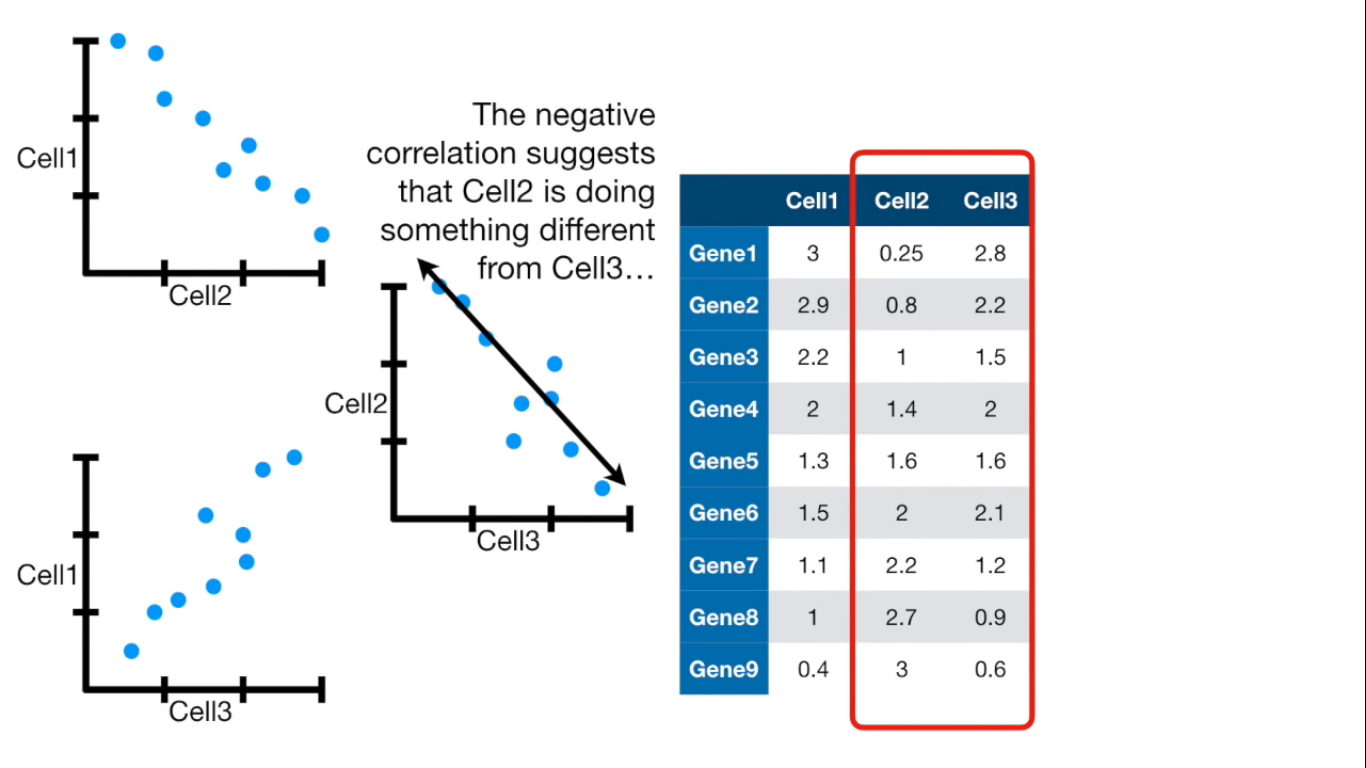
If more than 4 columns...

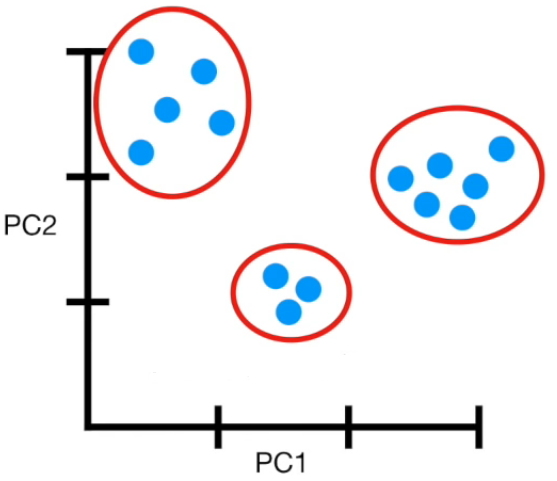
Feature extraction
- Loading data
- Applying PCA choosing amount of components
- Plotting
- Reconstructing data from components
import numpy as np
to_save_load=np.load("to_save.npy")
to_save_load.shape
(1113, 125000)
Loading data
from sklearn.decomposition import PCA
pca = PCA(n_components=10)#% of variance or number
principalComponents = pca.fit_transform(to_save_load)
(1113, 10)
Applying PCA

l = pca.explained_variance_ratio_
sum(l)#0.412558136188802
Plotting
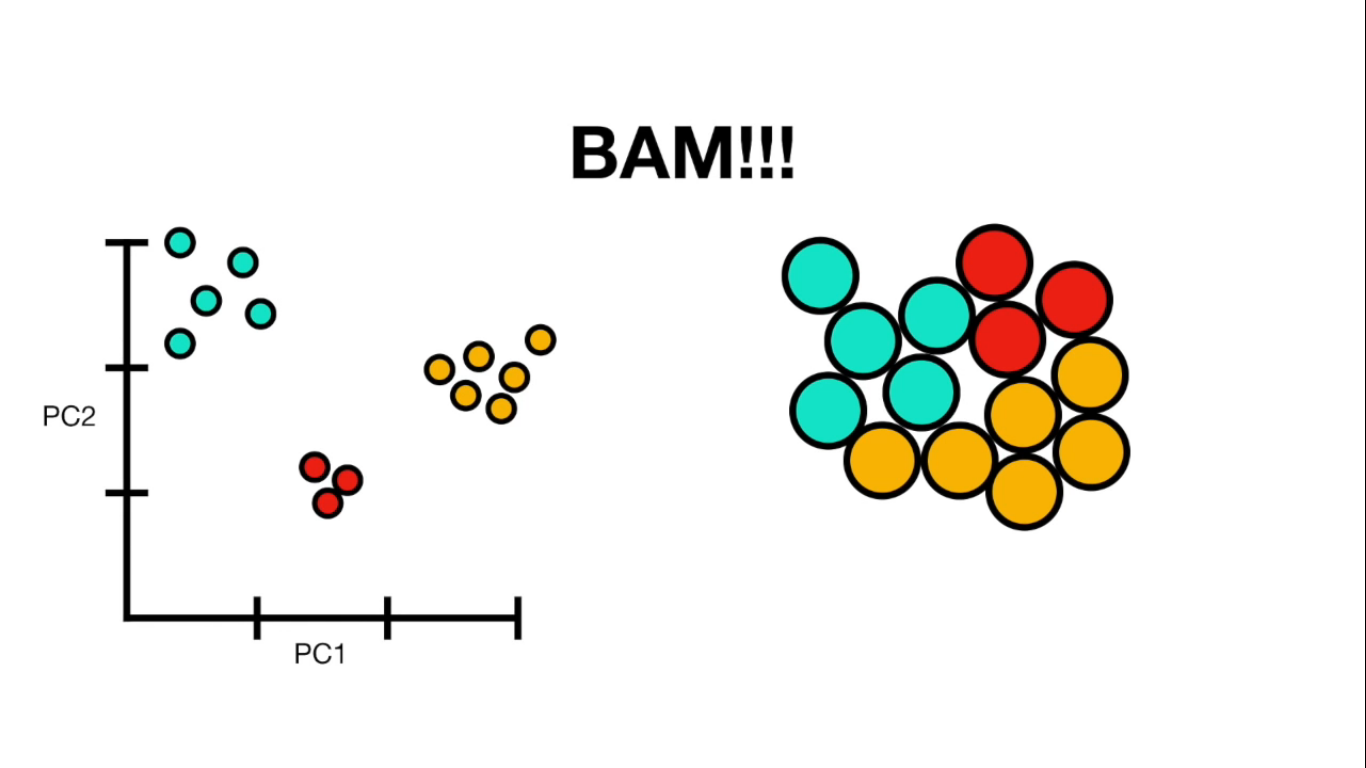
Labeling
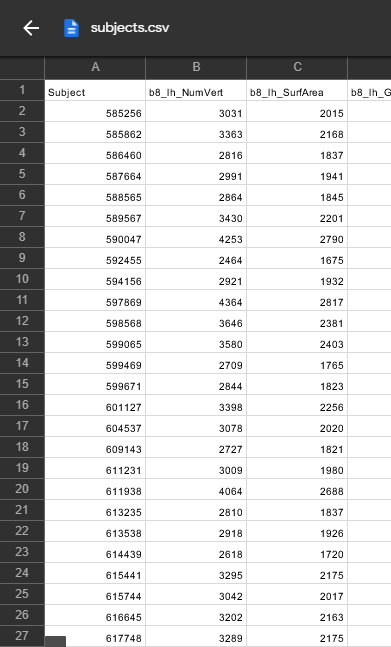
import pandas as pd
subjects = pd.read_csv('subjects.csv')
columns = subjects[['Subject','class']]
labels= columns.set_index('Subject').T.to_dict('list')
import os
dirs = os.listdir( "brain_nii" )
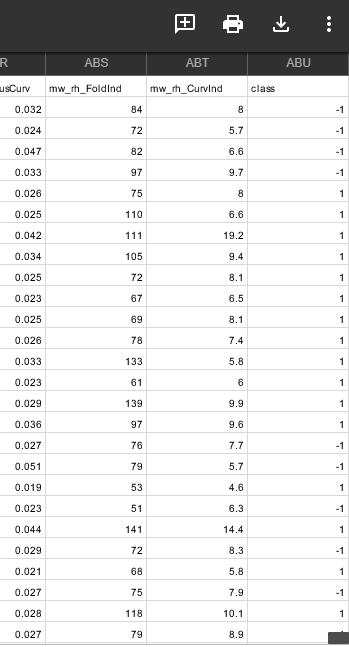
Getting Colors
{585256: [-1], 585862: [-1], 586460: [-1], 587664: [-1], 588565: [1],...}
colors = []
for name in dirs:
id,ext = name.split('.')
try:
colors.append(labels[int(id)][0])
except:
colors.append(0)
[1, -1, 1, 1, 1, 1, 1, 1, -1, 1, -1, -1, 1, 1,...]
#1,0(unlabeled) ,-1
Separate classes
class1 = frame[(frame['class']== 1)] print("Total class 1:", len(class1)) class2 = frame[(frame['class']== 0)] print("Total class 0:", len(class2))
Total class 1: 550
Total class 0: 558
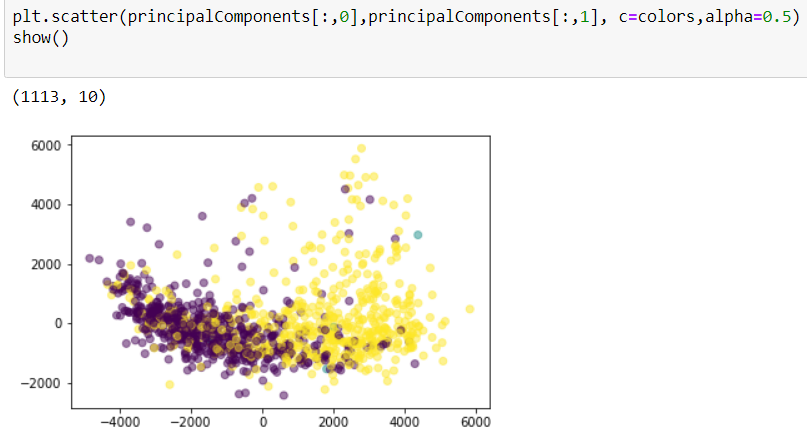
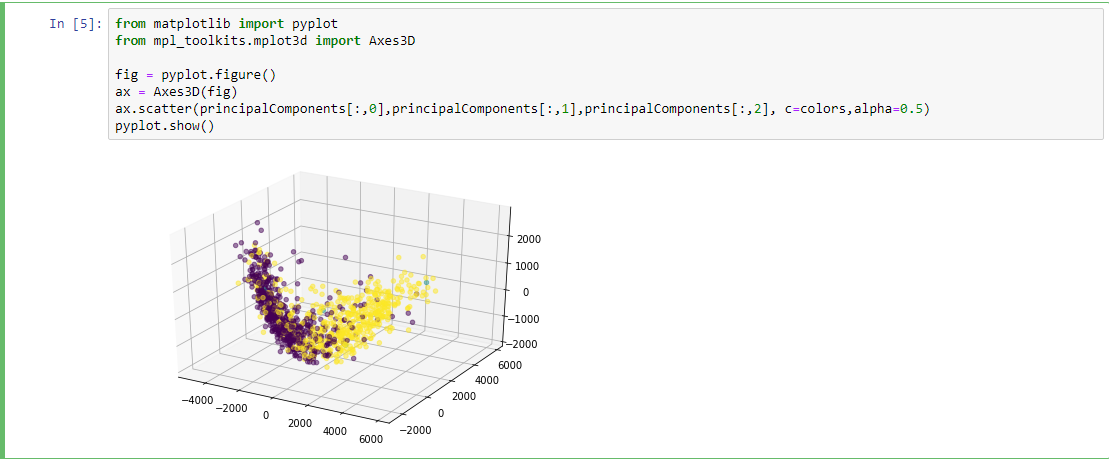
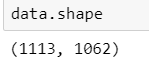
Post-PCA Data Proprocessing
After PCA:
- Data set of dimension 1113x1062 ('PCA.npy')
- Data in the form of array (npy format)

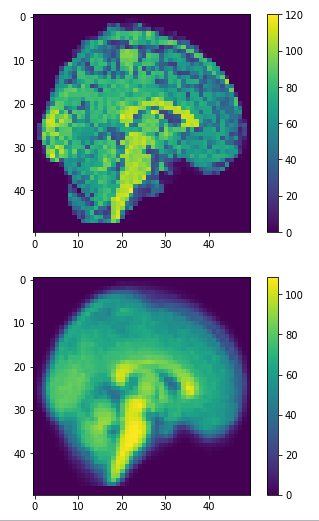
dim=50
approximation = pca.inverse_transform(principalComponents)
restored = approximation.reshape(-1,dim,dim,dim)
(1113, 50,50,50)
10
100
500
0.41
0.81
0.59
PCA reconstruction
Eigen brains
Eigen brains.
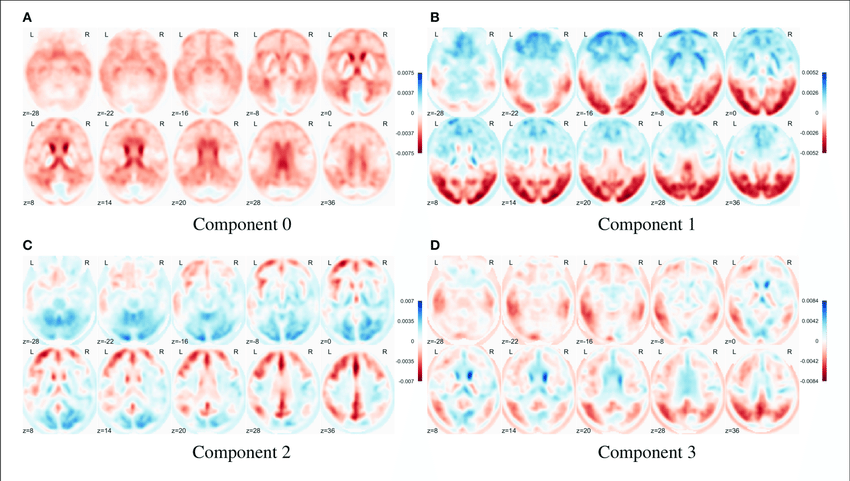
First four eigenbrains (components 0 to 3) of the PET ADNI dataset. (Functional Brain Imaging Synthesis Based on Image Decomposition and Kernel Modeling: Application to Neurodegenerative Diseases)
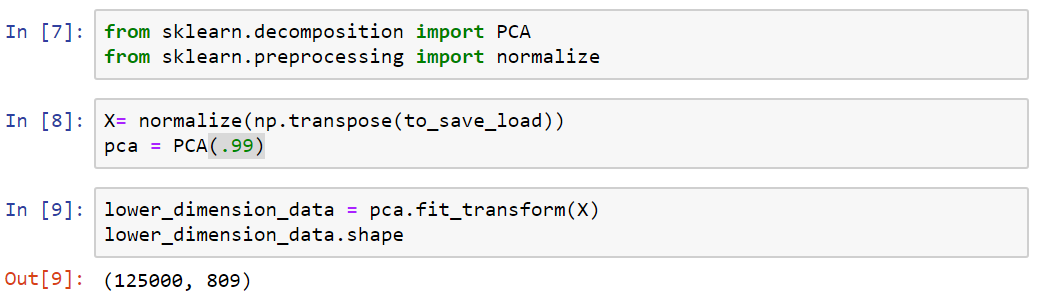
Applying PCA
1113x125000
125000x1113
125000x809
Transpose
PCA(99.9)
Reshaping

125000x809
Transpose
Reshape
50x50x50
eigen brain 809
eigen brain 1
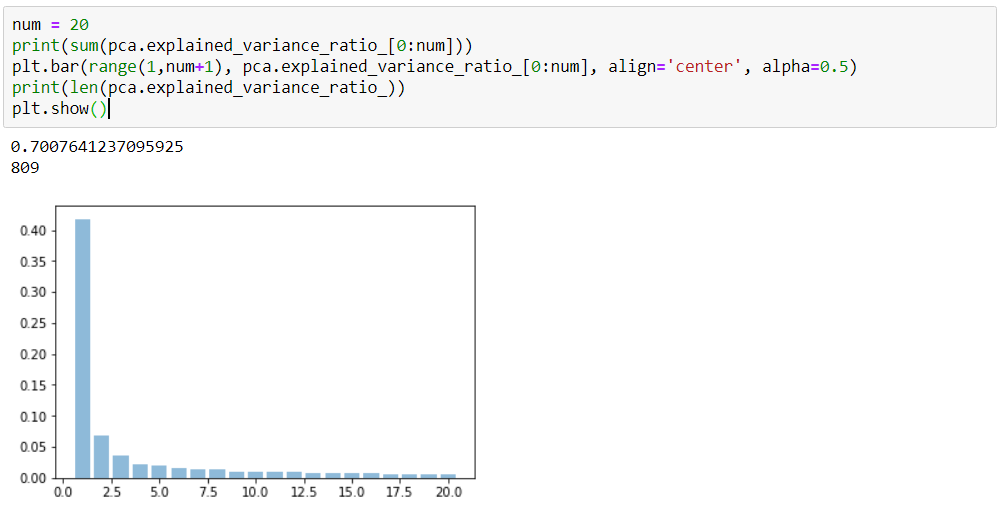
Plotting

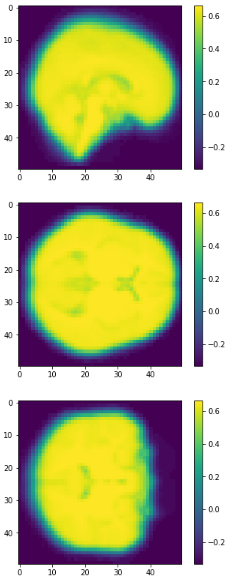
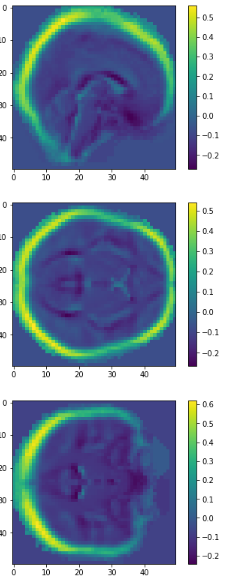

0.417
0.069
0.035
0.022
1
2
3
4
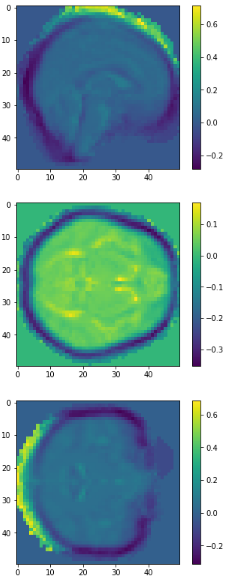
Average brains
from sklearn.preprocessing import normalize average_brain1 = normalize(class1).mean(0) average_brain2 = normalize(class2).mean(0) avg_vol1 = average_brain1.reshape(50,50,50) print(avg_vol1.shape) avg_vol2 = average_brain2.reshape(50,50,50) print(avg_vol2.shape)
(50, 50, 50)
(50, 50, 50)
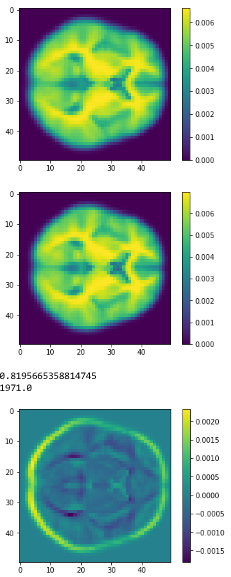
c1
c2
diff

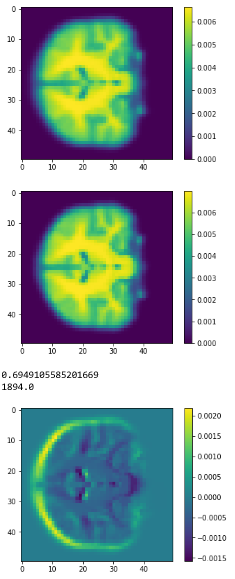
class1
class2
3D volume (fail)
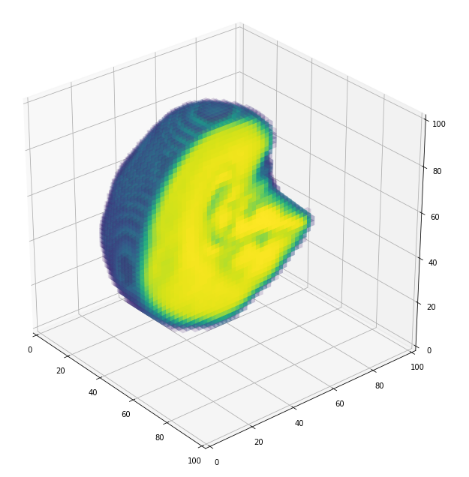
Training
Classification
- Resampling and hyperparameter tunning
- Models fittings
Model fittings
- Logistic Regression
- Support Vector Machine with Linear Kernel
- Support Vector Machine with Gaussian Kernel
- K-nearest neighbors (k-nn)
- 3D Convolutional Neural Networks (3DCNN)
Model fittings
Underfitting happens when a model unable to capture the underlying pattern of the data => high bias, low variance
Overfitting happens when model captures the noise along with the underlying pattern in data. In other words, our model is trained a lot over noisy data => low bias, high variance
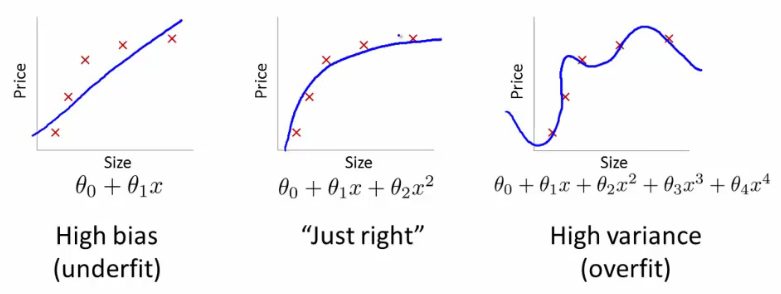
Model fittings
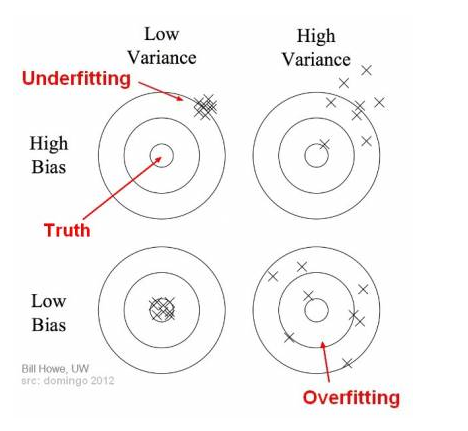
Why over-fitting:
- Too complex models, too many features
- Too small training data set
- Too small regularization term
...
Why under-fitting:
- Too simple model while the data are too complex
- Too large regularization term
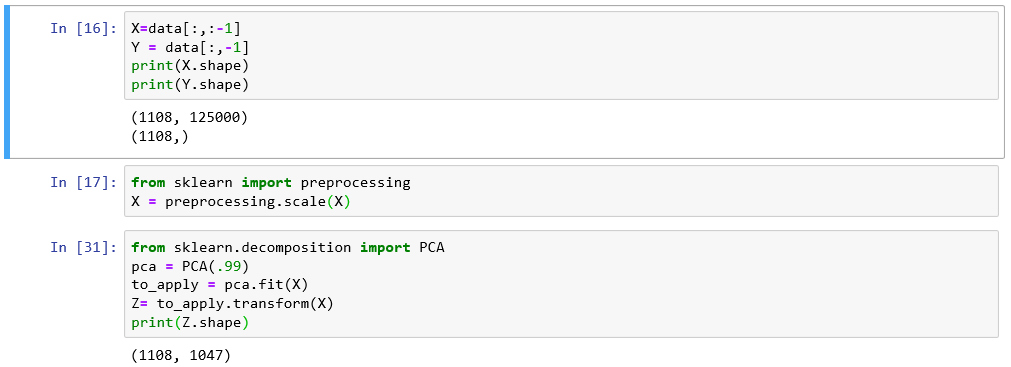
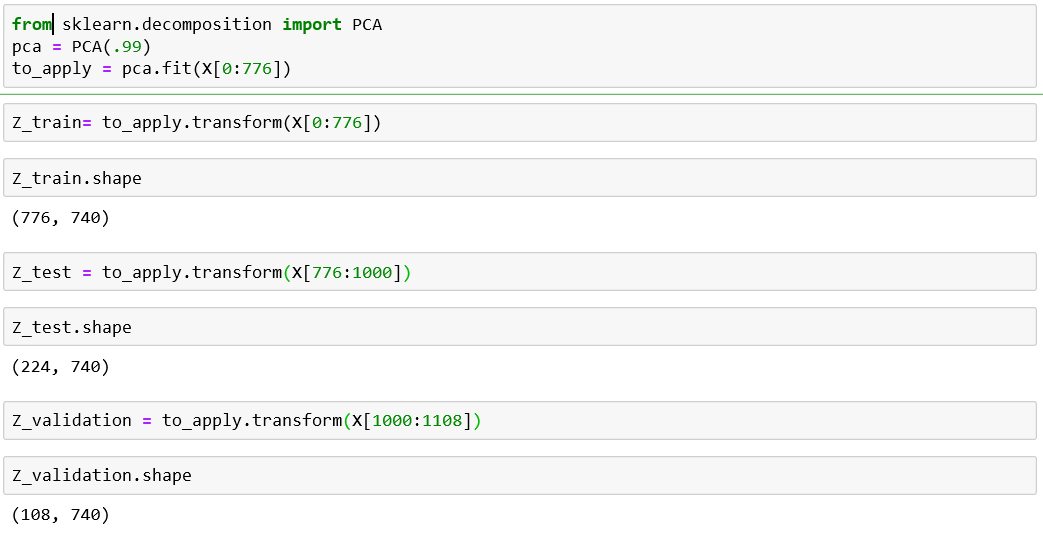
PCA should only be applied on the training set
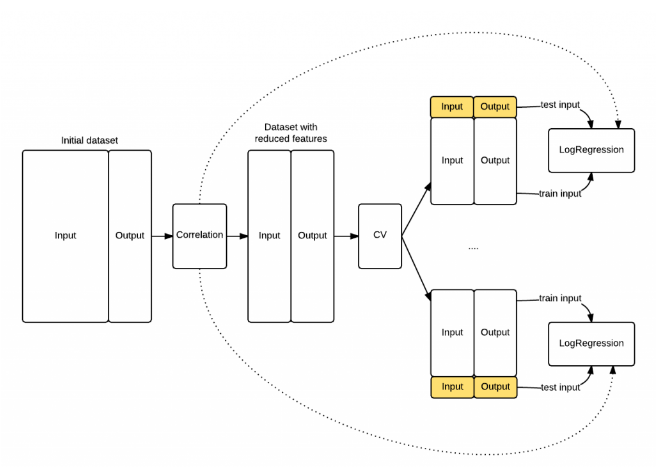
Introducing bias to dataset
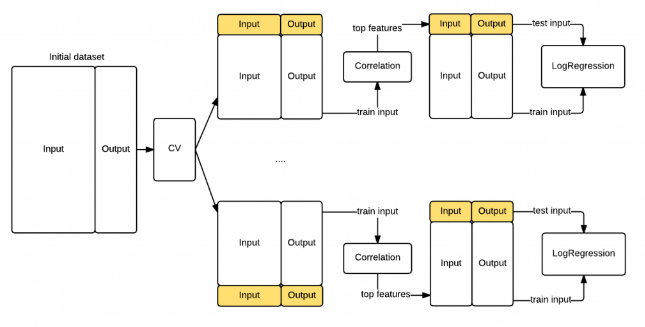
Avoding bias when applying PCA
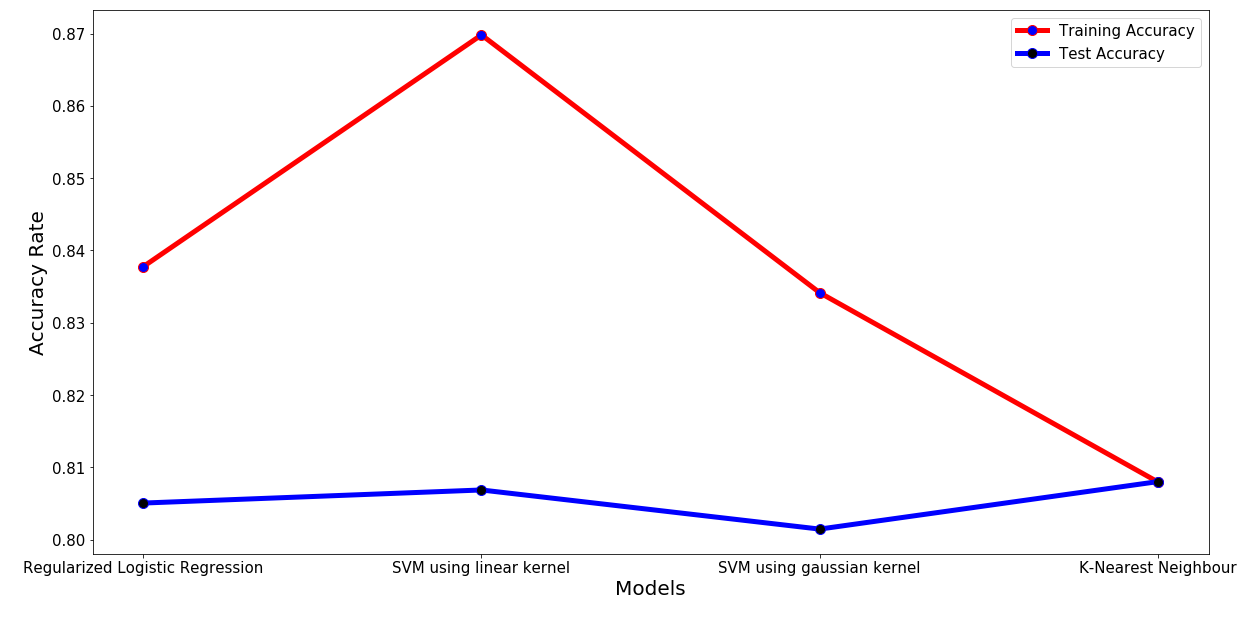
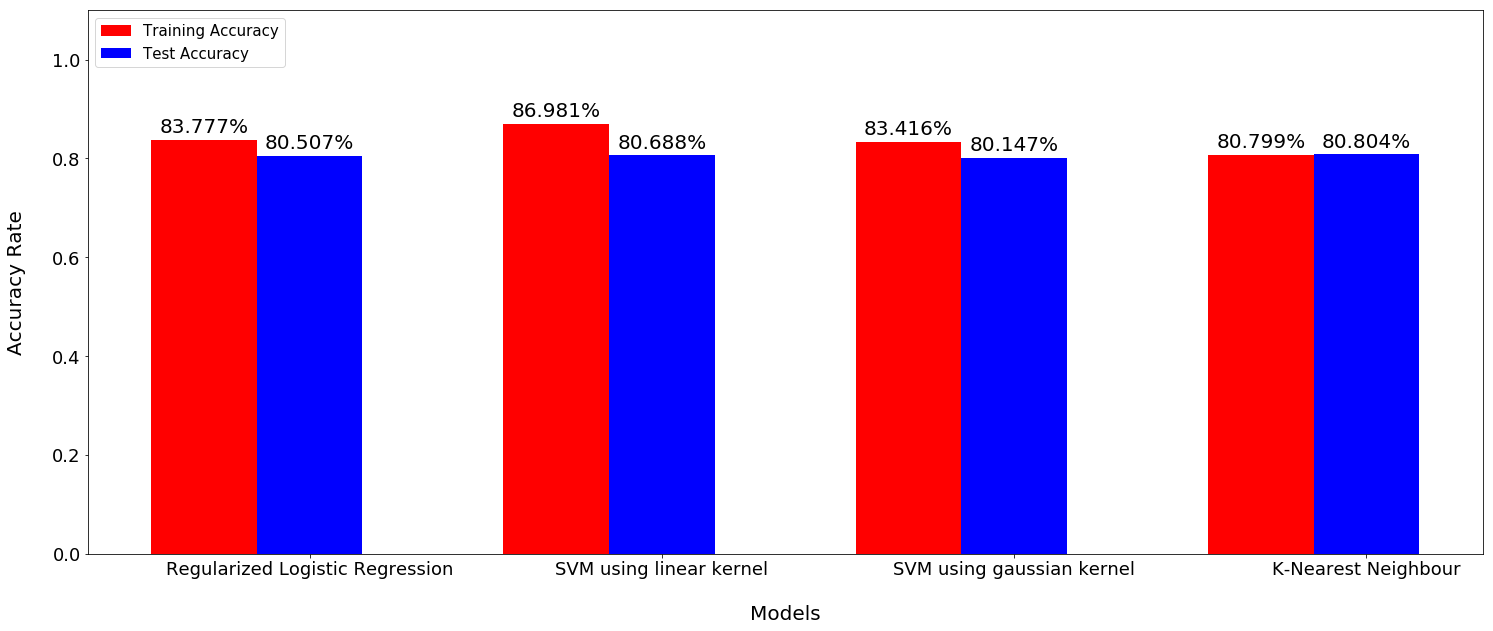
Logistic Regression
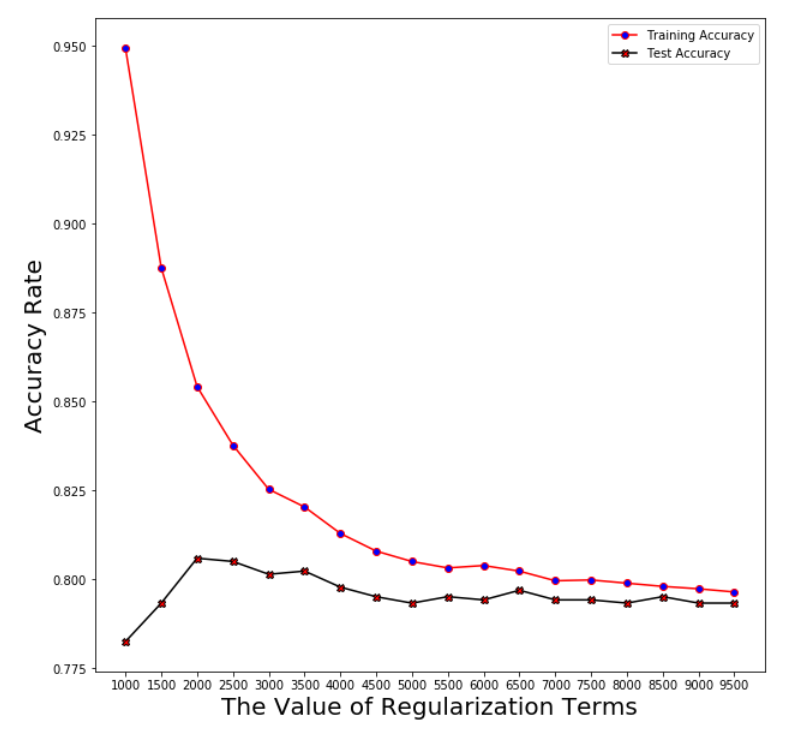
Logistic Regression
Regularization term: log_reg_term=2500
Averaged training accuracy: 83.78%
Averaged test accuracy: 80.51%
Support Vector Machine
- A discriminative classifier formally defined by a separating hyperplane
- The algorithm outputs an optimal hyperplane which categorizes new examples (a line in 2-D dimension)
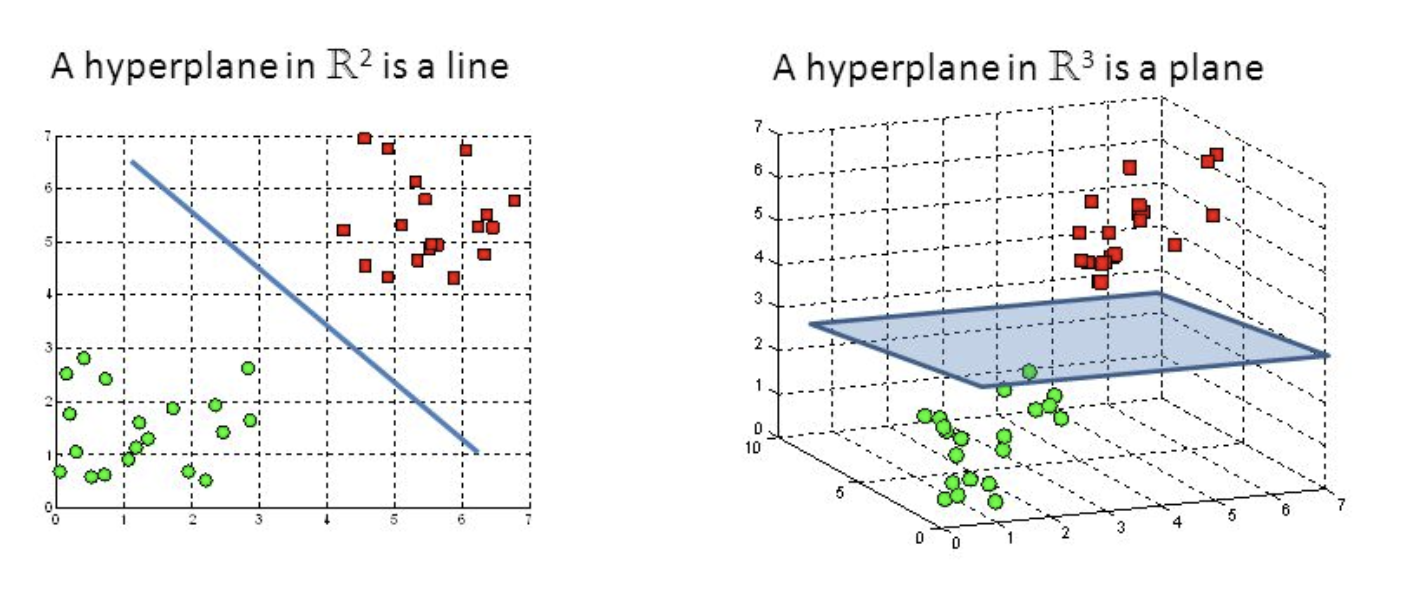
Support Vector Machine
Support Vector Machine
Plotting the averaged training and test error after running through 5 folds
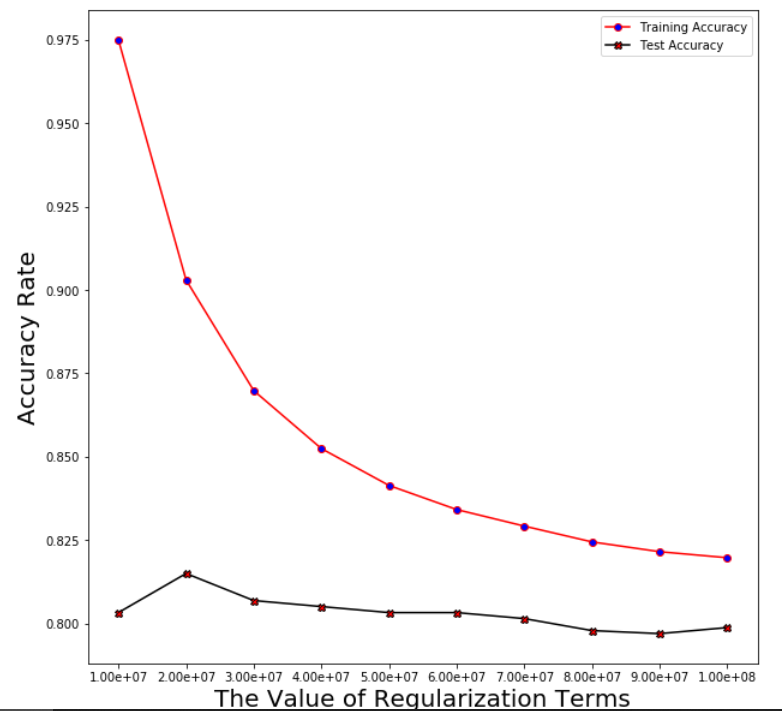
Support Vector Machine
Regularization linear_svc_reg=3*10**7
Averaged training accuracy: 86.98%
Averaged test accuracy: 80.69%
Support Vector Machine with Gaussian Kernel
Best test accuracy: 0.8014716073539603
Best regularization term: 1
Best gamma: 100000000
K nearest neighbors
(KNN)
the input consists of the k closest training examples in the feature space.
(modified pipeline)
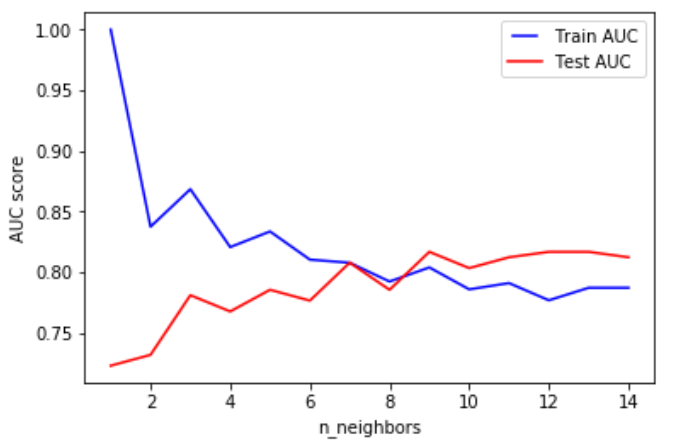
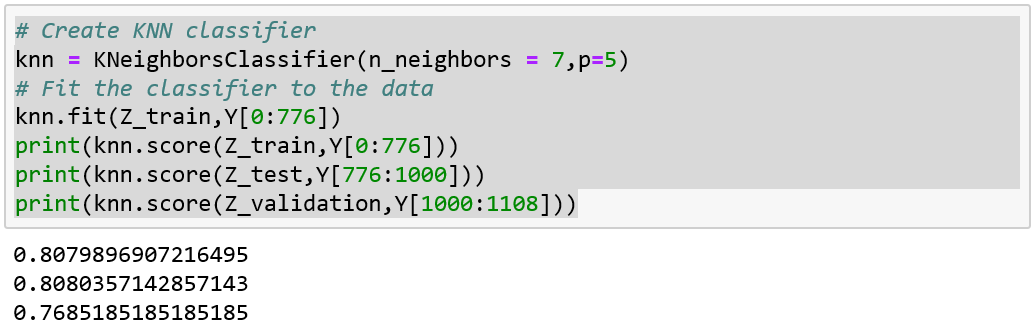
best parameters only for that test fold!!!
Models Performance
Models Performance
(PCA)
3DCNN
[1108x155x165x195x1]
1108
1
[256x256x256]
[155x165x195]
Original
Cropped
Input Tensor
Layer (type) Output Shape Param #
=================================================================
conv1 (Conv3D) (None, 155, 165, 195, 8) 1728008
_________________________________________________________________
max_pooling3d (MaxPooling3D) (None, 51, 55, 65, 8) 0
_________________________________________________________________
conv2 (Conv3D) (None, 51, 55, 65, 16) 2000016
_________________________________________________________________
max_pooling3d_1 (MaxPooling3 (None, 25, 27, 32, 16) 0
_________________________________________________________________
conv3 (Conv3D) (None, 25, 27, 32, 32) 1728032
_________________________________________________________________
max_pooling3d_2 (MaxPooling3 (None, 12, 13, 16, 32) 0
_________________________________________________________________
conv3d (Conv3D) (None, 12, 13, 16, 64) 2048064
_________________________________________________________________
max_pooling3d_3 (MaxPooling3 (None, 6, 6, 8, 64) 0
_________________________________________________________________
conv3d_1 (Conv3D) (None, 6, 6, 8, 128) 1024128
_________________________________________________________________
max_pooling3d_4 (MaxPooling3 (None, 3, 3, 4, 128) 0
_________________________________________________________________
flatten (Flatten) (None, 4608) 0
_________________________________________________________________
dense (Dense) (None, 2048) 9439232
_________________________________________________________________
dense_1 (Dense) (None, 512) 1049088
_________________________________________________________________
predictions (Dense) (None, 1) 513
=================================================================
Total params: 19,017,081
Trainable params: 19,017,081
Non-trainable params: 0
1st test
First attempt
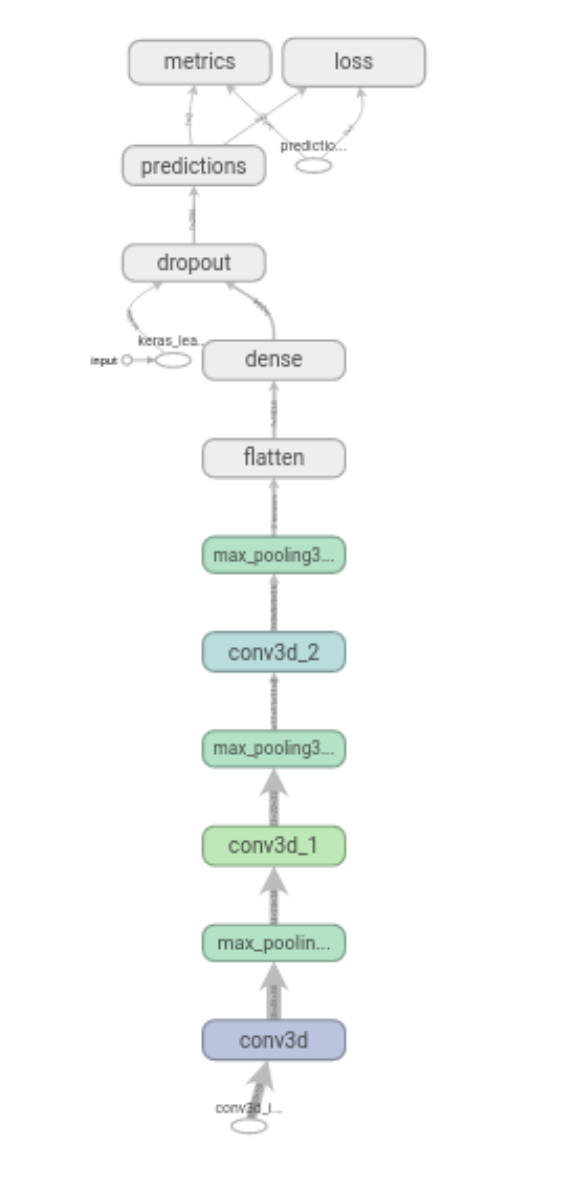
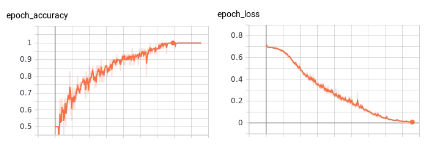
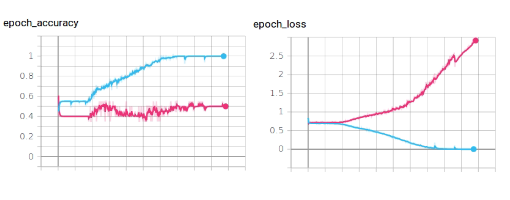
[1108x155x165x195x1]
1108
1
[256x256x256]
[155x165x195]
Original
Cropped
Input Tensor
Layer (type) Output Shape Param #
=================================================================
conv1 (Conv3D) (None, 155, 165, 195, 8) 1728008
_________________________________________________________________
max_pooling3d (MaxPooling3D) (None, 51, 55, 65, 8) 0
_________________________________________________________________
conv2 (Conv3D) (None, 51, 55, 65, 16) 2000016
_________________________________________________________________
max_pooling3d_1 (MaxPooling3 (None, 25, 27, 32, 16) 0
_________________________________________________________________
conv3 (Conv3D) (None, 25, 27, 32, 32) 1728032
_________________________________________________________________
max_pooling3d_2 (MaxPooling3 (None, 12, 13, 16, 32) 0
_________________________________________________________________
conv3d (Conv3D) (None, 12, 13, 16, 64) 2048064
_________________________________________________________________
max_pooling3d_3 (MaxPooling3 (None, 6, 6, 8, 64) 0
_________________________________________________________________
conv3d_1 (Conv3D) (None, 6, 6, 8, 128) 1024128
_________________________________________________________________
max_pooling3d_4 (MaxPooling3 (None, 3, 3, 4, 128) 0
_________________________________________________________________
flatten (Flatten) (None, 4608) 0
_________________________________________________________________
dense (Dense) (None, 2048) 9439232
_________________________________________________________________
dense_1 (Dense) (None, 512) 1049088
_________________________________________________________________
predictions (Dense) (None, 1) 513
=================================================================
Total params: 19,017,081
Trainable params: 19,017,081
Non-trainable params: 0
1108
1
[256x256x256]
[200^3]
Original
Cropped
Input Tensors
[150^3, 100^3, 50^3]
Resized
3DCNN Input
Input Tensors

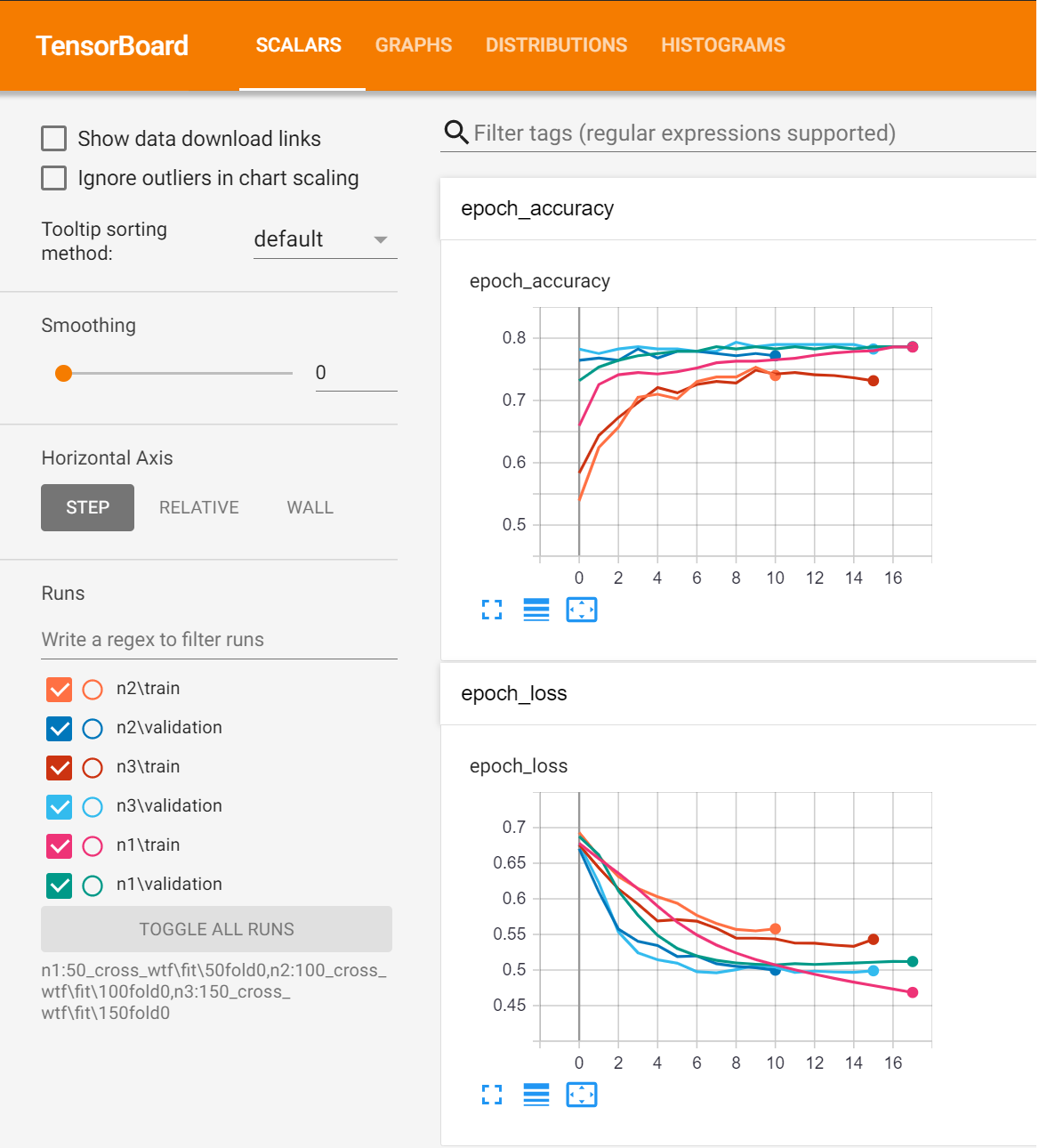
3DCNN
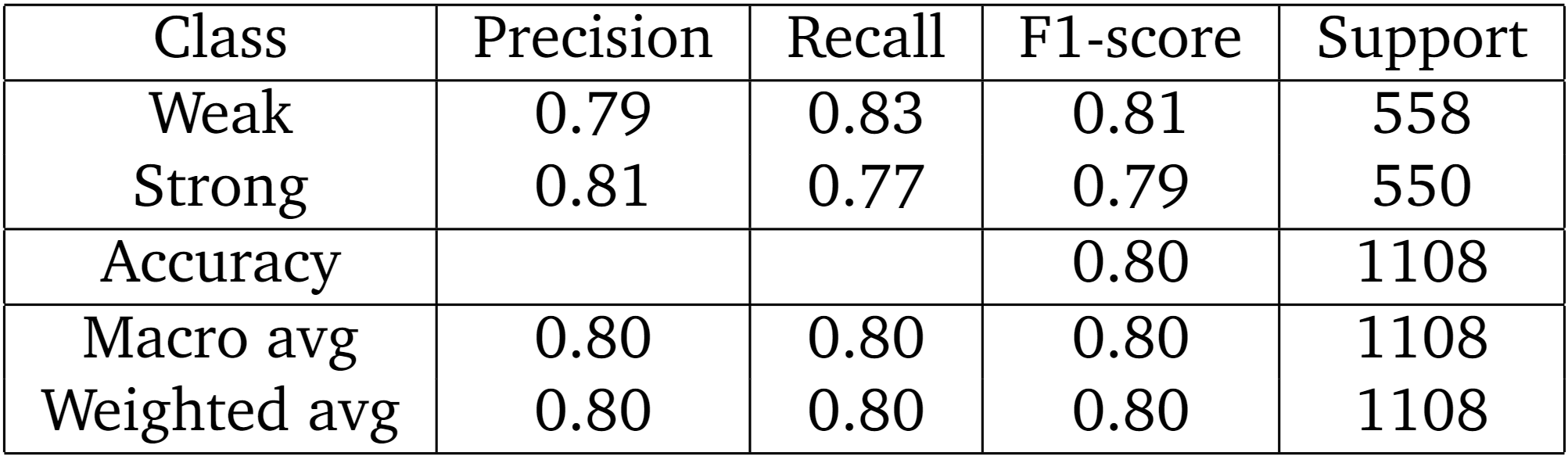
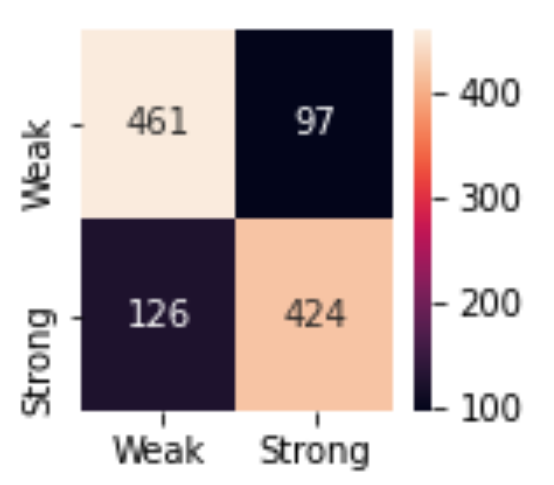
Results
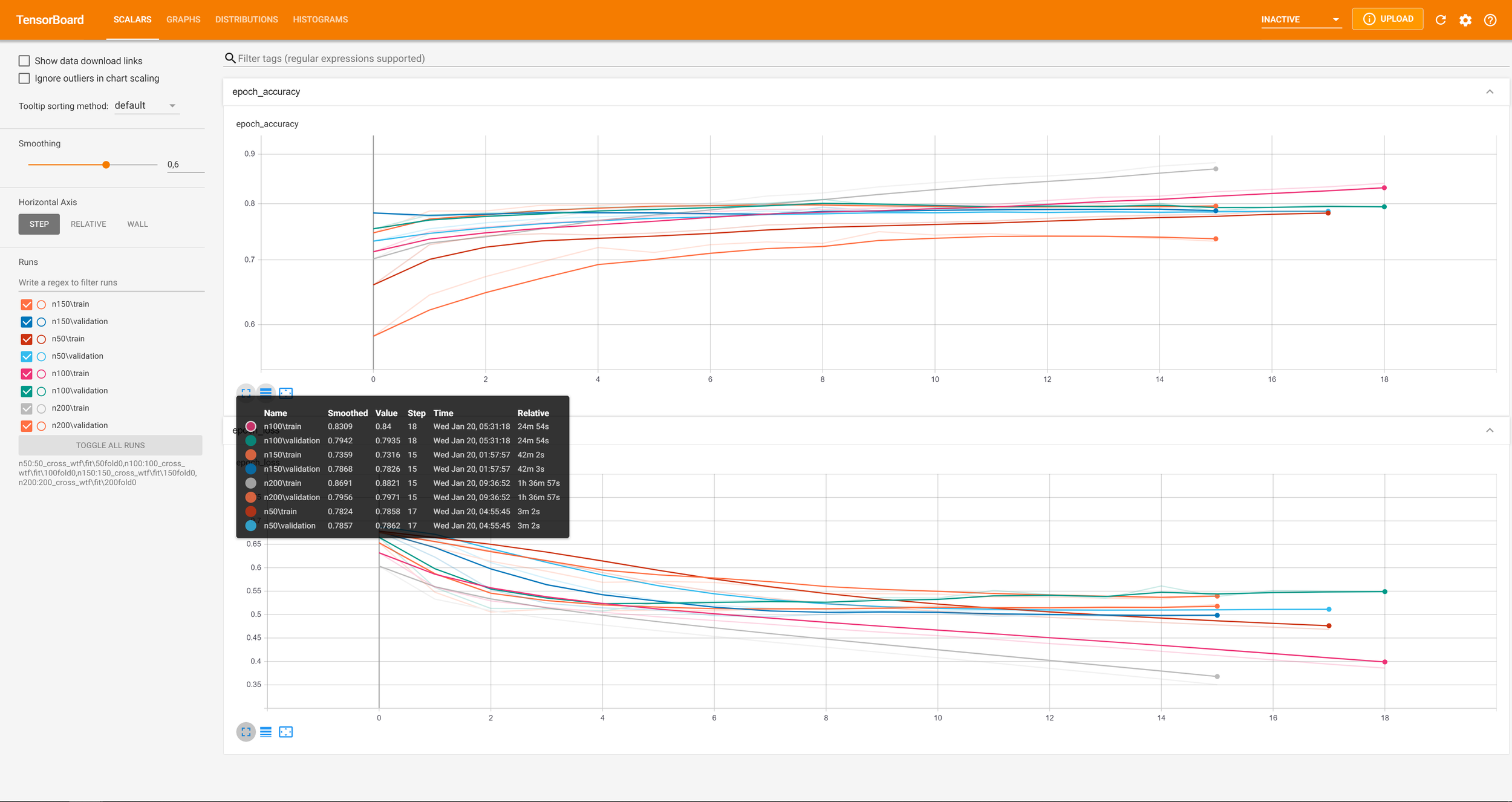

Multi-resolution test Results
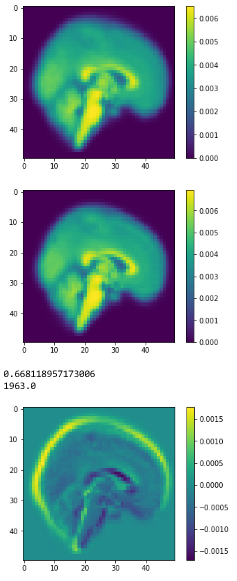
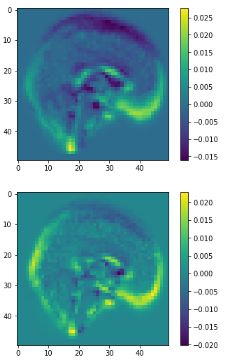
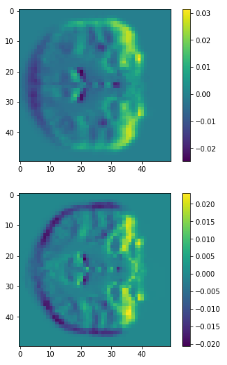
Layer Visualizations

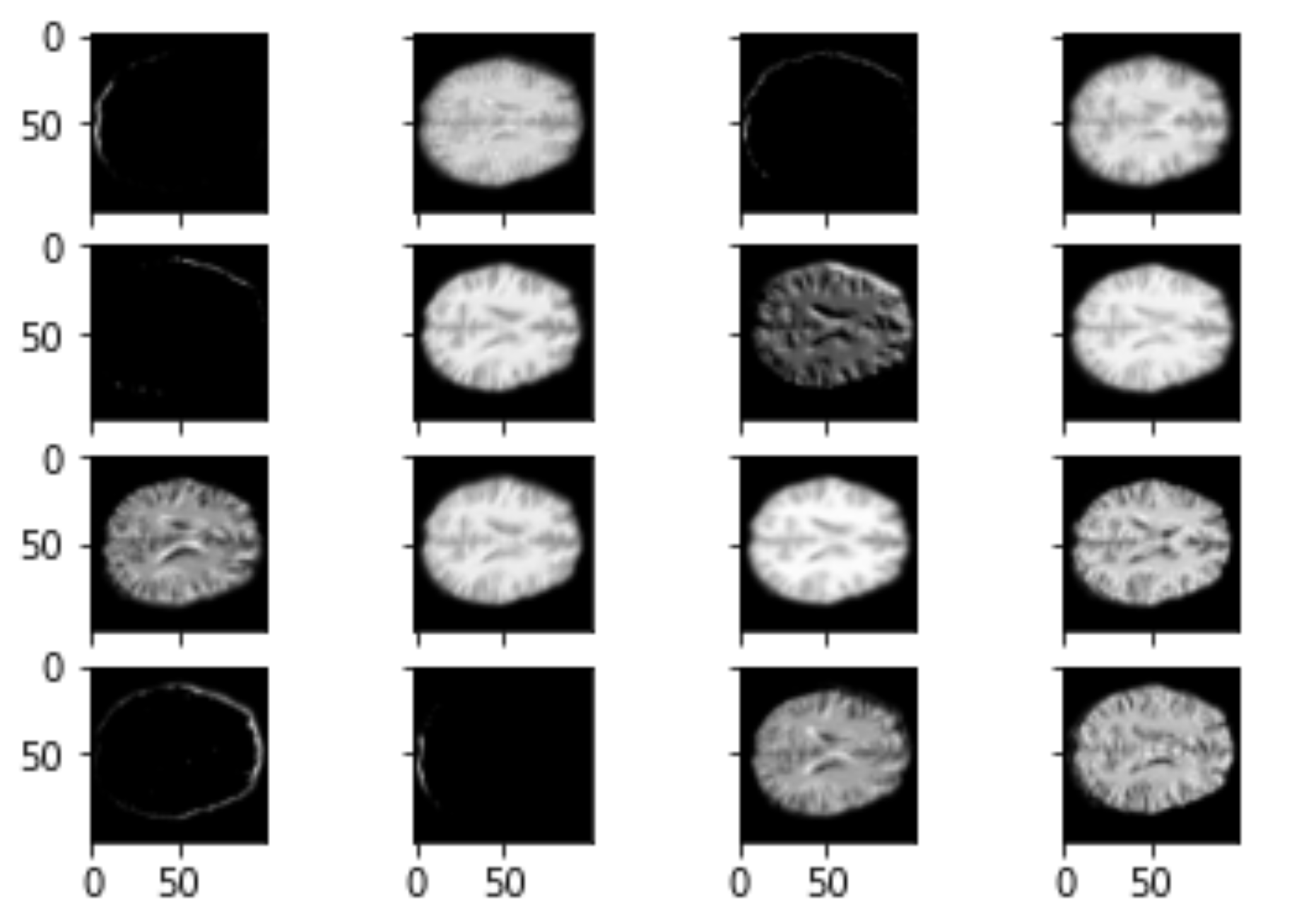

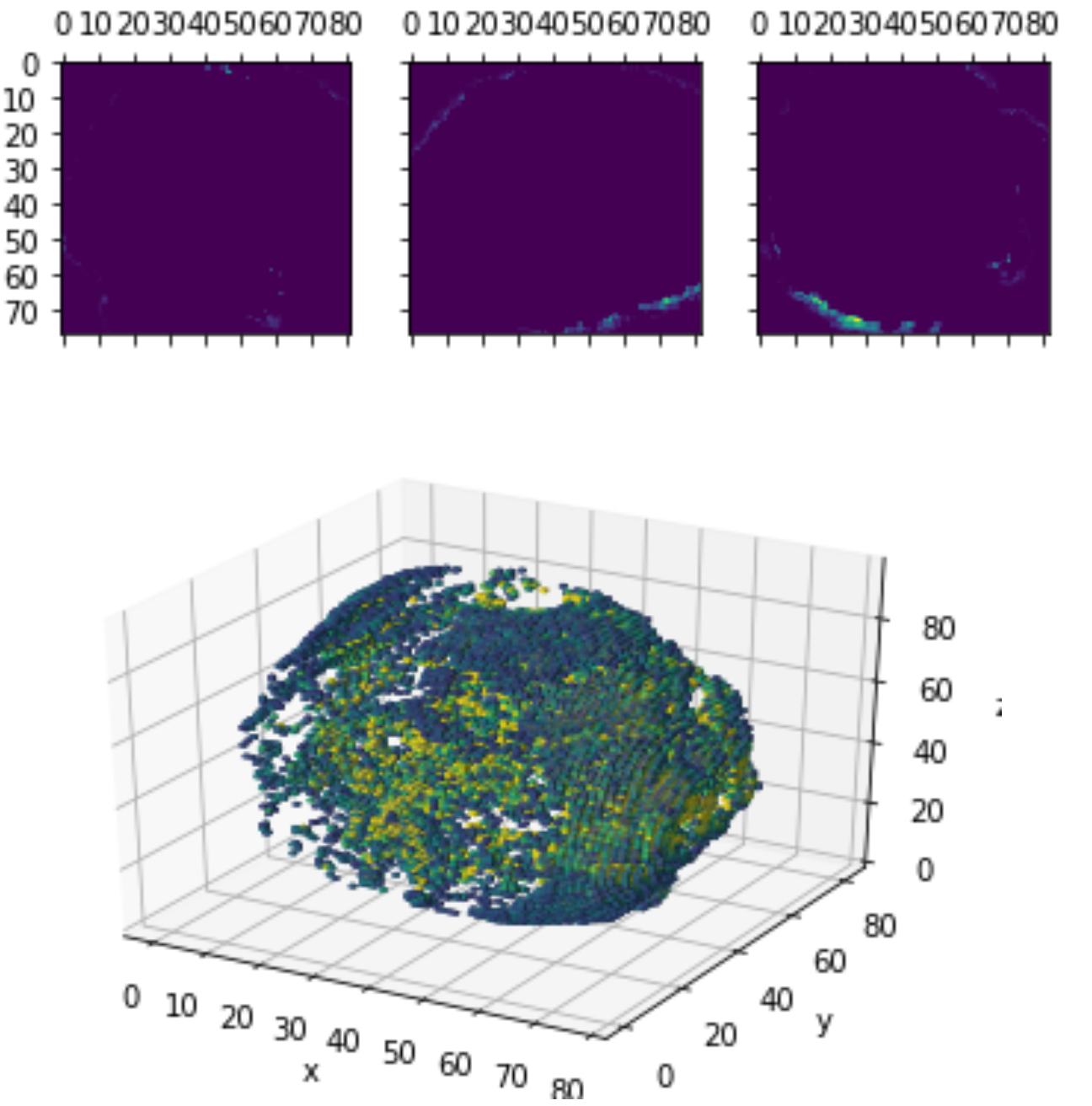
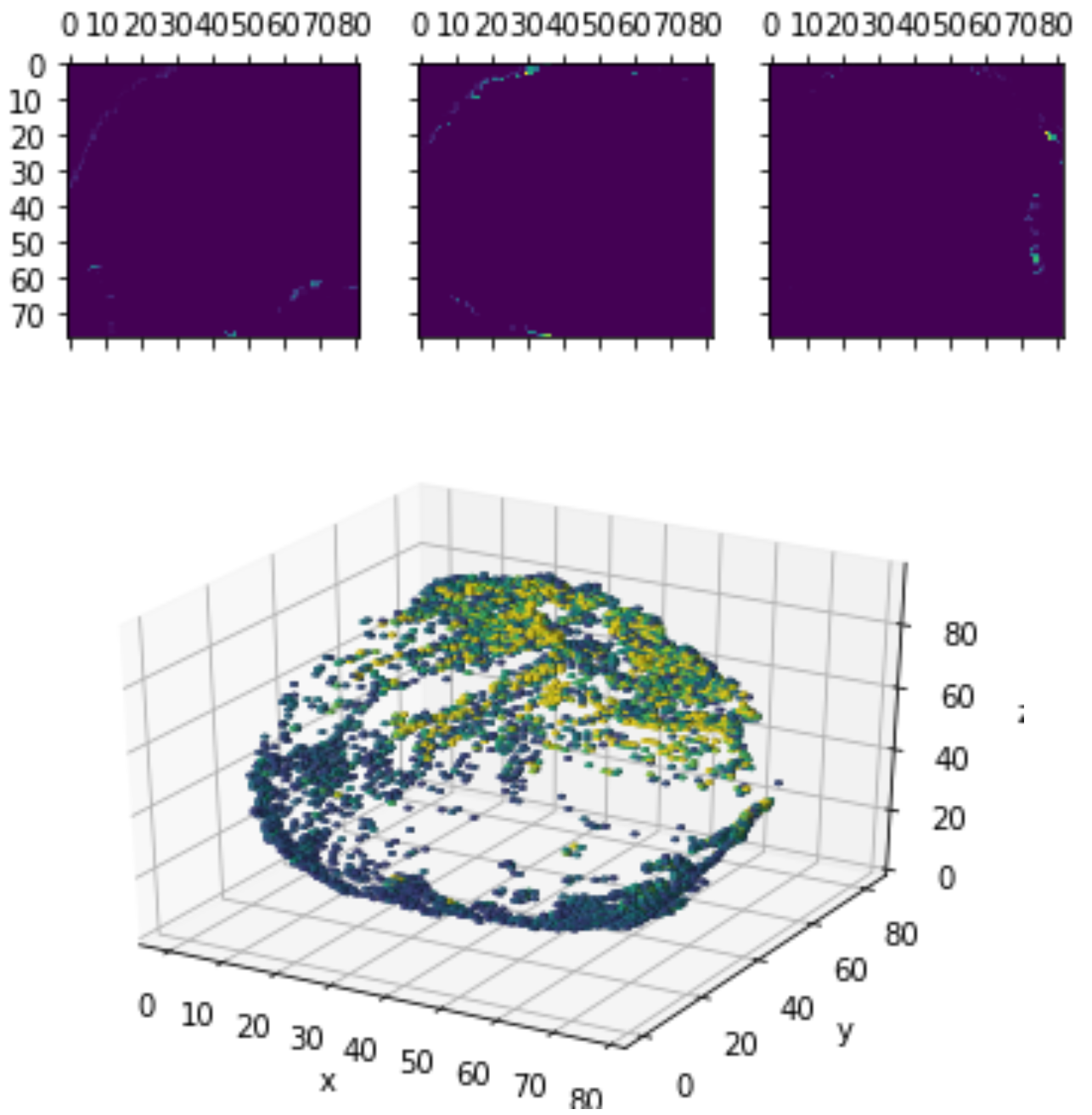
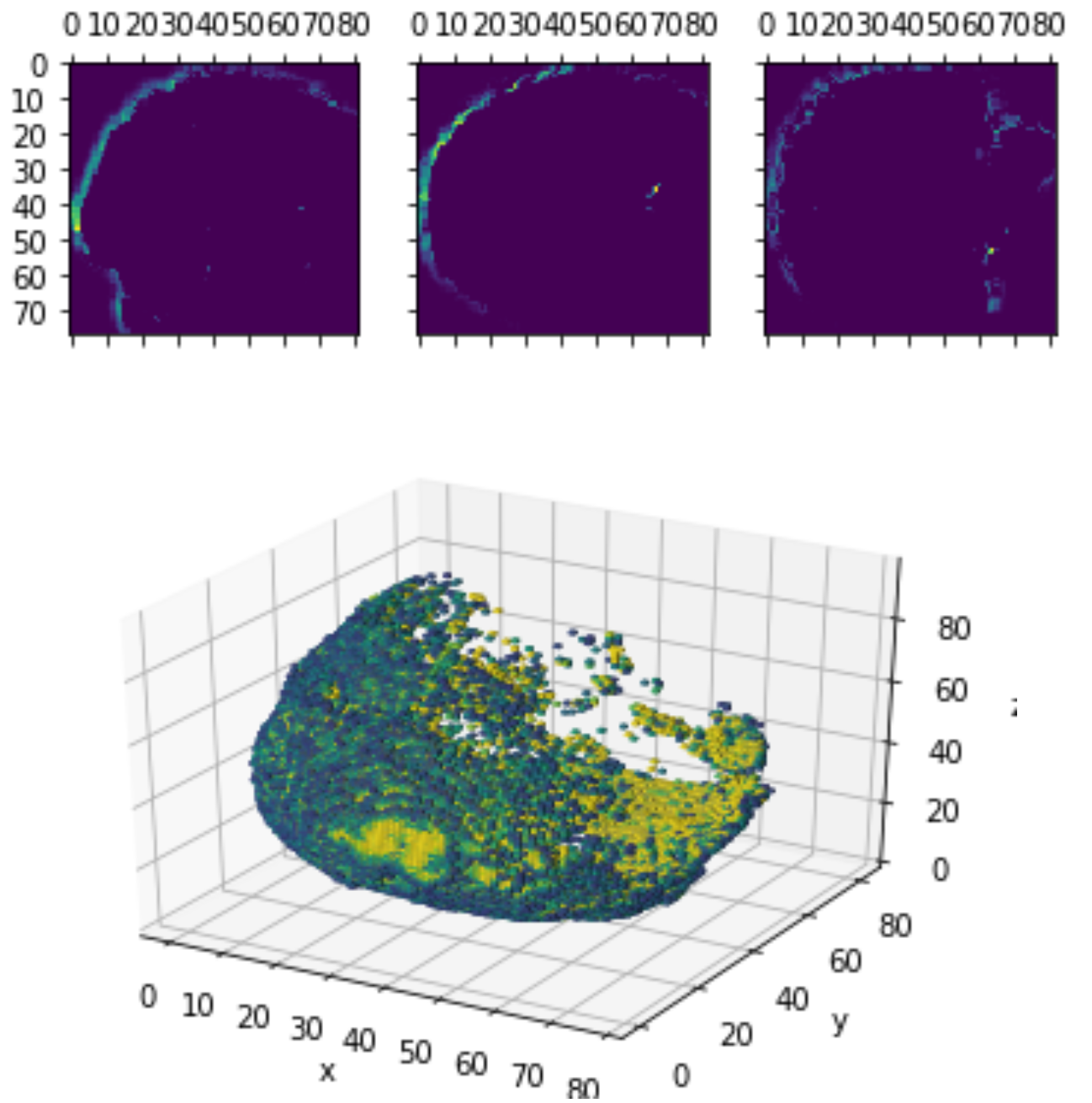
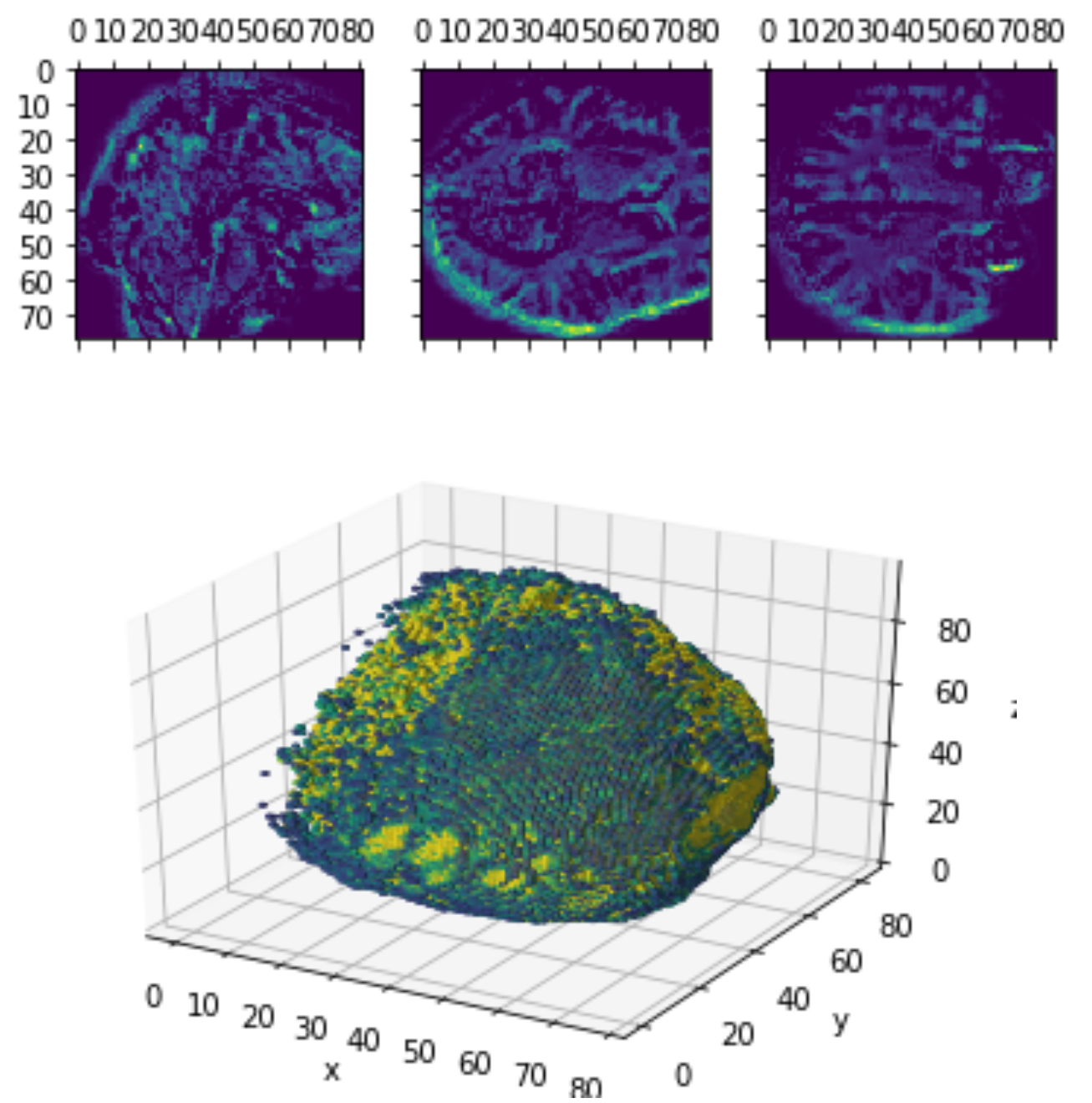
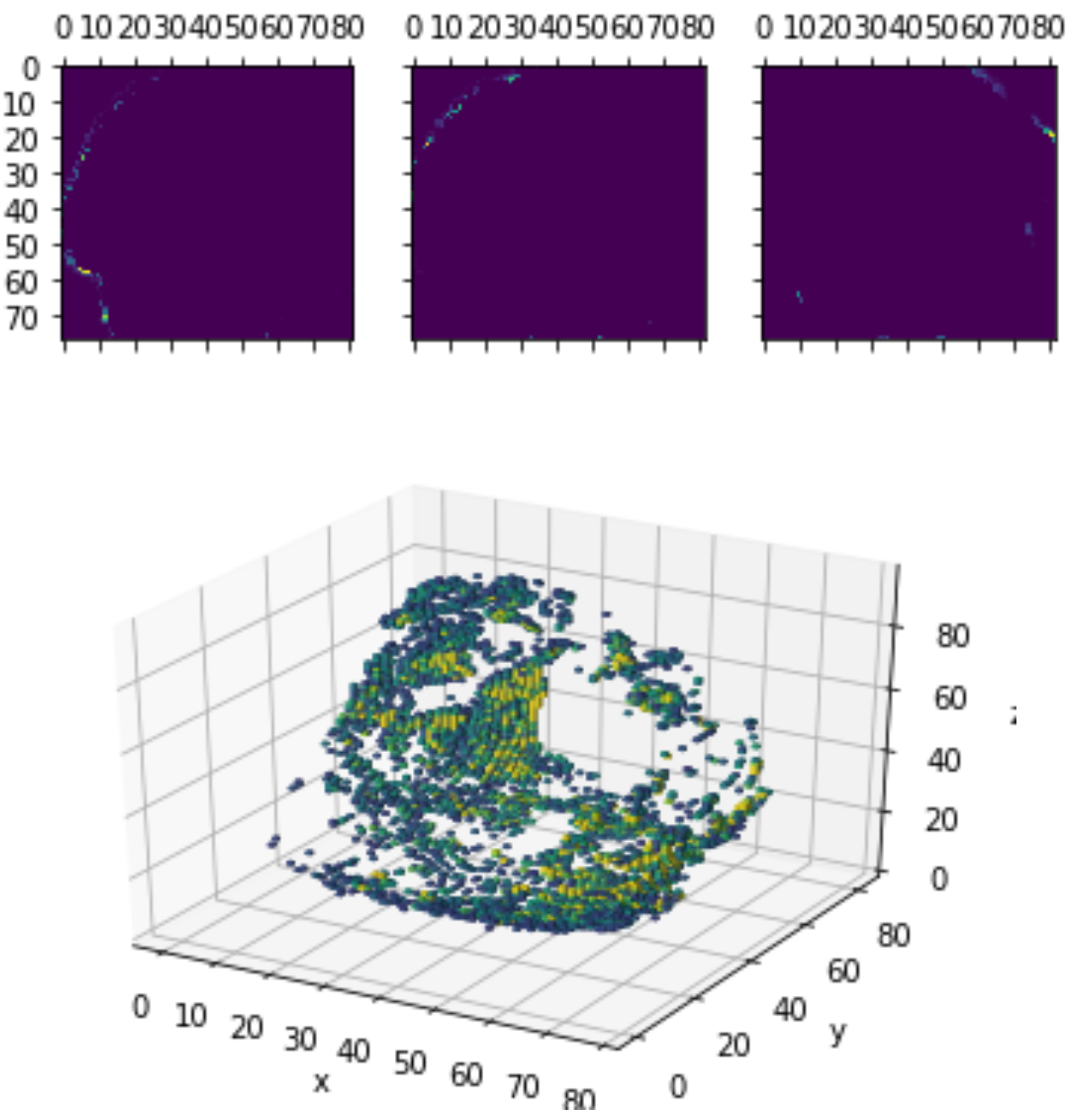



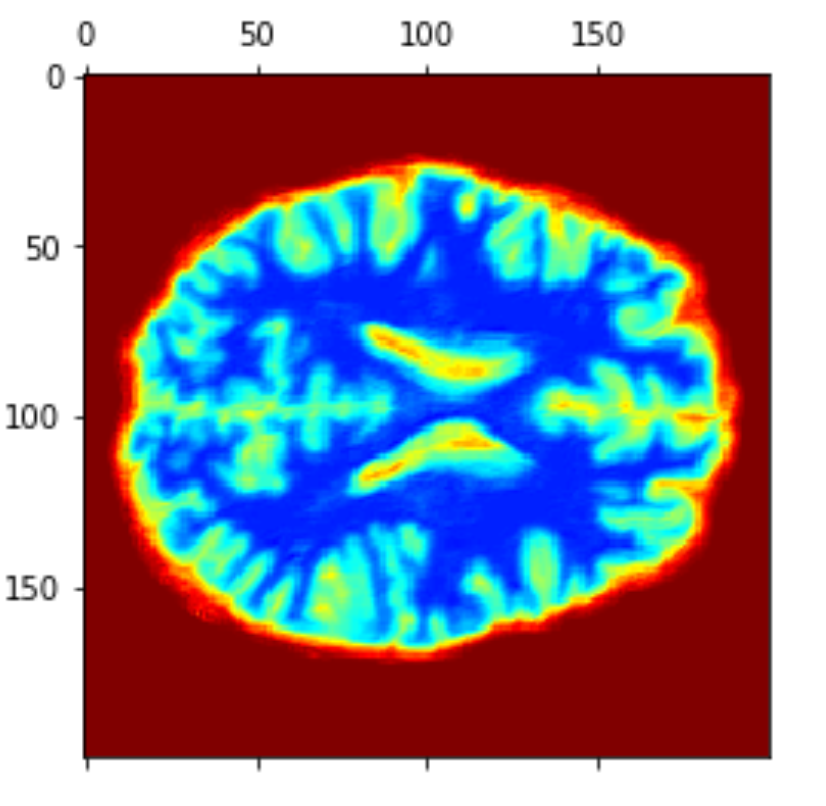
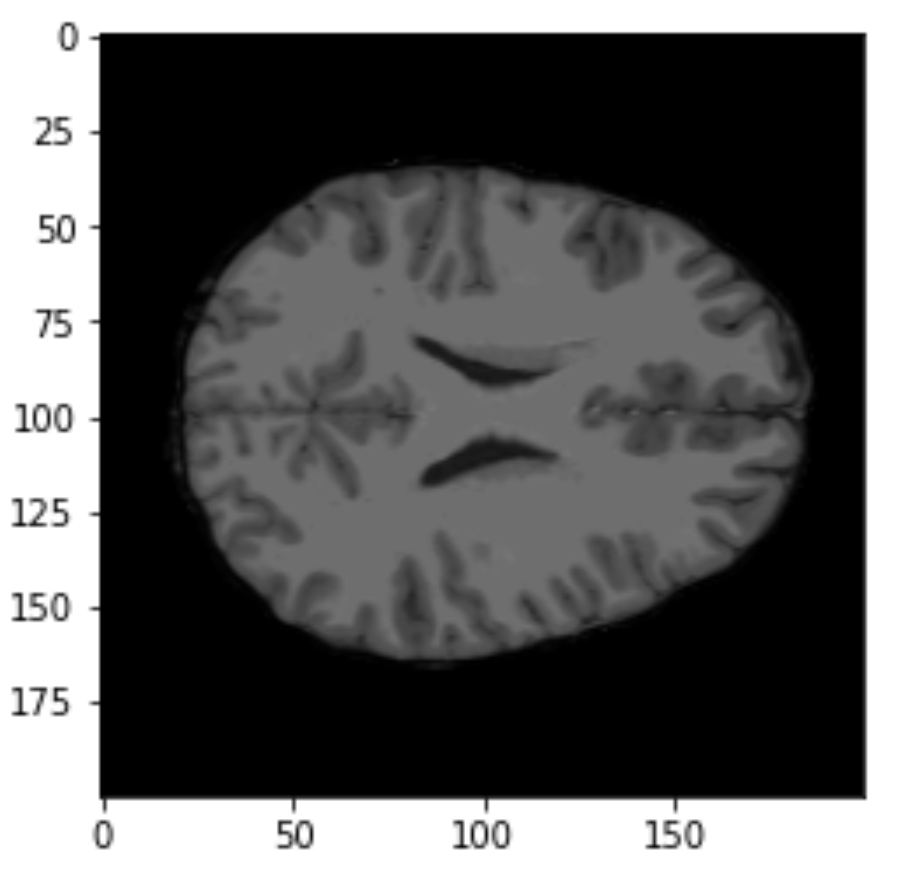
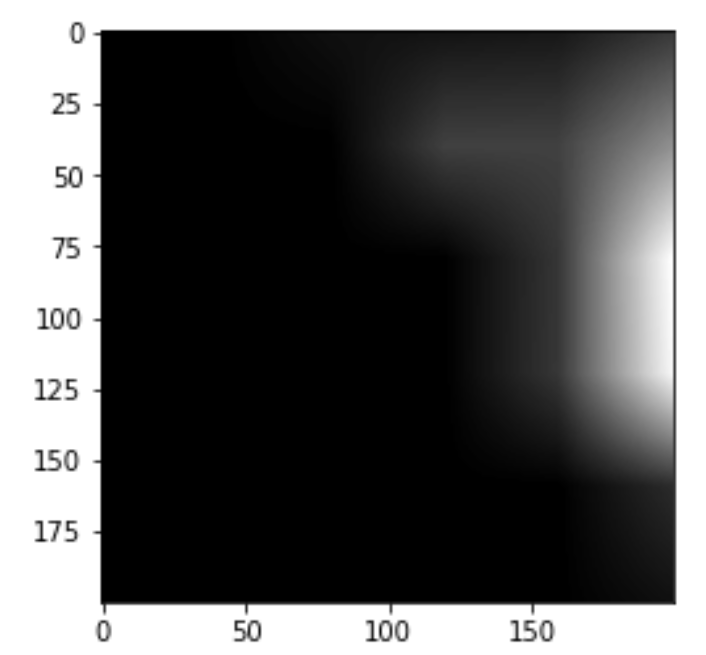
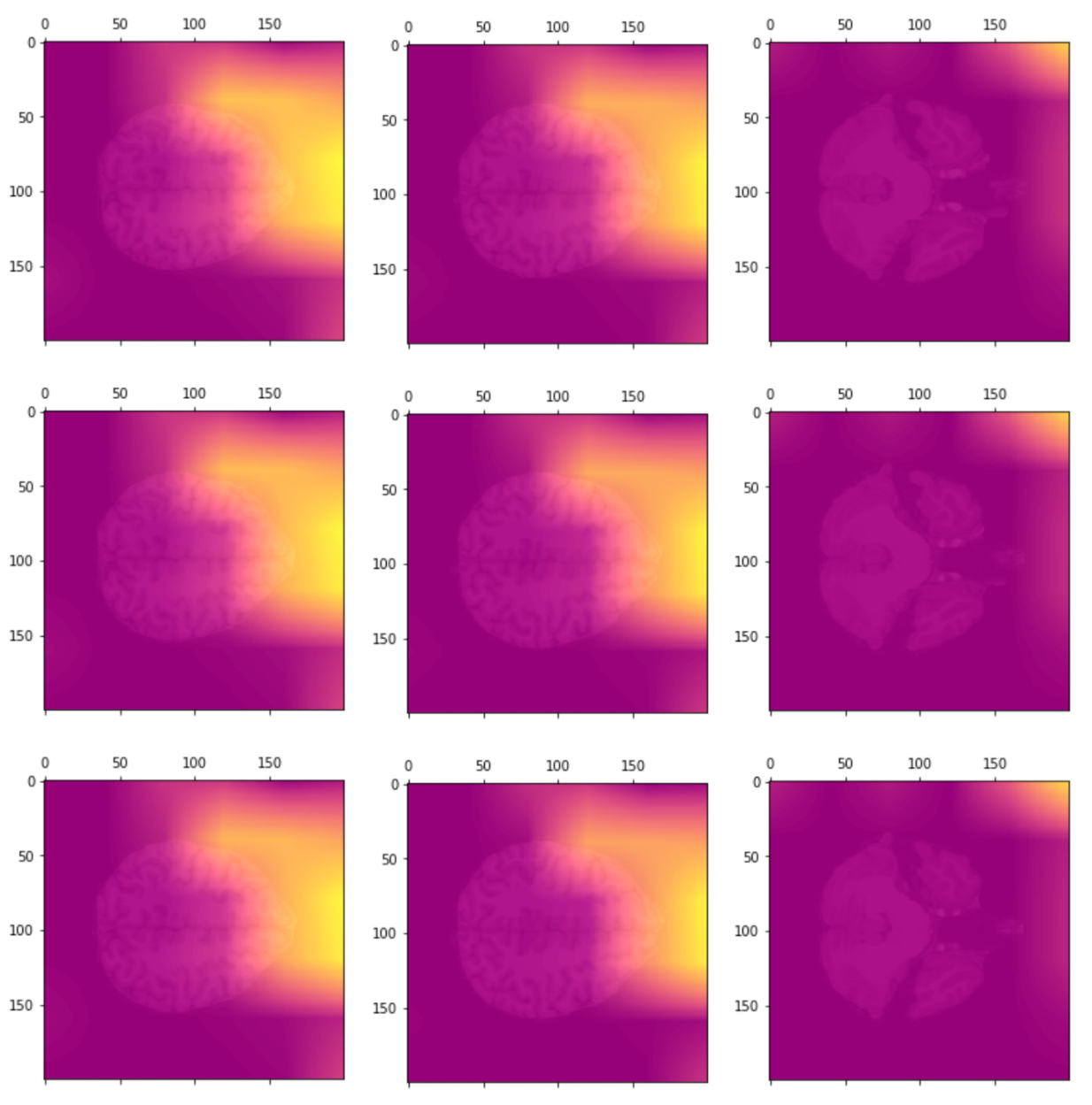
0.4 *
=
Heatmap CAM (last layers)
Class Activation Mapping
(CAM of top layers)
Conclussions
- PCA and dimentionality reduction.
- 3DCNN
PCA and dimentionality reduction.
- It is possible to reduce the dimension using simple operations like: cropping and resizing , however, this also means we lose information.
- Aspect ratio in not conserved during resize step (warping).
- PCA help us reduce the amount of features by finding a subspace in which classes can be seperated normally using the principal components as new axes for our data.
- PCA can be used for different purposes depending the application.
- The computation of PCA is fairly expensive and can be speeded up by using SVD algorithm.
- Vizualization of volumes is expensive...(GPU based solutions).
- Feature selection should be applied ONLY to the train data BEFORE cross validation step.
- Nested cross validation is needed in order to eliminate the bias coming from parameter search (learning only for a piece of data).
- PCA should be applied with care due to introdution of bias if done wrong (leak of knowledge).
- Nestes cross validation is computational expensive due to inner and outer loops (parameter search + cross val).
- Work with cropped 3D volumes produce less overhead.
3DCNNs
- There are restrictions on memory when building "big" models and dealing with high dimentional data.
- The amount of memory given by some hardware guides decisions over hyper-parameters like the batch number and the learning rate.
- Custom data generators that format/feed the data to the networks properly must be imple-mented. E.g 3D matrices to 5D tensors.
- Tere is no need of high definition images if the problem does not require to look at that level of detail.
- Taking into account demographics or medical descriptions could improve the accuracy of the model.
- The curse of dimensionality, fading gradients and long training times are by-producs of working with big networks and high-dimentional datasets.
- Using smaller kernel sizes, skipping max-pooling layers and using larger strides can reduce computing times at the cost of skiping granuar detail.
- The kernel size can affect the size and information on the heatmaps, using gradients and feature maps from interesting layers could be explored further if looking for ROIs is the main priority of the model.
Bleeding edge
Future...
- Explore effective ways of drawing Nuclear Medicine Images and other types of volumes on screen using 3D software like Unity.
- Use distributed TensorFlow to spread the workload and train models on different devices.
Q&A
3DCNN & MRI
By gabriel munoz




