Intrinsically Motivated Collective Motion



Henry Charlesworth (H.Charlesworth@warwick.ac.uk)
WMG, 21 December, 2018
Dilemma: What to talk about?

- Large personal project: applying self-play deep RL to a four-player card game called Big 2.
- Results very positive.
- Paper accepted at AAAI-19 Workshop on Reinforcement Learning in Games.
- Not much in terms of "serious research" - more of an interesting application and a fun way to learn more about RL.
PhD research

"Future state maximisation as an intrinsic motivation for decision making"
- Not directly a machine learning project
- Primary application was to a model of collective motion - sent out to review at Nature.
- Overall a very successful project.
- Definite potential to apply some of these ideas to reinforcement learning.
Thesis title:
Collective Motion
- Coordinated motion of many individuals all moving according to the same rules.
- Occurs all over the place in nature at many different scales - flocks of birds, schools of fish, bacterial colonies, herds of sheep etc.




Why Should we be Interested?
Applications
- Animal conservation
- Crowd Management
- Computer Generated Images
- Building decentralised systems made up of many individually simple, interacting components - swarm robotics.
- We are scientists - it's a fundamentally interesting phenomenon to understand!
Existing Collective Motion Models
- Often only include local interactions - do not account for long-ranged interactions, like vision.
- Tend to lack low-level explanatory power - the models are essentially empirical in that they have things like co-alignment and cohesion hard-wired into them.

Example: Vicsek Model
T. Vicsek et al., Phys. Rev. Lett. 75, 1226 (1995).
R
\mathbf{v}_i(t+1) = \langle \mathbf{v}_k(t) \rangle_{|\mathbf{r}_k-\mathbf{r}_i| < R} + \eta(t)
\mathbf{r}_i(t+1) = \mathbf{r}_i(t) + \mathbf{v}_i(t)
Our approach
- A model based on a simple, low-level motivational principle - "future state maximisation".
- No built in alignment/cohesive interactions - these things emerge spontaneously.
Future state maximisation
- Loosely speaking - taking everything else to be equal, it is preferable to keep one's options open as much as possible.
- Alternatively: generally speaking it is desirable to maintain as much control over your future environment as is possible.
- "Empowerment" framework - one attempt to formalise this idea in the language of information theory.
"Variational Information Maximisation for Intrinsically Motivated Reinforcement Learning",
Proceedings of the 29th Conference on Neural Information Processing Systems (NIPS 2015)
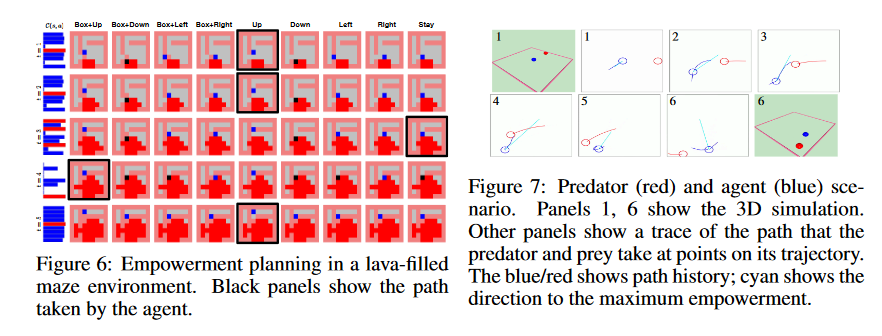
- Recently DeepMind used this as an intrinsic motivation for solving some simple RL problems:
How can this principle be useful in understanding collective motion?
Our Model
- Consider a group of circular agents equipped with simple visual sensors, moving around on an infinite 2D plane.

Possible Actions:
Visual State
Making a decision
Simulation Result - Small flock
This looks good!
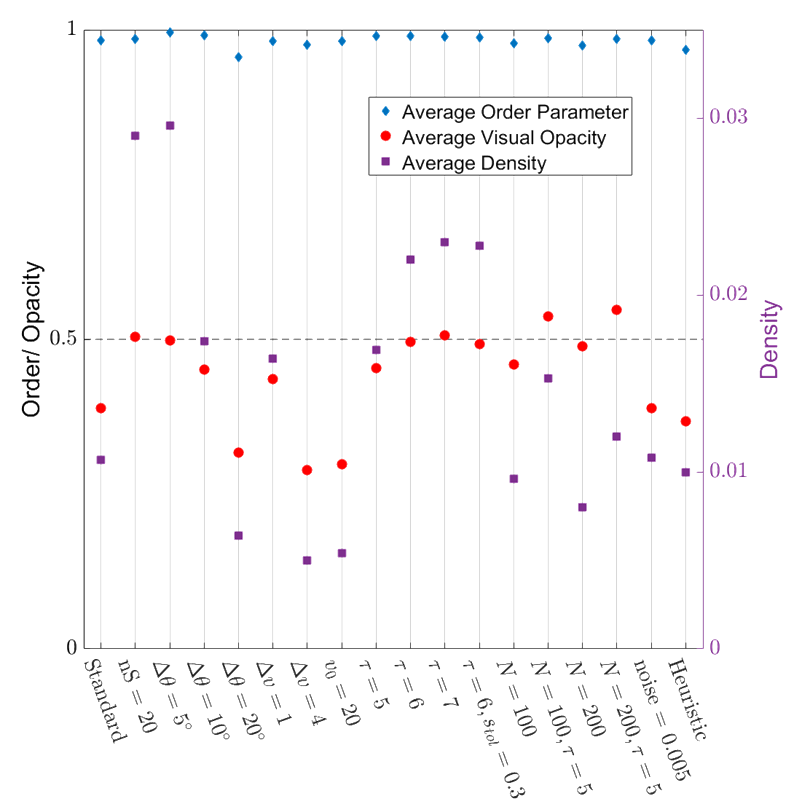
- Very highly ordered collective motion. (Average order parameter ~ 0.98)
- Density is well regulated, flock is marginally opaque.
- These properties are robust over variations in the model parameters!
\phi = \frac{1}{N} |\sum_i \mathbf{\hat{v}}_i |
Order Parameter:
Even Better - Scale Free Correlations!
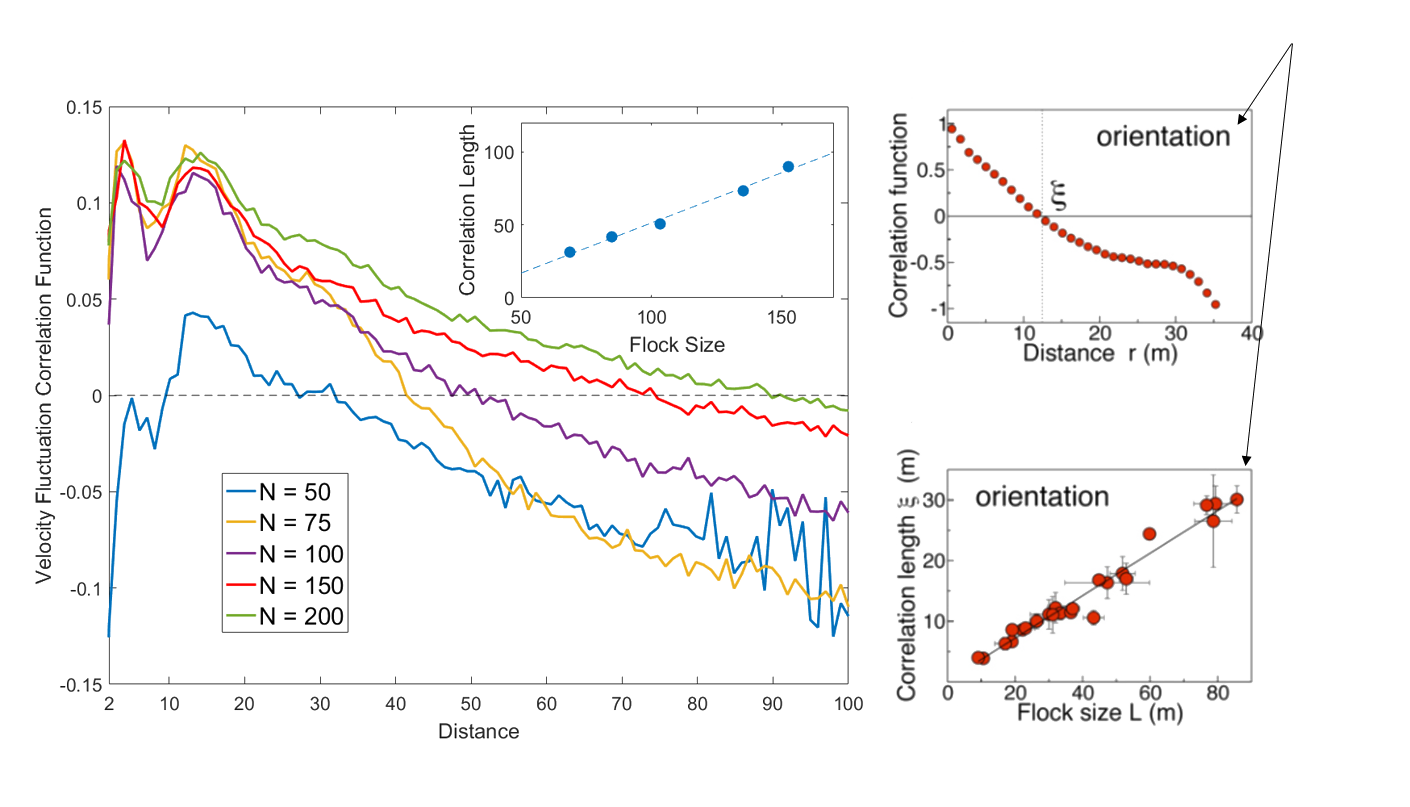
Real starling data (Cavagna et al. 2010)
Data from model
- Scale free correlations mean an enhanced global response to environmental perturbations!
\mathbf{u_i} = \mathbf{v_i} - \langle \mathbf{v} \rangle
correlation function:
C(r) = \langle \mathbf{u}_i(0) . \mathbf{u}_j(|r|) \rangle
velocity fluctuation
Larger flock - remarkably rich emergent dynamics
Quickly: some machine learning
- This algorithm is very computationally expensive. Can we generate a heuristic that acts to mimic this behaviour?
- Train a neural network on trajectories generated by the FSM algorithm to learn which actions it takes, given only the currently available visual information (i.e. no modelling of future trajectories).
Visualizing the Neural Network
previous visual sensor input
current visual sensor input
hidden layers of neurons
output: predicted probability of action
How does it do?
Conclusions
- Proposed a minimal model of collective motion based purely on a low-level motivational principle.
- This principle is able to spontaneously produce a swarm which is highly-aligned, cohesive, robust to noise with remarkably rich emergent dynamics.
- Future state maximisation is an extremely general principle - many potential applications, and we have demonstrated an example of the kind of sophisticated behaviour it can induce.
IMCM Warwick Dec 2018
By Henry Charlesworth




