Exploring Corporate Digital Footprints: NLP Insights fromWebSweep's
High-Speed Web Scraping
Peter Gerbrands
Javier Garcia-Bernardo
KvK: Annual Reports (PDF)
FBB: Extract Financial Info
KvK: Company Information
SIDN: ".nl"
Registrations
WebSweep:
Scrape websites
FBB: Site text and extra info
LISA:
Employment
FBB: Linked Data "Backbone"
BIG
PICTURE
WebSweep
Consolidates, for each base URL, the information of different pages
A User-Friendly and High-Speed Web Scraping Library
For each base URL, clicks and downloads up to 100 pages in parallel (1 second wait for each request per domain)
Output: HTML pages of each base URL
Input: List of base URLs
Crawler
Extract
Consolidate
For each page (HTML), extracts key information (clean text, identifiers, etc)
Modular


Example code (as a library)
Example code (as CLI)

Other features:
- Decide which pages to download based on the url
- Retry failed downloads in different ways
- Extract and crawl at the same time (avoid saving HTML files)
- Respects robots.txt (legal)
- Allows to add address of IP and host (but too slow)
Limitations:
- Performance declines with 50,000+ domains (~1M pages)
- Only HTTPS, no JavaScript, no PDFs (yet)
1. Scrape corporate websites at regular times:
- ~2,000,000 .nl domains (from SIDN), each with dozens of pages
- Find and scrape URLs of Dutch websites outside of the .nl domain
2. Extract useful information
3. Link it to KvK data
Scraping goals of FIRMBACKBONE
Today:
- Performance/statistics on sample: 80,000 domains
- Three potential applications:
- Query database through keywords
- Query database through Large Language Models
- Clustering companies using Large Language Models
Performance
(on a sample)
Statistics: errors
80,000 domains (364,426 pages) downloaded in ~18 hours
~20,000 pages/hour = 5 pages/second
Domain level
3% retried and corrected (automatically)
40% broken domains (or not secure)
20% problems with scraper (could be complemented)
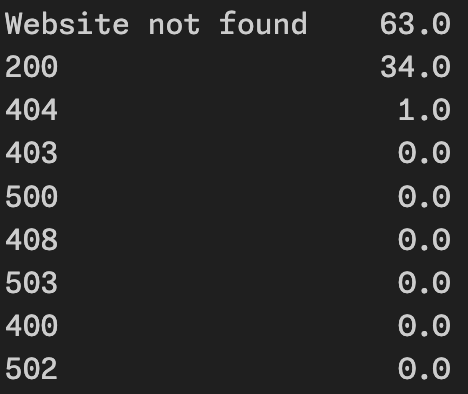
6% retried and corrected (automatically)
1% broken links (or not secure)
4.5% problems with scraper (could be complemented)
Page level (of sucessful domains)
Statistics: errors

Statistics: performance
Personal computer (limited by Internet)



Server (disk may not be fast enough)

Data:
Out of the 28,671 domains :
- 25,582 had more than 100 characters. Of those:
- 6,257 had a KvK number --> We could match directly to KvK data
- 5,361 matched on primary postcode
- And additional 12,089 had some address --> Could be matched
- 7,236 had no of little additional data
- Many sites do not have any contact info (apart from email/form)
- Many sites are down and have a standard error message
- Some important pages were not downloaded by the scraper
- 6,257 had a KvK number --> We could match directly to KvK data
Statistics: matching to companies
SIDN comparison:
Out of the 28,671 domains downloaded, 5,831 were linked to a KvK number in the original data (SIDN). Of those:
- Found matching KvK number by WebSweep: 3,898 pages
- Different KvK number found: 100 pages
- No KvK number found: 1,833. From a hand label of a small sample:
- 1/3 of domains did not show the KvK
- 1/3 wrote the KvK number only in PDFs
- 1/3 had other problems (weird technologies, zero-width spaces)
KvK number only in the scraped data: 2,359 domains
Statistics: matching to companies
Example Analyses
Querying FIRMBACKBONE database
Imagine you are interested in companies dealing with horses
You want to test if climate change is having an impact in the companies raising horses
You could check KvK data by sectors, but:
- Sectors can be coarse:
- Agriculture 01.49: "Other animal production".
- Recreation Code 93.19: "Other sports activities"
- Companies are often involved in several sectors, and owned by financial companies
Solution: We could find horse companies by their website, and link to KvK data for analysis

Approach 1: Querying using keywords

Convert each website to a vector:
- Elements in the vector = Words
- Weight of the words = TF-IDF
- TF: Term frequency: how often the word appears
- IDF: Inverse document frequency: how widespread the word is
Keywords: Words with the highest weight
Horse domains:


Approach 2: Querying using LLM
Convert each website to a vector:
- Vector = Embedding created by a large language model (in this case S-BERT multilingual)
Similar vectors = similar meaning in the text

Approach 2: Querying using LLM

Instead of querying by the presence of keywords, we can query by meaning
query = "Websites die sushi verkopen bieden een scala aan Japanse delicatessen, waaronder diverse soorten sushi, zoals nigiri, maki en sashimi."
We can:
- Convert query to vector using the same model
- Find nearest neighbors to that vector

Clustering websites
- Retrieve n closest to description

We have vectors for each website --> We can use them for clustering (maybe eventually to create our own sectors).
2D projection using PaCMAP and clusters
Keywords extracted using cTF-IDF
WebSweep needs some adjustments:
- Tweak concurrency to avoid errors
- Websites are very diverse
Interested in using/contributing to WebSweep? Send an email: javier.gbe@pm.me
Scraped data connected to financial data holds great potential:
- Find companies to analyze:
- Sectors that are not well-defined
- Analyze specific companies (e.g. large-companies in energy owned by states)
- How corporations display themselves to the public: framing
- Track topics over time
- Test the impact of policy
- Detecting innovation
- ...
Conclusions
- Finding URL of companies:
- Which browser works better?
- Small test with 1,287 URLS:
- 566 same url in Orbis, DDG and SIDN
- 239 different url in all sources
- 222 same in Orbis and DDG, different in SIDN
- 135 same in Orbis and SIDN, different in SIDN
- 125 same in SIDN and DDG, different in Orbis
- We then scraped all websites to see which method shows the highest correlation between kvk reported and kvk in website.
- DDG match KvK on 54% --> only using name!
- Orbis match KvK on 61% --> kvk/website reported by company
- SIDN match KvK on 70% --> kvk/website reported by company
General: Which source to trust? e.g., 1/3 of websites have different postcodes than those in Orbis/KvK
Potential discussion points
-
Redirects and URL changes:
- Follow the redirect and link to previous?
- How to detect if it's the same company?
- What features are useful for research?
- What would be useful for FIRMBACKBONE
- Keep HTML, cleaned text, or just features?
- Representation: How do we make sure we got all the websites linked to horses/sushi, etc
Potential discussion points
backbone
By Javier GB




