Best practices for using PHP to develop web crawlers!
Peter
Outline
-
About me
-
The motivation about writing this book
-
Guide for book
-
Technical keywords introduction
-
Section introduction
-
-
Extended sections
-
Missed, but important advanced crawling
-
-
Feedback about publishing book
Slide

About me
- Peter
- GitHub
- Active open source contributor
-
An associate engineer
- DevOps
- Back-end
- System Architecture Researching
- Web Application Security
- PHP, Python and JavaScript
- Smart Grid Technology (2017~2021)
- Database, Data platform architecture (2021~)


The Motiviation
Joke

Thinking?

Back to 2014
My small story about learning web crawler
Do you know this book?


The original author

Reading book......
Writing e-mail to ask author?
Ask author

Receive Reply from author
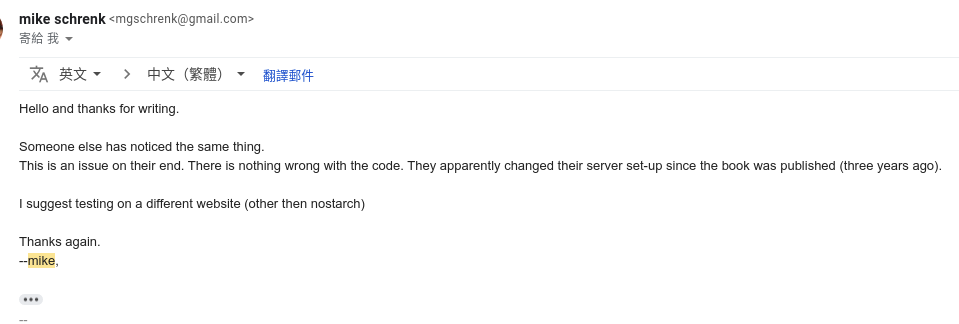
Receive Reply from author
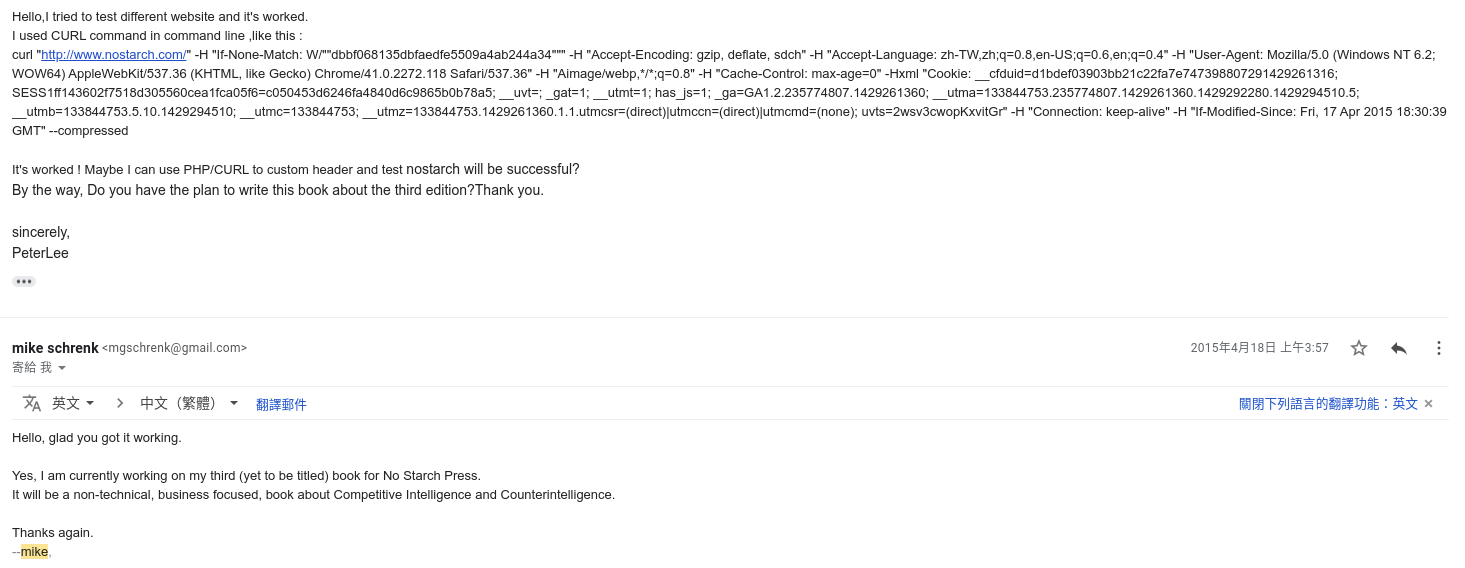
Screen Scraper Tricks Extracting Data from Difficult Websites
From then on
After six years...
There's no new book about PHP Web Crawler
That's why I write new one!
Guide for the book
Guide for book section
-
Section 1 to 10
-
Appendix A
Sample codes
Section 1
Fundamentals
Web crawler, spider and bot
Development Environment setup
Section 2
Lab 1-1、My university website
Analyze website behavior
Implementing RSS news fetching
Implementing RSS news parsing
-
Google Chrome DevTools
-
HTML/CSS
-
RSS
-
DOM
Section 3
Lab 1-2、University website
Analyze website loading contents
-
AJAX
-
HTTP POST Method
-
Google Chrome Dev Networks
Section 4
Lab 2-1、Courses Search System
Analyze course outlines website
-
AJAX
-
HTTP POST Method
-
Google Chrome Dev Networks
-
ASP.NET Forms
Analyze & Implement courses search system
Web crawler development troubleshooting
Section 5
Lab 3-1、Securities website
Analyze and Implement Securities data website
-
HTTP GET Method
-
Google Chrome Dev tools
-
ASP.NET
Fetch & analyze Securities web contents
Section 6
Lab 4-1、Convenient Store Cloud Printer
FamilyMart-part1
-
QRCode
-
base64 encode/decode
-
Google Chrome Dev tools
-
uuid
-
ramsey/uuid
-
ASP.NET
7-ELEVEN-part2
Section 7
Case studies integration
Cronjob integration
-
Gandi SMTP
-
MailGun
-
Cronjob
Section 8
Advanced web crawling techniques
Automated、Headless web browser
Anti-web-crawler→Captcha code
-
Selenium Web Driver
-
Headless Chrome
-
Puppeteer
-
Tesseract
Section 9
Lab 5-1
-
Tesseract
Automated login for a shopping website
Implement automated login webbot
Implement history shopping lists web crawler
Section 10
Lab 5-2
-
LocalStorage
-
chrome-php/chrome
-
nesk/puphpeteer
Radio program website
Analyze radio MP3 audio file download
Lists of MP3 audio file download-part1
A single audio file download-part2
Appendix A
Providing OVA file to import VirtualBox
Development environment setup
Register a MailGun account for section 7

Additional materials
-
Fetching HTTP requests from non-browser
-
Advanced recaptcha identifying
-
Cloud computing provider integration
Fetching HTTP requests from non-browser
Desktop App:Lightshot


Lightshot
Lightshot screenshot image

Lightshot uploading image

Lightshot uploading image link
https://prnt.sc/1sejtdr
How to upload picture?
How to upload file to https://prnt.sc?
Fetching Desktop App HTTP packets
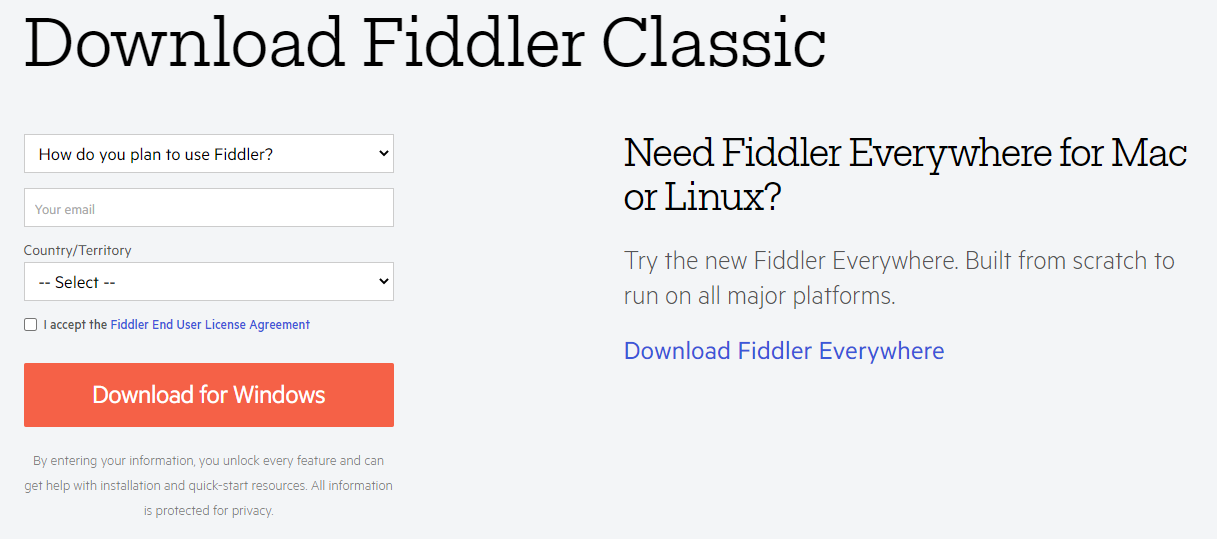
Operating system:Win 10
Installation steps
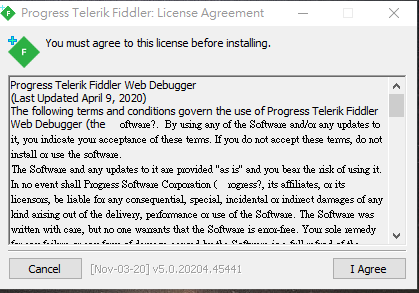
Installation steps
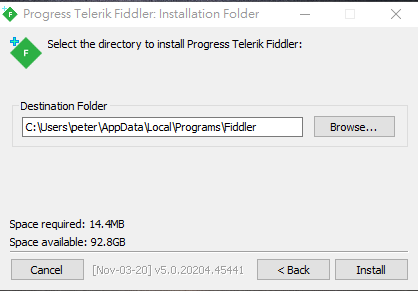
Installation steps
Installation steps
Installation steps
Usage
Open Fiddler4
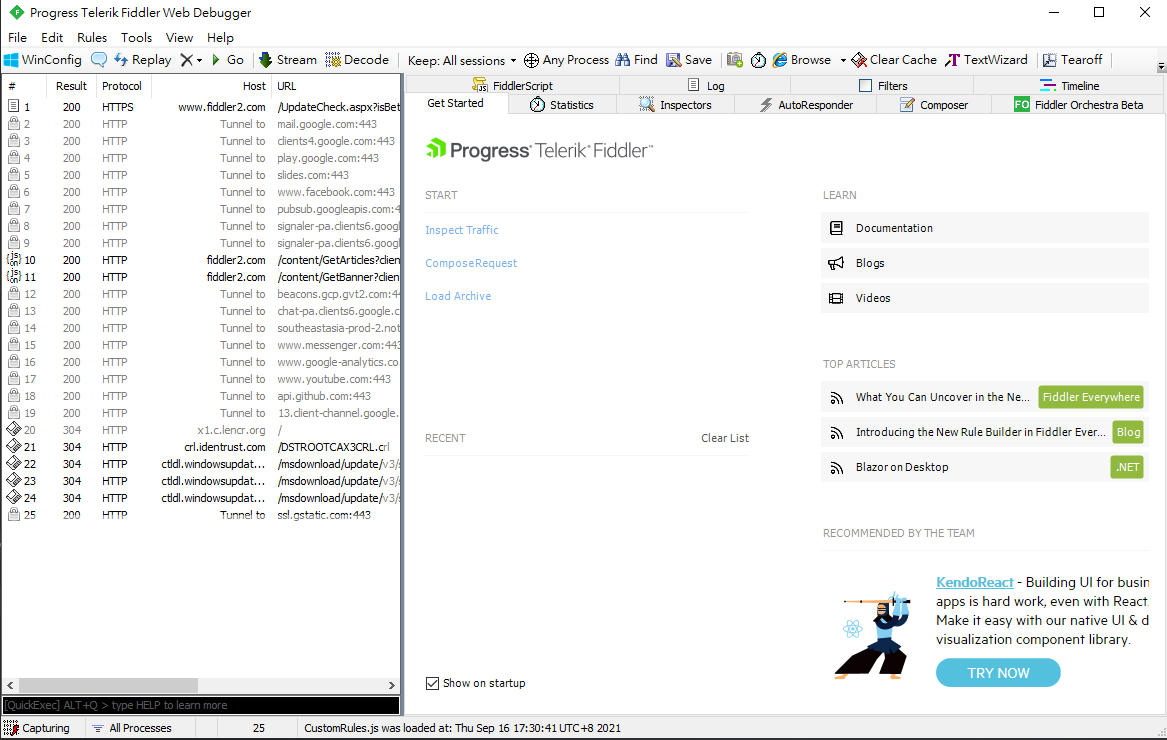
Configure non-browser only
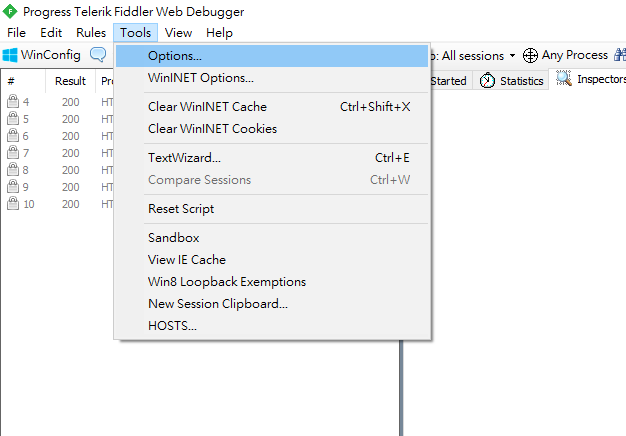
Configure non-browser only
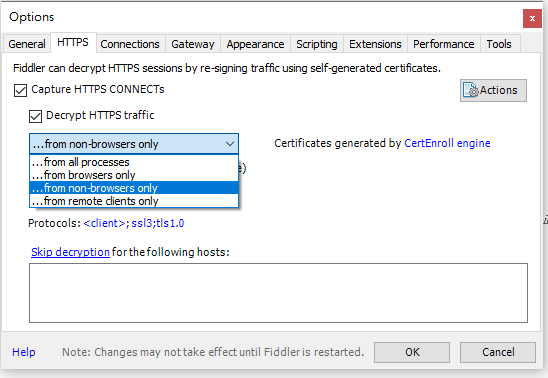
Trusted self-signed certificate
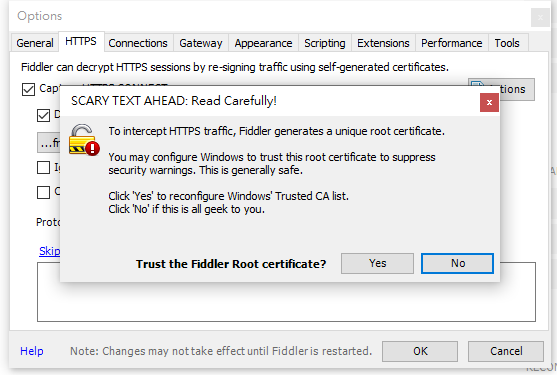
Filtering non-browser only requests

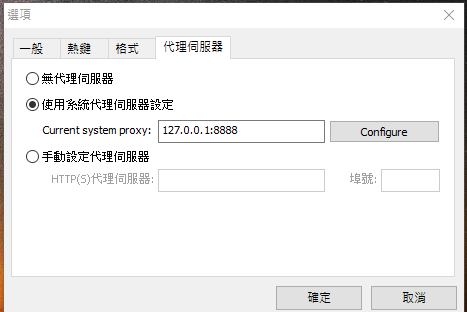
Proxy sever setup for Lightshot
Configure proxy server for Lightshot
Using Lightshot do screenshot & uploading
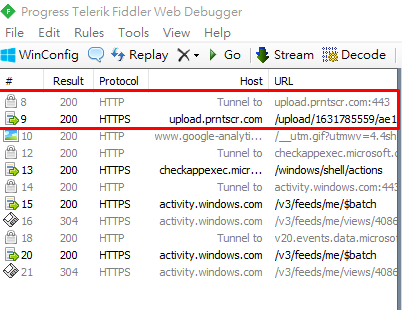
Using Fiddler to find HTTP requests
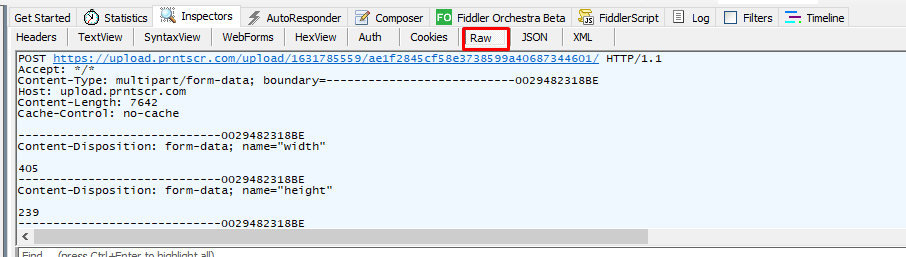
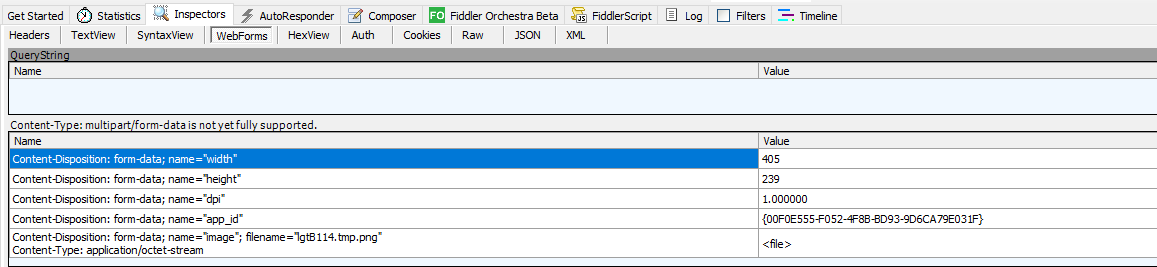
Develop uploading image program
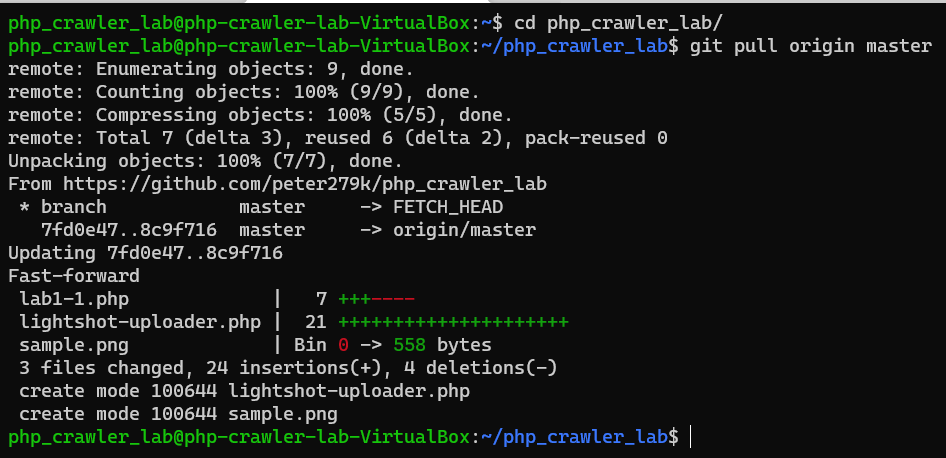
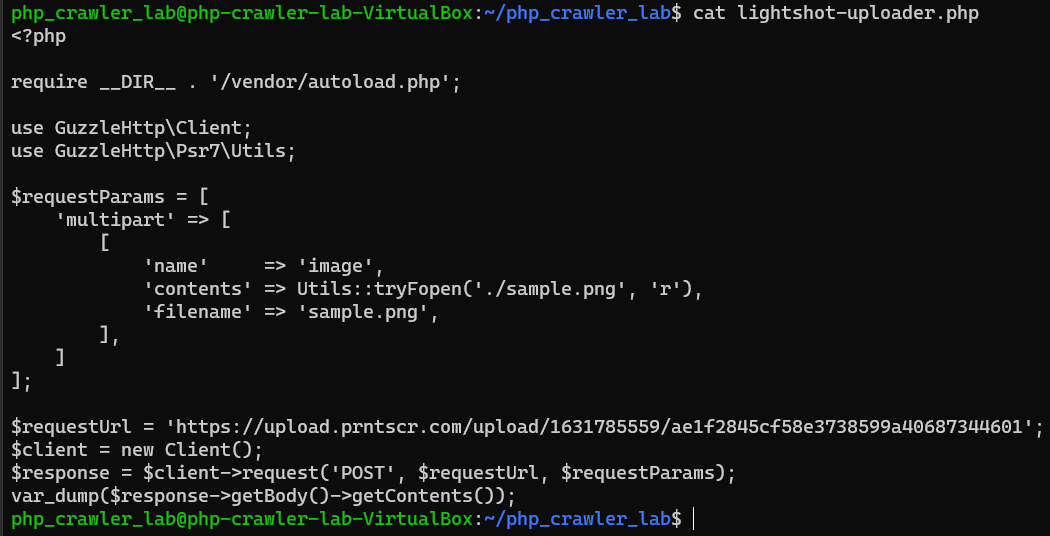
Develop uploading image program



Develop uploading image program
Advanced captcha image processing

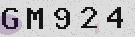
Advanced captcha image processing
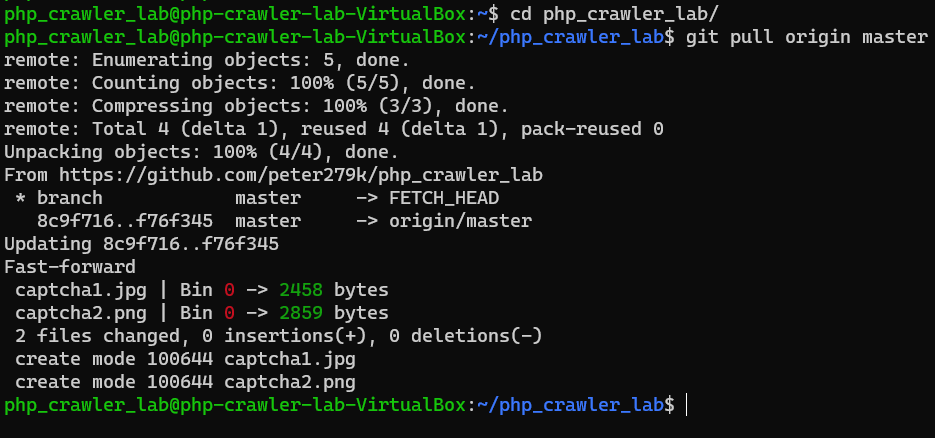

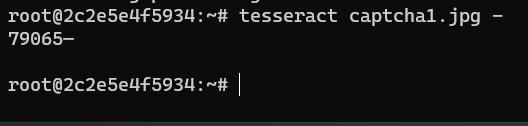
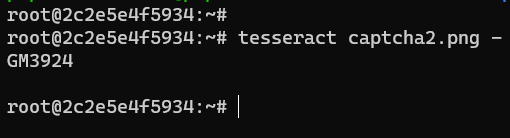
Advanced captcha image processing
ImageMagick

Install ImageMagick
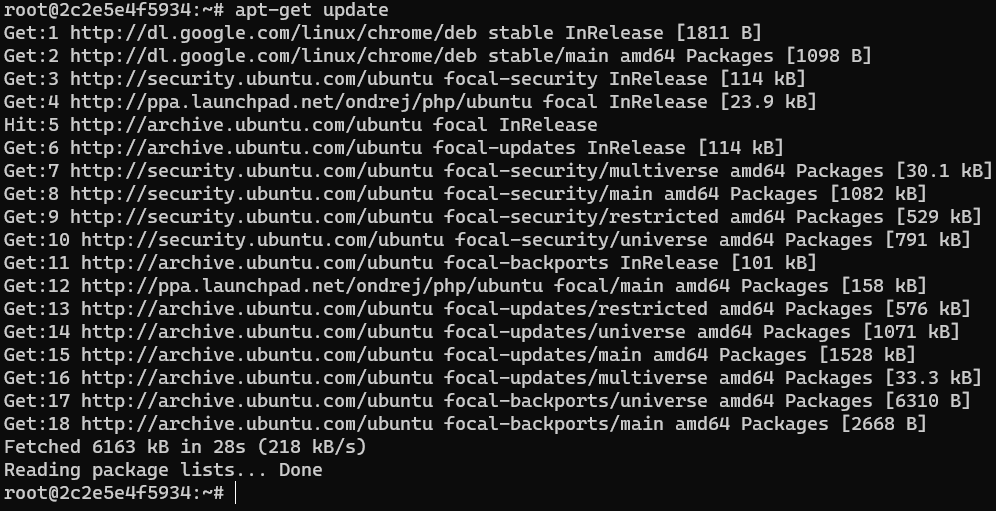
Install ImageMagick
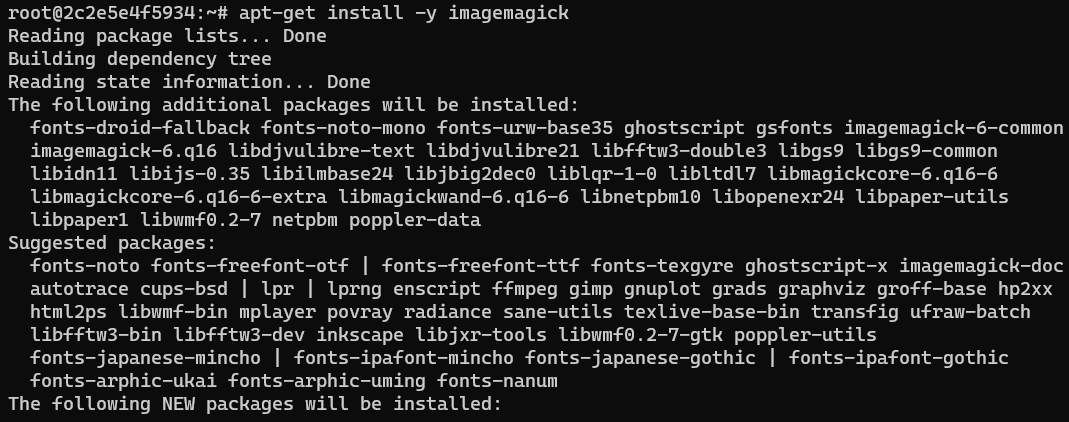
convert command usage
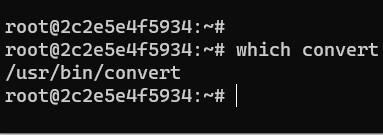
Gray scale image
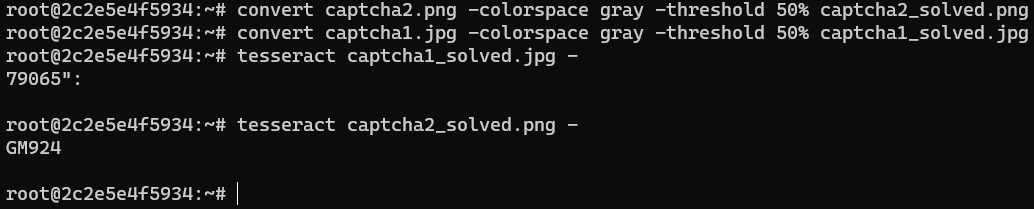
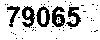
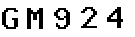
Gray scale image with PHP
Gray scale image with PHP
Gray scale image with PHP
<?php
// Threhold captcha image to be gray background
$captchaPath = './captcha1.jpg';
$solvedCaptchaPath = './captcha1_solved.jpg';
$imageMagick = new \Imagick($captchaPath);
$imageMagick->SetColorspace(Imagick::COLORSPACE_GRAY);
$max = $imageMagick->getQuantumRange();
$imageMagick->thresholdImage(0.5 * $max['quantumRangeLong']);
$imageMagick->setImageFormat("png");
file_put_contents($solvedCaptchaPath, $imageMagick);OCR on Google Cloud support

Feedback for publishing book


More additional materials
References
Contact me!
My e-mail address is available on my GitHub
Thanks!
Best practices for using PHP to develop web crawlers!
By peter279k
Best practices for using PHP to develop web crawlers!
PHP Conference Japan 2021




