STL第一次作業
組員:
406262163 資工二乙 黃品翰
406262515 資工二乙 鍾秉桓
實作
技術 :
* 編譯使用 make , shell script
* 繪圖分析 gnuplot
本次實作了兩個header file:"rand.h", "calcTime.h"
流程
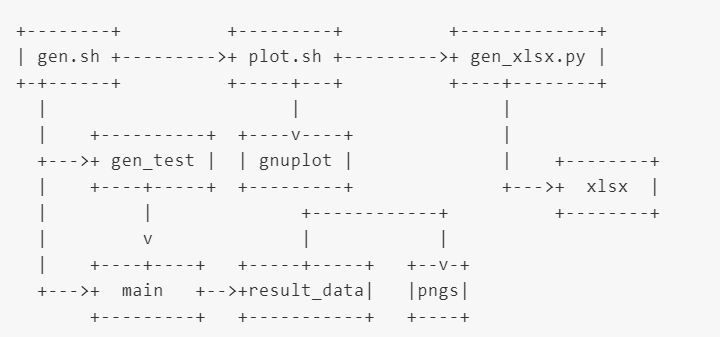
- gen.sh編譯並執行
- gen_test產生測資
- 導到main中產生結果資料
- plot.sh使用結果資料使用`gnuplot`依據*.gp畫出結果圖
- gen_xlsx.py產生excel
圖形分析
以下資料都會分成
固定長度(len)(N)
固定比數(line)(M)
Alternative(len)

字串的長度(len)要行數(line)夠大才有影響力
Alternative(line)
字串的行數(line)是影響時間的主要因素

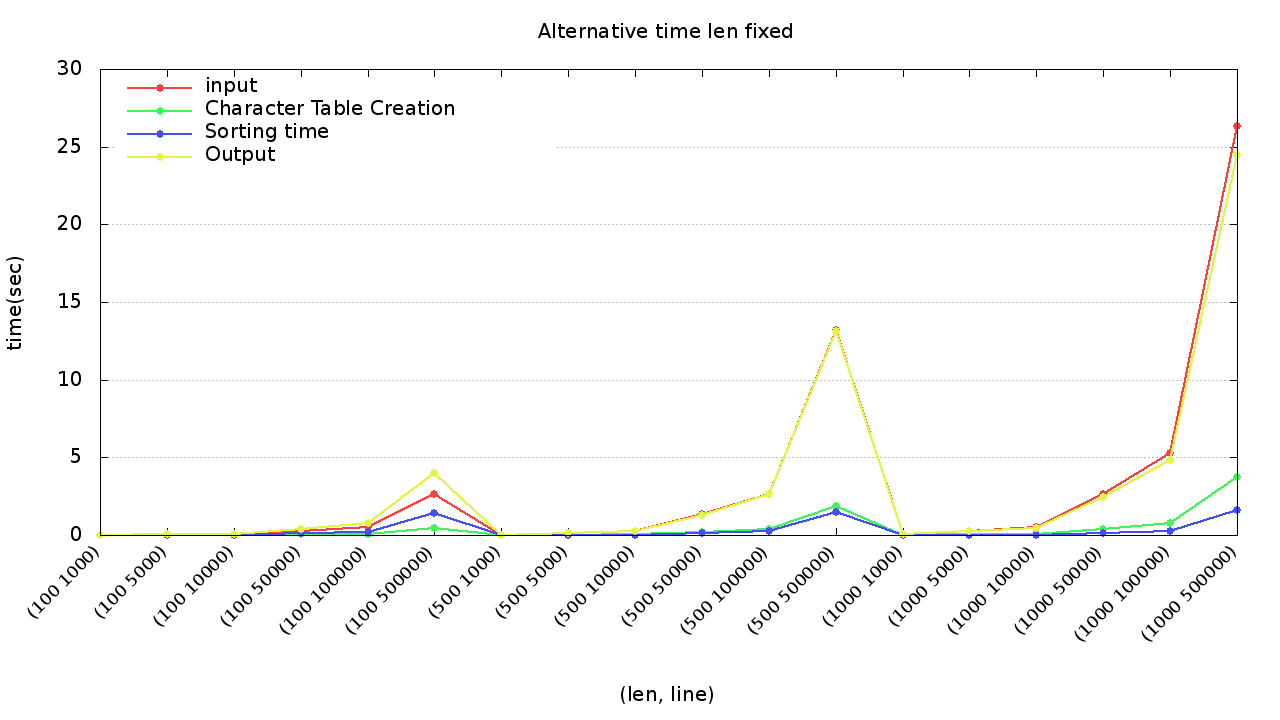
Alternative
- 整體來說,在輸入(Input)及輸出(Output)的部分佔整體的比例較大可以發現很明顯的趨勢: 隨著行數的增加,整體的時間皆會成長
- 可以發現輸入(紅色)、輸出(黃色)在(100, 100000)相較於(100, 500000)成長了5倍,相同的情況也可在(500, 100000), (500, 500000)以及(1000, 100000), (1000, 500000)觀察到。
Iterator(len)
在行數(line)很大時字串長度(len)增長500,時間增加約6~7秒

Iterator(line)
行數(line)至100000以上,才有比較明顯的成長

Iterator
- input隨著行數(line)在整體來說是比其他兩個部分還要高許多,而sorting的部分行數(line)、長度(len)多或是少,似乎沒有明顯的起伏,output的部分起伏稍微多一些。
- 這邊觀察到(100,500000), (500,500000), (1000,500000),這三個部分來說,雖然字串長度差距只有約1000。input卻明顯多了差距到10秒,但output可能只有3秒不到,而sorting完全沒什麼動靜

在行數(line)很大時字串長度(len)增長500,時間增加約6~7秒
Simple(len)

行數(line)至100000以上,才有比較明顯的成長
Simple(line)
Simple
- 基本上與iterator是差不多的,因為在實作上面也是類似的,輸入只是一個差在只記頭尾的iterator,一個是使用getline,輸出都是用copy到output_stream的方式,因此圖形幾乎與iterator相同
三種方法分析

Input分析
- 時間複雜度三者為O(MN)
- Alternative是使用getchar()的方式,一個一個字元做讀取,過程中不斷地將字元push_back至vector裡面,會不斷一直改變vector大小,花費的時間才會相較其他兩個方式高
- Iterator、Simple是getline抓取字串,將字串存入vector中,因此,時間花得比較少

Sorting分析
-
std::sort()的時間複雜度為O(nlogn),是使用quick-sort實作
-
三者時間複雜度皆為O(nlogn),最差為O(m*nlogn)
-
很明顯sorting時間都沒有超過兩秒,時間算是蠻快的,而alternative時作為字元陣列,simple與iterator是用string-vector實作,圖形上來看幾乎是重疊的


Output分析
-
輸出時間明顯可看出alternative花的時間較Iterator、Simple多。因為iterator、simple輸出的使用string-vector做輸出,而alternative是用char-vector,但alternative要花較多的時間才能輸出完成


Total分析
- 整體時間Alternative時間最久,從輸入輸出來看,很明顯是因為字元的vector速度拖慢了效率,iterator與simple使用getline實作,時間就快了許多
- 從(100,500000)來看,alternative的時間約是simple與iterator的兩倍左右,而在(1000,500000),alternative的時間是iterator跟simple的三倍左右


歡迎詳閱


stl01-hw
By halloworld
stl01-hw
泛型作業



