
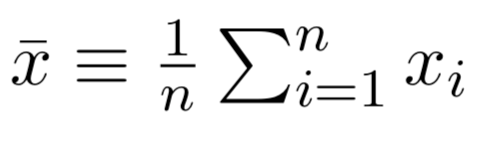
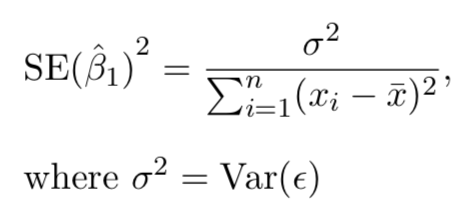
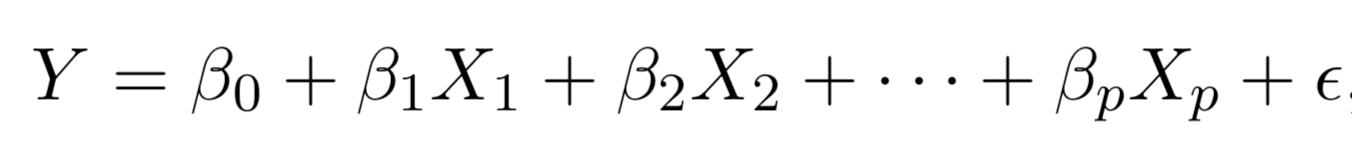
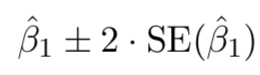

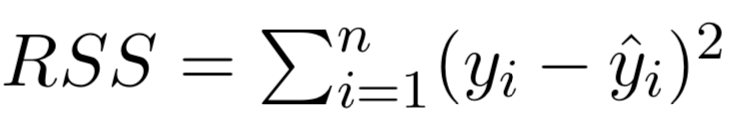
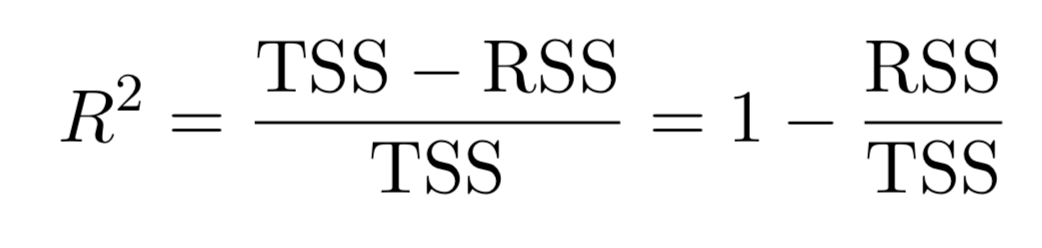
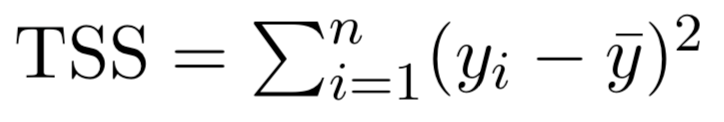



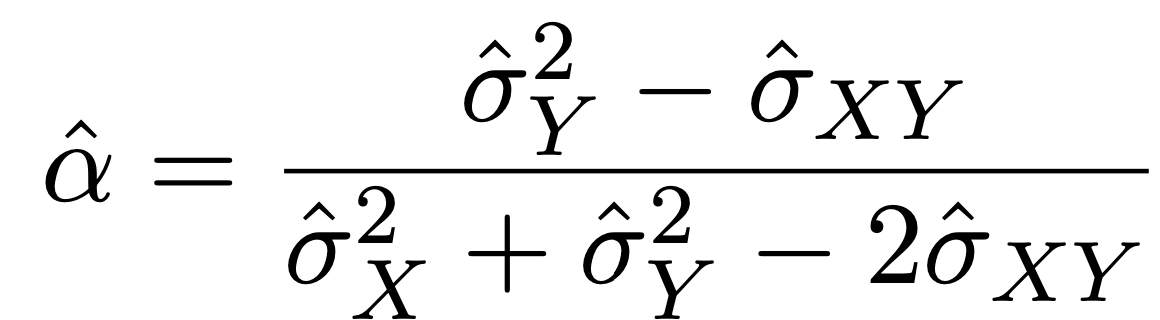
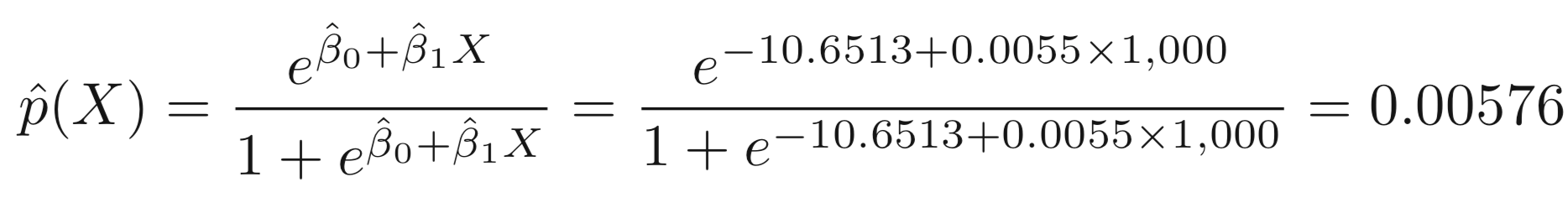

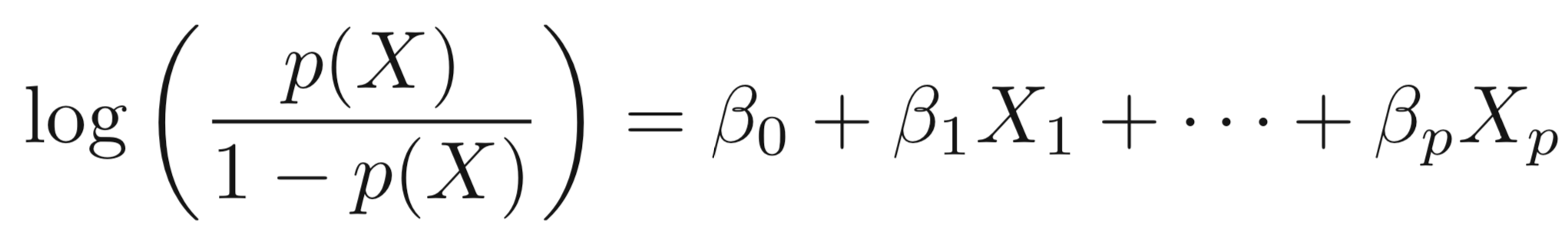
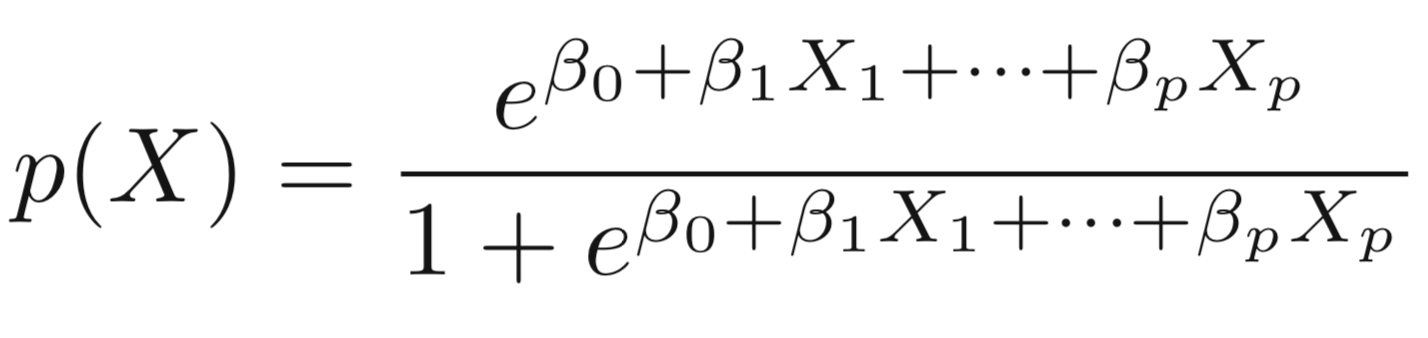
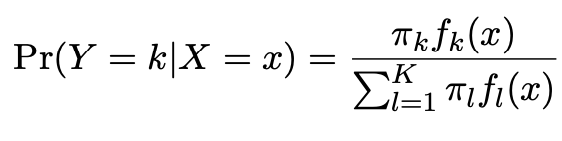
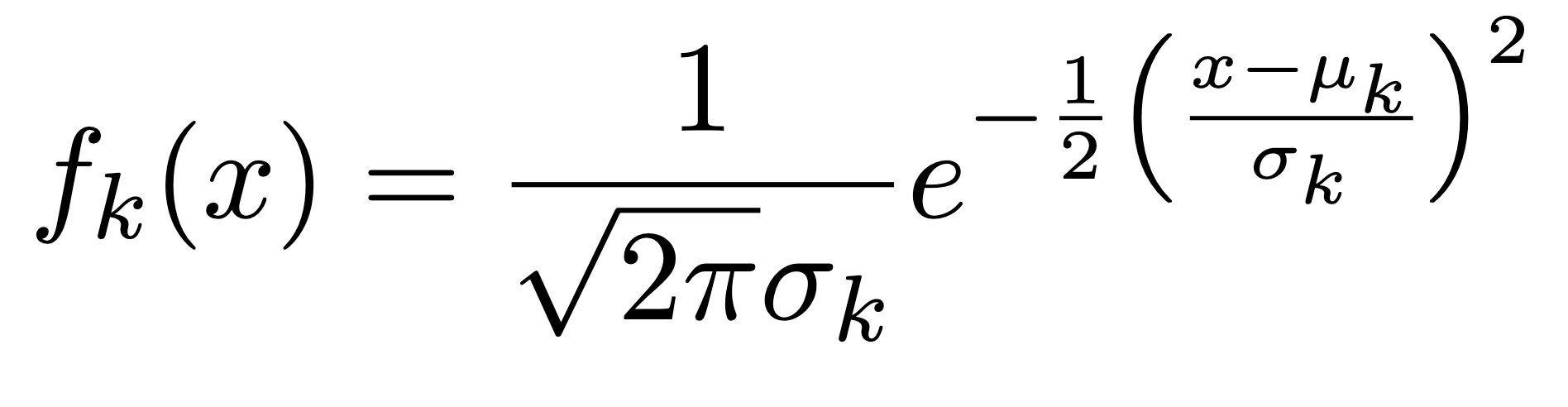
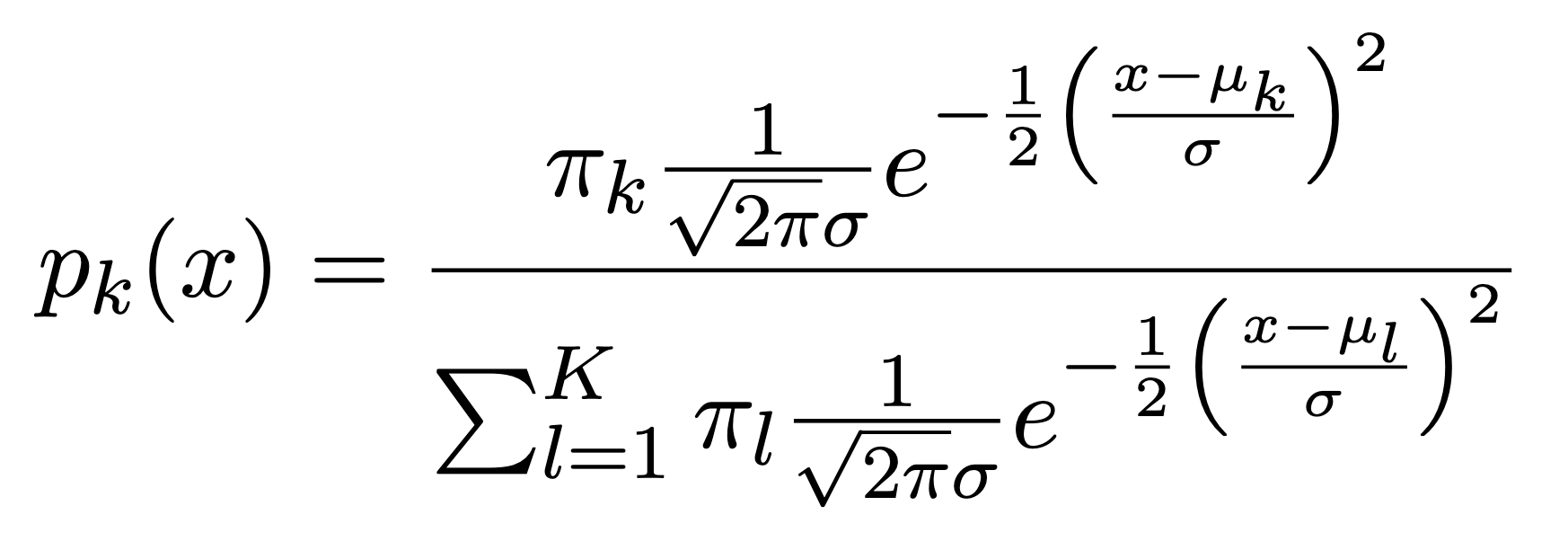

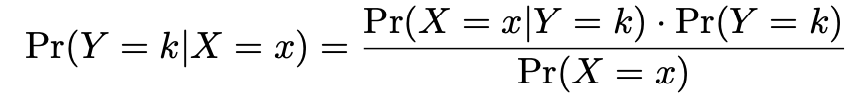





Karl Ho
Data Generation datageneration.io
Karl Ho
School of Economic, Political and Policy Sciences
University of Texas at Dallas
Workshop prepared for International Society for Data Science and Analytics (ISDSA) Annual Meeting, Notre Dame University, June 2nd, 2022.
There are a total of \(2^p\) models that contain subsets of \(p\) variables.
Three kinds of uncertainties
Reducible error: inaccurate coefficient estimates
Confidence intervals can be used.
Model bias: linearity assumption tested
Irreducible error: random error \(\epsilon\) in the model
Prediction intervals
Prediction intervals are always wider than confidence intervals, because they incorporate both the error in the estimate for \(f(X)\) (the reducible error) and the uncertainty as to how much an individual point will differ from the population regression plane (the irreducible error).
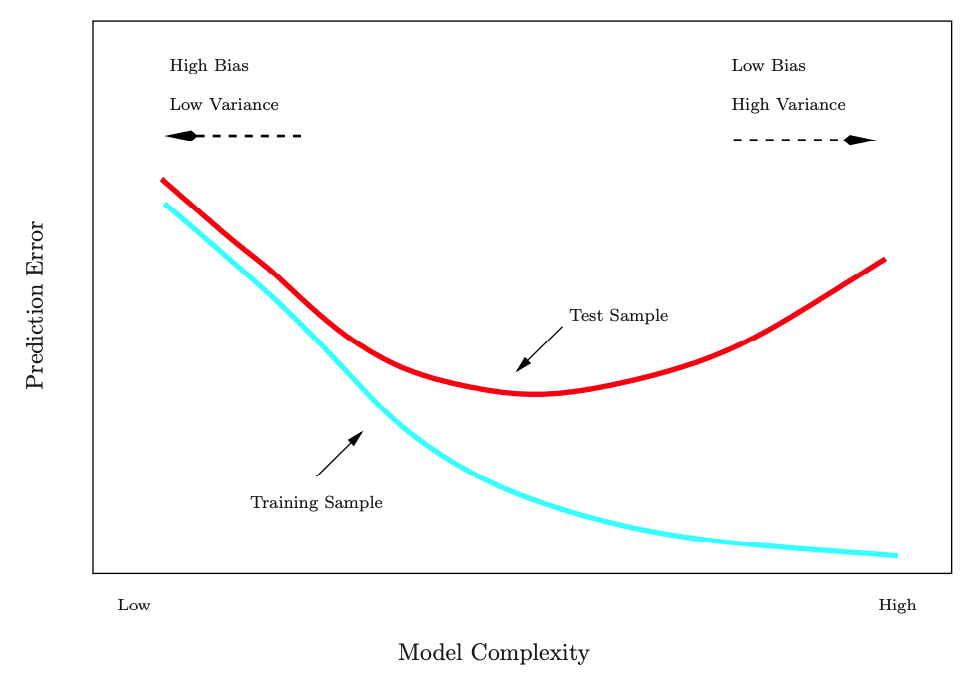
Source: ISLR Figure 2.7, p. 25
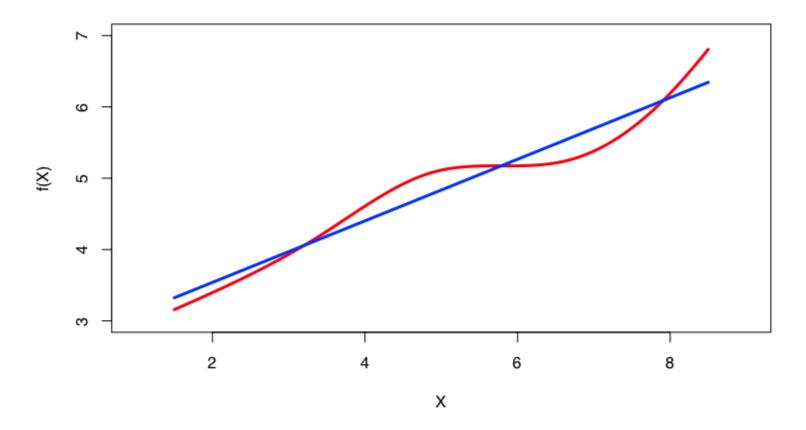
Again, beware of the evil of overfitting!
Source: ISLR Figure 2.7, p. 25
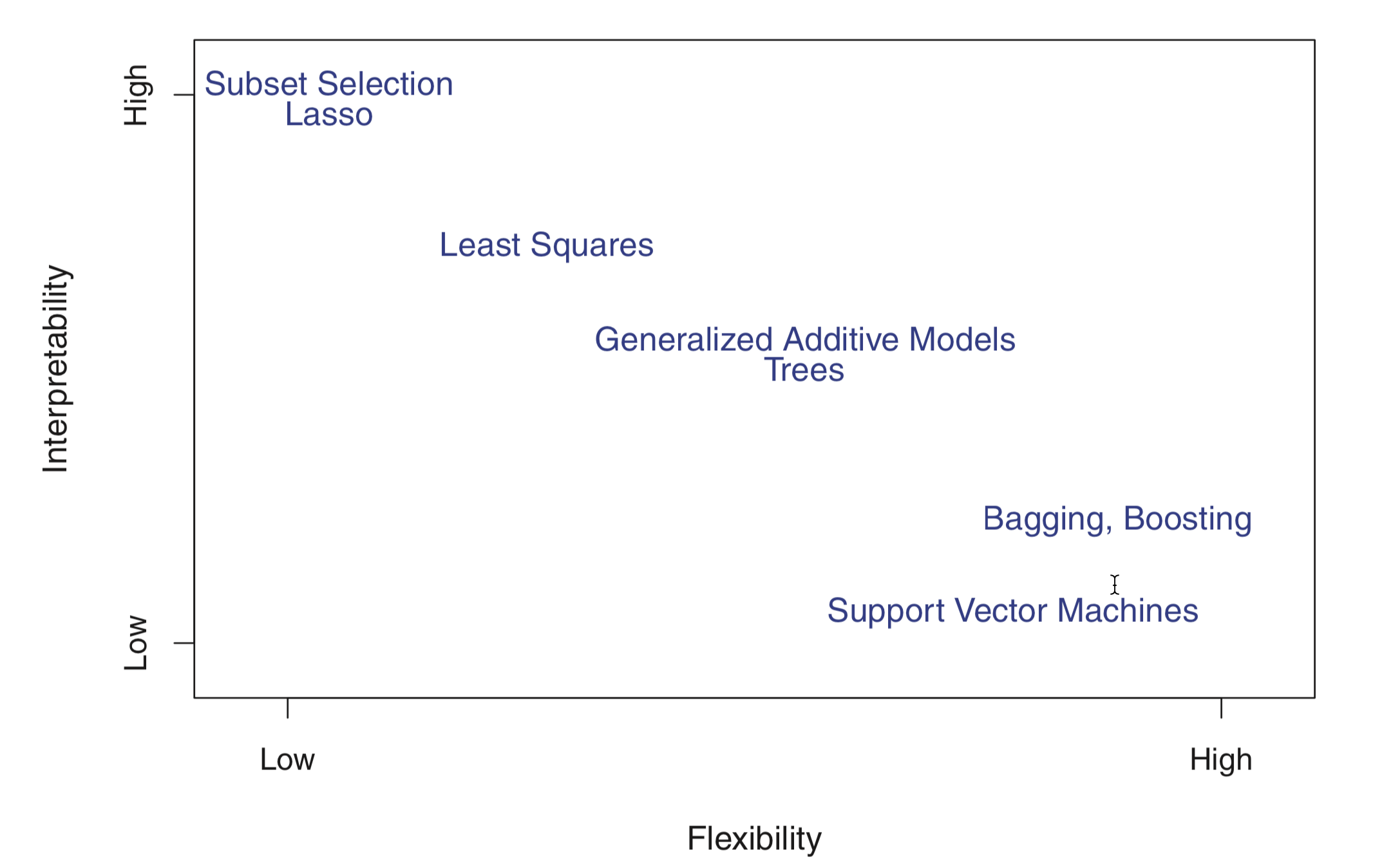
In general, as the flexibility of a method increases, its interpretability decreases.
$$ MSE=\frac{1}{n} \sum_{i=1}^n(y_{i}-\hat{f}(x_{i}))^2 $$
Mean Squared Error is the extent to which the predicted response value for a given observation is close to
the true response value for that observation.
where \(\hat{f}(x_{i})\) is the prediction that \(\hat{f}\) gives for the \(i^{th}\) observation.
The MSE will be small if the predicted responses are very close to the true responses, and will be large if for some of the observations, the predicted and true responses differ substantially.
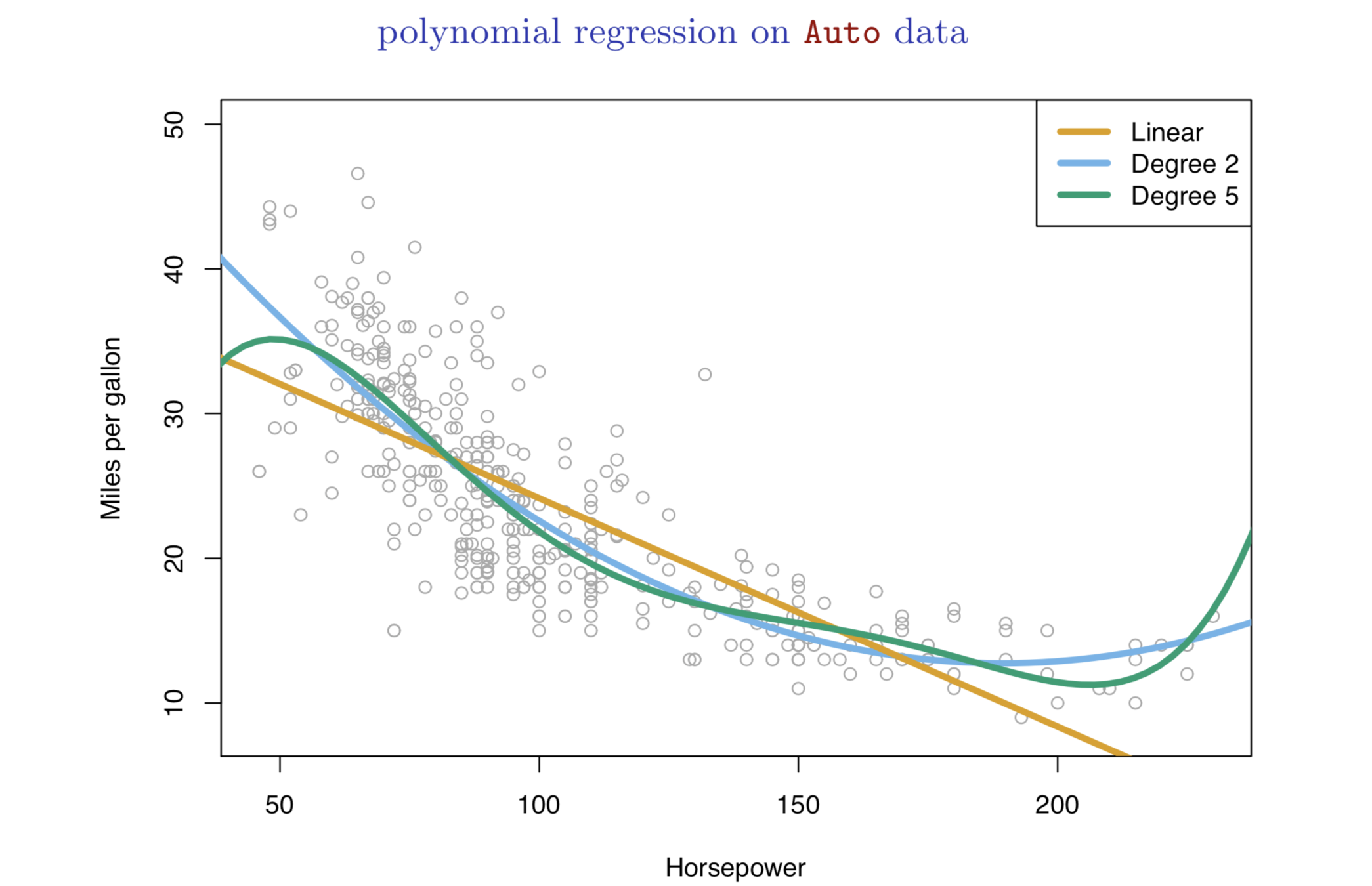
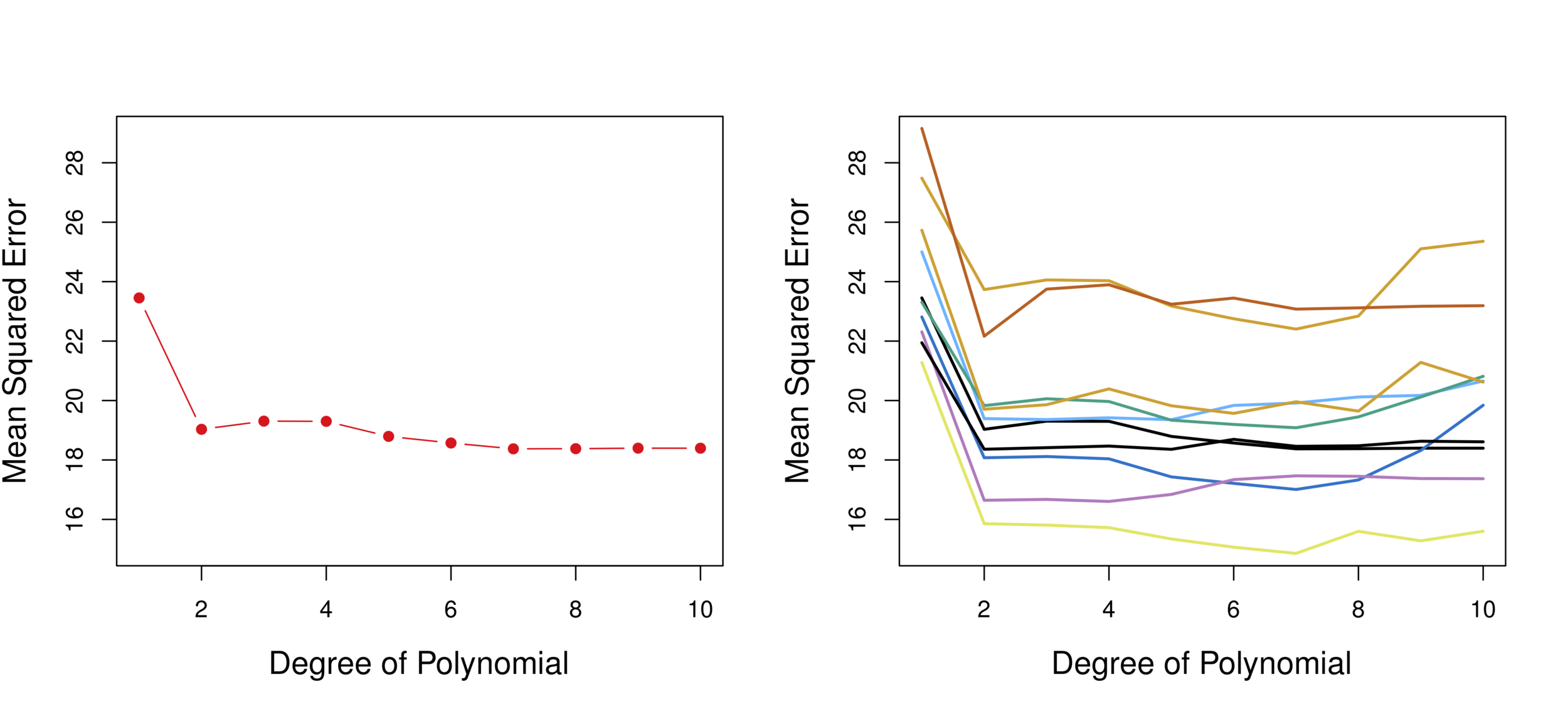
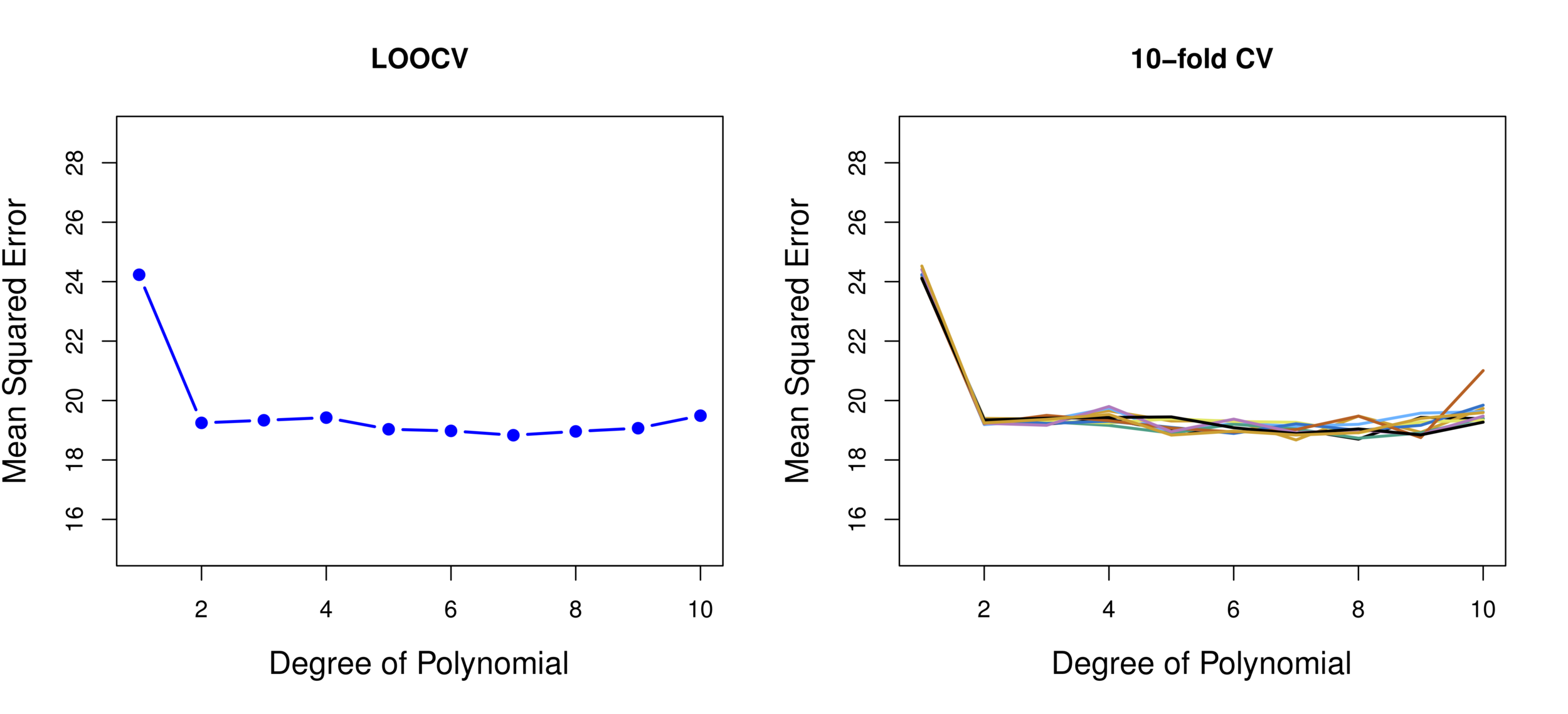
Linear vs. Quadratic vs. Cubic
Validation 10 times
Conclusion: Quadratic form is the best.
A set of \(n\) data points is repeatedly split into a training set containing all but one observation, and a validation set that contains only that observation. The test error is then estimated by averaging the \(n\) resulting \(MSE\)’s. The first training set contains all but observation 1, the second training set contains all but observation 2, and so forth.
A set of \(n\) observations is randomly split into five non-overlapping groups. Each of these fifths acts as a validation set, and the remainder as a training set. The test error is estimated by averaging the five resulting \(MSE\) estimates.
LOOCV sometimes useful, but typically doesn’t shake up the data enough. The estimates from each fold are highly correlated and hence their average can have high variance.
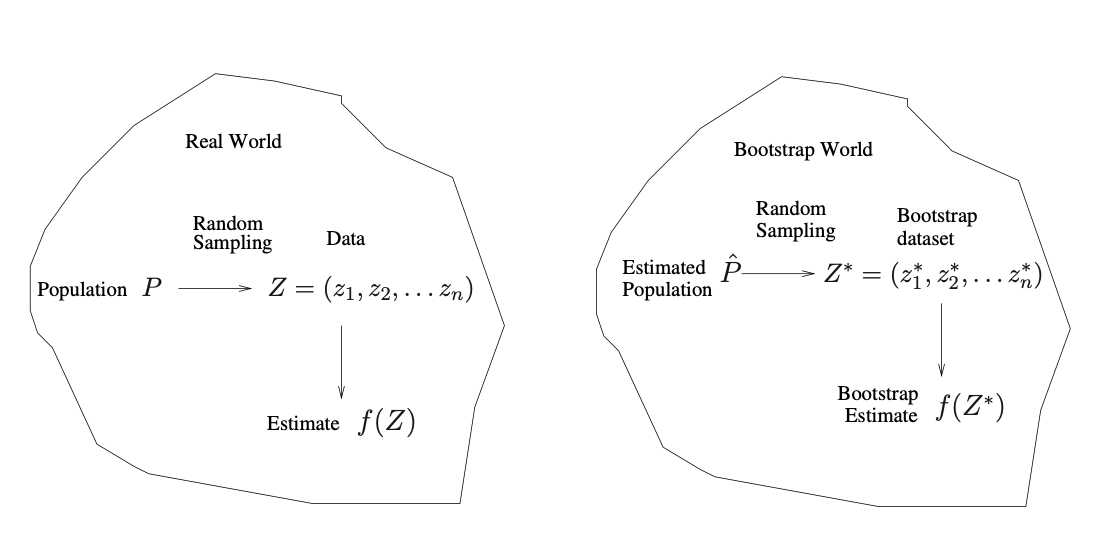
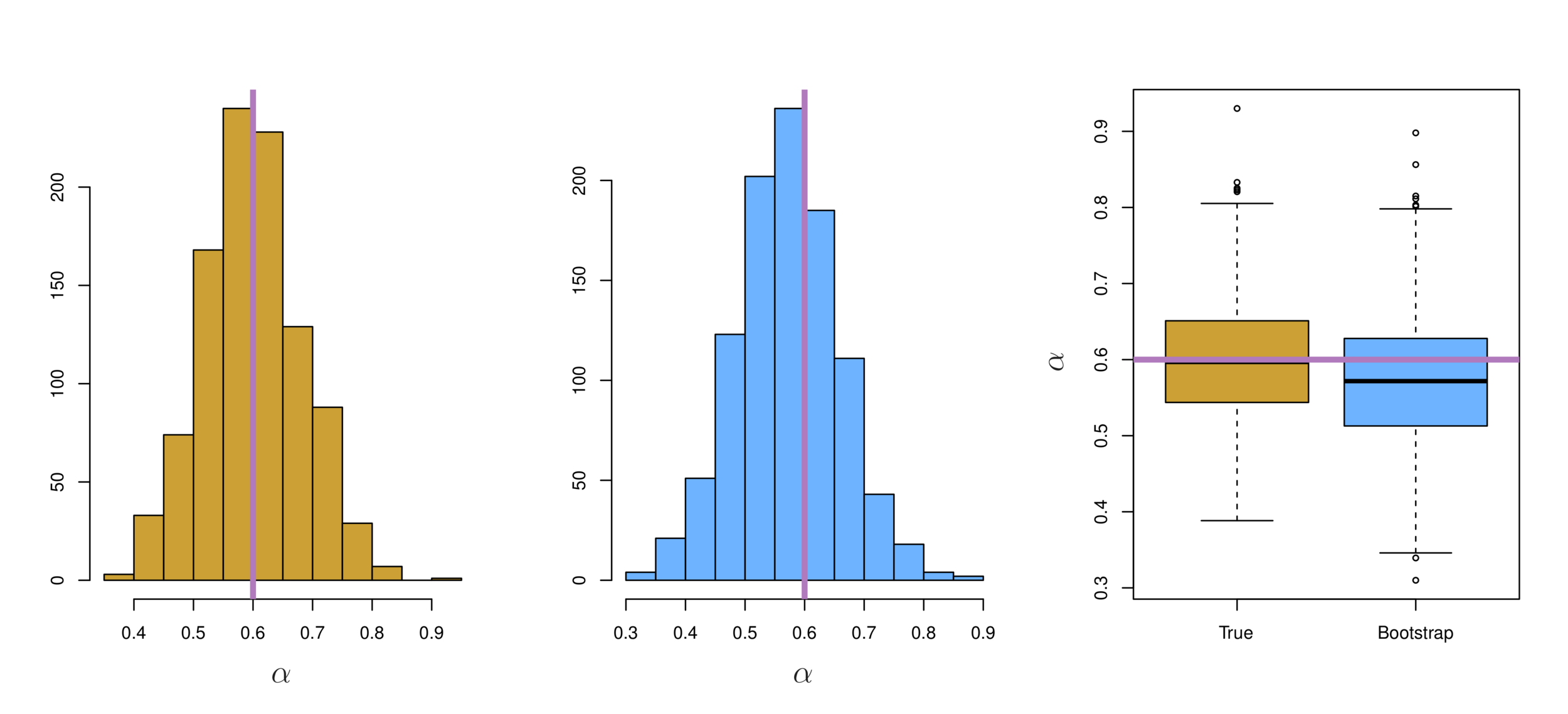
The Baron had fallen to the bottom of a deep lake. Just when it looked like all was lost, he thought to pick himself up by his own bootstraps.
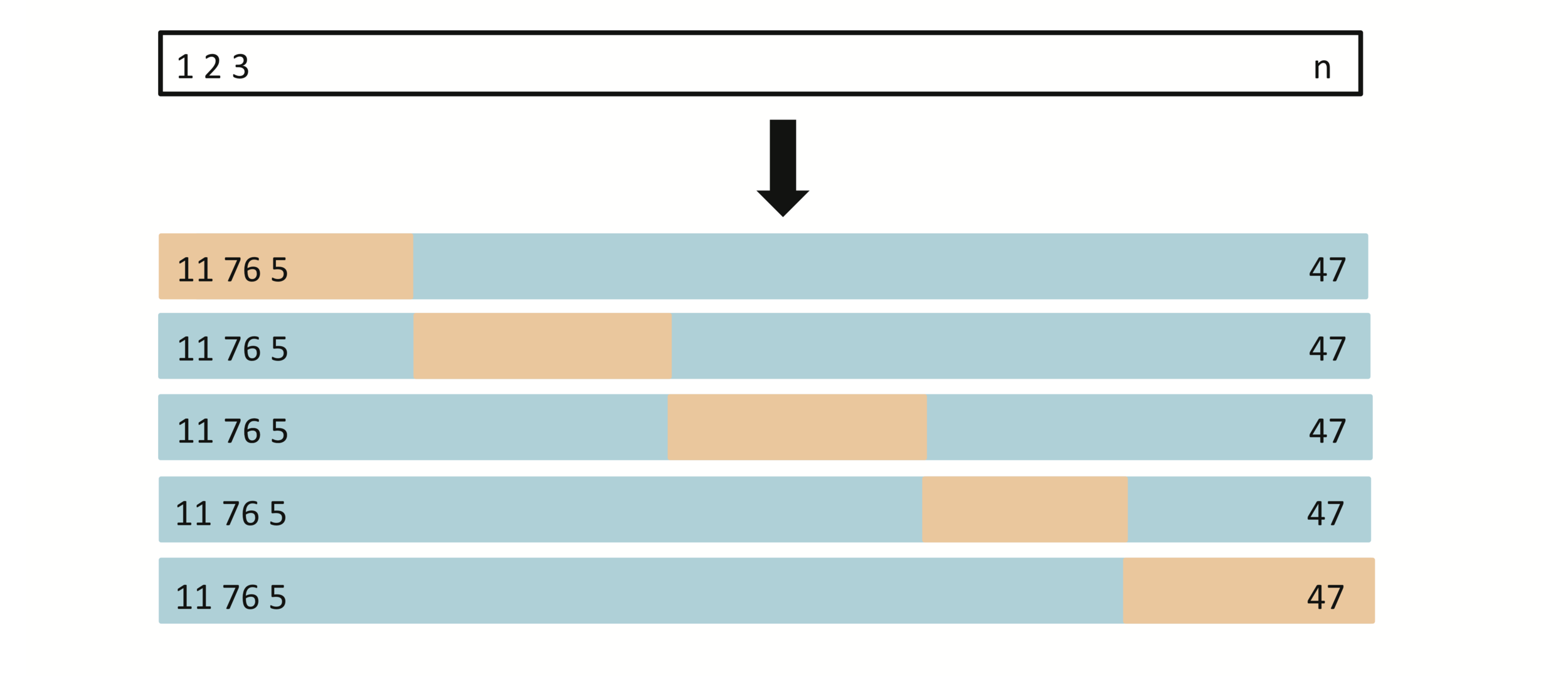
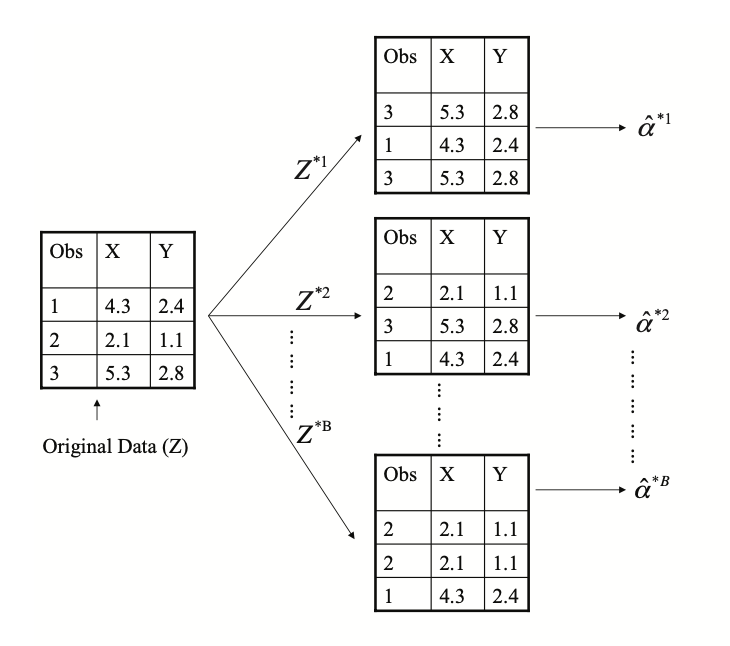
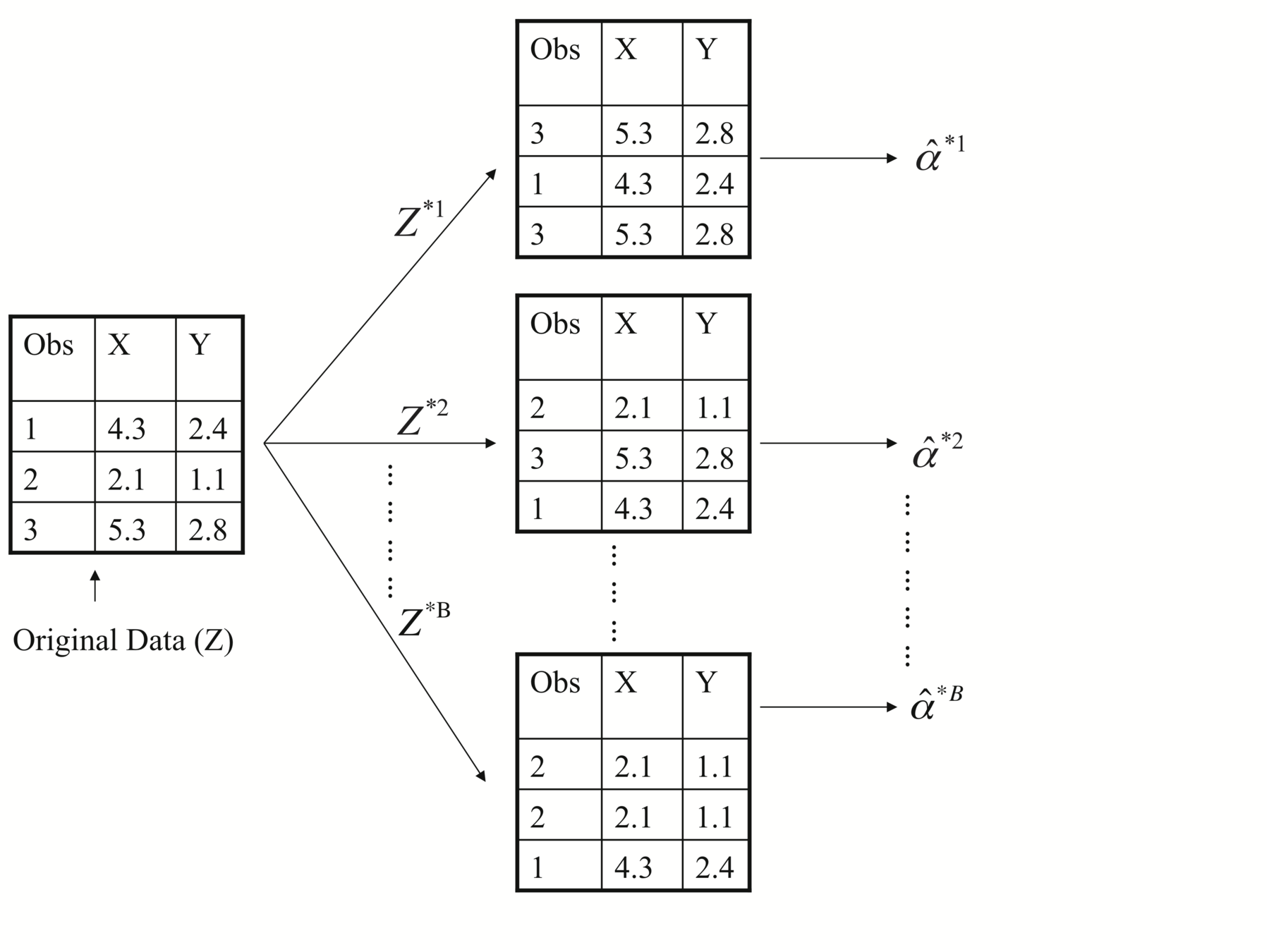
Each bootstrap data set contains \(n\) observations, sampled with replacement from the original data set. Each bootstrap data set is used to obtain an estimate of \(\alpha\)
[1,2,3,4,5], [2,5,4,4,1], [1,3,2,5,5],......
[1,2,3,4,5], [2,5,4,1], [1,2,5],......
Left: Histogram of the estimates of \(\alpha\) obtained by generating 1,000 simulated data sets from the true population. Center: A histogram of the estimates of \(\alpha\)obtained from 1,000 bootstrap samples from a single data set. Right: Boxplots of estimates of \(\alpha\) displayed in the left and center panels. In each panel, the pink line indicates the true value of \(\alpha\).
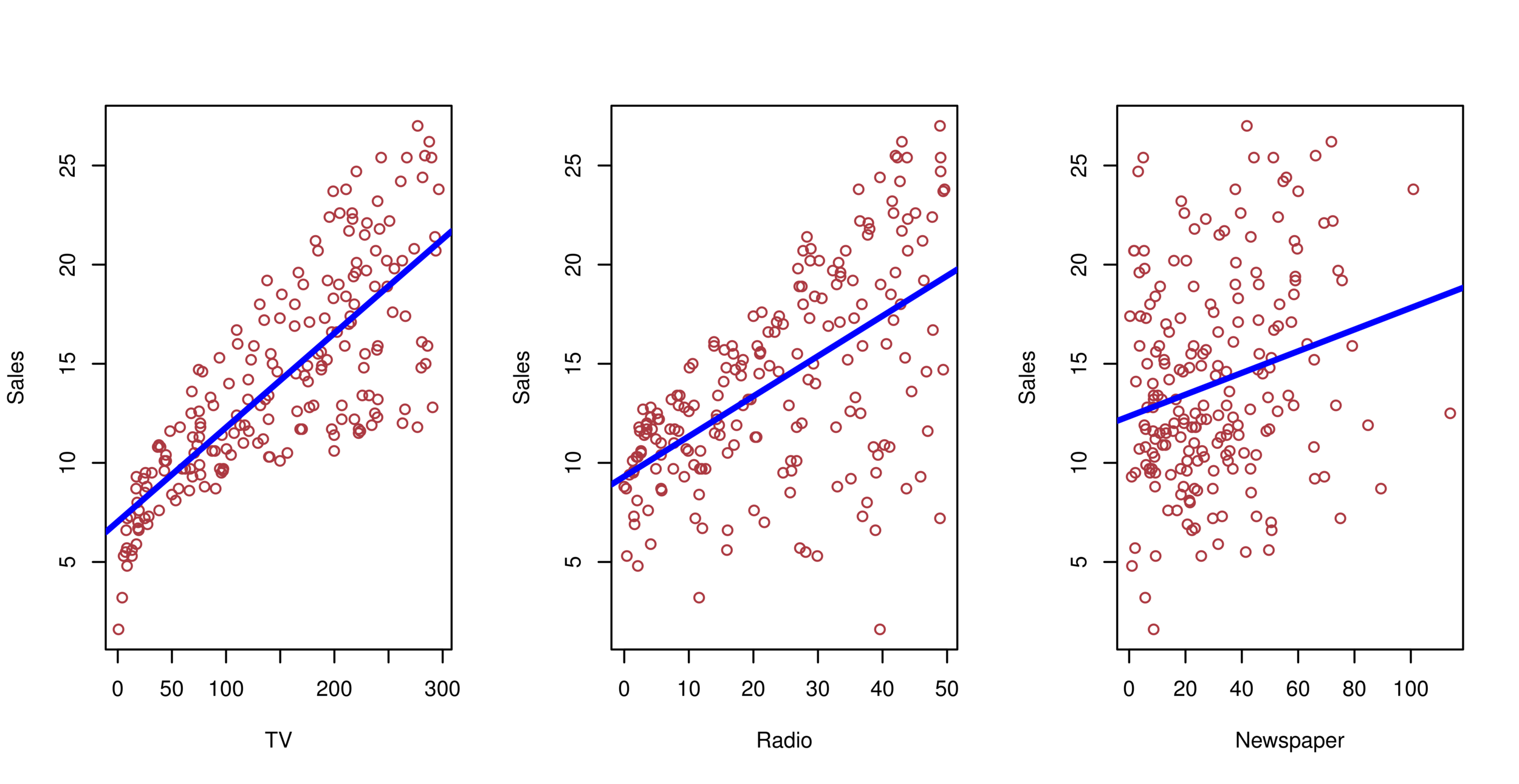
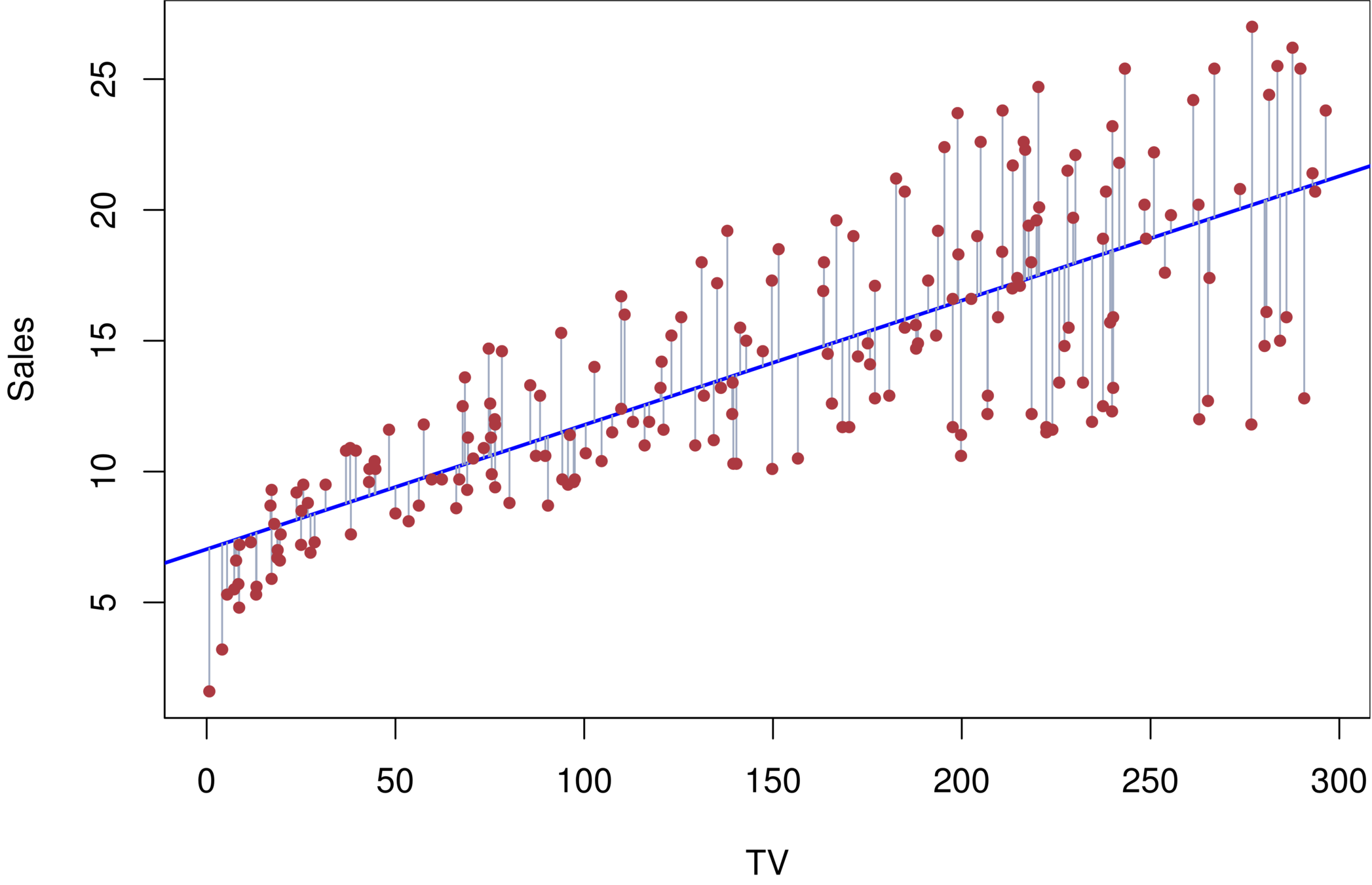
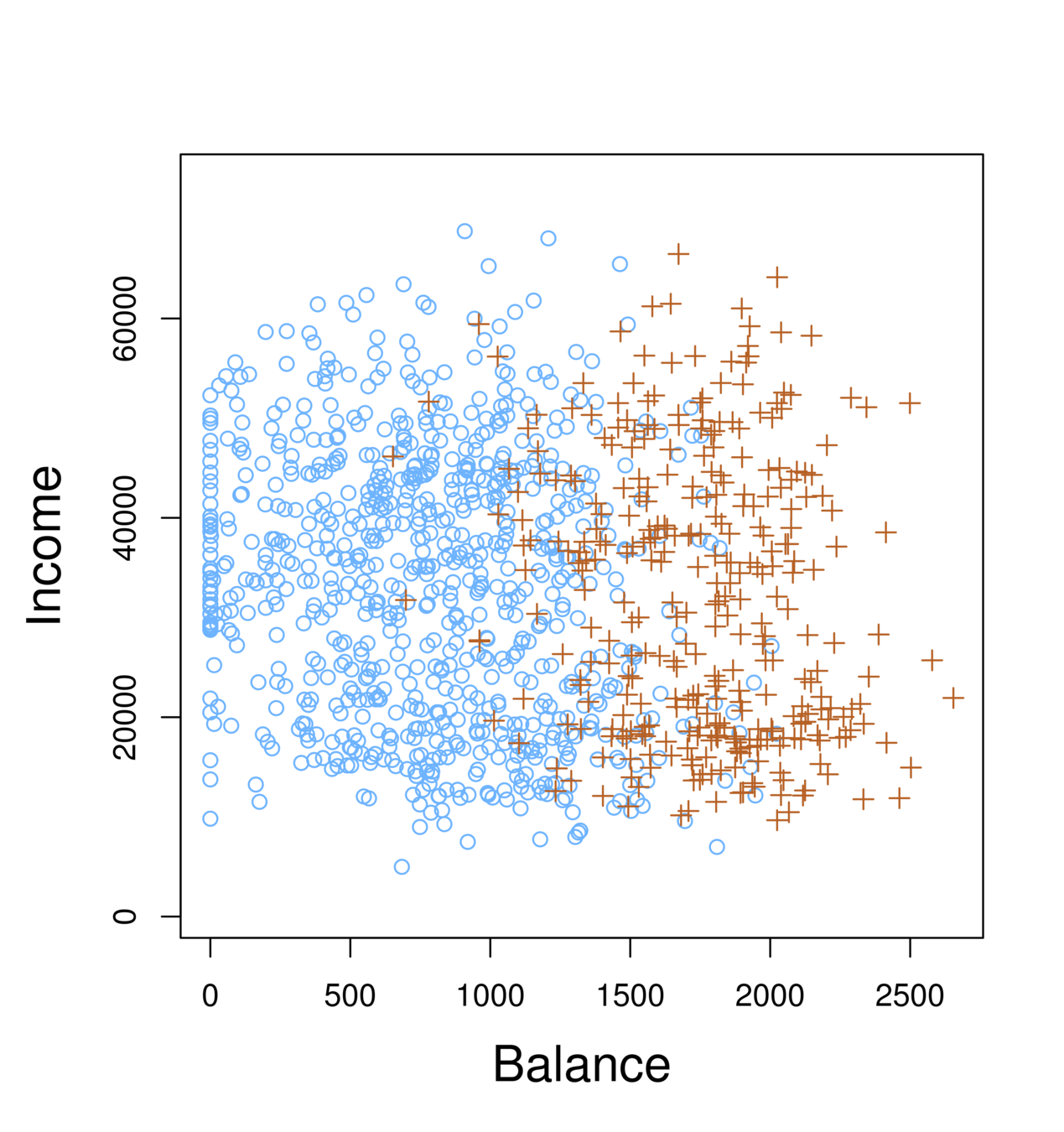
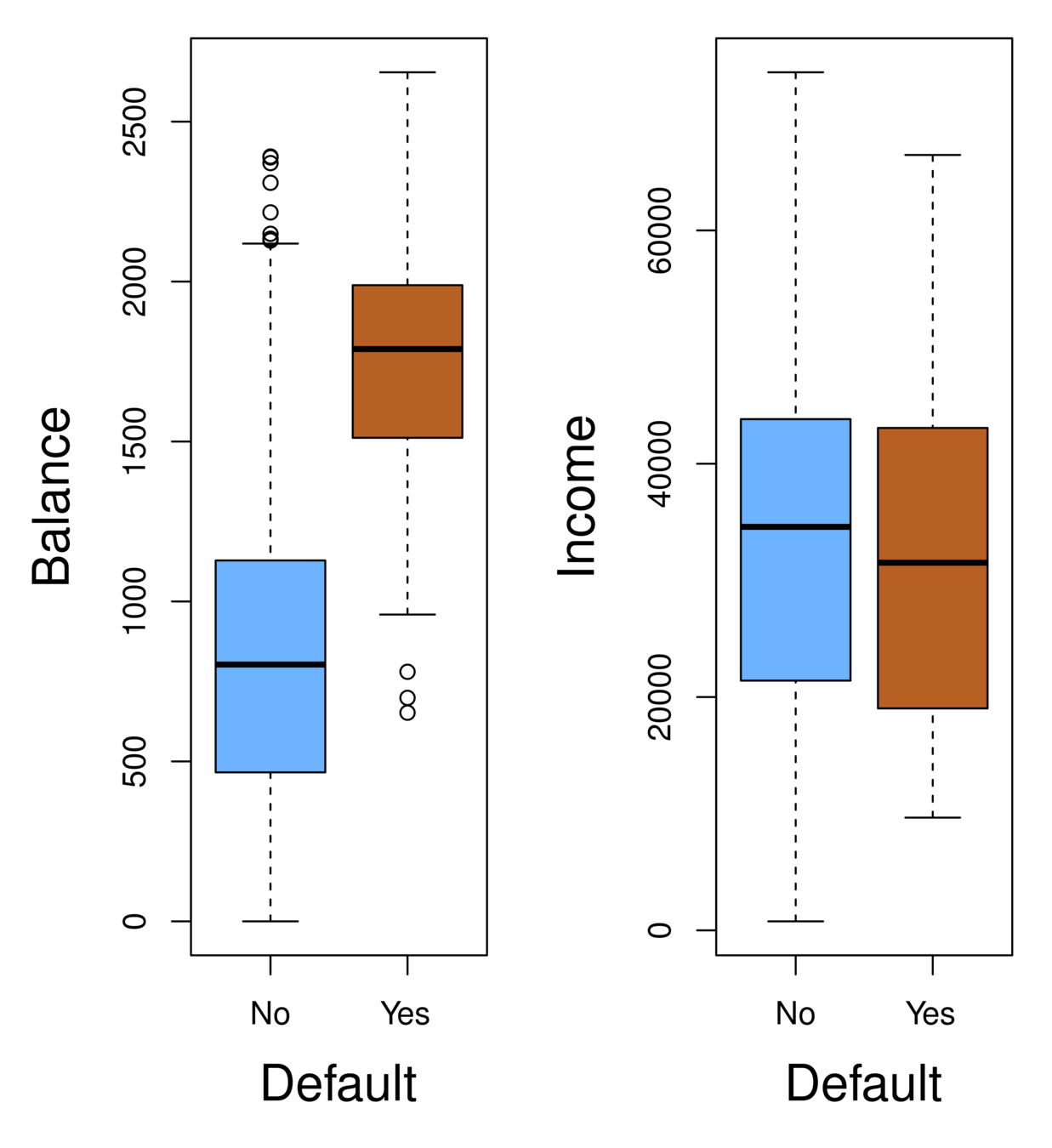
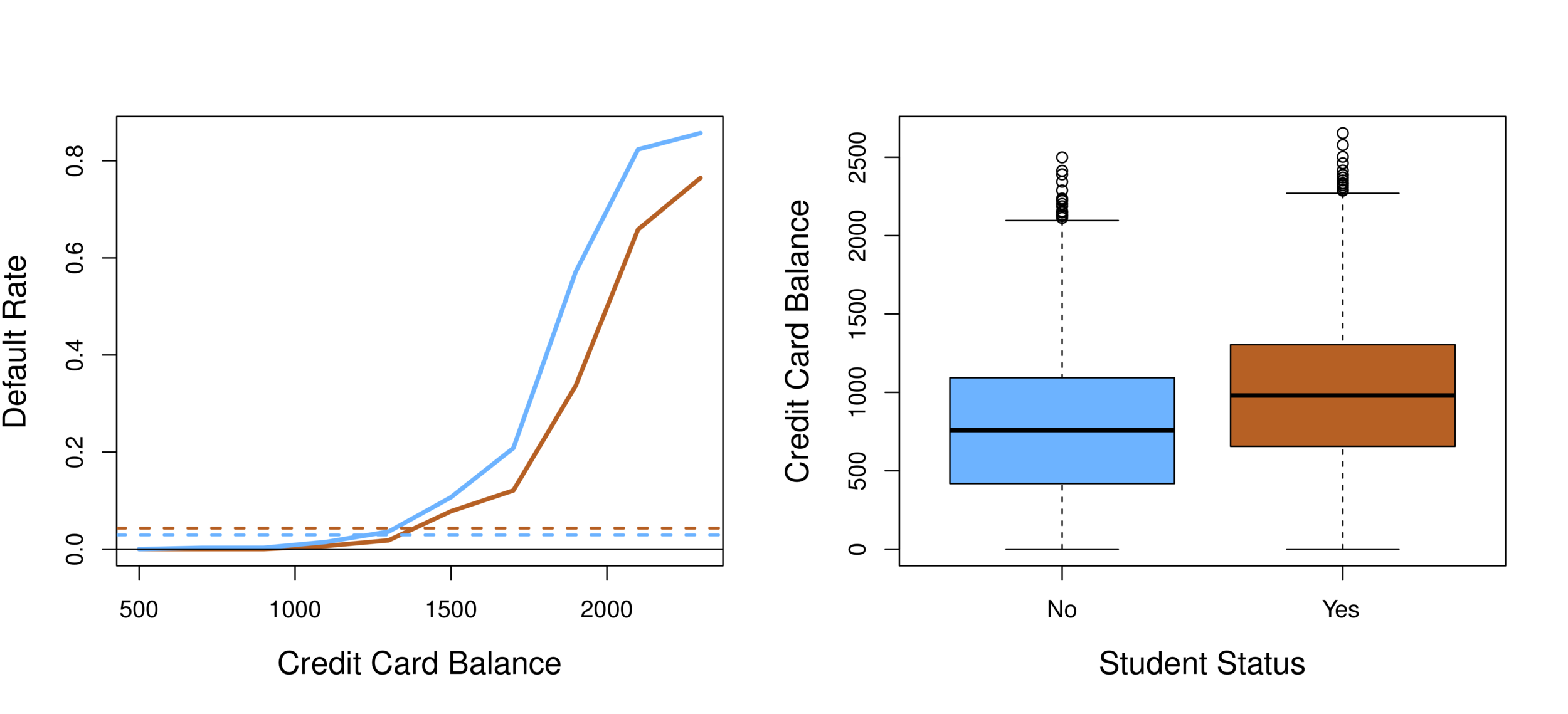
Orange: default, Blue: not
Overall default rate: 3%
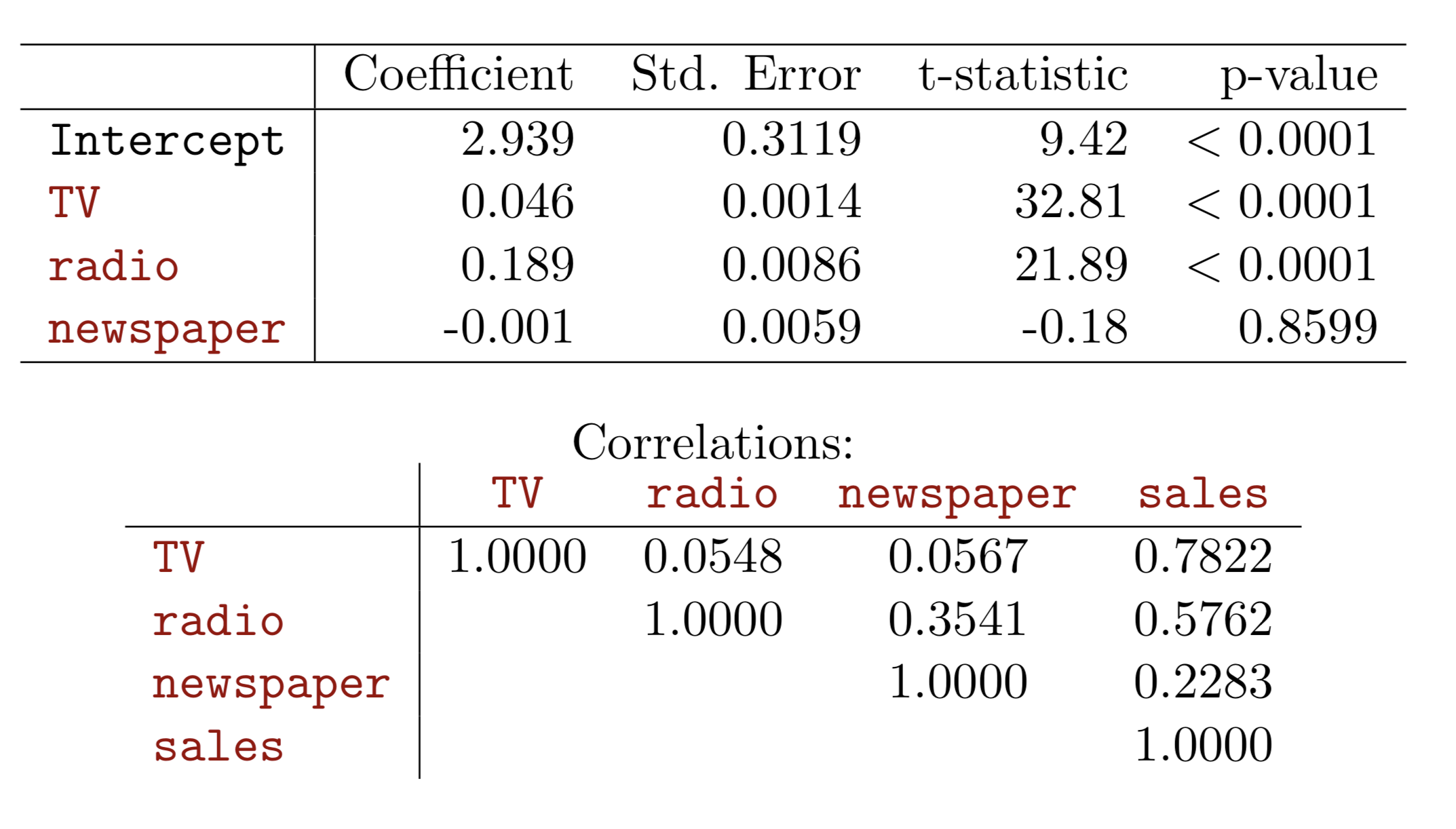
Higher balance tend to default
Income has any impact?
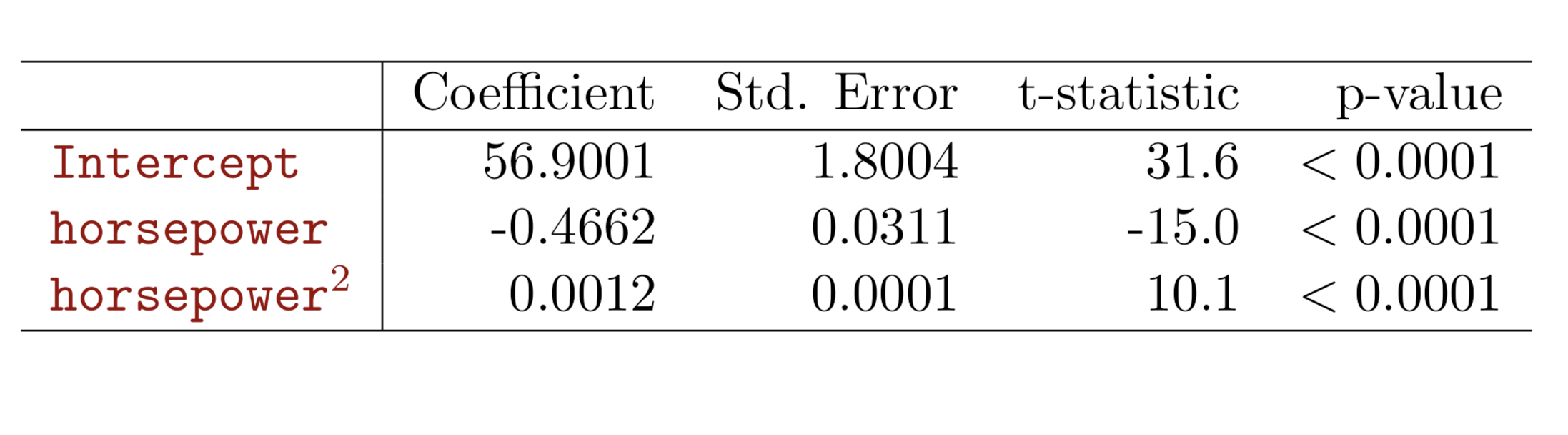
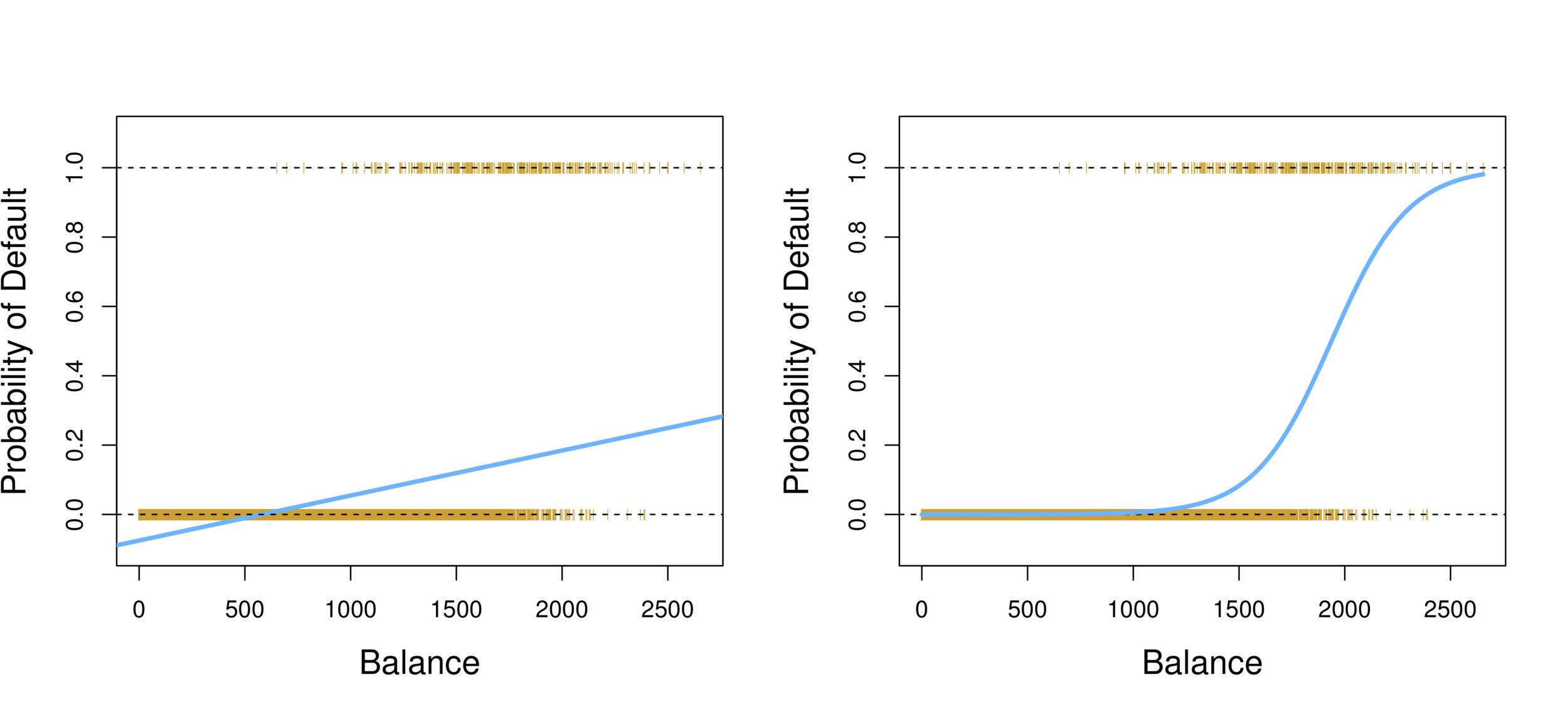
Linear regression vs. Logistic regression
Using linear regression, predictions can go out of bound!
Probability of default given balance can be written as:
\(Pr(default = Yes | balance)\).
Prediction using \(p(x)>.5\), where x is the predictor variable (e.g. balance)
Can set other or lower threshold (e.g. \(p(x)>.3\))
To model \(p(X)\), we need a function that gives outputs between 0 and 1 for all values of \(X\).
In logistic regression, we use the logistic function,
The numerator is called the odds
Which is the same as:
\[p(X) = \frac{e ^ {\beta_0+\beta_1X}}{1+e ^ {\beta_0+\beta_1X}}\]
\[e^{\beta_0+\beta_1X}\]
\[\frac{p(X)}{1-p(X)}\]
\(e ≈ 2.71828\) is a mathematical constant [Euler’s number.] No matter what values \(\beta_0\), \(\beta_1\) or \(X\) take, \(p(X)\) will have values between 0 and 1.
The odds can be understood as the ratio of probabilities between on and off cases (1,0)
For example, on average 1 in 5 people with an odds of 1/4 will default, since \(p(X) = 0.2\) implies an odds of
\(0.2/(1-0.2) = 1/4\).
\[\frac{p(X)}{1-p(X)}\]
Taking the log of both sides, we have:
The left-hand side is called the log-odds or logit, which can be estimated as a linear regression with X.
Note that however, \(p(X)\) and \(X\) are not in linear relationship.
\[\frac{p(X)}{1-p(X)}=e^{\beta_0+\beta_1X}\]
\[log(\frac{p(X)}{1-p(X)})=\beta_0+\beta_1X\]
Logistic Regression can be estimated using Maximum Likelihood.
We seek estimates for \(\beta_{0}\) and \(\beta_{1}\) such that the predicted probability \(\hat{p}(x_{i})\) of default for each individual, using \(p(X) = \frac{e ^ {\beta_0+\beta_1X}}{1+e ^ {\beta_0+\beta_1X}}\) corresponds as closely as possible to the individual’s observed default status.
In other words, we try to find \(\beta_{0}\) and \(\beta_{1}\)such that plugging these estimates into the model for \(p(X)\) yields a number close to one (1) for all individuals that fulfill the on condition (e.g. default) and a number close to zero (0) for all individuals of off condition (e.g. not default).
Maximum likelihood to estimate the parameters: \[\ell(\beta_0, \beta) = \prod_{i:y_i=1}p(x_i)\prod_{i:y_i=0}(1-p(x_i))\]
This likelihood gives the probability of the observed zeros and ones in the data. We pick \(\beta_0\) and \(\beta_1\) to maximize the likelihood of the observed data.
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -1.065e+01 3.612e-01 -29.49 <2e-16 ***
balance 5.499e-03 2.204e-04 24.95 <2e-16 ***
Output:
Suppose an individual has a balance of $1,000,
glm.fit=glm(default~balance,family=binomial)
summary(glm.fit)| Default | |||
|---|---|---|---|
| Student | No | Yes | |
| No | 6,850 | 206 | 0.029 |
| Yes | 2,817 | 127 | 0.043 |
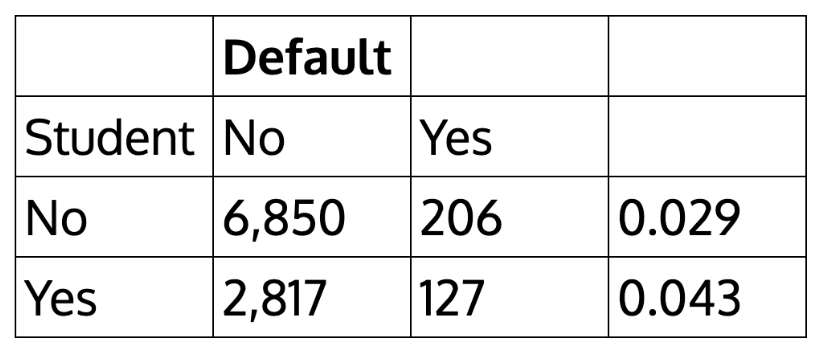
How about the case of students?
> table(student,default)
default
student No Yes
No 6850 206
Yes 2817 127
We can actually calculate by hand the rate of default among students:
Coefficients: Estimate Std. Error z value Pr(>|z|) (Intercept) -3.50413 0.07071 -49.55 < 2e-16 *** studentYes 0.40489 0.11502 3.52 0.000431 ***
glm.sfit=glm(default~student,family=binomial)
summary(glm.sfit)We can extend the Logistic Regression to multiple right hand side variables.
> glm.nfit=glm(default~balance+income+student,data=Default,family=binomial)
> summary(glm.nfit)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -1.087e+01 4.923e-01 -22.080 < 2e-16 ***
balance 5.737e-03 2.319e-04 24.738 < 2e-16 ***
income 3.033e-06 8.203e-06 0.370 0.71152
student[Yes] -6.468e-01 2.363e-01 -2.738 0.00619 **
Why student becomes negative? What does this mean?
Confounding effect: when other predictors in model, student effect is different.
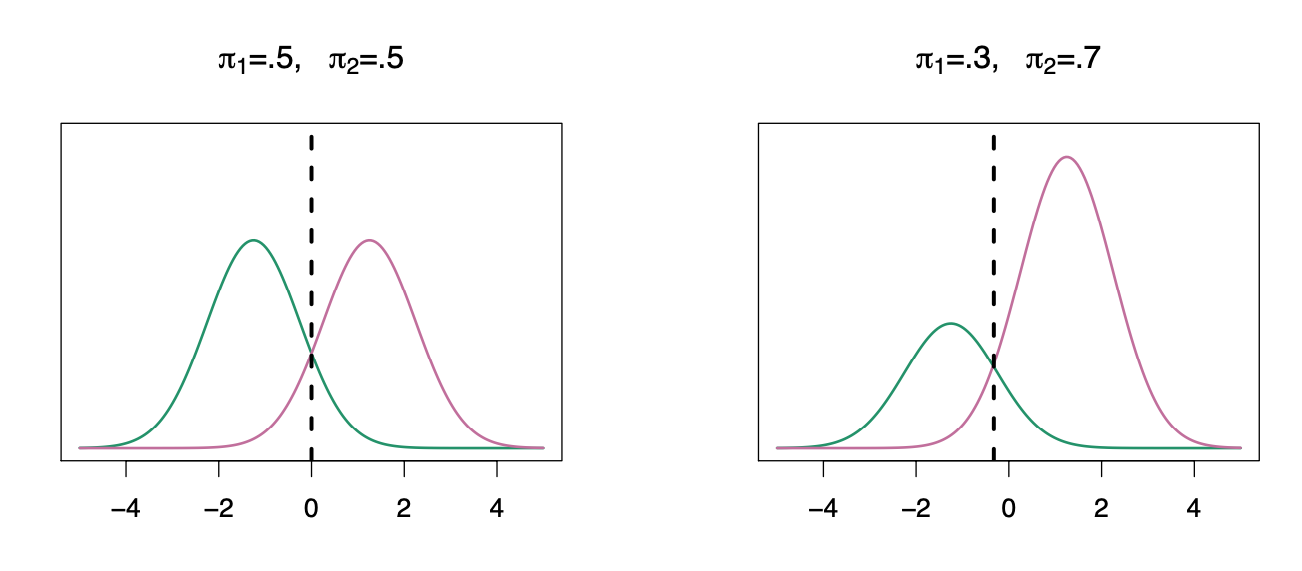
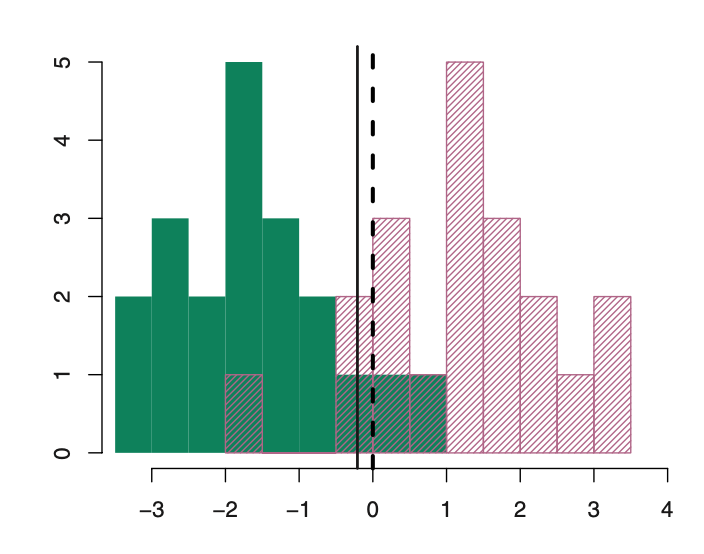
We classify a new point according to which density is highest.
The dashed line is called the Bayes decision boundary.
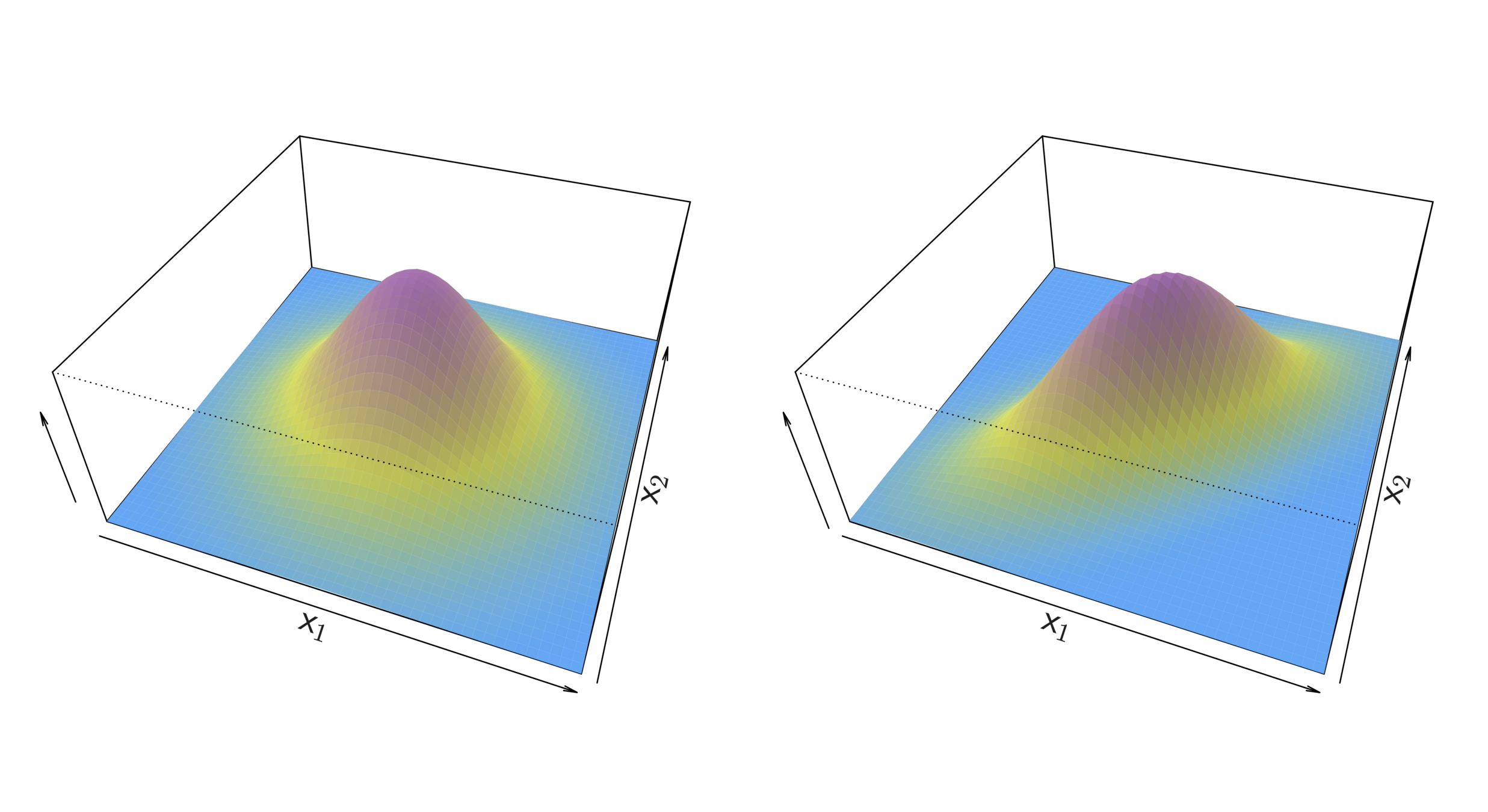
When the priors are different, we take them into account as well, and compare \(\pi_{k}\)\(f_{k}(x)\). On the right, we favor the light purple class — the decision boundary has shifted to the left.
LDA improves prediction by accounting for the normally distributed x (continuous).
Bayesian decision boundary
LDA decision boundary
Why not linear regression?
When p=1, The Gaussian density has the form:
Here \(\mu_{k}\) is the mean, and \(\sigma_{k}^{2}\) the variance (in class k). We will assume that all the \(\sigma_{k}\)=\(\sigma\)are the same. Plugging this into Bayes formula, we get a rather complex expression for \(p_{k}(x)\)=\(Pr(Y=k|X=x)\):
~1701-1761
Source: https://www.bayestheorem.net
Two multivariate Gaussian density functions are shown, with p = 2. Left: The two predictors are uncorrelated. Right: The two variables have a correlation of 0.7.
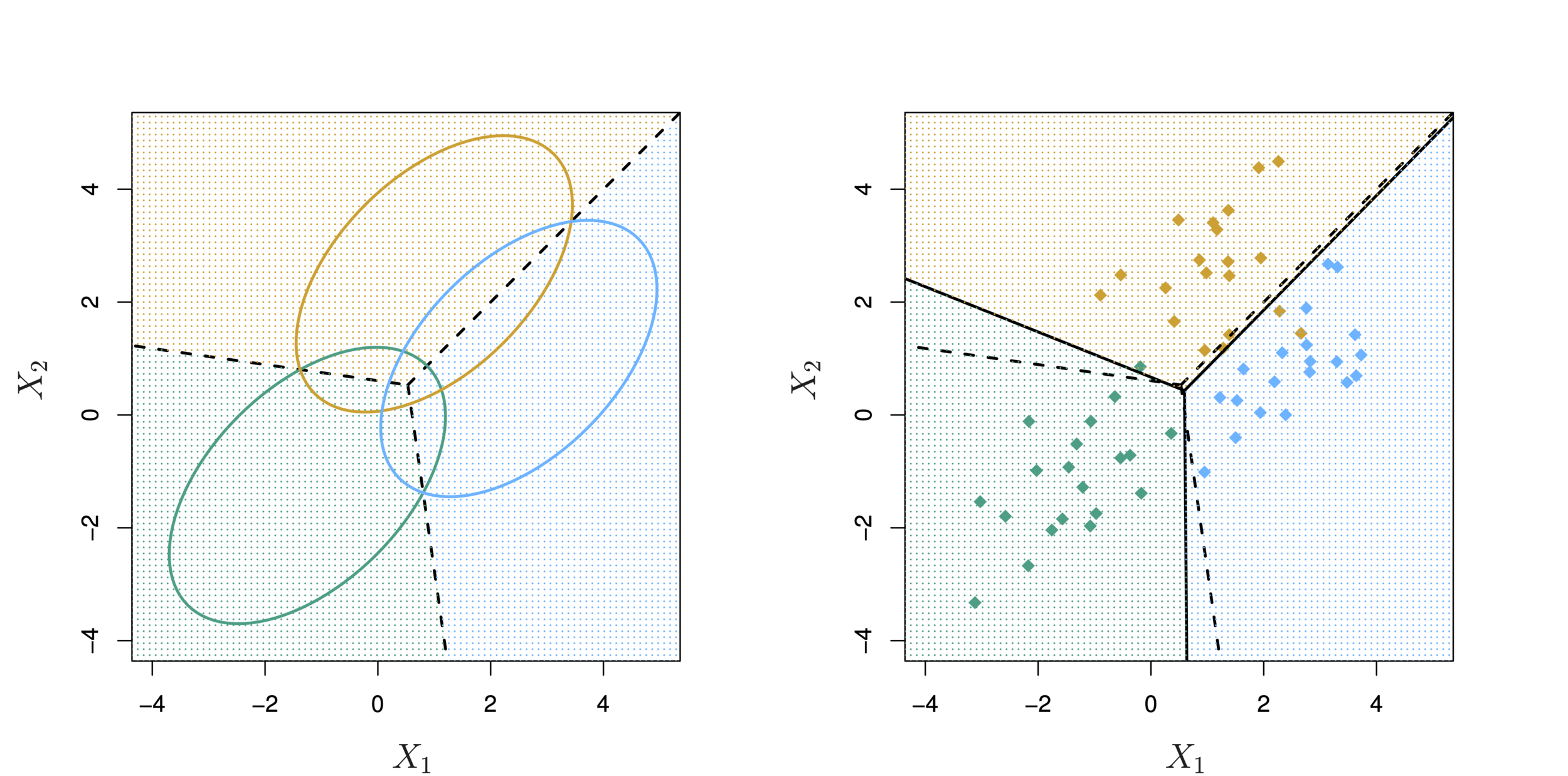
LDA with three classes with observations from a multivariate Gaussian distribution(p = 2), with a class-specific mean vector and a common covariance matrix. Left: Ellipses contain 95 % of the probability for each of the three classes. The dashed lines are the Bayes decision boundaries. Right: 20 observations were generated from each class, and the corresponding LDA decision boundaries are indicated using solid black lines.
The Receiver Operating Characteristics (ROC) curve display the overall performance of a classifier, summarized over all possible thresholds, is given by the area under the (ROC) curve (AUC). An ideal ROC curve will hug the top left corner, so the larger the AUC the better the classifier.
Correct
Incorrect
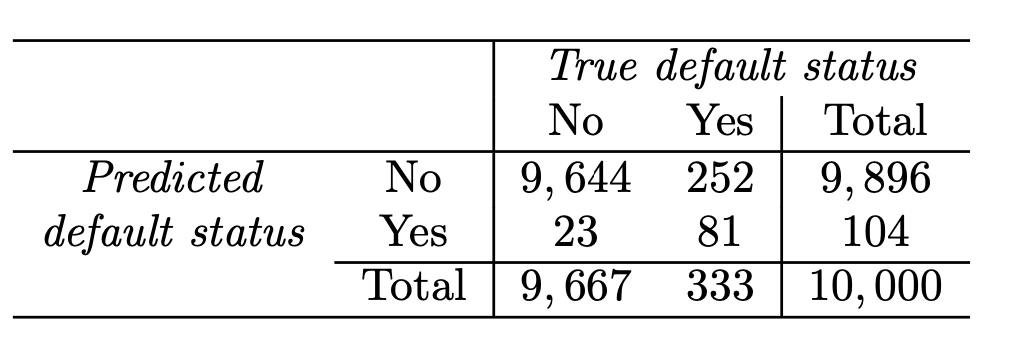
LDA error: (23+252)/10,000=2.75%
Yet, what matters is how many who actually defaulted were predicted?
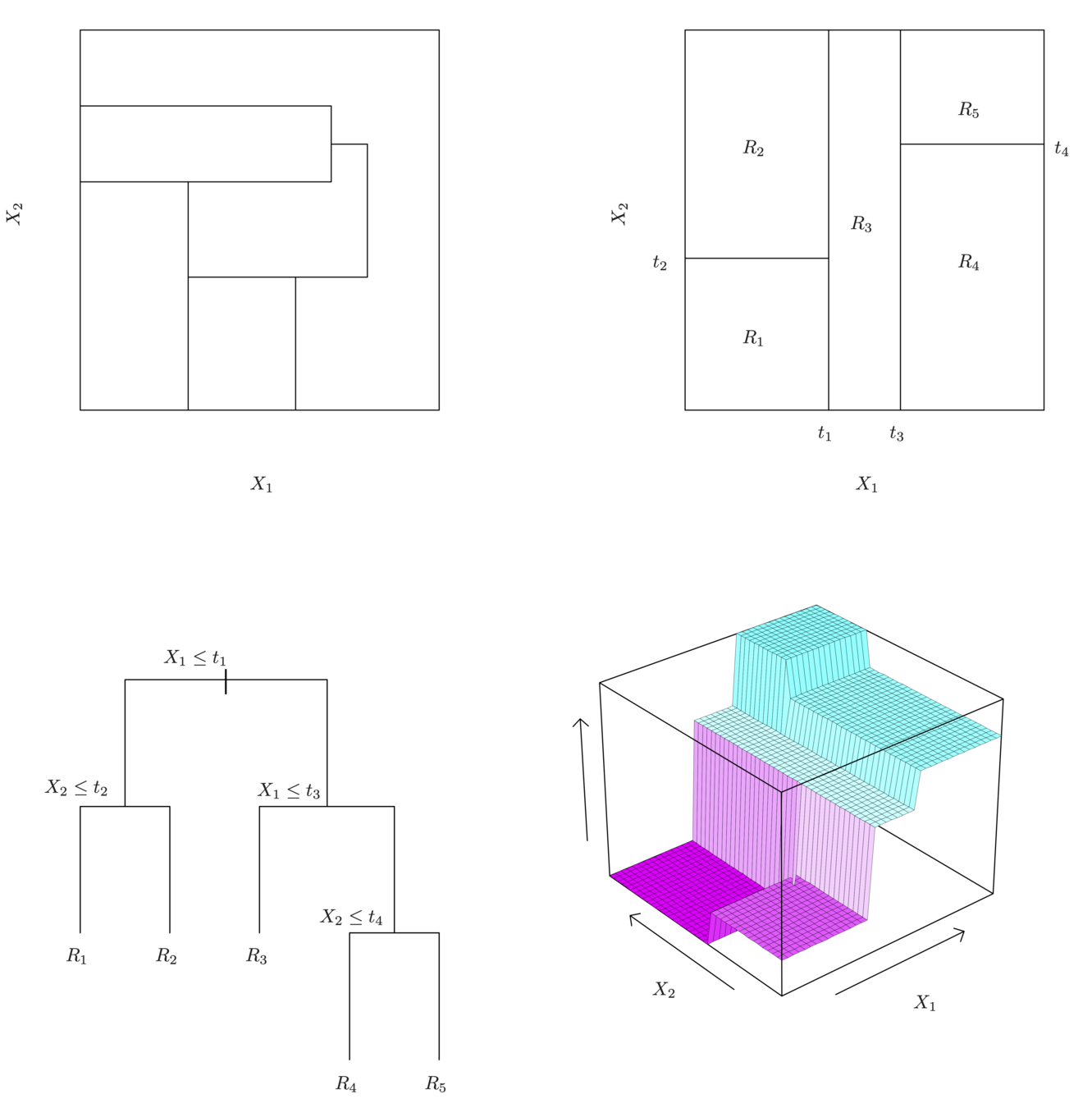
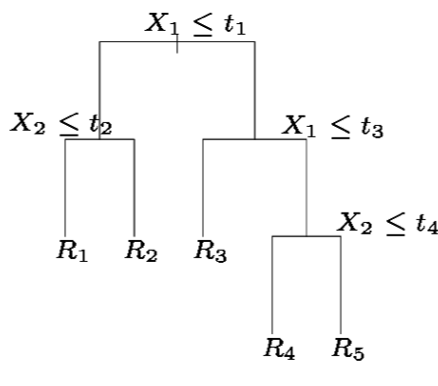
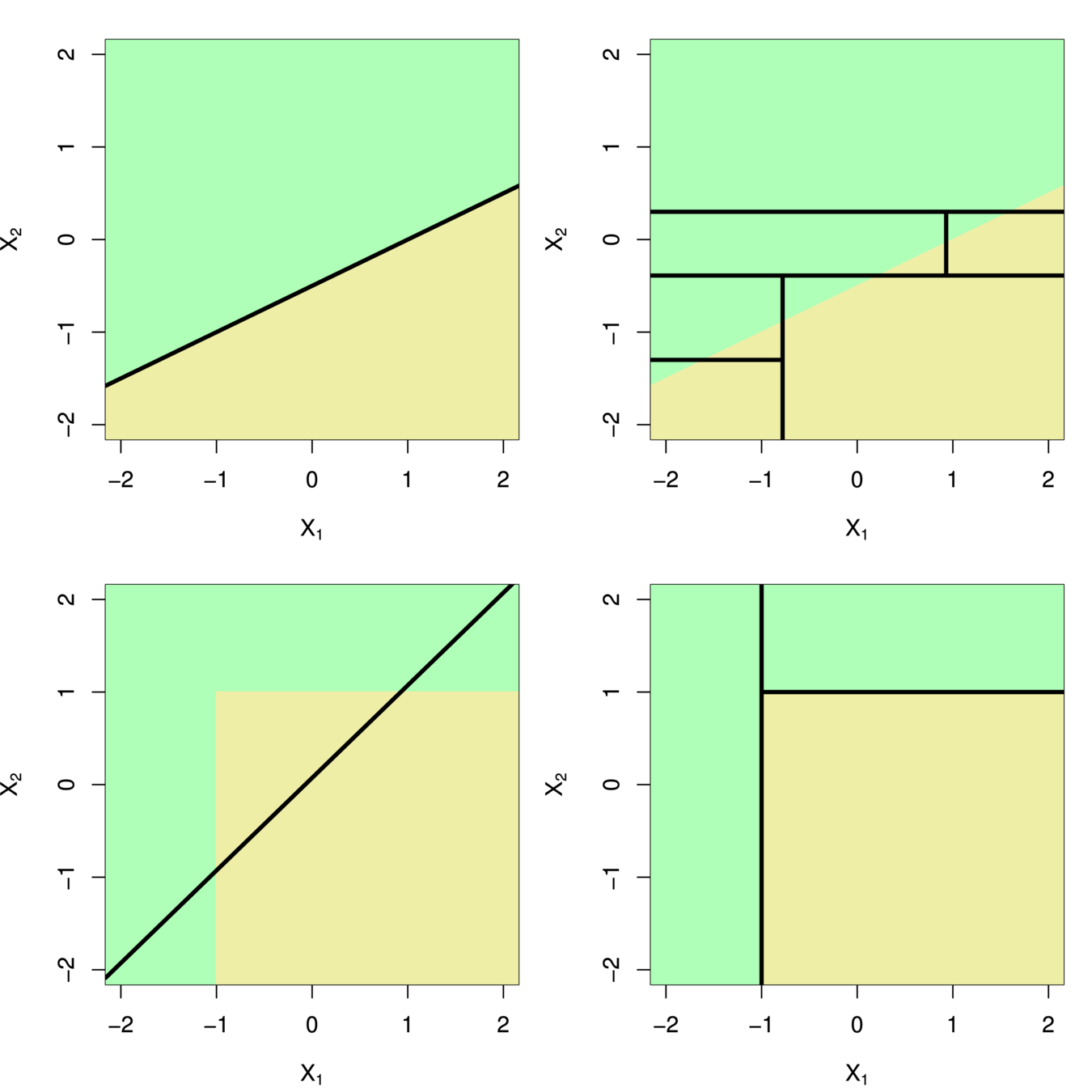
A partition of two-dimensional feature space that could not result from recursive binary splitting.
A perspective plot of the prediction surface corresponding to that tree.
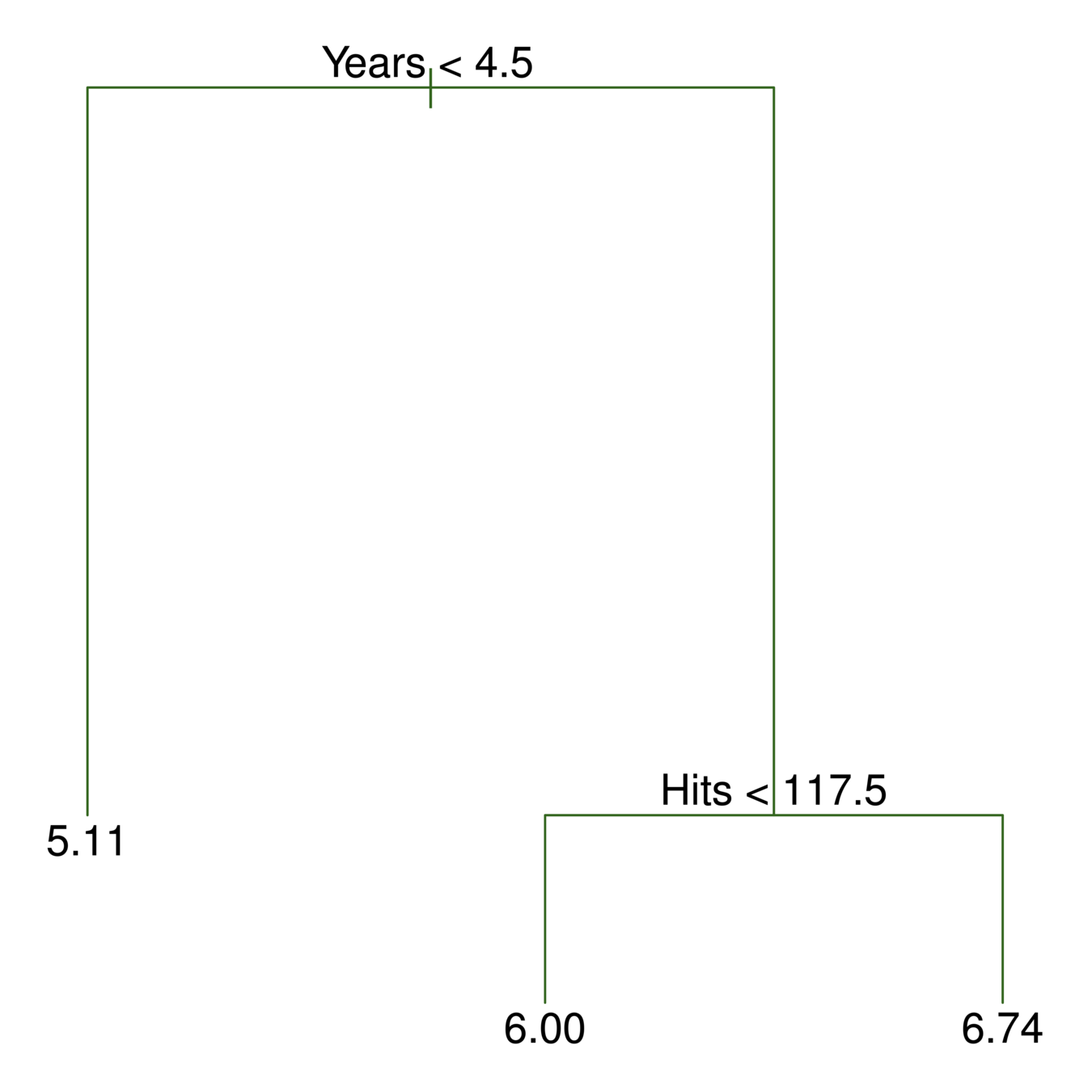
A tree corresponding to the partition in the top right panel.
The output of recursive binary splitting on a two-dimensional example.
Generally we create the partitions by iteratively splitting one of the X variables into two regions
\(t_3\)
\(X_1\)
\(X_2\)
\(t_1\)
\(t_2\)
\(t_4\)
\(R_1\)
\(R_2\)
\(R_3\)
\(R_5\)
\(R_4\)
117.5
4.5
Here we have two predictors and three distinct regions
A classification tree is very similar to a regression tree except that we try to make a prediction for a categorical rather than continuous Y.
For each region (or node) we predict the most common category among the training data within that region.
The tree is grown (i.e. the splits are chosen) in exactly the same way as with a regression tree except that minimizing MSE no longer makes sense.
There are several possible different criteria to use such as the “gini index” and “cross-entropy” but the easiest one to think about is to minimize the error rate.
A large tree (i.e. one with many terminal nodes) may tend to over fit the training data in a similar way to neural networks without a weight decay.
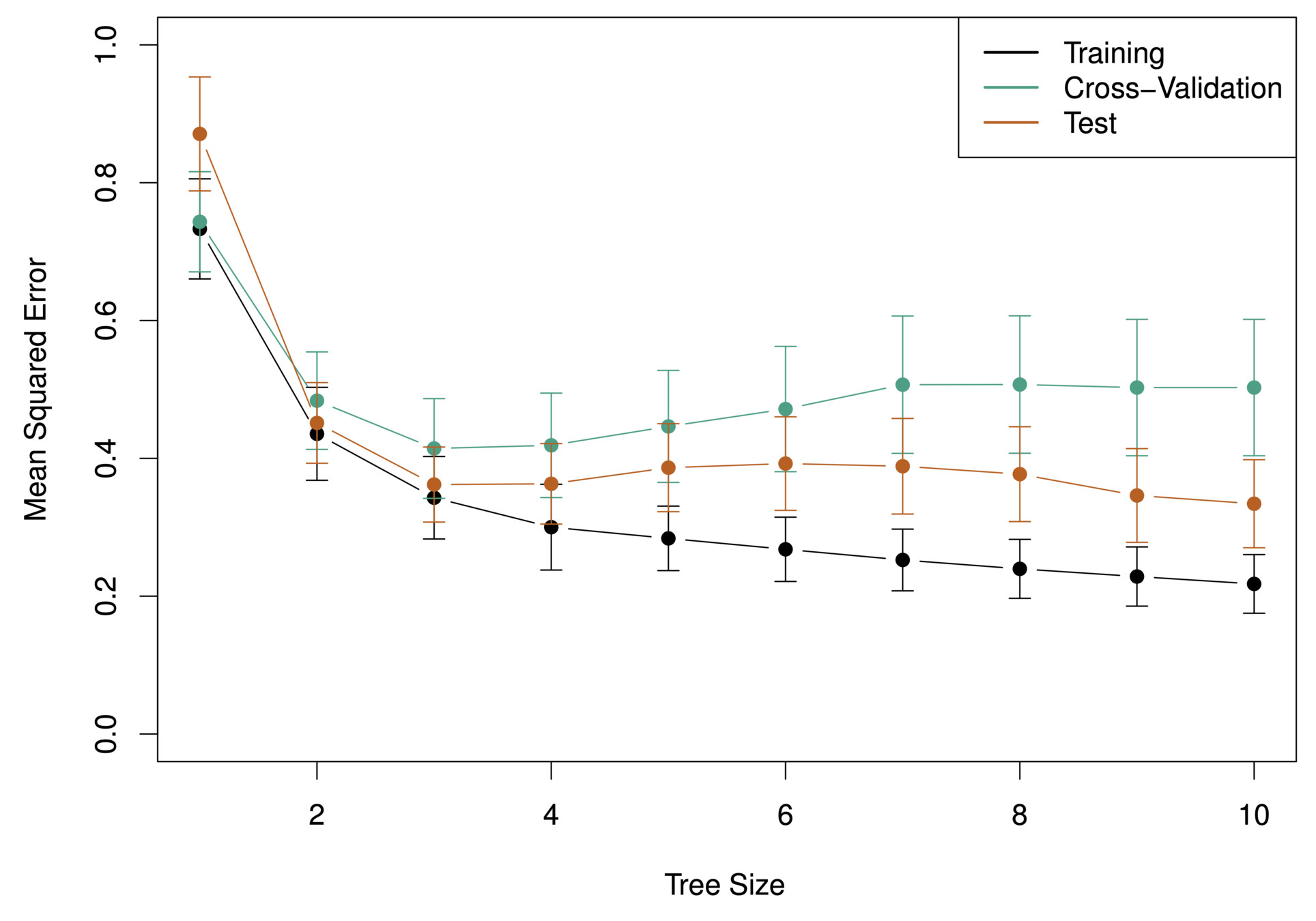
Generally, we can improve accuracy by “pruning” the tree i.e. cutting off some of the terminal nodes.
How do we know how far back to prune the tree? We use cross validation to see which tree has the lowest error rate.
What tree size do we use?
If the relationship between the predictors and response is linear, then classical linear models such as linear regression would outperform regression trees
On the other hand, if the relationship between the predictors is non-linear, then decision trees would outperform classical approaches
| Good | Not so good |
|---|---|
| Highly interpretable (even better than regression) | Prediction Accuracy |
| Plotable | High variance |
| for qualitative predictors (without create dummy variables) | |
| For both regression and classification |
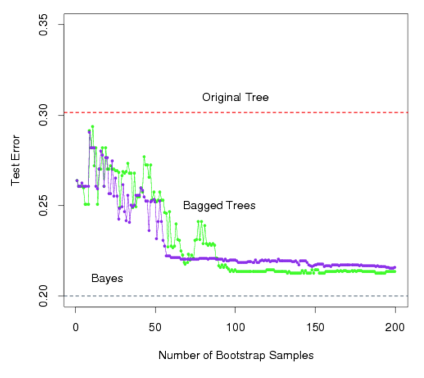
Record the class that each bootstrapped data set predicts and provide an overall prediction to the most commonly occurring one (majority vote).
If our classifier produces probability estimates we can just average the probabilities and then predict to the class with the highest probability.
Green line represents a simple majority vote approach
Purple line corresponds to averaging the probability estimates.
Both do far better than a single tree (dashed red) and get close to the Bayes error rate (dashed grey).
On average, each bagged tree makes use of around two-thirds of the observations.
The remaining one-third of the observations not used to fit a given bagged tree are referred to as the out-of-bag (OOB) observations.
Predict the response for the \(i^{th}\) observation using each of the trees in which that observation was OOB. This will yield around \(\frac{B}{3}\) predictions for the \(i^{th}\) observation, which we average.
This estimate is essentially the Leave One Out (LOO) cross-validation error for bagging, if \(B\) is large
Bagging typically improves the accuracy over prediction using a single tree, but it is now hard to interpret the model!
We have hundreds of trees, and it is no longer clear which variables are most important to the procedure
Thus bagging improves prediction accuracy at the expense of interpretability.
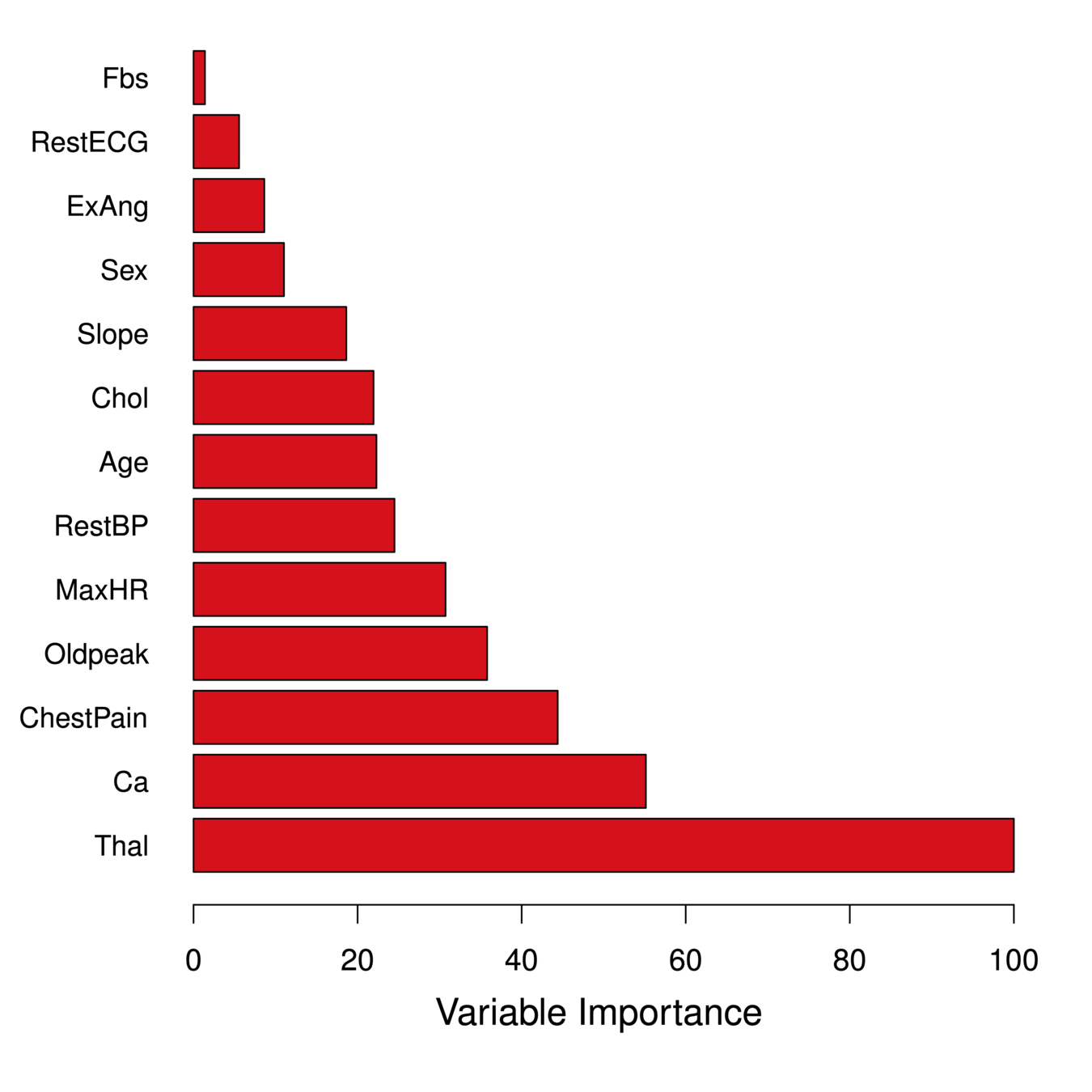
But, we can still get an overall summary of the importance of each predictor using Relative Influence Plots
Relative Influence Plots give a score for each variable.
These scores represents the decrease in MSE when splitting on a particular variable
A number close to zero indicates the variable is not important and could be dropped.
The larger the score the more influence the variable has.
Relative Influence Plots give a score for each variable.
These scores represents the decrease in MSE when splitting on a particular variable
A number close to zero indicates the variable is not important and could be dropped.
The larger the score the more influence the variable has.
age
sex
chest pain type (4 values)
resting blood pressure
serum cholestoral in mg/dl
fasting blood sugar > 120 mg/dl
resting electrocardiographic results (values 0,1,2)
maximum heart rate achieved
exercise induced angina
oldpeak = ST depression induced by exercise relative to rest
the slope of the peak exercise ST segment
number of major vessels (0-3) colored by flourosopy
thal (Thalassemias): 3 = normal; 6 = fixed defect; 7 = reversable defect
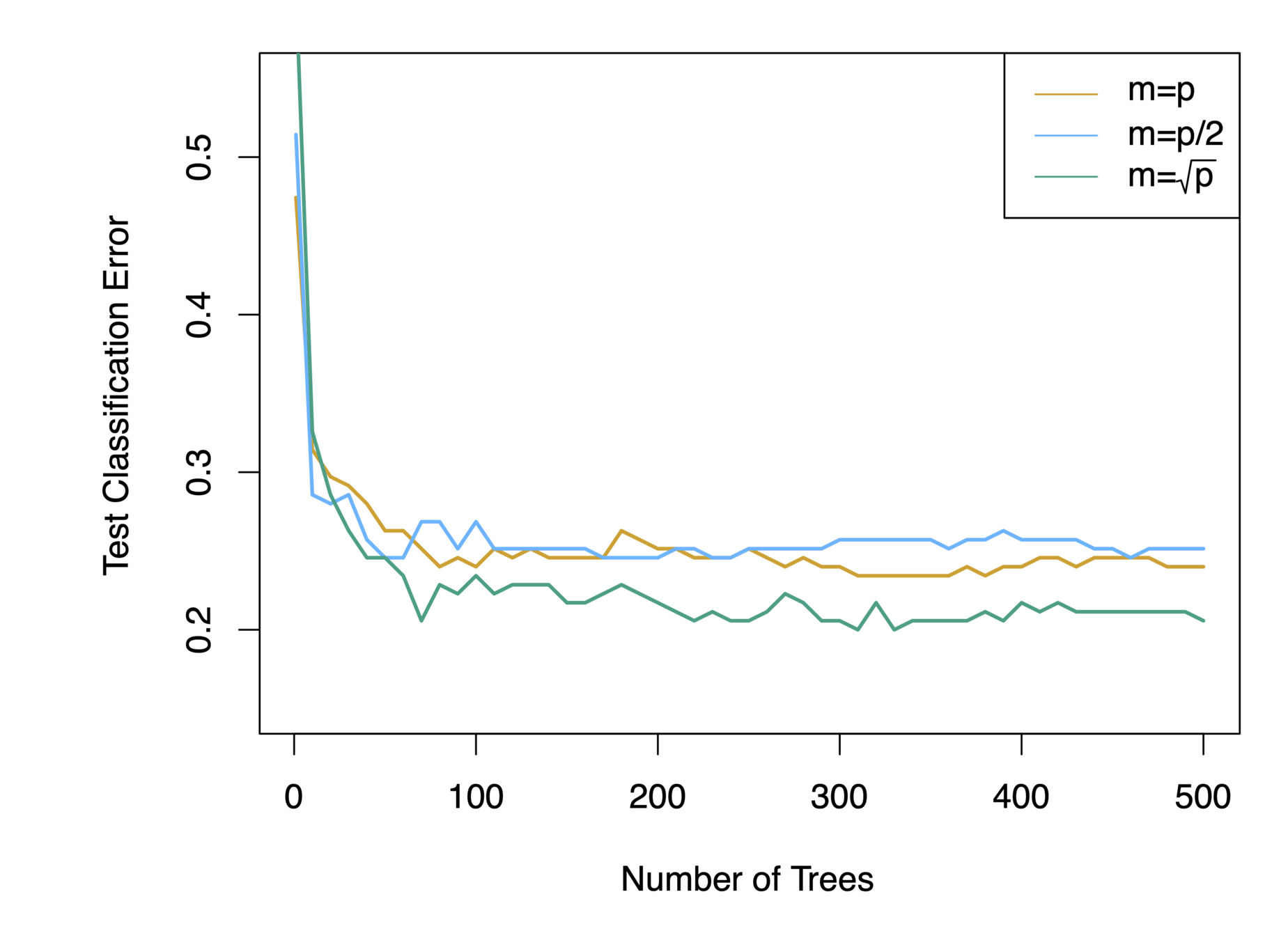
When \(m = p\), this is simply the bagging model.
Building on the idea of bagging, random forest provides an improvement because it de-correlates the trees
Procedures:
Build a number of decision trees on bootstrapped training sample
When building the trees, each time a split in a tree is considered
a random sample of \(m\) predictors is chosen as split candidates from the full set of \(p\) predictors (Usually \(m\approx\sqrt{p}\) )
By Karl Ho
ISDSA Workshop: Gentle Introduction to Machine Learning - Supervised Learning 2/4




