Ontologie typu wordnet
Tematyka
Wordnet to wielojęzyczna leksykalno-semantyczna baza danych. Zawiera informacje na temat rzeczowników, czasowników, przymiotników i przysłówków w wielu językach. Te wszystkie informacje są organizowane wewnątrz najważniejszego pojęcia - synsetu.
A synset is a set of words with the same part-of-speech that can be interchanged in a certain context.
Synset
Synset może być związany z innymi sysnetami poprzez relacje semantyczne, m.in. hyperonymy czy meronymy
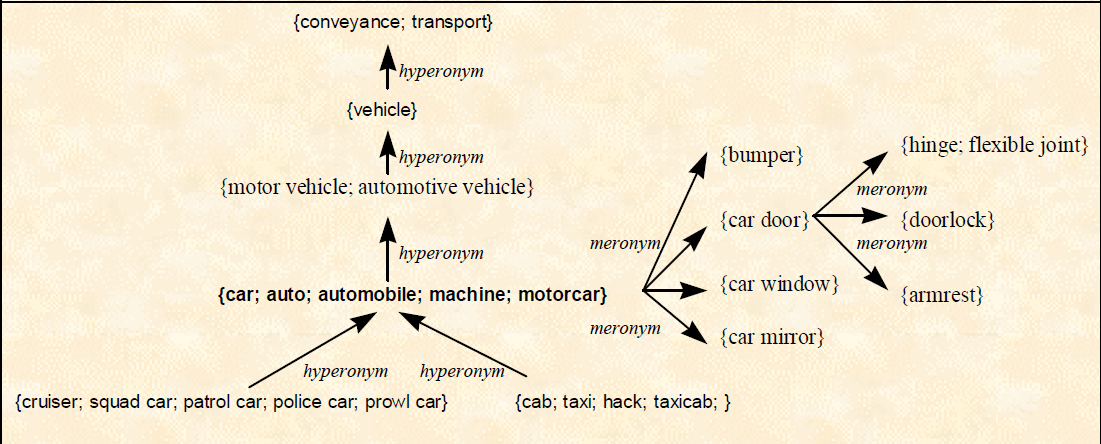
Za pomocą tych i innych powiązań semantycznych / pojęciowych wszystkie znaczenia słowa w języku mogą być ze sobą połączone, tworząc ogromną sieć.
Sieć
Te sieci semantyczne informują o leksykalizacji wzorców językowych, o gęstości pojęciowej obszarów słownikowych oraz o rozkładzie rozróżnień semantycznych czy stosunków w różnych dziedzinach słownictwa.
Tworzenie takiej sieci jest możliwe dzięki m.in. Princeton WordNet.
W bazie EuroWordNet można przejść od jednego synsetu w sieci wordnet do synsety w innej sieci, która jest powiązana tą samą koncepcją w Princeton WordNet. Taka wielojęzyczna baza danych jest przydatna do wyszukiwania informacji międzykulturowych, do przekazywania informacji z jednego zasobu do innego lub do porównywania różnych sformułowań. Porównanie może nam powiedzieć coś o spójności stosunków w słowach, gdzie różnice mogą wskazywać na niespójność lub specyficzne dla języka właściwości zasobów, a także właściwości samego języka.
WordNet - podstawowe pojęcia i założenia
Mogłoby się wydawać, iż WordNet Princeton i inne ontologie typu wordnet to to samo, ale przede wszystkim pojęcie synsetu i główne relacje semantyczne zostały przejęte w dalszych ontologiach. Wprowadzono szczególne zmiany w projekcie bazy danych, które są głównie motywowane następującymi celami:
- utworzenie wielojęzycznej bazy danych
- uzyskanie relacji językowych wokół słów
- osiągnięcie maksymalnej zgodności różnych zasobów
- budować ontologie stosunkowo niezależne i ponownie wykorzystywać istniejące zasoby
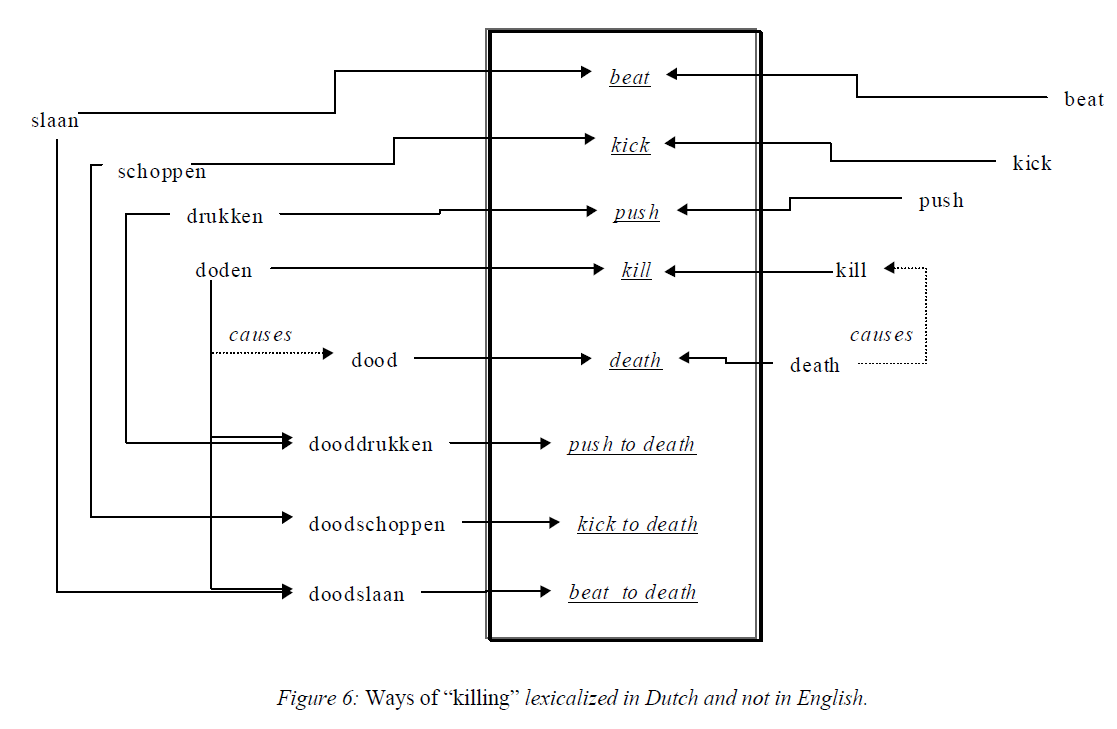
Wielojęzyczność
Najważniejszą różnicą EuroWordNet i ontologii typu wordnet w odniesieniu do WordNet jest wielojęzyczność, która jednakże rodzi pewne problemy dotyczące statusu informacji monojęzycznych w słowach.
Zasadniczo wielojęzyczność osiąga się przez dodanie relacji ekwiwalentnej dla każdego z synsetów w języku do najbliższego synsetu w systemie Princeton WordNet. Synsety powiązane z tym samym synonimem mają być równoważne lub bliskie znaczeniu i mogą być porównywane.
Jeśli "równoważne" słowa są powiązane w różny sposób w różnych zasobach, musimy podjąć decyzję o słuszności tych różnic.
in the Dutch wordnet we see that hond (dog) is both classified as huisdier (pet) and zoogdier (mammal). However, there is no equivalent for pet in Italian, and the Italian cane, which is linked to the same synset dog, is only classified as a mammal in the Italian wordnet.
Ontologia typu wordnet
Językowa ontologia (ang. linguistic ontology) dokładnie odzwierciedla leksykalizację i relacje między słowami w języku. Jest to "wordnet" w prawdziwym tego słowa znaczeniu, a zatem zawiera cenne informacje o konceptualizacjach, które są leksykalizowane przy użyciu dostępnego zasobu słów i wyrażeń w języku.
W celu budowy oraz rozwoju takiej ontologii dokonuje się jednoznacznego podziału na moduły zależne od danego języka i moduły niezależne językowo. Każdy moduł językowy jest system specyficznych dla języka wewnętrznych stosunków językowych między synsetami, zaś relacje pomiędzy synsetami z różnych języków są zarządzane przez Inter-Lingual-Index (ILI). Każdy synset ma co najmniej jedną równoważną relację ze swoim odpowiednikiem w ILI.
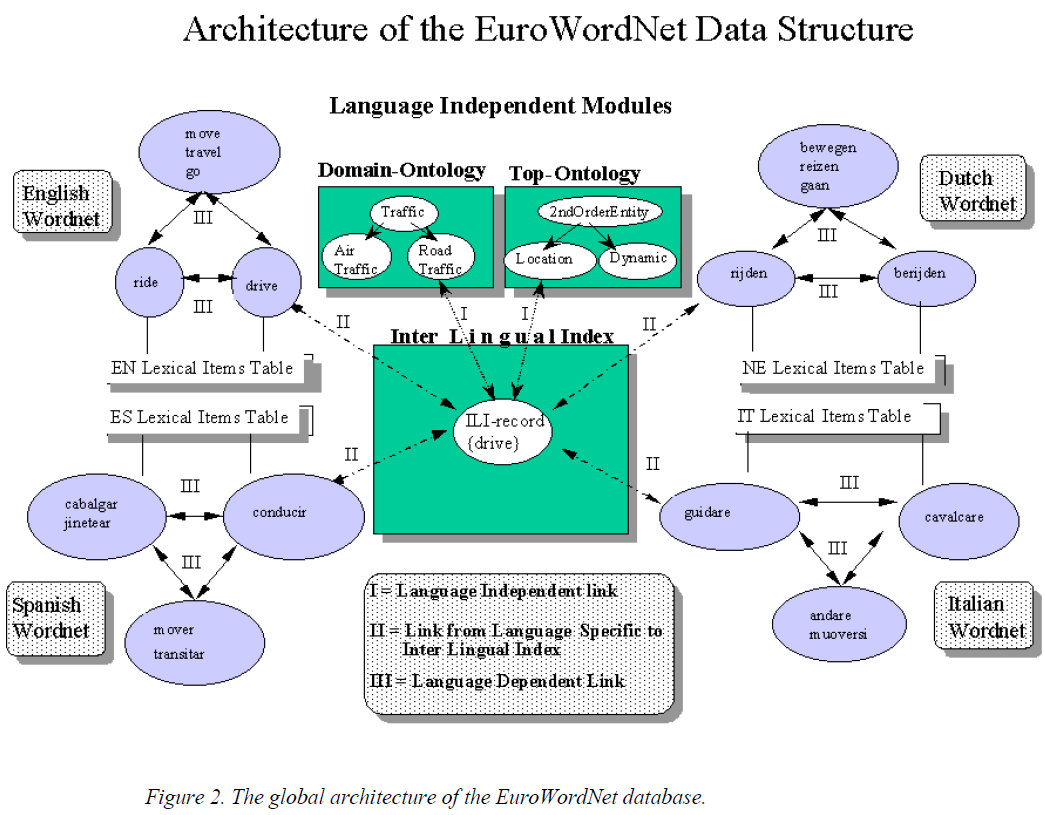
- Brak obowiązku tworzenia relacji wiele-do-wielu w stosunku do innych języków - ILI jako główny zasób
- można dodać nowe języki bez potrzeby ponownej analizy stosunków równoważności w innych
Niektóre niezależne od języka struktury wewnątrz ILI są dostarczane przez dwie niezależne ontologie, które mogą być powiązane z rekordami w ILI:
- Top Concept ontology - wskazuje hierarchię pojęć niezależnych od języka i opisuje istotne rozróżnienia semantyczne, np. obiekt i substancja, lokalizacja
Via the language-internal relations, the Top Concept can be further inherited by all other related language-specific concepts. The main purpose of the Top Ontology is to provide a common framework for the most important concepts in all the wordnets. It consists of 63 basic semantic distinctions that classify a set of 1300 ILI-records representing the most important concepts in the different wordnets.
- Hierarchia etykiet domen, które są strukturami wiedzy grupującymi ze sobą znaczenia w kategoriach tematów, np. Traffic, Road-Traffic, Air-Traffic, Sports, Hospital, Restaurant. Mogą być używane bezpośrednio do wyszukiwania informacji (a także w narzędziach do nauki języków), aby pogrupować koncepcje na wiele sposbów, opierając się raczej na skryptach niż na klasyfikacji. Domeny mogą być również używane do oddzielenia języka rodzajowego od słownictwa specyficznego dla danej domeny. Ważne jest, aby kontrolować problem niejednoznaczności w przetwarzaniu języków naturalnych.
Relacje między częściami mowy
Bardzo ważną różnicą pomiędzy Princeton WordNet a ontologiami typu wordnet jest podejście do relacji między słowami na płaszczyźnie części mowy.
1stOrderEntity
Any concrete entity (publicly) perceivable by the senses and located at any point in time, in a three-dimensional space, e.g. object, substance, animal, plant, man, woman, instrument.
2ndOrderEntity
Any Static Situation (property, relation) or Dynamic Situation, which cannot be grasped, heart, seen, felt as an independent physical thing. They can be located in time and occur or take place rather than exist; e.g. be, happen, cause, move, continue, occur, apply.
3rdOrderEntity
Any unobservable proposition that exists independently of time and space. They can be true or false rather than real. They can be asserted or denied, remembered or forgotten. E.g. idea, thought, information, theory, plan, intention.
Ontologie typu wordnet (np. EuroWordNet) reprezentują bardziej ogólny model semantyczny w stosunku do Princeton WordNet, który zawiera różne typy relacji semantycznych, które można wyciągnąć z słowników (i innych źródeł) do wykorzystania w aplikacjach NLP. Definicja takiego szerokiego modelu nie oznacza jednak, że zapewniono wszelkie możliwe relacje dla wszystkich znaczeń. Biorąc pod uwagę ograniczenia czasowe i budżetowe projektu, kodowanie dodatkowych stosunków semantycznych ograniczało się do tych znaczeń, które mogą być (pół) automatycznie uzyskiwane ze źródeł lub do tych znaczeń, które nie mogą być powiązane prawidłowo tylko za pomocą bardziej podstawowych powiązań .
Kryteria identyfikacji relacji pomiędzy synsetami
Stworzono specjalne testy substytucji oraz ramy
diagnostyczne w celu sprawdzenia relacji miedzy synsetami. Przykładowo, wstawienie dwóch słów do zdań testowych spowoduje głównie ocenę "normalności" i "anomalii", na podstawie której można określić związek. Synsety oraz ich relacje mogą być identyfikowane na podstawie możliwości zastąpienia słowa innym przez określony kontekst.
a. X is a Noun1 therefore X is a Noun2
b. Y Verb(-phrase)1 therefore Y Verb(-phrase)
For instance, fiddle and violin are synonyms on the basis of the ‘normality’ of (1a) and (1b), while dog and animal are not, due to the ‘abnormality’ of (2b); in a similar way, enter and go into are synonyms, while walk and move are not:
1a. It is a fiddle therefore it is a violin.
2a. It is a violin therefore it is a fiddle.
3a. It is a dog therefore it is an animal.
4a. *It is an animal therefore it is a dog.
1b. John entered the room therefore John went into the room.
2b. John went into the room therefore John entered the room.
3b. The dog walked therefore the dog moved.
4b. *The dog moved therefore the dog walked.
Takie testy były tworzone dla każdej relacji w ontologii typu wordnet (i dla każdego języka). Należy pamiętać, że takie testy obsługują tylko i wyłącznie relacje semantyczne (nie powinny badać nic poza tym).
Poza testami, do kształtowania relacji można użyć:
- Economy principle
- Compatibility principle
- Szczegółowe testy (np. dla danego języka)
Należy pamiętać, że jeżeli dwa słowa są połączone jednym typem relacji semantycznej, to nie mogą być połączone żadnym innym. To z pozoru łatwą zasadę bardzo trudno utrzymać, zwłaszcza w przypadku wykorzystania kilku języków.
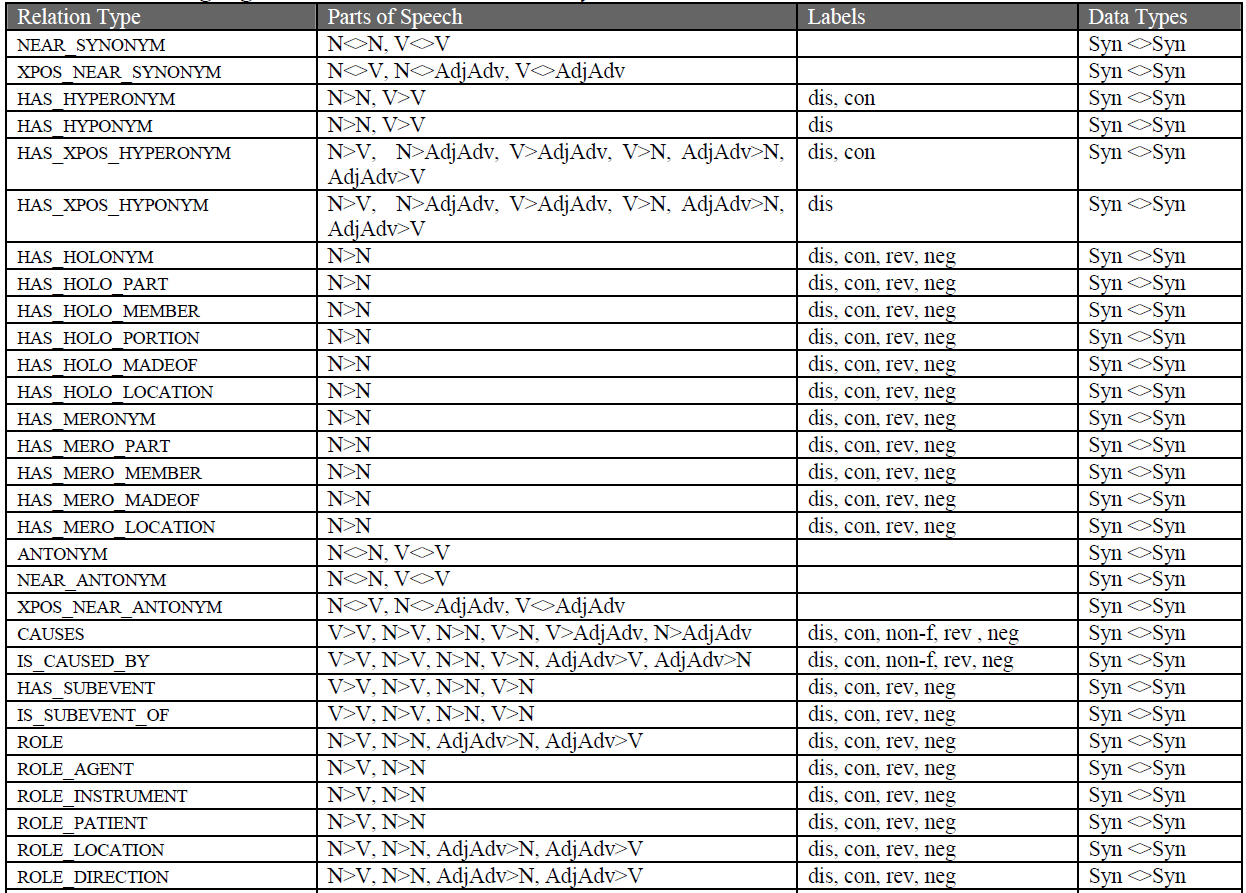
Etykiety relacji
Istotną różnicą pomiędzy bazą danych EWN a strukturą WN1.5 jest możliwość dodawania etykiet do relacji. Te etykiety są potrzebne, aby rozróżnić dokładne konsekwencje semantyczne wynikające z zdefiniowanych relacji. Wyróżniono następujące typy etykiet:
- Koniunkcja/Dysjunkcja (Conjunction /Disjunction) - służą do oznaczenia stanu wielu relacji tego samego typu, reprezentowanych przez synset.
door1 -- (a swinging or sliding barrier that will close the entrance to a room or building; “he knocked on the door”; “he slammed the door as he left”) PART OF: doorway, door, entree, entry, portal, room access
door 6 -- (a swinging or sliding barrier that will close off access into a car; “she forgot to lock the doors of her car”) PART OF: car, auto, automobile, machine, motorcar.
- Faktywność (Factivity) - Rozróżnia różne typy przyczynowości w oparciu o faktowość efektu:
factive: event E1 implies the causation of E2
“to kill causes to die”non-factive: E1 probably or likely causes event E2 or E1 is intended to cause some event E2
“to search may cause to find”
- Negacja (Negation) - Taka etykieta może być użyta do zablokowania pewnych implikacji.
macaque HAS_MERONYM tail
Barbary ape HAS_MERONYM tail negative
- Odwrócenie relacji (Reversed) - są relacje, które są koncepcyjnie dwukierunkowe, a inne, które nie są:
hand HAS_MERONYM finger
finger HAS_HOLONYM hand
car HAS_MERONYM door
door HAS_HOLONYM car reversed
computer HAS_MERONYM disk drive reversed
disk drive HAS_HOLONYM computer
Podtypy relacji wewnątrzjęzykowych
Dla każdego związku podaje się następujące informacje:
- jego nazwę,
- połączone części mowy (ze wskazaniem "kierunku" powiązania),
- dalsze relacje etykiet, które mogą mieć zastosowanie,
- typ połączonych danych
Synonim jest podstawą do organizacji bazy danych za pomoca synsetów. Zasadniczo wszystkie semantycznie równoważne słowa powinny należeć do tych samych synsetów (gdzie mogą być odróżniane przez etykiety).
Jeśli X jest "semantycznie podobny" do Y, to Y jest "semantycznie podobny" do X, Podczas gdy oczywiście hiponymy powinny być asymetryczne.
- Hiponimy (Hyponymy) - to najbardziej fundamentalny związek, wokół którego tworzone są wordnety. Zachodzi on między wyrazem o treści bardzo szczegółowej i zakresie węższym a wyrazem o treści bardziej ogólnej i szerszym zakresie.
taxi HAS_HYPERONYM car HAS_HYPERONYM motor vehicle HAS_HYPERONYM vehicle HAS_HYPERONYM instrument HAS_HYPERONYM object HAS_HYPERONYM entity
- Antonimy - oznaczają przeciwieństwo, odwrotność znaczeniową innego terminu. Antonimy zazwyczaj tworzą kontrastujące kategorie w tym samym wymiarze. Oznacza to, że antonim nie tylko kontrastuje z innym antonimem w jednej lub więcej cechach, ale muszą dzielić tym samym hiperonimem.
- Meronimy - wyrazy oznaczające część pewnej całości:
(i) between (the nouns standing for) a whole and their constituent parts (“part”, e.g. “hand”-“finger”);
(ii) between a portion and the whole from which it has been detached (“portion”, e.g. “ingot”-“metal”);
(iii) between a place and a wider place which includes it (“location”, e.g. “oasis”-“desert”);
(iv) between a set and their members (e.g. “fleet” -“ship”);
(v) between a thing and the substance it is made of (“made-of”, e.g. “book”-“paper”).
Bibliografia
"EuroWordNet General Document", Piek Vossen, 2002
"Inteligentne systemy e-learningowe wykorzystujące ontologie typu word.net", Jacek Marciniak, 2015
http://plwordnet.pwr.wroc.pl/wordnet/
https://wordnet.princeton.edu/
Ontologie typu wordnet
By kko



