Intrinsically Motivated Collective Motion



Henry Charlesworth (H.Charlesworth@warwick.ac.uk)
Supervisor: Professor Matthew Turner
Warwick Biological, Soft and Active Matter Group Meeting, 13/11/2017
Collective Motion
- Coordinated motion of many individuals all moving according to the same rules.
- Occurs all over the place in nature at many different scales - flocks of birds, schools of fish, bacterial colonies, herds of sheep etc.




Why Should we be Interested?
- Because we are scientists! Understanding things is interesting!
Applications
- Building autonomous robots/drones
- Animal conservation
- Crowd Management
- Swarm Computing
- Computer Generated Images

(https://erc.europa.eu/projects-figures/stories/flocking-drones-swarming-pigeons)
Existing Collective Motion Models
- Tend to be local in space (i.e. interactions between nearest neighbours only).
- Also local in time (i.e. how they choose to update their behaviour only depends on the current state of the collective system).

Example: Vicsek Model
T. Vicsek et al., Phys. Rev. Lett. 75, 1226 (1995).
R
\mathbf{v}_i(t+1) = \langle \mathbf{v}_k(t) \rangle_{|\mathbf{r}_k-\mathbf{r}_i| < R} + \eta(t)
\mathbf{r}_i(t+1) = \mathbf{r}_i(t) + \mathbf{v}_i(t)
Intrinsic Motivation
- A concept that stems from the psychology literature. Distinguishes between behaviour that is motivated by a clearly defined external reward (extrinsic motivation) and doing something because it is inherently useful or interesting.
- Simple examples: exploration, play and other curiosity driven behaviour.
- Developing skills that are applicable to a wide range of possible scenarios rather than being useful in trying to solve just a specific problem.
Intrinsic Motivation
- White (1959) argued that intrinsically motivated behaviour is essential for an agent to gain the competence necessary to achieve mastery over its environment.
- The idea of maximizing the control that you have over your future environment seems like it could be a useful principle to follow in many situations.
- A couple of attempts have been made to formalize this idea:
- Empowerment: A universal agent-centric measure of control, Kluybin, et al., The 2005 IEEE Congress on Evolutionary Computation (2005)
- Causal Entropic Forces, Wissner-Gross and Freer, Physical Review Letters (2013)
- Informally: with all else being equal, it makes sense to keep your options open as much as possible.
Empowerment
- Attempt to formalize this idea of maximizing control over one's future in the language of information theory.
- Formally, it is defined as the "channel capacity" between an agent's set of possible action sequences and its possible sensor states at some later time.
- Really what this means is that it is a measurement of how much information an agent could potentially inject into its environment and then itself be able to detect at a later point, i.e. how much influence it has over what its sensors can potentially read in the future.
Empowerment
- Recent application by the Google DeepMind team to the field of reinforcement learning:
"Variational Information Maximisation for Intrinsically Motivated Reinforcement Learning", Proceedings of the 29th Conference on Neural Information Processing Systems (NIPS 2015)
- Importantly for our model, in a deterministic environment with a discrete set of possible actions and possible sensor states, the empowerment is simply given by the number of unique sensor states that can be accessed at some time into the future.
- Difficult quantity to calculate because it involves considering everything an agent could possibly do rather than just what it will do.
Can any of these ideas be applied to collective motion?
Model
- Simple application of the empowerment framework to a group of agents equipped with simple visual sensors.

Possible Actions:
Visual State
Model
- Idea is that each agent moves so as to maximize the number of unique visual states that are accessible to it over a fixed number (𝝉) of timesteps into the future.
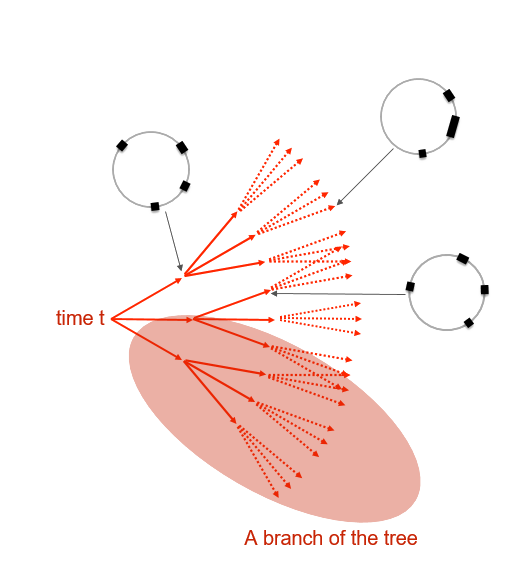
- Each makes the assumption that the others will continue to move in a straight line at for the next 𝝉 steps.
v_0
Model
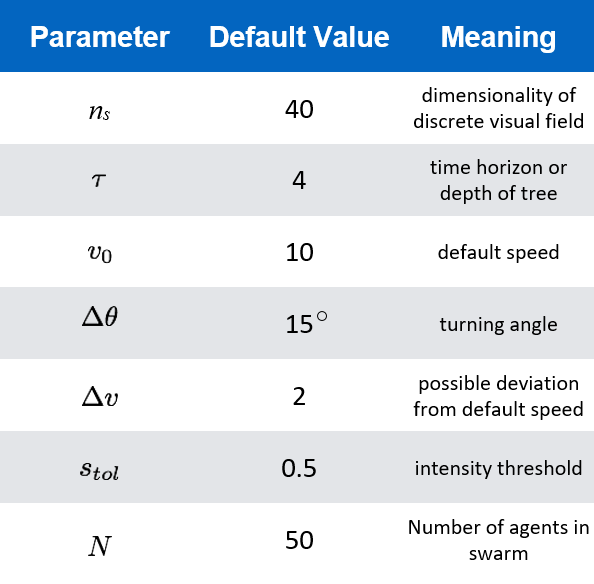
Model Parameters
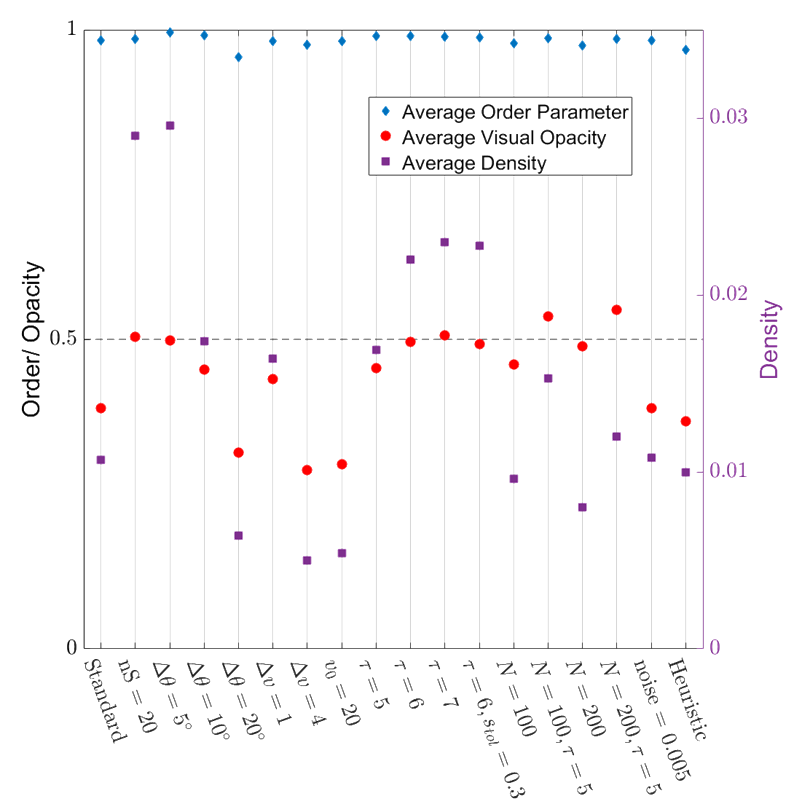
Simulation Result
This looks good!
- Very highly ordered collective motion. (Average order parameter ~ 0.98)
- Density is well regulated, flock is marginally opaque.
- These properties are robust over variations in the model parameters!
\phi = \frac{1}{N} |\sum_i \mathbf{\hat{v}}_i |
Order Parameter:
Even Better - Scale Free Correlations!
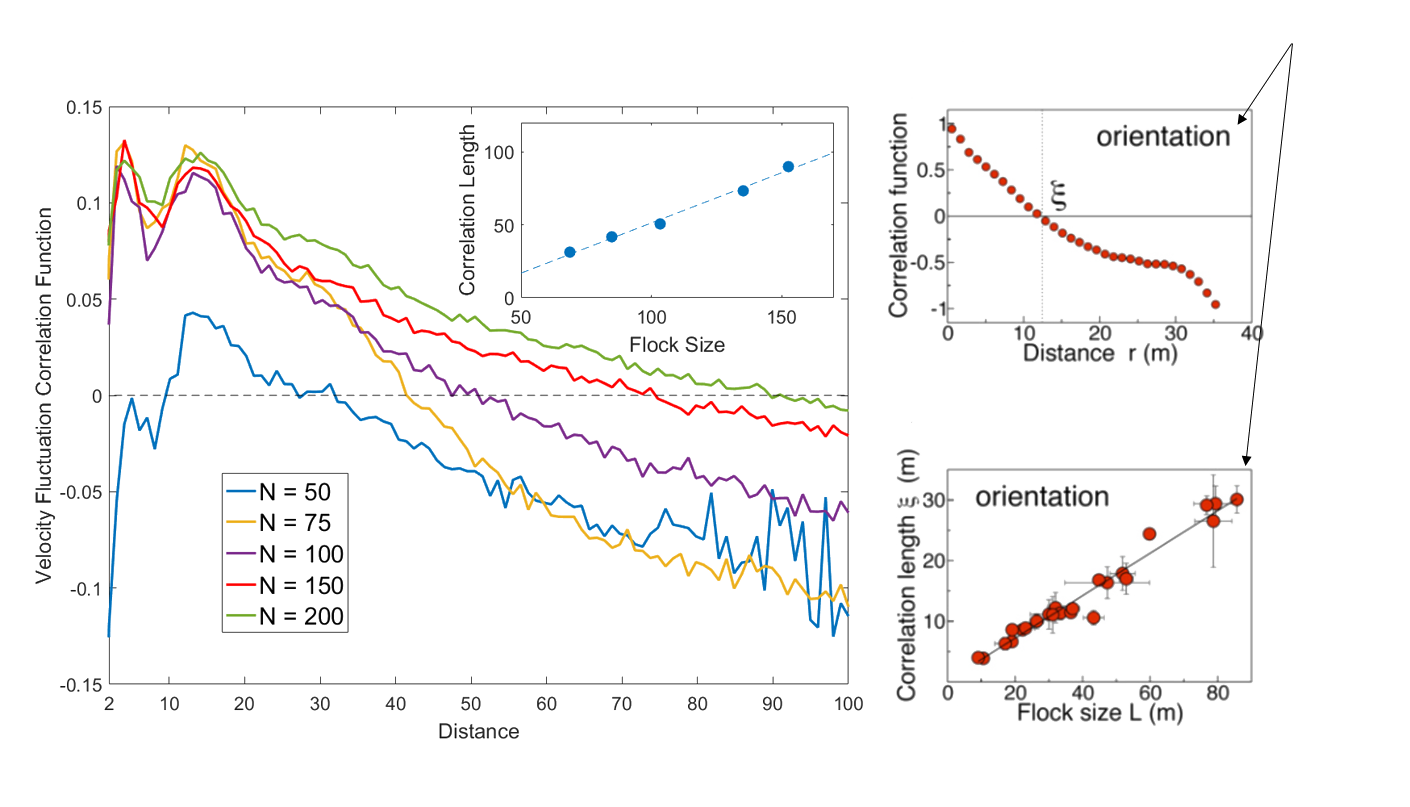
Real starling data (Cavagna et al. 2010)
Data from model
- Scale free correlations mean an enhanced global response to environmental perturbations!
\mathbf{u_i} = \mathbf{v_i} - \langle \mathbf{v} \rangle
correlation function:
C(r) = \langle \mathbf{u}_i(0) . \mathbf{u}_j(|r|) \rangle
velocity fluctuation
Problems
- Assumption that other agents move ballistically is clearly not quite right (although the order is very high).
- Algorithm is slow to run. Cannot extend to run for large flock sizes or large values of 𝝉.
- This is completely unrealistic - obviously real birds are not making these kinds of calculations!!

Can this behaviour be mimicked with a simple heuristic?
Training a Neural Network to Mimic the Full Algorithm
- Idea: Run the full empowerment maximizing algorithm and record data about the decisions made at each step along with the current visual state (and the previous timesteps visual state)
- Use this data to train a neural network classifier to learn which move the full algorithm would make in any given situation.
Visualizing the Neural Network
previous visual sensor input
current visual sensor input
hidden layer of neurons
output: predicted probability of action
How does it do?
Using different models for the other "birds"
APPROACH 1
- Assume the rest of the flock moves with a fixed order parameter.
APPROACH 2
- Assume they move according to the heuristic we learned from training on the original data.
APPROACH 1
- Model future trajectories of other agents as moving so that collectively the order parameter is approximately fixed at .
\phi_t
- Do this by randomly iterating through the flock and choosing which move brings the total order parameter closest to the target.
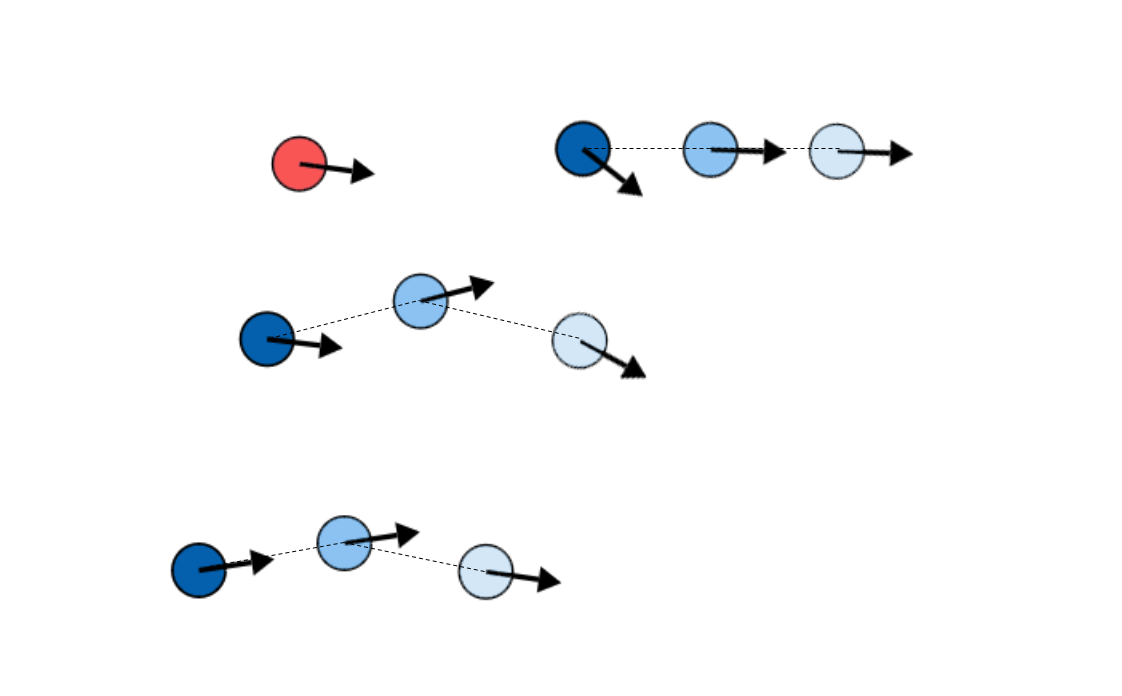
Iterating this procedure
- Run this algorithm with this assumption for the other agents with a particular value of . The resultant flock will have an average order parameter .
\phi_t
\phi_f
- Plug this new value back in as the new value of . Iterate this procedure.
\phi_t
Start with an input
\phi_t
This produces a flock
with average order
\phi_f
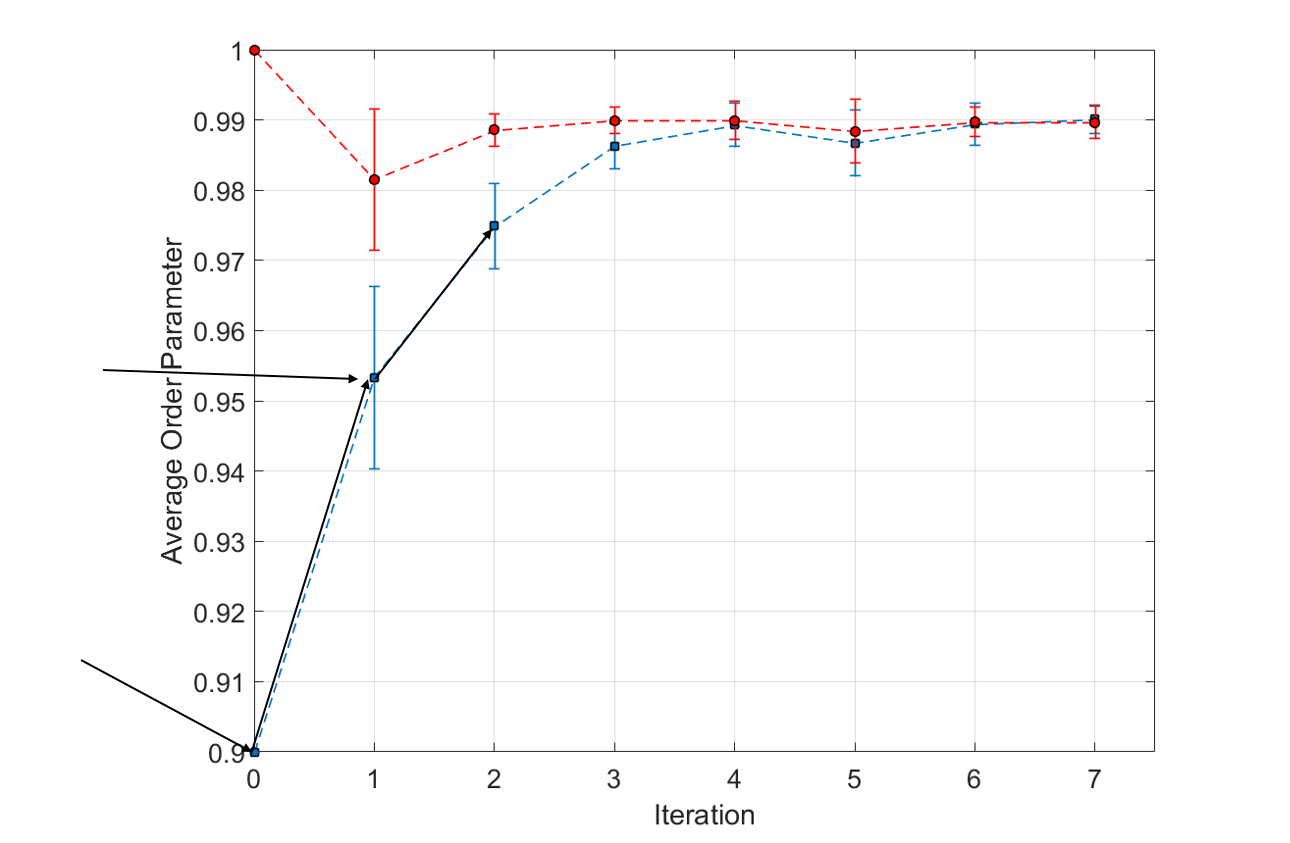
Simulations
Assuming other agents are moving with target order parameter 0.9:
Simulations
Assuming other agents are moving with target order parameter 0.953:
APPROACH 2
- Idea is to use the neural network that we learned to model the future trajectories of the other agents needed for the empowerment maximizing algorithm.
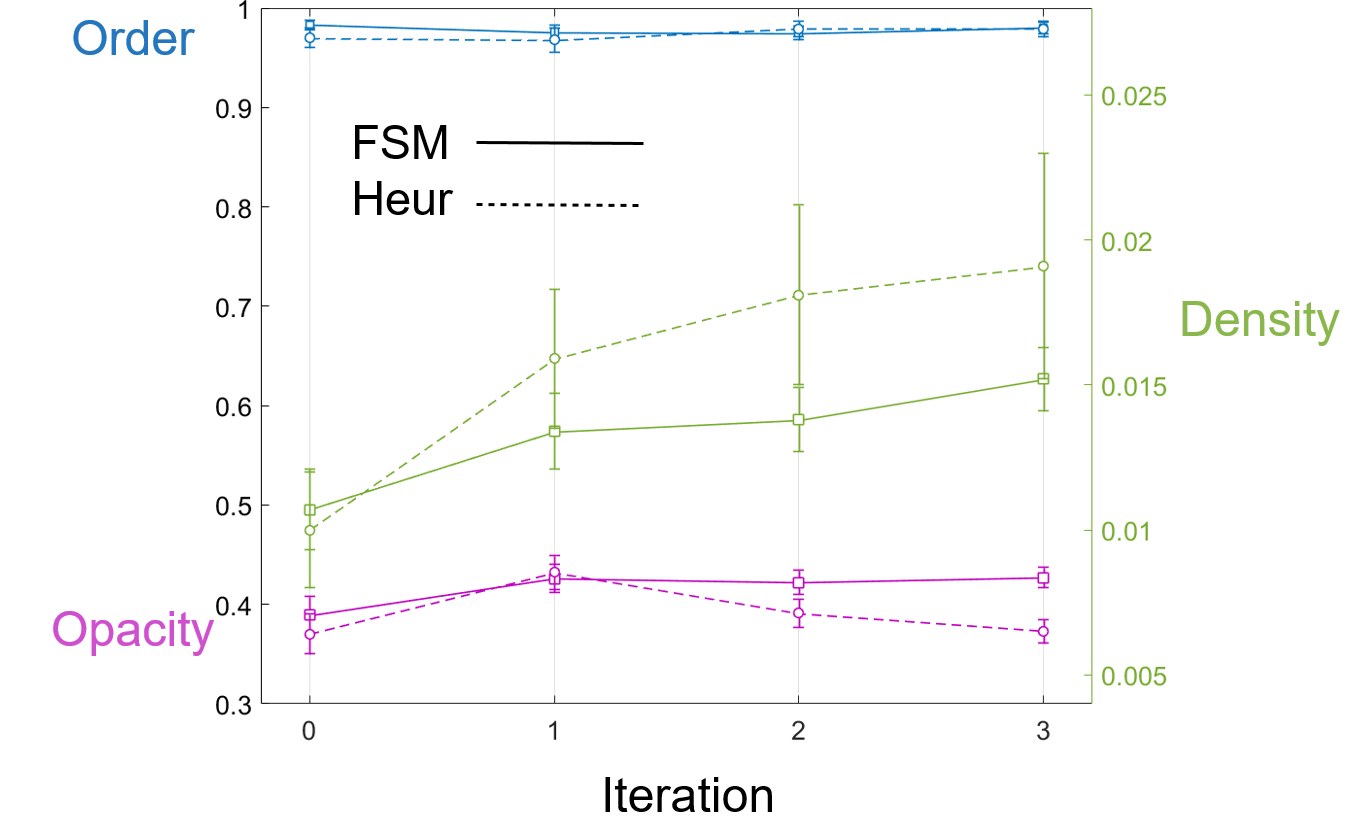
- The data from the result of running this new algorithm can then be used in exactly the same way to train a new neural network to act as a heuristic. This can again be iterated to look for convergence to some kind of self-consistency.
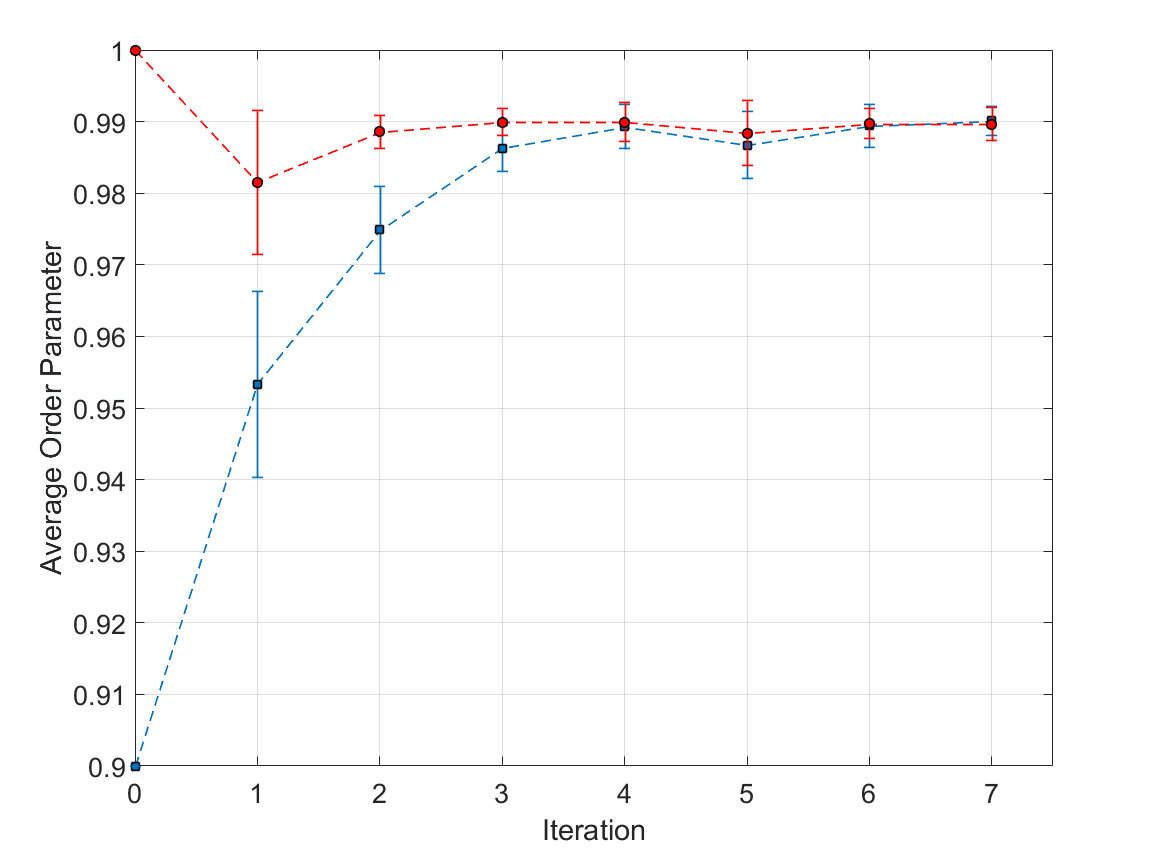
Simulations
Empowerment Algorithm with other agent's future trajectories calculated with the first neural network heuristic
Next heuristic learned from this data
Convergence
Controlling the flock (briefly)
Summary
- Relatively simple implementation of an algorithm which aims to maximize the control that the agents have over their futures produces realistic swarms with features associated with real flocks of birds.
- The algorithm is remarkably robust over variations in model parameters and different ways of modelling the future trajectories of others.
- This behaviour can be mimicked using a simple heuristic which only uses visual information which is currently available to each agent.
- Possible to make some progress with making this type of model closed and self-consistent.
Intrinsically Motivated Collective Motion
By Henry Charlesworth




