瞿旭民(kevinbird61)
成大資訊所

Apr 26, 2018
@NCKU-IMSLab
Heavy-Hitter Detection Entirely
in the Data Plane
-
Why we need "Heavy-Hitter" detection?
-
Background on "Heavy-Hitter" detection
-
Problem formulation
-
Existed solutions
-
-
The new way - HashPipe Algorithm
-
Inspire from "Space Saving Algorithm", "Count-Min Sketch"
-
-
Evaluation of HashPipe
-
Tuning, accuracy, comparison
-
-
Conclusion
Outline
Part I
What is Heavy-Hitter ( hereinafter called "H.H." ) detection?
Why we need it?
Overview
Heavy hitter: "high-volume traffic" in our large network.
Identifying the "H.H." flows in the data plane is important for several applications:
- flow-size aware routing
- DoS(e.g. Denial of Service) detection
- traffic engineering
Overview (Conti.)
Currently, the measurement on data plane is constrained by line rate (10~100 Gb/s) on target switching hardware, and its limited memory space.
Existing solutions to monitoring heavy items are hard to reach the reasonable correct rate under acceptable resource consumption.
So this paper provide another solution - "HashPipe", to solve this problem from data plane. (P4 + emerging programmable data plane)
Part II
Background of H.H detection
- Problem Formulation
- Overhead on Switch
- Existing solutions
Problem Formulation
- Heavy Hitter
- Flows are larger than a fraction "t" of the total packets seen on the link ("threshold-t" problem)
- = top k flows by size ("top-k" problem)
- Flow granularity
- Decide which data need to collect
- IP address → host
- Transport port number → application
- five-tuple → transport connection
- Decide which data need to collect
- Accuracy
- False positive/ False negative
Overhead on switch
- Calculate overhead on switch, need to consider:
- total amount of memory ( data structure )
- stage number used by switch pipeline
- Limitation on algorithm is the resource of each stage can provide:
- available number of memory access
- computation
Existing Solution
- Packet Sampling
- NetFlow, sFlow : implement in current router
- sampling from network, and transmit the statistics to controller.
-
Streaming Algorithm
- Well-designed data structure, enable data plane dealing with each packet in heavy traffic under limited memory and processing time.
- That make this algorithm very suitable for network monitoring
- Algorithm that dealing with data stream: Sketching , limited memory, and limited processing time per items.
Sketching
- Count sketch
- Count-min sketch
Using "per-packet" operation, like hashing the packet headers, increase counter of hashed locations, and find out the minimal or median value among the small group of hashed counters.
But these sketching algorithm do not track the "flow ID" of packets; And hash collisions make it challenging to "invert" (e.g. 轉換) the sketch into the constituent flows and counters.
So we need a solution that can decode keys from hash-based sketches and also it can apply on the fast packet-processing path - "Counter-based algorithms".
Counter-based algorithm
- Focus on measuring the heavy items, maintaining a table of "flow IDs" and corresponding "counts".
- Employ "per-counter" increment and subtraction operations, but all counters in the table are updated during some flow insertions. (e.g. NOT immediately update)
- And there have another challenge when update several counters within a same stage, because it will take a lot of processing time on each packet.
- Another counter-based algorithm - Space saving algorithm prevail.
Space saving
Only use O(k) counters to track down "k" heavy flows, and reach the best memory utility in heavy-hitter algorithm.
How does it work:
- Only update one counter per-packet.
- Need to find out the minimal counter in table (But this feature is not supported in emerging programmable hardware)
- Maintain data structure: sorted linked-list, or priority queue, will have several memory access in per-packet processing time.
- So we need a more efficient algorithm for heavy-hitter: "HashPipe" !
Space saving (illustration)
→ Flow ID = k (incoming packet)
→ Flow ID = k (incoming packet)
→ Flow ID = k (incoming packet)
| k | 1 |
|---|---|
| k | 2 |
|---|---|
| e | 3 |
| k | 3 |
|---|---|
| e | 3 |
| j | 1 |
|---|---|
| i | 4 |
| k | 2 |
|---|---|
| i | 4 |
Part III
HashPipe Algorithm
HashPipe Algorithm
First thing we know is: HashPipe is derived from "Space saving algorithm", and have some modification on it to fit with switch hardware implementation.
Track the k-heaviest items, maintain a table with m slot with corresponding key and counter, with empty initial state.
And now we can see how to derive this algorithm !
Sampling for the minimum
With the knowledge of space saving , we can start some simple modification!
First, we choose a number "d" as the number of sampling, so we can constrain the memory access number into "d".
So that we can have a modified version - "HashParallel", which have some features:
- constrain table size with "m".
- then using number of "d" different hash function to deal with each incoming packet.
- space saving need to deal with the entire table, now only need to deal with "d" times.
Progress to HashPipe
In HashParallel, we have reduce the number of table slots from entire table into "d" to reduce the number of memory access.
However, there still have "d" times for read, and 1 time for write per-packet. And we know that in emerging switch hardware, it's impossible to do several read/write in the same table.
How to solve it? Can we reduce access times to 1 read and 1 write ?
So we need "multiple stages" of hash table !
After we reduce the table slots, now we separate "d" slots into "d" stages to eliminate "multiple read/write", each stage only need to do read/write just for 1 time.
And each object's entry point will be decided by hash function.
So we can divide into 2 steps:
- Find the minimum value in each stage ( among "d" slots )
- Update counter ( Accomplish through "packet recirculation", but recirculation will impact the bandwidth of switch's pipeline itself ), exploit "metadata" to carry related information between stages.
Progress to HashPipe (conti.)
HashPipe Algorithm
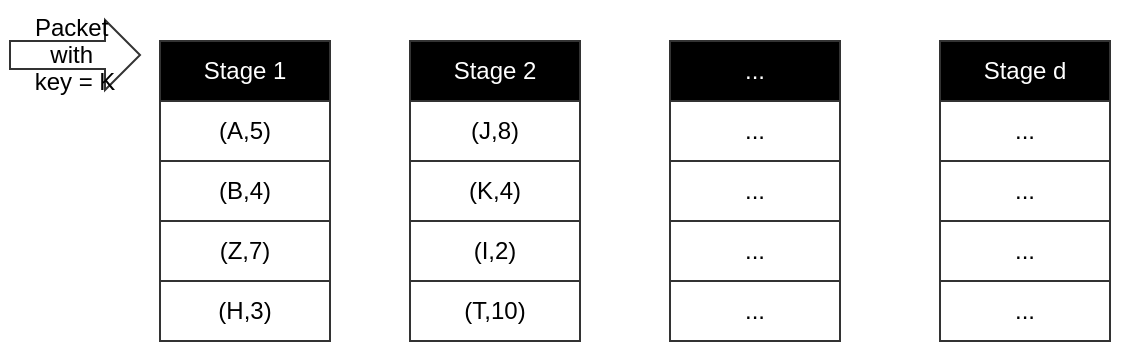
Pipeline with d stages, and each stage dealing with one time read/write
In each stage, packet will be hashed into a location and compare the result.(If in first stage, always do the replacement.)
HashPipe Algorithm
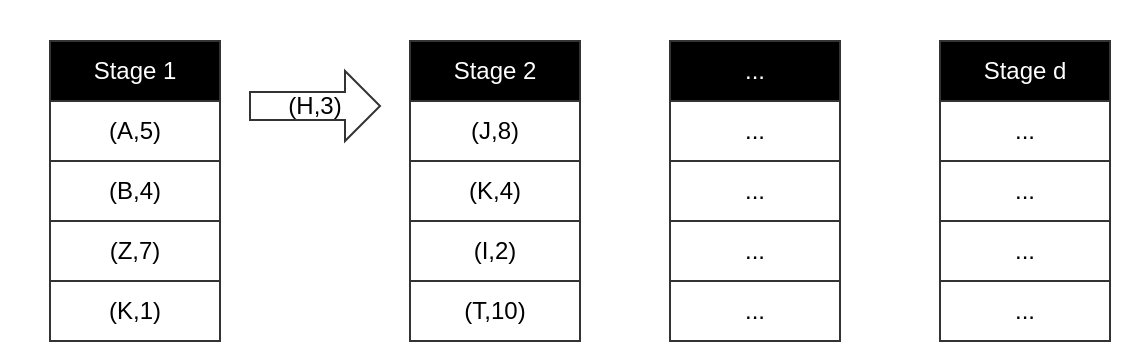
And the one which has been evicted, will have its key and count value together and go to the next stage.
Part IV
Evaluation
Several aspects on evaluation
- Tuning HashPipe - Adjust the table size "d" (Notice: also impact stage number)
- Accuracy - Evaluate performance in isolated environment
- Comparison - Compare with existing method ( e.g. packet sampling, sketching ... ), using result from "Step 2" represent HashPipe.
- Performance of HashPipe which under ideal condition.
Experiment Setup
This paper use two real traces (e.g. network flows):
-
First traces is recorded from ISP backbone link (2016, 10 Gb/s ), and using 5-tuple to detect heavy-hitter. Record duration is about 17 minutes, include 400 million packets.
- Separate into 50 chunks, each chunks duration is 20 seconds, which contain 10 million packets, and average contain 400,000 5-tuple flows.
- Second one is record from data center (2010), using source/destination IP to detect heavy-hitter. Record duration is about 2 and a half hours, include 100 million packets. ( nearly 10K packets per second, 300 flows.)
Experiment Setup
| ISP backbone | Data Center | |
|---|---|---|
| record date | 2016 | 2010 |
| duration | 17 min | 2.5 hr |
| detection | 5-tuple | src, dest IP |
| total packets | 400 million | 100 million |
Experiment Method
Using high frequency packet rate to examine the "correct rate" in 1 second duration from HashPipe applying on both traces.
Packet size = 850 bytes
Network utilization = 30%
switch = 1GHz, 48 ports of 10Gb/s => 20 million packets per second (entire switch), 410 k packets per second ( single link ), and we will set "second" as report duration.
Experiment Index
After setting experiment method, we can have some useful index to observe.
3 useful index:
- false negatives (heavy flows that are not reported)
- false positives (non-heavy flows that are reported)
- average estimation error (error for heavy flows, like it's count value is bigger than actual value)
And then we can start evaluation with different aspect mention before!
Part IV - (1)
Evaluation - Tuning HashPipe
(Adjust table size)
Tuning HashPipe
In this case, the parameter is the table stages: "d".
Consider under limited memory "m":
If "d" increase, then the number of heaviest key increase, too.
But "m" is fixed, so when "d" increase, the number of slots in each stage will decrease. That cause hash collision more frequently, and also increase the times of duplication.
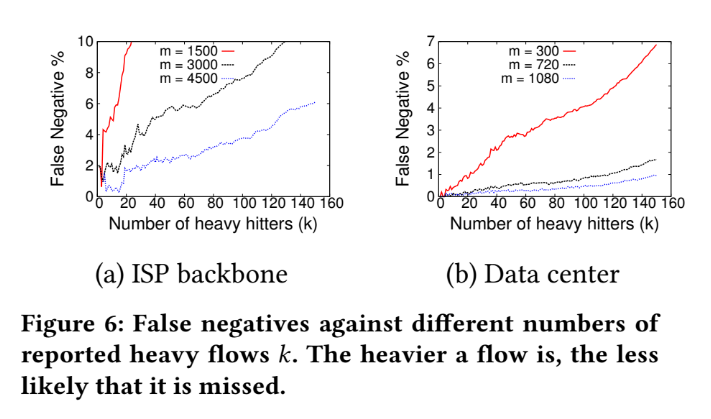
Tuning HashPipe - false negative
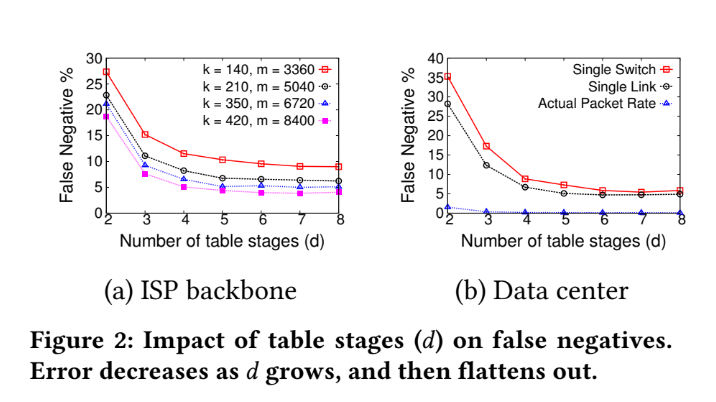
Tuning HashPipe - duplicate entries

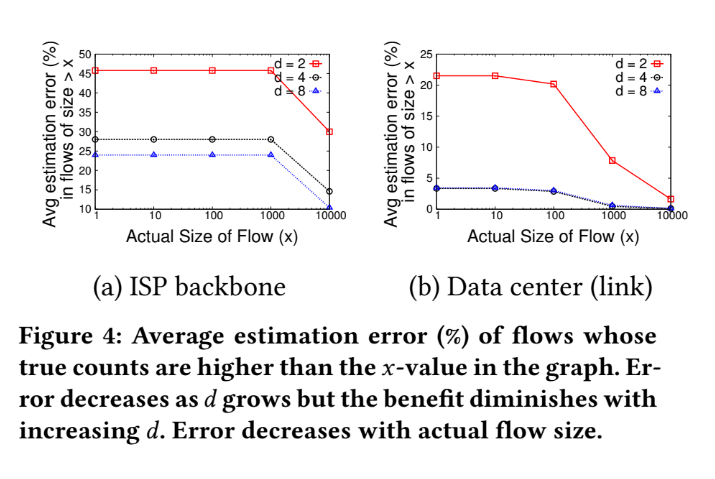
Tuning HashPipe - estimation error
P4 code in action stage
# p4_14
action doStage1(){
mKeyCarried = ipv4.srcAddr;
mCountCarried = 0;
// Get the location from hash table, and store into mIndex
modify_field_with_hash_based_offset(mIndex,0,stage1Hash,32);
// read the key and value at that location
mKeyTable = flowTracker[mIndex];
mCountTable = packetCount[mIndex];
mValid = validBit[mIndex];
// check for empty location or different key
mKeyTable = (mValid == 0) ? mKeyCarried : mKeyTable;
mDif = (mValid == 0) ? 0 : mKeyTable - mKeyCarried;
// update hash table - write back
flowTracker[mIndex] = ipv4.srcAddr;
packetCount[mIndex] = (mDif == 0) ? mCountTable+1 : 1;
validBit[mIndex] = 1;
// update metadata carried to the next table stage
mKeyCarried = (mDif == 0) ? 0 : mKeyTable;
mCountCarried = (mDif == 0) ? 0 : mCountTable;
}P4 code in action stage (conti.)
# p4_14
action doStage2(){
...
mKeyToWrite = (mCountInTable < mCountCarried) ? mKeyCarried : mKeyTable;
flowTracker[mIndex] = (mDif == 0) ? mKeyTable : mKeyToWrite;
mCountToWrite = (mCountTable < mCountCarried) ? mCountCarried : mCountTable;
packetCount[mIndex] = (mDif == 0)? (mCountTable + mCountCarried): mCountToWrite;
mBitToWrite = (mKeyCarried == 0) ? 0 : 1;
validBit[mIndex] = (mValid == 0) ? mBitToWrite : 1;
...
}Part IV - (2)
Evaluation - Accuracy of HashPipe
False negative
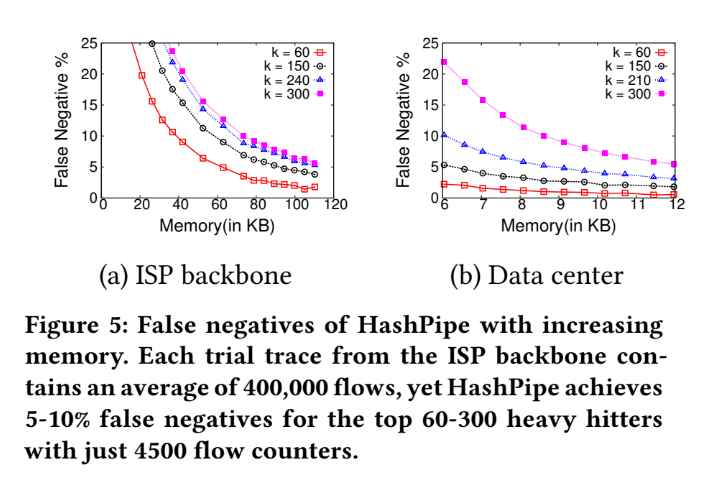
Accuracy of HashPipe
Base on the result in Part I, pick d=6 to go on accuracy test.
We can adjust memory usage among different numbers of reported heavy hitters "k".
We can see some phenomena:
1. After 80 KB (About 4500 counters) memory usage, the improvement between different case in ISP backbone have become smaller.
2. And some result happen in 9 KB (About 520 counters) memory usage in Data Center.
False negative - heavy flow
False positive
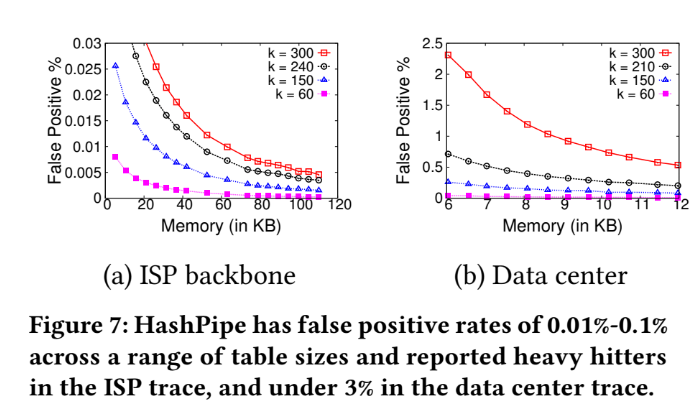
Analyze with false positive:
- See the figure in previous page, the rate of false positive is very low in ISP backbone.
- The reason is that there are lots of small flow on ISP backbone, so the false positive (a.k.a report a non-heavy flow as heavy one ) is low.
- And when reach 80 KB memory usage , the reduction of false positive rate come to ease.
Part IV - (3)
Evaluation -
Compare HashPipe with existing solution
HashPipe v.s. Existing solution
Compare with the methods : sampling and sketching (which also can apply on switch hardware to calculate the counters)
Experiment method:
- Using same amount of memory, and use k=150 (top 150 flow) to measure.
- And now we only do experiment on ISP backbone.
False negative
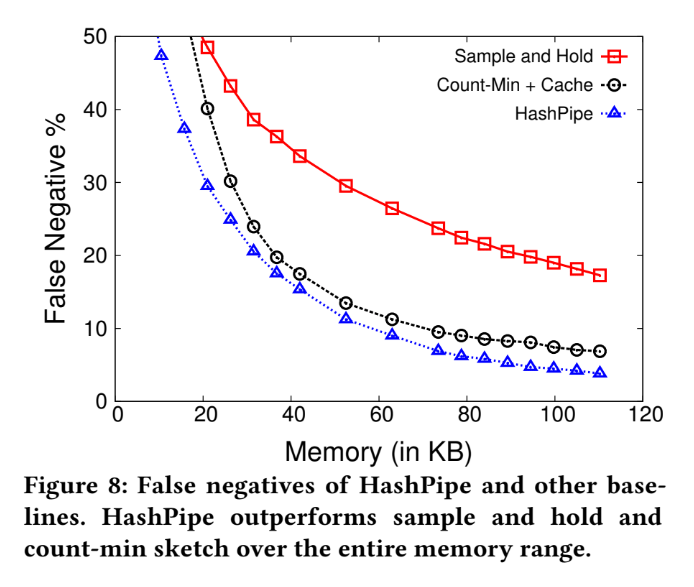
Method (1) : Sample and Hold
- Transform the flow table into list form
- Let all the new-coming packet can search the entire table, and be able to add new entry until fill up the entire memory.
- And the value of probability of sampling will be according to "available flow table size".
Method (2) : Count-min sketch
- Count-min sketch augmented with a "heavy flow cache"
- Similarly with "count-min sketch", but using flow cache to retain "flow key" and "exact count"
(Original sketching algorithm doesn't provide flow ID of packet for tracking)
Average estimation error
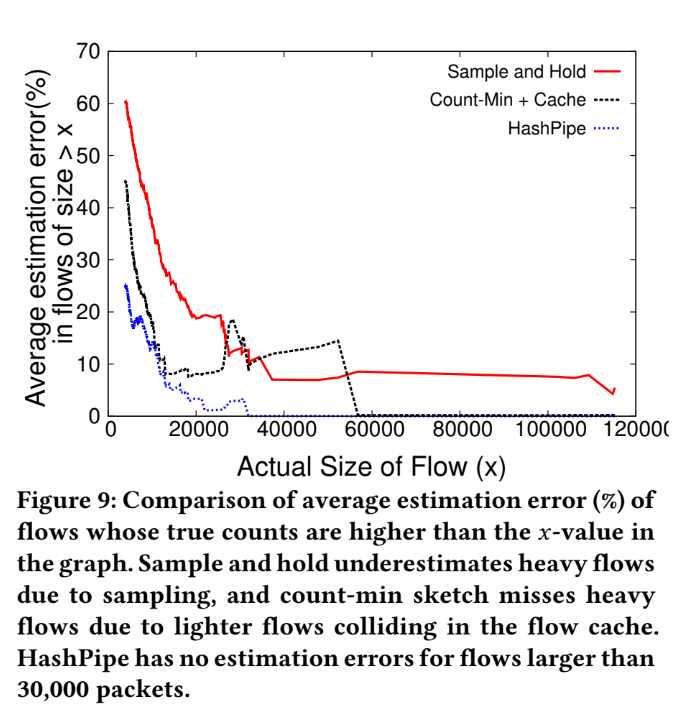
Analysis
Run those different method with same memory usage : 26 KB
The estimation error made by Simple & Hold:
- miss first set of packets from a heavy flow ( because of not sampling the flow early enough)
- miss the flow entirely due to not sampling or the flow table becoming full and drop
The estimation error made by Count-min Sketch:
- Unable to distinguish difference between heavy and light when hash collision occur.
- This probably cause the problem which "light flow" occupied the space of "heavy flow" and cause the estimation error.
Part IV - (4)
Evaluation -
Compare HashPipe with idealized schemes
HashPipe v.s Idealized Schemes
Compare with "Space saving algorithm" and "HashParallel".
There are some reason can cause the performance of "Space saving" will outperform "HashPipe":
- HashPipe may eliminate the key which heavier than the minimum key in table, which cause missing heavy item.
- The mechanism may let lots of duplicated flow keys retain in table, and cause heavy flow be dropped among lots of duplication.
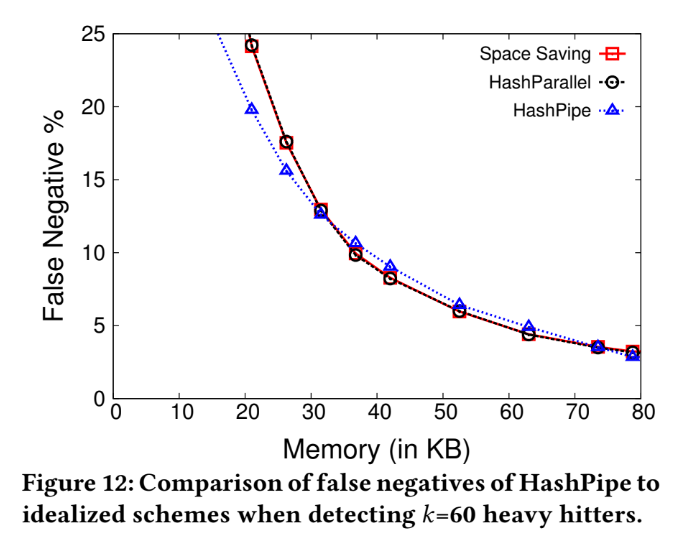
False negative, k=60
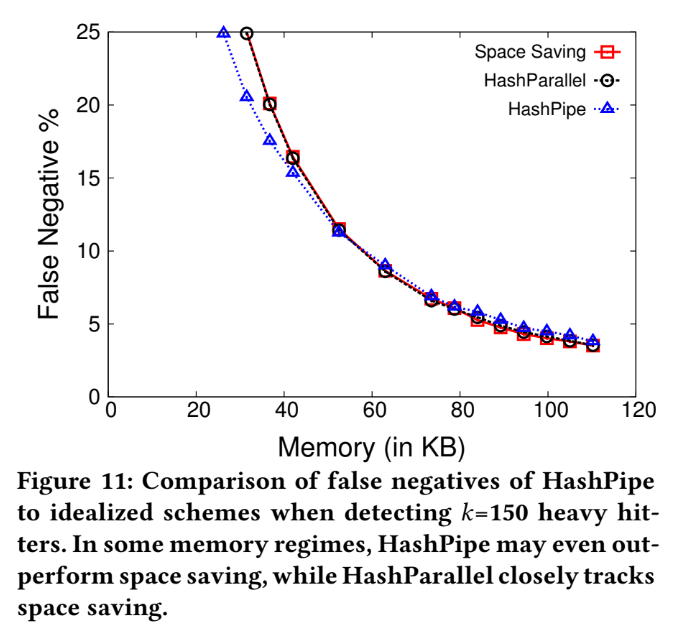
False negative , k=150
HashPipe v.s Space saving
Using two scenario: k=60,150 with different memory size to compare their false negative rate.
Among these two scenario, we can see two features:
- When the false negative rate is lower than 20%, the performance from 3 algorithms are similar with each other.
- But HashPipe use relatively small memory to reach the same false negative rate.
HashPipe v.s Space saving (conti.)
Why the ability of fetching heavy items in space saving is poorer than HashPipe?
- HashPipe treat each new entry in table, all its count value of flow key will start from 1, not inherit from the replaced.
- And in space saving, it will using the count value from replaced one, cause some problems:
- this key isn't correspond to maximum, but it replace the one should have been to a heavy flow.
- And this value isn't its real count value, using space saving will get the result which much larger than its original count value.
In space saving table ...
For k=150, we using a memory sizes (m = 1200) smaller than thresholds ( m = 2500), and incrementing a counter for each packet may result in catching up to a heavy flow.
Which leading to significant false positives, and may evicting truly heavy flows from the table.
False negative (Special Case)
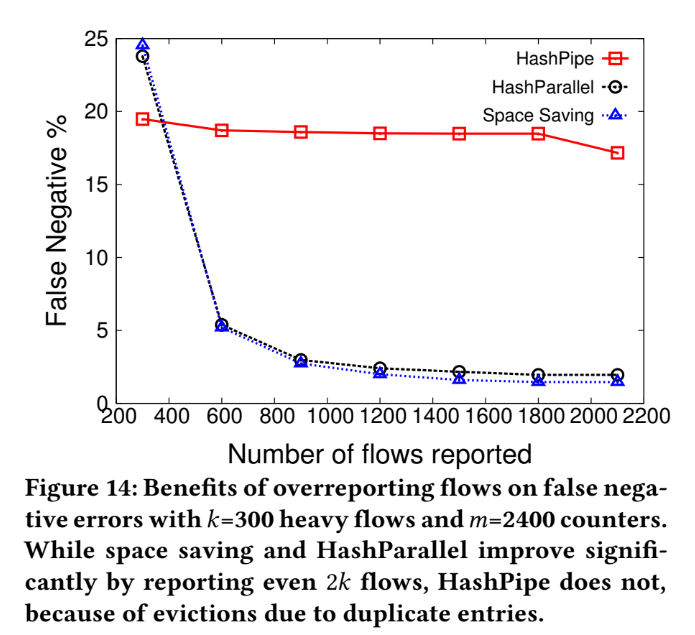
Duplicated key impact on table
We use the parameter : k=300, m=2400 as our experiment environment.
Due to duplicated key occupying the table, which cause HashPipe having a high false negative rate.
Part V
Conclusion
Some Highlights
- HashPipe Algorithm
- Using hashing table mechanism in pipeline to track "heavy flow", and efficiently eliminate the "lighter flow" by time.
- Provide a new algorithm that fit in emerging switch architecture, let it enable to analysis the "heavy flow" when packet pass through in real-time.
- Using P4 to implement its prototype
- Using real network traces to experiment, make the proof of accuracy of this HashPipe algorithm.
Reference
Question?




Heavy-Hitter Detection Entirely in the Data Plane
By Kevin Cyu
Heavy-Hitter Detection Entirely in the Data Plane
P4 Scenario on ISP backbone and data center.




