



Frédéric Clavert
historian. digital history. digital memory studies. join me on mastodon: @inactinique@mastodon.social
frédéric clavert
@inactinique@hcommons.social
frederic.clavert@uni.lu
inactinique.net
They can help understand
Archived, they will help future historians understand our present
About this tweet, see: Joshua Sternfeld, « Historical Understanding in the Quantum Age », Journal of Digital Humanities, 3-2, 2014.
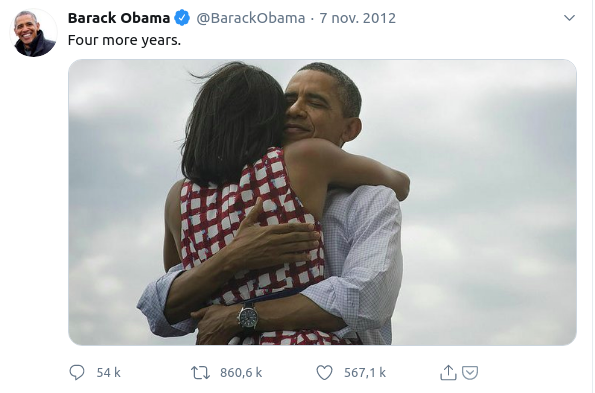
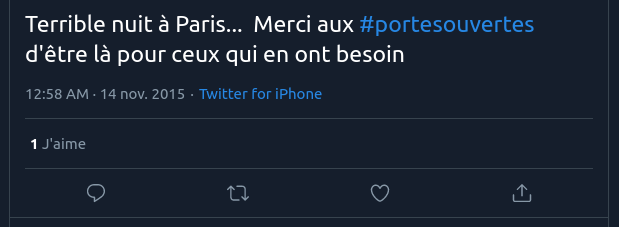
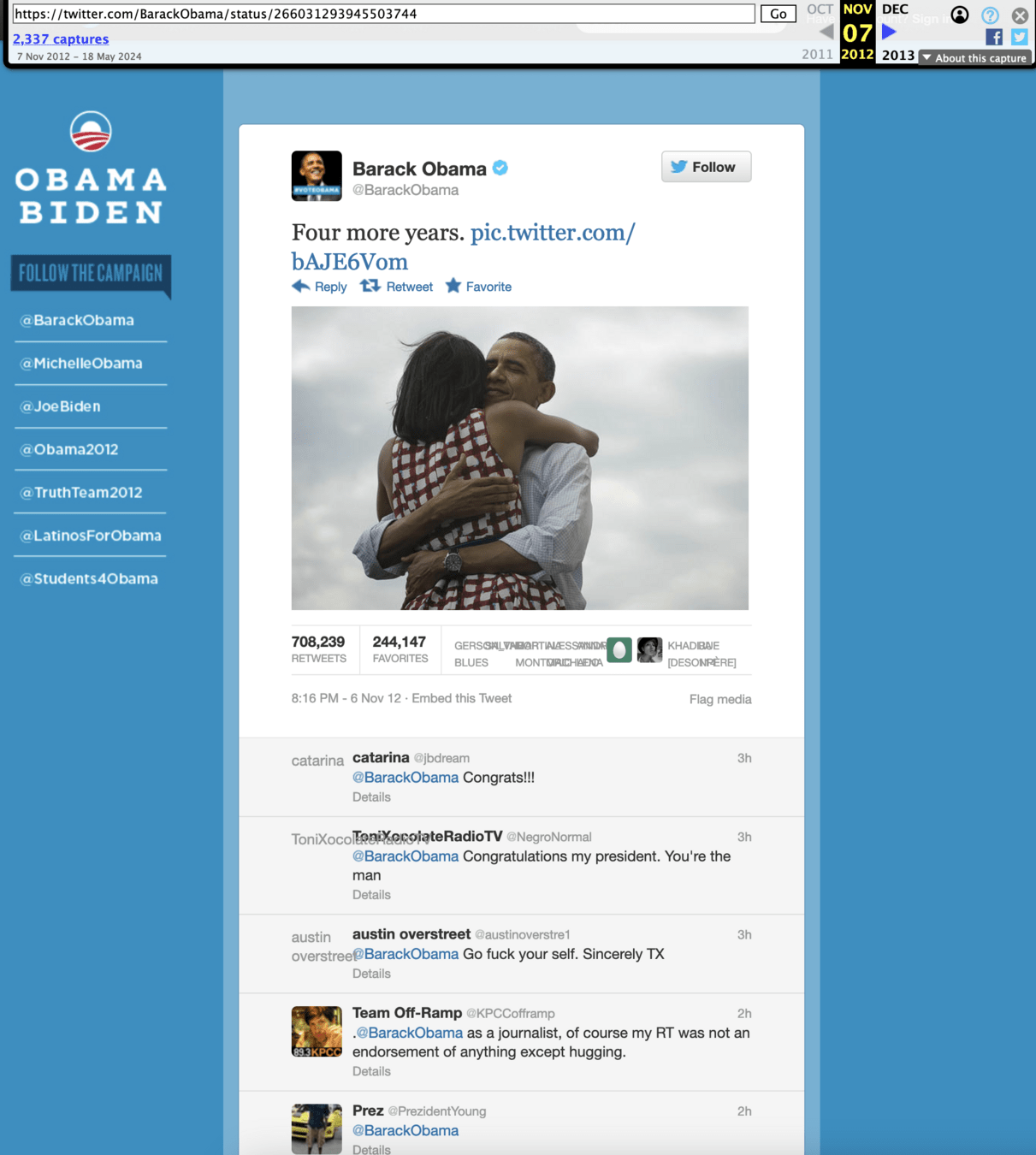
Tweet from the night of the Bataclan attack, with the #portesouvertes hashtag
The ones we can.
An application programming interface (API) is a computing interface which defines interactions between multiple software intermediaries.
source: wikipedia
Who are we studying when collecting and analysing social media data?
Any other ideas?
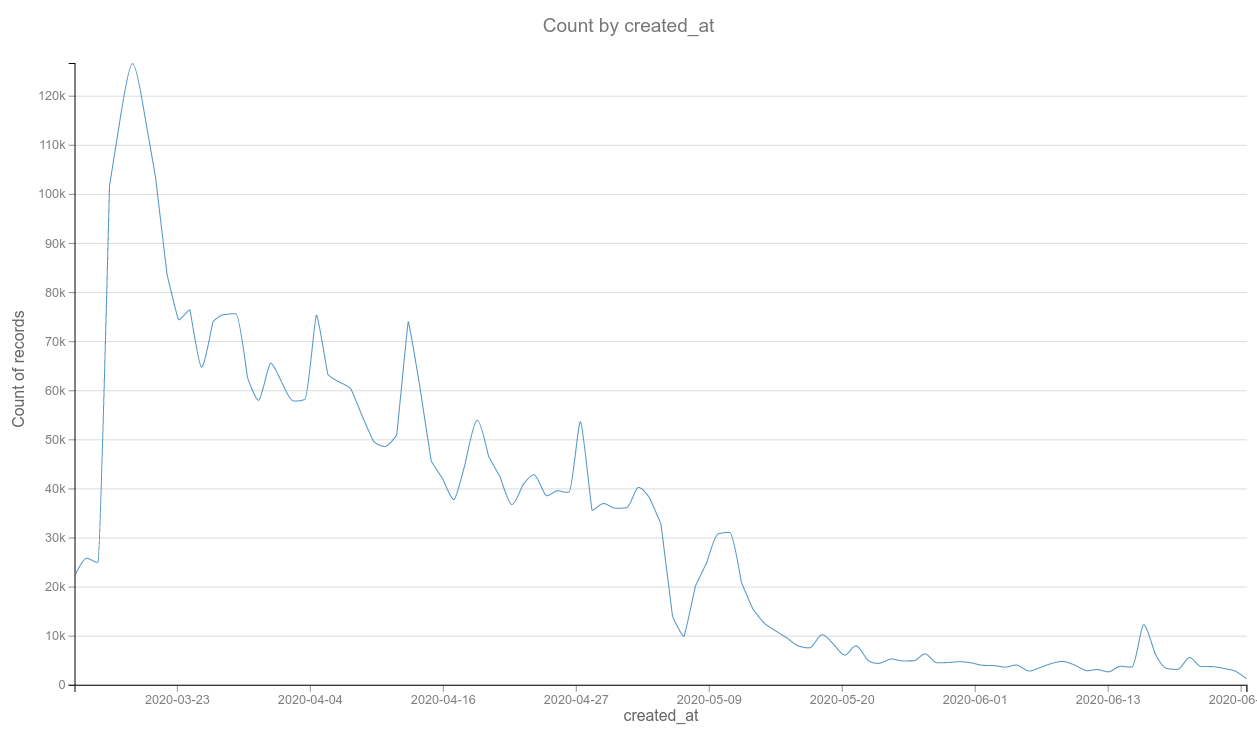
9 millions+ tweets collected
Background: John Hopkins University coronavirus map. Screenshot (7/7/2020)
Works now only with the search engine
By Frédéric Clavert




