
Patrick Power
Economics PhD @ Boston University
Example: When Learning is Costly
Why is this not a good idea?
What's a Better Idea?
10 Immediate Data Questions
(1) What is the Unit of Observations
(2) Am I working with the population? If not, how was the sample formed?
(3) What types of variable do I have? Continuous/ Discrete/ Categorical?
(A) How are they distributed?
(B) Should I be concerned about outliers?
(4) Is the task prediction or causal?
Data Analytics
Programming
Statistics
Probability Space
Starting Point
What are you uncertain about?
Example of rolling a die
Uncertain about which of the 6 values
Example of hiring a trader
How good a trader are they?
Sample Space
Set of possible outcomes that could happen
Example of rolling a die
Example of hiring a trader
Random Variables
Set of possible outcomes that could happen
Example of rolling a die
Example of hiring a trader
In Python
import jax
import jax.numpy as jnpRolling a Die
def f(x):
return 1 if x % 2 == 0 else -1Define the Random Variable
sample_space = jnp.array([1, 2, 3, 4, 5, 6])Sample Space
Key
outcome = jax.random.choice(jax.random.PRNGKey(0), sample_space)Experiment/ Simulation
Rolling a Die
def f(x):
return 1 if x % 2 == 0 else -1
sample_space = jnp.array([1, 2, 3, 4, 5, 6])
outcome = jax.random.choice(jax.random.PRNGKey(0), sample_space)
print(f(outcome))Winnings/ Losings
Hiring a Trader
def f(x):
return 2_000_000
outcome = jax.random.uniform(jax.random.PRNGKey(0), minval=0.0, maxval=1.0)
print(f(outcome))Winnings/ Losings
The Sample Space is Not Countable
Float
String
stringify
Float
Float
Float
percentage_grade
Float
Float
String
Set
Subset
Filter
Expectation
Filter
Standard Deviation
Dart Board
Sample Space
Subset
Dart Board
This specific point
Dart Board
Dart Board
Sample Space
Dart Board
Sample Space
Element
In
Such that
Get mapped into
Motivation
Programming
Statistics
Data Manipulation
Insight
Dart Board
Sample Space
Dart Board
Dart Board
Dart Board
Dart Board
Dart Board
We can assign probability to the subset A
Set of all WNBA Players
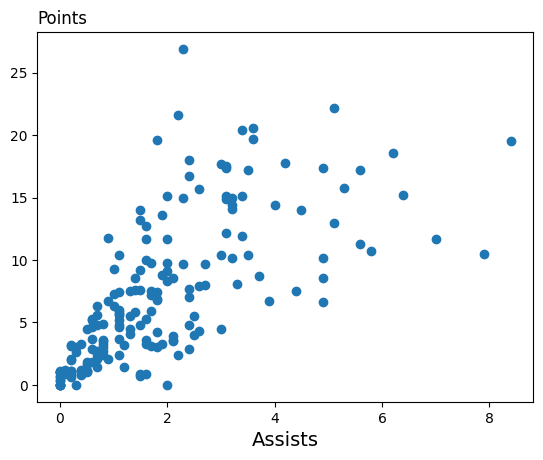
Points
Assists
Set of all WNBA Players
Points
Set of all WNBA Players
Teams
["Let's", "go", "to", "the", "beach"]
Set of all WNBA Players
Points
Assigns probability to subsets of Points
Set of all WNBA Players
Points
Points Demeaned
Points Demeaned Squared
Set of all WNBA Players
Points
Probability Space
The set of all possible outcomes
Sample Space
The set of all events that we can assign probability to
Event Space
A Function that assigns the probabilities
Probability Measure
Probability Space Example
The set of all people we could hire (finite set)
The set of all subsets of people that we could hire
Sample Space
Event Space
A Function that assigns 1/n
probability to each {i}
Probability Measure
(Continued)
All U.S. Houses
Price
Size
Price of House
Average Price Given Its Size
Error Term
Basics of Python
Data Manipulation
Probability Theory
Variables
Functions
For-loops
Lists
Dictionaries
Frequency Tables
Scatter Plots
Correlations
Filtering
Map
Sample Space
Random Variables
Probability Measures
Subsets
Expected Value
Variance
Variables
Functions
For-loops
Lists
Dictionaries
Frequency Tables
Scatter Plots
Correlations
Filtering
Map
Sample Space
Random Variables
Probability Measures
Subsets
Expected Value
Variance
Set of all WNBA Players
Set of all WNBA Players
Set of all WNBA Players
Movie Reviews
Positive Score
Large Language Model with prompt
All American Voters
Candidate
All Surveys
Candidate
Fraction Voting for Specific Candidate
All Surveys
Fraction Voting for Specific Candidate
All Surveys
Set of all Keys
Fraction Voting for Specific Candidate
Set of All Possible Midterm Questions
Subset of Questions on the Midterm
Set of All Possible Wednesdays
Specific Wednesday
Set of All Possible Wednesdays
Set of All Possible Midterm Questions
Set of all Midterm Experiences
Set of all Midterm Experiences
Function Space
Set of all Linear Functions
Function Space
Set of all Linear Functions
Parameter Space
Parameter Space
Objective Function
Function Space
Set of all Linear Functions
Parameter Space
Function Space
Parameter Space
Objective Function
How Does the Sample Mean Differ From the Population Mean?
How Do the Possible Sample Means Differ From Each Other?
Can We Estimate this "Variation"?
All US Voters
Age Group
Vote
All Phone Calls to Credit Card Customer Services
Day of the Month
Number of Calls
All listening sessions of podcasts
Podcast Type
Amount of Commericals listened to
All US Adults
Age
Income
All US Adults
Income
All Possible Surveys
Age
Income
All listening sessions of podcasts
Podcast Type
Amount of Commericals listened to
By Patrick Power




