Stream Processing
Streams
when input is unbound - unknown size, not limited in time
consists of events
related events are grouped into topic or stream
Main characteristics of messaging system:
- what happens if messages are produced faster than they are consumed (drop, buffer, block - backpresser). Unix and TCP use backpresser. If buffer than how large, stored in memory or disk?
- what happens if node crashes
Brokers
Brokerless - direct UDP protocol (ZeroMQ) to increase throughput
Broker - kinda database, responsible for durability, applies different overload strategies. Means that processing should be async.
Broker vs Database:
- messages are shortlived - large memory to store them is not expected
- DB indexes are same as broker topics
- DB expects query, Broker notifies
Brokers
Load balancing - each message is delivered to one of the consumers
Fan-out - each message is delivered to all consumers
To ensure message is not lost brokers use acknowledgment
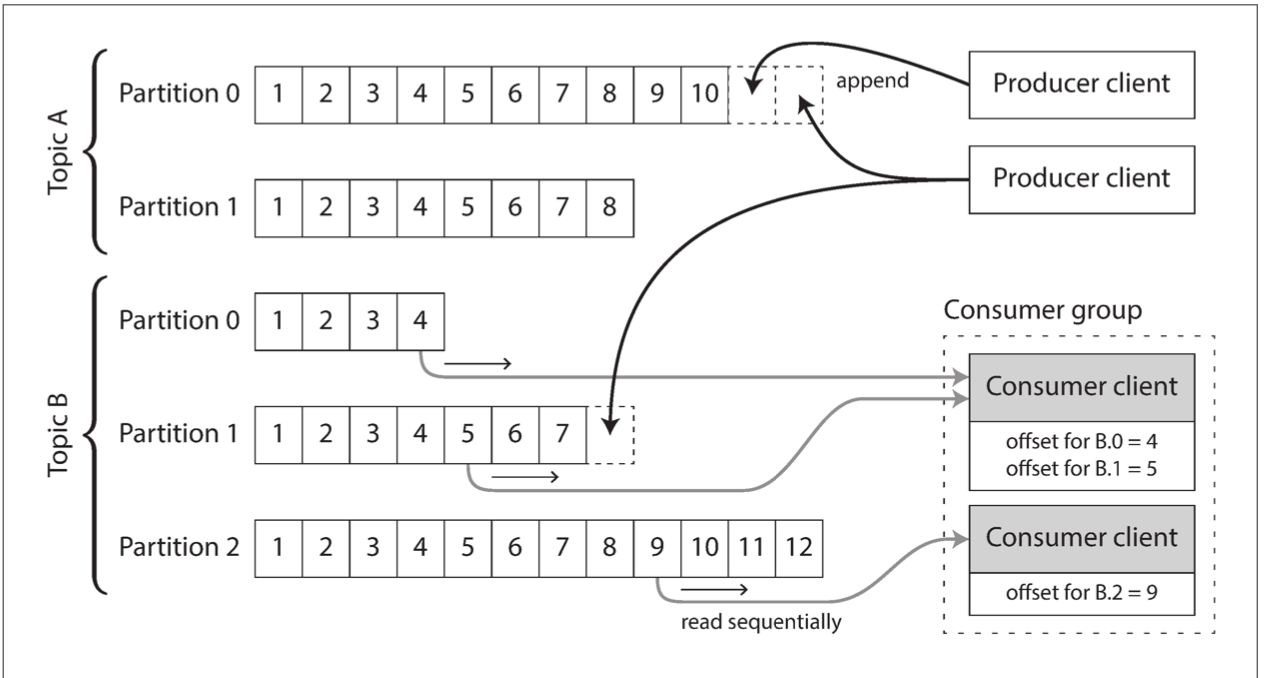
Log-based message brokers
Kafka, Kinesis - preserve the order
Consumer nodes are assigned to partitions => Max consumer nodes - number of partitions
Node reads from partition in a single-threaded mode => if single message is slow it blocks the whole node
No ack needed since offset is used. If consumer fails it will use offset once back. No need for dead letter queue.
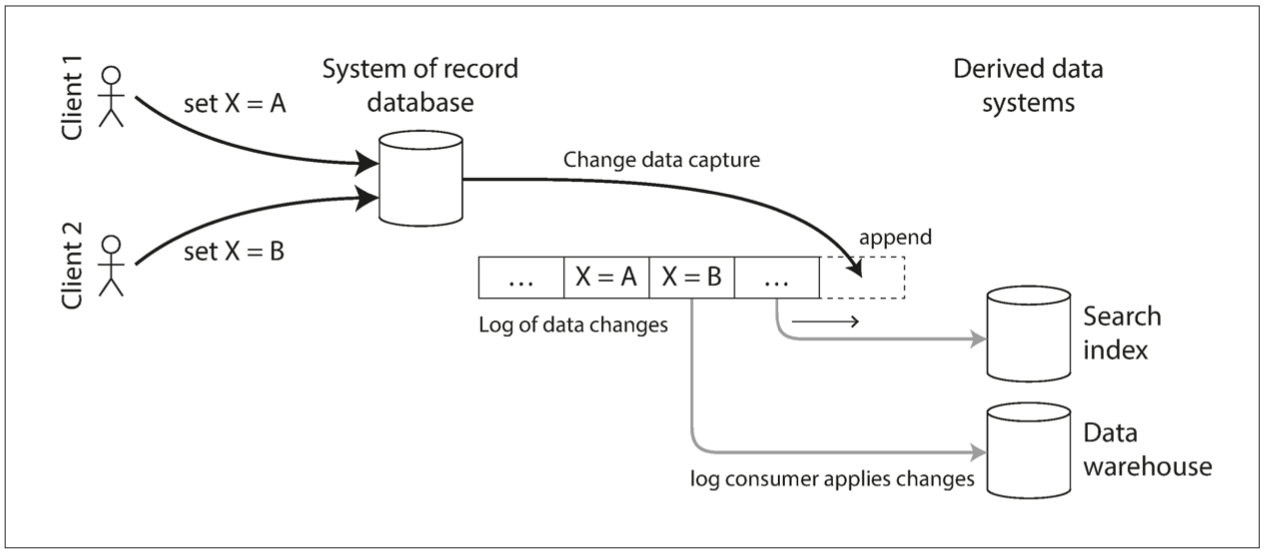
Change Data Capture
A log-based message broker is well suited for transporting the change events from the source database, since it preserves the ordering of messages
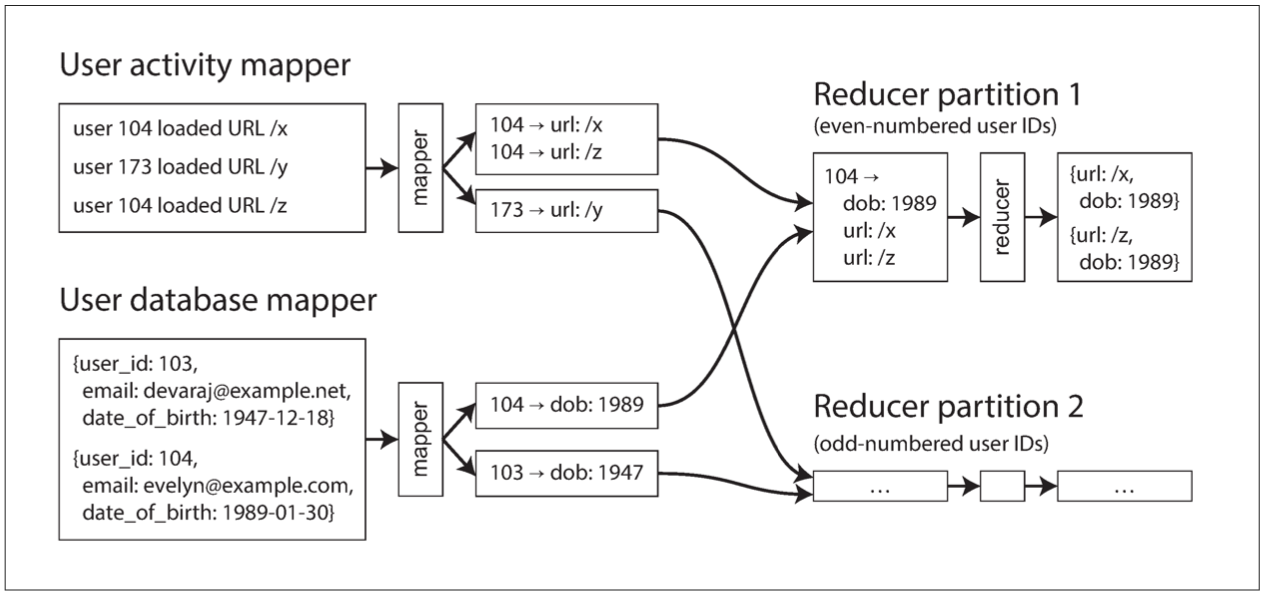
Reduce-side Joins
Naive: get user data one by one from remote DB - throughput limitation, requests are not deterministic since data can b updated between 2 requests
Solution: have a copy of DB close to the join process.
Results of one joint can be sorted against results from another joint (dob comes first) - secondary sort. Since mapper output is sorted by key, and the reducer merges sorted lists of results of both merges the algorithm is called sort-merge join.
Reduce-side Groups
Examples: count, sum, top k records..
skew: if there is too much data for a particular single key (linchpin object or hotkey)
Pig makes pre-sampling to indicate hotkeys
Crunch requires manual setup.
In both cases the key is partitioned among multiple reducers.
Hive uses map-side join
Map-side joins
Joining large and small datasets:
- the small dataset can fit into the memory. The approach is called broadcast hash join
- or store on the disk together with big dataset but create an index to aces data
Reduce-side joins: don't care about initial input data - that will be prepared by mappers. Downside: we copy data from mappers to reducers which might be expensive.
Output of reduce-side join is partitioned and sorted by key
Output of map-side join is partitioned and sorted same as a large dataset
Materialization
Problems:
- one task can start only after the previous one is fully complete
- mappers are often redundant and just read the input files, reducers could be stacked instead
- in a distributed file system materialized files are replicated which is overkill
Solution: dataflow engines (Spark, Tex, Flink) - chain of lambda functions:
- sorting is done on demand only (in MapReduce always)
- no unnecessary map tasks
- way for optimizations since framework aware of all steps of the job
- intermediate steps can be kept in memory, not on disk
- no need to wait for the entire step to finish
- VMs (like JVM) can be used instead of starting over and over
Materialization
We still need materialization sometimes:
- for fault tolerance, if computation is expensive to start over
- when do sorting we anyway have to wait for the whole task to be done before proceeding with another
Stream Processing
By Michael Romanov



