





















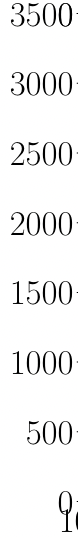








He Wang PRO
Knowledge increases by sharing but not by saving.
第 4 部分 深度学习基础
主讲老师:王赫
2023/12/29
ICTP-AP, UCAS
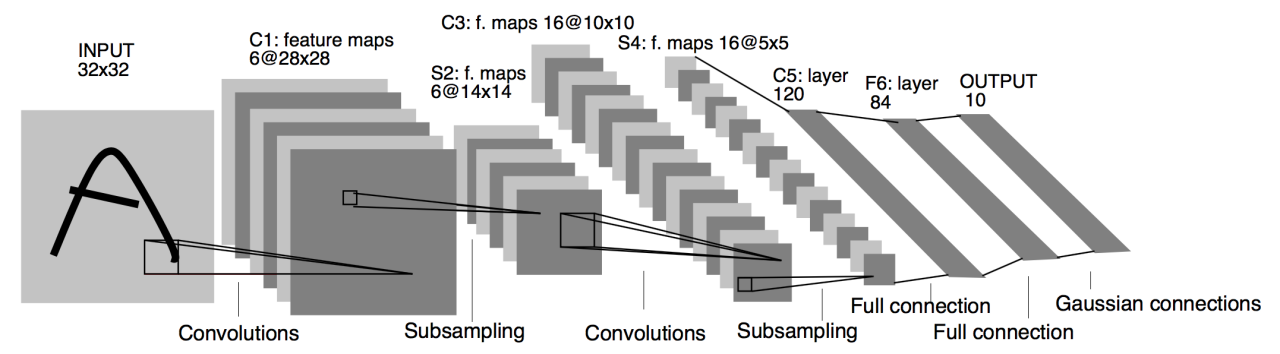
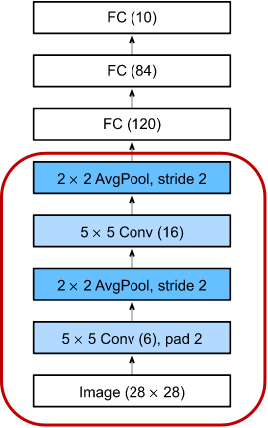
卷积神经网络与引力波信号探测
# GW: DL
Gebru et al. ICCV (2017)
Zhou et al. CVPR (2018)
Shen et al. CVPR (2018)
Image courtesy of Tesla (2020)
# GW: DL
# GW: DL
# GW: DL
# GW: DL
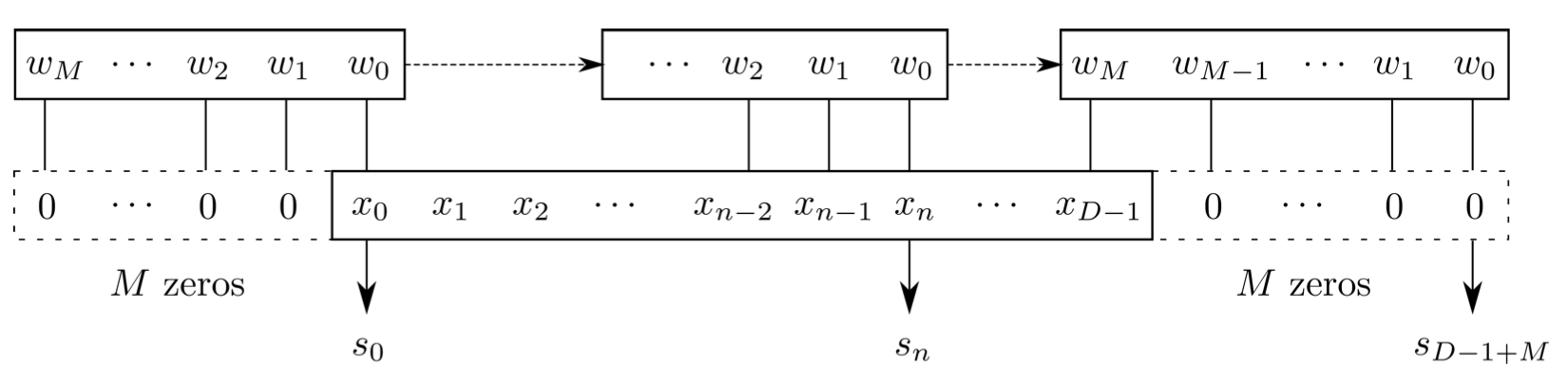
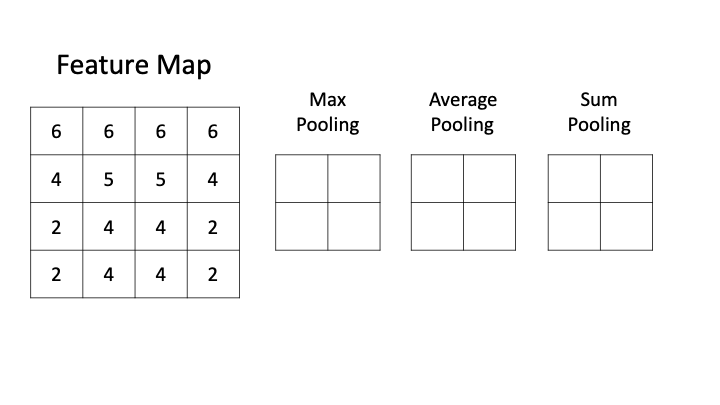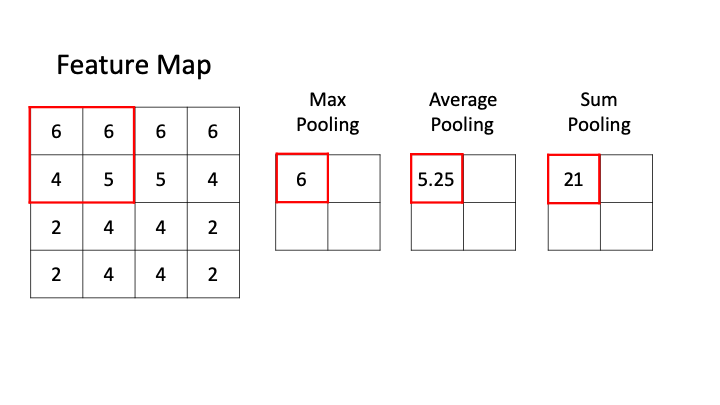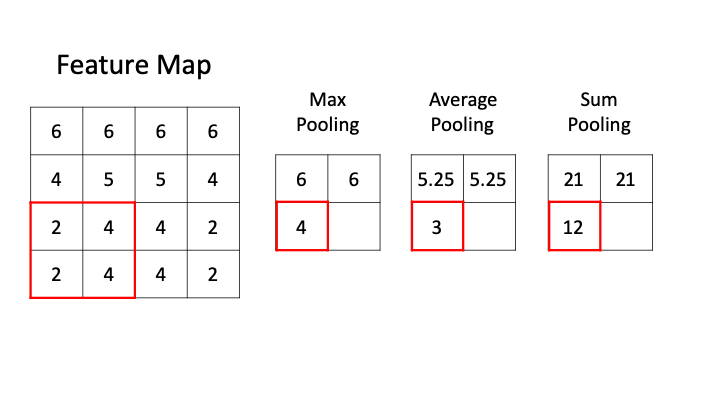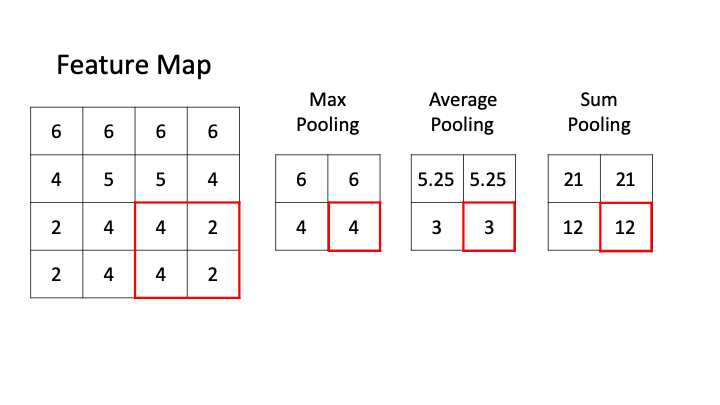
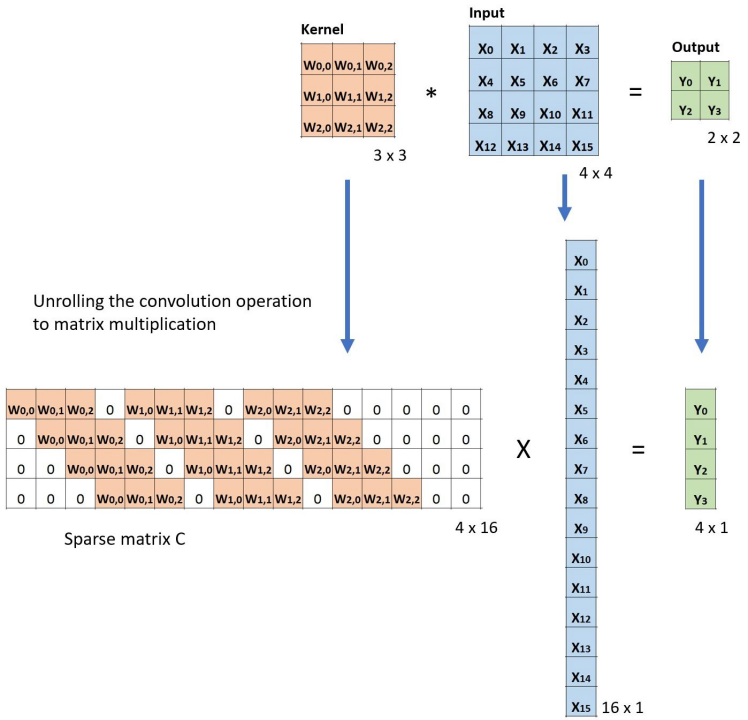
[1,1,5] \(\star\) [1,1,3] \(\rightarrow\) [1,1,3/5/7]
样本个数
“深度”维度
卷积核个数
# GW: DL
[1,1,5] \(\star\) [1,1,3] \(\rightarrow\) [1,1,3/5/7]
样本个数
“深度”维度
卷积核个数
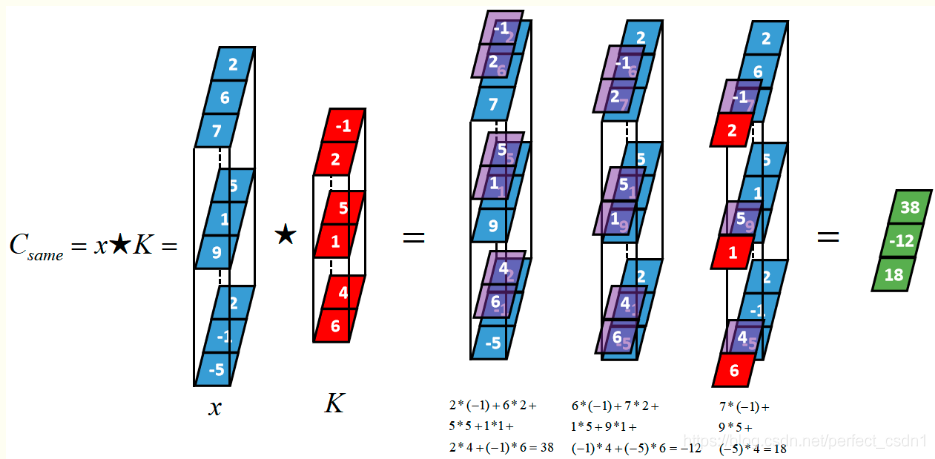
[1,3,3] \(\star\) [1,3,2] \(\rightarrow\) [1,1,3]
“深度”维度
# GW: DL
[1,3,3] \(\star\) [1,3,2] \(\rightarrow\) [1,1,3]
“深度”维度
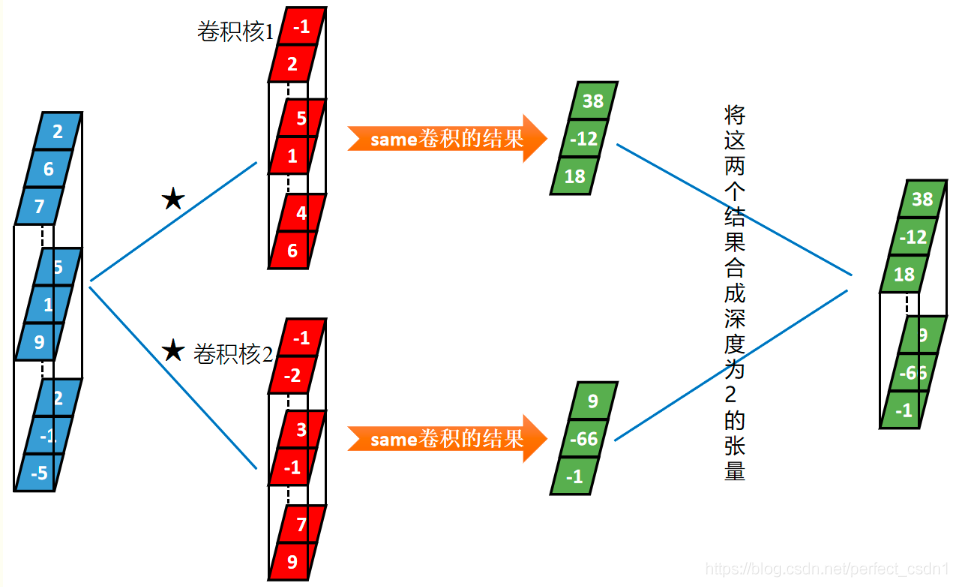
[1,3,3] \(\star\) [2,3,2] \(\rightarrow\) [1,2,3]
“深度”维度
样本个数
卷积核个数
# GW: DL
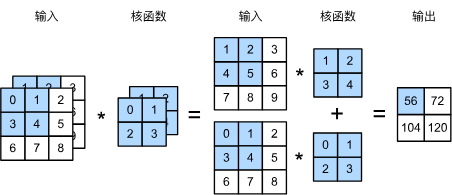
[1,2,3,3] \(\star\) [1,2,2,2] \(\rightarrow\) [1,1,2,2]
样本个数
channel
卷积核个数
长和宽
# GW: DL
[1,3,3,3] \(\star\) [2,3,1,1] \(\rightarrow\) [1,2,3,3]
样本个数
channel
卷积核个数
长和宽
# GW: DL
# GW: DL
# GW: DL
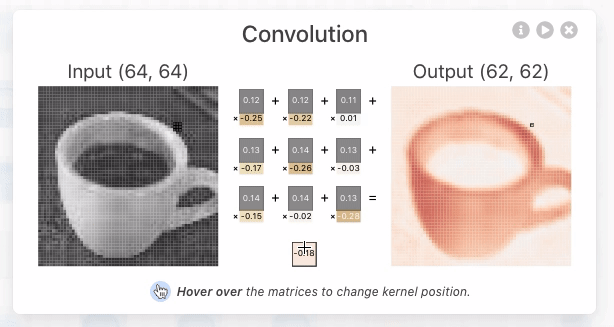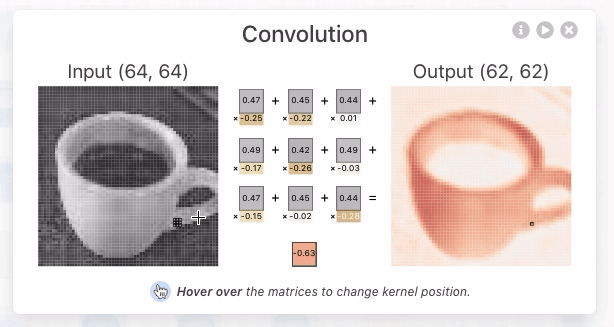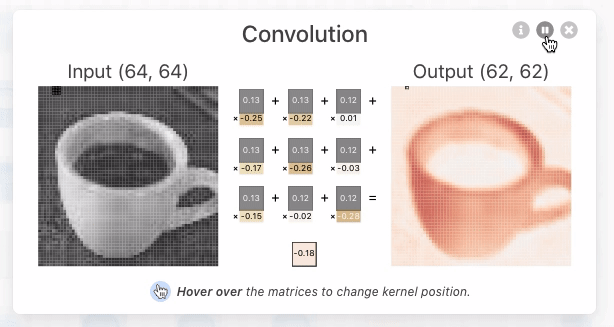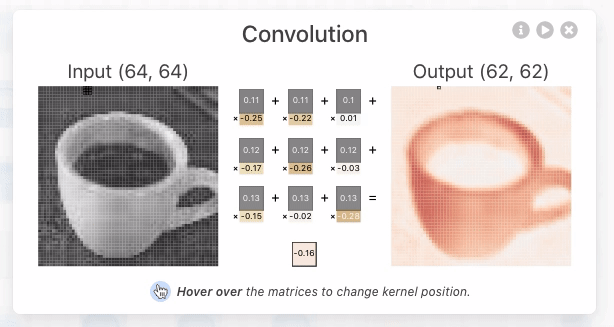
CNN Explainer:https://poloclub.github.io/cnn-explainer/
# GW: DL
# GW: DL
# GW: DL
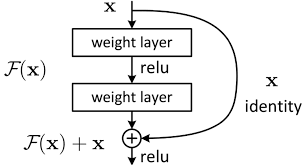
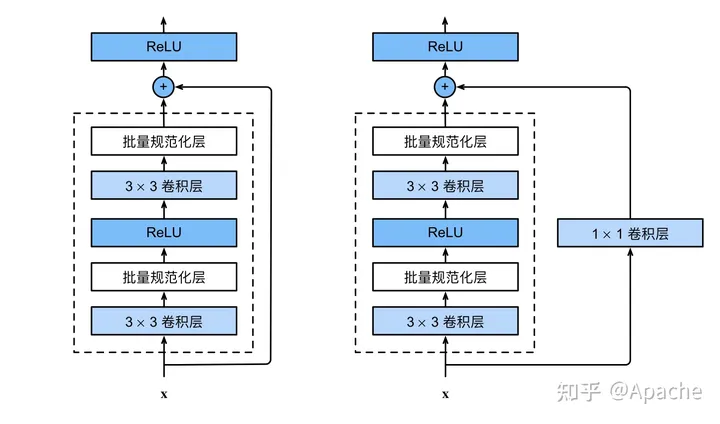
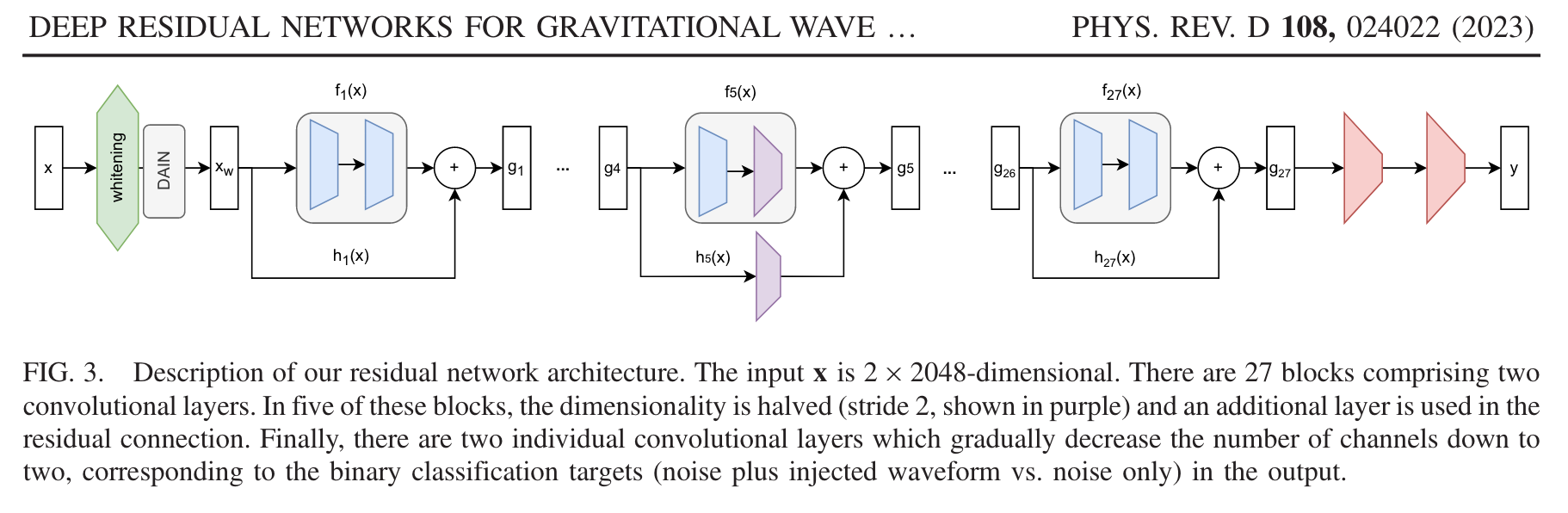
残差的思想: 去掉相同的主体部分,从而突出微小的变化。
可以被用来训练非常深的网络
He K, Zhang X, Ren S, et al. Deep residual learning for image recognition. CVPR (2016)
# GW: DL
# GW: DL
See also:
D. George and E.A. Huerta Phys. Lett. B 778 64–70 (2018)
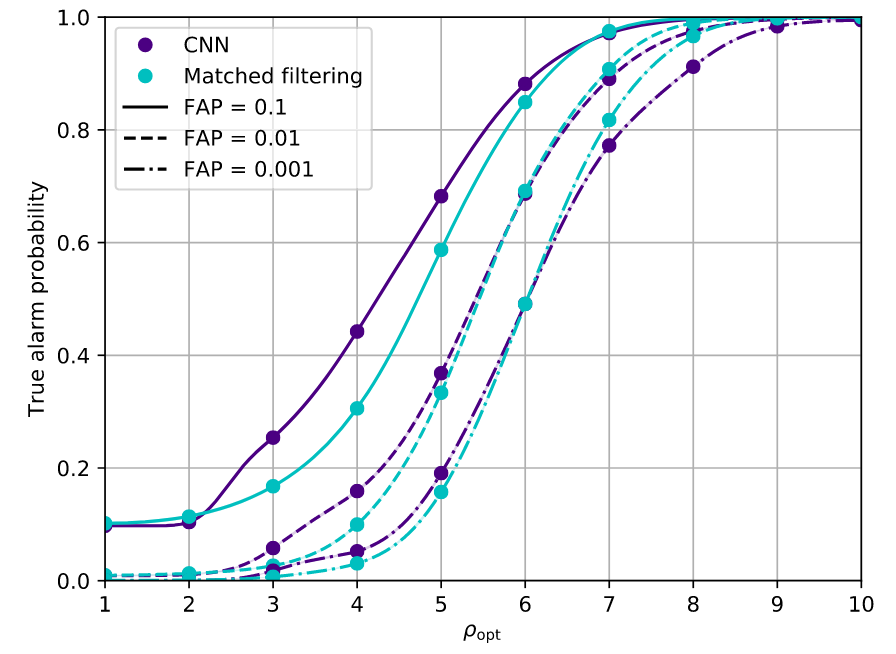
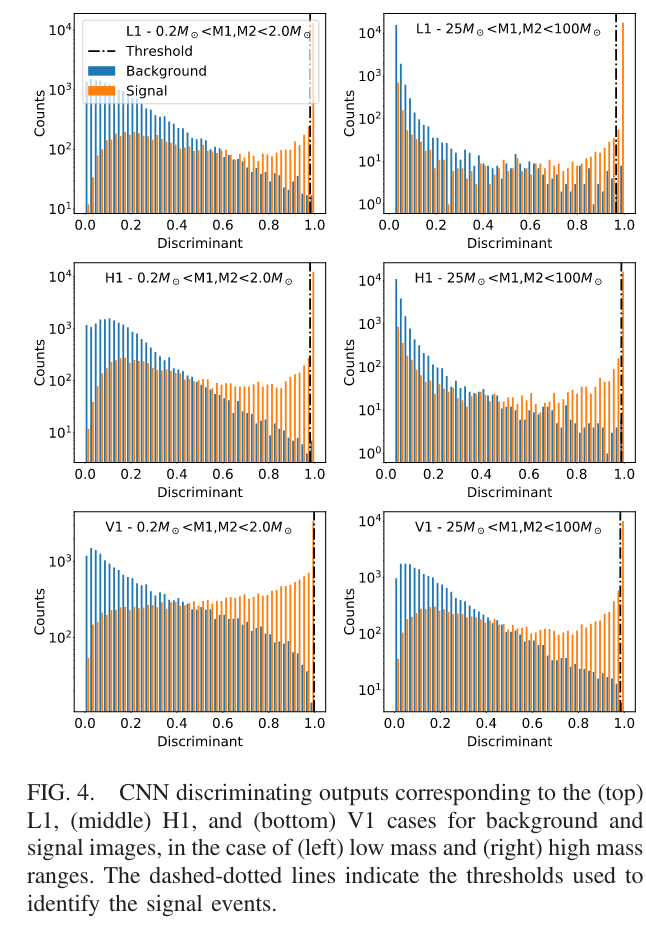
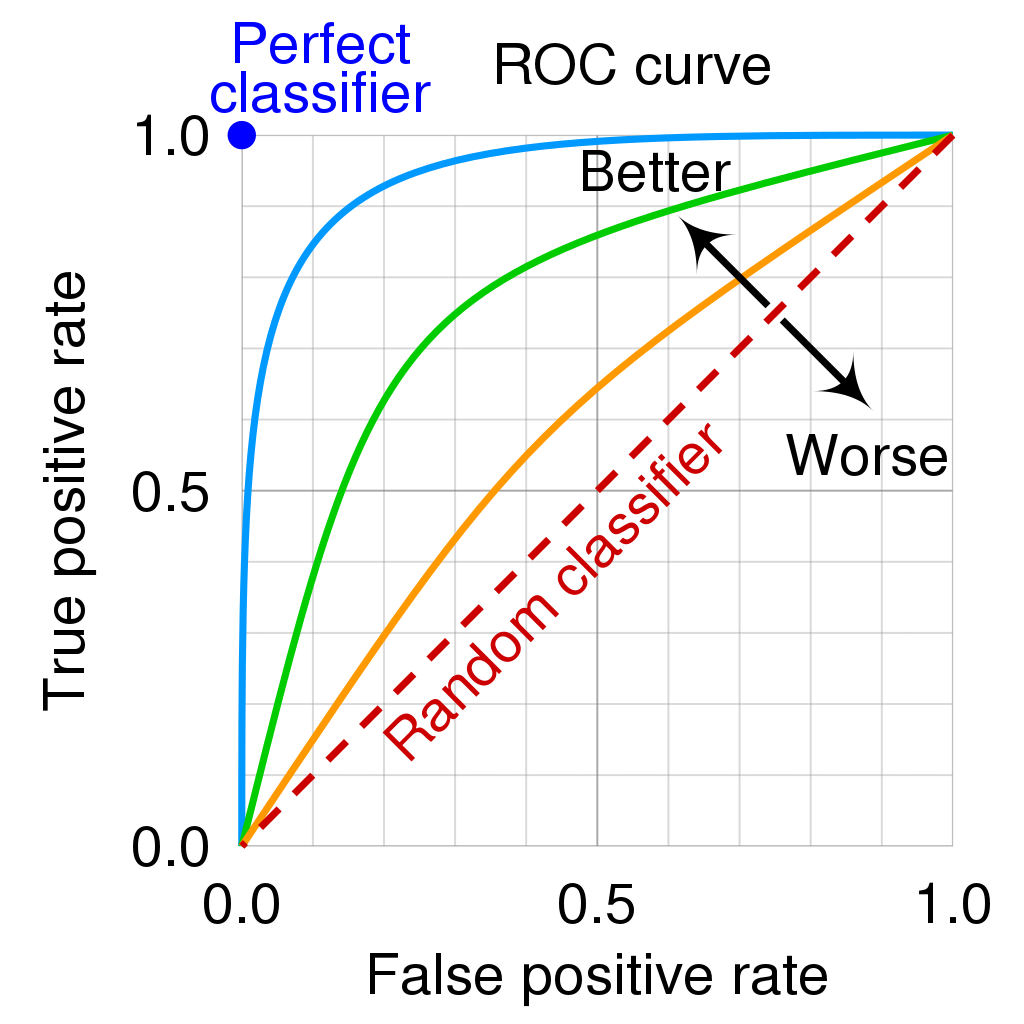
What is ROC?
# GW: DL
# GW: DL
0.99
0.05
期望达到的效果(Evaluation):
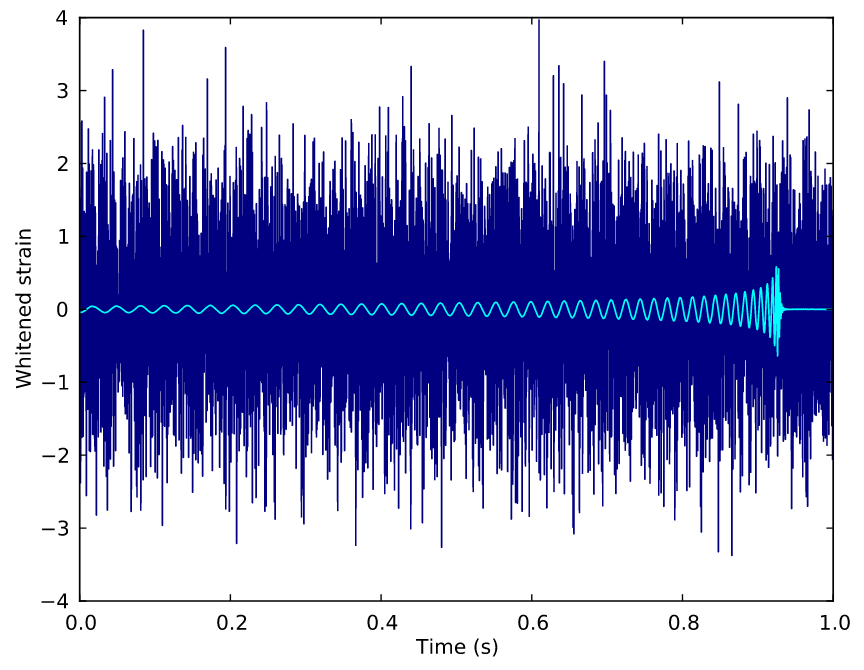
H1
L1
CNN
# GW: DL
训练的过程(Train):
1
0
H1
L1
Labels
CNN
[6,2,16384][6,2]1
1
0
0
# GW: DL
CNN
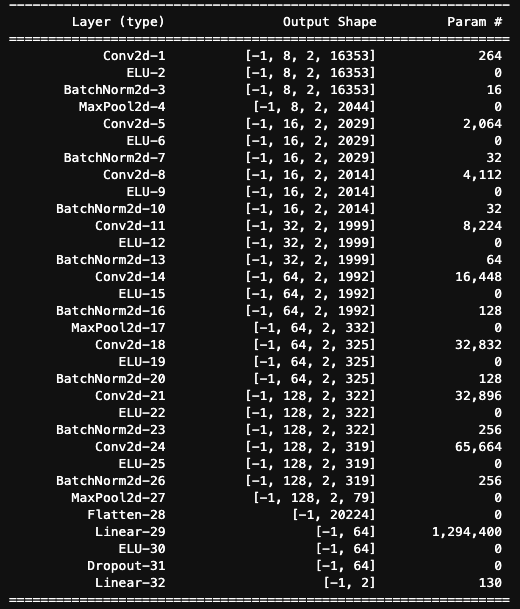
[6,2,16384] -> Reshape your input data:
[6,1,2,16384]样本个数
in channel
长和宽
Conv2D:
Conv2d(1, 8, kernel_size=(1, 32), stride=(1, 1))[8,1,1,32][6,8,2,16353]卷积核个数 / out channel
in channel
out channel
# GW: DL
CNN
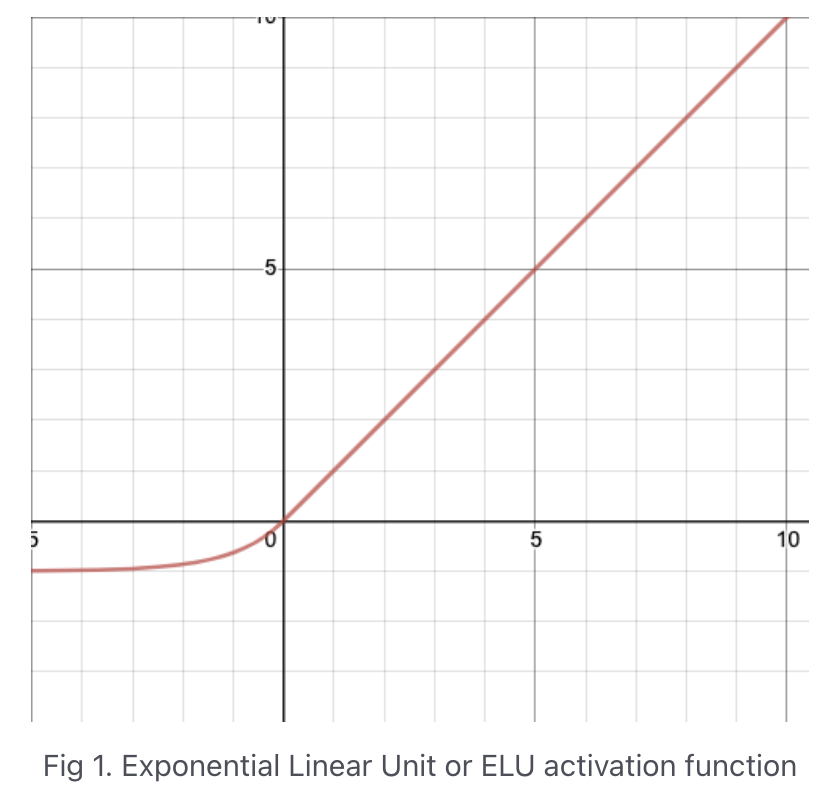
ELU activation
[6,8,2,16353][6,8,2,16353]ELU(alpha=0.01)# GW: DL
CNN
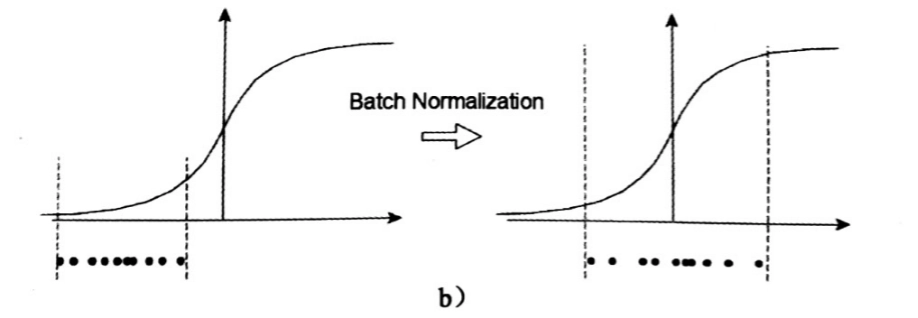
Batch Normalization
[6,8,2,16353][6,8,2,16353]BatchNorm2d(8, eps=1e-05, momentum=0.1)in channel
# GW: DL
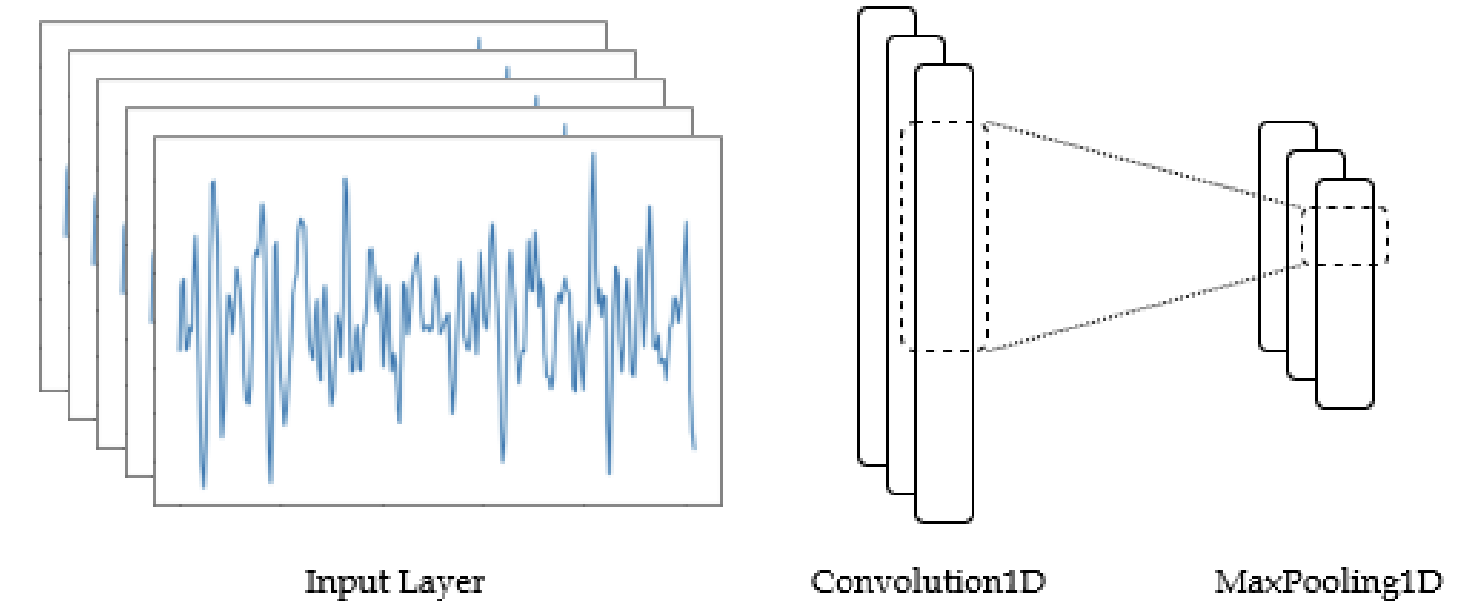
CNN
Max Pooling
[6,8,2,16353][6,8,2,2044]MaxPool2d(kernel_size=[1, 8],
stride=[1, 8],
padding=0)# GW: DL
CNN
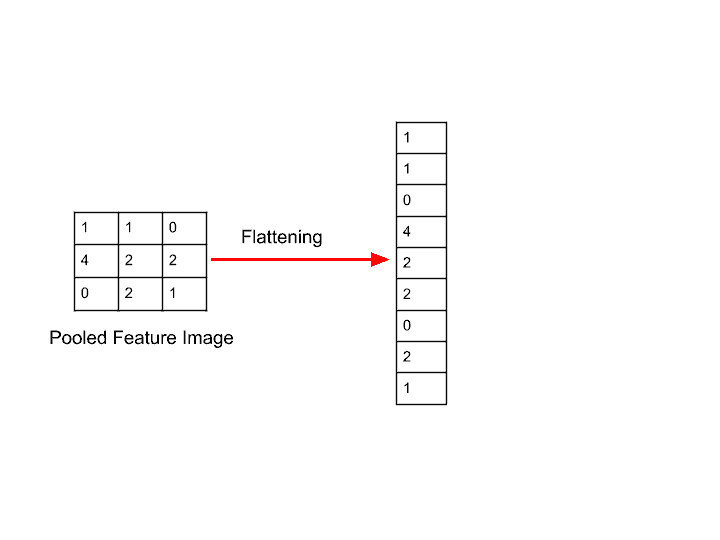
Flatten
[6,128,2,79][6,20224]Linear
[6,20224][6,64][6,64][20224,64][64,2][6,2]# GW: DL
CNN
Dropout
[6,20224][6,64][20224,64]Dropout(p=0.5)# GW: DL
训练的过程(Train):
1
0
H1
L1
Labels
CNN
[6,2,16384]1
1
0
0
[6,2]# GW: DL
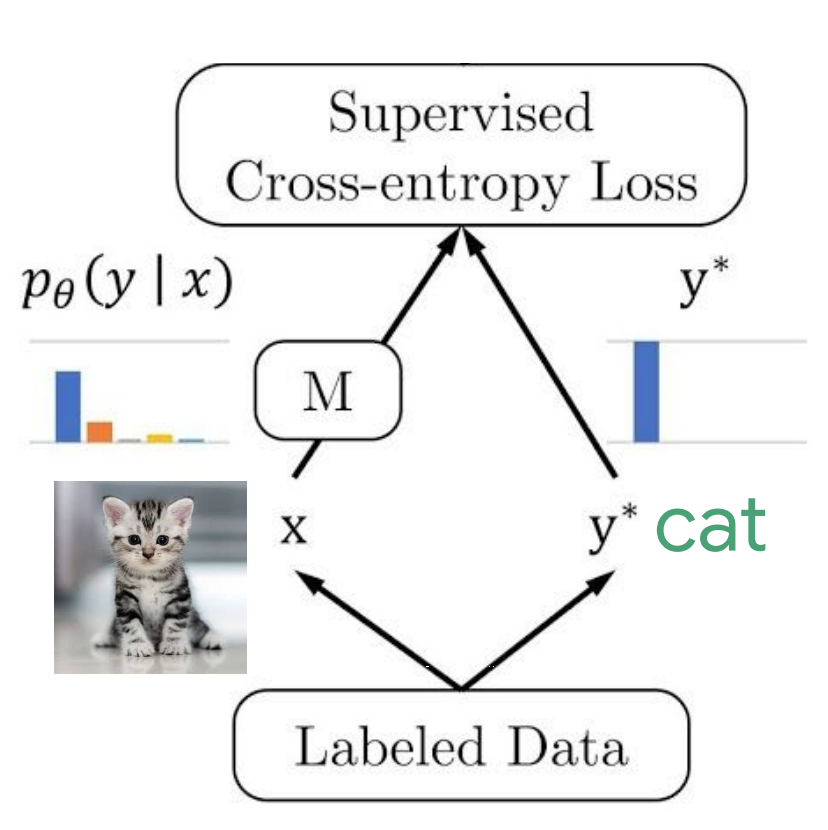
Dataset containing \(N\) examples sampling from true but unknown data generating distribution \(p_{\text {data }}(\mathbf{x})\):
with coressponding ground-truth labels:
Machine learning model is nothing but a map \(f\) from samples to labels:
where \(\mathbb{\Theta}\) is parameters of the model and the outputs are predicted labels:
described by \(p_{\text {model }}(\mathbf{y}|\mathbf{x} ; \boldsymbol{\Theta})\), a parametric family of probability distributions over the same space indexed by \(\Theta\).
# GW: DL
Dataset containing \(N\) examples sampling from true but unknown data generating distribution \(p_{\text {data }}(\mathbf{x})\):
with coressponding ground-truth labels:
Machine learning model is nothing but a map \(f\) from samples to labels:
where \(\mathbb{\Theta}\) is parameters of the model and the outputs are predicted labels:
described by \(p_{\text {model }}(\mathbf{y}|\mathbf{x} ; \boldsymbol{\Theta})\), a parametric family of probability distributions over the same space indexed by \(\Theta\).
Objective:
# GW: DL
Objective:
to construct cost function \(J(\Theta)\) (also called loss func. or error func.)
For classification problem, we always use maximum likelihood estimator for \(\Theta\)
# GW: DL
Objective:
在信息论中,可以通过某概率分布函数 \(p(x),x\in X\) 作为变量,定义一个关于 \(p(x)\) 的单调函数 \(h(x)\),称其为概率分布 \(p(x)\) 的信息量(measure of information): \(h(x) \equiv -\log p(x)\)
定义所有信息量的期望为随机变量 \(x\) 的 熵 (entropy):
若同一个随机变量 \(x\) 有两个独立的概率分布 \(p(x)\) 和 \(q(x)\),则可以定义这两个分布的相对熵 (relative entropy),也常称为 KL 散度 (Kullback-Leibler divergence),来衡量两个分布之间的差异:
可见 KL 越小,表示 \(p(x)\) 和 \(q(x)\) 两个分布越接近。上式中,我们已经定义了交叉熵 (cross entropy) 为
# GW: DL
Objective:
当对应到机器学习中最大似然估计方法时,训练集上的经验分布 \(\hat{p}_ \text{data}\) 和模型分布之间的差异程度可以用 KL 散度度量为:
由上式可知,等号右边第一项仅涉及数据的生成过程,和机器学习模型无关。这意味着当我们训练机器学习模型最小化 KL 散度时,我们只需要等价优化地最小化等号右边的第二项,即有
Recall:
由此可知,对于任何一个由负对数似然组成的代价函数都是定义在训练集上的经验分布和定义在模型上的概率分布之间的交叉熵。
# GW: DL
训练的过程(Train):
1
0
H1
L1
Labels
CNN
[6,2,16384]1
1
0
0
[6,2]# GW: DL
训练的过程(Train):
1
0
H1
L1
Labels
CNN
[6,2,16384]1
1
0
0
[6,2]# GW: DL
基于分类问题的网络模型里,我们都是用 softmax 函数作为模型最终输出数据时的非线性计算单元,其函数形式为:
1
0
Labels
1
1
0
0
[6,2]由于该函数的输出元素都介于 0 和 1 之间,且向量之和为 1,这使得其可以作为一个有效的“概率分布” \(p_\text{model}(y=k|\mathbf{x}^{(i)})\)。
由此,我们使用最大化条件对数似然输出某样本的目标分类 \(y\) 时,即等价于对下式最大化,
上式中的第一项表示模型的直接输出结果 \(\hat{y}_k\),对优化目标有着直接的贡献。在最大化对数似然时,当然是第一项越大越好,而第二项是鼓励越小越好。根据 \(\log\sum^N_j\exp(\hat{y}_ j)\sim\max_j\hat{y}_ j\) 近似关系,可以发现负对数似然代价函数总是强烈的想要惩罚最活跃的不正确预测。如果某样本的正确 label 对应了 softmax 的最大输入,那么 \(-{y}_k\) 项和 \(\log \sum_j^N \exp \left({y}_j\right)\sim\max_jy_j=y_j\) 项将大致抵消。
# GW: DL
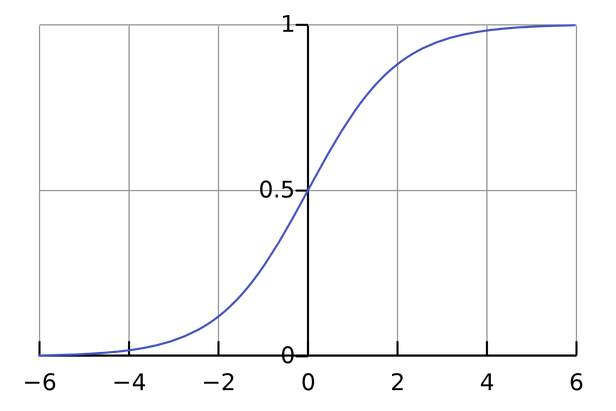
对于二值型的分类学习任务,softmax 函数会退化到 sigmoid 函数:
1
0
Labels
1
1
0
0
[6,2]由此可以证明,cost funcion 可以表示为
# GW: DL
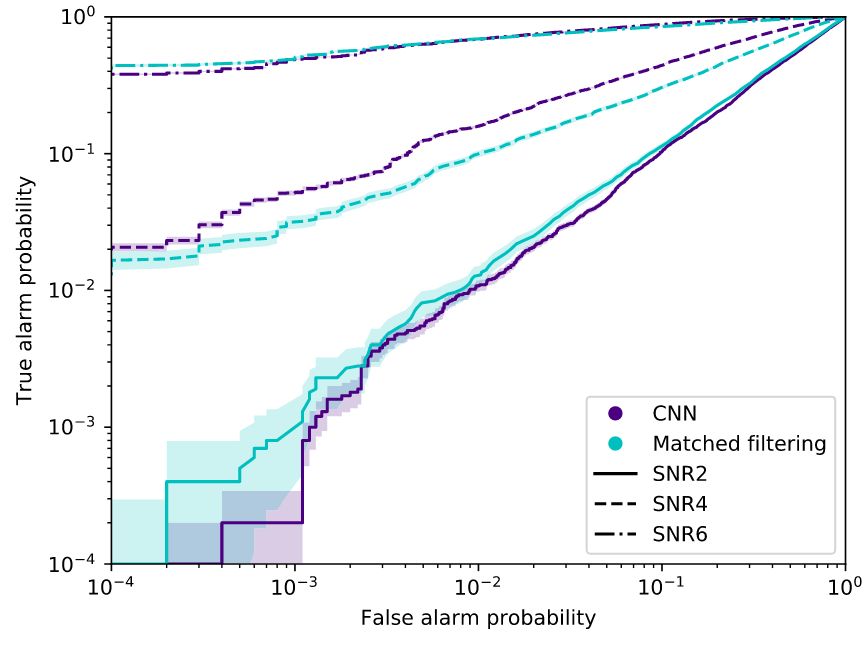
Menéndez-Vázquez A, et al.PRD 2021
arXiv: 2307.09268
# GW: DL
训练的过程(Train):
1
0
H1
L1
Labels
CNN
[6,2,16384]1
1
0
0
[6,2]# GW: DL
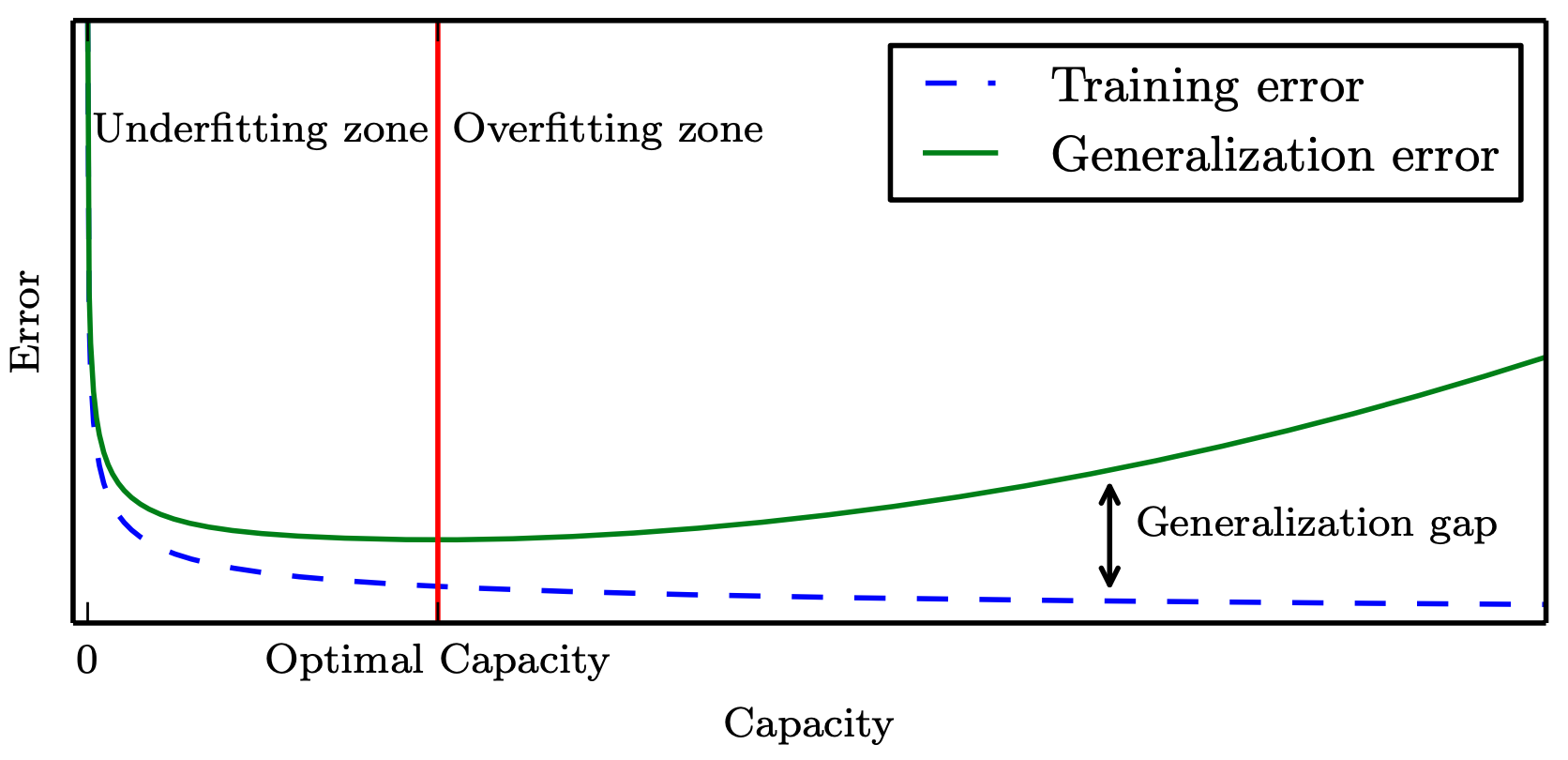
“最合适”的模型:机器学习从有限的观测数据中学习出规律 [训练误差 (training error)],
并将总结的规律推广应用到未观测样本上 \(\rightarrow\) 追求泛化性能 [泛化误差 (generalization error)]。
所以,我们认定机器学习算法效果是否很好,两个学习目标:
降低训练误差。
缩小训练误差和测试误差的差距。
这两个目标分别对应了机器学习的两个重要挑战:
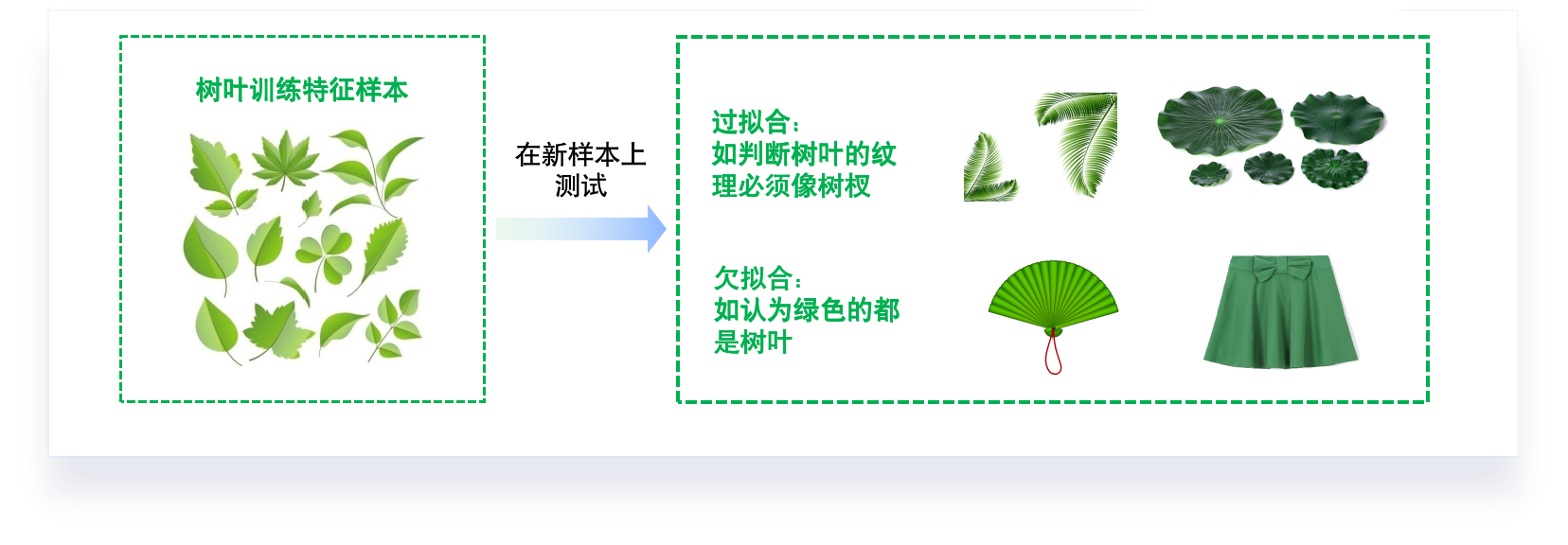
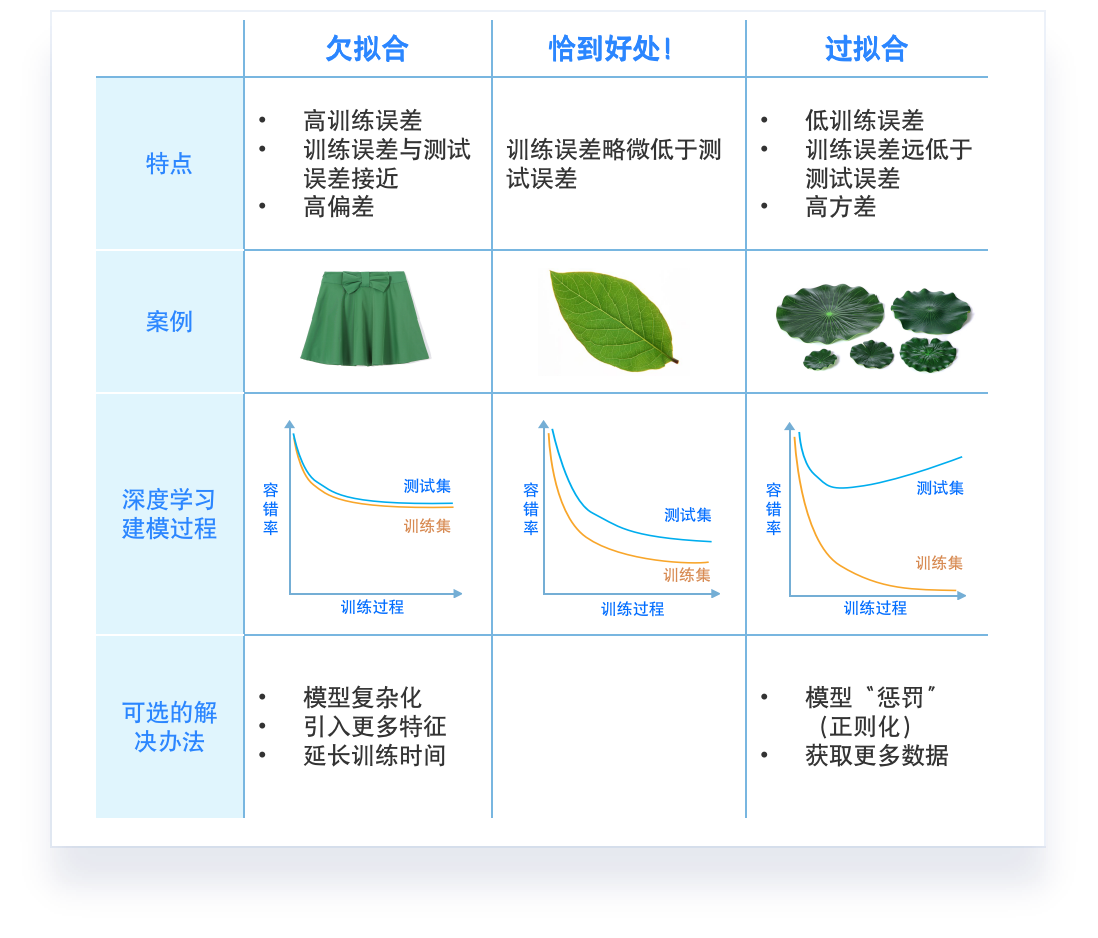
欠拟合 (underfitting):模型不能在训练集上获得足够低的误差。
过拟合 (overfitting):训练误差与测试误差之间的差距过大。
# GW: DL
“最合适”的模型:机器学习从有限的观测数据中学习出规律 [训练误差 (training error)],
并将总结的规律推广应用到未观测样本上 \(\rightarrow\) 追求泛化性能 [泛化误差 (generalization error)]。
所以,我们认定机器学习算法效果是否很好,两个学习目标:
降低训练误差。
缩小训练误差和测试误差的差距。
这两个目标分别对应了机器学习的两个重要挑战:
欠拟合 (underfitting):模型不能在训练集上获得足够低的误差。
过拟合 (overfitting):训练误差与测试误差之间的差距过大。
泛化性能 是由
学习算法的能力、
数据的充分性以及
学习任务本身的难度共同决定。
模型的容量 Capacity 是指其拟合各种函数的能力,一般也可以代表模型的复杂程度。(“计算学习理论”)
奥卡姆剃刀原理:
惩罚大模型复杂度
训练集的一般性质尚未被
学习器学好
学习器把训练集特点当做样本的 一般特点.
偏差-方差窘境(bias-variance dilemma)
# GW: DL
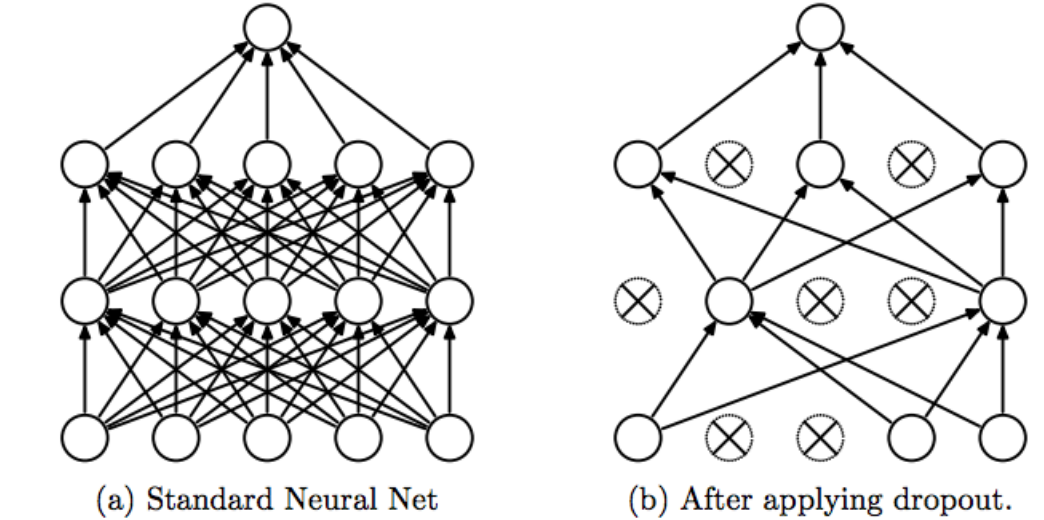
early stop、dropout
参数调得好不好,往往对最终性能有关键影响。
# GW: DL
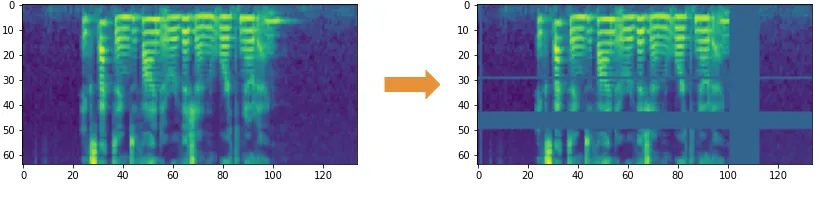
SpecAugment
# GW: DL
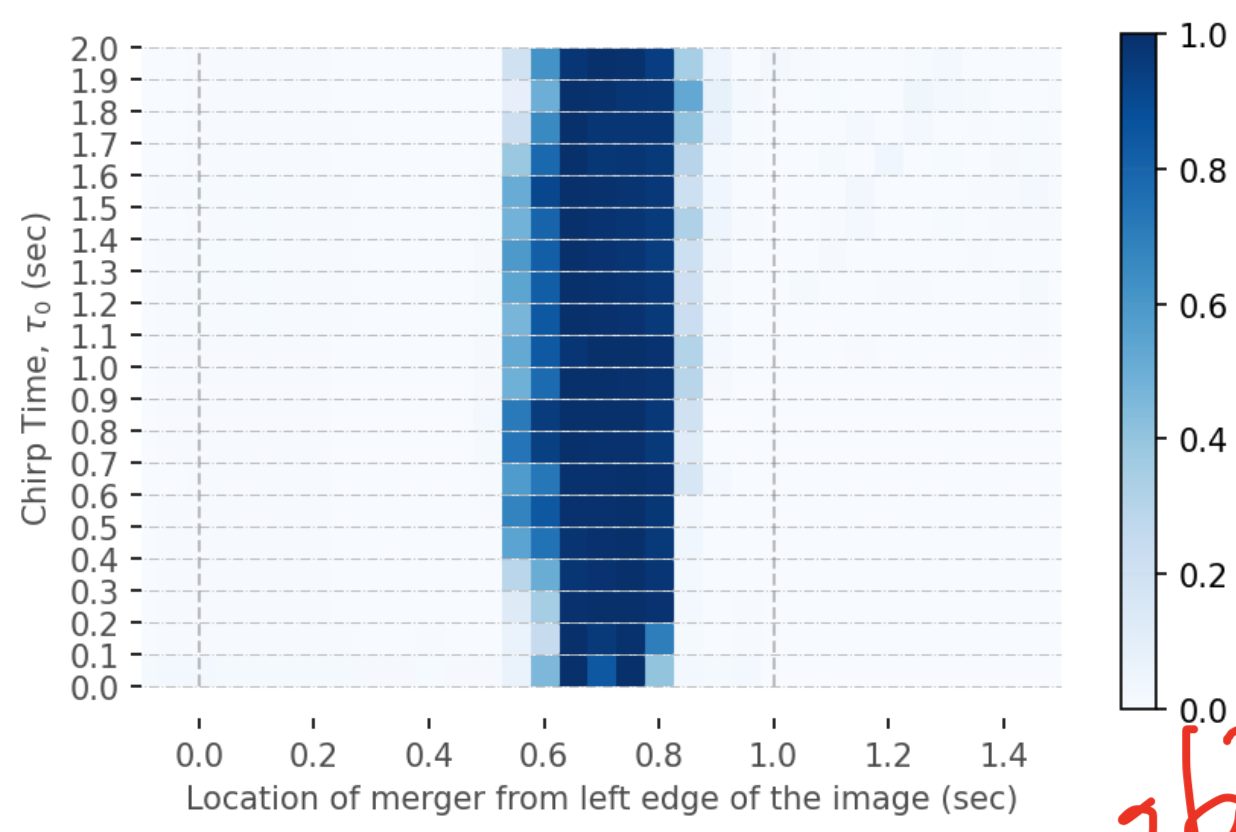
1.
Source: X
PSD
2.
noise instance
...
...
waveform
...
...
Jadhav et al. 2306.11797
merger location
...
...
# GW: DL
期望达到的效果(Evaluation):
H1
L1
CNN
0.99
0.05
# GW: DL
分类模型泛化性能评估:混淆矩阵/ROC/AUC
期望达到的效果(Evaluation):
H1
L1
CNN
0.54
有信号?无信号?
# GW: DL
CNN
0.54
有信号?无信号?
分类模型泛化性能评估:混淆矩阵/ROC/AUC
H1
L1
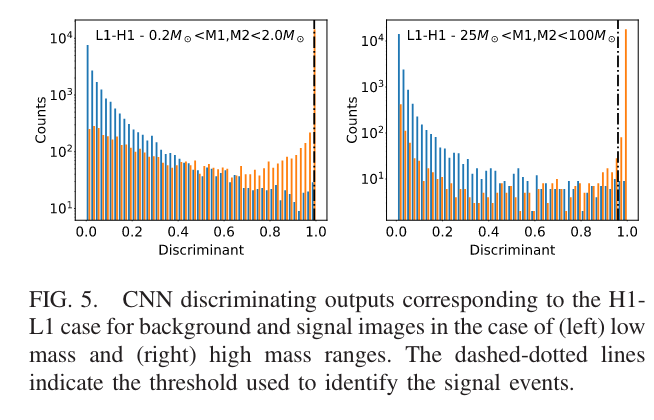
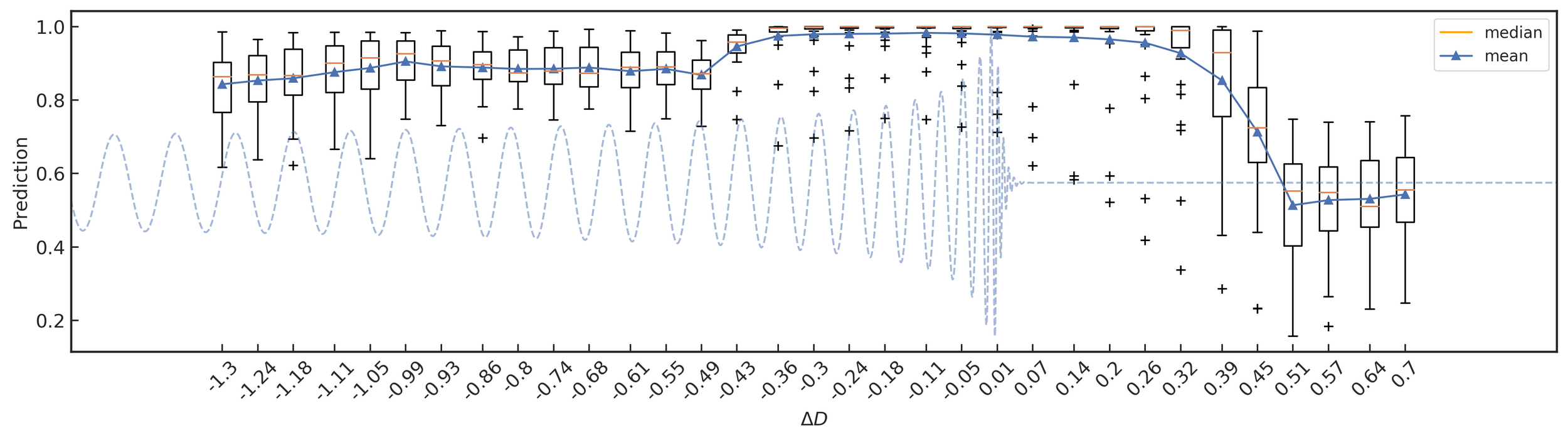
threshold = 0.5,这里有引力波信号!
threshold = 0.6,这里没有引力波信号!
# GW: DL
CNN
0.54
有信号?无信号?
分类模型泛化性能评估:混淆矩阵/ROC/AUC
H1
L1
threshold = 0.5,这里有引力波信号!
threshold = 0.6,这里没有引力波信号!
# GW: DL
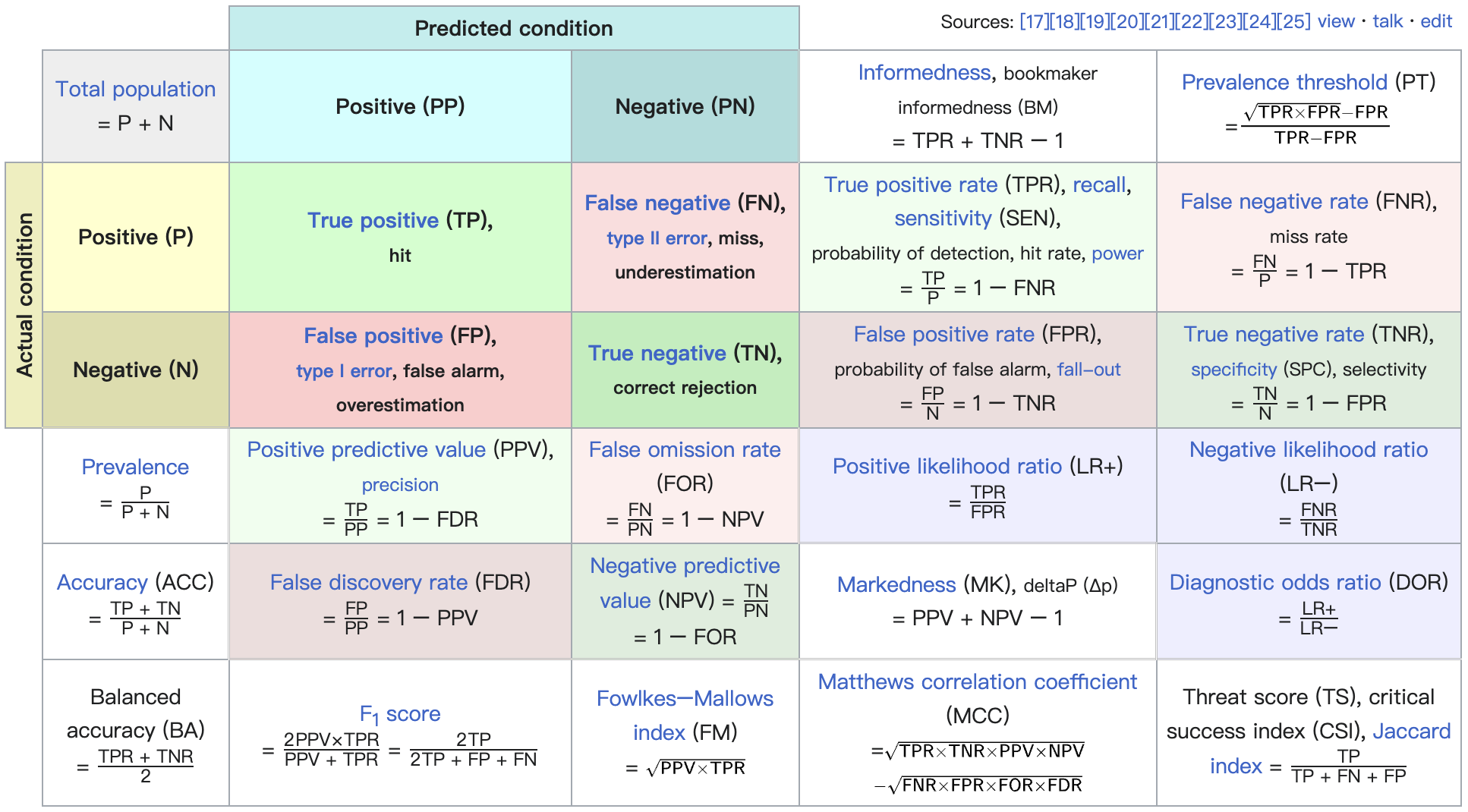
| 真实情况 | 正例(预测结果) | 反例(预测结果) |
|---|---|---|
| 正例 | TP (真正例) | FN (假反例) |
| 反例 | FP (假正例) | TN (真反例) |
arXiv: 2302.00666
# GW: DL
| 真实情况 | 正例(预测结果) | 反例(预测结果) |
|---|---|---|
| 正例 | TP (真正例) | FN (假反例) |
| 反例 | FP (假正例) | TN (真反例) |
arXiv: 2302.00666
Source: Wiki-en
# GW: DL
Source: Wiki-en
# GW: DL
Source: Wiki-en
# GW: DL
Source: Wiki-en
# GW: DL
很多其实很重要但没能讲到的内容:
# GW: DL
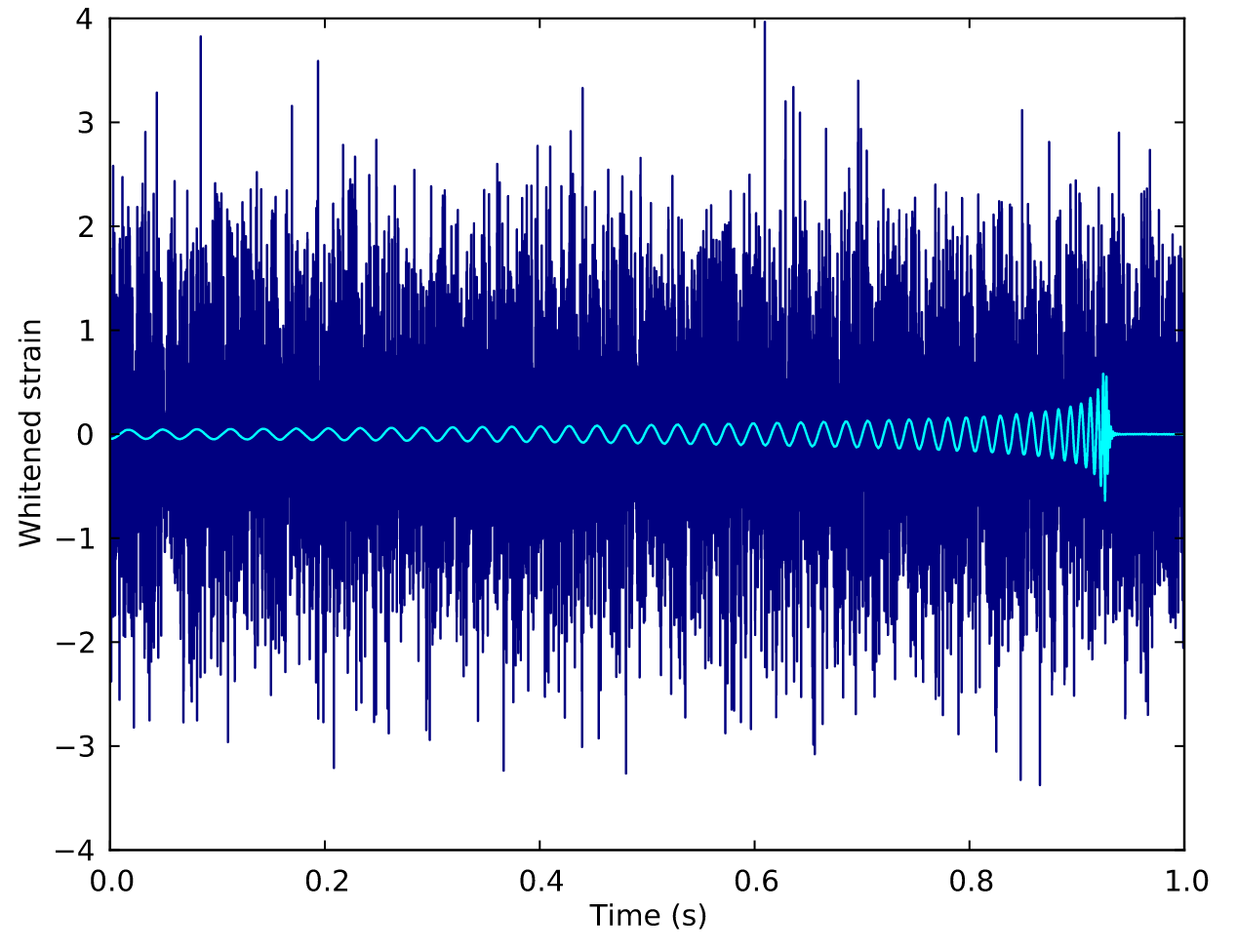
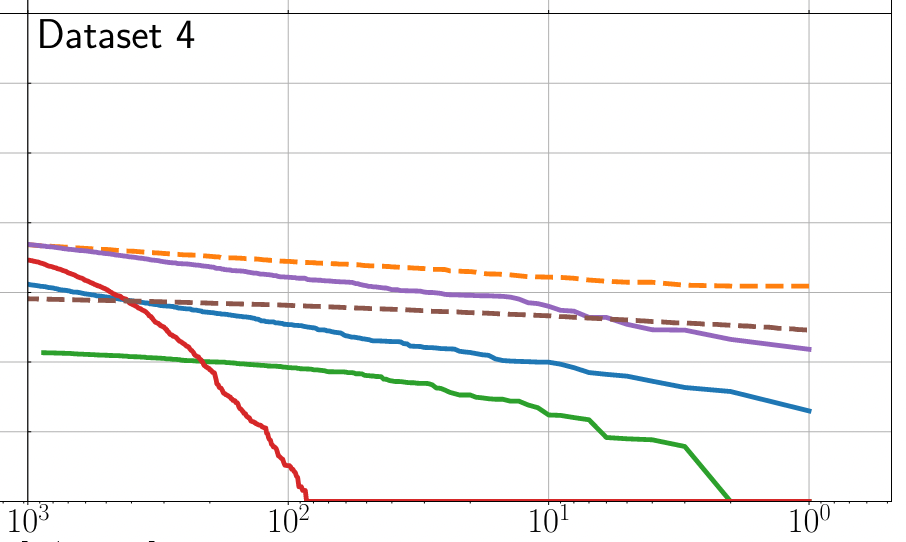
Can you find the GW signals?
# GW: DL
数据科学挑战:引力波信号搜寻
Home: https://www.kaggle.com/competitions/2023-gwdata-bootcamp
本竞赛将于北京时间 2023年12月29日22:00 开始,并于北京时间 2024年1月5日23:59 结束。
请确保在截止日期前提交你的解决方案。
# Homework
Repo of the course: https://github.com/iphysresearch/GWData-Bootcamp
通向自我实现之路:Kaggle
By He Wang
引力波数据探索:编程与分析实战训练营。课程网址:https://github.com/iphysresearch/GWData-Bootcamp




