








Karl Ho
Data Generation datageneration.io
Karl Ho
School of Economic, Political and Policy Sciences
University of Texas at Dallas
Not the salary
Part One Relational Languages
Part Two Database Design
Part Three Application Design and Development
Part Four Big Data Analytics
Part Five Storage Management and Indexing
Part Six Query Processing and Optimization
Part Seven Transaction Management
Part Eight Parallel and Distributed Databases
Part Nine Advanced Topics
Part Ten Appendix A
Part Eleven Online Chapters
Part One Relational Languages
Part Two Database Design
Part Three Application Design and Development
Part Four Big Data Analytics
Part Five Storage Management and Indexing
Part Six Query Processing and Optimization
Part Seven Transaction Management
Part Eight Parallel and Distributed Databases
Part Nine Advanced Topics
Part Ten Appendix A
Part Eleven Online Chapters
Part One Relational Languages
Part Two Database Design
Part Three Application Design and Development
Part Four Big Data Analytics
Part Five Storage Management and Indexing
Part Six Query Processing and Optimization
Part Seven Transaction Management
Part Eight Parallel and Distributed Databases
Part Nine Advanced Topics
Part Ten Appendix A
Part Eleven Online Chapters
Part One Relational Languages
Part Two Database Design
Part Three Application Design and Development
Part Four Big Data Analytics
Part Five Storage Management and Indexing
Part Six Query Processing and Optimization
Part Seven Transaction Management
Part Eight Parallel and Distributed Databases
Part Nine Advanced Topics
Part Ten Appendix A
Part Eleven Online Chapters
Part One Relational Languages
Part Two Database Design
Part Three Application Design and Development
Part Four Big Data Analytics
Part Five Storage Management and Indexing
Part Six Query Processing and Optimization
Part Seven Transaction Management
Part Eight Parallel and Distributed Databases
Part Nine Advanced Topics
Part Ten Appendix A
Part Eleven Online Chapters
Part One Relational Languages
Part Two Database Design
Part Three Application Design and Development
Part Four Big Data Analytics
Part Five Storage Management and Indexing
Part Six Query Processing and Optimization
Part Seven Transaction Management
Part Eight Parallel and Distributed Databases
Part Nine Advanced Topics
Part Ten Appendix A
Part Eleven Online Chapters
| Topic | Reading |
|---|---|
| Introduction | IF 1, 4 |
| Relational Languages | SKS 1, 2 |
| SQL I | SKS 3, 4 |
| SQL II | SKS 5 |
| ERM and Relational Database Design | SKS 6, 7 |
| Complex Data Types | SKS 8 |
| Application Design | SKS 9 |
| Big Data | SKS 10; IF 5 |
| Data Analytics | SKS 11 |
| Query Processing | SKS 15 |
| Database-System Architectures | SKS 20 |
| Parallel and Distributed Systems | SKS 21-22 |
| Blockchain Databases | SKS 26 |
| New Developments in Data/Information systems | SKS 28, 29, 30, 32; Beckman reports 2013, 2016 |
| Topic | Reading |
|---|---|
| Introduction | IF 1, 4 |
| Relational Languages | SKS 1, 2 |
| SQL I | SKS 3, 4 |
| SQL II | SKS 5 |
| ERM and Relational Database Design | SKS 6, 7 |
| Complex Data Types | SKS 8 |
| Application Design | SKS 9 |
| Big Data | SKS 10; IF 5 |
| Data Analytics | SKS 11 |
| Query Processing | SKS 15 |
| Database-System Architectures | SKS 20 |
| Parallel and Distributed Systems | SKS 21-22 |
| Blockchain Databases | SKS 26 |
| New Developments in Data/Information systems | SKS 28, 29, 30, 32; Beckman reports 2013, 2016 |
INTeger
NUMeric
Factor
CHARacter
TRUE/FALSE
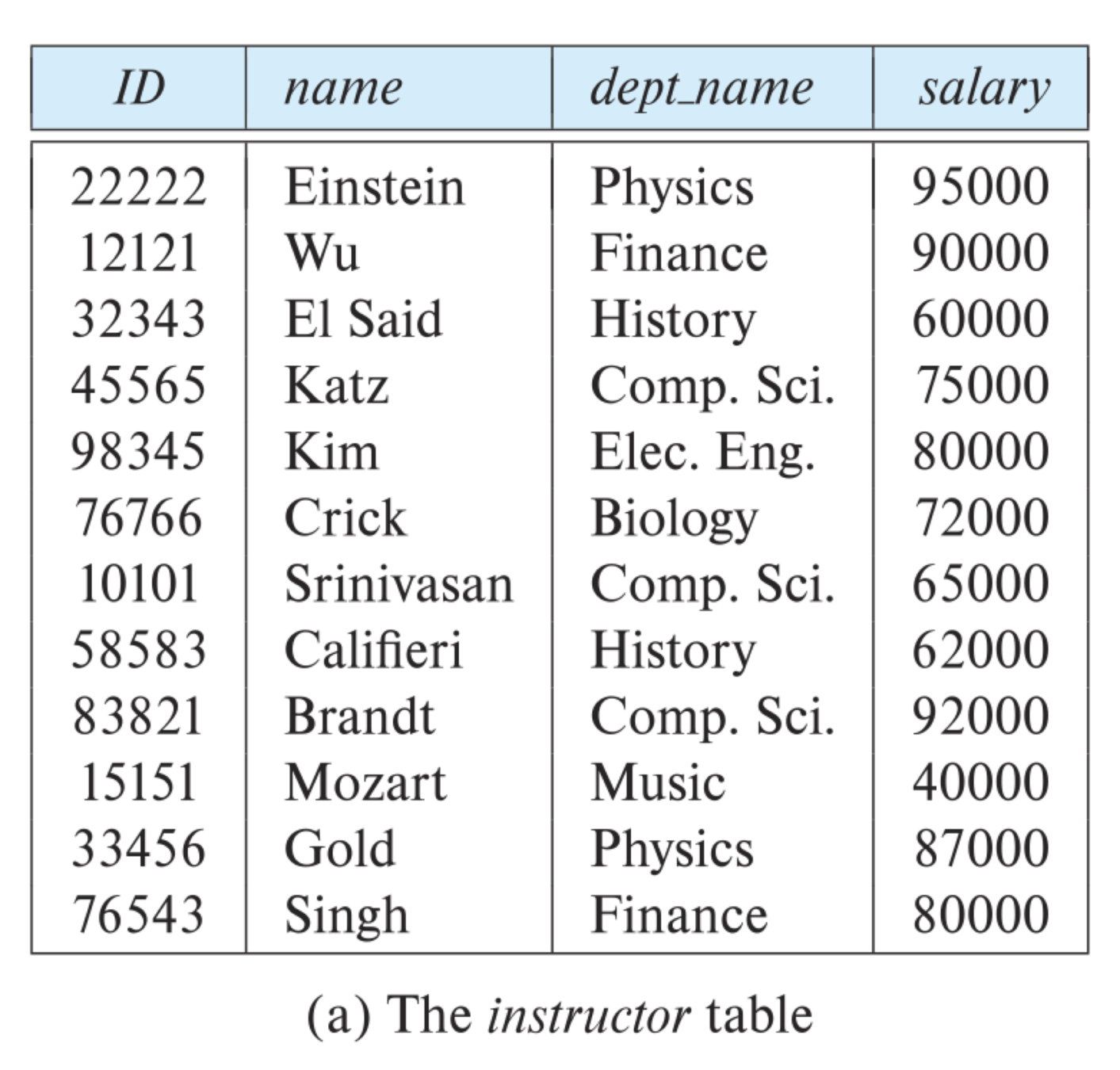
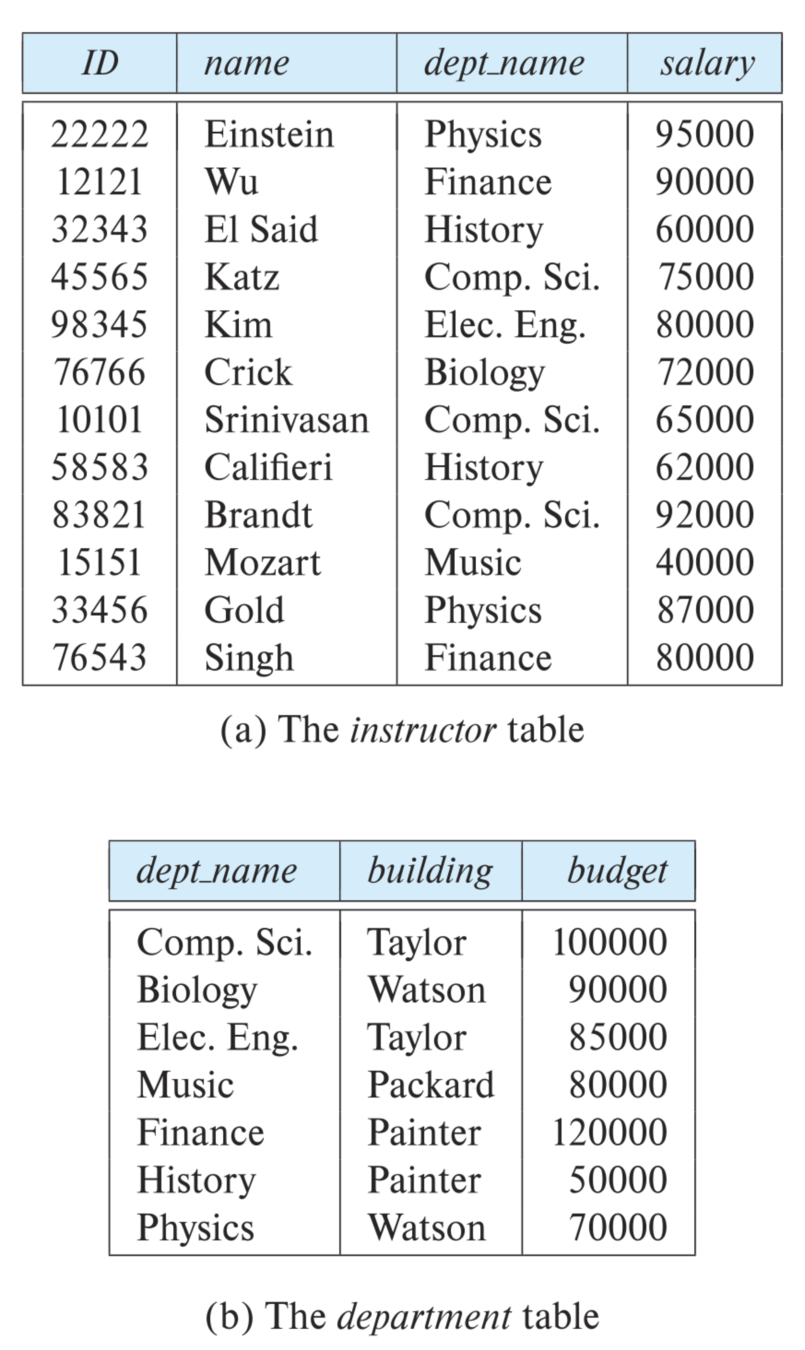
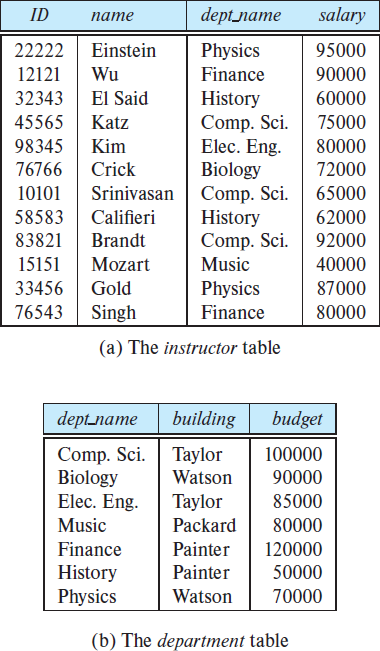
The university database example will be used to illustrate all the concepts.
Edgar (Ted) Frank Codd defines the relational data model
IBM Research begins System R prototype
UC Berkeley (Michael Stonebraker) begins Ingres prototype
Oracle releases first commercial relational database
High-performance (for the era) transaction processing
- Michael Stonebraker
https://history.computer.org/pioneers/codd.html
Non-nested tables
Ingress means: a place or means of access, an entrance. POSTGRES, that is the successor to the INGRES relational database system.
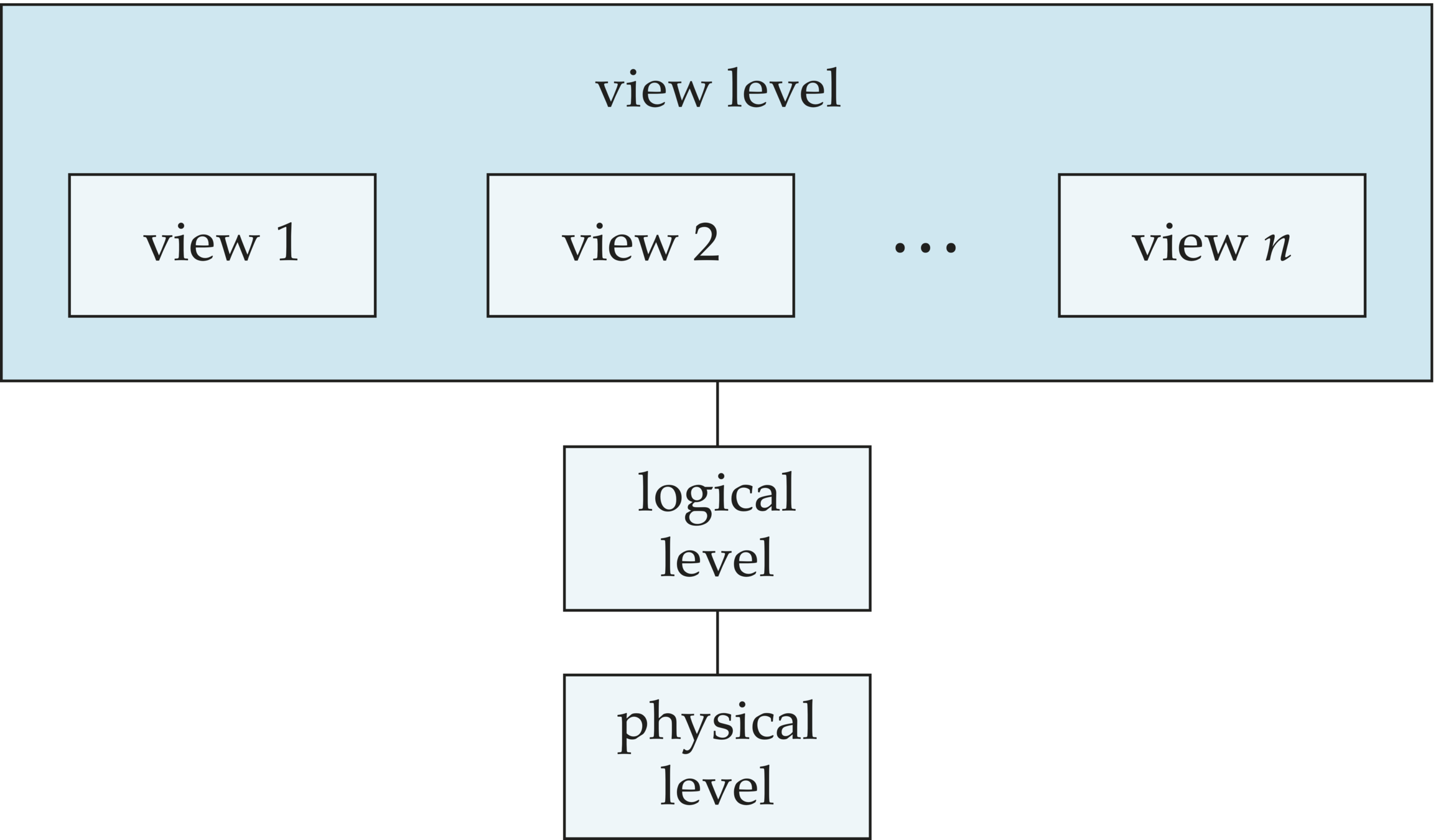
A major purpose of a database system is to provide users with an abstract view of the data
Data models
A collection of conceptual tools for describing data, data relationships, data semantics, and consistency constraints.
Data abstraction
Hide the complexity of data structures to represent data in the database from users through several levels of data abstraction.
SKS, p. 10
Physical level: describes how a record is stored.
Logical level: describes data stored in database, and the relationships among the data.
View level: Views can hide information (such as person's ID) for security purposes.
In developing a data model, we commonly first identify the entities that are to be modeled and then define their properties and relationships.
For example, the entities include individuals, institutions, parties, each of which has various properties (e.g., for individuals, name, address, employer)
The relationships include “is employed by” and “support” This conceptual data model can then be translated into relational tables or some other database representation.
https://www.databankimx.com/
https://history.nasa.gov/computers/Ch8-2.html
Data redundancy and inconsistency:
data is stored in multiple file formats resulting in duplication of information in different files
Difficulty in accessing data
Need to write a new program to carry out each new task
Data isolation
Multiple files and formats
Integrity problems
Integrity constraints (e.g., account balance > 0) become “buried” in program code rather than being stated explicitly
Hard to add new constraints or change existing ones
Atomicity of updates
Failures may leave database in an inconsistent state with partial updates carried out
Example: Transfer of funds from one account to another should either complete or not happen at all
Atomicity:
The process must happen in its entirety or not at all.
e.g. fund transfer from one account to the other account
Concurrent access by multiple users
Concurrent access needed for performance
Uncontrolled concurrent accesses can lead to inconsistencies
E.g. Two people reading a balance (say 100) and updating it by withdrawing money (say 50 each) at the same time
Security problems
Hard to provide user access to some, but not all, data
Foster et al. 2016, p. 97
Foster et al. 2016, p. 97
Foster et al. 2016, p. 99
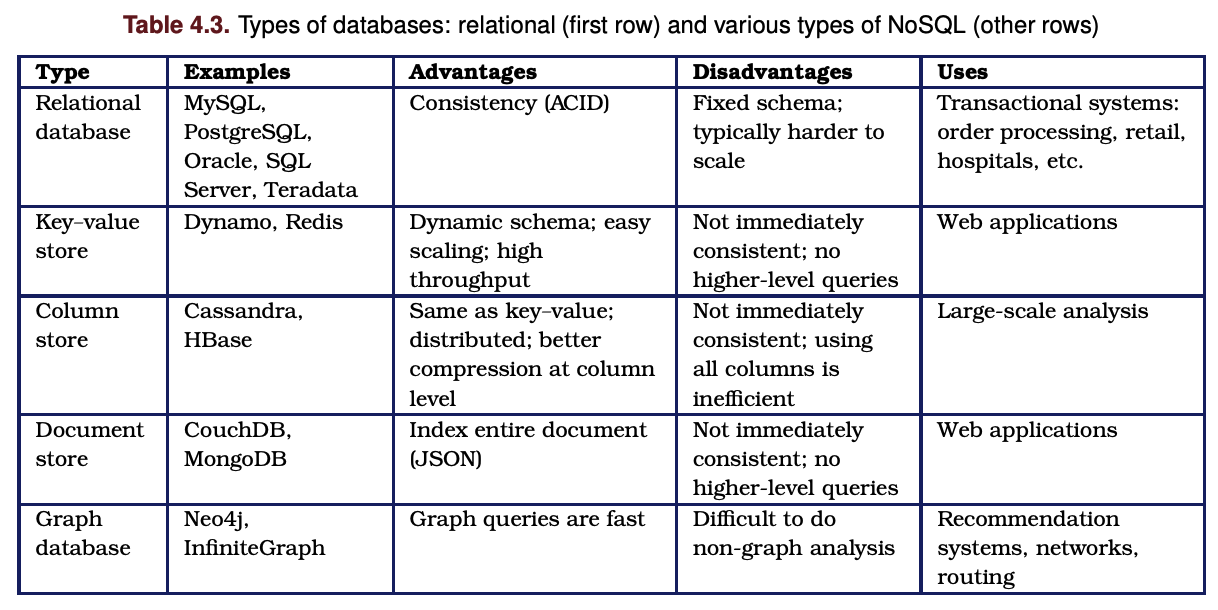
ACID: Atomicity, Consistency, Isolation, Durability
Foster et al. 2016, p. 100
SKS, p. 9
SKS, p. 689
SKS, p. 689
Query processing refers to the range of activities involved in extracting data from a database including:
Steps in query processing:
By Karl Ho
Information Management: Introduction



