COSCUP 2025
Peter
2025/08/09
My Best Practices about Integrating NiFi with the PostgreSQL database

Slide

About me
-
Peter, GitHub
-
Active open source contributor
-
Speaker
-
COSCUP, MOPCON and so on
-
-
An engineer
-
DevOps
-
Back-end
-
System Architecture Researching
-
Web Application Security
-
PHP, Python and JavaScript
-
-
Industrial Technology Research Institute
-
Smart Grid Technology (2017~2021)
-
-
Institute for Information Industry
-
Database, Data platform architecture (2021~)
-

Outlines
-
What's NiFi?
-
NiFi Components Introduction
-
Integrating PostgreSQL with the NiFi
-
Case(1)、Using the NiFi and PostgreSQL to build a Aggregating Calculating Data Pipeline
-
Case(2)、Using the NiFi and PostgreSQL to build a Collecting Data Pipeline
-
-
How to deploy the NiFi Cluster?
-
How to measure the NiFi performance?
-
Summary and Future Work
Outlines
-
What's NiFi?
-
NiFi Components Introduction
-
Integrating PostgreSQL with the NiFi
-
Case(1)、Using the NiFi and PostgreSQL to build a Aggregating Calculating Data Pipeline
-
Case(2)、Using the NiFi and PostgreSQL to build a Collecting Data Pipeline
-
-
How to deploy the NiFi Cluster?
-
How to measure the NiFi performance?
-
Summary and Future Work
What's NiFi?
-
Apache NiFi is developed by NSA
-
Since 2014, it's the Apache Top-Level Project
-
It's a Data Pipeline or Data Flow Control service
Outlines
-
What's NiFi?
-
NiFi Components Introduction
-
Integrating PostgreSQL with the NiFi
-
Case(1)、Using the NiFi and PostgreSQL to build a Aggregating Calculating Data Pipeline
-
Case(2)、Using the NiFi and PostgreSQL to build a Collecting Data Pipeline
-
-
How to deploy the NiFi Cluster?
-
How to measure the NiFi performance?
-
Summary and Future Work
NiFi Components Introduction (1/5)
-
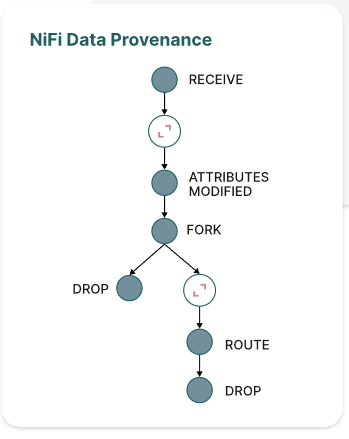
FlowFile
-
A piece of data or a single record in a file
-
Or a dataset has many records
-
E.g. 100 records have 100 FlowFiles
-
It has own attribute and content
-
The attribute is metadata or key-value
-
It includes size, path and permission
-
-
The content is the real data. CSV or JSON
-
-
NiFi Components Introduction (2/5)
-
Processor
-
It can imagine that a logical processing unit
-
NiFi has many built-in processors
-
It can use the configuring approach to
-
generate, process, convert and output the FlowFile
-
-
-
Connection
-
When creating the data flow, we can establish the relationships between processors
-
It can be flexible to establish many connection and every route state and meaning
-
It can also configure the queue state
-
NiFi Components Introduction (3/5)
-
Process(Processor) Group
-
If we have two data pipelines, then have the same one, and we can let same pipeline be the Process Group. It can be reusable
-
We can also split many Process Group with projects or teams
-
It can configure Processor Group permissions for different users
-
-
Funnel
-
Let many source connections be a single connection. It can be helpful for making data pipeline readable
-
We can have many processor and connect the same processor
-
NiFi Components Introduction (4/5)
-
Controller Service
-
A third-party connection and it can establish the connection with the Internet service
-
Using the Controller Service to manage and reuse the third-party connection
-
-
Reporting Task
-
It plays an important role in monitoring the NiFi
-
It can let hardware metrics be informations and publish them
-
These hardware metrics can be CPU, memory and disk usage.
-
-
We send above monitoring information to the Prometheus, DataDog or CloudWatch
-
Using these third-party services to visualize hardware utilization changes
-
-
NiFi Components Introduction (5/5)
-
Template
-
It can be used to transfer/migrate the NiFi environment
-
For example, we migrate the NiFi machine A and migrate to the NiFi machine B
-
NiFi Architecture Introduction
-
Architecture
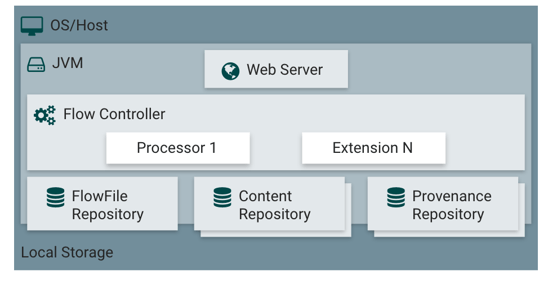
NiFi is developed by Java and it's run in the JVM
FlowFile Repository, it stores every processor process state and metadata
Content Repository, it has individual Directory and store real FlowFile contents in instances
Provenance Repository, it stores individual FlowFile about tracking events
Flow Controller, the core of NiFi. It's used to dispatch processor resource usage
-
Web Server, users can use the drag-drop to generate data flow in the Web UI
Outlines
-
What's NiFi?
-
NiFi Components Introduction
-
Integrating PostgreSQL with the NiFi
-
Case(1)、Using the NiFi and PostgreSQL to build a Aggregating Calculating Data Pipeline
-
Case(2)、Using the NiFi and PostgreSQL to build a Collecting Data Pipeline
-
-
How to deploy the NiFi Cluster?
-
How to measure the NiFi performance?
-
Summary and Future Work
Building your own NiFi Environment (1/14)
-
Building the NiFi environment has many approaches
-
Running the NiFi in the dedicated or virtual machine directly
-
Running the NiFi with the Docker Container
-
Running the NiFi with the Docker Compose
-
-
We use the Docker Compose approach to build the NiFi
-
NiFi 1.28.x is at end of life since 2024-12-08!
-
NiFi 2.x doesn't have good enough deployment script on the Internet
-
Don't worry. The open source project is available here:
-
Building your own NiFi Environment (2/14)
-
Since the NiFi 2.0.0 version is released,
-
The official NiFi Docker image has been dropped HTTP mode
-
My first contribution to the NiFi project
-
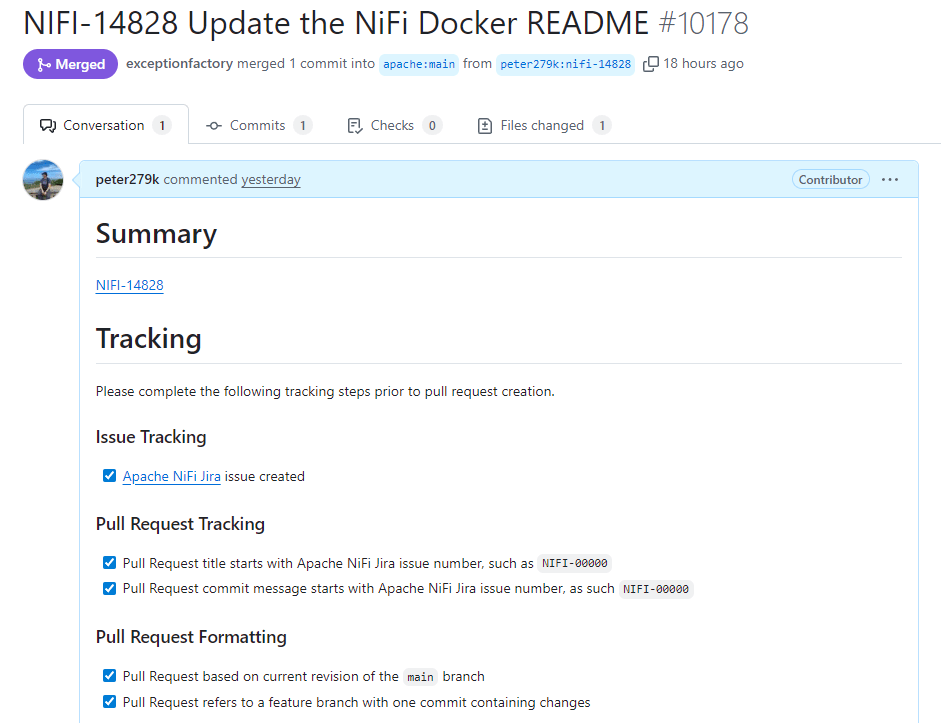
Building your own NiFi Environment (3/14)
-
Step1: Using the git clone command to clone the project
$ git clone https://github.com/peter279k/nifi_persistence-
Step2: Using following commands to configure file persistence
-
Prerequisites
-
Docker is available. It should be 28.3.2 or later
-
keytool command is available. It should be Java 17 or later
-
sudo apt-get install -y openjdk-17-jdk
-
-
$ cp providers.xml.file providers.xml
$ cp docker-compose-file.yml docker-compose.yml-
Step3: Using the command to enable HTTPS certificate
-
Remember to configure correct IP address and DNS for the SNI (Server Name Indication)
-
$ cat SAN.txt
$ ip:127.0.0.1,ip:146.71.85.60,dns:nifi.peterli.website,dns:nifiBuilding your own NiFi Environment (4/14)
-
Step4: Executing the run_nifi_file.sh shell script to setup NiFi
$ ./run_nifi_file.sh
$ Starting tricky NiFi persistence...
[sudo] password for lee:
......
[+] Running 5/5
.......
[+] Stopping 3/3
✔ Container nifi_persistence-registry-1 Stopped 0.4s
✔ Container nifi_persistence-nifi-1 Stopped 10.5s
✔ Container nifi_persistence-zookeeper-1 Stopped 0.6s
Setting related nifi and nifi_registry permissions is done.
Generating the truststore.p12 and keystore.p12 with the keytool
......
Trust this certificate? [no]: Certificate was added to keystore
Moving truststore.p12 and keystore.p12 to the ./nifi_conf directory
Remove the nifi-cert.crt file
Uncomment the next line after copying the /conf directory from the container to your local directory to persist NiFi flows
[+] Running 3/3
✔ Container nifi_persistence-registry-1 Started 0.8s
✔ Container nifi_persistence-nifi-1 Started 0.7s
✔ Container nifi_persistence-zookeeper-1 Started 0.4s
Starting tricky NiFi persistence has been done.Building your own NiFi Environment (5/14)
-
Step5: Using the Netcat and cURL commands to verify NiFi
$ nc -vz localhost 8091
Connection to 127.0.0.1 8091 port [tcp/*] succeeded
$ curl -k https://127.0.0.1:8091/nifi/
<!--
~ Licensed to the Apache Software Foundation (ASF) under one or more
~ contributor license agreements. See the NOTICE file distributed with
~ this work for additional information regarding copyright ownership.
~ The ASF licenses this file to You under the Apache License, Version 2.0
~ (the "License"); you may not use this file except in compliance with
......Building your own NiFi Environment (6/14)
-
Step6: Using the Cloudflare Tunnel to secure the NiFi
-
According to the above steps, our NiFi is using the self-signed certificate
-
We assume the SNI has the nifi.peterli.website
-
And the domain has been configured by the Cloudflare
-
Firstly, go to the Cloudflare Zero Trust configuration page
-
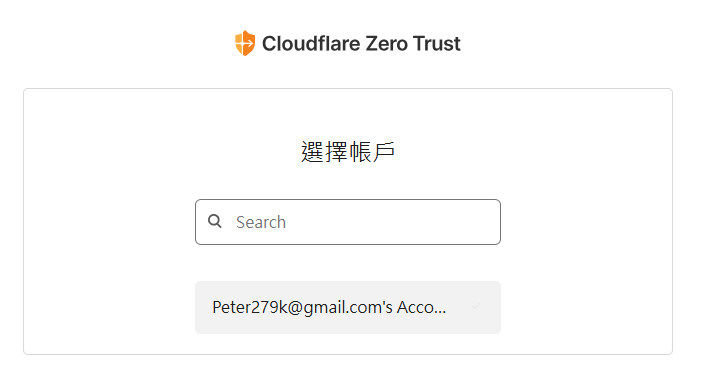
Building your own NiFi Environment (7/14)
-
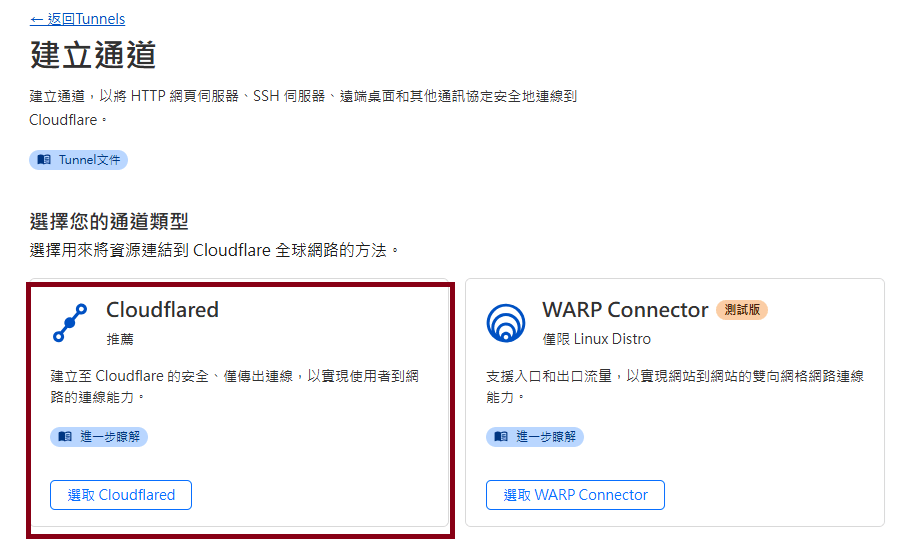
Step7: Clicking "Tunnels" and create the Cloudflare Tunnel
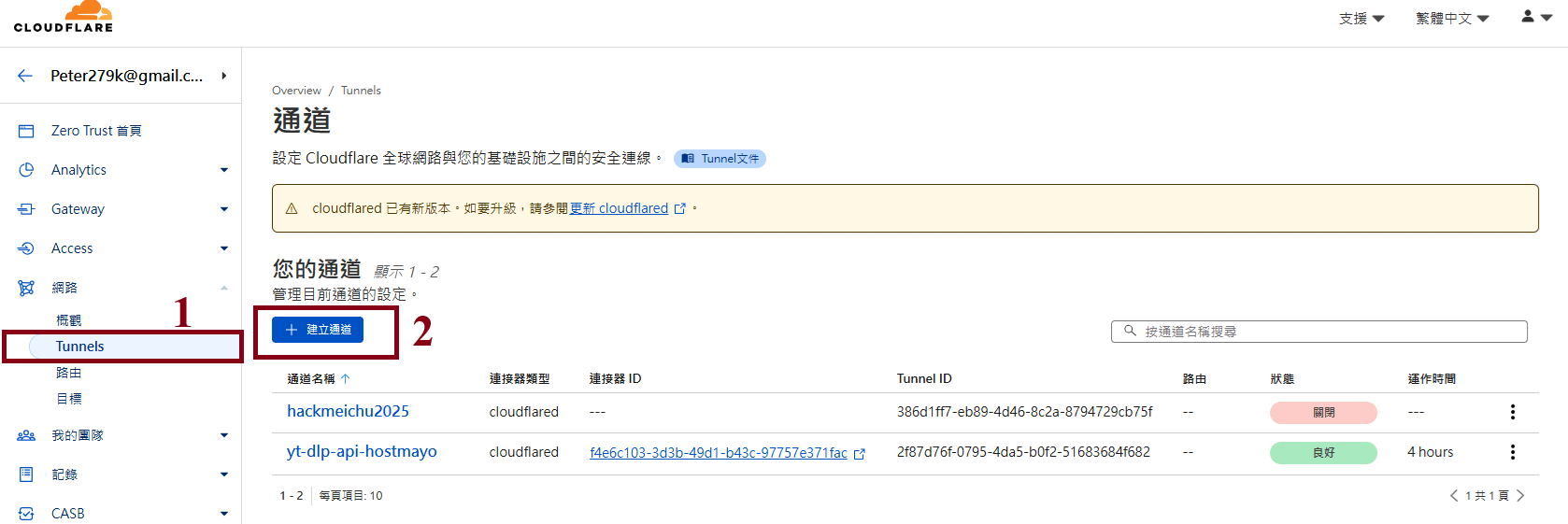
Building your own NiFi Environment (8/14)
-
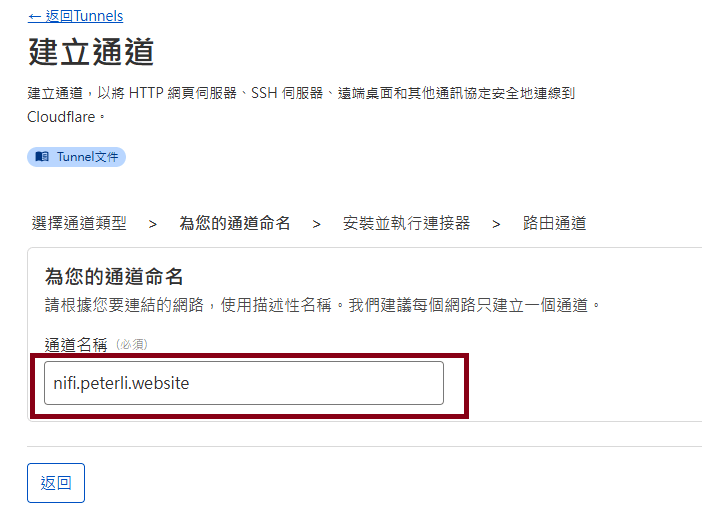
Step8: Choose the "Cloudflared" and naming the tunnel
Building your own NiFi Environment (9/14)
-
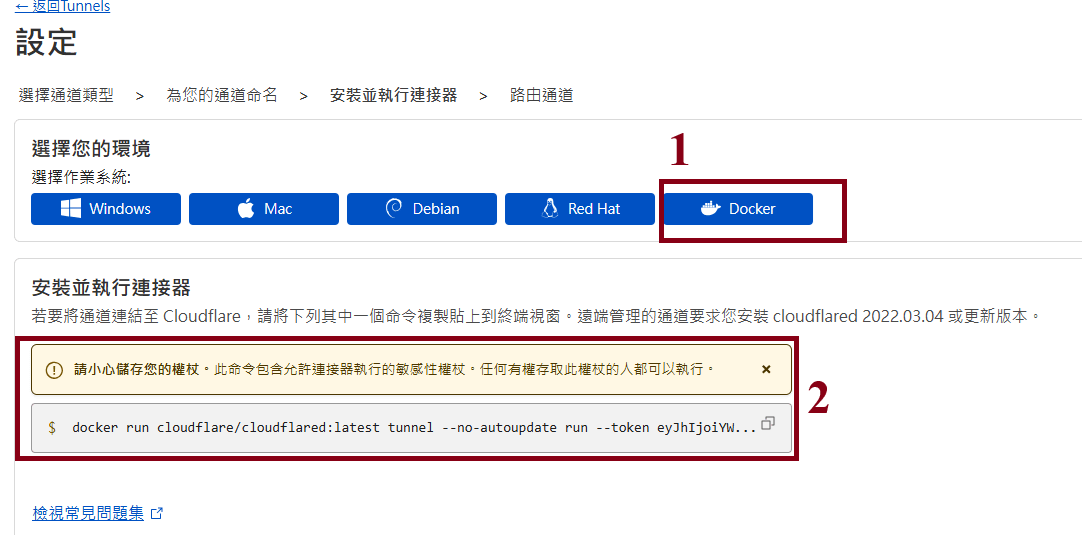
Step9: Choose the Docker Tunnel to setup the Cloudflared
-
Using "docker run -d cloudflare/cloudflared:latest " to run the daemon tunnel
-
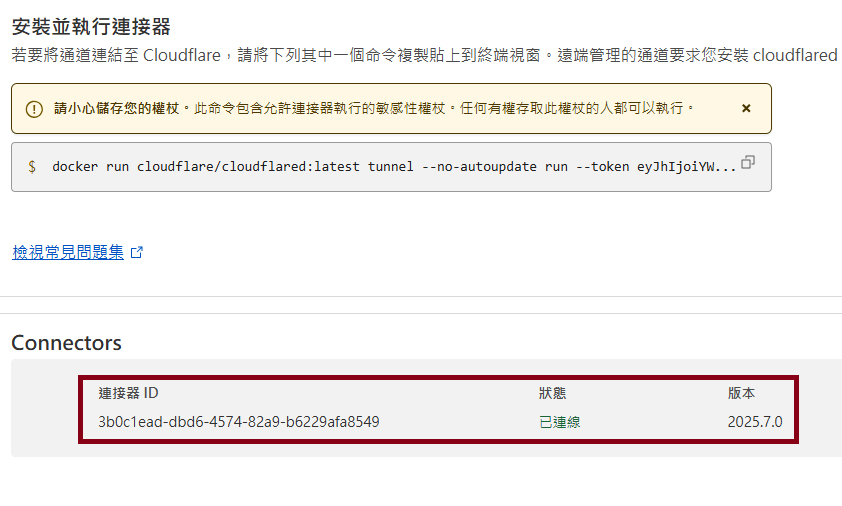
Once the connection is connetced, the list will have the available connector
-
Building your own NiFi Environment (10/14)
-
Step10.1: Creating the subdomain DNS record
-
It should ensure that the subdomain DNS record has been deleted
-
After creating the DNS record, creating the forwarding local service type
-
Then clicking the button to complete the configuration
-
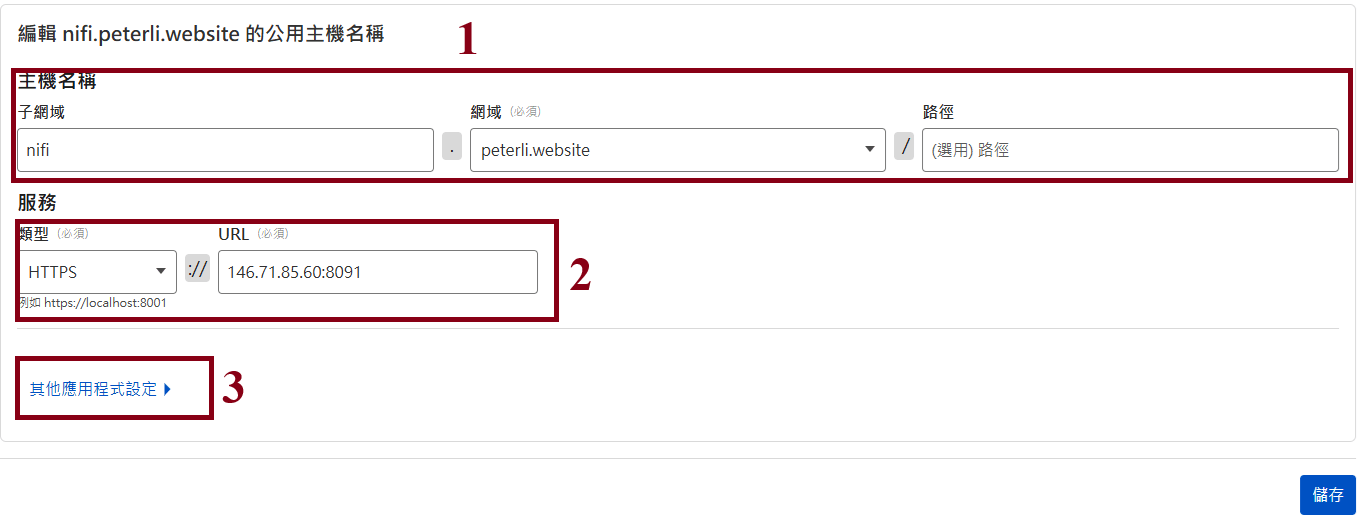
Building your own NiFi Environment (11/14)
-
Step10.2: Creating the subdomain DNS record
-
Clicking the "其他應用程式設定", then enabling "no TLS certificate verification"
-
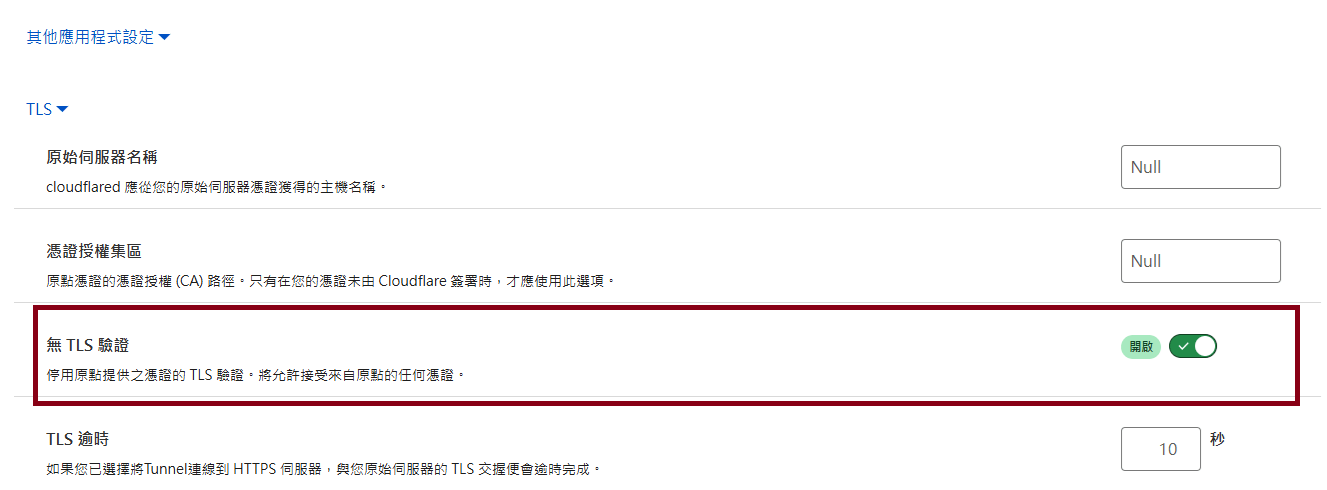
Building your own NiFi Environment (12/14)
-
Step11: Verifying the Cloudflare Tunnel list
-
We can see that our nifi.peterli.website setting is in the Cloudflare Tunnel list now
-

Building your own NiFi Environment (13/14)
-
Step12: Verifying the NiFi website via the web browser
-
Open web browser then browse the "https://nifi.peterli.website" to verify certificate
-
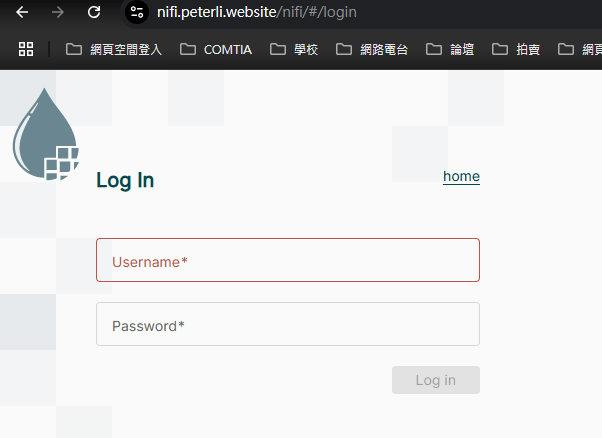
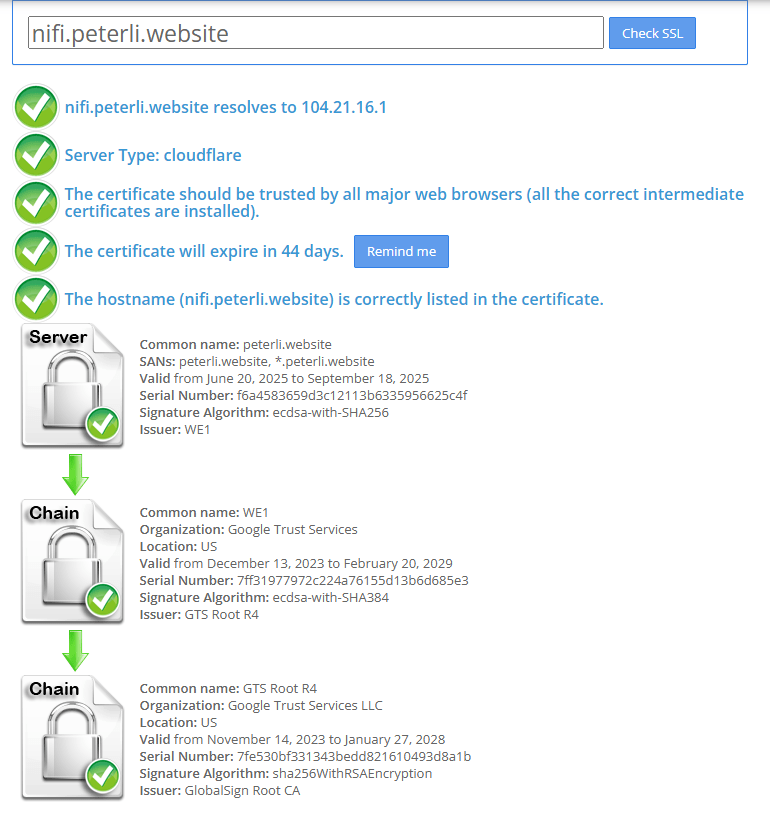
Building your own NiFi Environment (14/14)
-
Step13: Verifying the NiFi website via the web browser
-
After logging in NiFi account has been completed, it's expected to retrieve the UI
-
Building your own PostgreSQL (1/2)
-
Step1: Creating the docker-compose.yml file
-
Using the Docker Compose file to define the PostgreSQL service
-
We use the PostgreSQL 16 for these case studies
-
Running following commands to complete PostgreSQL database setup
-
$ mkdir postgres-16
$ cd postgres-16
$ vim docker-compose.yml
$ cat docker-compose.yml
services:
postgres_db:
image: postgres:16
ports:
- "5433:5432"
container_name: postgres_db
environment:
POSTGRES_DB: regions
POSTGRES_USER: postgres
POSTGRES_PASSWORD: postgres123
volumes:
- ./postgres_data:/var/lib/postgresql/data
networks:
- postgres-db-net
networks:
postgres-db-net:
driver: bridge
$ docker compose down
$ docker compose up -d --build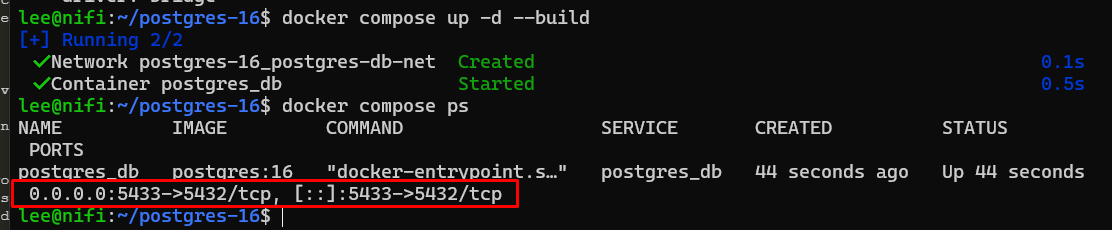

Verify the PostgreSQL DB Connection
Setup the PostgreSQL DB with Docker Compose
Building your own PostgreSQL (2/2)
-
Step2: Entering this PostgreSQL Docker container
-
Creating the countries_count table
-
$ docker compose exec -it postgres_db bash
root@943ad56ebb06:/# psql -U postgres
psql (16.9 (Debian 16.9-1.pgdg120+1))
Type "help" for help.
postgres=# \c regions
You are now connected to database "regions" as user "postgres".
regions=# CREATE TABLE countries_count (
country_id SERIAL PRIMARY KEY,
counter INT,
event_time TIMESTAMPTZ DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLEOutlines
-
What's NiFi?
-
NiFi Components Introduction
-
Integrating PostgreSQL with the NiFi
-
Case(1)、Using the NiFi and PostgreSQL to build a Aggregating Calculating Data Pipeline
-
Case(2)、Using the NiFi and PostgreSQL to build a Collecting Data Pipeline
-
-
How to deploy the NiFi Cluster?
-
How to measure the NiFi performance?
-
Summary and Future Work
Case (1) Building an aggregating data pipeline
-
This data pipeline is about aggregating the data
-
We design a data pipeline to complete this case
-
The building steps are as follows:
-
Creating the InvokeHTTP Processor
-
Then send an HTTPS request to https://covid-api.com/api/regions
-
-
Creating the EvaluateJsonPath Processor
-
Using the JSONPath to filter the data field ($.data) and store "data" attribute
-
-
Creating the ExecuteScript Processor
-
Using the customized Groovy Script to read "data" attribute and retrieve array length
-
-
Creating a PutSQL Processor
-
Execute the SQL to store the aggregated results
-
Case (1) The InvokeHTTP Processor
-
Creating the InvokeHTTP Processor
-
Then send HTTPS request to https://covid-api.com/api/regions
-
Using the GET method to send the request to the above URL
-

Expected JSON Response
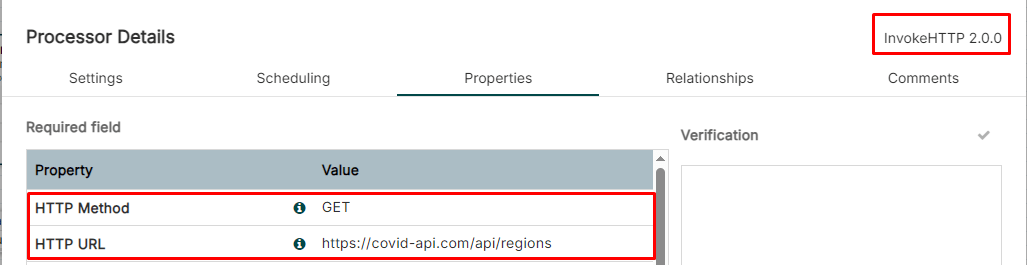
InvokeHTTP Processor Setting
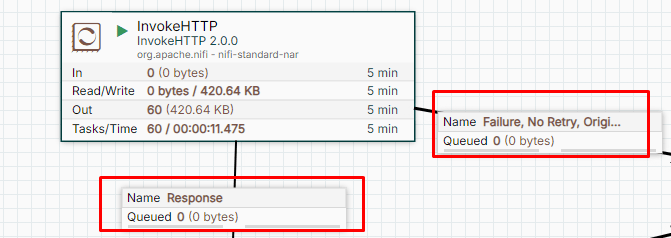
InvokeHTTP Processor Relationships
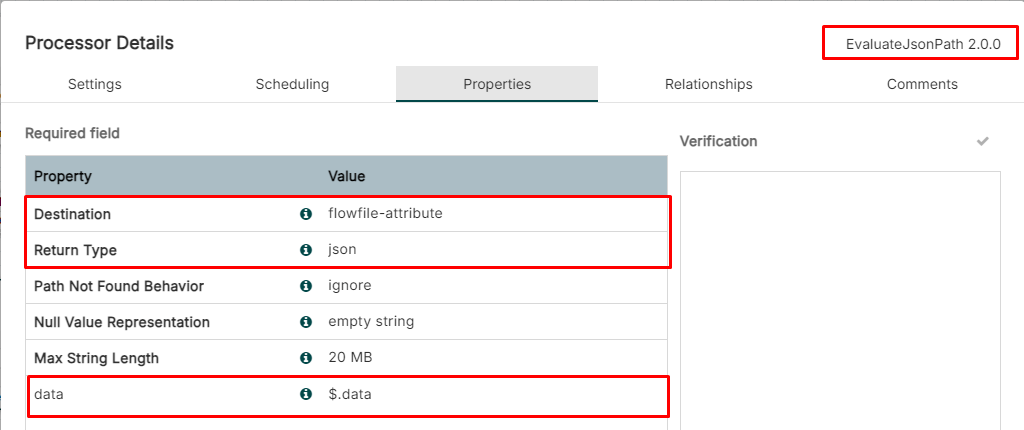
Case (1) The EvaluateJsonPath Processor
-
Creating the EvaluateJsonPath Processor
-
Using the JSONPath to filter the data field ($.data) and store "data" attribute
-
Expected JSON Response
EvaluateJsonPath Processor Setting
EvaluateJsonPath Processor Relationships
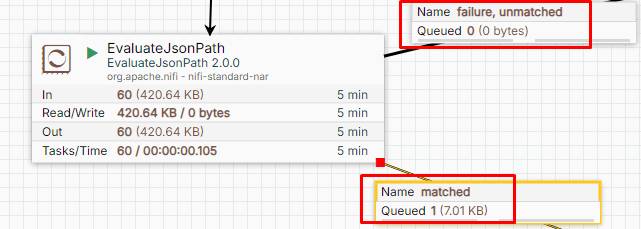
Case (1) The ExecuteScript Processor
-
Creating the ExecuteScript Processor
-
Apache Groovy. A flexible and extensible Java-like language for the JVM
-
Using the customized Groovy Script to read "data" attribute and retrieve array length
-
Creating a Groovy script and it's as follows:
-
import groovy.json.JsonSlurper
FlowFile flowFile = session.get()
if (flowFile == null) {
return
}
String responseBody = flowFile.getAttribute('data')
if (responseBody != null) {
log.info("Response JSON Data: " + responseBody)
def jsonSlurper = new JsonSlurper()
def data = jsonSlurper.parseText(responseBody)
session.putAttribute(flowFile, "data_size", data.size().toString())
session.transfer(flowFile, REL_SUCCESS)
return
}
session.transfer(flowFile, REL_FAILURE)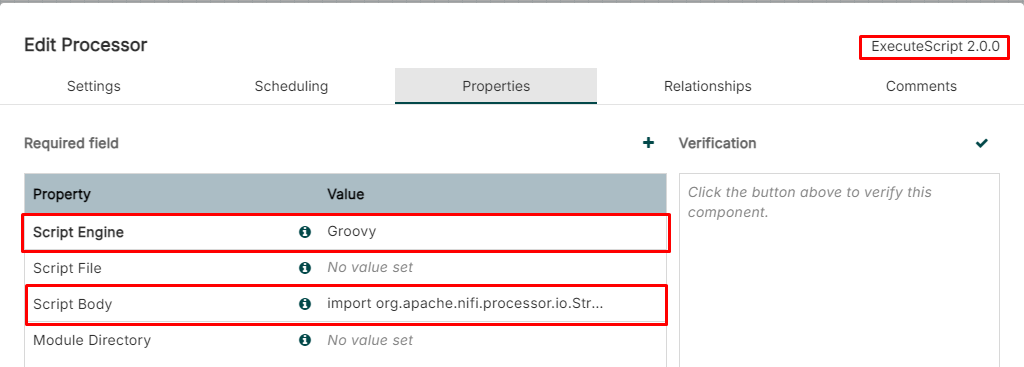
ExecuteScript Processor Setting
Case (1) The JDBC Controller Service(1/3)
-
Creating a JDBC Connection Pool Controller Service for the PutSQL Processor
-
Creating the JDBC Controller Service for connecting the PostgreSQL DB
-
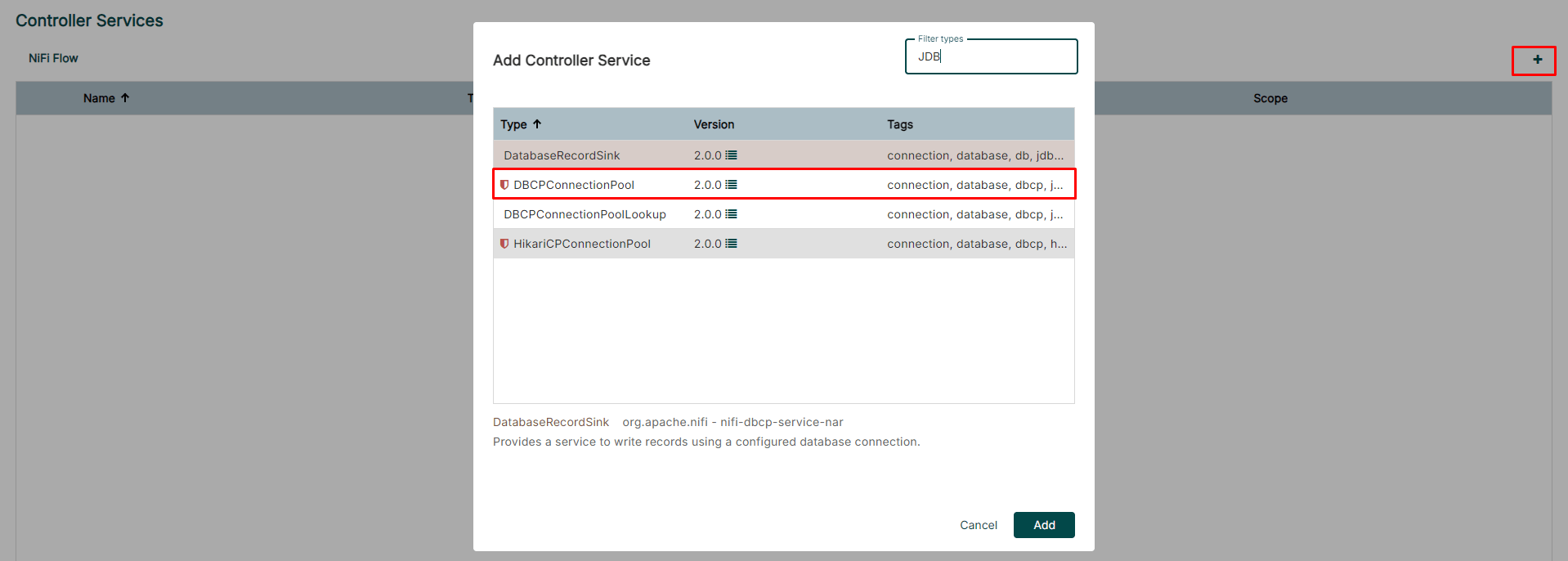
Case (1) The JDBC Controller Service(2/3)
-
Creating a JDBC Connection Pool Controller Service for the PutSQL Processor
-
Creating the JDBC Controller Service for connecting the PostgreSQL DB
-
Download the PostgreSQL JDBC Driver from https://jdbc.postgresql.org/download
-
wget https://jdbc.postgresql.org/download/postgresql-42.7.7.jar
-
-
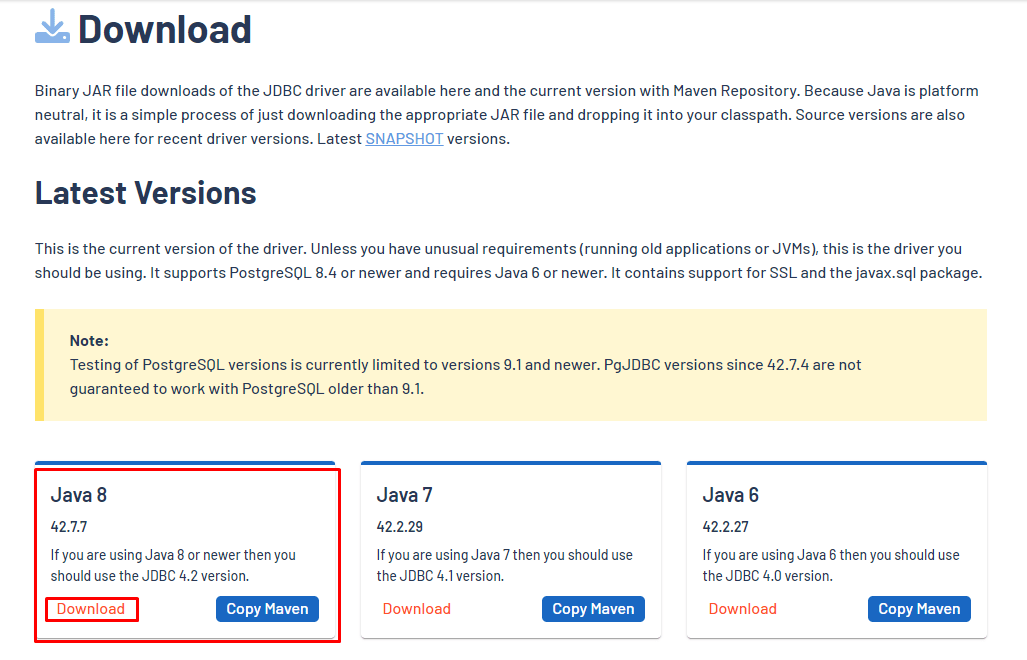
$ cd /path/to/nifi_persistence/
$ wget https://jdbc.postgresql.org/download/postgresql-42.7.7.jar
$ docker compose cp postgresql-42.7.7.jar nifi:/home/nifi/
$ docker compose exec nifi ls /home/nifi/
postgresql-42.7.7.jar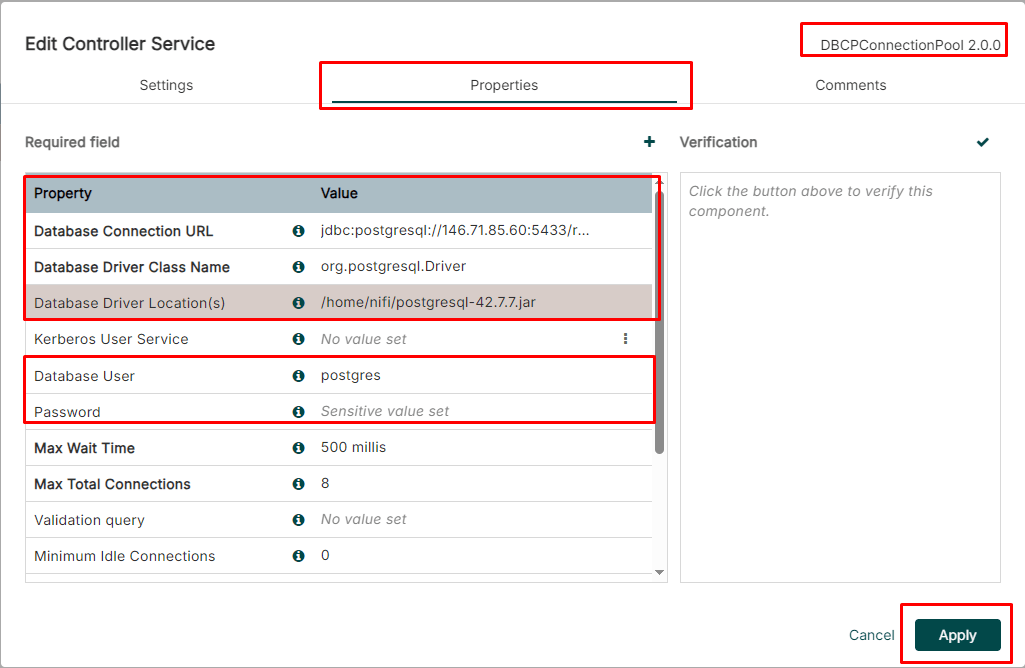
JDBC Controller Service Setting
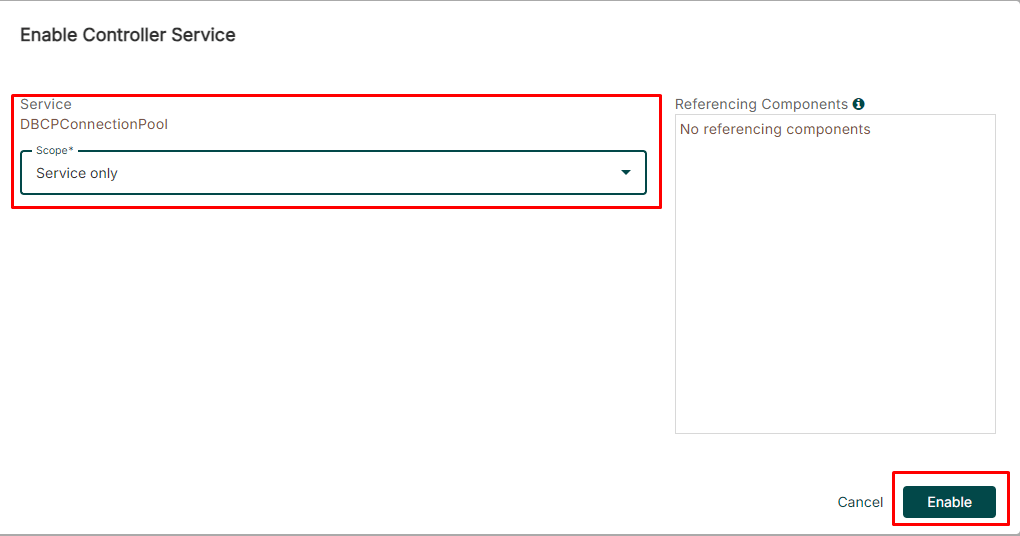
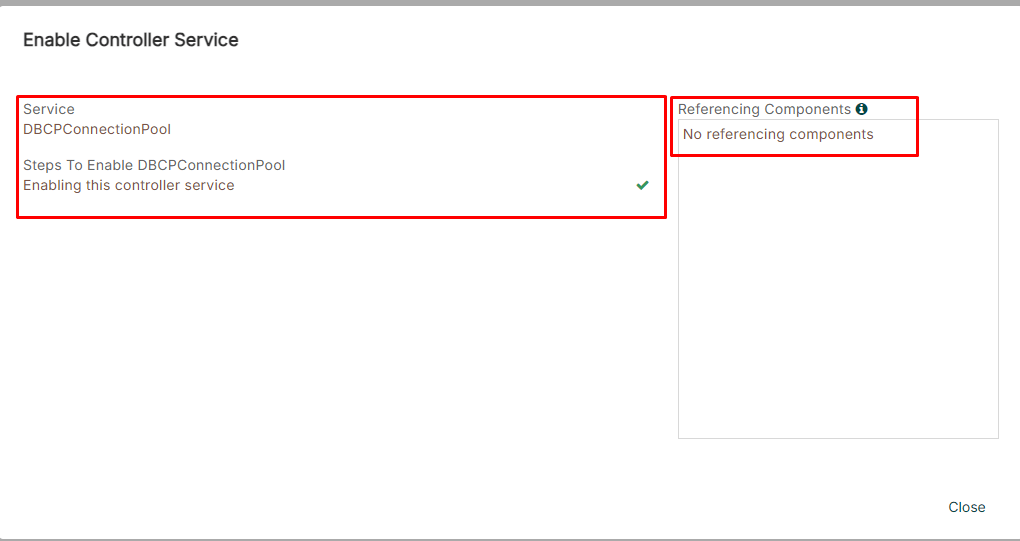
Case (1) The JDBC Controller Service(3/3)
-
Creating a JDBC Connection Pool Controller Service for the PutSQL Processor
-
Enabling the configured JDBC Controller Service
-

Case (1) The PutSQL Processor
-
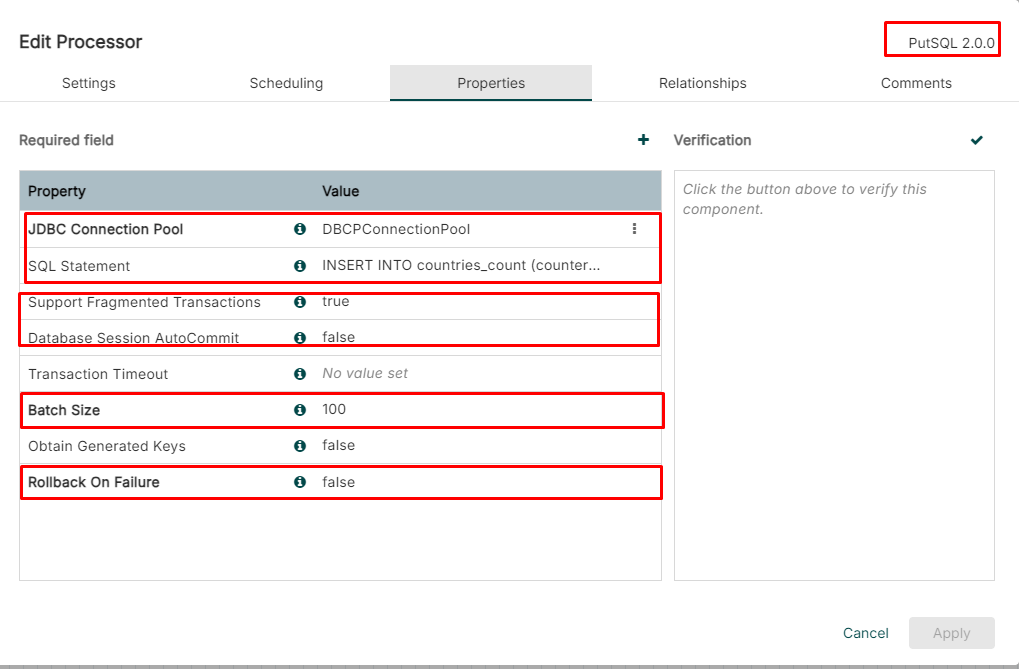
Creating a PutSQL Processor
-
Execute the SQL to store the aggregated results
-
Configuring this processor and add the INSERT SQL statement
-
INSERT INTO countries_count (counter) VALUES (${data_size})
-
-
import groovy.json.JsonSlurper
FlowFile flowFile = session.get()
if (flowFile == null) {
return
}
String responseBody = flowFile.getAttribute('data')
if (responseBody != null) {
log.info("Response JSON Data: " + responseBody)
def jsonSlurper = new JsonSlurper()
def data = jsonSlurper.parseText(responseBody)
session.putAttribute(flowFile, "data_size", data.size().toString())
session.transfer(flowFile, REL_SUCCESS)
return
}
session.transfer(flowFile, REL_FAILURE)Groovy Script Body is from ExecuteScript Processor
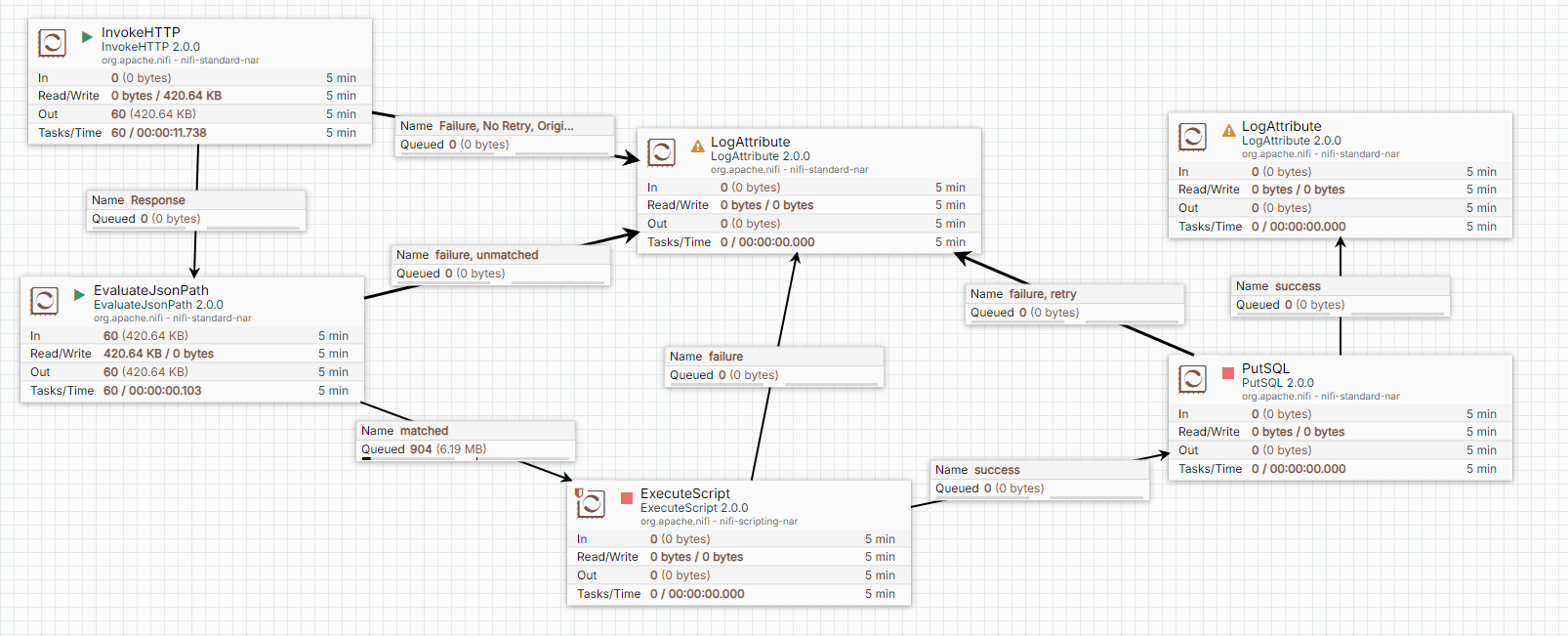
Case (1) The Completed Data Pipeline
-
The completed data pipeline looks like a flow control chart
-
It determines how the data routed in this pipeline
-
The LogAttribute Processor is used to record the message
Case (1) Run the Completed Data Pipeline
-
Making all data pipeline running!
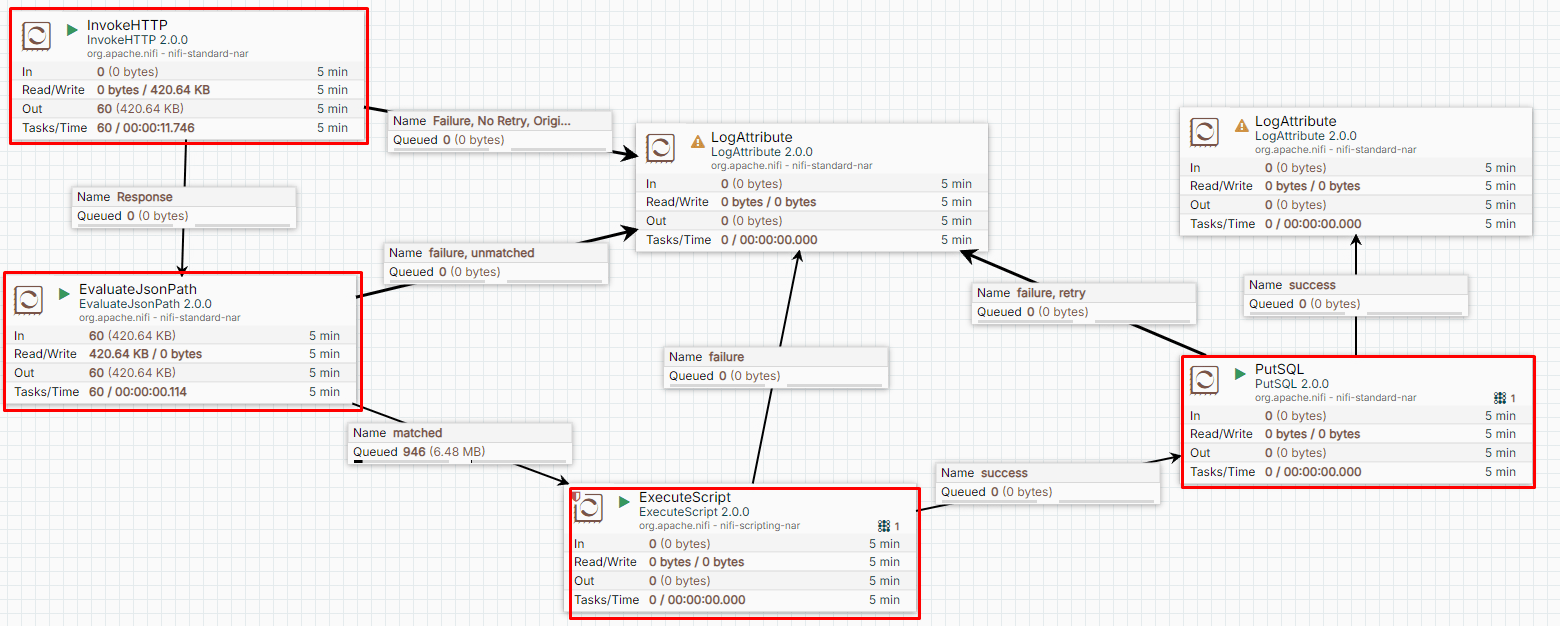
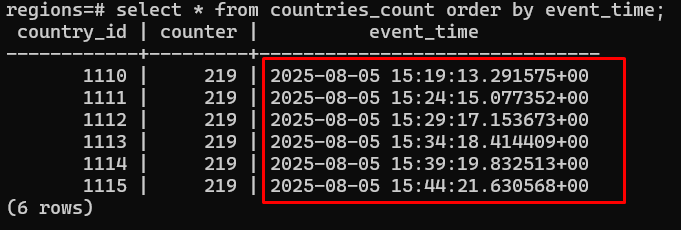
Case (1) Verifying the Data Pipeline (1/3)
-
We ensure processed data will be stored in the DB correctly
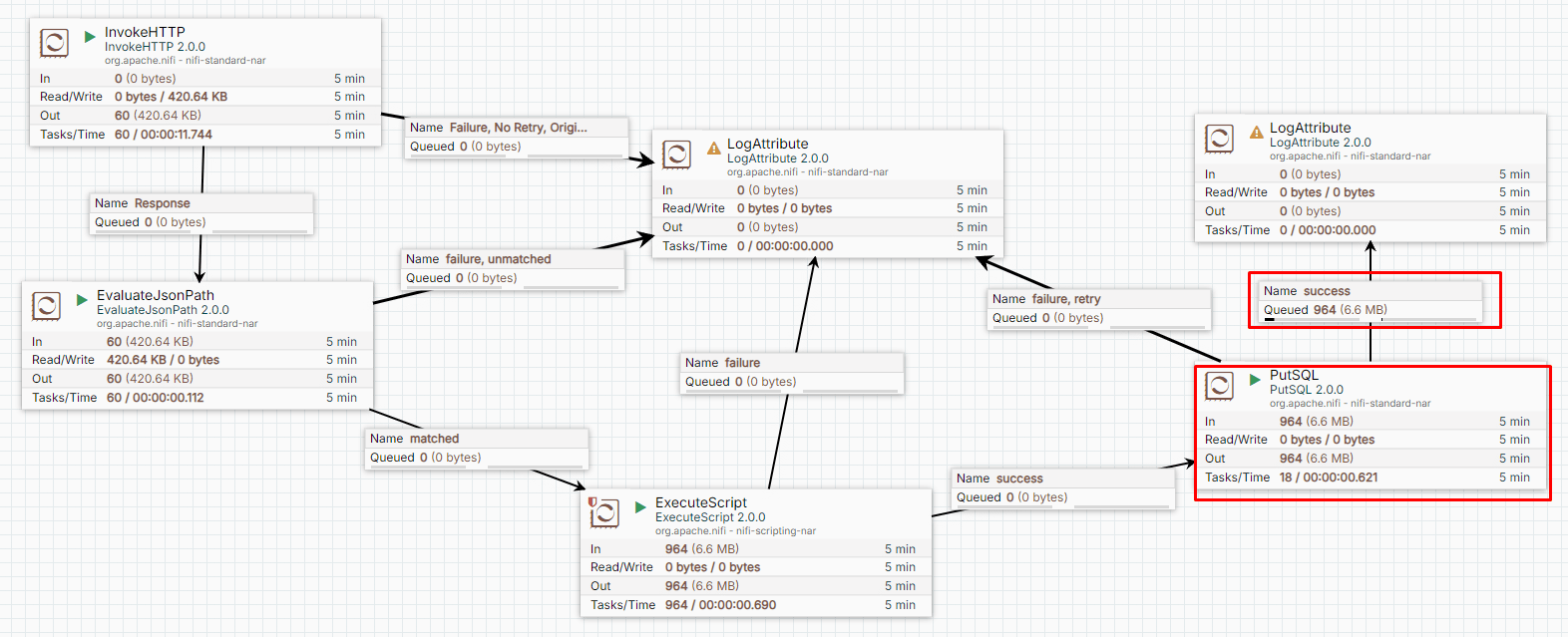
Case (1) Verifying the Data Pipeline (2/3)
-
Entering the PostgreSQL shell and ensuring these records
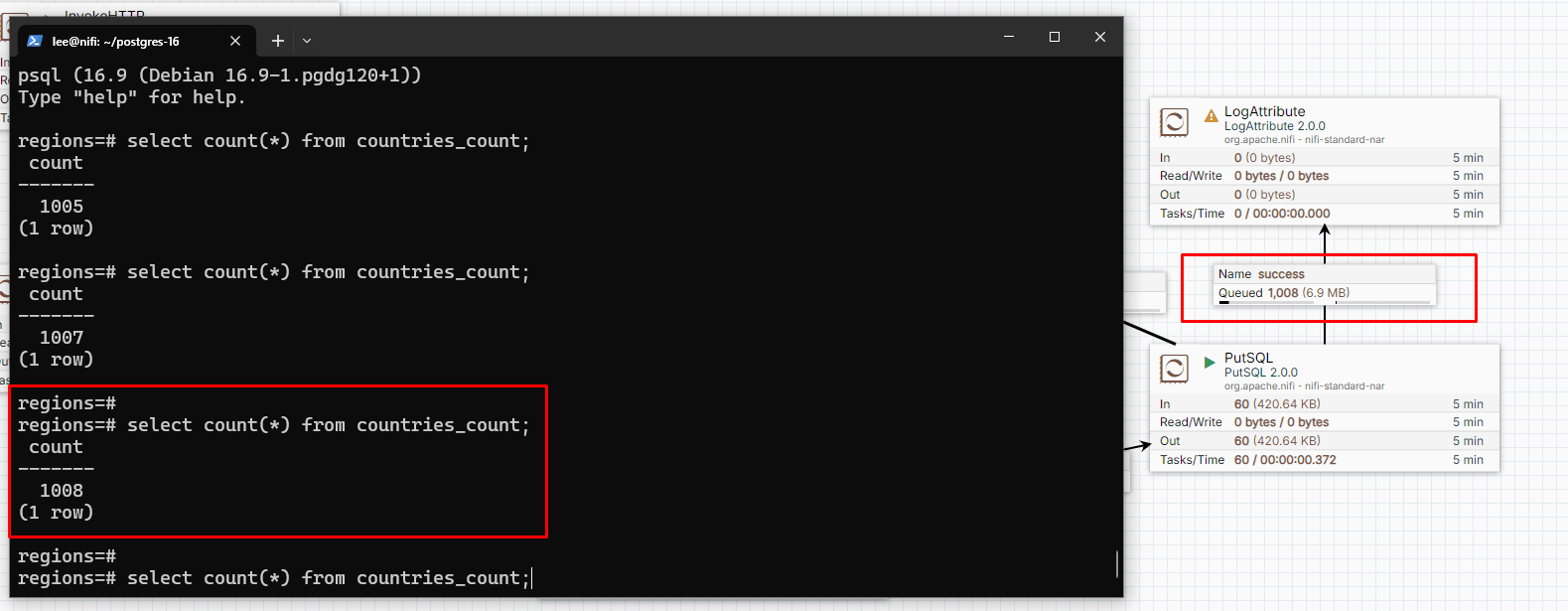
Case (1) Verifying the Data Pipeline (3/3)
-
Entering the PostgreSQL shell and ensuring these records
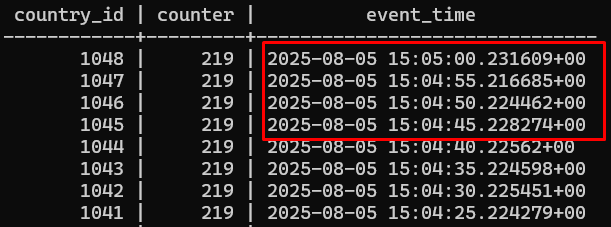
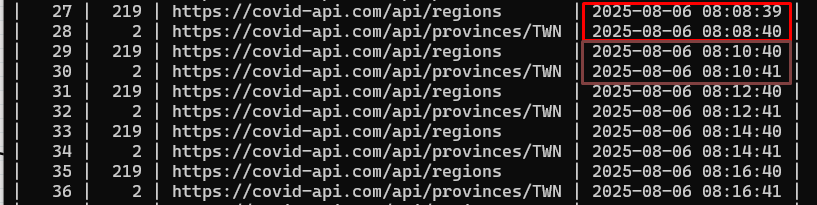
Case (1) Configuring the schedule
-
We can configure and schedule the InvokeHTTP Processor
-
For example, configuring fetch the remote URL every 5 minutes
-
Using the timer driven to complete the setting
-
The configuration can be "1 sec", "1 min", "1 hour" or "1 day"
-
-
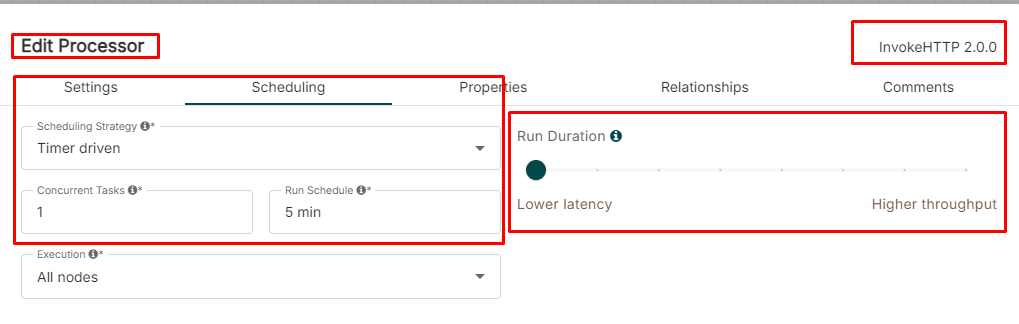
Case (1) Verifying the schedule configuration
-
We can configure and schedule the InvokeHTTP Processor
-
Verifying the schedule configuration
-
Outlines
-
What's NiFi?
-
NiFi Components Introduction
-
Integrating PostgreSQL with the NiFi
-
Case(1)、Using the NiFi and PostgreSQL to build a Aggregating Calculating Data Pipeline
-
Case(2)、Using the NiFi and PostgreSQL to build a Collecting Data Pipeline
-
-
How to deploy the NiFi Cluster?
-
How to measure the NiFi performance?
-
Summary and Future Work
Case (2) Building a collecting data pipeline
-
This data pipeline is used to collect the data
-
We design a data pipeline to complete this case. The building steps are as follows:
-
Creating two InvokeHTTP Processors
-
Sending HTTPS request to https://covid-api.com/api/regions
-
Sending HTTPS request to https://covid-api.com/api/provinces/TWN
-
-
Creating two EvaluateJsonPath Processors
-
Using the JSONPath to filter the data field ($.data) and store "data" attribute
-
Using the JSONPath to filter the data field ($.data) and store "prov_data" attribute
-
-
Creating two ExecuteScript Processors
-
Using Groovy Script to read "data" attribute and retrieve length
-
Using Groovy Script to read "prov_data" attribute and retrieve length
-
-
Creating two PutSQL Processors
-
Execute SQL to store the collected results for both the "data" and "prov_data" records
-
Case (2) The ExecuteScript Processor (1/2)
-
This data pipeline is similar with the case (1)
-
The different things are about ExecuteScript Processor-1
-
import groovy.json.JsonSlurper
FlowFile flowFile = session.get()
if (flowFile == null) {
return
}
String responseBody = flowFile.getAttribute('data')
if (responseBody != null) {
log.info("Response JSON Data: " + responseBody)
def jsonSlurper = new JsonSlurper()
def data = jsonSlurper.parseText(responseBody)
session.putAttribute(flowFile, "data_size", data.size().toString())
session.putAttribute(flowFile, "data_type", "data_size")
session.transfer(flowFile, REL_SUCCESS)
return
}
session.transfer(flowFile, REL_FAILURE)Case (2) The ExecuteScript Processor (2/2)
-
This data pipeline is similar with the case (1)
-
The different things are about ExecuteScript Processor-2
-
import groovy.json.JsonSlurper
FlowFile flowFile = session.get()
if (flowFile == null) {
return
}
String responseBody = flowFile.getAttribute('prov_data')
if (responseBody != null) {
log.info("Response JSON Data: " + responseBody)
def jsonSlurper = new JsonSlurper()
def data = jsonSlurper.parseText(responseBody)
session.putAttribute(flowFile, "prov_data_size", data.size().toString())
session.putAttribute(flowFile, "data_type", "prov_data_size")
session.transfer(flowFile, REL_SUCCESS)
return
}
session.transfer(flowFile, REL_FAILURE)Case (2) The PutSQL Processor (1/2)
-
This data pipeline is similar with the case (1)
-
The different things are about PutSQL Processor
-
Reusing the DBCPConnectionPool Controller Service
-
Creating the new data_count table in the PostgreSQL DB
-
regions=# CREATE TABLE data_count (
count_id SERIAL PRIMARY KEY,
counter INT, data_type VARCHAR(20),
event_time TIMESTAMPTZ DEFAULT CURRENT_TIMESTAMP
);
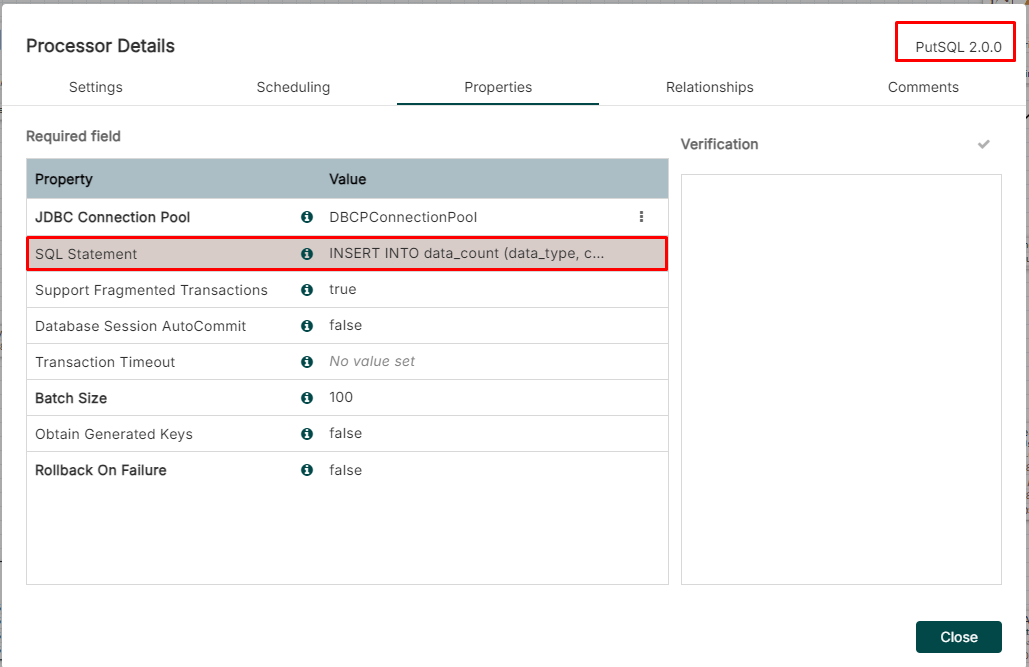
CREATE TABLECase (2) The PutSQL Processor (2/2)
-
This data pipeline is similar with the case (1)
-
The different things are about PutSQL Processor
-
Noticing that the PutSQL Processor SQL Statement
-
INSERT INTO data_count (data_type, counter) VALUES ('${data_type:toString()}', ${data_size})
-
INSERT INTO data_count (data_type, counter) VALUES ('${data_type:toString()}', ${prov_data_size})
-
-
Case (2) The Completed Data Pipeline
-
The LogAttribute Processor is used to record the message
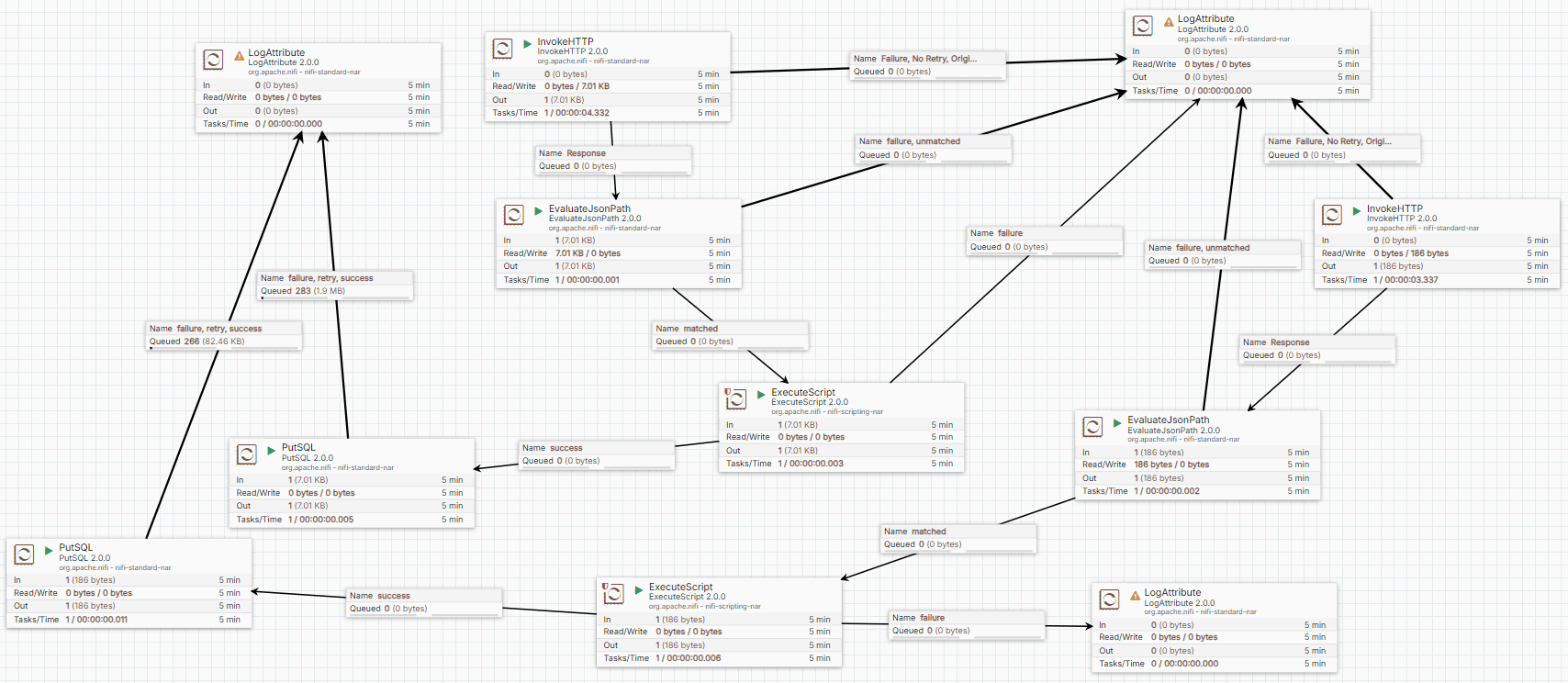
Case (2) Verify the Data Pipeline
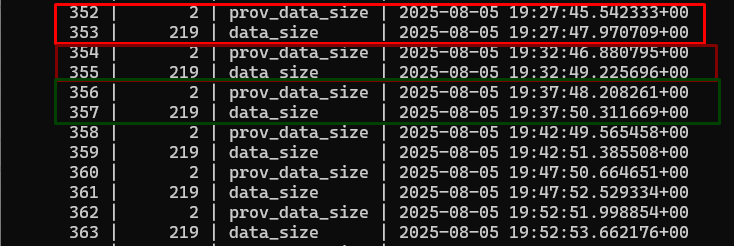
-
We check these records in the data_count table to verify the Data Pipeline
Think Twice: Simplify Case (2) Data Pipeline
-
We try to consider simplifying the Case (2) Data Pipeline
-
Let API URLs be stored in the SQL database and remove some "two" processors
-
And query them to use batched approach to send the API request
-
-
Here is the simplified Data Pipeline
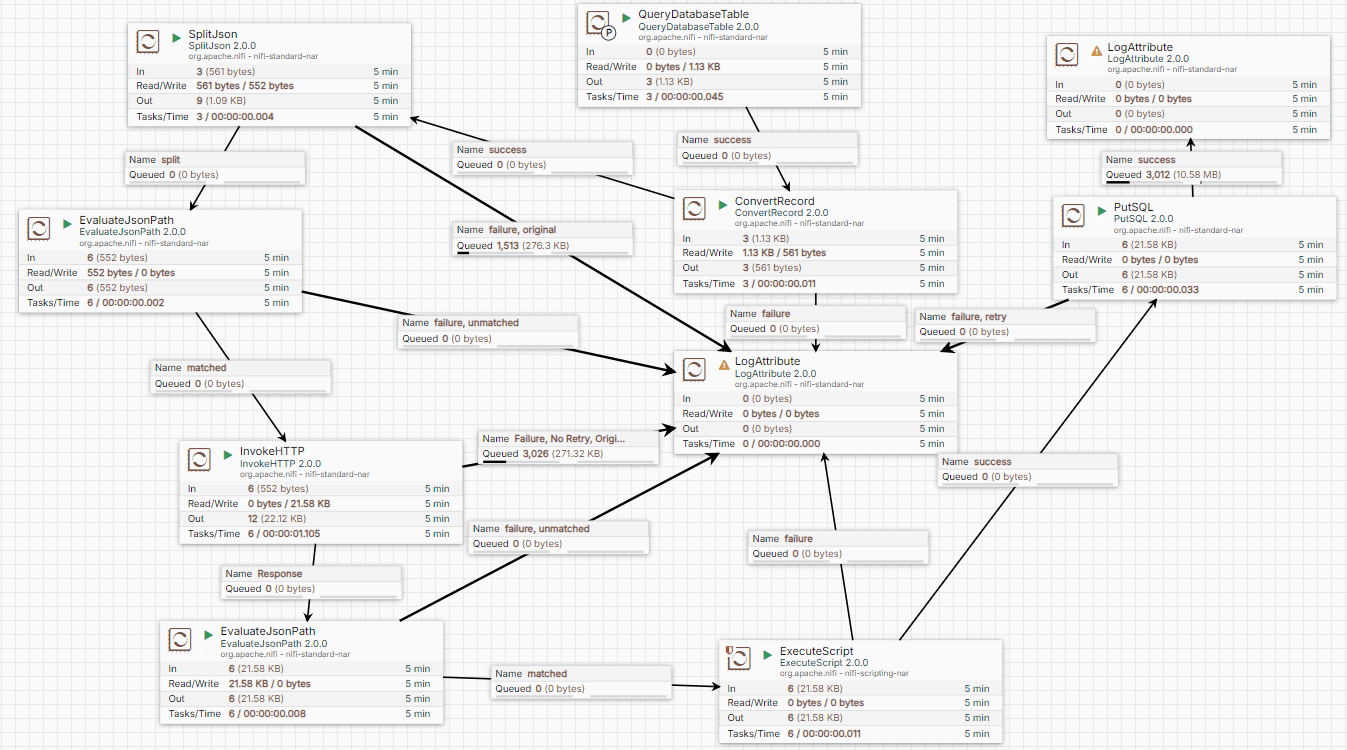
Outlines
-
What's NiFi?
-
NiFi Components Introduction
-
Integrating PostgreSQL with the NiFi
-
Case(1)、Using the NiFi and PostgreSQL to build a Aggregating Calculating Data Pipeline
-
Case(2)、Using the NiFi and PostgreSQL to build a Collecting Data Pipeline
-
-
How to deploy the NiFi Cluster?
-
How to measure the NiFi performance?
-
Summary and Future Work
How to deploy the NiFi Cluster? (1/2)
-
To make NiFi work with the high availability feature,
-
It should consider deploying the NiFi cluster
-
-
Using the Zookeeper to coordinate the nodes in the NiFi Cluster
-
The NiFi Cluster is deployed as the zero-master feature
-
Coordinator Node
-
Primary Node
-
Isolated Processors
-
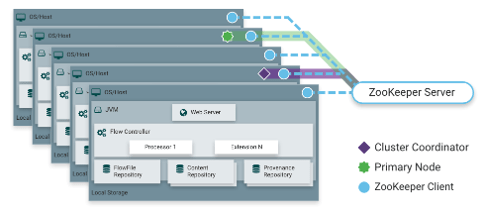
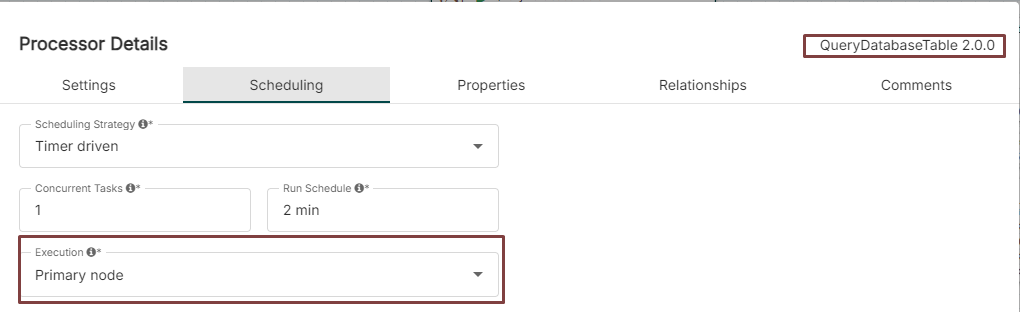
How to deploy the NiFi Cluster? (2/2)
-
Deploying the NiFi Cluster strategy references are as follows:
-
Using Docker compose to deploy the NiFi Cluster
-
Using NiFiKop to deploy the NiFi Cluster in the Kubernetes Cluster
-
Outlines
-
What's NiFi?
-
NiFi Components Introduction
-
Integrating PostgreSQL with the NiFi
-
Case(1)、Using the NiFi and PostgreSQL to build a Aggregating Calculating Data Pipeline
-
Case(2)、Using the NiFi and PostgreSQL to build a Collecting Data Pipeline
-
-
How to deploy the NiFi Cluster?
-
How to measure the NiFi performance?
-
Summary and Future Work
How to measure the NiFi performance?
-
There're some ways about measuring the NiFi performance
-
Measuring specific Processor performance with the status history
-
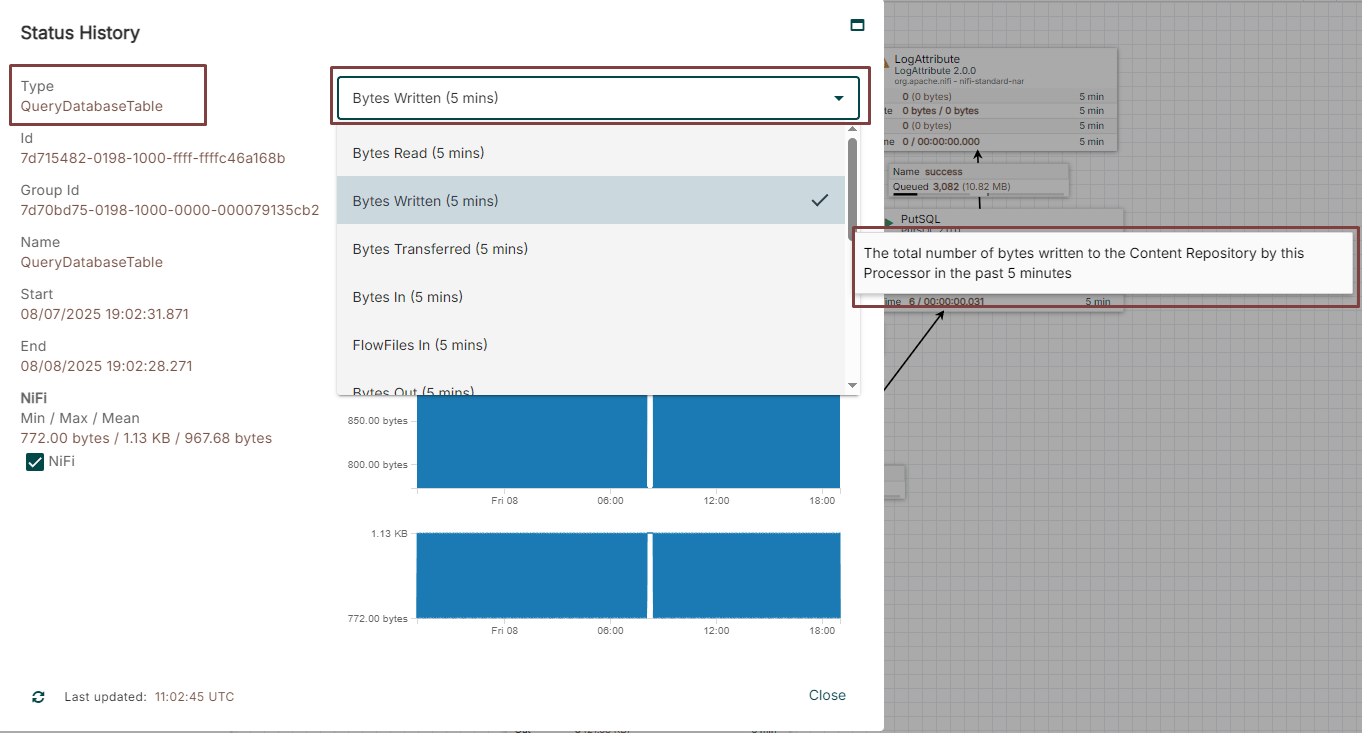
How to measure the NiFi performance?
-
There're some ways about measuring the NiFi performance
-
Measuring specific Processor performance with operating information
-
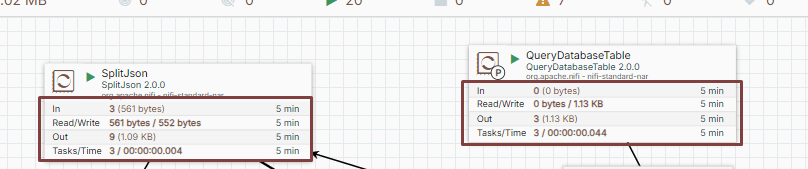
Outlines
-
What's NiFi?
-
NiFi Components Introduction
-
Integrating PostgreSQL with the NiFi
-
Case(1)、Using the NiFi and PostgreSQL to build a Aggregating Calculating Data Pipeline
-
Case(2)、Using the NiFi and PostgreSQL to build a Collecting Data Pipeline
-
-
How to deploy the NiFi Cluster?
-
How to measure the NiFi performance?
-
Summary and Future Work
Summary and Future Work (1/2)
-
NiFi is a great tool to build routine data collection processing
-
It can consider avoiding complicated data pipeline flow
-
We can consider following approaches to simplify data flow:
-
Using the ExecuteStreamCommand Processor
-
Build your own Processor
-
-
-
Consider using OIDC to integrate authorization server
-
For example, the authorization server can be Keycloak or Google Identity OIDC
-
-
NiFi can be used as part of a Data Middle Platform
-
Consider deploying the NiFi Clusters to make high availability
-
NiFiKop can be easy for you to complete this goal
-
Summary and Future Work (2/2)
-
Monitoring the NiFi or NiFi Data Pipeline is important
-
It can consider using the NiFi REST API to complete this purpose
-
-
To make automated NiFi Data Pipeline management,
-
It can consider using the NiFi REST API to complete this purpose
-
-
Using the NiFi to collect data scenario is very appropriate
-
Using the LogAttribute Processor to collect logs
-
For example, it can use the Elasticsearch to collect logs
-
-
Considering deploying an event-driven architecture
-
Using the Kafka or RabbitMQ to integrate the NiFi and develop a EDA
-
References
-
NiFi Expression Language Reference
-
https://nifi.apache.org/docs/nifi-docs/html/expression-language-guide.html
-
Apache Nifi Expression Language Cheat Sheet
-
-
Apache Groovy Script Reference
-
BYOP: Custom Processor Development with Apache NiFi
-
More NiFi Data Pipeline References
Any Questions?
COSCUP 2025: My Best Practices about Integrating NiFi with the PostgreSQL database
By peter279k
COSCUP 2025: My Best Practices about Integrating NiFi with the PostgreSQL database
COSCUP 2025: My Best Practices about Integrating NiFi with the PostgreSQL database




