今流行りの Ring Buffer とその罠
石 立行 (@ishitatsuyuki)
@ishitatsuyuki
東京大学 理学部情報科学科 3年
低レイヤーでどうでも良さそうな問題を
一生懸命考えるのが好きです
今日もどうでも良さそうな問題を見ていきます
Ring Buffer は、 First-In First-Out の Queue を実現するデータ構造
今回は、Single-Producer Single-Consumerのユースケースに着目します
(1スレッドが書き込み、1スレッドが読み出し)
近年、Spectre の Mitigation で
コンテキストスイッチのコストが爆上がりしている
アイデア: Consumer (e.g. Userland) と
Producer (e.g. Kernel) を
別々のスレッドにすれば、
コンテキストを同時に2つ持てる
Ring Buffer のコンテキストスイッチへの応用
- virtio (2008)
- Guest Kernel → Host Kernel → Host Guest と必要だった遷移を、Ring Buffer により回避
- io_uring (2019)
- syscall を場合によってはコンテキストスイッチ不要に
- perf ring buffer, bpf ringbuf
- Kernel からのトレースデータを高速に Userspace に渡す
よくある Ring Buffer の実装
void push(int val) {
int write_ = atomic_load(write, relaxed);
// handle buffer full...
data[write_ % LEN] = val;
atomic_store(write, write_ + 1, release);
}
void pop(int *out) {
int read_ = atomic_load(read, relaxed);
// handle buffer empty
int write_ = atomic_load(write, acquire);
if (read_ == write_) blocking_wait();
*out = data[read_ % LEN];
atomic_store(read, read_ + 1, release);
}Acquire-Release anomaly
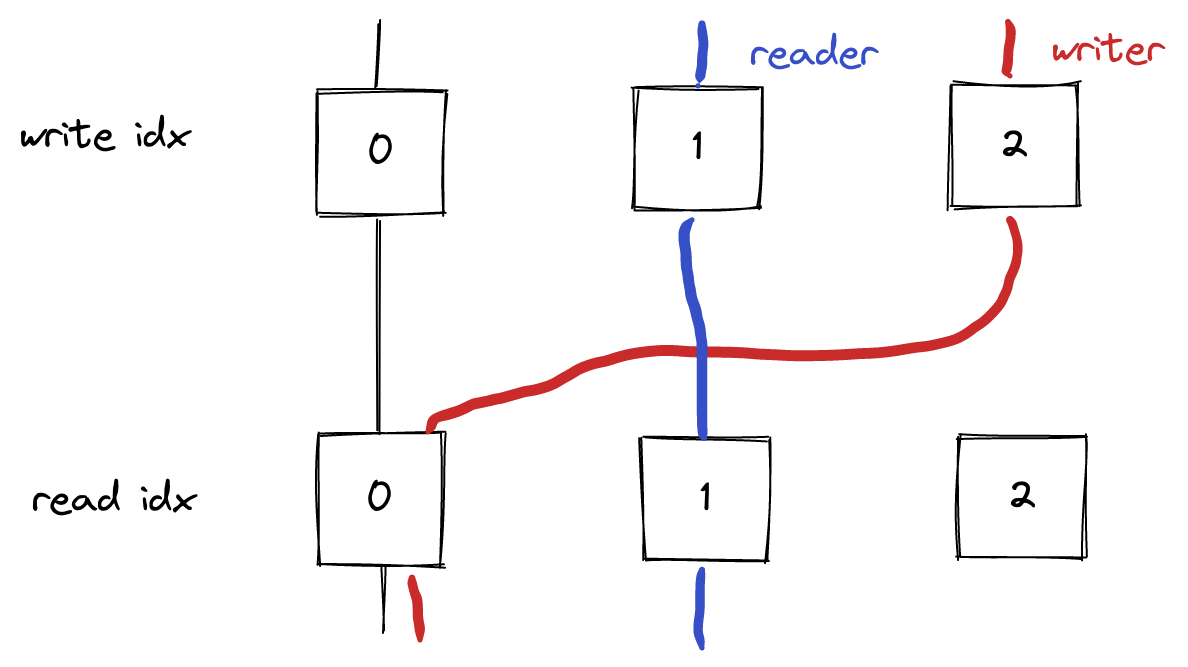
なぜ、Anomaly が起こるのか
x86 では原則として、メモリ操作は順番通りに実行されることが保証される
Read-after-Write
RAW を禁止すると、強力なハードウェア最適化である Store Forwarding が行えない
自スレッドで Write が実行されたように見えても、他スレッドからは見えているとは限らない
例外:
事情:
結果:
解決策1
スリープしない
他スレッドの書き込みは、スピンしていれば「いつか」読み出せる
問題: 不要なリソース消費
解決策2
SeqCst
relaxed, acquire を seq_cst に置き換え
C++標準では total order を保証する
→ Write が lock xchg になり、完了してから次の Read が行われる
問題: 30倍も遅くなる
300Mops/s → 10Mops/s
解決策3
OS にどうにかしてもらう
プロセッサ間割り込みを使って、他 CPU の
実行を中断して書き込みを吐き出させる
Linux: membarrier()
Windows: FlushProcessWriteBuffers()
問題: Not Portable
一応内部実装を仮定して同じ機能を実現する術はある
参考
今流行りの Ring Buffer とその罠
By Tatsuyuki Ishi


