slate.js
source code study
Process
- WYSIWYG 的粗略介紹
- slate.js 的粗略介紹
- CustomType
- Normalization
WYSIWYG
WYSIWYG :中文名『所見即所得』,為英文 “ What You See Is What You Get ” 取字頭的縮寫,是由『菲利普·威爾遜( Flip Wilson )』所提出的一種電腦文字編輯器方面的技術,也是一種 UI design pattern

Microsoft word
IT 邦幫忙
slate.js

Document Model
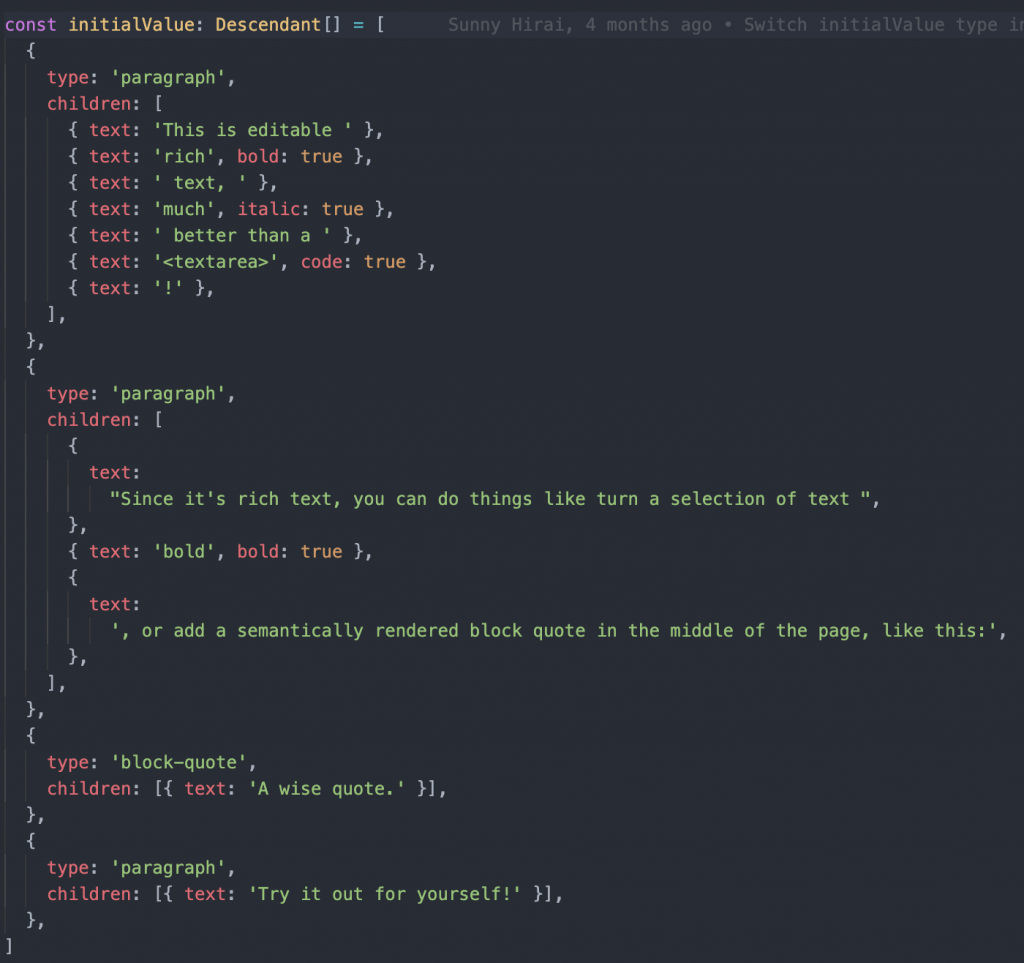
const Element = ({ attributes, children, element }) => {
switch (element.type) {
case 'block-quote':
return <blockquote {...attributes}>{children}</blockquote>
case 'bulleted-list':
return <ul {...attributes}>{children}</ul>
case 'heading-one':
return <h1 {...attributes}>{children}</h1>
case 'heading-two':
return <h2 {...attributes}>{children}</h2>
case 'list-item':
return <li {...attributes}>{children}</li>
case 'numbered-list':
return <ol {...attributes}>{children}</ol>
default:
return <p {...attributes}>{children}</p>
}
}const Leaf = ({ attributes, children, leaf }) => {
if (leaf.bold) {
children = <strong>{children}</strong>
}
if (leaf.code) {
children = <code>{children}</code>
}
if (leaf.italic) {
children = <em>{children}</em>
}
if (leaf.underline) {
children = <u>{children}</u>
}
return <span {...attributes}>{children}</span>
}Singleton Core
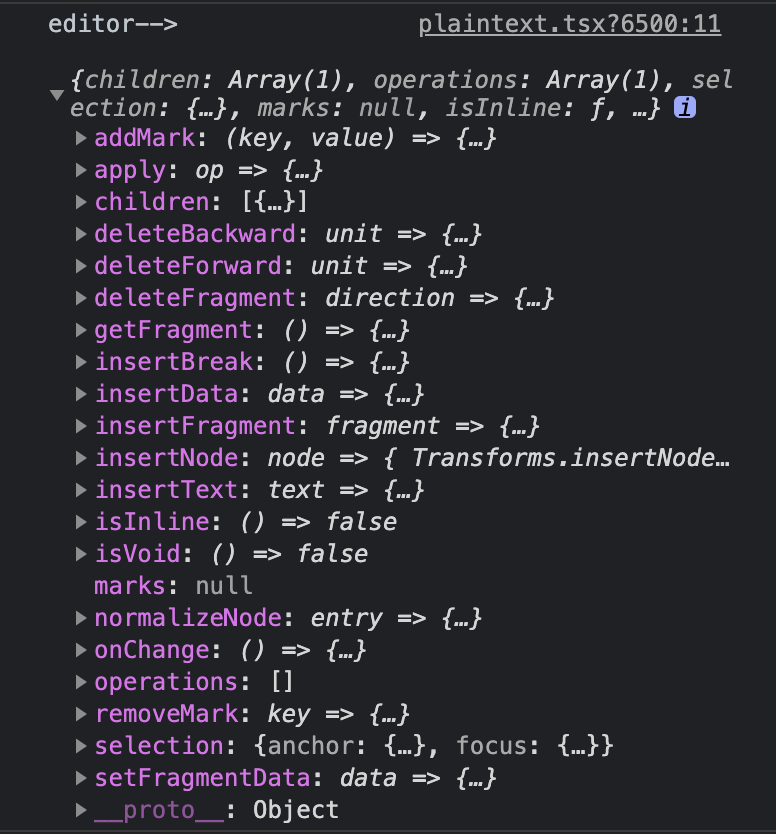
import { createEditor } from 'slate';
console.log('editor-->\n', createEditor());Parallel to DOM
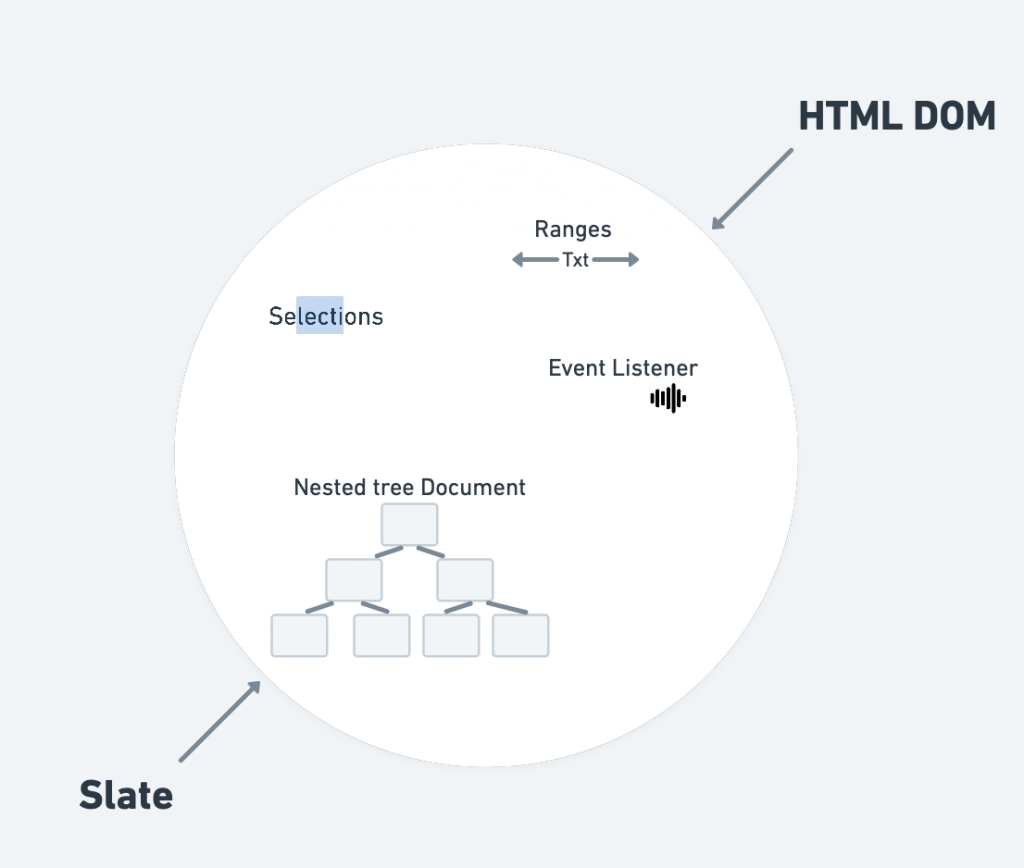
Data type Interface
Defined Interface
/**
* `Text` objects represent the nodes that contain the actual text content of a
* Slate document along with any formatting properties. They are always leaf
* nodes in the document tree as they cannot contain any children.
*/
export interface BaseText {
text: string
}
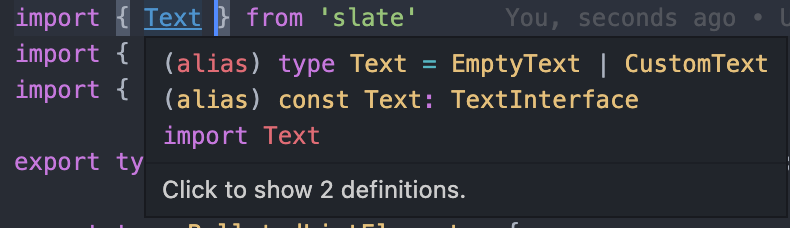
export interface TextInterface {
equals: (text: Text, another: Text, options?: { loose?: boolean }) => boolean
isText: (value: any) => value is Text
isTextList: (value: any) => value is Text[]
isTextProps: (props: any) => props is Partial<Text>
matches: (text: Text, props: Partial<Text>) => boolean
decorations: (node: Text, decorations: Range[]) => Text[]
}Location type Interface
- node
- element
- text
- path
- point
- range
Provided Method api
Customizable
// custom-type.d.ts
export type CustomText = {
bold?: boolean
italic?: boolean
code?: boolean
text: string
}
export type EmptyText = {
text: string
}
declare module 'slate' {
interface CustomTypes {
Text: CustomText | EmptyText
}
}
Operation & Transforms
Operations are the granular, low-level actions that occur while invoking Transforms.
// Operation.ts
export type BaseInsertNodeOperation = {
type: 'insert_node'
path: Path
node: Node
}
// transforms/node.ts
/**
* Insert nodes at a specific location in the Editor.
*/
insertNodes: <T extends Node>(
editor: Editor,
nodes: Node | Node[],
options?: {
at?: Location
match?: NodeMatch<T>
mode?: 'highest' | 'lowest'
hanging?: boolean
select?: boolean
voids?: boolean
}
) => void- Transforms.insertNodes may invokes multiple insert_node operations
- slate sees Operations as micro-tasks. It triggers the screen re-render after a whole set of Operations ( a set of FLUSHING ) finished
Monorepo / Layer Separated
Data-Layer
View-Layer
CustomType
interfaces/custom-types.ts
/**
* Extendable Custom Types Interface
*/
type ExtendableTypes =
| 'Editor'
| 'Element'
| 'Text'
| 'Selection'
| 'Range'
| 'Point'
| 'InsertNodeOperation'
| 'InsertTextOperation'
| 'MergeNodeOperation'
| 'MoveNodeOperation'
| 'RemoveNodeOperation'
| 'RemoveTextOperation'
| 'SetNodeOperation'
| 'SetSelectionOperation'
| 'SplitNodeOperation'
export interface CustomTypes {
[key: string]: unknown
}
export type ExtendedType<
K extends ExtendableTypes,
B
> = unknown extends CustomTypes[K] ? B : CustomTypes[K]ExtendableTypes
type ExtendableTypes =
| 'Editor'
| 'Element'
| 'Text'
| 'Selection'
| 'Range'
| 'Point'
| 'InsertNodeOperation'
| 'InsertTextOperation'
| 'MergeNodeOperation'
| 'MoveNodeOperation'
| 'RemoveNodeOperation'
| 'RemoveTextOperation'
| 'SetNodeOperation'
| 'SetSelectionOperation'
| 'SplitNodeOperation'
export type ExtendedType<
K extends ExtendableTypes,
B
> = ...ExtendableTypes 事先為可以進行擴充的 types 做好限制,在 ExtendedType 吃的第一個 generic type 有限制了它的範圍必須縮限在 ExtendableTypes 之中
CustomTypes
CustomTypes 是主要讓開發者定義 custom types 的 interface ,利用 interface 可以 extend 的特性讓開發者可以透過 declare module 等方式擴充。
declare module 'slate' {
interface CustomTypes {
Editor: CustomEditor
Element: CustomElement
Text: CustomText | EmptyText
}
}ExtendedType utility
- K : 縮限於上方的 ExtendableTypes ,負責比對 CustomTypes 中指定的 key 類型是否被擴充定義。
- B : 傳入的 base-type ,如果對應到的 key 沒有在 CustomTypes 中被擴充定義的話會原封不動地回傳 B 。
export type ExtendedType<
K extends ExtendableTypes,
B
> = unknown extends CustomTypes[K] ? B : CustomTypes[K]透過小範例來協助介紹
/** text.ts */
export interface BaseText {
text: string
}
export type Text = ExtendedType<'Text', BaseText>
/** custom-types.ts */
export type ExtendedType<
K extends ExtendableTypes,
B
> = unknown extends CustomTypes[K] ? B : CustomTypes[K]/** text.ts */
export interface BaseText {
text: string
}
export type Text = ExtendedType<'Text', BaseText>
/** custom-types.ts */
export type ExtendedType<
K extends ExtendableTypes,
B
> = unknown extends CustomTypes[K] ? B : CustomTypes[K]- 在我們將 'Text' 與 BaseText 傳入 ExtendedType 以後,它首先會確認 'Text' 是否存在於 ExtendableTypes 裡。
- 接著進行 unknown extends CustomTypes[K] 的三元判斷式,這裏運用了 unknown 只會 extends unknown 這項特性,當判斷結果為 true 時代表開發者未在 CustomTypes 裡對 K 做擴充,回傳 base-type 給 Text,反之則回傳 CustomTypes 裡 K 對應到的擴充內容給 Text 。
Normalizing
在關聯式資料庫的世界裡,執行資料正規化的『目的』是為了去除冗餘的資料,我們事先針對各種正規化形式定義出了不同的『 constraints 』,而資料庫的欄位結構則須符合這些『 constraints 』,例如:在第一正規化( 1NF )中,一個欄位只能存入一筆資料,而不能是複數筆,這就是其中一條 constraint 。
slate 為了應對過於彈性的 document model ,它也規範了一套內建的 constraints ,每當觸發了編輯器的資料更新時便會自動執行 Normalization ,確保資料符合 constraints 的規範
-
所有的 Element 節點內必須含有至少一個 Text 子節點。在進行正規化時如果遭遇到不符合此規範的 Element 節點,會加入一個空的 Text 節點進入它的子層。
-
將兩個相鄰且擁有完全相同的 properties 的 Text nodes 合併成同一個節點(不會刪減文字內容,只是單純做節點合併而已)。
-
...
Implement Properties
- Normalization Deferring (正規化延遲)
Normalize 的執行方式並不是『一個 Operation 搭配一次 Normalize 』,而是『一組完整的 FLUSHING 搭配一次 Normalize 』。畢竟一次 Transform 裡有好多次的 Operations ,才剛弄乾淨馬上就被下一個 Operation 弄髒顯然不是我們想要的
- Multi-pass Normalizing (正規化的 Infinite-loop )
slate 實際執行正規化功能的方式是透過呼叫 Transforms api 達成,因為我們無法保證每次的正規化實際上會觸發執行哪些 Transform 。因此 slate 採用的方式是在每個 Operation 裡對更新的節點進行骯髒標記的演算法,並在骯髒標記的清單完全被清除以後才結束正規化
Normalization Deffering
withoutNormalize
所有會需要 Normalizing 功能的 Transform methods 裡都一定會包進這個 method 裡來實作
insertNodes<T extends Node>(
editor: Editor,
// ... args
): void {
Editor.withoutNormalizing(editor, () => {
// ... Implementation
})
},withoutNormalize
/**
* Call a function, deferring normalization until after it completes.
*/
withoutNormalizing(editor: Editor, fn: () => void): void {
const value = Editor.isNormalizing(editor)
NORMALIZING.set(editor, false)
try {
fn()
} finally {
NORMALIZING.set(editor, value)
}
Editor.normalize(editor)
},- 儲存了 isNormalizing method 回傳的資料作為 NORMALIZING WeakMap 的初始值。
- 將 NORMALIZING value 設為 false ,等執行完傳入的 fn 以後再設 NORMALIZING 回先前存下來的初始值
- 重新執行 normalize method
isNormalizing
/**
* Check if the editor is currently normalizing after each operation.
*/
isNormalizing(editor: Editor): boolean {
const isNormalizing = NORMALIZING.get(editor)
return isNormalizing === undefined ? true : isNormalizing
},isNormalizing 其實單純就是回傳當前 editor 的 NORMALIZING value ,代表編輯器當前是否為『完成正規化』的狀態,只是多加了一層三元判斷:如果 value === undefined 則回傳 true (因為 undefined 為初始值,編輯器的初始狀態就是已經完成正規化的狀態了)。
normalize(
editor: Editor,
options: {
force?: boolean
} = {}
): void {
// ...
if (!Editor.isNormalizing(editor)) {
return
}
// ... Implementation
}normalize
呼叫節點正規化的主要 function
這些操作使得一組 Transform 裡頭除了最初呼叫的那次包進 withoutNormalizing 的 fn method 會推遲執行 normalize method 之外,其餘在過程中呼叫的 normalize 都會因為 isNormalizing 回傳值為 false 因而直接跳過。
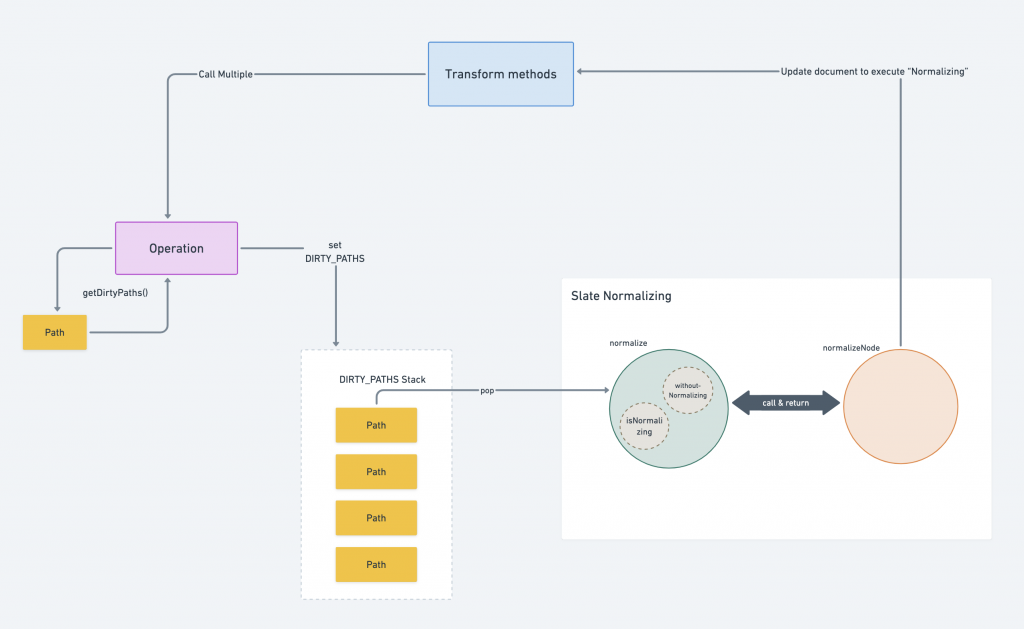
Multi-pass Normalizing feat. Dirty-Path
DIRTY_PATHS WeakMap
// weak-map.ts
export const DIRTY_PATHS: WeakMap<Editor, Path[]> = new WeakMap()Function call when Operation triggered
const set = new Set()
const dirtyPaths: Path[] = []
const add = (path: Path | null) => {
if (path) {
const key = path.join(',')
if (!set.has(key)) {
set.add(key)
dirtyPaths.push(path)
}
}
}
const oldDirtyPaths = DIRTY_PATHS.get(editor) || []
const newDirtyPaths = getDirtyPaths(op)
for (const path of oldDirtyPaths) {
const newPath = Path.transform(path, op)
add(newPath)
}
for (const path of newDirtyPaths) {
add(path)
}
DIRTY_PATHS.set(editor, dirtyPaths)在每一次的 Operation 中:
- oldDirtyPaths 會去取得儲存在 DIRTY_PATHS 裡頭前一次的結果,經過這次的 operation transform 為正確的 path 以後經由 add method 推入 dirtyPaths 變數裡。
- newDirtyPaths 會透過 getDirtyPaths 取得這次 operation 會製造出的 Dirty-Path 並經由 add method 推入 dirtyPaths 變數裡。
- add method 會將丟入的 path 與第一行的 set 比對,只推入還不存在於 dirtyPaths 變數裡的 path 以避免重複推入。
- 最後將 dirtyPaths 存為 DIRTY_PATHS 裡 editor 的 value 。
const set = new Set()
const dirtyPaths: Path[] = []
const add = (path: Path | null) => {
if (path) {
const key = path.join(',')
if (!set.has(key)) {
set.add(key)
dirtyPaths.push(path)
}
}
}
const oldDirtyPaths = DIRTY_PATHS.get(editor) || []
const newDirtyPaths = getDirtyPaths(op)
for (const path of oldDirtyPaths) {
const newPath = Path.transform(path, op)
add(newPath)
}
for (const path of newDirtyPaths) {
add(path)
}
DIRTY_PATHS.set(editor, dirtyPaths)Multi-pass Normalizing
normalize(
editor: Editor,
options: {
force?: boolean
} = {}
): void {
...
if (getDirtyPaths(editor).length === 0) {
return
}
// Main-Process
Editor.withoutNormalizing(editor, () => {
...
});
},
withoutNormalizing(editor: Editor, fn: () => void): void {
...
try {
fn()
}
...
Editor.normalize(editor)
},// Main-Process
Editor.withoutNormalizing(editor, () => {
// ...
const max = getDirtyPaths(editor).length * 42 // HACK: better way?
let m = 0
while (getDirtyPaths(editor).length !== 0) {
if (m > max) {
throw new Error(`...`)
}
const dirtyPath = getDirtyPaths(editor).pop()!
// If the node doesn't exist in the tree, it does not need to be normalized.
if (Node.has(editor, dirtyPath)) {
const entry = Editor.node(editor, dirtyPath)
editor.normalizeNode(entry)
}
m++
}
});
Reference
Code
By ian Lai




