SakuSaku検索
Aug-2013
Nobuhide Tsuda
自己紹介
名前:津田伸秀
サイト: http://vivi.dyndns.org/ twitter:vivisuke
facebook:https://www.facebook.com/nobuhide.tsuda
ぼちぼちソフト作家、年齢不詳のおじさん、自宅研究員(主席)
趣味:テニス、オセロ、思考ゲーム・パズル類
Qt/C++ 使い, 一応webアプリ(PHP, JS, jQ, SQL)も出来るよ
Windows用テキストエディタ ViVi を延々開発中
最近は、世界最速「さくさくエディタ」 開発中だよ
迷走中、お仕事募集中でござるぞ
名前:津田伸秀
サイト: http://vivi.dyndns.org/ twitter:vivisuke
facebook:https://www.facebook.com/nobuhide.tsuda
ぼちぼちソフト作家、年齢不詳のおじさん、自宅研究員(主席)
趣味:テニス、オセロ、思考ゲーム・パズル類
Qt/C++ 使い, 一応webアプリ(PHP, JS, jQ, SQL)も出来るよ
Windows用テキストエディタ ViVi を延々開発中
最近は、世界最速「さくさくエディタ」 開発中だよ
迷走中、お仕事募集中でござるぞ
BackGround
文字列検索
- 長さ n の text 中の
- 長さ m の pattern 位置を検索
- 世の中で広く使われている重要な基礎技術
- テキストエディタ、ブラウザなどなど
- ファイルから検索(grep)
- DNA 検索
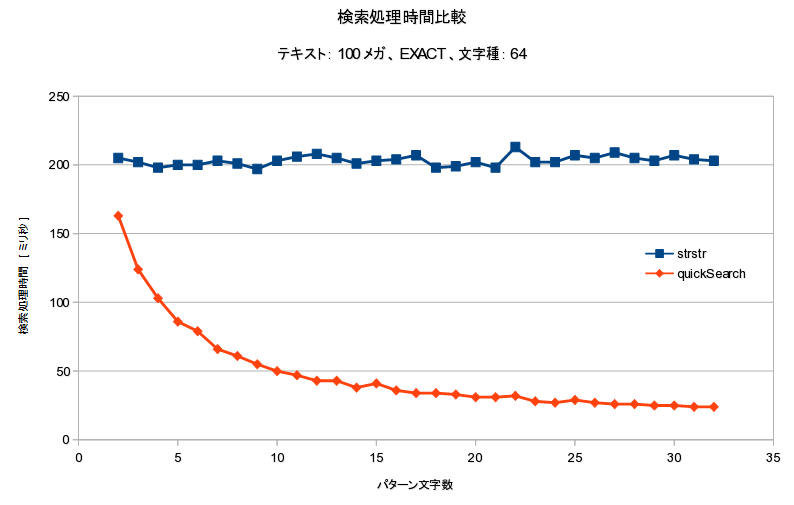
strstr, std::Search
- 最も単純で基本的なアルゴリズム
-
brute force
- ワーストケース:O(n*m)
- 平均的には O(n) で、そこそこ速い
- pat 前処理を行わない
BM系
- 不一致の時にジャンプしたら速くなるんじゃね?
- pat を前処理した情報を利用
- O(σ) のメモリを使用 (※σ は文字種数)
- 検索処理時間:
- 平均的:O(n/m)
- 最悪:O(n*m)
- BM, BM-Horspool, QuickSearch などなど
- QuickSearch は単純で、最も高速と言われている
検索処理時間
bitmap(bitap)系
-
レジスタの1ビットをオートマトンの1状態に
- 複数の状態遷移を同時並行的かつ高速に処理
- Shift-Or, Shift-And
- 前処理:
- 処理時間:O(σ+m)
- 使用メモリ:σ×レジスタサイズ
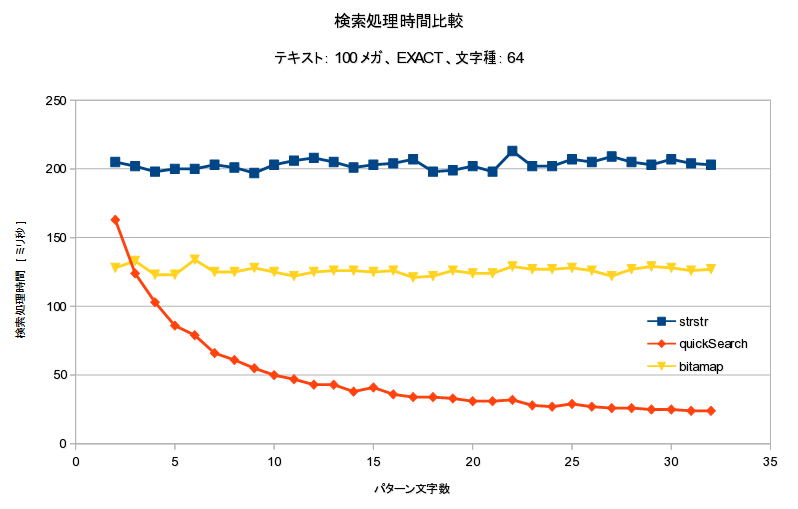
- 検索処理時間:O(n)
- 長所:パターン長、文字種数に依らず、高速
- 長所:検索時の特定文字同一視処理が無コスト
- 欠点:レジスタビット数を超えると低速
検索処理時間
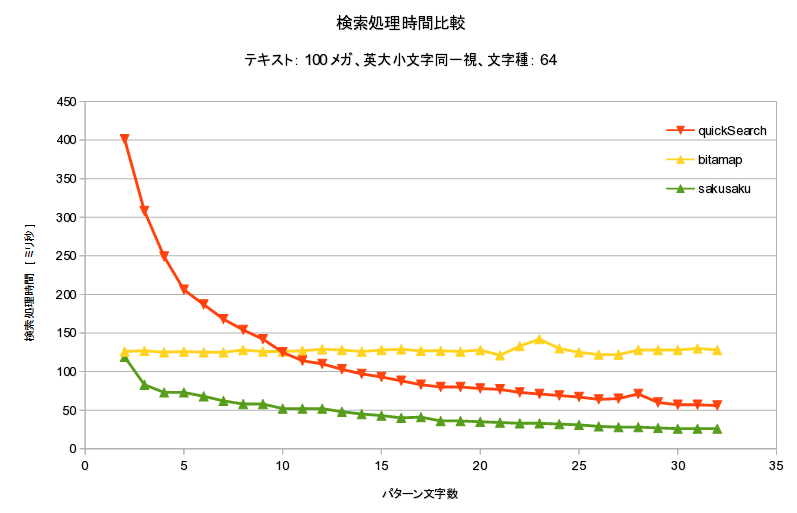
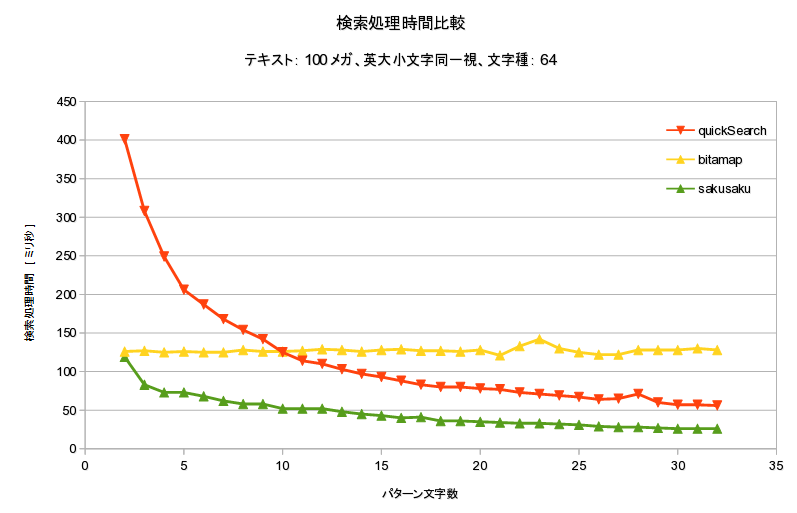
英大小文字同一視
テキストエディタでは英大小文字同一視がデフォ
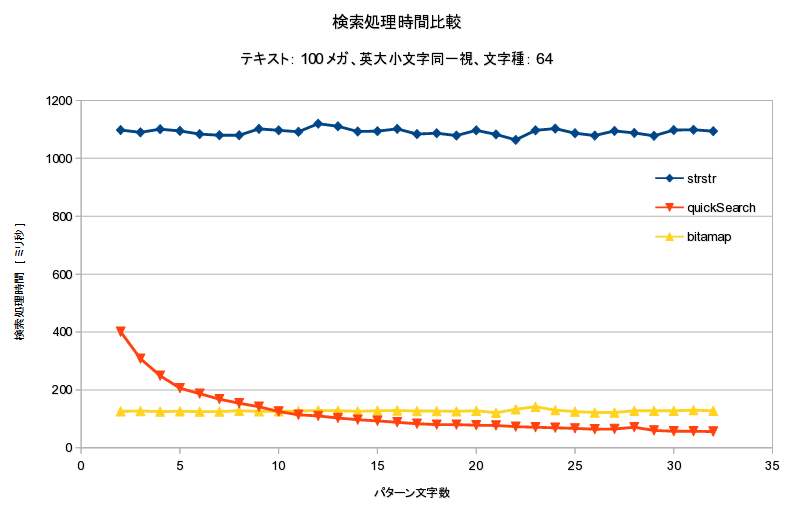
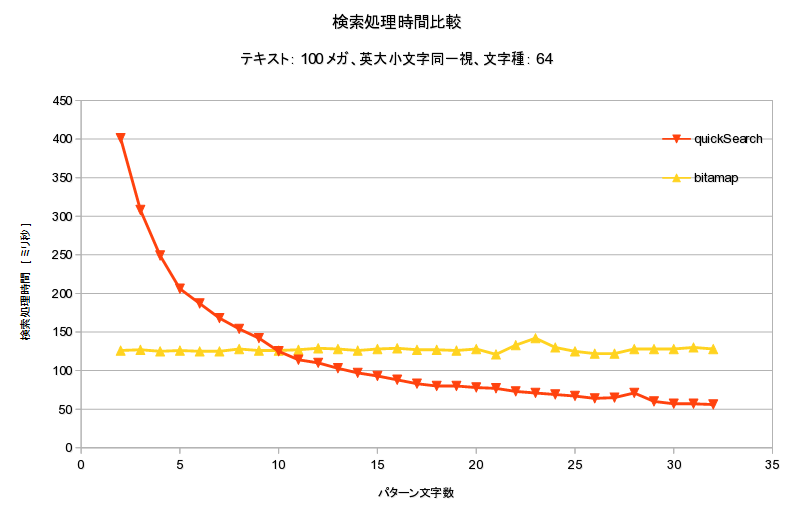
bitmap系 vs BM系
-
2つの処理時間を比較すると・・・
- 条件によって詳細は変わるが
- パターンが短いとbitmap系が高速
- パターンが長いとBM系が高速
- 文字種が少ないとbitmap系が高速
- 文字種が多いとBM系が高速
- 英大小文字同一視ではbitmap系有利
さくさく検索アルゴリズム
発明は組み合わせだ
bitmap系とBM系のアイデアを組み合わせれば
高速なアルゴリズムが出来るんじゃね?
うまくいけば・・・
そんな単純なこと
既に誰かが
試してるんじゃね?
ちょろっと調べたけど
先行研究わかんない
検索アルゴリズム多すぎ
全部理解するのしんどいでござる
→ 実装して速度比較だ
速度計測結果
- 英大小文字区別、同一視の両方において、ほぼ最速
- 最悪ケースでも O(n)
- 実は bitmap の2倍遅かったので O(2*n)
速度計測結果
まじっすか?
- バグってない?いんちきしてない?
- 最速&既に誰かが考案しているなら、
- だったら既に有名になってるんじゃね?
- 本当に新規性がある?
- BMH → QuckSearch に10年もかかった
- 誰しも盲点はある
- あり得ない話ではない
- 本当に最速なのか?
- 知らないアルゴリズムがあるではないか?
- 専門家に聞くのがよさげ
- facebook, twitter でつぶやいてみた
- BNDM 教えてもらった
BNDM
- bitmap系+BM系 というアイデアは(当然)既にあった
-
Backward
- パターンの末尾からチェック
- 非決定性オートマトンでパラレル処理
- 不一致の場合、マッチ可能性のある場所から再チェック
- 検索処理時間
- 平均的ケース:O(n/m)
- ワーストケース:O(n*m)
- 「さくさく検索」の方が高速、メモリ使用量多め
BNDM family
- いろいろある
- SBNDM (Navarro, 2001; Peltola & Tarhio, 2003)
- LNDM (He & Fang, 2004)
- FNDM (Holub & Durian, 2005)
- Forward-SBNDM (Faro & Lecroq, 2009)
Forward-SBNDM
- smart を参考にインプリメントして速度計測
- さくさく検索の高速化テクニックが既に採用されていた orz
- しかも、さくさく検索よりも概ね高速 orz orz
SakuSaku検索詳細
Shift-And コード
uint R = 0;uint mask = 1 << (m-1);while( text != tend ) {R = ((R << 1) + 1) & CV[(uchar)*text++];if( (R & mask) != 0 ) return text - m; // found}return 0; // not found
単純が一番
- Shift-And で不一致の場合にスキップすればいいんじゃね?
- backward ではなく forward スキャン
- ワーストケースで O(n) となる
- ワーストケースで O(n*m)は避けた方がよいと思う
-
R != 0 の間は一致の可能性がある
- R == 0 であれば不一致
スキップ方法
- R == 0 となった時に text[m-1] を参照
- CV[text[m-1]] == 0 ならばtextをmスキップ可能
- CV[ch] == 0 となる確率は、((1-σ)/σ)^m
- スキップの期待値は m * ((1-σ)/σ)^m
- σ=64, m = 10 ならば、8.543
- 期待値は結構大きい
文字種数(σ)が小さい場合
-
σが小さく、m が大きいとスキップ確率が低下する
- σ=4, m=250 の場合、(3/4)^250 = 5.8*10^(-32)
- DNA検索は通常こんな感じ
-
スキップ判定を1文字にせず、複数文字で行う
- 1回のスキップ量は減るが、確率が上がるので、
- 期待値は増える
- σ=4,m=250の場合に、最後の2文字をチェックすると
- 1 - (1-5.8*10^(-32))^2 = 1.16x10^(-31)
- σ、m により、スキップ量期待値を最大にするチェック数があるはず(要解析)
- 文字の参照にはコストがかかるので、少なめがよい
パターンが長い場合
-
パターン文字数が大きくレジスタビット長を超えると低速
- 33文字の検索は32文字検索の5割増
- レジスタが32ビットの場合の話
- 33文字以上では他のアルゴリズムに切り替えるほうがいいかもしれない
Conclusion
- オリジナリティがあるかどうかはまだ不明
- 有効性はかなり疑問
- また車輪の再発明をやってしまいました
- が、ちょっとだけ夢を見れたのでよしとしよう
- (大変だけど)論文・教科書をしっかり読みましょう
SakuSaku検索
By Nobuhide Tsuda



