













































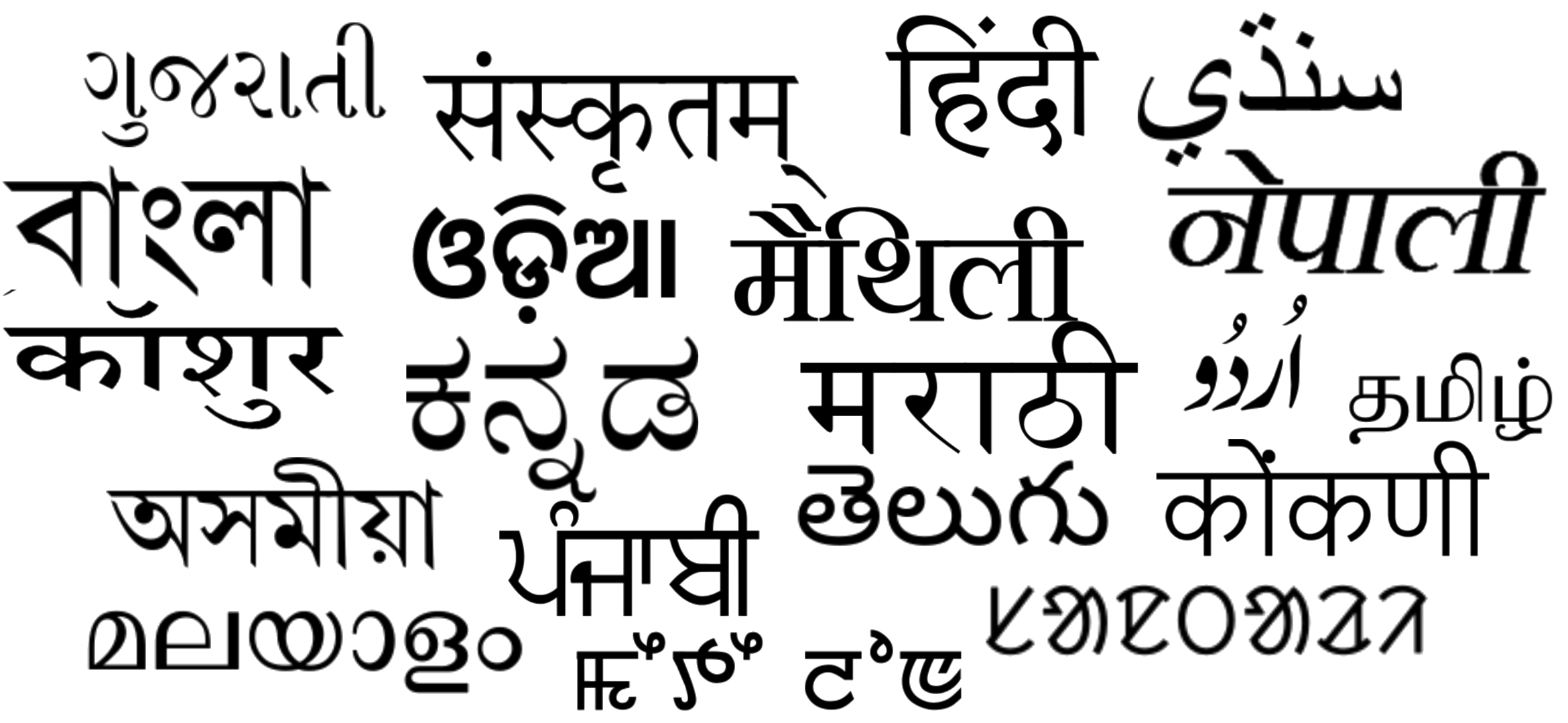





















One Fourth Labs
We deliver courseware in AI and related areas
An AI4BHARAT INITIATIVE
indicnlp.ai4bharat.org
A HUB FOR INDIC NLP RESOURCES, DATASETS AND TOOLS
Assistant Professor, IIT Madras
BTech from IIT Bombay, PhD from ETH Zurich
Worked at IBM research
DL consultant for startups
35 research papers, 18 patents
Assistant Professor, IIT Madras
PhD from IIT Bombay
Exp in teaching DL to industry and academia,
5 years exp at IBM research,
40+ research papers
Google Faculty Award, Young Faculty Recognition Award
Dr. Mitesh M. Khapra
Dr. Pratyush Kumar
Launched in Jul 2019: Working on several open-source projects of social importance in AI
About Us
Senior Applied Researcher, Microsoft India,
PhD from IIT Bombay
Exp. in Machine Translation, Multilingual NLP, Building tools and resources for Indian NLP
2+ years experience at Microsoft Translator group
35+ research papers
Dr. Anoop Kunchukuttan
About Us
বা ગુ हि ಕ മ म ने ਪੰ த తె ار
বা ગુ हि ಕ മ म ने ਪੰ த తె ار
বা ગુ हि ಕ മ म ने ਪੰ த తె ار
Multilingual chatbots
Sentiment Analysis
Content Moderation
Code mixed song search
Speech
QA
Multilingual Authoring Tools
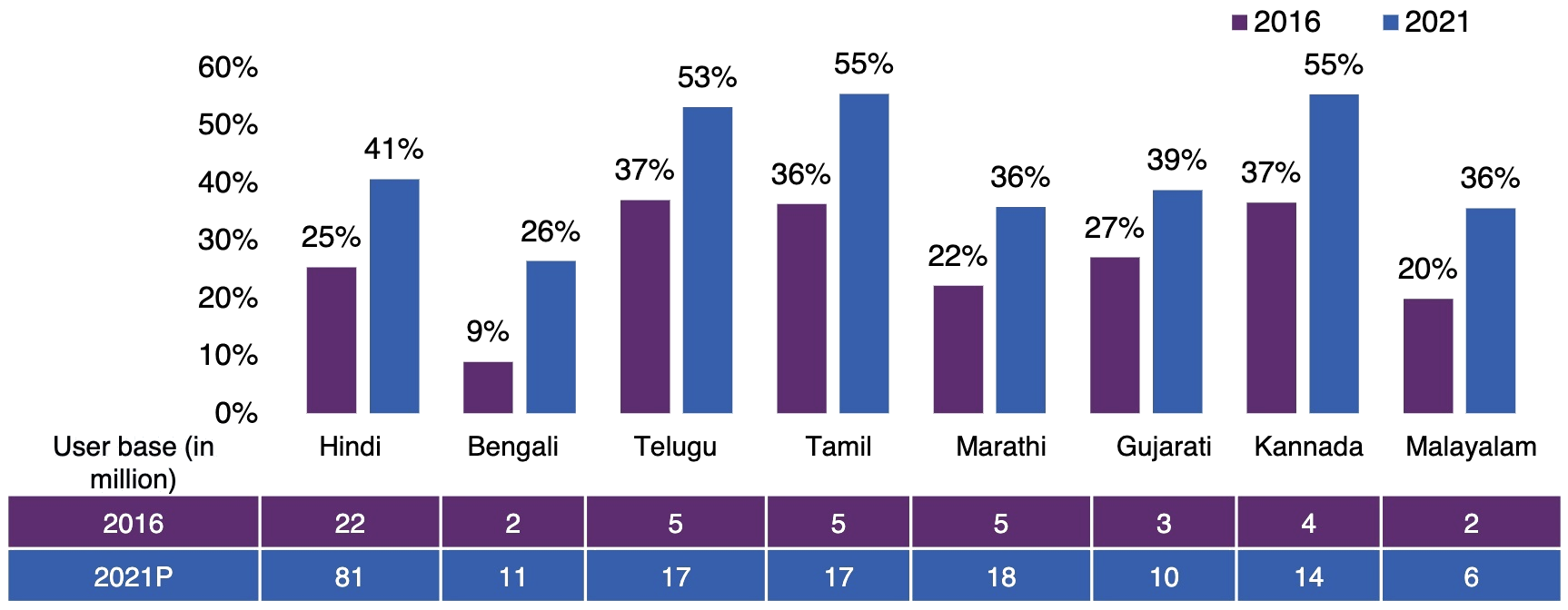
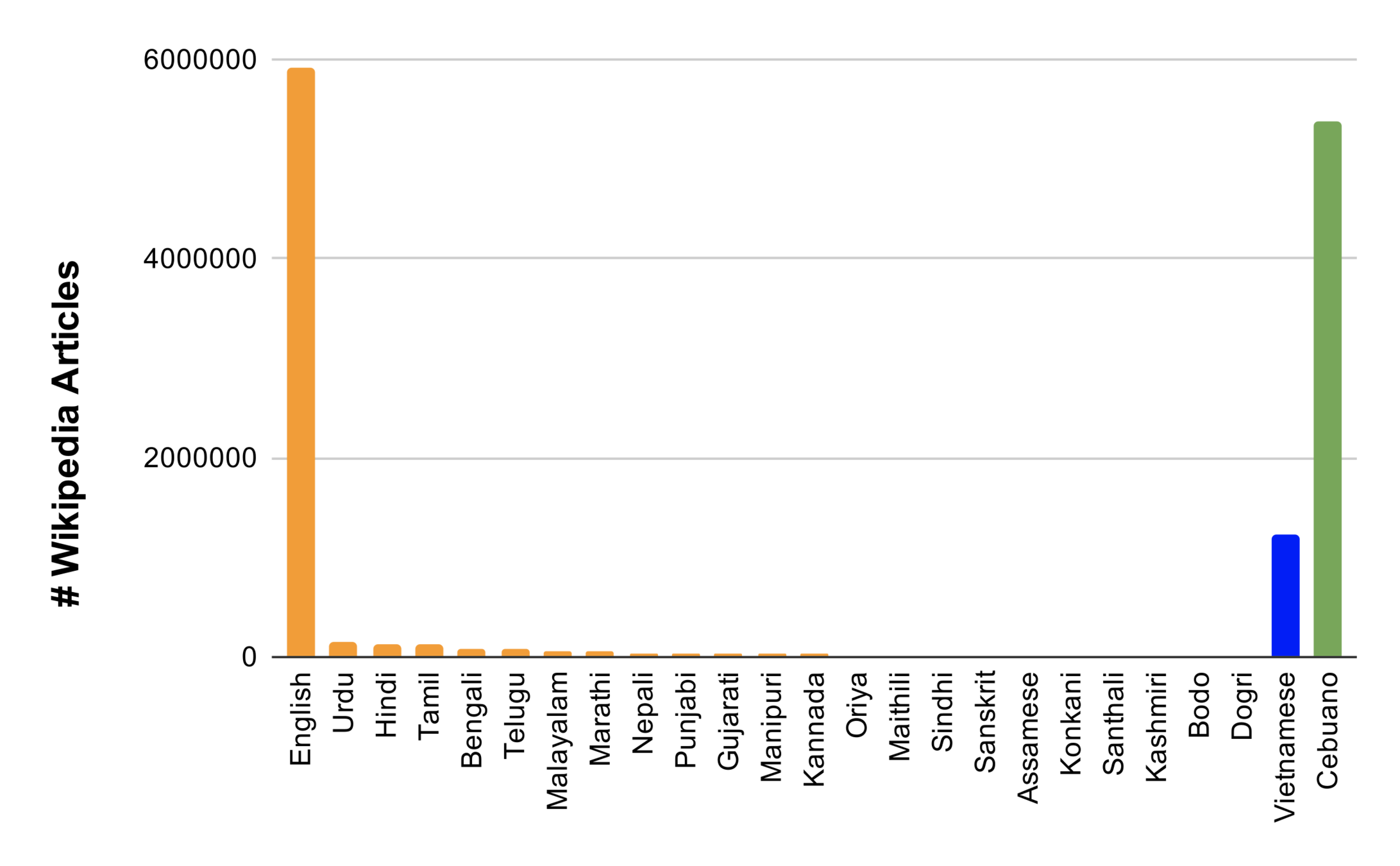
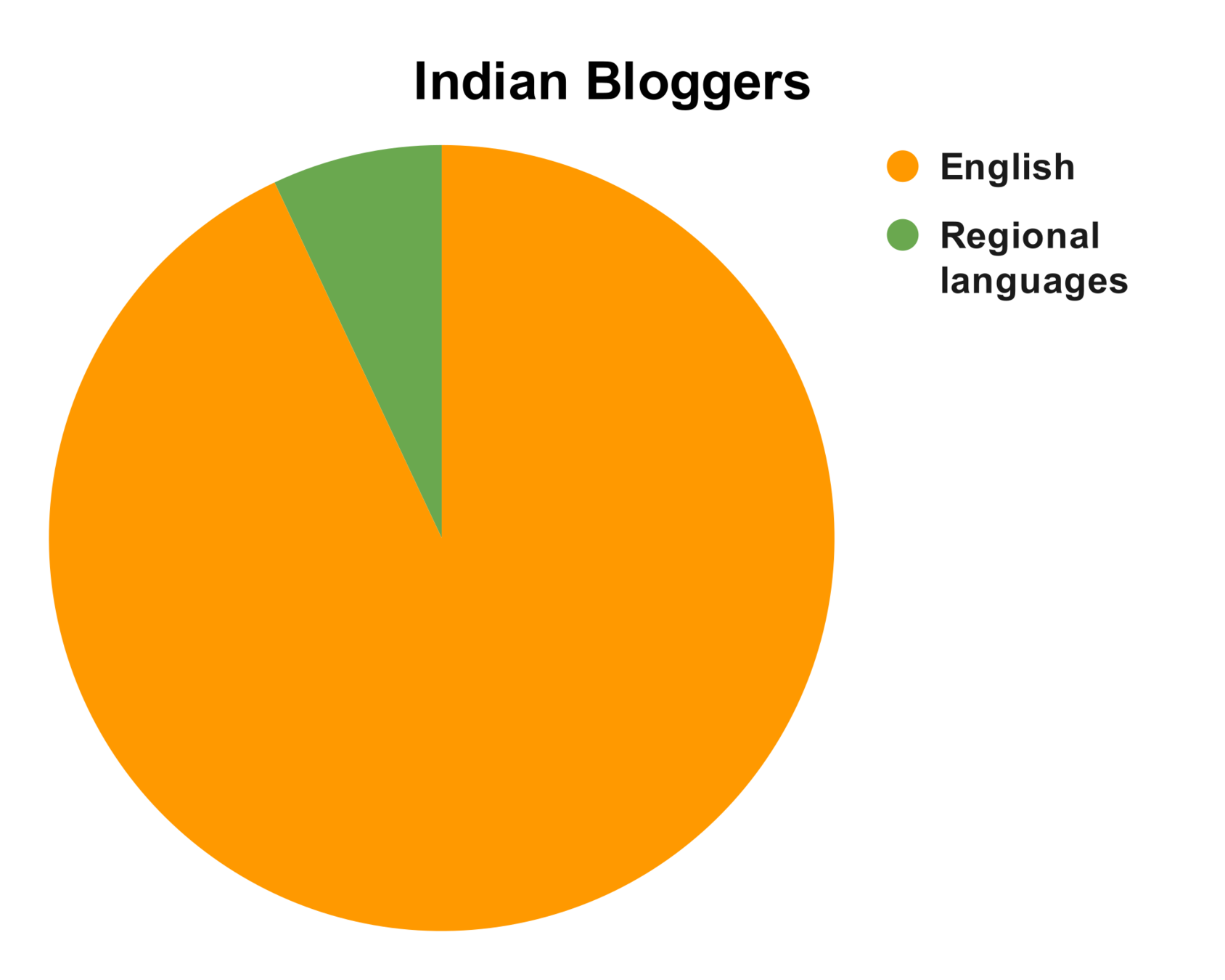
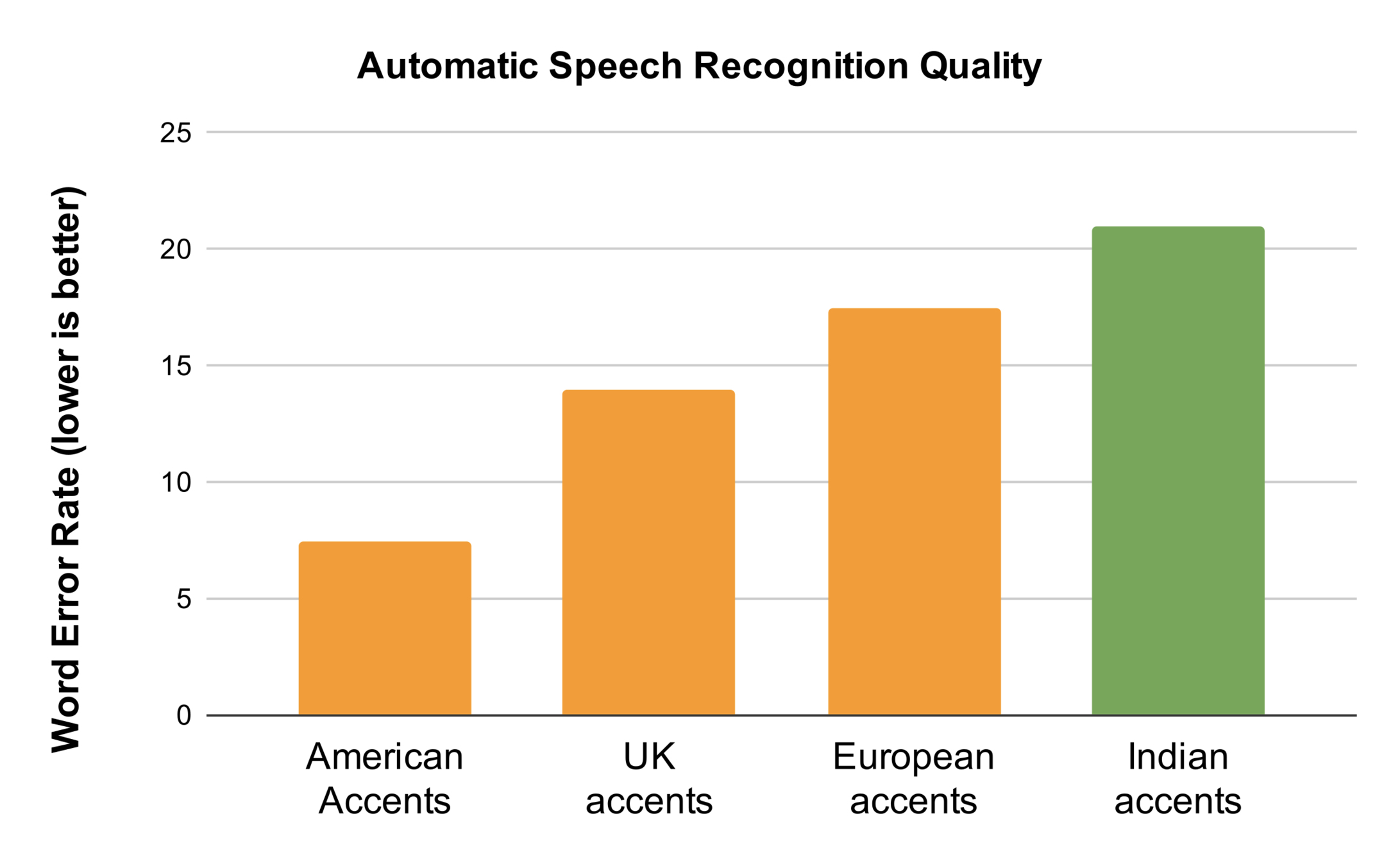
*Source Google-KPMG report https://assets.kpmg/content/dam/kpmg/in/pdf/2017/04/Indian-languages-Defining-Indias-Internet.pdf
કેમ છો
कैसे हैं
Chat applications
Digital entertainment
Social media platforms
Digital
news
Digital write-ups
Digital payments
e-governance services
e-commerce services
Authors: Divyanshu Kakwani, Anoop Kunchukuttan, Satish Golla, Gokul N.C., Avik Bhattacharyya, Mitesh M. Khapra, Pratyush Kumar
বা
ગુ
हि
ಕ
म
ଓ
ਪੰ
த
മ
অ
తె
https://github.com/anoopkunchukuttan/indic_nlp_library
+
বা
ગુ
हि
ಕ
म
ଓ
ਪੰ
த
മ
অ
తె
বা
ગુ
हि
ಕ
म
ଓ
ਪੰ
த
മ
অ
తె
বা
ગુ
हि
ಕ
म
ଓ
ਪੰ
த
മ
অ
తె
ਪੰ
हि
த
Let's make India ready for the AI age
Anoop Kunchukuttan
Mitesh M. Khapra
Pratyush Kumar
miteshk@cse.iitm.ac.in
pratyush@cse.iitm.ac.in
By One Fourth Labs
A hub for Indic NLP resources, datasets and tools




