Partitioning
vertical scaling or scaling up
shared-memory architecture
Many CPUs, many RAM chips, and many disks can be joined together under one operating system
problem: cost + can be fault-tolerant with hot-swappable components but still geographically one cluster
buy a more powerful machine
problem: cannot scale up infinitely
shared-disk architecture
several machines stores data on an array of disks that are shared between them
problem: overhead of locking data limits scalability
shared-nothing architecture
each machine or virtual machine running the database software is called a node. Each node uses its CPUs, RAM, and disks independently
benefits: price, geo distribution, highly fault tolerante
MongoDB
Elasticsearch
SolrCloud
HBase
Bigtable
Cassandra
Couchbase
vBucket
vnode
tablet
region
shard
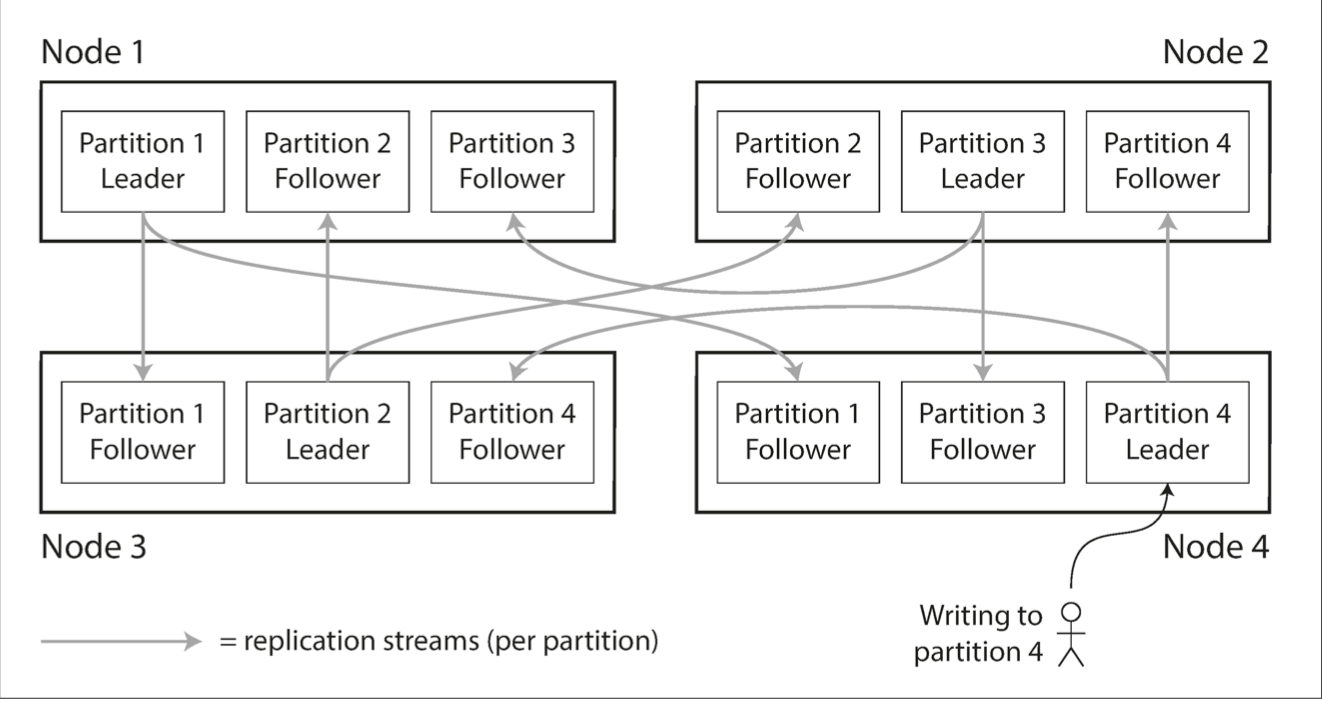
If the partitioning is unfair, so that some partitions have more data or queries than others, we call it skewed.
In an extreme case, all the load could end up on one partition, so n-1 out of n nodes are idle and your bottleneck is the single busy node
A partition with disproportionately high load is called a hot spot
Assign record to a partition
random
+ avoid hot spots due to randomness
- read requires querying all partitions since we don't have a way to calculate the correct partition
partitioning by key range
+ range scans are easy
- can lead to hot spots (example: timestamps and partitions by hour - all writes go to a single last hour partition. Solution: prefix with sensor name and partition by a sensor. The downside of solution: leads to querying all partitions again)
Assign record to a partition
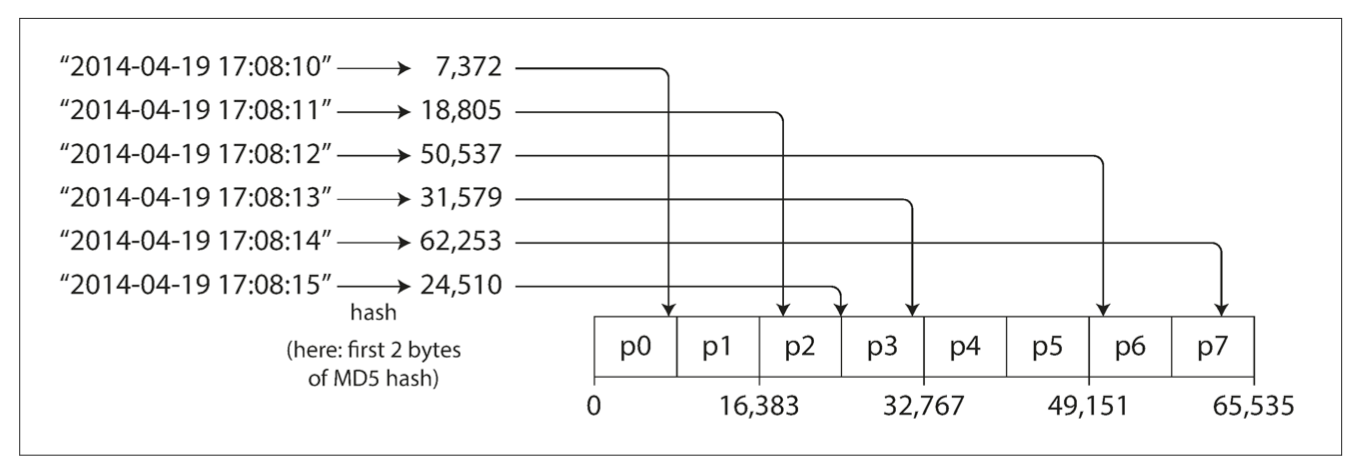
partitioning by hash of key
+ even distribution of load (if partition space is random - called consistent hashing)
- range scans not possible (more precisely, requests are sent to all partitions)
(note: hash function should be strong and determenistic: MD5 for example
hybrid
hash only the first part of the combined key. Example: (user_id, update_timestamp)
+ even distribution of load
+ range scans are possible for the consequent keys
Assign record to a partition
application level
example: celebrities on social networks
most data systems are not able to automatically compensate for such a highly skewed workload hence that shall be done on app-level
solution: add a random number to the beginning or end of the key. Just a two-digit decimal random number would split the writes to the key evenly across 100 different keys
+ remove the hot spot for writes
- reads are spread across partitions - have to query and combine
- needs book-keeping since not all keys are hot spots. Applying to small partitions would be an overhead
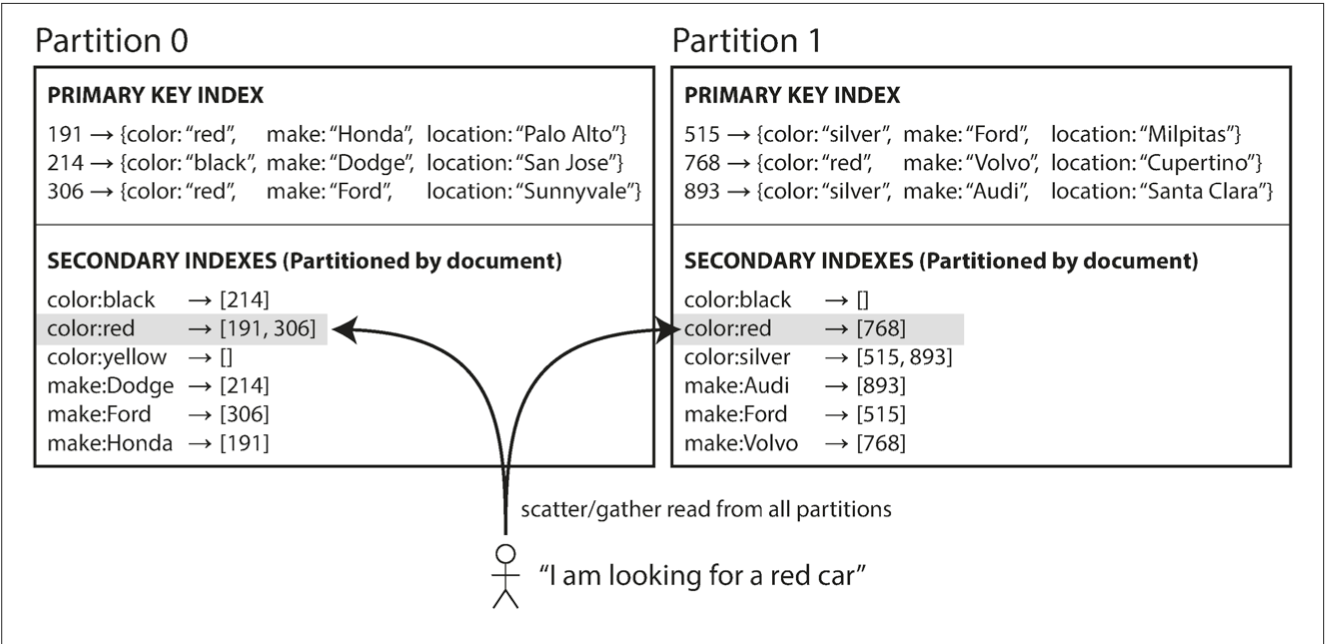
Secondary Indexes - by document
only operates within a partition (local index)
writes are fast
requires read queries to all partitions (scatter/gather)
used by: MongoDB, Riak, Cassandra, Elasticsearch, SolrCloud, and VoltDB
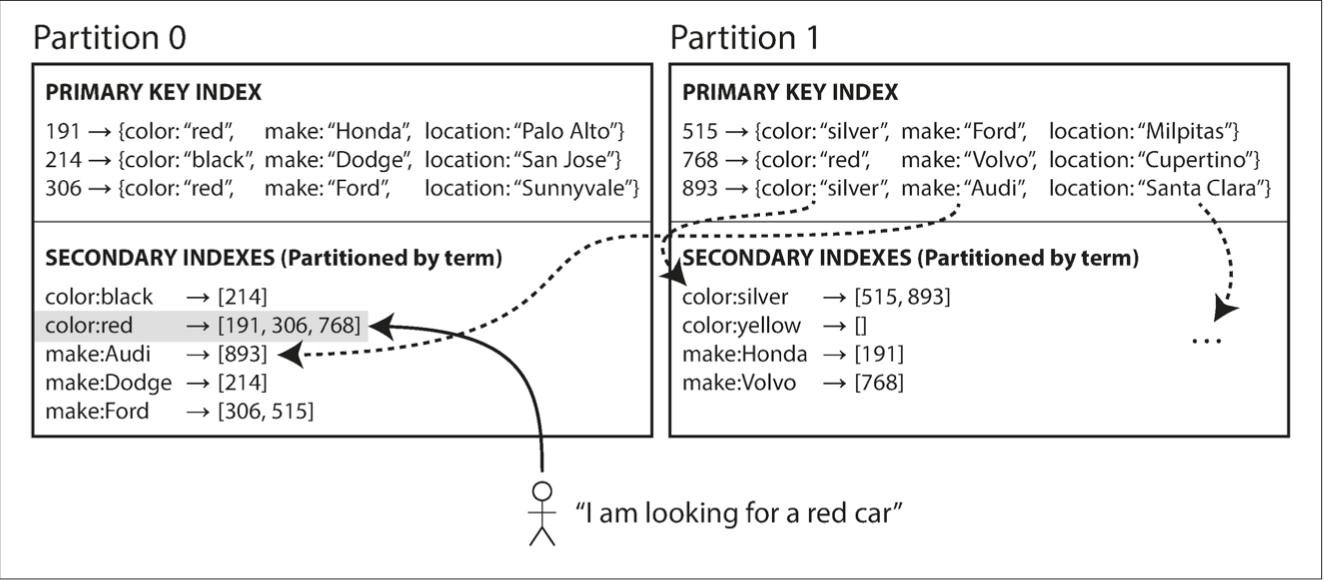
Secondary Indexes - by term
operates across all partitions (global index)
secondary index is also partitioned by its value (term comes from full-text indexes, where the terms are all the words that occur in a document
writes are slow (+ can lead to stale index reads due to distributed transaction)
reads are fast
Reasons:
- query throughput increases
- dataset size increases
- node fails
Requirements:
- after rebalancing, load should be shared fairly
- while rebalancing, database is in working condition
- no more data than necessary should be moved
Rebalancing
modulo approach
- requires a lot of data moving when rebalancing happens
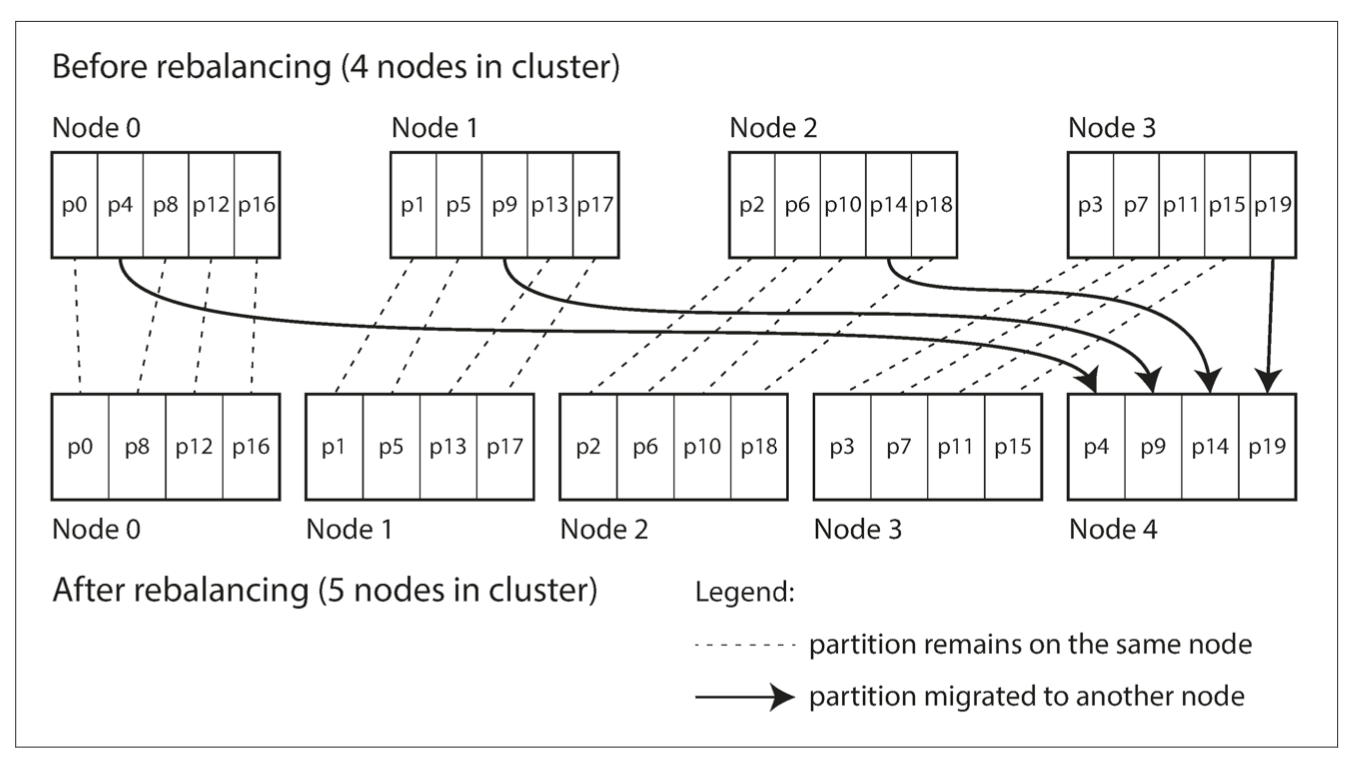
fixed number of partitions
create more partitions than there are nodes. Size of partition proportional to dataset size. Move the whole partition not keys within a partition. While moving operate with old one.
if partitions are very large, rebalancing and recovery from node failures become expensive. But if partitions are too small, they incur too much overhead.
+ easy to operate
- choosing the right number of partitions is difficult if the total size of the dataset is highly variable
used in: Riak, Elasticsearch,
Couchbase, Voldemort
dynamic partitioning
used by: MongoDB, HBase, RethinkDB
amount of nodes are fixed, size of partition is fixed (~10GB), amount of partitions dynamic and proportional to the size of the dataset
+ adapts to dataset size
+ good choice for range-partitioned data
- empty dataset starts with one partition - no fault tolerance and all writes are on single node (to mitigate some DBs including MongoDB allow to configure number of partitions (pre-splitting)
partitioning proportionally to nodes
used by: Cassandra, Ketama
fixed number of partitions per node (consistent hashing)
size of each partition grows proportionally to the dataset size while the number of nodes remains unchanged, but when you increase the number of nodes, the partitions become smaller again. Since a larger data volume generally requires a larger number of nodes to store, this approach also keeps the size of each partition fairly stable.
When a new node joins the cluster, it randomly chooses a fixed number of existing partitions to split
automatic or manual rebalancing
some databsases generate a suggested partition assignment automatically, but require an administrator to commit it before it takes effect.
fully automated rebalancing can be unpredictable as together with automatic failure detection can lead to cascading failure
For example, say one node is overloaded and is temporarily slow to respond to requests. The other nodes conclude that the overloaded node is dead, and automatically rebalance the cluster to move load away from it. This puts additional load on the overloaded node, other nodes, and the network—making the situation worse and potentially causing a cascading failure.
request routing (service discovery)
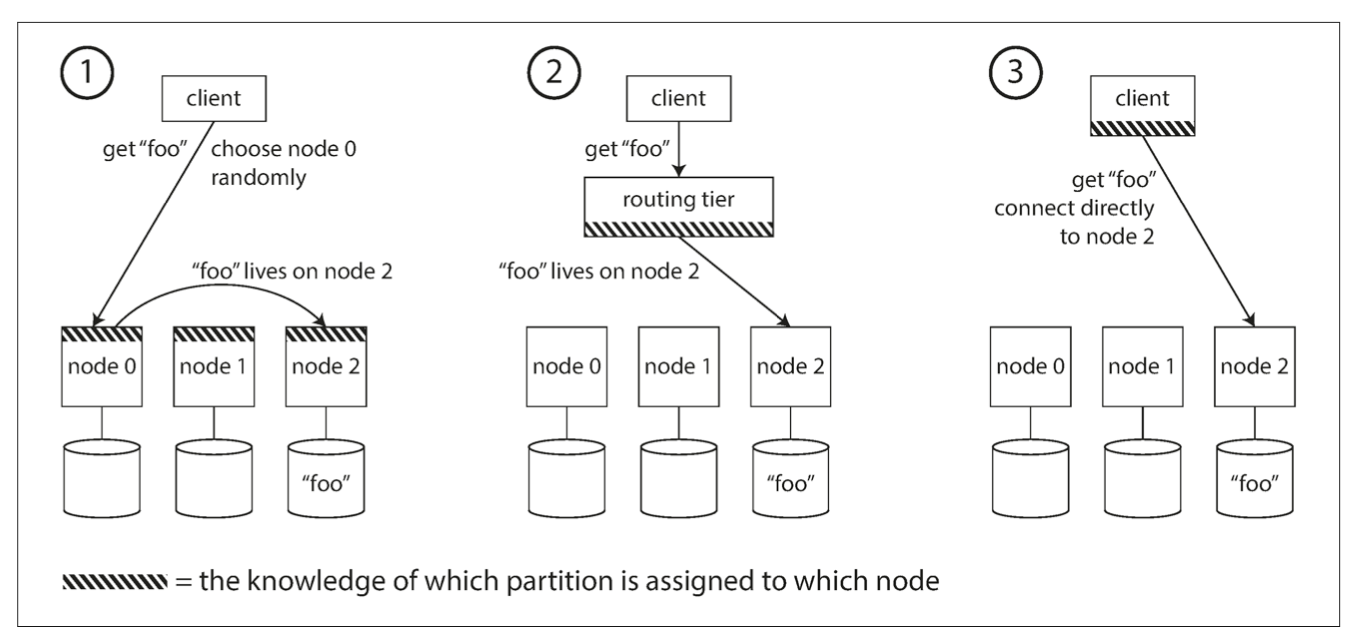
in all cases, the key problem is: how does the component making the routing decision learn about changes in the assignment of partitions to nodes?
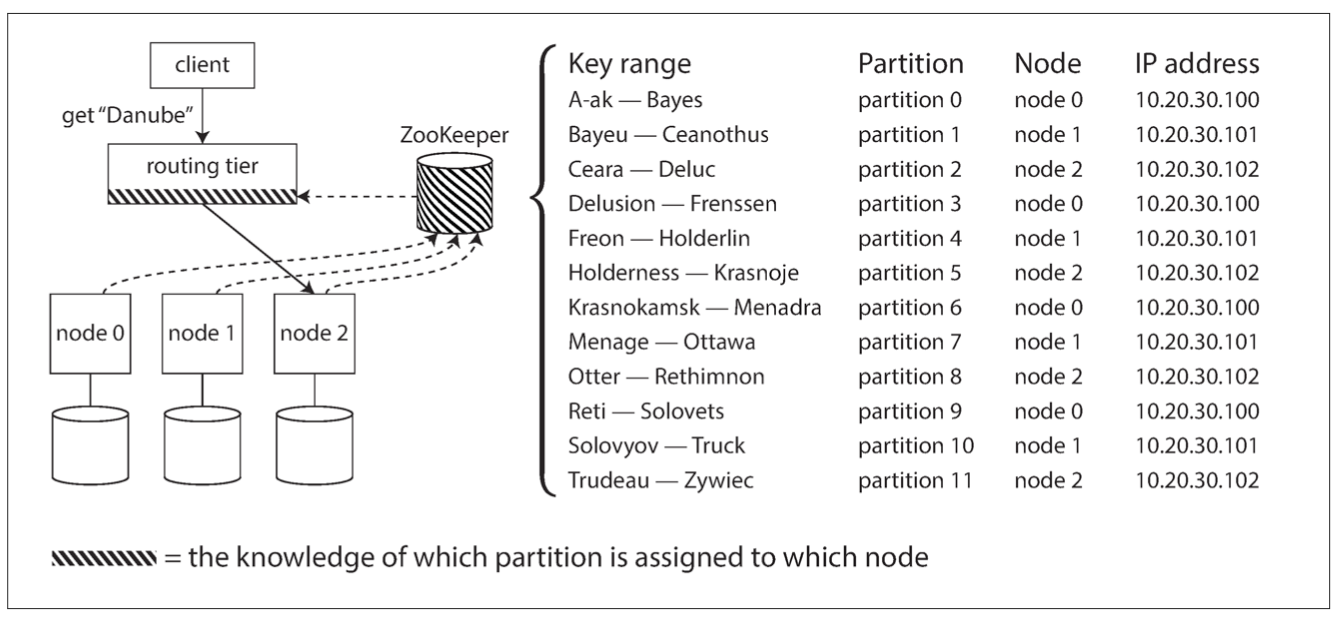
Apache ZooKeeper
HBase, SolrCloud, Kafka use ZooKeepr
MongoDB uses approach with routing tier but relies on its own config server instead of ZooKeeper
Cassandra and Riak use gossip protocol
Partitioning
By Michael Romanov



