A weekend of Analytic(s) Hacking in MongoDB
-- or --
Cultural Learnings of Mongodbia for Make Benefit Glorious Nation of Analytics Computation

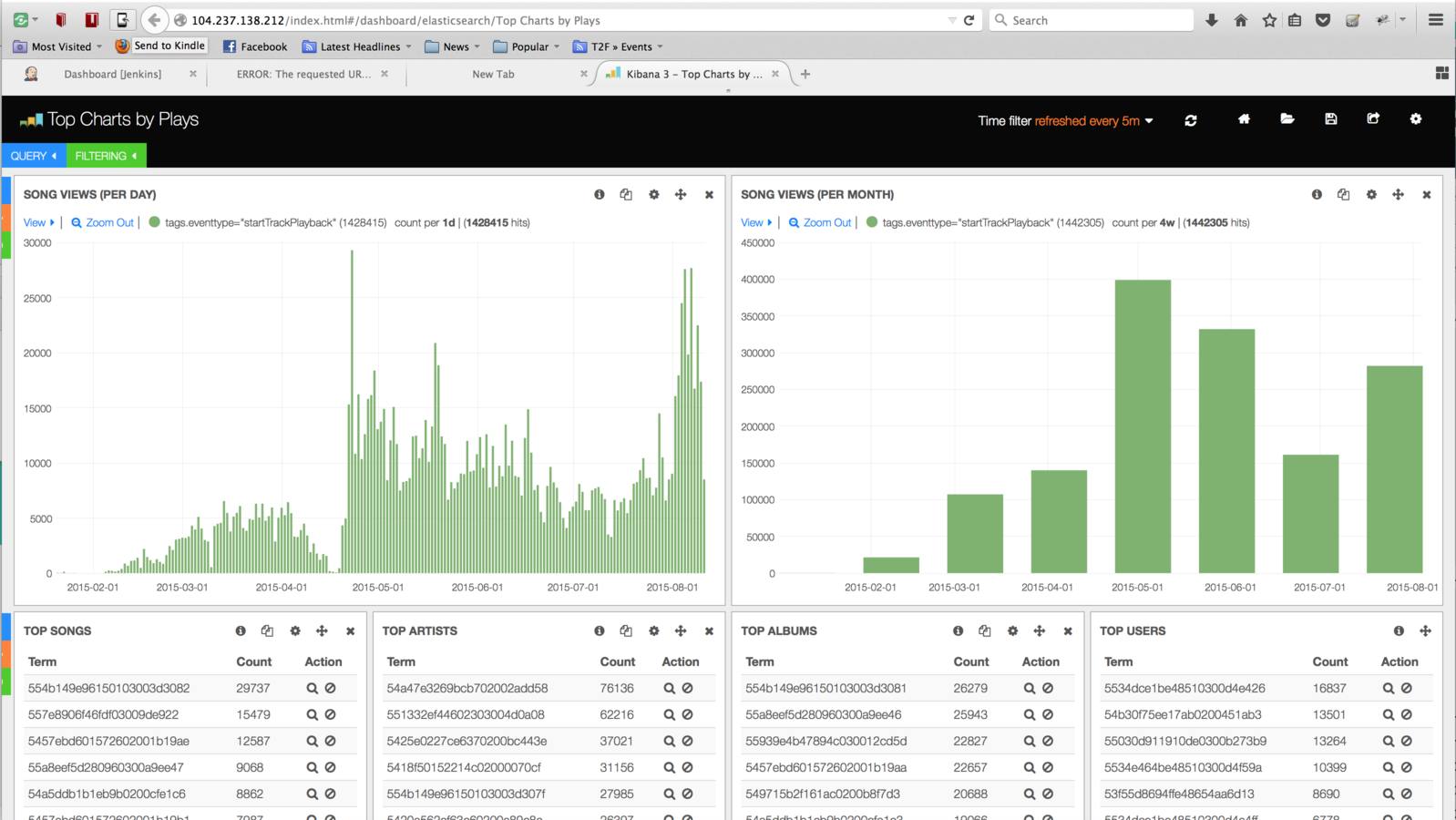
System A: ELK
Pros
- Aggregates Any Sort of structured Data
- Filters based upon any sort of criteria
- Panels provide great WYSIWYG
- Scalability is simple, configuration based.
- Personally benchmarked to a hundreds events per second via test suite.
- Out of the Box solution.
Cons/Whatifs
- Repeatability: What if I want to recompute a certain subset of my data. (Music / Agreements)
- ES does not promise to be a reliable data store
- LS agents transmit via UDP
- Moving parts. Different things can go down. Network packets can drop, etc
Pros(Cont)
Cons(Cont)
- Moving parts. Different things can go down. Network packets can drop, etc
Protocols

Protocols
- Binary Protocols: MySQL Client/Server Protocol
- Binary Protocols(Cont): JNI, RMI
- Binary Protocols(Cont): Basic Socket connections, Thrift, Google Protocol Buffers,
- HTTP Based: Rest, Soap
- Websockets
- File IO
{
"tags": {
"album": "5403b0c2f5f5680200b45d89",
"song": "5403b0c2f5f5680200b45d91",
"locatorname": null,
"eventtype": "startTrackPlayback",
"artist": "5403b0c2f5f5680200b45d87",
"locatortype": "buttonClick",
"user": null,
"device": "windows-unknown",
"browser": "chrome"
},
"timestamp": 1427223676.554661,
"host": "localhost",
"message": null,
"time_taken": null,
"client": "UNKNOWN",
"exc_info": null,
"logger": "analytic",
"type": "realtime_api",
"levelname": "INFO"
}Data now
- Goes to a file instead of a Network Connection.
- Conformed JSON standard is http://jsonlines.org/
- This serves as an interface.
- Logstash has a plugin that can read JSON lines.
- System A is happy.
- My process has all it takes to be repeatable.
- I'm not a slave to my technology. I know file IO works liked it has worked for my forefathers. Files can be rotated and rsyncs also work
Requirements
- Events: plays, favorites, etc
- Reporting granularity: day, month, year, week, alltime
- Concepts: Song, Artists, Albums, Labels
- TopN & Time Series
All hail Mongodb
Assumptions

Collections
- stats_counters
- stats_counters_week
- stats_counters_month
- stats_counters_year
- stats_counters_alltime
- Granularity: (Day, Week, Month, Year, All)
- Criteria: (Song, Album, Label, Artist, User)
{
"_id": ObjectId("55942e2a1a704cc8c3151b90"),
"criteria": "user",
"criteria_value": "5534dce2be48510300d4e5f0",
"day": 5,
"event": "playlistSavePopupOpen",
"label": "123",
"month": 5,
"year": 2015,
"counter": 32,
"ymd": 20150505
}This ...
def stash_aggregation(song_record)
# / / / / / / / / / / / / / /
# \ \ \ In case you're wondering this is a zip line \ \ \
# / / / / / / / / / / / / / /
for criteria in ('album', 'label', 'artist'):
search_criteria = ({'criteria': inner_criteria_value, 'event': event, 'ymd': ymd})
counter_object = db.stats_counters.find_one(search_criteria)
if counter_object is None:
inserted_id = db.stats_counters.insert({"year": year, "month": month, "day": day, "label": label,\
"ymd": ymd,
"criteria": criteria, "criteria_value": inner_criteria_value,\
"event": event, "counter": 0})
else:
inserted_id = counter_object['_id']
db.stats_counters.update({"_id":inserted_id},{"$inc": {"counter": counter}})
(iso_year, iso_week, iso_day) = datetime.date(year, month, day).isocalendar()
ingest_week(year, iso_week, event, counter, song_id, song_label, song_album, song_artist)
ingest_month(year, month, event, counter, song_id, song_label, song_album, song_artist)
ingest_year(year, event, counter, song_id, song_label, song_album, song_artist)
ingest_alltime(event, counter, song_id, song_label, song_album, song_artist)And more ...
def ingest_week(year, iso_week, event, counter, song, song_label, song_album, song_artist):
search_criteria = ({'event': event, 'year': year, 'iso_week': iso_week})
for (criteria, value) in (('song', song), ('album', song_album), ('label', song_label), ('artist', song_artist)):
search_criteria["criteria"] = criteria
search_criteria["criteria_value"] = value
counter_object = db.stats_counters_week.find_one(search_criteria)
if counter_object is None:
insertion_object = dict(search_criteria)
insertion_object["counter"] = 0
inserted_id = db.stats_counters_week.insert(insertion_object)
else:
inserted_id = counter_object['_id']
db.stats_counters_week.update({"_id":inserted_id},{"$inc": {"counter": counter}})
Per event
- 5 (Day, Week, Month, Year, All)
- 4 (Song, Album, Label, Artist)
- 20 inserts per event
The Results
- Performance is so bad that I didn't have the patience to measure it.

Google Knows
- Mongodb is Constrained to 1 Core per connection, so the client should be threaded.
- Python driver sucks

You want to borrow your neighbours hose so you can wash your car. But you remember that last week, you broke their rake, so you need to go to the hardware store to buy a new one. But that means driving to the hardware store, so you have to look for your keys. You eventually find your keys inside a tear in a cushion - but you can’t leave the cushion torn, because the dog will destroy the cushion if they find a little tear. The cushion needs a little more stuffing before it can be repaired, but it’s a special cushion filled with exotic Tibetan yak hair.
The next thing you know, you’re standing on a hillside in Tibet shaving a yak. And all you wanted to do was wash your car.
Assumptions v2.0
- C is fast
- Hence a C program that implements the above logic will be faster.
Assumptions v3.0
- C is fast
- Mongodb's native import utilities must be blazingly fast.
- Hence a C program that spits inserts queries to a file that can be imported via
mongoimport --db dbname --collection colname --type json --file fname
File Writing
Not as fast as anticipated but still notable speedup.
mongoimport
- Parse Error Failure.
- Aha... Its because my file is large. I need to use
-jsonArray.
- But now this is too slow.
- Linux split command into roughly 1MB chunks. I've hundreds of files with no way of monitoring progress.
ingest_week(year, iso_week, event, counter, song_id, song_label, song_album, song_artist)
ingest_month(year, month, event, counter, song_id, song_label, song_album, song_artist)
ingest_year(year, event, counter, song_id, song_label, song_album, song_artist)
ingest_alltime(event, counter, song_id, song_label, song_album, song_artist)Easy Wins anyone?
Lets use the aggregation framework for these.
And also for these
for criteria in ("album", "artist", "label"):
# ...
passThis is what an aggregation looks like
aggregation_result = db.stats_counters.aggregate([
{"$match": {"event": event, "criteria": criteria, "valid": true}},
{"$match": {"ymd": { "$gte": ymd_from, "$lte": ymd_to},
{"$group":{"_id":"$criteria_value", "sum":{"$sum":"$counter"}}}
])
for result in aggregation_result['result']:
#print repr(result)
insertion_object = {"counter" : result['sum'], "criteria" : criteria, \
"criteria_value" : aggregation_result['result'][0]["_id"], "event" : event, \
"year" : year, "week": week, "label": "None"}
inserted_id = db.stats_counters_week.insert(insertion_object)- Almost 20x speedup. (For this part of the code)
- Everything is fast. 6 hours for 100K records.
- But why do inserts suck so bad
- Maybe its a ...

counter_object = db.stats_counters.find_one(search_criteria)
inserted_id = None
if counter_object is None:
inserted_id = db.stats_counters.insert({"year": year, "month": month, "day": day, "label": None,\
"ymd": int("%02d%02d%02d"%(year, month, day)),\
"criteria": criteria, "criteria_value": criteria_value,\
"event": event, "counter": 0, "valid": True, "counter": count})
else:
inserted_id = counter_object['_id']db.stats_counters.update({
'event': '%s', 'criteria':'%s', 'criteria_value': '%s', 'ymd': %s},
{ $set: {'year': %s,
'month': %s,
'day': %s,
'label': '%s'
},
$inc: {'counter': %s}
},
{upsert:true})Changing This
To This
Viola
30 Minutes
Code Sober & RTFM
Now I can process 100K events in half an hour, which is a days worth of data. Its good, but if I discover a bug and want to recompute 90 days worth of data ~= 2 days.
All Hail Pandas?

"""
A data frame is a table, or two-dimensional array-like structure,\
in which each column contains measurements on one variable, and each row contains one case.
Data frames are implemented natively have a minimal memory footprint and are blazing fast
Below is a dataframe containing #event_type,user,song,artist,album,date
"""
df = pd.DataFrame() #Containing
"""
Code to store the aggregation results into mongo
"""
for criteria in ('song', 'artist', 'album'):
checkpoint = time.time()
event_counts = df.groupby(['$event', '$' + criteria])['$' + criteria].agg(['count'])
checkpoint = time.time()
for row in event_counts.iterrows():
event = row[0][0]
criteria_value = row[0][1]
count = int(row[1])
insert_into_mongo(event, criteria, criteria_value, count, date_list)
Time For the process
5 Seconds
Without delving into the UI side of things

TLDR
- No one tool does everything.
- Mongo aggregations are used for reporting from the precomputed results on the display layer.
Questions?
http://slides.com/iqbaltalaatbhatti/mo#/
About Me
https://twitter.com/iqqi84
https://au.linkedin.com/pub/iqbal-bhatti/14/63/493
CTO & Cofounder Patari[Pakistans largest Music Streaming Portal]
iqbal@patari.pk
CTO Active Capital IT[Software Consultancy working with Cataloging, Artwork & Telecom Sectors]
italaat@acit.com
A weekend of Analytics Hacking in Mongodb
By Iqbal Talaat Bhatti
A weekend of Analytics Hacking in Mongodb
Talk first given on the Sydney Mongodb Users Group on 25th August 2015.



