"Empowerment" as an Intrinsic Motivation to Explore Sparse Environments
- Empowerment is defined to be a measure of the amount of control an agent has over it its future environment.
- i.e. how much the agent's actions are able to influence the states it can potentially reach in the future
- Formally, empowerment is defined as the channel capacity between an agent's set of possible action sequences and the agent's environment state at a time in the future:
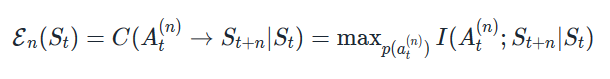
- Basically quantifies how much influence an agent's actions have over the possible future states that it is able to reach.
- Can also think of it as measuring how much information an agent can inject into its environment (through its actions), that it is able to itself detect at a later time.
How to calculate empowerment
- Not so easy - mutual information is a difficult quantity to calculate
- Have to choose a probability distribution over all possible sequences of actions to maximise this mutual information!
- Basically - very difficult to do this exactly for anything but the simplest toy systems, especially for large n.
Variational Bound on Mutual Information (Mohamed and Rezende, 2015 - also before I think)

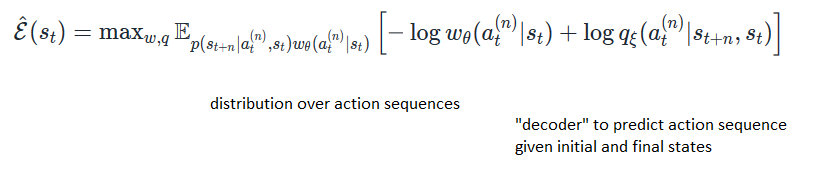
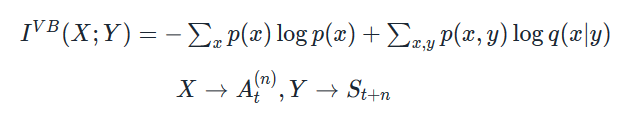
Can represent q (and w, the policy) by neural networks and maximise this! Mohamed and Rezende do this by alternating between maximising w.r.t q (maximum likelihood) and w (they derive an expression for the functional derivative of the above) - using SGD in both cases.
- Note: distribution w is not (necessarily) the policy you want to follow. It is just a policy which is needed for calculating the empowerment. A policy which moves to states that maximise empowerment is completely different.
- But w has some potentially useful properties - (roughly) it should uniformly explore all states that are accessible n steps into the future.
deck
By Henry Charlesworth




