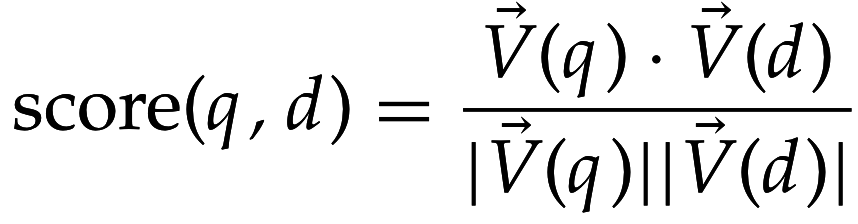


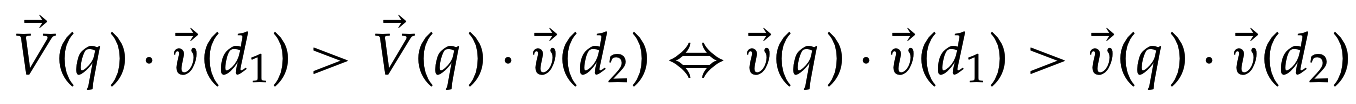
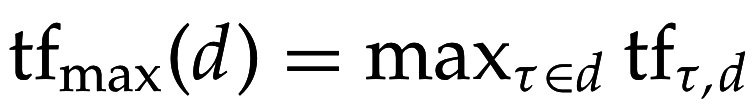
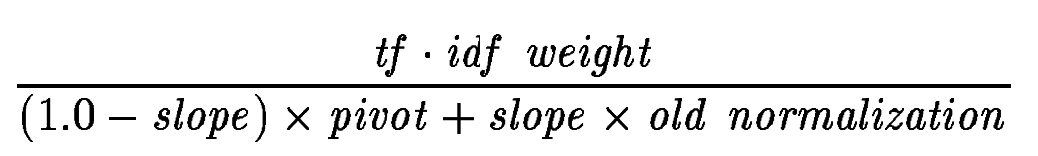
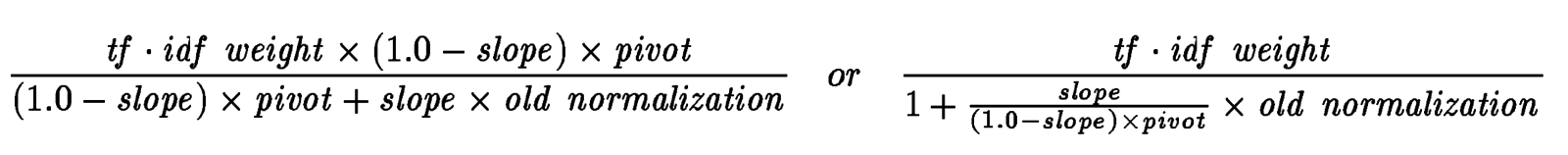
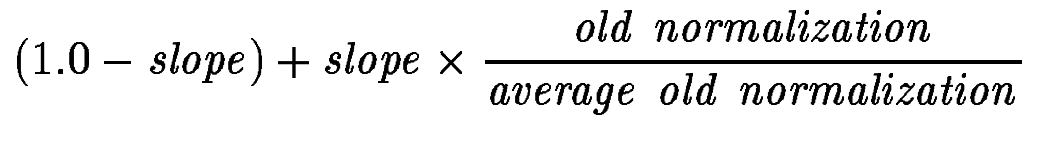
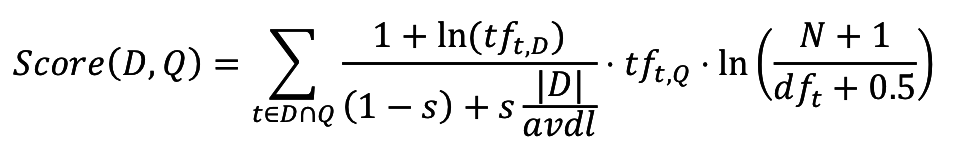

Nikita Zhiltsov
Research fellow at Kazan Federal University (Russia)
Лекция 3
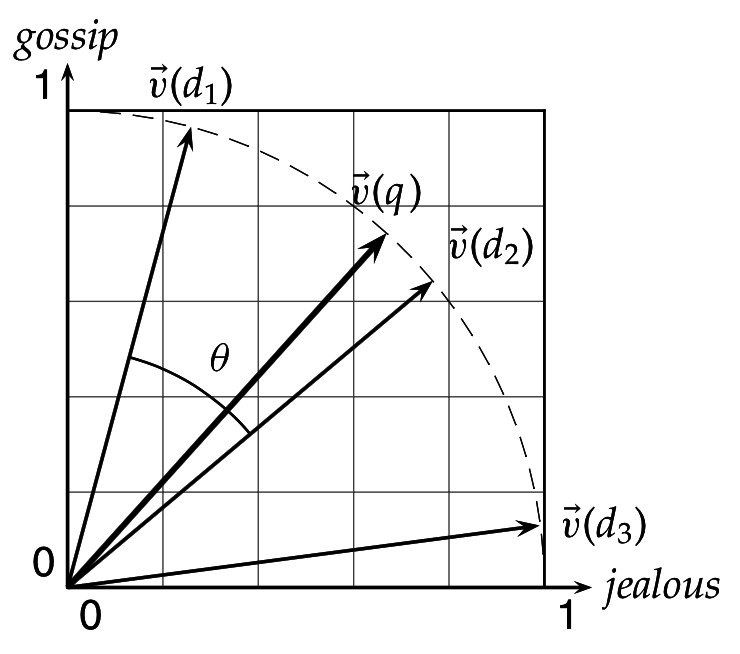
Ранжирование в векторной модели документа
*см. булевский поиск
*неформальный вывод, см. вероятностную интерпретацию в Robertson (2004)
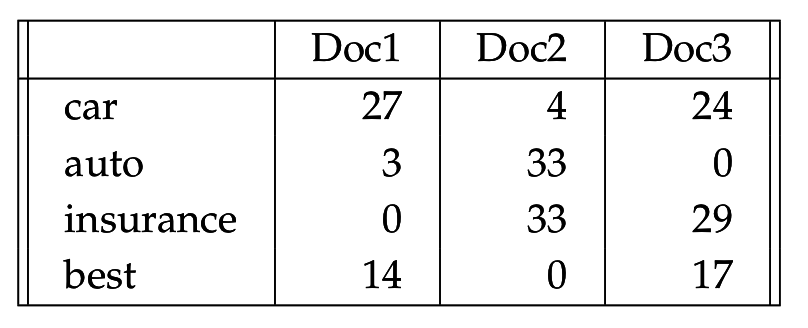
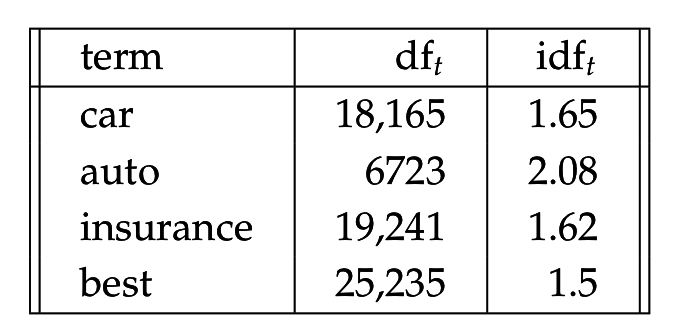
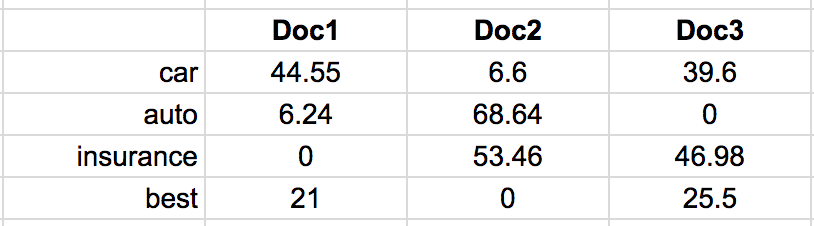
idf оценивает спефичность термина
Вычислительная сложность 10 шага по N? Какую структуру данных использовать?
Text
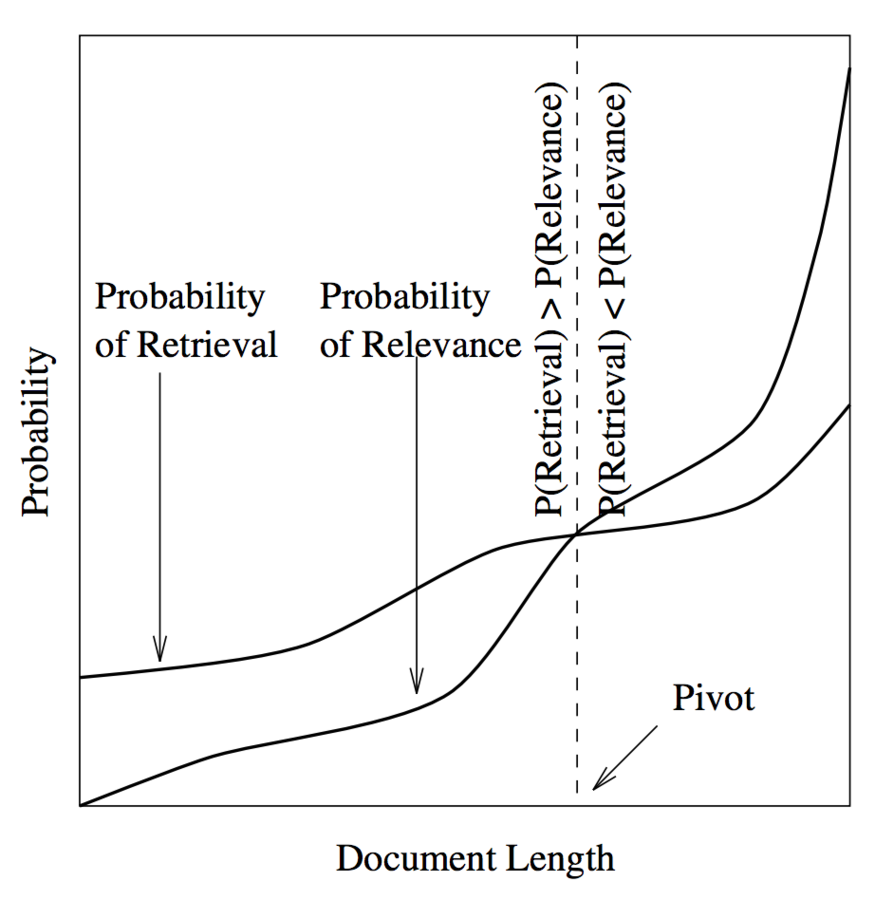
=> косинусное ранжирование искажает оценку релевантности за счет длинных документов
- количество уникальных терминов в d
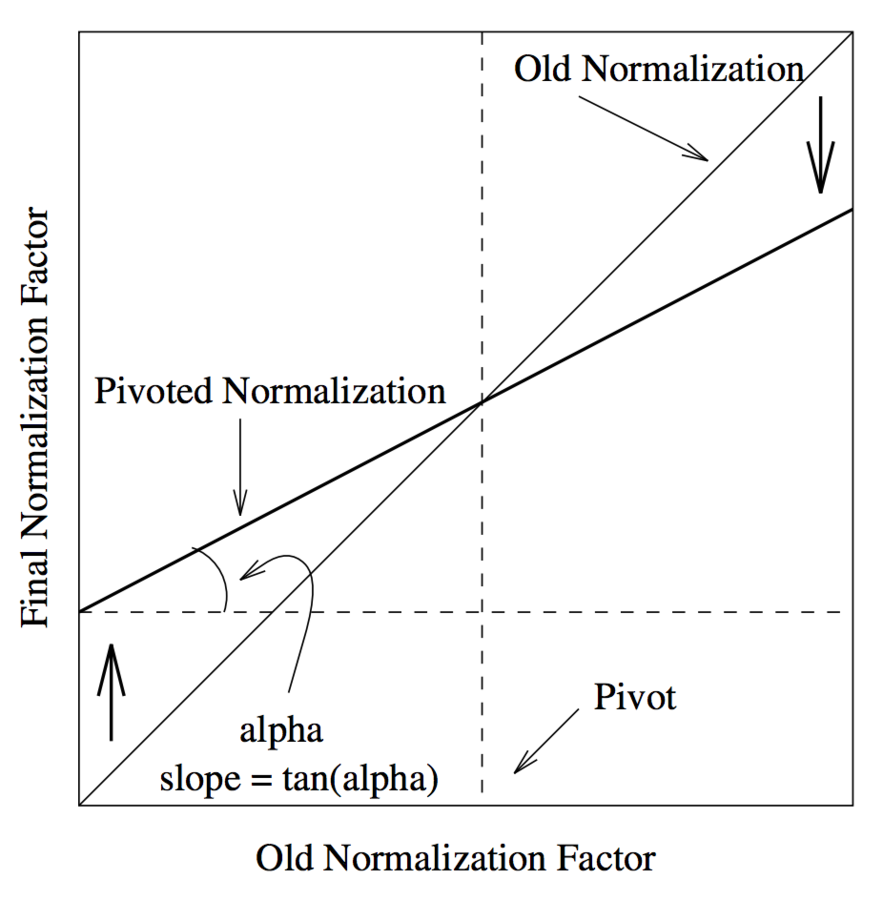
Необходимо оптизимизировать 2 параметра: pivot и s
=> можно просто зафиксировать pivot как среднее значение (по всей коллекции) при старой нормализации и свести к оптимизации 1 параметра (slope)
изменения в pivot можно компенсировать изменением в slope
*вариант модели, см. практическое задание 5
By Nikita Zhiltsov




