metody komputerowej analizy stylometrycznej tekstów w jEzyku polskim
prowadzący: dr inż. Tomasz Walkowiak
Maciej Baj
spis treSci
1. Przybliżenie problematyki
2. Atrybuty tekstu
3. Język polski
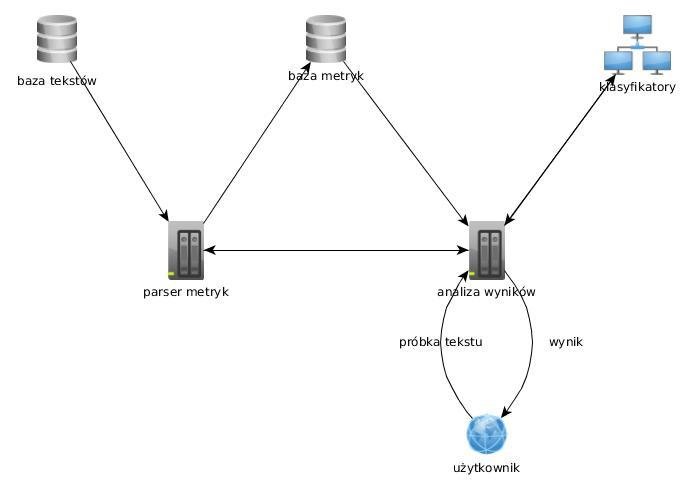
4. Schemat systemu
5. Proste metryki
6. Histogramy słów
7. Części mowy
8. Klasyfikatory
9. Analizy wyników
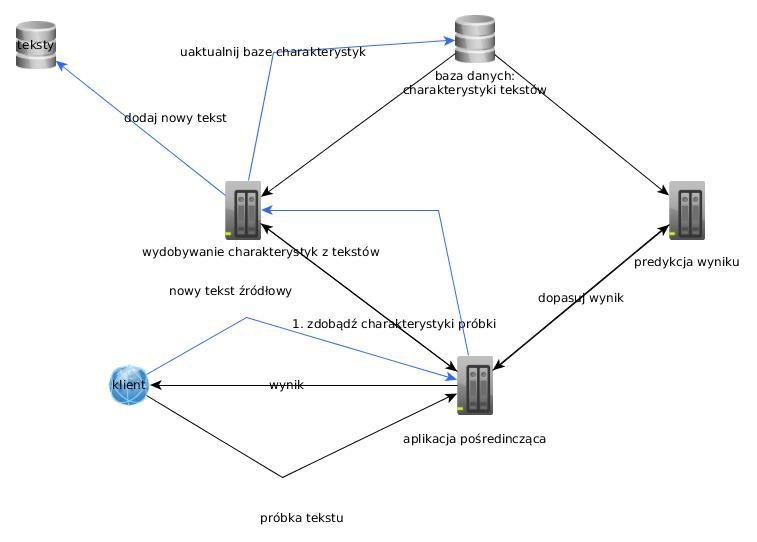
10. Działanie systemu
ASPEKT IŻYNIERSKI
Zapoznanie się z narzędziami NLP do języka polskiego (tager POS, wyznaczanie nazw wlasnych, parser zależnościowy). Konstrukjca aplikacji do analizy stylometrycznej.
Subtitle
aspekt badawczy
Opracowanie systemu komputerowej analizy stylometrycznej (np. atrybucja autorstwa) dla tekstów w języku polskim.
Selekcja zbioru cech deskryptywnych opisujących sygnały stylometryczne.
Porównanie efektywności algorytmów klasyfikacji z nauczycielem (np. SVM, Naive Bayes, drzewa decyzyjne)
PrzybliZenie problematyki
Stylometria - metoda analizy dzieła sztuki dla ustalenia statystycznej charakterystyki stylu autora
- Grupowanie tekstów w klasy na podstawie określonych form stylistycznych tekstu
- Mierzenie tekstu określonymi metrykami
- Kwalifikacja próbki tekstu do określonej klasy na podstawie zbioru uczącego
Atrybuty tekstu
- Autor
- Rodzaj (artykuł, wiersz, proza...)
- Epoka
- Płeć autora
- Wiek autora
- Temat (sport, motoryzacja, kuchnia ...)
JEzyk polski
Czasy
Lubi, lubił, będzie lubić, polubi
Odmiany
Mianownik, dopełniacz, celownik, biernik, nadrzędnik, wołacz
Rodzaje
Wszedłem, weszłam, weszło
schemat systemu
METRYKI LICZBOWE
-
- średnia długość słowa
- średnia długość zdania
- współczynnik częstości znaków specjalnych
- współczynnik najrzadziej używanych słów
METRYKI LICZBOWE
"average_word_length" : 5.8539325842696632,
"name" : "sienkiewicz",
"type_token_ratio" : 0.8202247191011236,
"average_sentence_length" : 22.2500000000000000,
"hapax_legomana_ratio" : 0.7415730337078652
NARZEDZIA DO ANALIZY
morgologicznej i skladniowej
NARZEDZIA DO ANALIZY
FLEKSYJNEJ I MORFOSYNTAKTYCZNEJ
def produce_xml_with_morphological_data(text_file_path, output_file_path):
os.system("~/apps/wcrft/wcrft/wcrft.py
-d ~/apps/model_nkjp10_wcrft/ ~/apps/wcrft/config/nkjp.ini -i txt " +
text_file_path + " -O " + output_file_path)PLIK WYNIKOWY WCRFT
<chunkList>
<chunk type="s">
<tok>
<orth>Czas</orth>
<lex disamb="1"><base>czas</base><ctag>subst:sg:nom:m3</ctag></lex>
</tok>
<tok>
<orth>był</orth>
<lex disamb="1"><base>być</base><ctag>praet:sg:m3:imperf</ctag></lex>
</tok>
<tok>
<orth>wiosenny</orth>
<lex disamb="1"><base>wiosenny</base><ctag>adj:sg:nom:m3:pos</ctag></lex>
</tok>
<tok>
<orth>o</orth>
<lex disamb="1"><base>o</base><ctag>prep:loc</ctag></lex>
</tok>
<tok>
<orth>świtaniu</orth>
<lex disamb="1"><base>świtanie</base><ctag>subst:sg:loc:n</ctag></lex>
</tok>
<ns/>Histogramy sLów
- histogram binarny
- na podstawie słownika
- na podstawie częstości wystąpień
NAJCZeSTSZE SLOWA
"base_words" : [
{
"i" : 7
},
{
"w" : 4
},
{
"na" : 3
},
{
"się" : 3
},
{
"rok" : 2
},
{
"co" : 2
},
{
"być" : 2
}
....CZesCI MOWY
"parts_of_speech_frequencies" : {
"adv" : 0.0194174757281553,
"praet" : 0.0776699029126214,
"imps" : 0.0291262135922330,
"pred" : 0.0097087378640777,
"interp" : 0.1067961165048544,
"subst" : 0.3398058252427185,
"qub" : 0.0388349514563107,
"comp" : 0.0291262135922330,
"conj" : 0.0873786407766990,
"adj" : 0.1359223300970874,
"prep" : 0.0970873786407767,
"fin" : 0.0291262135922330
},PREDYKCJA WYNIKU
Jakie wagi nadać parametrom tekstu?
- cechy numeryczne
- częstości słów
- częstości używania konkretnych części mowy
Klasyfikatory
heurystyczne przypisanie próbki do pewnej klasy
- SVM
- Naive Bayes
- drzewa decyzyjne
KLASYFIKACJA METODA NAIVE BAYES
from sklearn import naive_bayes
trainingSet = [reymontCharacteristics, sienkiewiczCharacteristics]
gaussian_naive_bayes = naive_bayes.GaussianNB()
gaussian_naive_bayes.fit(trainingSet, ['reymont', 'sienkiewicz'])
print gaussian_naive_bayes.predict(inputCharacteristics)klasyfikatory
Porównanie skuteczności klasyfikatorów
Porównanie skuteczności klasyfikatorów z prostymi metrykami
dane
Koleracja zmiany skuteczności ze wzrostem:
- zbioru uczącego
- rozmiaru tekstów zbioru uczącego
- rozmiaru tekstu próbki
Analiza wyników
Działanie systemu
bibliografia
Scikit- http://scikit-learn.org/stable/supervised_learning.html#supervised-learning
WCRFT- http://nlp.pwr.wroc.pl/redmine/projects/wcrft/wiki
partial-fit- http://scikit-learn.org/stable/modules/generated/sklearn.naive_bayes.MultinomialNB.html#sklearn.naive_bayes.MultinomialNB.partial_fit
Dziekuje
metody komputerowej analizy stylometrycznej tekstów w języku polskim
By Maciej Baj



