Optimizing
Gradient Descent
Kian Paimani
Zakarias Nordfäldt-Laws
June 2018
PERFORMANCE ENGINEERING
Recap: Gradient Descent
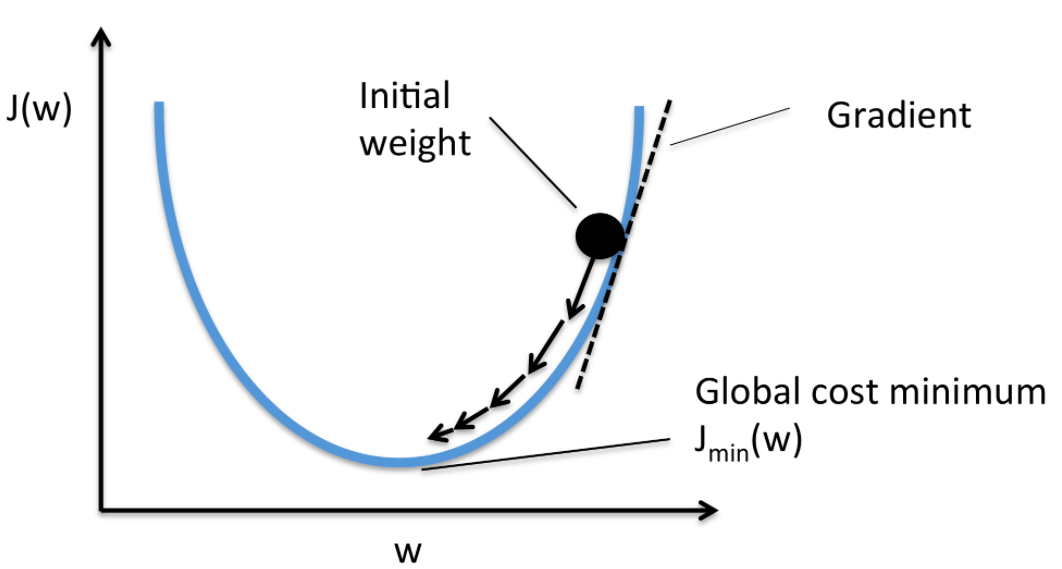
J(\theta) = \displaystyle\frac{1}{m}\sum_{t=1}^{m}(h_\theta(x^{(i)}) - y^{(i)})^2
- Final Algorithm: ADAM
Recap: Goals
- Final Algorithm: ADAM
- Reach the max Iteration/sec possible
- Preserving the algorithm's validity
-
Parallelization + Optimization
- CPU / GPU
Reference Implementation
for (i=1; i<iterations+1; i++){
for(z=0; z<length; z+=batch_size) {
update_gradient_batch(/* ... */);
for (n = 0; n < dim; n++) {
/* Eventually, update the weight */
par->weights[n] += (alpha * m_hat) / (sqrt(r_hat) + eps);
}
}
}void update_gradients_batch(){
for(i=start; i<start+batch_size; i++){
for (n=0; n<dim; n++) {
/* 1. Make a prediction */
/* 2. Compute error */
/* 3. Calculate gradient using the cost function */
}
}
}Analytical Model
T_{exec} = Iter_{gradient} * Gradient\_Update \bigg[ (\#_{compute} * T_{compute}) + (\#_{mem} * T_{mem}) \bigg]
+ Iter_{weight} * Weight\_Update \bigg[ (\#_{compute} * T_{compute}) + (\#_{mem} * T_{mem}) \bigg]
+ T_{overhead}
Iter_{gradient} = (iteration*\frac{data\_points}{batch\_size})
Iter_{weight} = (iteration*\frac{data\_points}{batch\_size}*dim)
Analytical Model
Iteration over all data
Setup
Finalize
Gradient\_Update
Weight\_Update
Gradient\_Update
Weight\_Update
Gradient\_Update
Weight\_Update
Small Batch_size
Large Batch_size
CPU Based Parallelization
/* Initial Version - Generic Gradient Descent */
void gradient_descent(struct parameters *par);
void stochastic_gradient_descent(struct parameters *par);
/* ADAM Versions */
void adam(struct parameters *par);
void adam_seq_opt(struct parameters *par);
void adam_data_opt(struct parameters *par);
void adam_omp(struct parameters *par);
void adam_omp_simd(struct parameters *par);
CPU Based Parallelization
-
adam_seq_opt()
-
Loop unrolling, Function removal, Code motion etc.
-
-
adam_data_opt()
-
cache optimization by better data access pattern.
-
CPU Based Parallelization
-
adam_omp()
-
2 loops exposed
-
Iteration over all data
Setup
Finalize
Gradient\_Update
Weight\_Update
Setup
Finalize
Gradient\_Update
Weight\_Update
CPU Based Parallelization
-
adam_omp_simd()
for (i=1; i<iterations+1; i++){
for(z=0; z<length; z+=MIN(batch_size, length-z)) {
/* ... */
#pragma omp parallel
{
#pragma omp for
for(n=z; n<MIN(z+batch_size, length); n++){
for (a=0; a<dim-7; a+=8) { /* Vectorized Execution: Calculate Guess */ }
error = par->Y[n] - guess;
for (a=0; a<dim-7; a+=8){ /* Vectorized Execution: Update Gradients */ }
}
#pragma omp critical
{
/* Vectorized Execution: Reduction */
}
#pragma omp barrier
#pragma omp for schedule(static) private(n, m_hat, r_hat)
for (n=0; n<dim; n++) { /* Update weights */}
}
}
}GPU Based Parallelization
/* GPU Versions */
void adam_cuda_global_mem(struct parameters *par);
void adam_cuda_global_mem_unrolled(struct parameters *par);
void adam_cuda_shared_mem(struct parameters *par);
void adam_cuda_shared_mem_stream(struct parameters *par);
void adam_cuda_shared_mem_stream_pinned(struct parameters *par);
void adam_cuda_shared_mem_stream_pinned_unrolled(struct parameters *par);
GPU Based Parallelization
-
adam_cuda_global_mem()
Setup
Finalize
Gradient\_Update
Weight\_Update
Implies:
Bigger batches => Better Speedup
GPU Based Parallelization
-
adam_cuda_shared_mem()
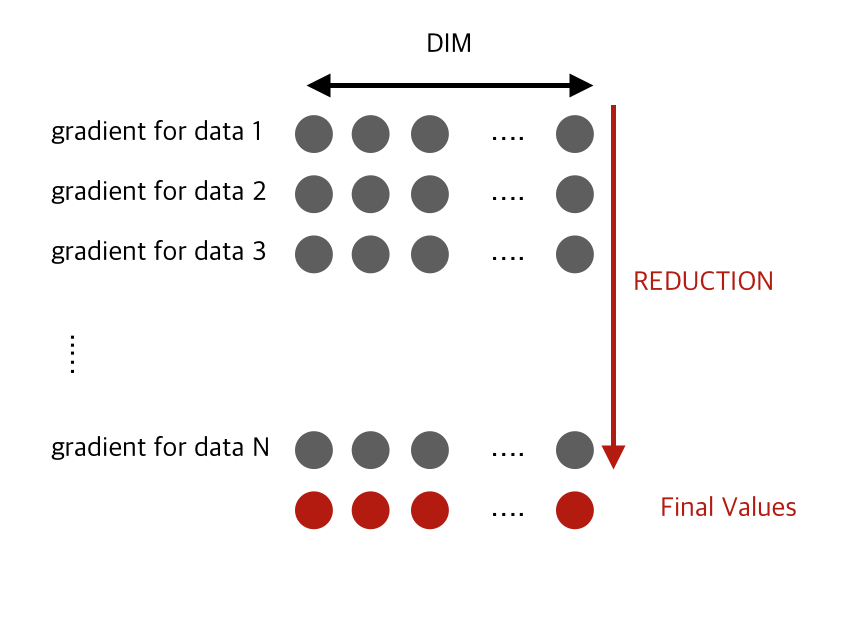
- Everything copied back to CPU.
- Then reduced to final batch results
GPU Based Parallelization
- Little is done on each thread.
- Huge data transfers.
- GPU Performance analysis with counters:
- High level goal: computation / Mem ratio
- Global Mem: 70 / 30
- High level goal: computation / Mem ratio
GPU Based Parallelization
-
adam_cuda_shared_mem()
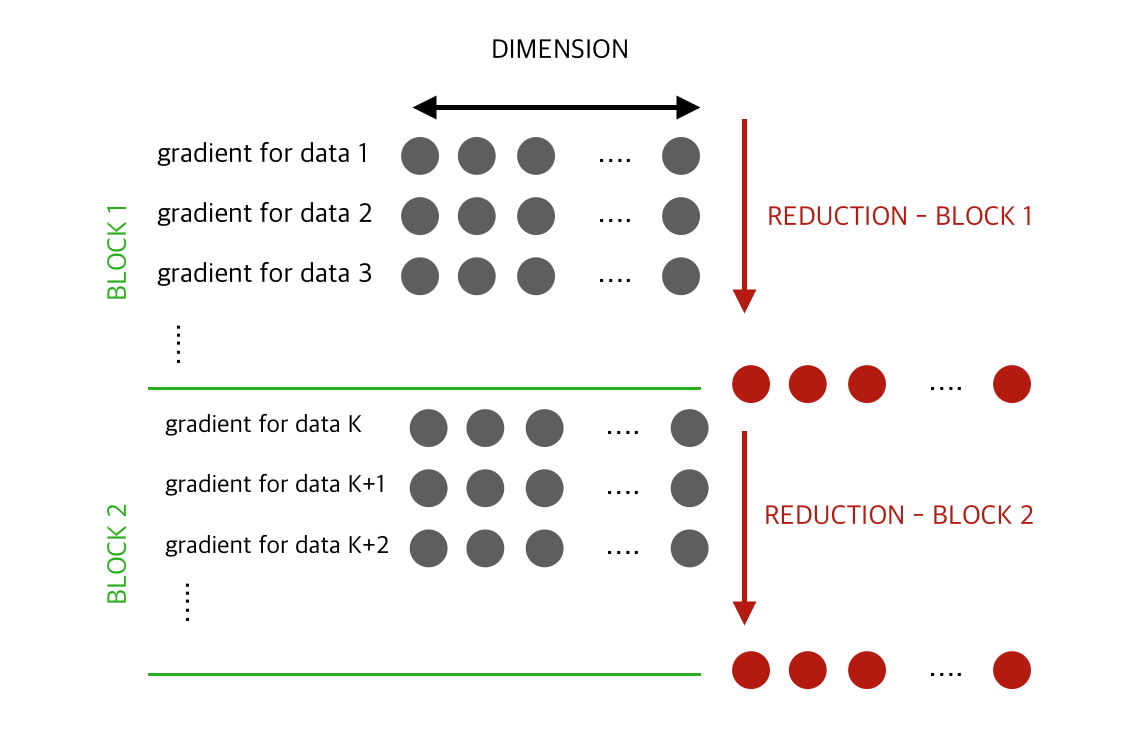
- 2 Phase reduction
- Partial reduction in GPU. minimal wrap up in CPU.
- Less copy
- More device utilization
- Shared Mem: 64 / 36
GPU Based Parallelization
-
adam_cuda_shared_mem_stream()
Copy\_To\_Device
Copy\_To\_Device
Copy\_To\_Device
Copy\_To\_Device
Copy\_To\_Device
Ratio: 58 / 42
GPU Based Parallelization
-
adam_cuda_shared_mem_stream_pinned_unrolled()
- Host Memory: Pagable
- Device Preferred Memory: Pinned
- Reduces Copy time by a factor of 2~4
- Needs redundant data on host
- New Ratio: 52 / 48
-
Unroll the kernel execution
- Not as much improvement as we expected...
GPU Based Parallelization
adam_cuda_shared_mem_stream_pinned_unrolled()
-
Unrolling:
- Less API overhead, not enough!
-
Streaming
- Async copy: a much slower memory transfer
Copy\_To\_Device
Results: Base

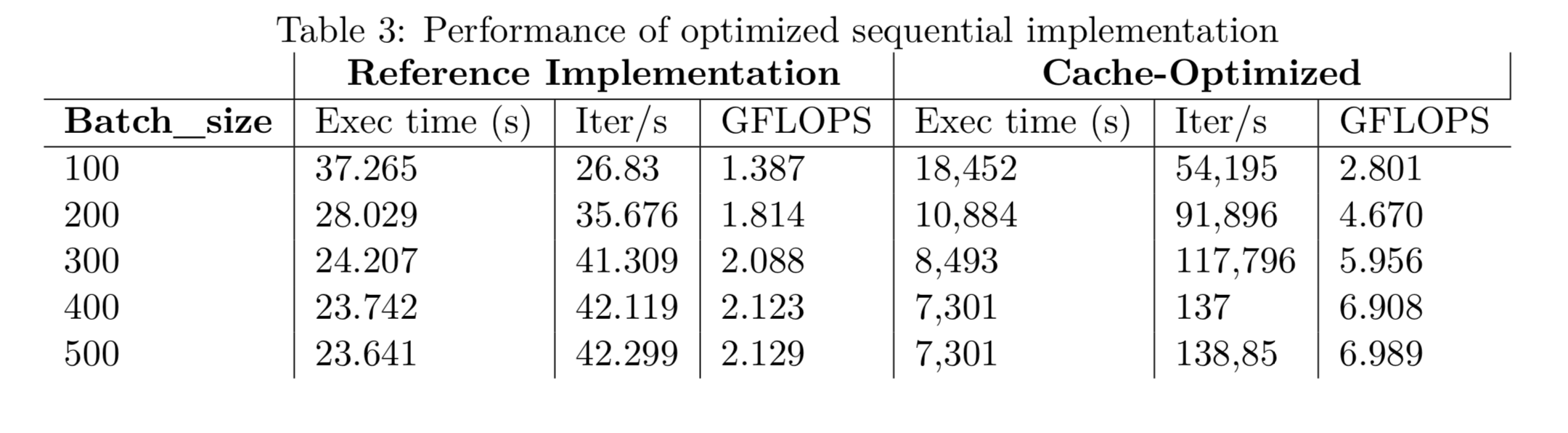
Results: Optimized

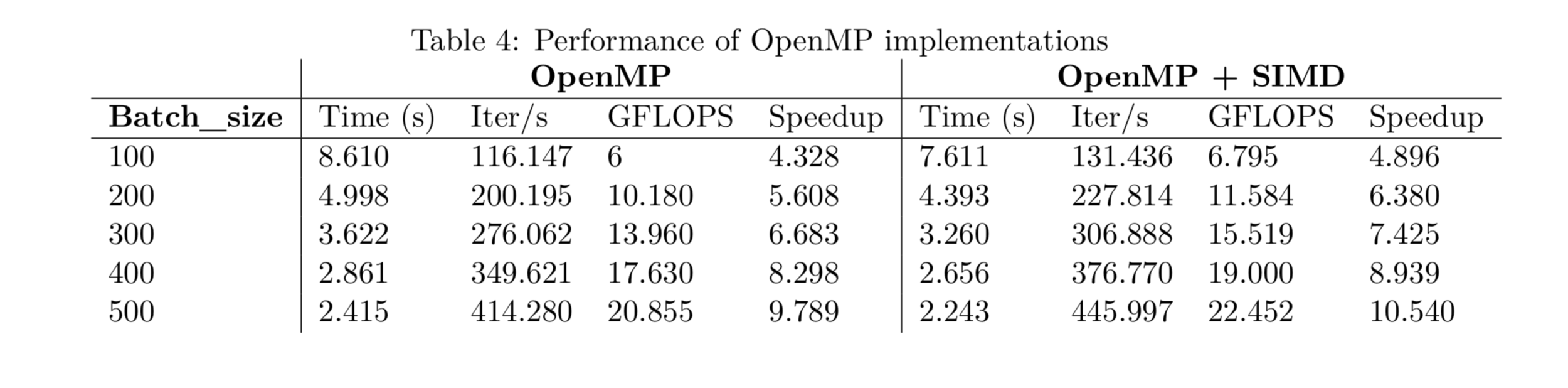
Modeling: Some Explanation
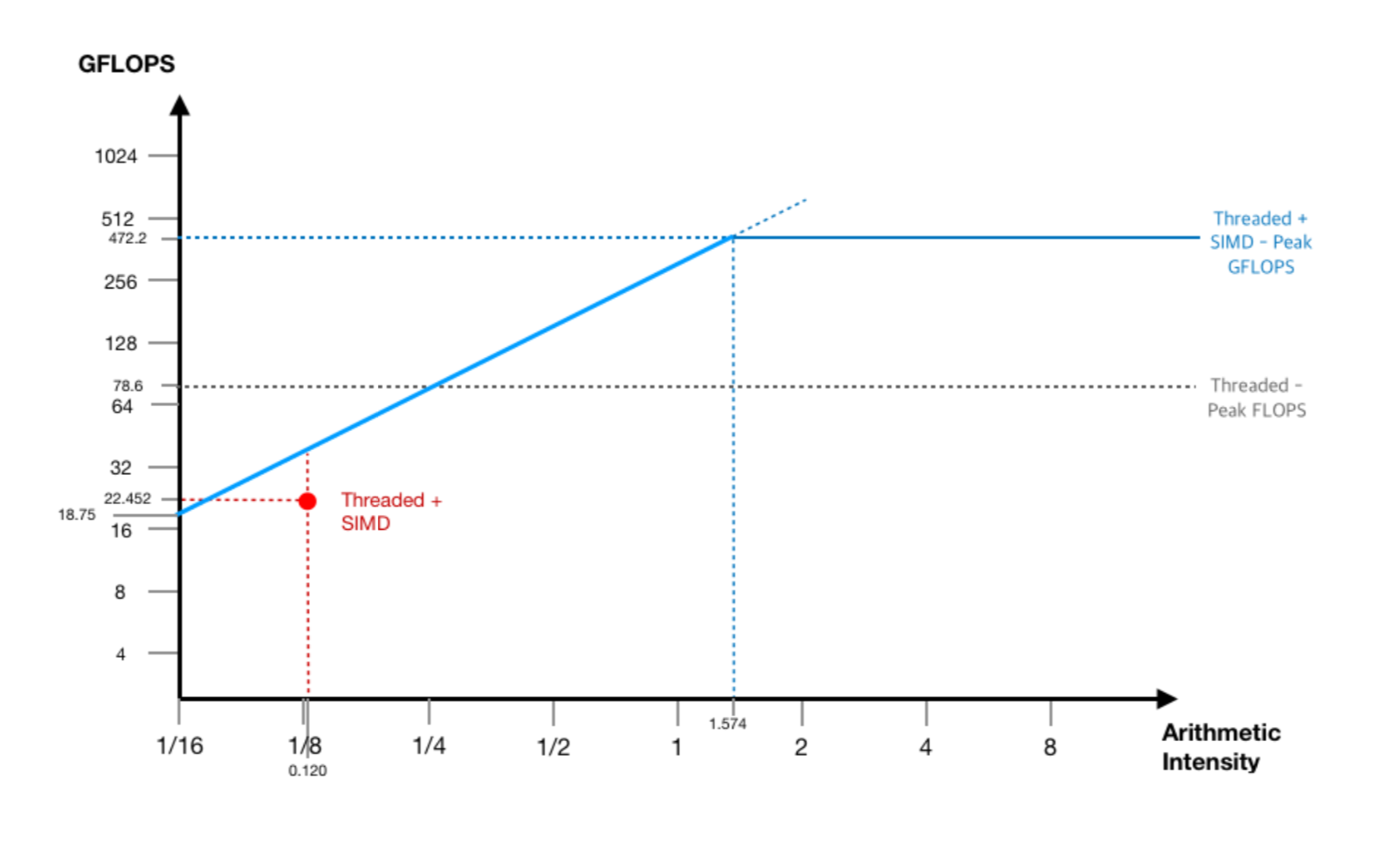
Modeling: Some Explanation
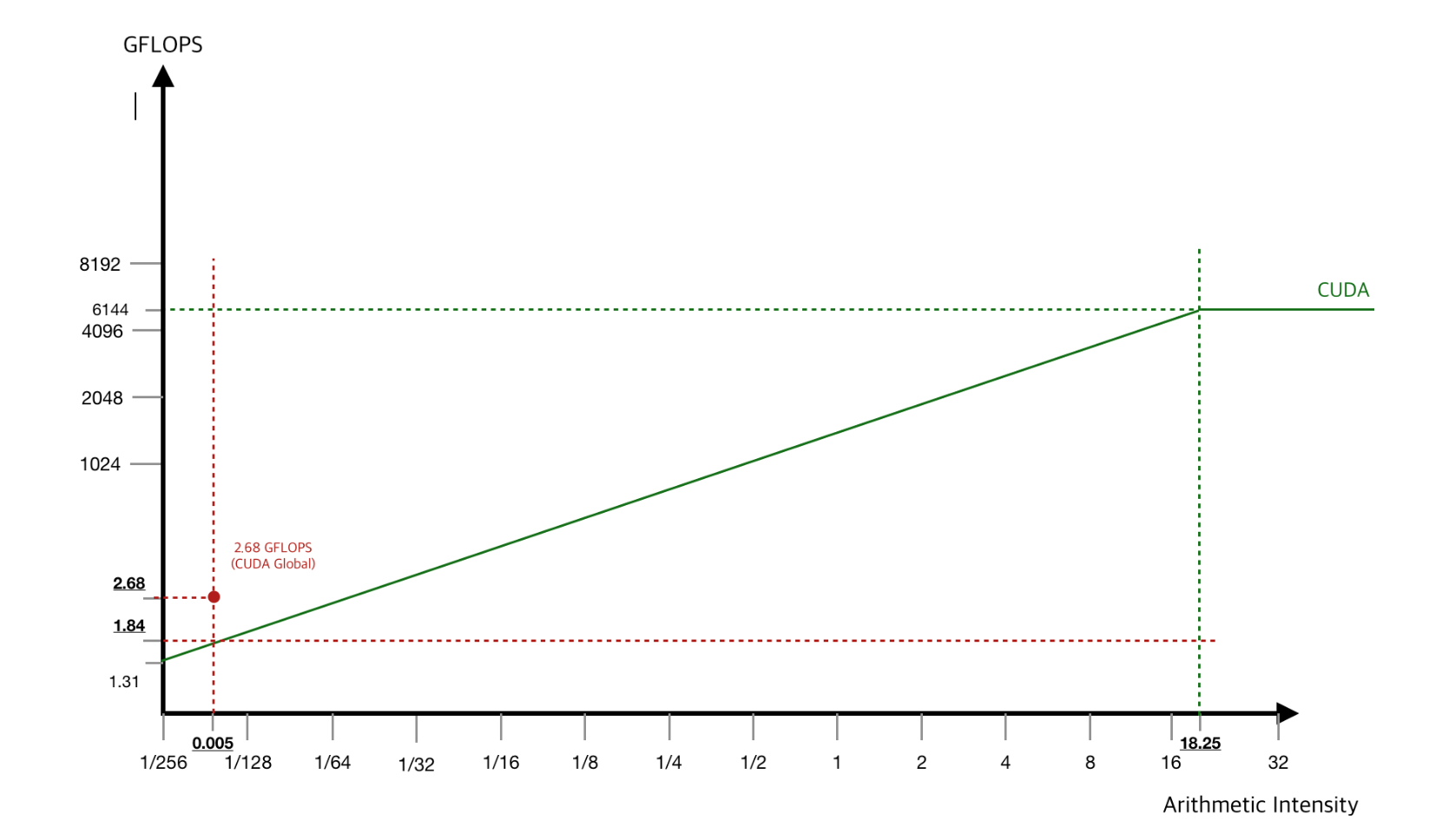
Modeling: Some Explanation
Memory
Bounded



Copy of uva-pe-1
By Kian Peymani
Copy of uva-pe-1
Midterm presentation of Performance Engineering course



