さくさくエディタ
x64 Data Structure
自己紹介
名前:津田伸秀
サイト: http://vivi.dyndns.org/ twitter:vivisuke
facebook:https://www.facebook.com/nobuhide.tsuda
ぼちぼちソフト作家、年齢不詳のおじさん、自宅研究員(主席)
趣味:テニス、オセロ、思考ゲーム・パズル類
Cocos2d-x/Qt/C++ 使い, 一応webアプリ(PHP, JS, jQ, SQL)も出来るよ
Windows用テキストエディタ ViVi を延々開発中
世界最速「さくさくエディタ」 も開発中だよ
迷走中、お仕事募集中でござるぞ
今日の内容
- 「さくさくエディタ」 32bit 版バッファデータ構造概説
- 64bit 版での問題点
- 解決策案たち
32bit 版さくさくエディタ
最速賢美 さくさくエディタ
- 編集エンジンが世界最速
- ユーザを賢く
- vi(美) コマンドサポート
- 窓の杜大賞2013ノミネート

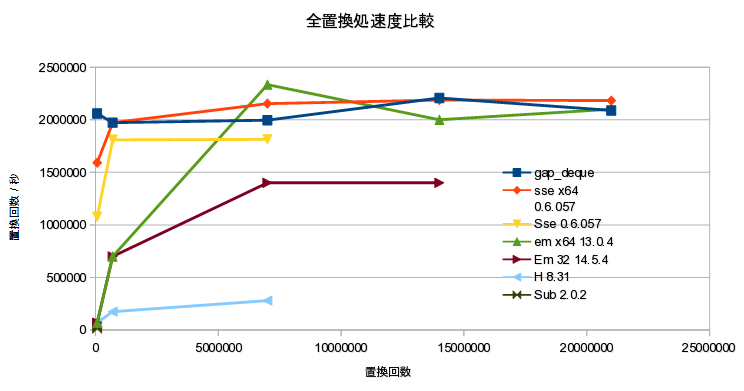
全置換速度比較
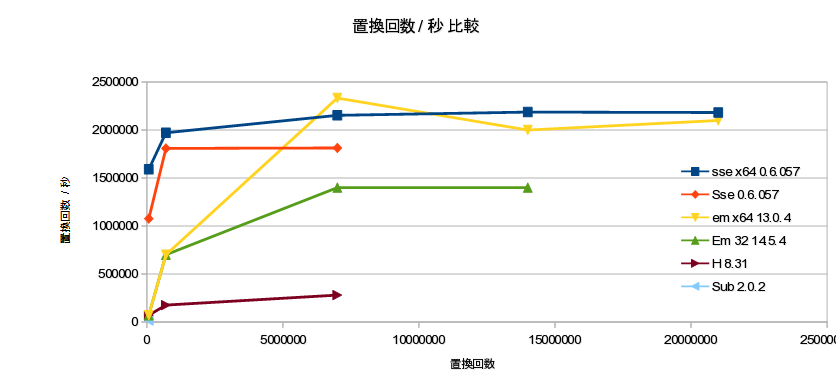
その他の機能・特徴
- 文字削除時アニメーション
- 右下背景画像
- 全体マップ
- Zen-Coding
- カラーテーマ
- 各種言語サポート
- 遅延無し折り返し処理
- マークダウン
- 自動・手動補完
- スタートページ
- ネタ エディタではありません
32bit 版 編集バッファ
データ構造概説
テキストエディタ
- エディタとは、簡単に言うと、プレーンなテキスト情報を保持し、ユーザの指示により内容を表示・編集するプログラム
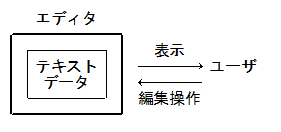
バッファ
- バッファ:テキストそのものを管理する部分
- 必要十分な機能・品質・高速性・高メモリ効率・使いやすさ・拡張性等が要求される

-
最重要メソッド:文字参照・挿入・削除
- charAt(index_t pos)
- insert(index_t pos, string str)
-
erase(index_t first, index_t last)
- ※ 文字位置は整数で指定(他の方式もある)
- ランダムアクセス、編集処理の高速性が求められる

テキストデータ
- 基本的には1次元コンテナに文字を格納するとよい
- C++ 汎用コンテナクラス:
- std::vector<T> // 動的配列
- std::list<T> // 双方向リンクリスト
vector と list
- std::vector, std::list には一長一短がある

許されるのは O(N*Log N)まで

解決策
- 行単位管理 (vi)
- ギャップバッファ (Emacs)
局所参照性
- テキストエディタのテキスト参照箇所には局所性がある
- 常に97%、通常は99%以上がシーケンシャル参照
- http://www.cs.unm.edu/~crowley/papers/sds.pdf
- 編集箇所についても同様の局所性がある
- 局所性を前提とすることで、処理速度向上を実現できる
ギャップバッファ
- 局所参照向けに std::vector を改良
- データが無い部分を中央に配置(ギャップ)
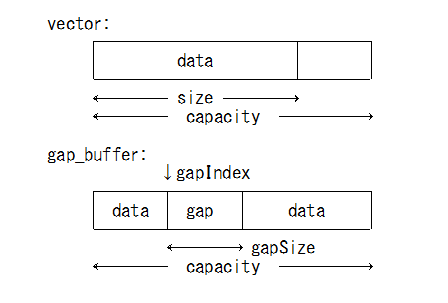
ギャップバッファ
template <typename T> class gap_buffer {
T *m_data; // データ領域
pos_t m_gapIndex; // ギャップ位置
ssize_t m_gapSize; // ギャップサイズ
ssize_t m_size; // データサイズ、capacity = size + gapSize
};1文字参照
T GapBuffer::charAt(pos_t pos) const
{
if( pos >= m_gapIndex ) // pos がギャップ以降
pos += m_gapSize; // ギャップサイズ分補正
return m_data[pos];
}
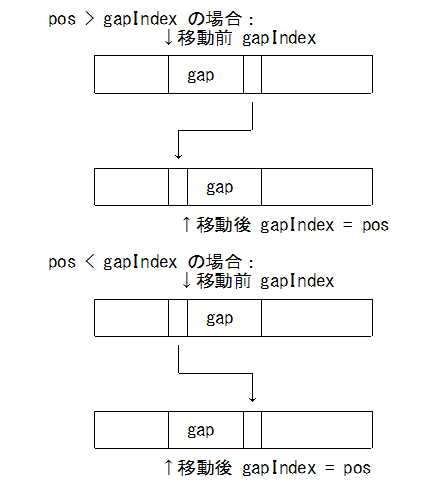
ギャップ移動
void GapBuffer::moveGapTo(pos_t pos)
{
if( pos < m_gapIndex ) {
[pos, m_gapIndex) を [pos+m_gapSize, m_gapIndex+m_gapSize] に移動
m_gapIndex = pos;
} else if( pos > m_gapIndex ) {
[m_gapIndex+m_gapSize, pos+m_gapSize) を [m_gapIndex, pos) に移動
m_gapIndex = pos;
}
}
ギャップ移動
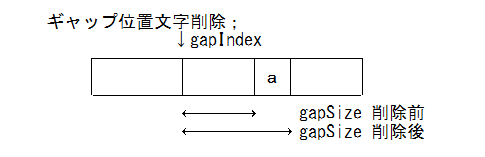
削除
void GapBuffer:erase(pos_t pos) {
moveGapTo(pos); // ギャップを pos に移動
++m_gapSize; // ギャップサイズを増やすだけで文字が消える
}
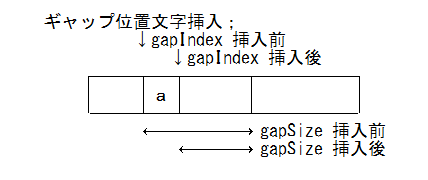
挿入
void GapBuffer::insert(pos_t pos, T ch) {
if( ギャップが無い )
データエリアを(1.5~2倍に)拡張;
moveGapTo(pos); // ギャップを pos に移動
m_data[m_gapIndex++] = ch; // ギャップ先頭に文字挿入
--m_gapSize;
}
パフォーマンス計測
- 総合ベンチマークとしては何を計測すべきか?
- 参考:「サクラエディタはベンチマークの夢を見るか?」
- シーケンシャルな参照、削除、挿入処理時間が最も重要
- →全置換処理を計測するのがよい
- ("XYZはいってる。"*7+"\n")*(100~10万行) に対して、「XYZ」→「abcde」全置換
- C++ でゼロから実装した gap_buffer<T> を計測
- 比較対象:QVector<wchar_t>, QLinkedList<QString>
計測結果

64bit化に於ける問題点
64bit化
- VC++ x64 モードでビルドすると、64bit モードとなる
- 4GB超のメモリが使用可能になる
- 32bitモードでは合計4GBまで
- 実質的に使用できるのは2GB程度
- ポインタが 64bit となる
- VC++ では long は32bit, long long が64bit
- 4GB超のメモリが使用可能になる
64bit 化に伴う問題点
- 32bit版ではオープン可能ファイル上限は300MB程度
- 64bit版では10GB以上でもオープン可能
- ギャップバッファの挿入・処理時間:
- 局所的であれば O(1)
- 非局所的であれば O(N)
- 一般的に O(N) は高速なアルゴリズムであるが、N が大きくなリすぎると、処理時間が問題となる
- オープン・全置換などで時間を要するのは説得力があるが、1文字の挿入・削除で最悪1秒以上を要するのはいかがなものか?
解決策案たち
解決策案たち
- gap_deque
- 階層的 gap_buffer
- piece_table
ギャップ デック
gep_deque
gap_deque
- gap_buffer + 末尾ギャップ
- ギャップ個数を増やしても、複雑さの増加に見合うパフォーマンスの向上が見られないと言われている
- 2つめのギャップを末尾に固定することで、パフォーマンスの低下を回避
- 先頭付近、末尾での交互編集:O(1)
gap_deque
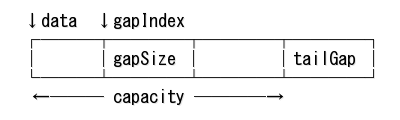
class gap_deque {
.....
private:
pointer m_data; // バッファ先頭アドレス
mutable size_type m_gapIndex; // ギャップ位置
mutable size_type m_gapSize; // ギャップサイズ
size_type m_tailGapSize; // 末尾ギャップサイズ
size_type m_size; // データトータルサイズ
}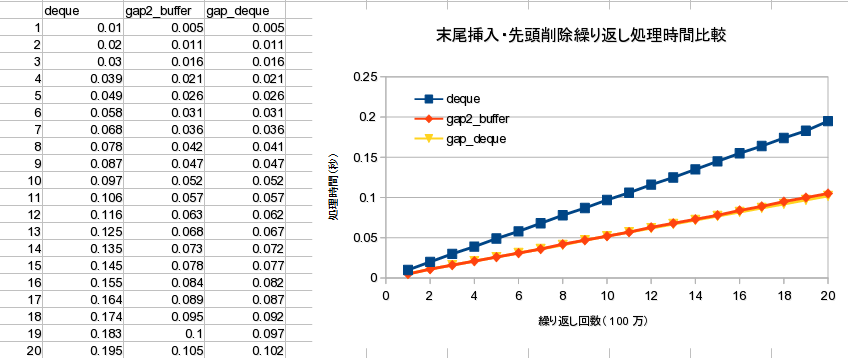
Text
※ gap_buffer は O(N^2)
※ gap2_buffer はバランス処理を行わない版
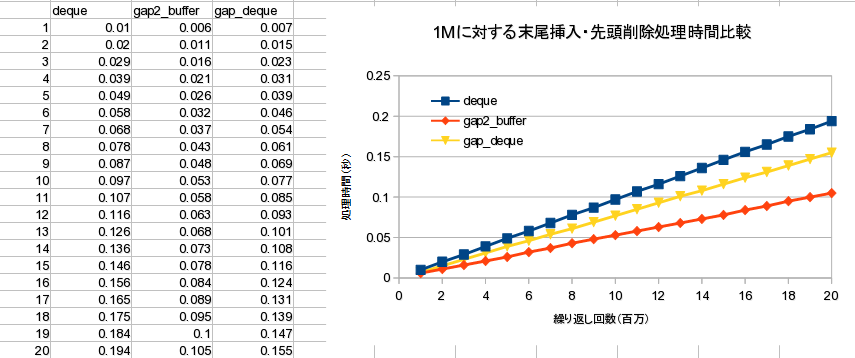
全置換処理速度比較
結果
- 局所的編集+末尾編集であれば高速
- 先頭編集後、末尾付近を編集すると、
- データ移動に O(N) の処理時間を要する
- 意味があるのか微妙
階層的ギャップバッファ
階層的ギャップバッファ
- 複数のギャップバッファをギャップバッファで管理
- ひとつのバッファの容量を 1MB とかに制限する
- 編集時のデータ転送量の増大が避けられる
template<typename T>
class hgap_buffer {
....
gap_buffer< gap_buffer<T>* > m_buffers;
};階層的ギャップバッファ
- 各バッファ・サイズは動的(ギザギザ配列)
- インデックス→文字位置計算:O(Log N)
- 単層のギャップバッファに比べると、全置換が数倍遅い
ピーステーブル
ピーステーブル
- 階層的データ構造のひとつ
- 書き込みのみを行うデータエリアと
- データへのポインタ、文字数から成る
- これを「ピース」と呼ぶ
ピーステーブル
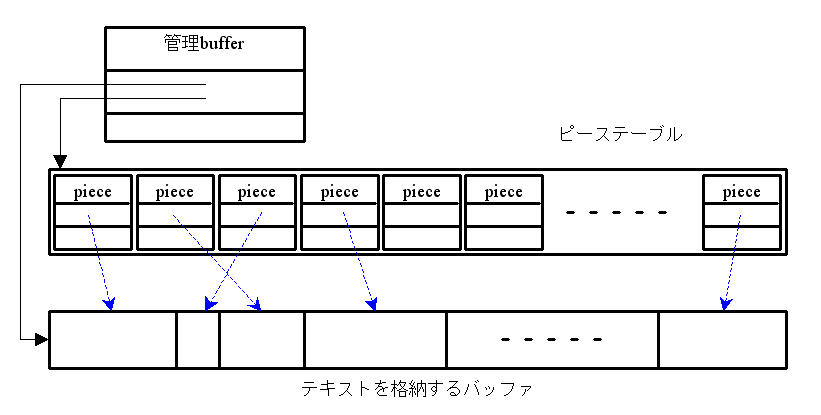
ピーステーブル
- ランダム・アクセス
- 処理時間:ピース管理方法に依存
- 通常 O(Log N) の処理時間が必要
- 文字挿入
- ピースを作成し、ピーステーブルに追加
- 追加処理そのものは O(1)
- 文字削除
- ピースを前後に分割
- 削除処理そのものは O(1)
ピーステーブル
- データの移動をいっさい行わないので、巨大データ処理に有利
- インデックス→文字位置計算:O(Log N)
- 大量のピースが生成され、メモリ効率が低下する恐れがある
- 1ピース:ポインタ+サイズ=16バイト
- vector 類は最悪でも2倍~1.5倍
- undo/redo のための情報が残っている
- 情報を積極的に利用するためには、編集エンジンの修正箇所が多い
まとめ
- 局所的編集処理が高速な「ギャップバッファ」について概説
- ギャップバッファは巨大データとの相性がよろしくない
- 64bit版バッファを高速化しようと、いろいろやってみたが、全置換処理時間がギャップバッファよりも低速になってしまい、あまりうまく行きませんでした orz
- いいデータ構造・アルゴリズムがあったらご教授してください
ご清聴ありあとうございました~

SakuSakuEditor x64 Data Structure
By Nobuhide Tsuda



