局所参照性を利用した
Text Editor の高速化
28-Jul-2013,
1-Sep-2013
Nobuhide Tsuda
自己紹介
名前:津田伸秀
サイト: http://vivi.dyndns.org/ twitter:vivisuke
facebook:https://www.facebook.com/nobuhide.tsuda
ぼちぼちソフト作家、年齢不詳のおじさん、自宅研究員(主席)
趣味:テニス、オセロ、思考ゲーム・パズル類
Qt/C++ 使い, 一応webアプリ(PHP, JS, jQ, SQL)も出来るよ
Windows用テキストエディタ ViVi を延々開発中
最近は、世界最速「さくさくエディタ」 開発中だよ
迷走中、お仕事募集中でござるぞ
名前:津田伸秀
サイト: http://vivi.dyndns.org/ twitter:vivisuke
facebook:https://www.facebook.com/nobuhide.tsuda
ぼちぼちソフト作家、年齢不詳のおじさん、自宅研究員(主席)
趣味:テニス、オセロ、思考ゲーム・パズル類
Qt/C++ 使い, 一応webアプリ(PHP, JS, jQ, SQL)も出来るよ
Windows用テキストエディタ ViVi を延々開発中
最近は、世界最速「さくさくエディタ」 開発中だよ
迷走中、お仕事募集中でござるぞ
Contents
- バックグラウンド
- 行ノードキャッシュ法
- ギャップバッファ
- 行情報局所更新法
バックグラウンド
テキストエディタ
-
エディタとは、簡単に言うと、プレーンなテキスト情報を保持し、ユーザの指示により内容を表示、編集するプログラム
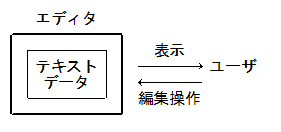
バッファ
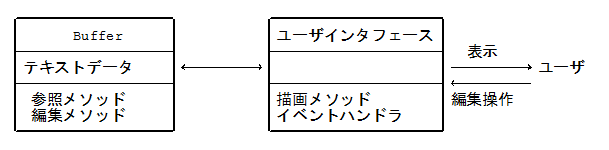
- バッファ:テキストそのものを管理する部分
- 必要十分な機能・品質・高速性・高メモリ効率・使いやすさ・拡張性等が要求される

-
最重要メソッド:文字参照・挿入・削除
- charAt(index_t pos)
- insert(index_t pos, string str)
- erase(index_t first, index_t last)
- 文字位置は整数で指定(他の方式もある)
-
ランダムアクセス、編集処理の高速性が求められる
テキストデータ
-
基本的には1次元コンテナに文字を格納するとよい
- std::vector<T>
- std::list<T>
vector と list
- std::vector, std::list には一長一短がある
| ランダムアクセス | 挿入・削除 | |
| vector | O(1) | O(N) |
| list | O(N) | O(1) |
| 2分木 | O(Log N) | O(Log N) |
許されるのは O(N*Log N)まで

解決策
- 行単位管理 (vi)
- ギャップバッファ (Emacs)
局所参照性
- テキストエディタのテキスト参照箇所には局所性がある
- 常に97%、通常は99%以上がシーケンシャル参照
- http://www.cs.unm.edu/~crowley/papers/sds.pdf
- 編集箇所についても同様の局所性がある
- 局所性を前提とすることで、処理速度向上を実現できる
行ノードキャッシュ法
list<string> で行管理

- テキストを行単位に分けることで、データ転送量を減らす
- 1行は最大100文字程度(ソースの場合)
- string は vector と同じ
-
行数は数千以上になることもあるので、list を使用
- 行増減処理:O(1)
- シーケンシャルアクセス:O(1)
- ランダムアクセス:O(L) ※ L は総行数
- 昔はシーケンシャルアクセスがほとんどで、無問題
-
【問題】 GUIが出てきてからは、垂直スクロールバーをぐりぐりされるとちょと重い
画面表示処理
list<string>::const_iterator View::line_iterator(int ln){auto itr = lineMgr.cbegin();for(int i = 0; i < ln; ++i) ++itr; // ここが O(L)return itr;}
void View::画面表示(){int ln = vScrollBar->value();auto itr = line_iterator(ln);while( 画面内の場合 ) {*itr を表示;++itr;}}
画面表示処理
int ln = vScrollBar->value();while( 画面内の場合 ) {auto itr = line_iterator(ln);*itr を表示;++ln;}
解決方法
- 行番号→ノード 変換結果を記憶
- line_iterator(int) の最後で記憶
- 編集を行った場合は明示的に記憶
- iterator が無効になる場合があるため
- リンクをたどり始める起点を、先頭・末尾・記憶箇所から選択
-
line_iterator(int ln) にて、ln がどこに近いかを判定
- 単純に考えると O(L) は変化しないが、2~3倍高速
- 参照箇所は局所化されており、実測的には O(1) となる
解決方法
list<string>::const_iterator View::line_iterator(int ln){if( ln が記憶行番行と同じ ) return 記憶イテレータ;if( ln が記憶行番行より大きい ) {if( ln が末尾から遠い )記憶行、イテレータより探す;else末尾から探す;} else {if( ln が先頭から遠い )記憶行、イテレータより探す;else先頭から探す;}itr, ln を記憶;return itr;}
結論
- ViVi 開発開始当初(1996年、PenPro 200MHz)は、本方式により垂直スクロール時の処理遅延が改善された
- デモプログラムを作って追試してみたが、現状では10万行でも充分高速だった ^^;;;
- 双方向リンクのランダムアクセス速度を向上させる方法として、「スキップリスト」がある
- スキップリストは参照局所性を仮定せず汎用的
- 本方式に比べ、メモリを余分に消費する
-
本方式は局所参照性を前提とするが、コードが単純で分かりやすく、使いやすいぞ
-
iterator って何それ美味しいの?って人向け
ギャップバッファ
- 局所参照向けに std::vector を改良
- データが無い部分を中央に配置(ギャップ)
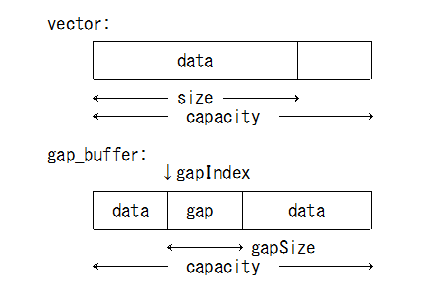
template <typename T> class GapBuffer {T *m_data; // データ領域int m_gapIndex; // ギャップ位置int m_gapSize; // ギャップサイズint m_size; // データサイズ、capacity = size + gapSize };
-
1文字参照
T GapBuffer::charAt(int pos) const{if( pos >= m_gapIndex ) // pos がギャップ以降pos += m_gapSize; // ギャップサイズ分補正return m_data[pos];}
- ギャップ移動
void GapBuffer::moveGapTo(int pos) {if( pos < m_gapIndex ) {[pos, m_gapIndex) を [pos+m_gapSize, m_gapIndex+m_gapSize] に移動 m_gapIndex = pos; } else if( pos > m_gapIndex ) { [m_gapIndex+m_gapSize, pos+m_gapSize) を [m_gapIndex, pos) に移動 m_gapIndex = pos; }}
ギャップ移動
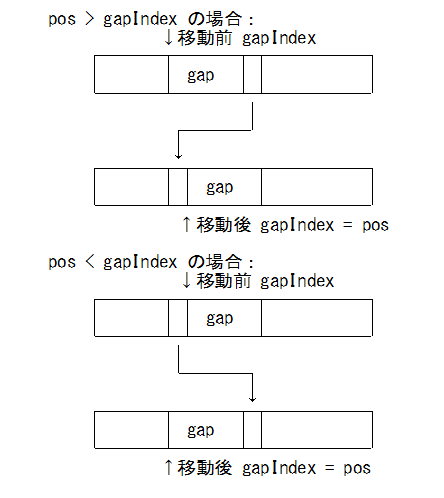
- 削除
void GapBuffer:erase(int pos){moveGapTo(pos); // ギャップを pos に移動++m_gapSize; // ギャップサイズを増やすだけで文字が消える}
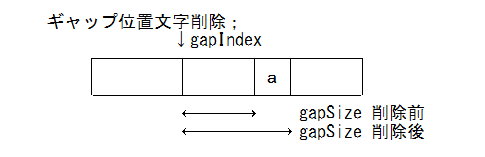
-
挿入
void GapBuffer::insert(int pos, T ch){if( ギャップが無い ) データエリアを(1.5~2倍に)拡張;moveGapTo(pos); // ギャップを pos に移動m_data[m_gapIndex++] = ch; // ギャップ先頭に文字挿入--m_gapSize;}
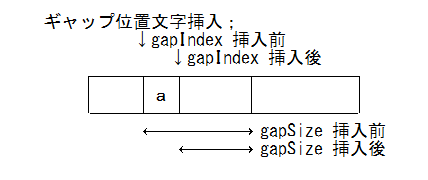
パフォーマンス計測
- 総合ベンチマークとしては何を計測すべきか?
- シーケンシャルな参照、削除、挿入処理時間が最も重要
- →全置換処理を計測するのがよい
- ("XYZはいってる。"*7+"\n")*(100~10万行) に対して、「XYZ」→「abcde」全置換
- C++ でゼロから実装した gap_buffer<T> を計測
- 比較対象:QVector<wchar_t>, QLinkedList<QString>
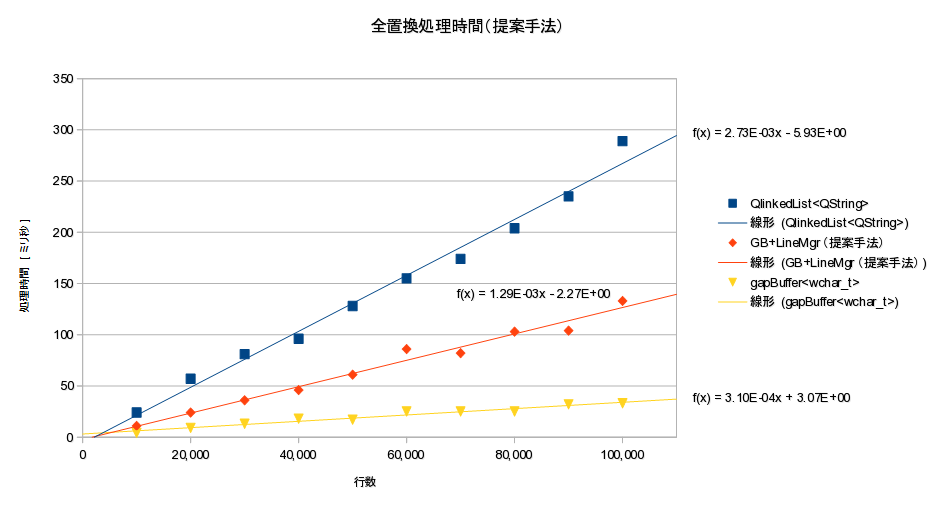
- 計測結果:
計測結果
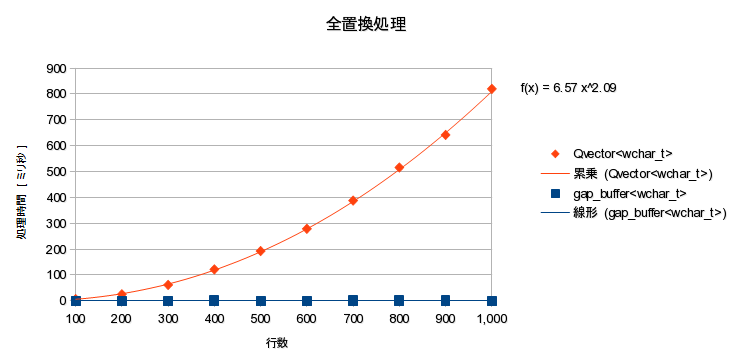
計測結果
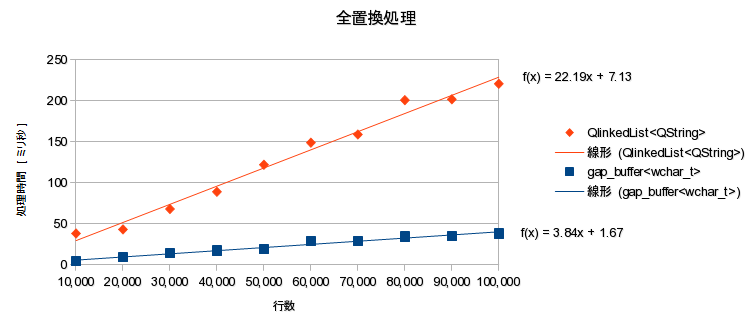
- 10万行:GB:38ミリ秒、list:221ミリ秒
結論
- 全置換処理時間は理論通り(ほぼ) O(L) だった。
- ギャップバッファは行単位双方向リンクに比べ、全置換処理が約5.8倍高速だった
- ただし、実際のテキストエディタでは行単位の管理も必要であり、その分は割り引いて評価する必要がある
- 行管理については次回発表予定
- 局所参照性を前提とすることで、vector の O(L^2) から O(L) という絶大な高速化を実現できた
- ギャップバッファは単純な構造とはうらはらに結構すごいやつだ
高速行情報更新法
バックグラウンド
- gap_buffer<T> は参照 O(1), 編集 O(1) と高速
- 画面表示を行うには行番号→行先頭位置変換が必要
- 特に、垂直スクロールバー操作時
- 表示時にテキストを参照し、行先頭位置を取得することは可能だが、O(N) で遅い
行情報管理
(A) 行先頭位置を配列で管理
or
(B) 行長を配列で管理
or
…
(A) 行先頭位置を配列で管理
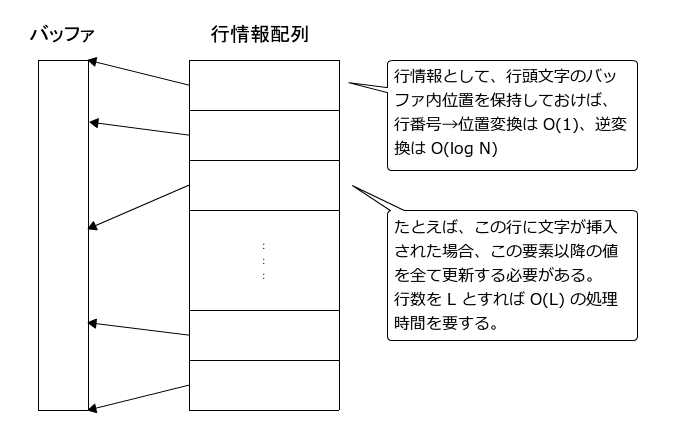
全置換処理時間
1回の処理時間がO(L)なので、全置換処理は O(L^2)

(B) 行長を配列で管理
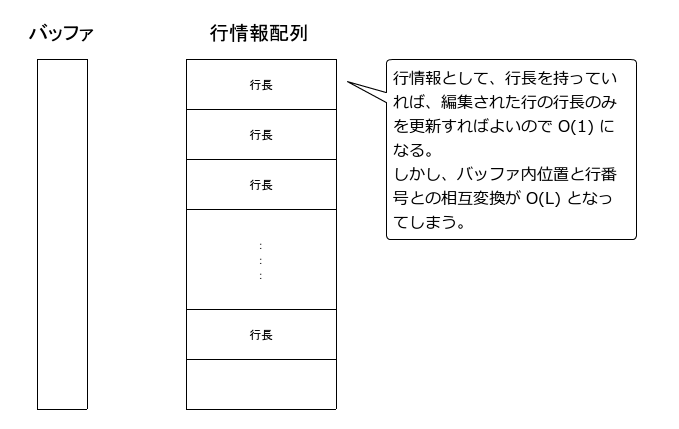
どうしましょ?
提案手法
-
編集箇所の局所性を利用
- 行先頭位置を配列で管理 + 行長が変化した場合は、変化行番号、変化量 を記録するだけ
- 行先頭位取得時:行番号が変化行番号と比較し、大きければ配列要素に変化量をプラス
提案手法
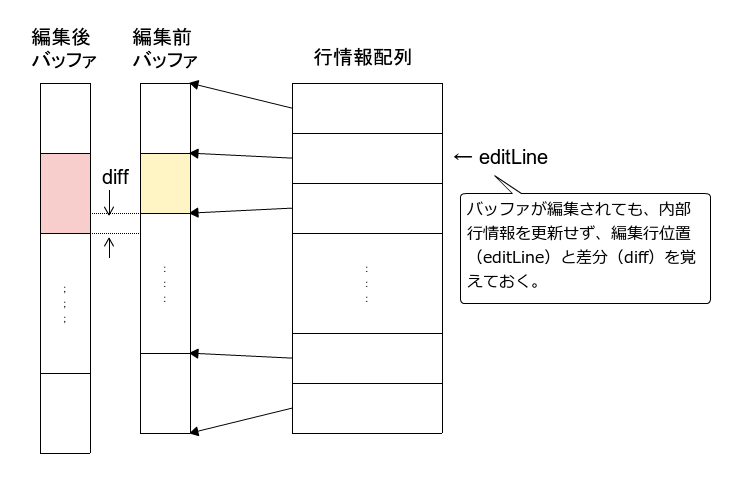
提案手法
- 行先頭位置配列の内容を更新しなくていいので、処理時間は O(1) となる
- 既に(変化行番号、変化量)が存在する場合は、記録変化行~新変化行間だけを更新する
- 編集箇所は局所化されているので処理時間は通常 O(1)、ワーストケースで O(L)
実装
- 行先頭位置 m_lv : gap_buffer<int>
- ステップ位置を m_stepIndex : int、
- ステップ量を m_stepSize : int とする
実装(行先頭位置取得)
int lineStartPosition(int ln){if( ln > m_stepIndex )ln += m_stepSize;return m_lv[ln];}
実装(挿入・削除時更新処理)
void update(size_t ln, diffptr_t d){
if( !m_stepSize ) { // 差分が 0 の場合
m_stepIndex = ln;
} else if( ln < m_stepIndex ) { // ステップ行以前を編集した場合
while( m_stepIndex > ln ) {
m_lv[m_stepIndex--] -= m_stepSize;
}
} else if( ln > m_stepIndex ) { // ステップ行以降を編集した場合
do {
m_lv[++m_stepIndex] += m_stepSize;
} while( ln > m_stepIndex );
}
m_stepSize += d;
}パフォーマンス計測結果
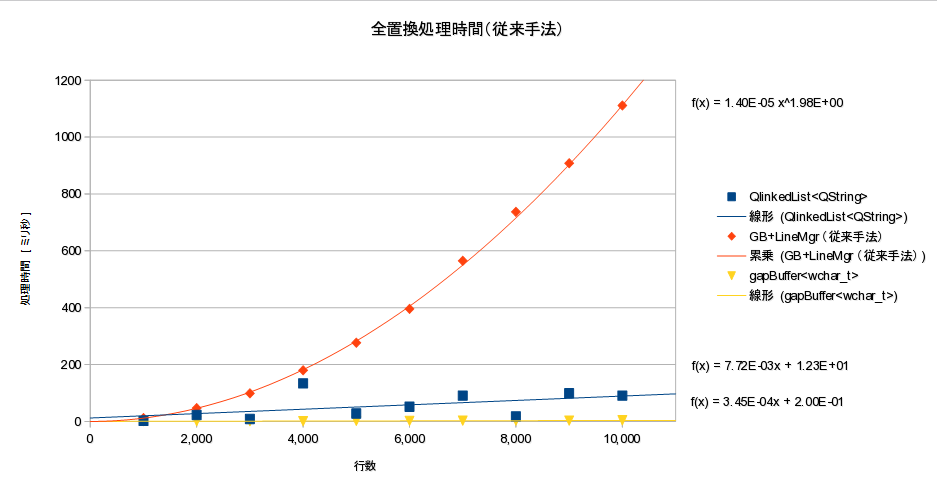
パフォーマンス計測結果
パフォーマンス計測結果
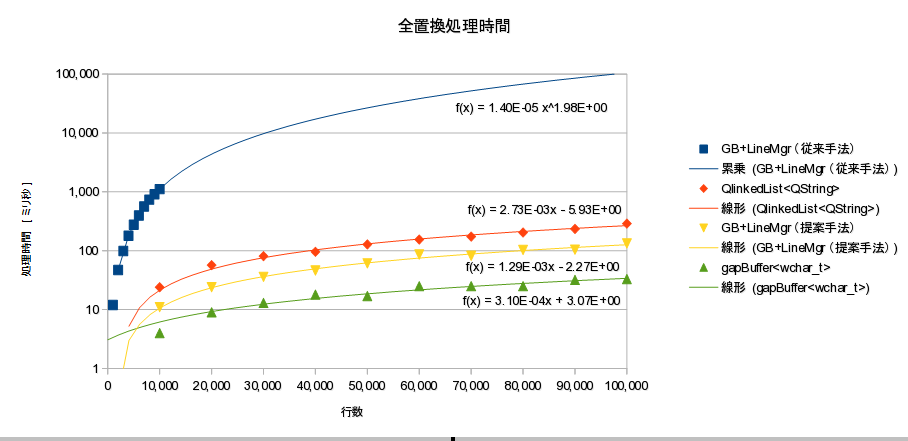
結論
- 本手法により、gap_buffer + 行管理 での全置換処理時間を O(L^2) から O(L) に高速化することに成功した
- 同機能の行単位双方向リンク管理より2倍程度高速
- 本方式は非常に単純で分かりやすく効果的である
余談
- 本手法は筆者が 2011年10月頃、独自に考案した
- ただし、単純な方法なので、既に誰かが発見していると想像していた。
- 最近「Scintillaのデータ構造」というページを発見
- 遅くとも 2011年2月には本手法と同じものが Scintilla に実装済みだったことが判明
- 本手法はバッファが gap_buffer でなくても使用可能だが、gap_buffer を前提とする別の高速手法があることも判明
局所参照性を利用した Text Editor の高速化
By Nobuhide Tsuda



