Transactions
Problems
The database software or hardware may fail at any time (incl. in the middle of a write operation).
The application may crash at any time (including halfway through a series of operations).
Interruptions in the network can unexpectedly cut off the application from the database, or one database node from another.
Several clients may write to the database at the same time, overwriting each other’s changes.
A client may read data that doesn’t make sense because it has only partially been updated.
Race conditions between clients can cause surprising bugs.
Transaction
all the reads and writes in a transaction are executed as one operation
either the entire transaction succeeds (commit) or it fails (abort, rollback)
If it fails, the application can safely retry
ACID
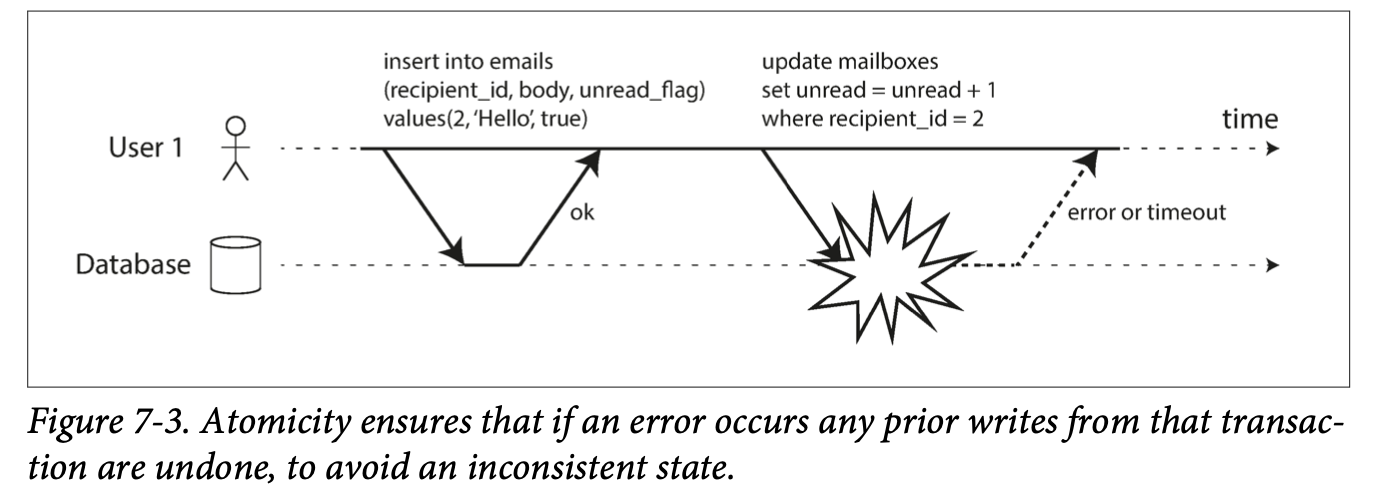
Atomicity - either commit all operations or abort all operations
Consistency - respect data invariants. However, almost always is the responsibility of the application rather than a database
Isolation - controls access to the same data. Ideally prevents race conditions. Concurrently executing transactions are isolated from each other
Another name - serializability - the database ensures that when the transactions have been committed, the result is the same as if they had run serially (one after another), even though in reality they may have run concurrently
Durability - promise that once a transaction has been committed successfully, any data it has written will not be forgotten, even if there is a hardware fault or the database crashes.
In a replicated database, durability may mean that the data has been successfully copied to some number of nodes. In order to provide a durability guarantee, a database must wait until these writes or replications are complete before reporting a transaction as successfully committed.
Multi-object
Multi-object transactions require some way of determining which read and write operations belong to the same transaction. In relational databases, that is typically done based on the client’s TCP connection to the database server: on any particular connection, everything between a BEGIN TRANSACTION and a COMMIT statement is considered to be part of the same transaction.
This is not ideal. If the TCP connection is interrupted, the transaction must be aborted. If the interruption happens after the client has requested a commit but before the server acknowledges that the commit hap‐ pened, the client doesn’t know whether the transaction was committed or not. To solve this issue, a transac‐ tion manager can group operations by a unique transaction identifier that is not bound to a particular TCP connection.
Single-object
wrongly called a transaction though the transaction is an operation on multi-object
example: writing a 20 KB JSON document to a database
atomicity: log for crash recovery
isolation: locking the object
increment operation: read and write in one transaction
compare-and-set operation: allows writing only if the value is the same as it was when was read
Reasons to have transaction
foreign key constraint: when inserting dependent objects
denormalized data (often needed to avoid joins in NoSQL): if we want to update both record and the aggregation value that leave in another object
updating secondary indexes
Retrying transaction issues
transaction actually succeeded: server failed to acknowledge client about that
if an error is due to overload that will increase the load even more. Solution: limit retries; handle overload errors differently
in case of permanent error (opposed to transient) doesn't make sense to retry. Example: constraint violation
if transaction has side effects outside of database. Solution: two-phase commit (2PC)
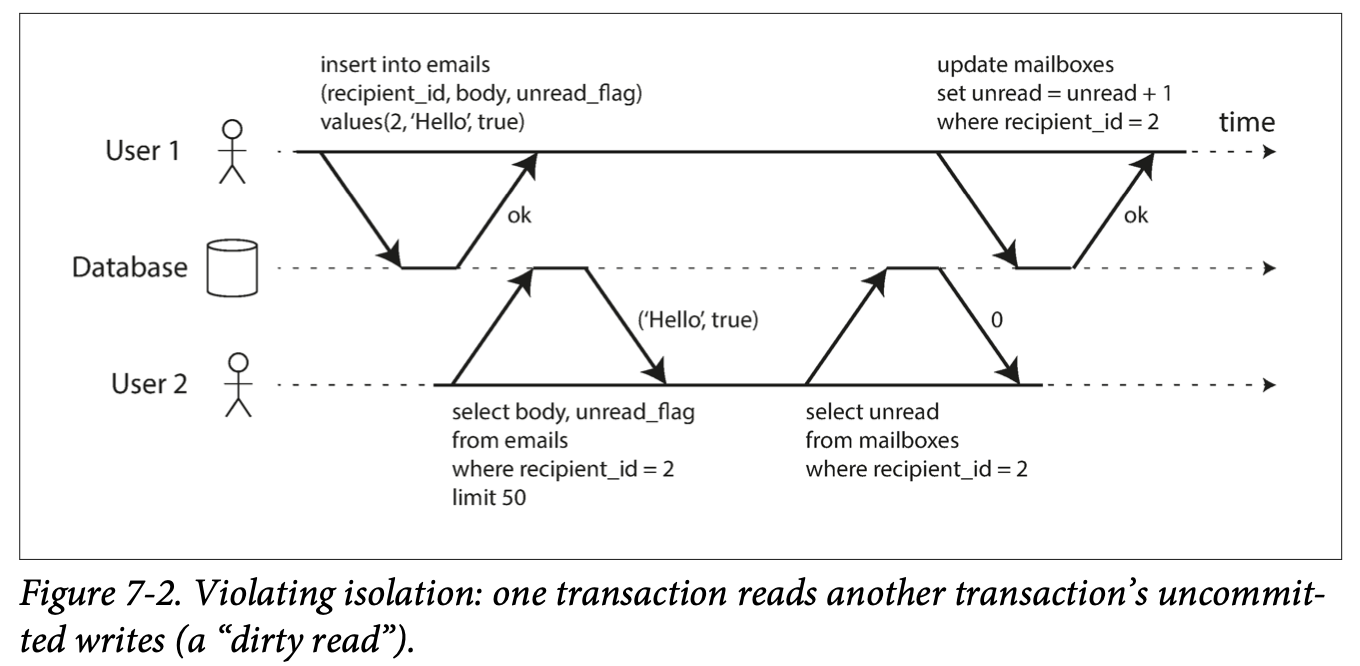
Weak Isolation - Read committed
serialisable isolation has performance cost
Read committed (default in many databases):
no dirty reads (only read committed data); prevents seeing system in partially updated state; if aborted previous reads would be wrong. Solution: ignores locked value, and uses old, committed one
no dirty writes (only overwrite committed data). Solution: lock records
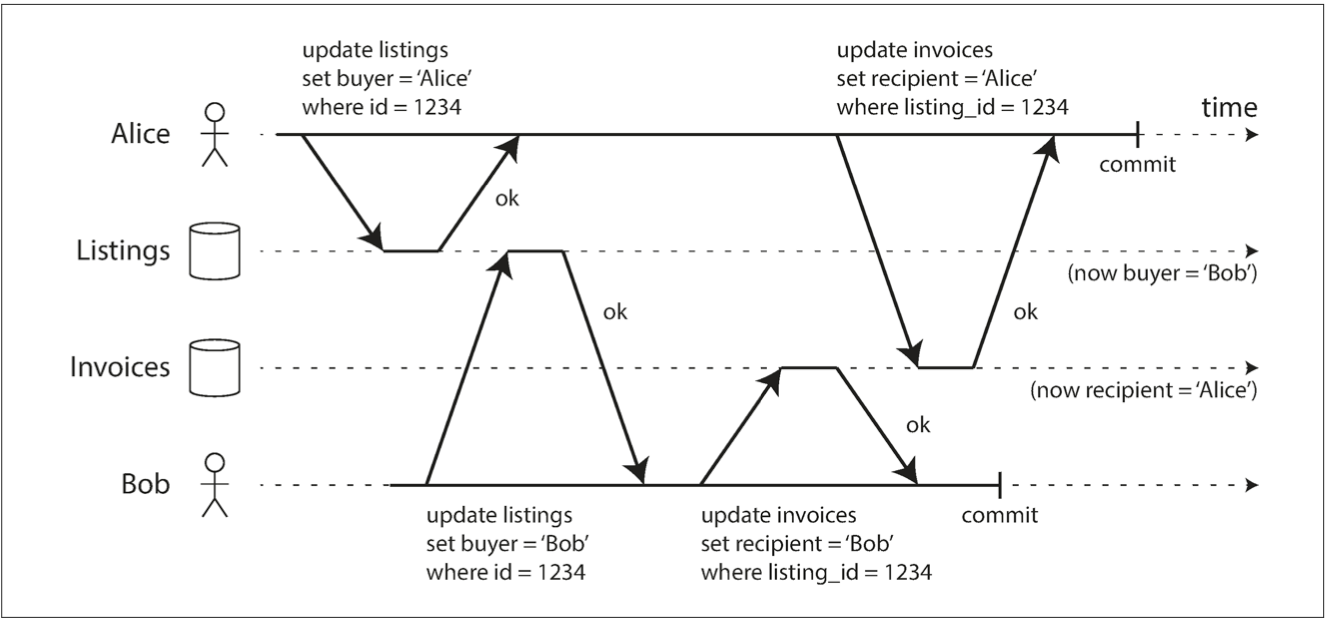
Weak Isolation - Read committed
Problem with Read Committed is non-repeatable read or read-skew
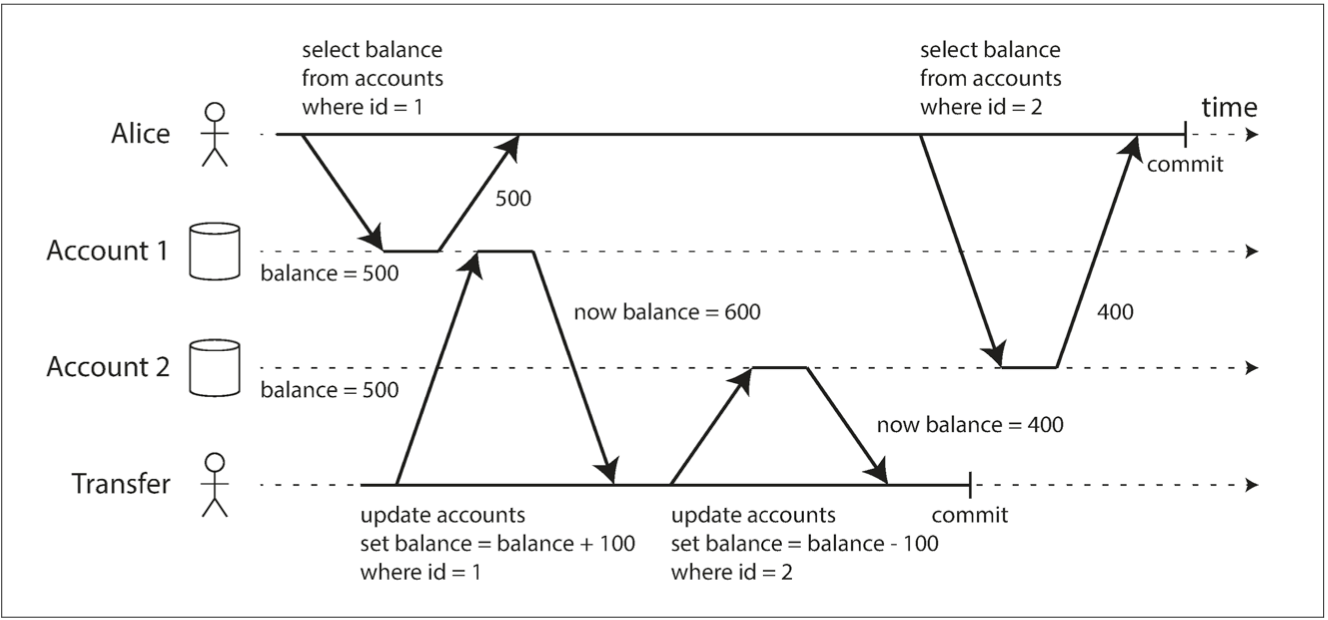
This is a big issue for:
- backups (since writes are made during backup process)
- analytics
- integrity checks
Weak Isolation - Snapshot isolation
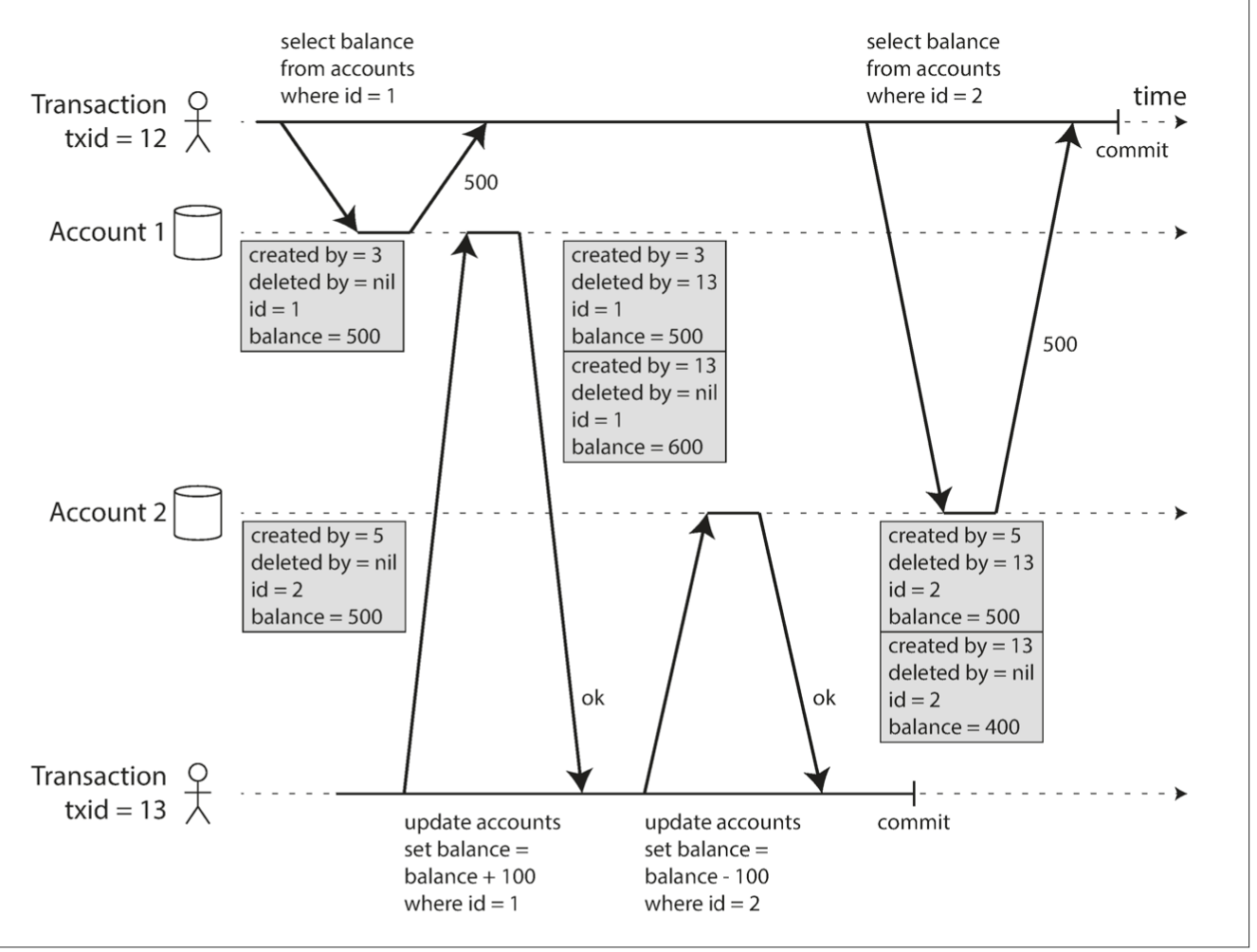
Snapshot isolation (or repeatable read)
each transaction reads from a consistent snapshot - transaction sees all the data that was committed to the database before transaction started
writes are implemented with lock
for reads multiple committed versions of the records are used (multi-version concurrency control - MVCC)
reads and writes throughputs are
independent
In Oracle it is called serializable
in PostgreSQL and MySQL -
repeatable read
Weak Isolation - Snapshot isolation
Snapshot isolation
Another approach is used in CouchDB, Datomic, and LMDB. Although they also use B-trees, they use an append-only/copy-on-write variant that does not overwrite pages of the tree when they are updated, but instead creates a new copy of each modified page. Parent pages, up to the root of the tree, are copied and updated to point to the new versions of their child pages. Any pages that are not affected by a write do not need to be copied, and remain immutable.
With append-only B-trees, every write transaction (or batch of transactions) creates a new B-tree root, and a particular root is a consistent snapshot of the database at the point in time when it was created. There is no need to filter out objects based on transaction IDs because subsequent writes cannot modify an existing B-tree; they can only create new tree roots. However, this approach also requires a background pro‐ cess for compaction and garbage collection.
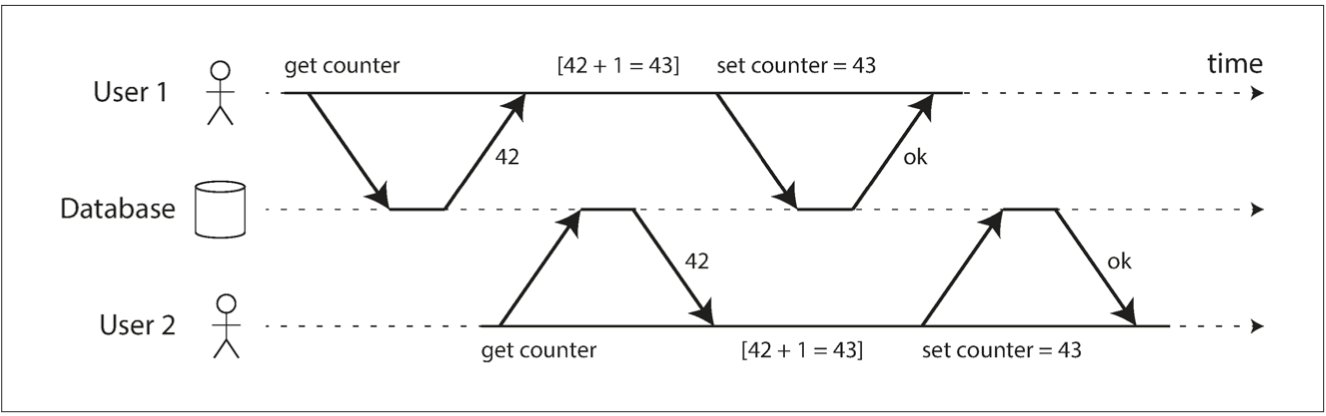
Weak Isolation - Lost Update
Happens when application reads some value from the data‐ base, modifies it, and writes back the modified value (a read-modify-write cycle).
Scenarios:
- increment counter, or update account balance
- adding element to a JSON file
- 2 users editing the same object (wiki page)
Weak Isolation - Lost Update
Atomic update operations
MongoDB provide atomic operations for making local modifications to a part of a JSON document, and Redis provides atomic operations for modifying data structures such as priority queues.
Implementation: exclusive lock on the record so it cannot be read (cursor stability).
Explicit locking made on application level
Automatically detect lost updates - uses snapshot isolation (somehow?) to detect and rollback transactions leading to lost updates
Compare-and-set - with write request send the read value as well
for replicas - commutative data types work (counter, sets, etc.) - otherwise app=level conflict resolution
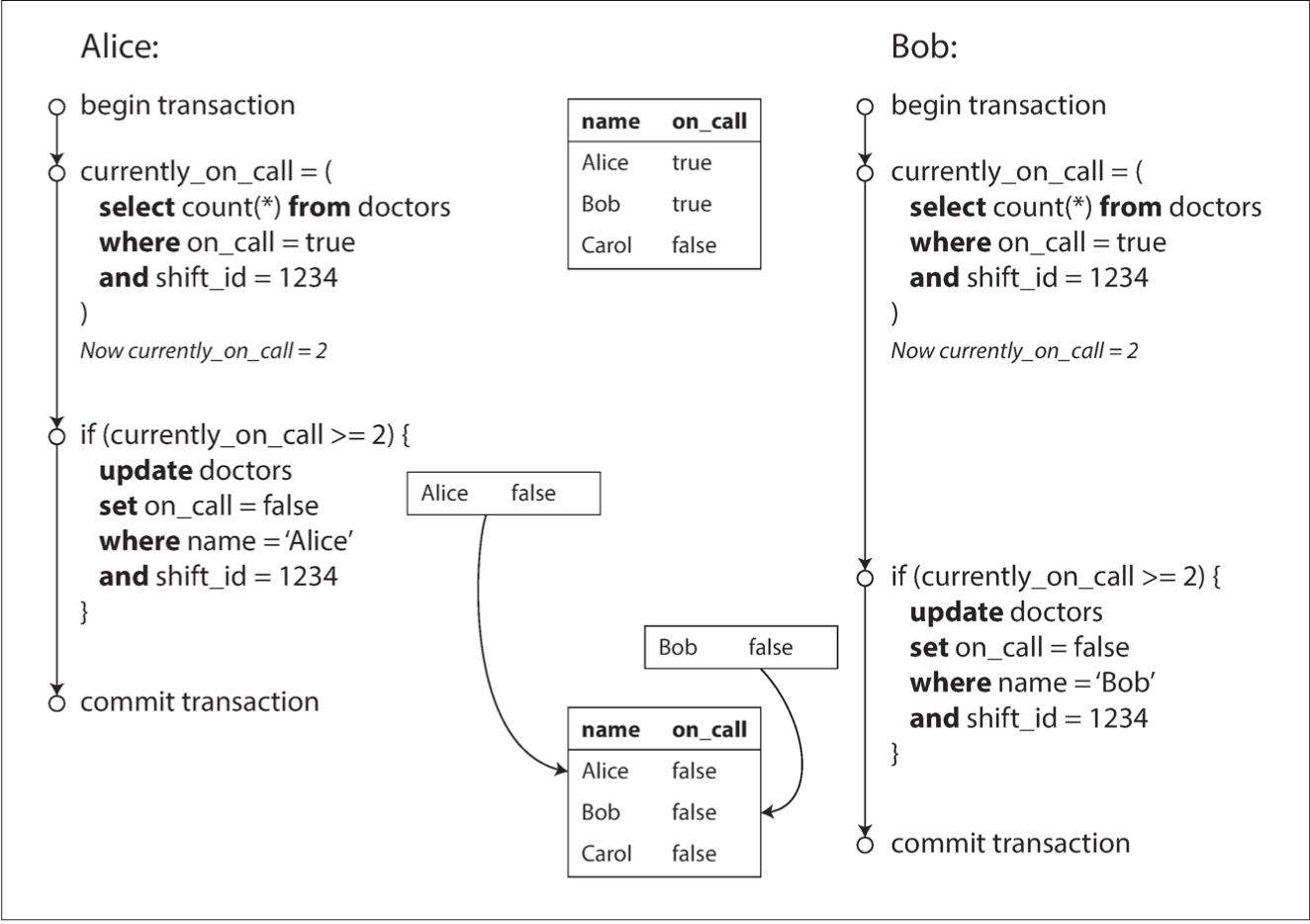
Weak Isolation - Write Skew
write skew is a generalization of the lost update problem. Write skew can occur if two transactions read the same objects, and then update some of those objects (different transactions may update different objects). In the special case where different transactions update the same object, you get a dirty write or lost update anomaly (depending on the timing).
Weak Isolation - Write Skew
- atomic single-object doesn't help since multiple objects involved
- automatic detection doesn't work
- most databases do not support multi-object constraints
- potential solution: lock all involved records for updates
- best solution: serialisability
Weak Isolation - Write Skew
- meeting room booking system
- multiplayer game - using lock we can prevent users from moving the same figure. We can't prevent them from moving it to the same position or another move that violates the rules of the game
- claim a username (unique constraint might help though)
- spending money or bonus points - preventing double spending
phantom pattern: when write on one transaction changes the result of a search query in another
for read-only queries snapshot isolation fixes phantom issue
for read-write operations write skew happens
Weak Isolation - Write Skew
Materialising conflicts
for doctors' example we could lock all read records for updates
for meeting room or double spend examples that's difficult because we're adding records so nothing to lock
solution: create those records. For example, generate all possible combinations of time intervals for each rooms and lock lock the room%time record whenever it's read for a booking transaction. Those records might not be used for bookings data but just for locking reasons.
Since it pollutes data model it is not recommended
Serializability
makes transactions to run kinda in serial order - one after another
solves all weak isolation issues
Serializability - Actual Serial Execution
execute only one transaction at a time, in serial order, on a single thread.
Locks the whole DB
used by: VoltDB/H-Store, Redis, Datomic
single threaded became possible in 2007 due to:
- RAM is cheap enough to keep the whole dataset in memory. Transactions execute much faster if loaded from memory rather than from disk
- separation of long read analytics transactions and fast OLTP transactions
to scale - partition database so that each transaction needs data within a single partition only
This can be problematic with secondary indexes.
VoltDB reports a throughput of about 1,000 cross-partition writes per second
Serializability - Actual Serial Execution
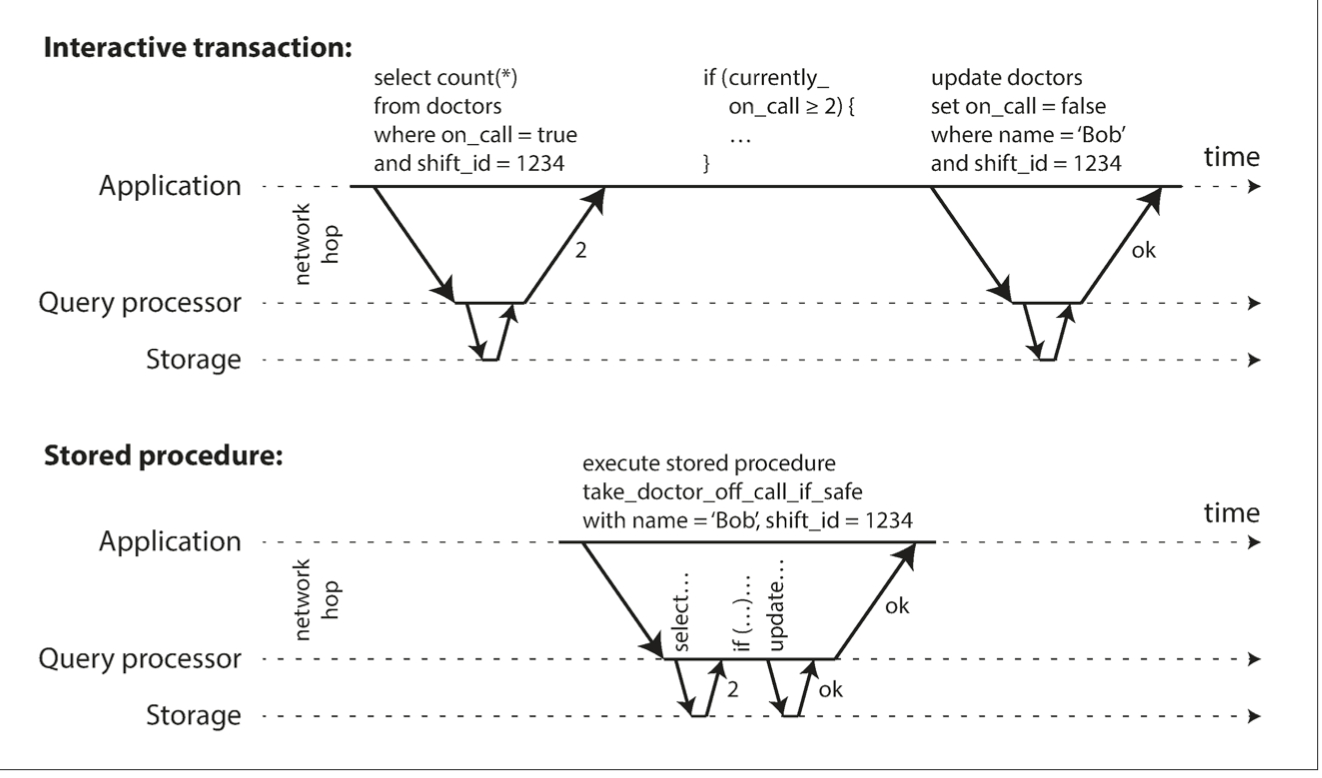
single-threaded might be faster due to no overhead of locking. It's throughput is limited to single CPU though.
transactions have to be structured differently - 1 transaction per HTTP request. Alternative: stored procedure
Serializability - Actual Serial Execution
problems with stored procedures:
- each Db vendor has its own language (modern DBs use general-purpose languages though: Java, Clojure, Lua)
- code running in DB is difficult to manage (versions, debugging)
- DB is more vulnerable since used by many apps - if a stored procedure has memory leak - it will affect everyone
Serializability - 2PL
Two-Phase Locking (used in MySQL and SQL Server). Locks a record/index/table
In oppose to snapshot isolation (where reads and writes are independent) writes block reads and reads block writes:
- If transaction A has read an object and transaction B wants to write to that object, B must wait until A commits or aborts before it can continue.
- If transaction A has written an object and transaction B wants to read that object, B must wait until A commits or aborts before it can continue.
to read object - acquire lock in shared mode. Several transactions can have shared locks on the same object
to write object - acquire lock in exclusive mode. Others cannot have any kind of logs if record is on exclusive lock. Also exclusive lock can be acquired only if record is not locked at all
such approach can lead to deadlocks (one of the transactions is aborted by DB then)
Serializability - 2PL
another type of lock is predicate lock which is put on a query result rather than single row or table
it can solve a phantom problem - room booking app - since predicate is applied to non-existing records as well
to read - set a shared predicate lock on query results
to write - make sure no predicate lock on the record
biggest problem is performance
single slow transaction can halt others
predicate logs specifically requires time-consuming matching checking (to workaround this we can approximate query to an indexed result - called index-range locking or next-key locking)
Serializability - SSI
Serializable Snapshot Isolation - very new and doesn't have enough production data
Instead of locking check for violation after transaction is complete - optimistic
if there are a lot of transaction accessing the same key - most of them will be aborted leading to bad performance
how it works:
it is snapshot isolation + a way to understand if transaction operated on stale data, and abort that transaction
Serializability - SSI
Detect stale multi-version concurrency control (MVCC)
uncommitted write occurred before the read
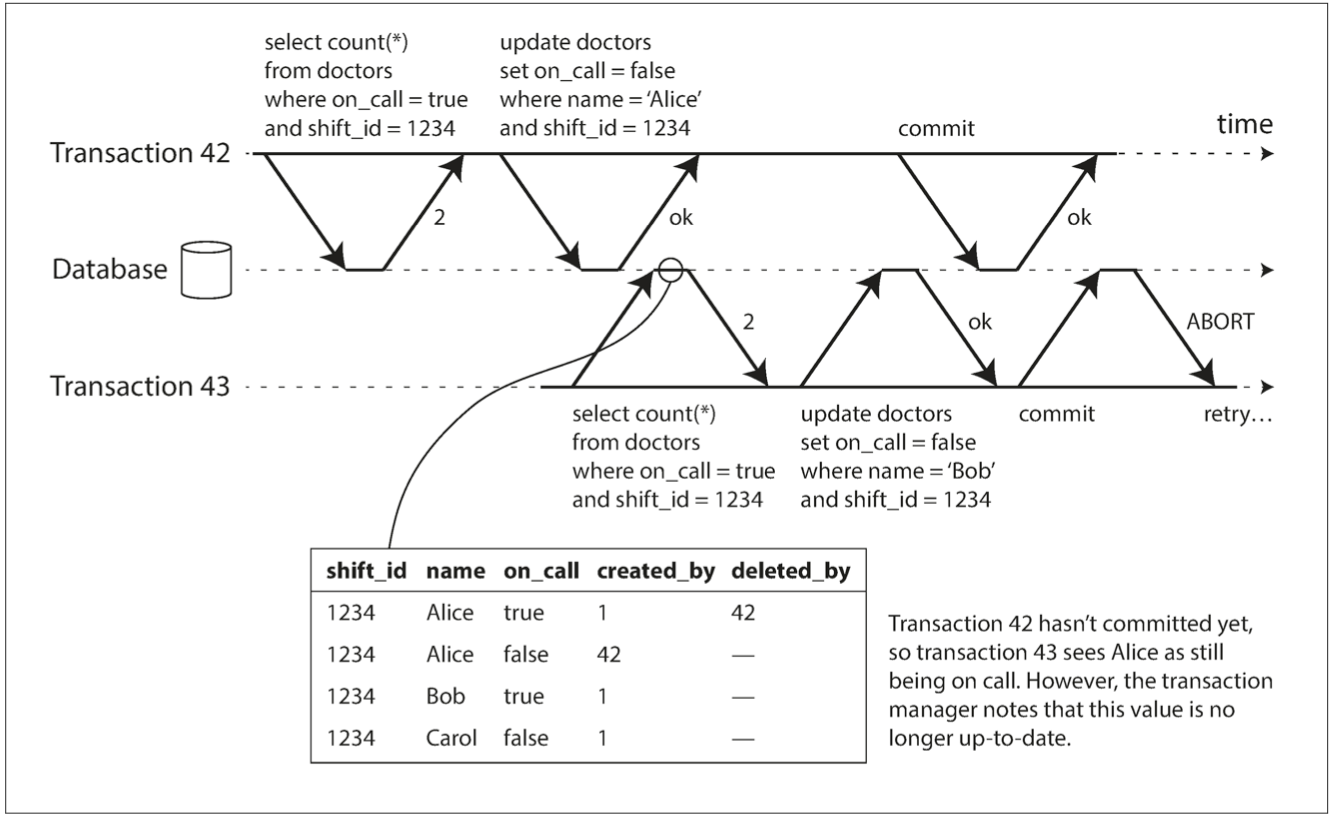
Serializability - SSI
Detect writes that affect prior reads
the write occurs after the read
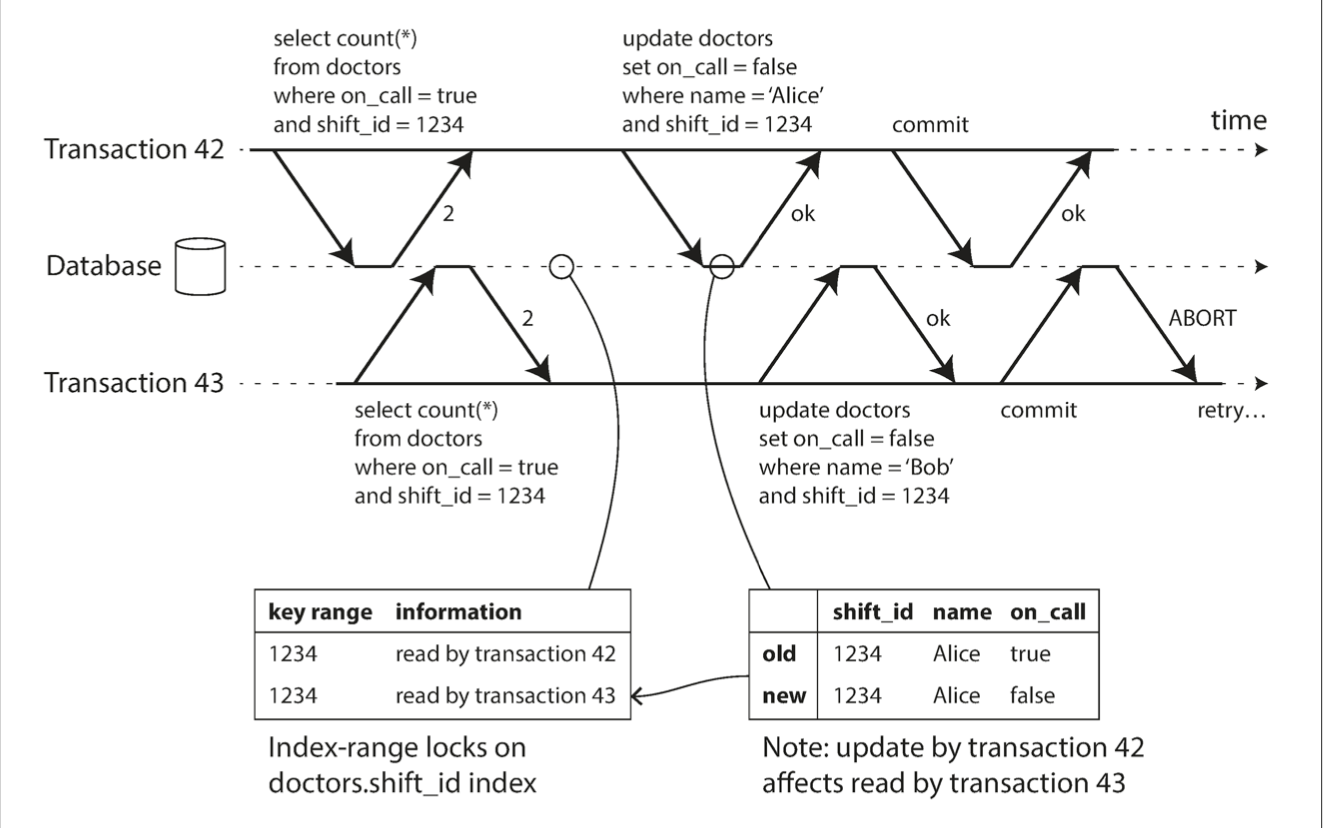
Serializability - SSI
If the database keeps track of each transaction’s activity in great detail, it can be precise about which transactions need to abort, but the bookkeeping overhead can become significant. Less detailed tracking is faster, but may lead to more transactions being aborted than strictly necessary.
Transactions
By Michael Romanov



